
Intro to Encoder-Decoder LSTM(=seq2seq)
Intro to Encoder-Decoder LSTM(=seq2seq)
Encoder-Decoder LSTM(=seq2seq)
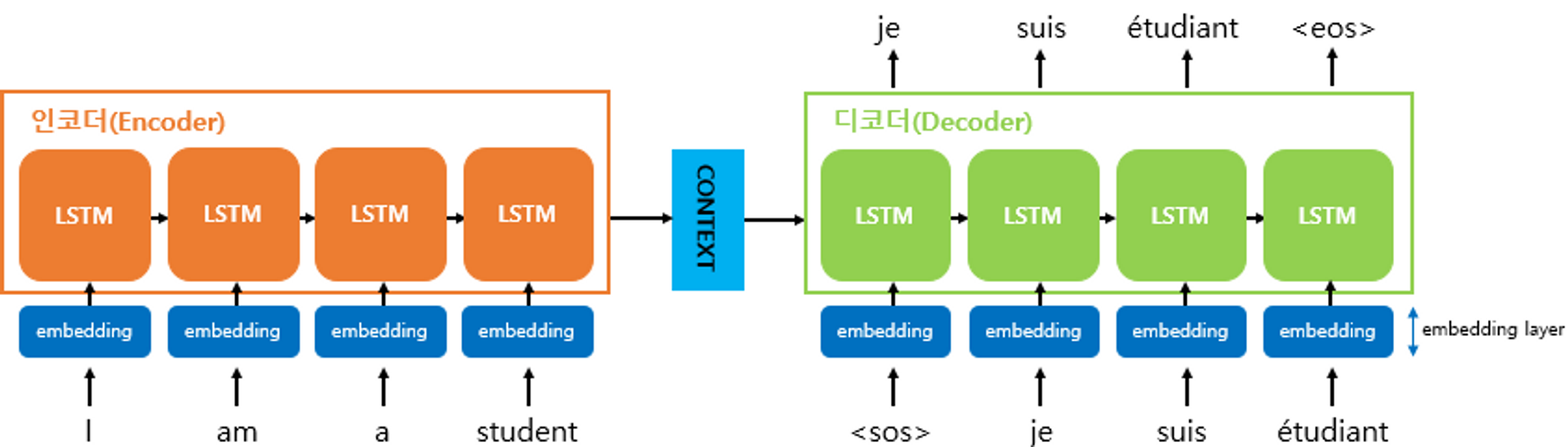
seq2seq는 input 문장의 모든 단어들을 순차적으로 입력받은 뒤 마지막에 모든 단어 정보를 압축해서 하나의 벡터로 만드는데, 이를 context vector라고 함
input 문장의 정보가 하나의 context vector로 모두 압축되면 encoder는 context vector를 decoder로 전송
decoder는 context vector를 받아서 번역된 단어를 한 개씩 순차적으로 출력
encoder에는 LSTM셀 또는 GRU셀로 구성되고 encoder RNN셀의 마지막 시점의 은닉 상태를 decoder RNN 셀로 넘겨줌. (이를 context vector라고 함) context vector는 디코더 RNN 셀의 첫번째 은닉 상태에 사용됨.

기계는 텍스트보다 숫자를 잘 처리하기때문에 seq2seq에 사용되는 모든 단어들은 임베딩 벡터로 변환 후 입력으로 사용됨. 그림에서 모든 단어에 대해서 임베딩 과정을 거치게 하는 단계인 embedding layer가 있음
- input, output 모두 sequencial data
- [ 문제 ] : input과 output의 sequence 길이가 다를 수 있다.
