
11/28

-> 해결 방법
#usual installation
pip install ipywidgets
jupyter nbextension enable --py widgetsnbextension
#you are my saver!
jupyter labextension install @jupyter-widgets/jupyterlab-manager
RuntimeError: CUDA out of memory. Tried to allocate 6.50 GiB (GPU 0; 31.75 GiB total capacity; 24.61 GiB already allocated; 1.73 GiB free; 28.79 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
-> 해결방법 : gpu 캐시를 비워주는 코드를 실행하는 해결됨
import gc
import torch
gc.collect()
torch.cuda.empty_cache()
11/29
git 오류
error: you need to resolve your current index first
-> git reset —merge로 해결 완료
11/30
GRU(Gate Recurrent Unit) 모델 구조
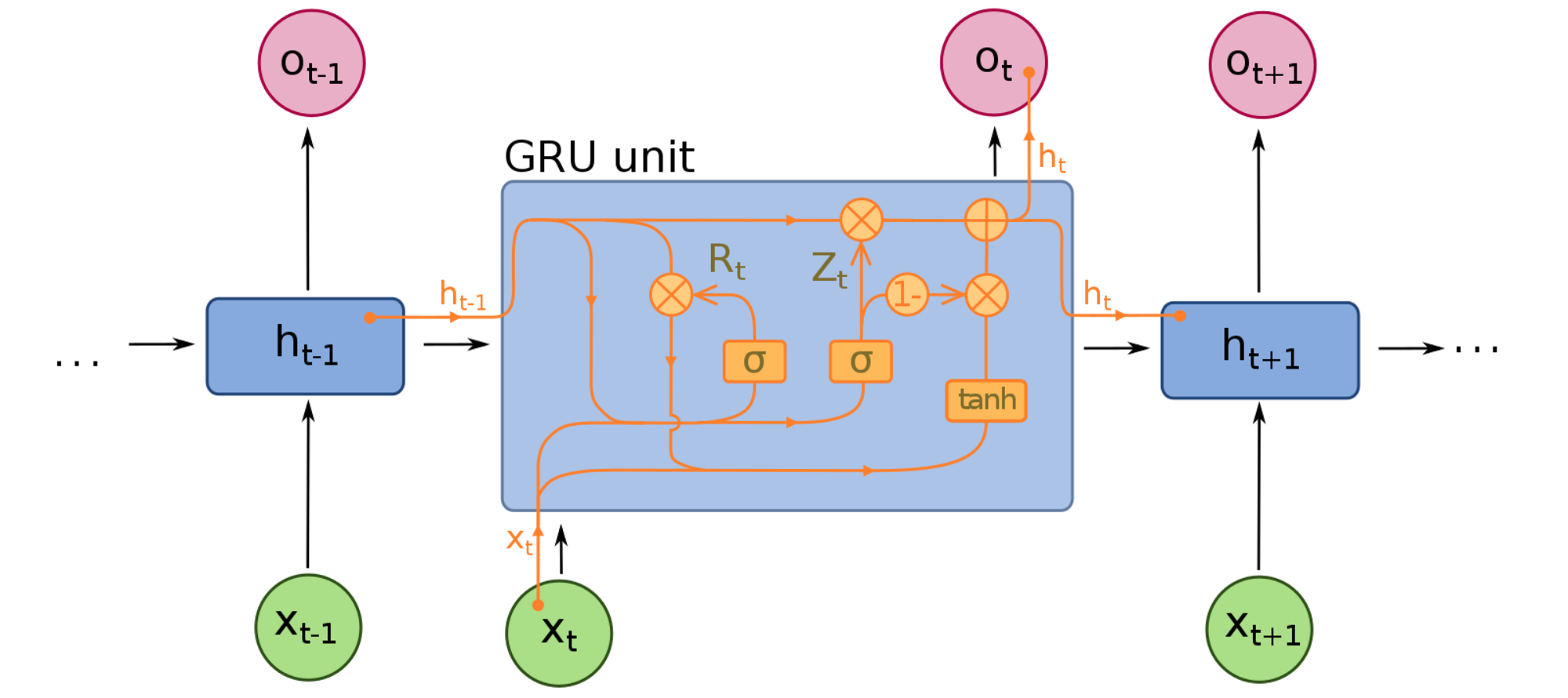
- Session : 유저가 서비스를 이용하는 동안의 행동을 기록한 데이터
- Session based Recommender System : 고객의 선호는 고정된 것이 아니므로 “지금” 고객이 좋아하는 것이 무엇인지 알아야 할 필요가 있다.
