1. Auto Encoder? 인코딩이 뭔데
"""인코딩이 뭔데! 나 빨리 VAE 공부하러 가야된다고!"""
인코딩이라는 것은 간단하게 말해서 zip파일과 같은 '압축'이라고 생각하면 된다.
압축을 이용하면 2차원의 이미지를 숫자 몇개 만으로도 표현할 수 있게 된다! (고차원의 이미지를, 저차원으로.)
그리고 이것이 Auto Encoder의 목표이다.
이미지를 어떻게 숫자 몇개로 압축하는지 이해가 안된다면, 간단한 예시를 한 번 보자.
0부터 9까지의 숫자들에 대한 손글씨 이미지들이 있다.근데, 흑백이라서 한 픽셀에 0부터 255까지의 값을 가질 수 있고, 그게 28x28 사이즈의 이미지이기에 256^(28*28) = 2의 6272승이라는 무지막지한 경우의 수가 생긴다.
그런데 우리는 이 이미지를 3가지 요소로 간단하게 분석할 수 있다.1. 0~9 중에 어떤 숫자인지2. 대충 어떤 글씨체인지3. 선 두께가 어느정도 되는지 등등
정말 대충 계산해서, 글씨체 1000종류 있다고 생각하고 선 두께가 1~10까지 있다고 생각해도10 1000 10 = 10만개의 경우으로 2의 6272승을 압축시킬 수 있다.

2. 그럼 어떻게 학습시킬까?
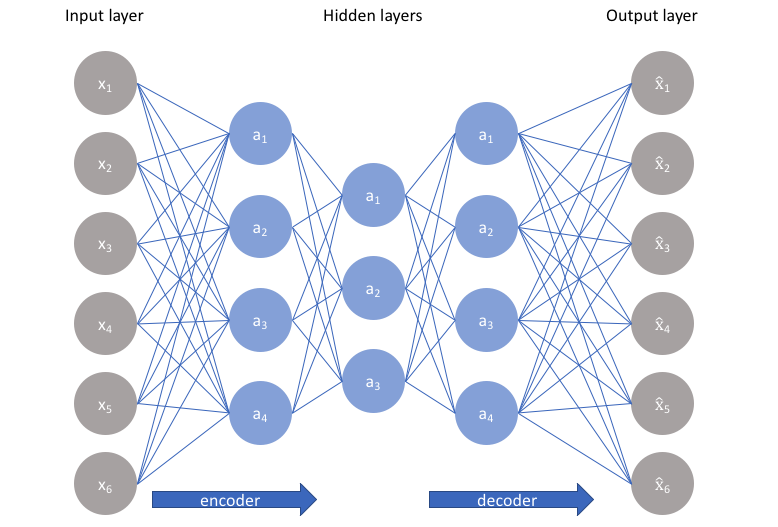
위처럼 생긴 네트워크에 이미지를 집어넣고,
중간레이어를 거쳐서 한번 압축한 후 다시 복원하도록 만든다.
"집어넣은 이미지 == 압축 후 복원한 결과 이미지"가 되도록 L1 loss를 취한다.
L1 loss가 뭔지 궁금하거나, 네트워크가 loss를 통해서 어떻게 학습하는지 궁금하면!
구글링하면 좋은 글이 많다 ㅎㅎ...
L1 loss는 픽셀단위로 값의 차이가 크면 클수록, 그만큼 페널티를 부여하는 것이고.
네트워크는 Back Propagation을 이용해서 학습하는데, 결과에서부터 어떻게 차근히 고쳐야할지 전달해나가는 것이다.
예를 들어, 맨끝에서 결과물이 '저 이미지처럼 생길려면 나는 100이 아니라 200을 받아야해!'라고 얘기하고,
그럼 맨끝에서 두번째는 '쟤한테 200을 주려면 우리는 2가 아니라 3을 곱해야하고, -5가 아니라 -3을 받아야해!'라고 하면서
전체적으로 퍼져나가 네트워크가 학습된다는 것이다.
(이해를 돕기위한 예시다. 정확한 학습은 따로!)
3. 압축하는 네트워크는 어떻게 구해요?
위 구조에서, 복원하는 부분을 똑! 떼버리면 압축하는 네트워크 완성이다.
보통 압축되어 나온 결과물을 _Latent Code, Latent Variabl_e 이라고 부른다.
이 포스팅에서는 이정도만 알아보자!
그럼 이제 수식의 지옥, 인공지능계의 뉴비 절단기, VAE로 떠나보자!