→ 해결
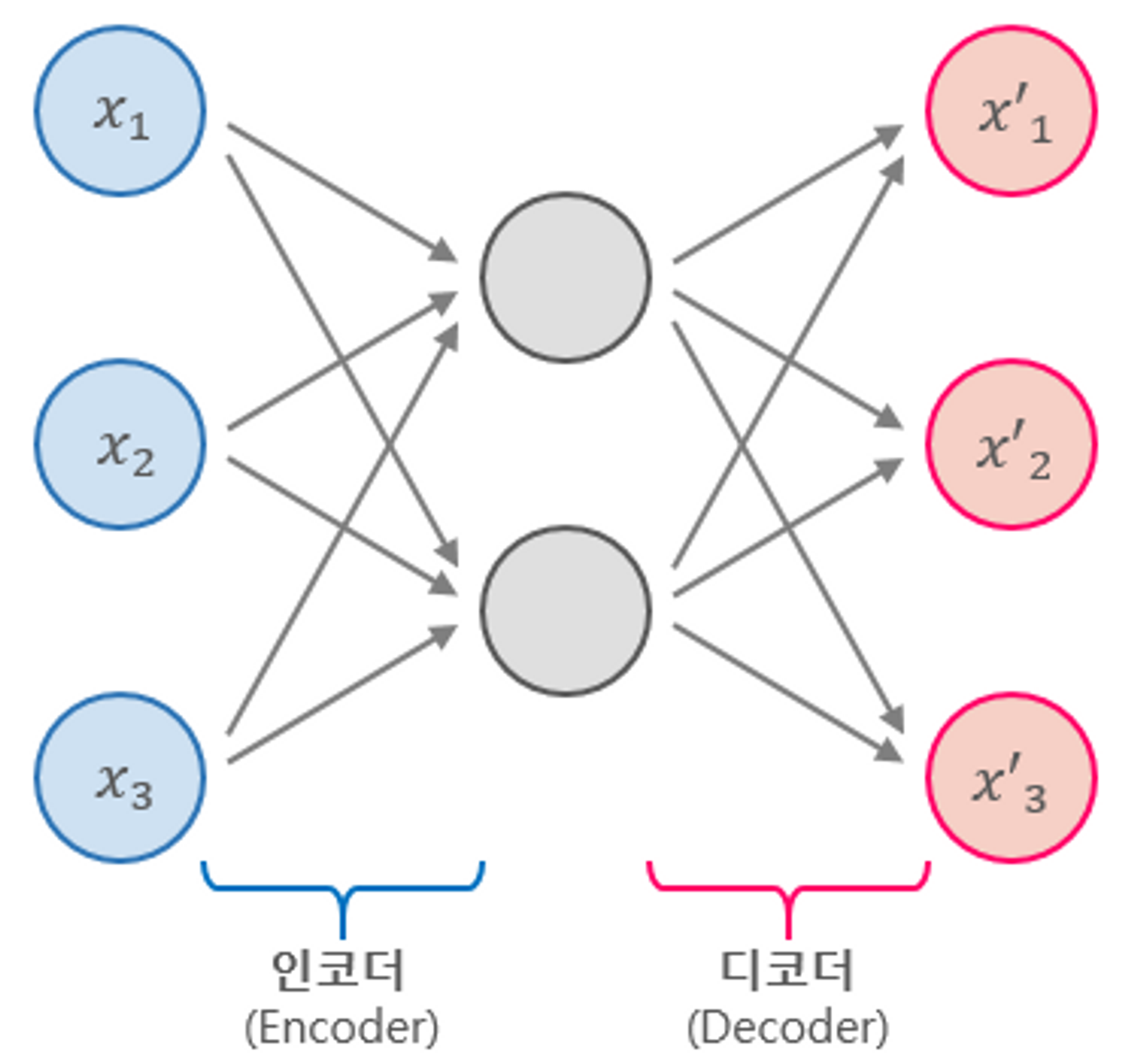
- Encoding : 여러 길이의 input을 고정 길이 벡터로 변환
- Decoding : 고정 길이 벡터를 해독하여 output 프린트
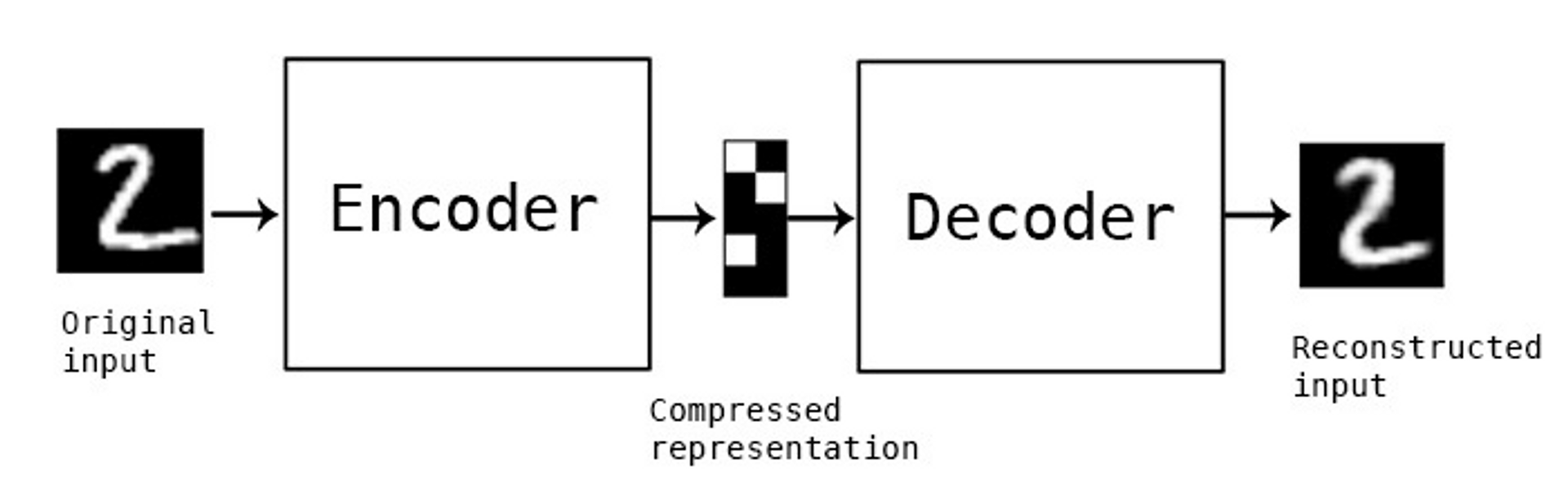
LSTM Autoencoder
- Encoder-Decoder LSTM 모델은 다양한 길이의 시계열 데이터를 받아, 다양한 길이의 시계열 출력 데이터를 만들 수 있음.
- LSTM Autoencoder는 다양한 길이의 시계열 input 데이터를 고정 길이 벡터로 압축해 Decoder에 입력으로 전달해줌
- input data를 encoded feature vector로 변환하는 과정이 있음.

- input data : 3 timestamps, 2 features (3*2)
- Layer 1, LSTM(128), return_sequences=True : 입력 32 → 출력 3128
- Layer 2, LSTM(64), return_sequences=False : 입력 3128 → 출력 164 (vector)
- Encodded features = encodded feature vector
- 이 벡터가 다시 Decoder LSTM에 전해지려면 복사해야 함
- Layer 3, RepeatVector(3) : 입력 164 → 출력 364
- Decoder layer는 Encoder layer를 거꾸로 뒤집은 순서로 쌓여있다
- 인코딩은 문자 to 임베딩이라면, 디코딩은 임베딩 to 문자이기 때문에 거꾸로 뒤집기
- Layer 4, LSTM(64), return_sequences=True : 입력 364 → 출력 364