GRU4Rec 모델 구조
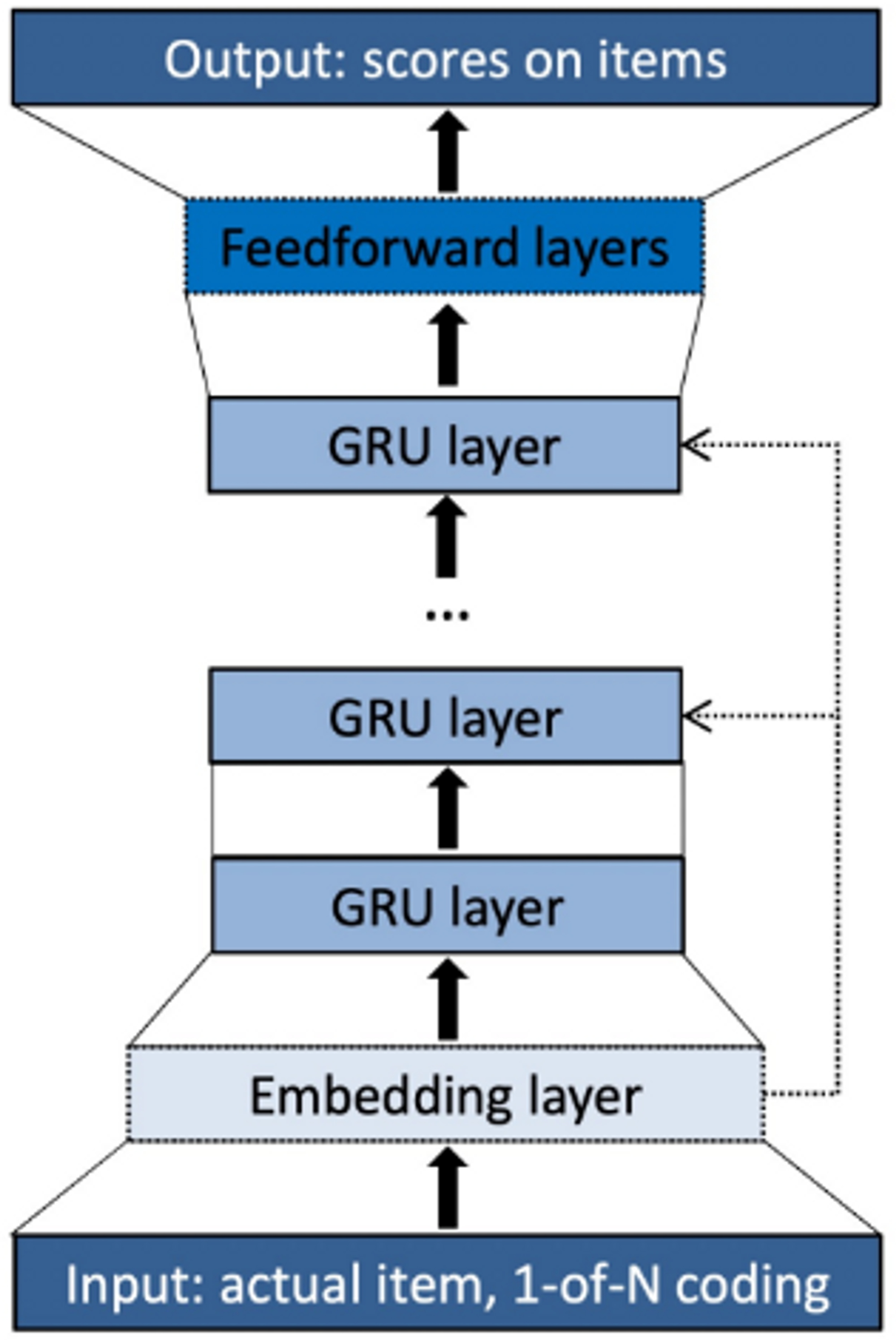
-
Session이라는 시퀀스를 GRU 레이어에 입력하여 바로 다음에 올 확률이 가장 높은 아이템을 추천하는 것.
-
input : One-hot encoding된 Session (Embedding layer가 점선으로 표현한 이유는 임베딩 레이어를 사용하지 않았을 때 성능이 더 높기 때문이다.)
-
GRU layer : 시퀀스 상 모든 아이템들에 대한 맥락적인 관계를 학습
-
Output : 다음에 추천될 아이템에 대한 선호도 스코어를 출력 (이때 Feedforward layer 또한 선택적으로 사용이 가능하다.)
GRU4Rec에 사용된 학습 테크닉
Session Parallel Mini Batches
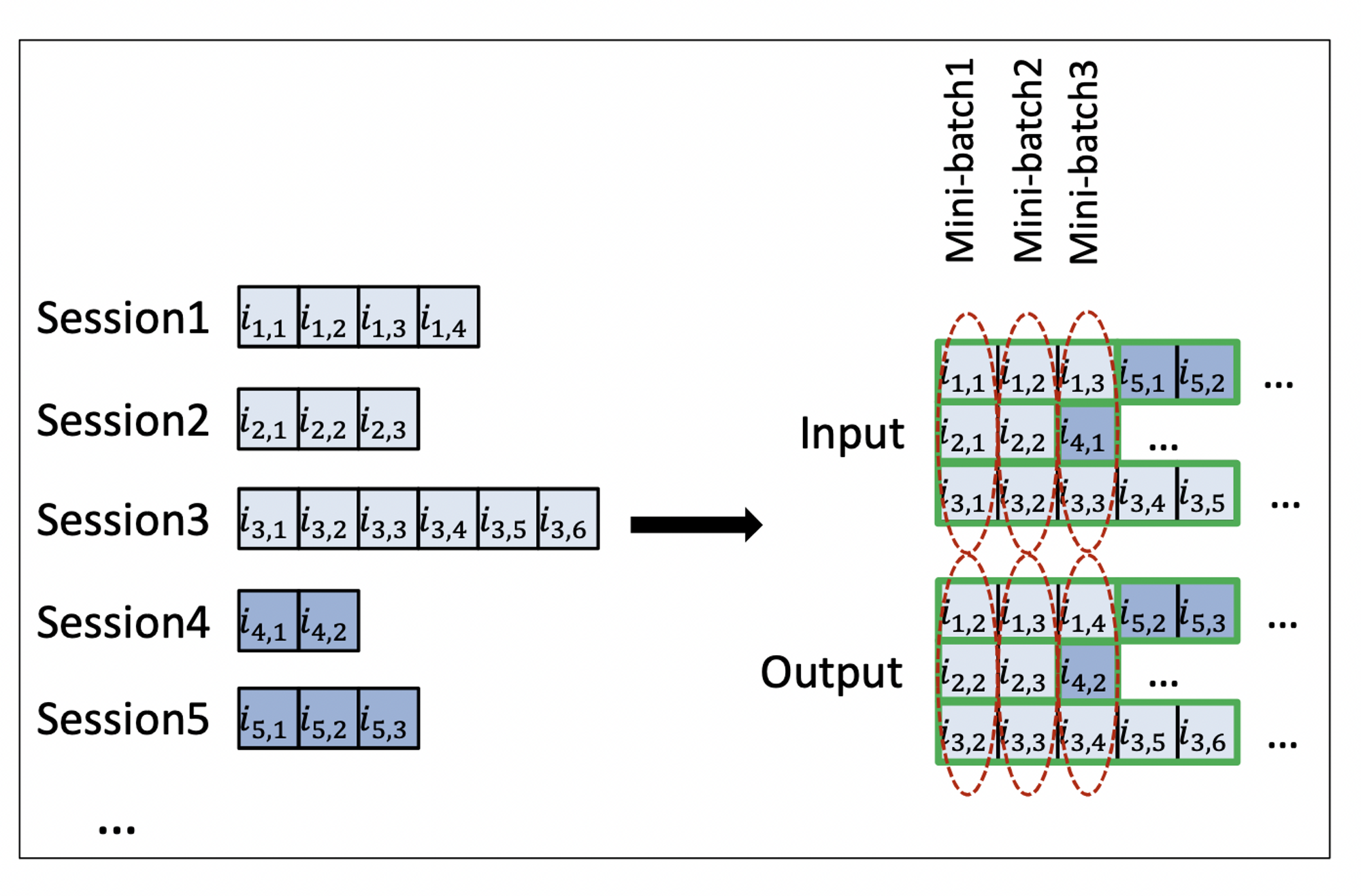
대부분 session이 짧지만 길이가 긴 것도 존재할 수 있음.
- 길이가 짧은 세션들이 단독 사용되어 Idle하지 않도록 세션을 병렬적으로 구성하여 미니 배치를 학습시킴
- 배치를 그대로 사용하는 것이 아니라 길이가 짧은 세션들은 다른 세션 뒤에 붙여서 미니 배치를 만들어 학습함
학습 데이터 sampling
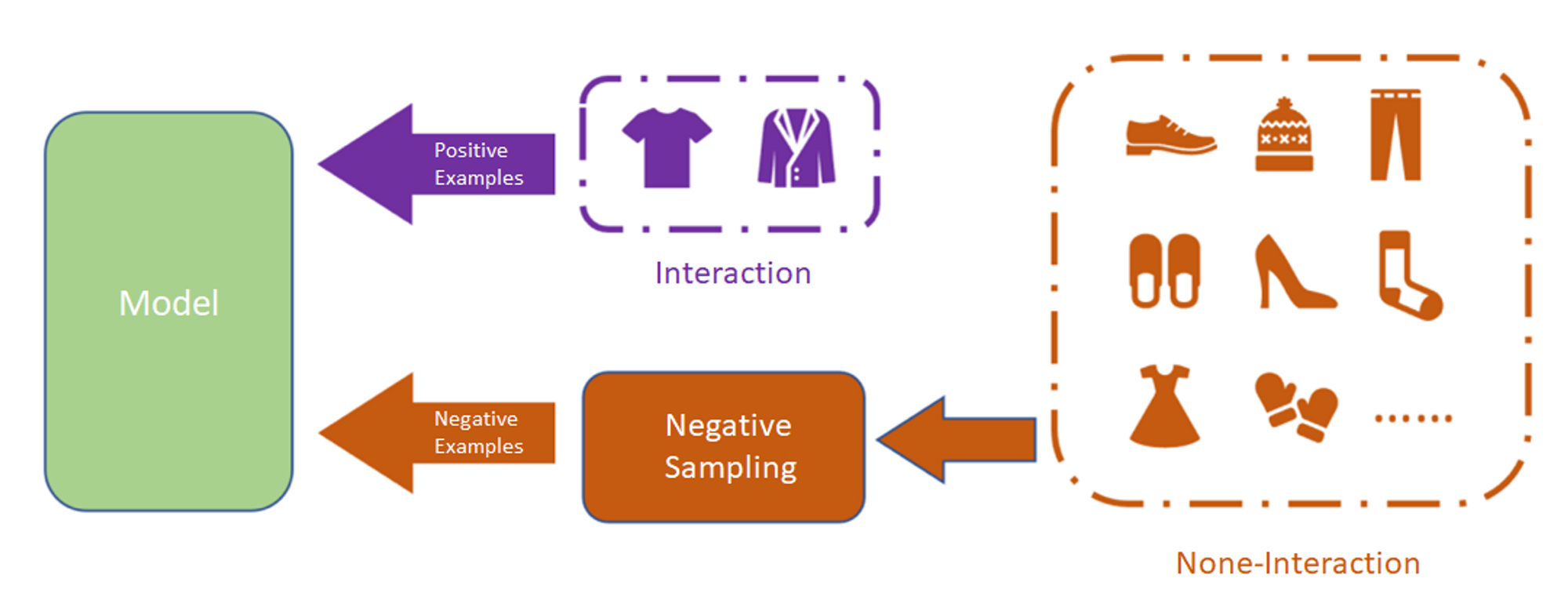
item을 negative samplig하여 subset만으로 loss를 계산
- 유저가 상호작용 하지 않은 item은 존재 자체를 몰랐거나 관심이 없는 것일 수 있음
- 아이템의 인기가 높은데 상호작용이 없다면 → 유저가 관심 없는 아이템이라고 가정
- 인기에 기반하여 negative sampling을 하여, 인기도가 높은 것을 위주로 negative sampling을 실행함
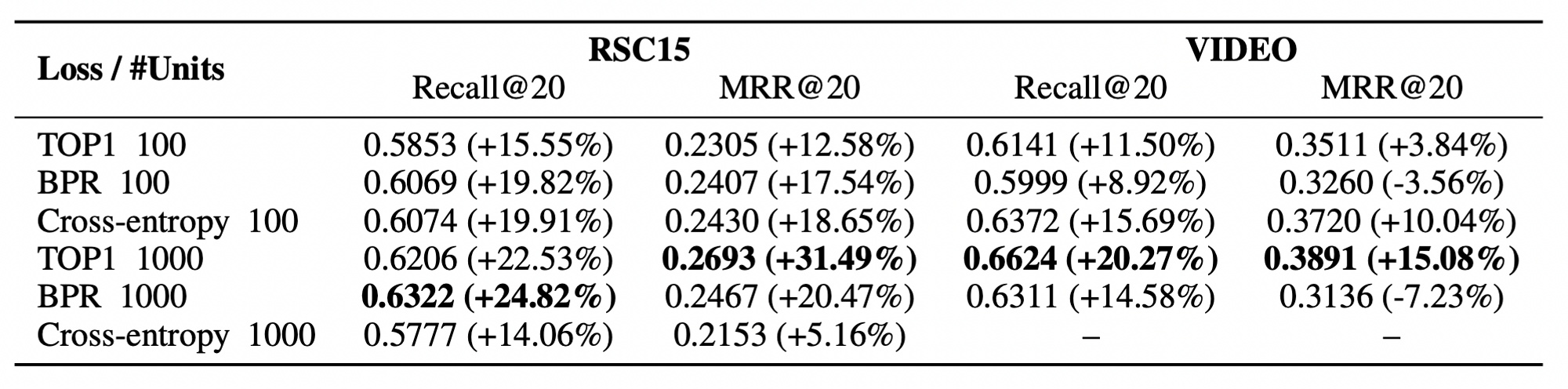
GRU 레이어의 hidden unit이 클 때 더 좋은 성능을 내는 것으로 알려져 있다.
11/30
멘토링
왜 학습이 잘 안되는가?
- epoch이 너무 작아서 학습이 제대로 안되는 것 같음 -> 더 오래 돌려보길.
- epoch을 최대한 돌려서 loss/validation 그래프 보기
- lr 한단계 더 낮게 실험해보기
- bert에 layer 더 쌓아보기
- 현재 loss 높음 -> 떨어뜨리기
회고
data augmetation을 해서 데이터를 늘려주면 학습이 좀 더 잘 될 줄 알았지만, 잘 되지 않았다. loss가 너무 높고, auc가 높아졌다 낮아졌다. 주말동안 실험해보면서 해결해보고 싶다.
GRU4Rec을 구현해보고 싶지만, baseline 없이 구현해야하는거라서 감이 잘 오지 않는다.

예전에는 블로그를 일주일에 한번씩 써서 매주 뭐 했는지 돌아보기 힘들었지만, 이렇게 노션에 기록해두니 찾아쓰기 쉬운 것 같다.