- Layer 5, LSTM(128), return_sequences=True : 입력 364 → 출력 3128
- Layer 6, TimeDistributed(Dense(2)) : 입력 3128 → 출력 1282
- TimeDistributed layer는 직전 레이어 출력의 feature 개수(여기선 Layer 5의 출력 3128의 feature 개수이므로 128) 길이만큼의 벡터를 만든다. 따라서 길이 128의 벡터. 그런데 '2'가 인수로 주어졌으므로 이 128 길이 벡터를 2번 복제한다. 따라서 최종 출력은 1282
- Layer 5의 출력 Layer 6의 출력 = (3, 128) (128,2) = (3,2)
- 따라서 최종 출력의 크기는 3*2 (입력 데이터와 크기 같음)
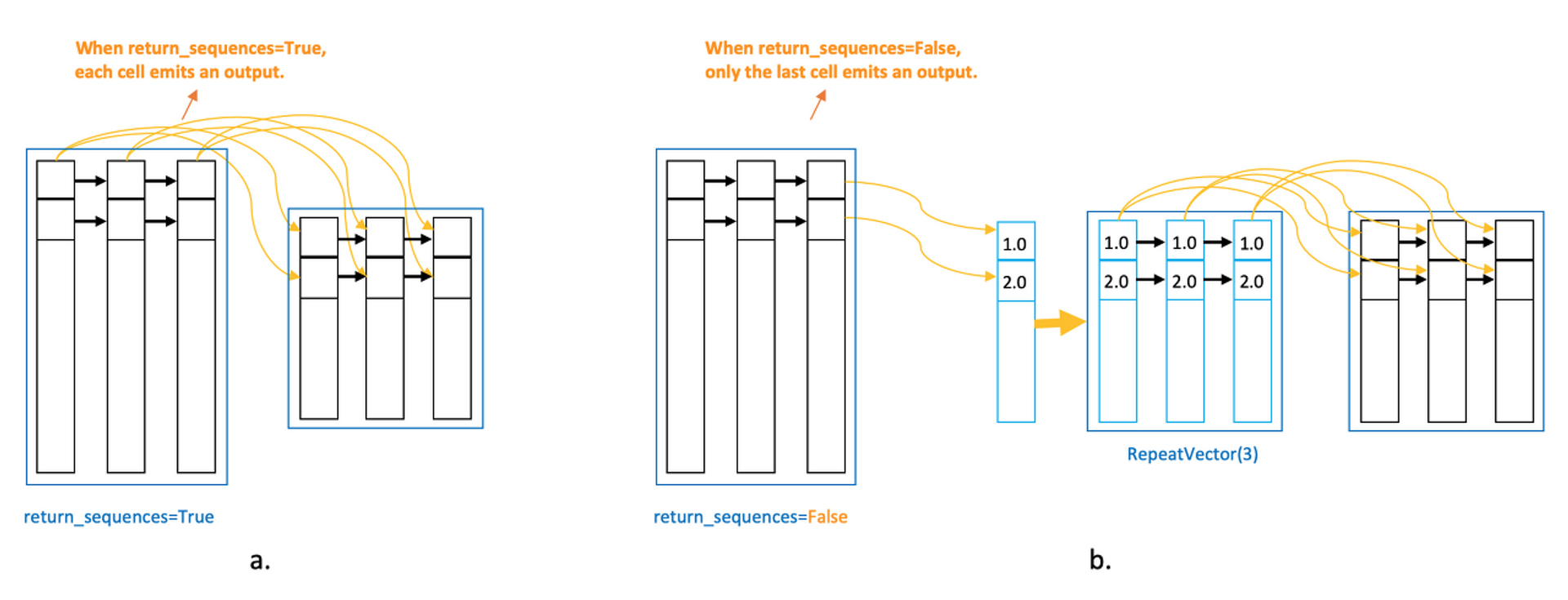
- return_sequences=True : 모든 time-stamp에서 신호를 전달함 (모든 time-stamp가 각자의 time-stamp에 전달)
- return_sequences=False : 마지막 time-stamp만 신호를 전달함
- 따라서 True이면 output 크기가 3 네모 / False이면 output 크기가 1 네모
- 전체 timestamp 개수가 3이니까, 마지막 timestamp는 1개니까
LSTM Autoencoder 와 LSTM 코드 비교
LSTM Autoencoder
2번째 LSTM 레이어의 return_sequences=False와 그에 따른 RepeatVector 레이어 추가가 유일한 차이점
# define model
model = Sequential()
model.add(LSTM(128, activation='relu', input_shape=(timesteps,n_features), return_sequences=True))
model.add(LSTM(64, activation='relu', return_sequences=False))
model.add(RepeatVector(timesteps))
model.add(LSTM(64, activation='relu', return_sequences=True))
model.add(LSTM(128, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(n_features)))
model.compile(optimizer='adam', loss='mse')
model.summary()LSTM
define model
model = Sequential()
model.add(LSTM(128, activation='relu', input_shape=(timesteps,n_features), return_sequences=True))
model.add(LSTM(64, activation='relu', return_sequences=True))
model.add(LSTM(64, activation='relu', return_sequences=True))
model.add(LSTM(128, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(n_features)))
model.compile(optimizer='adam', loss='mse')
model.summary()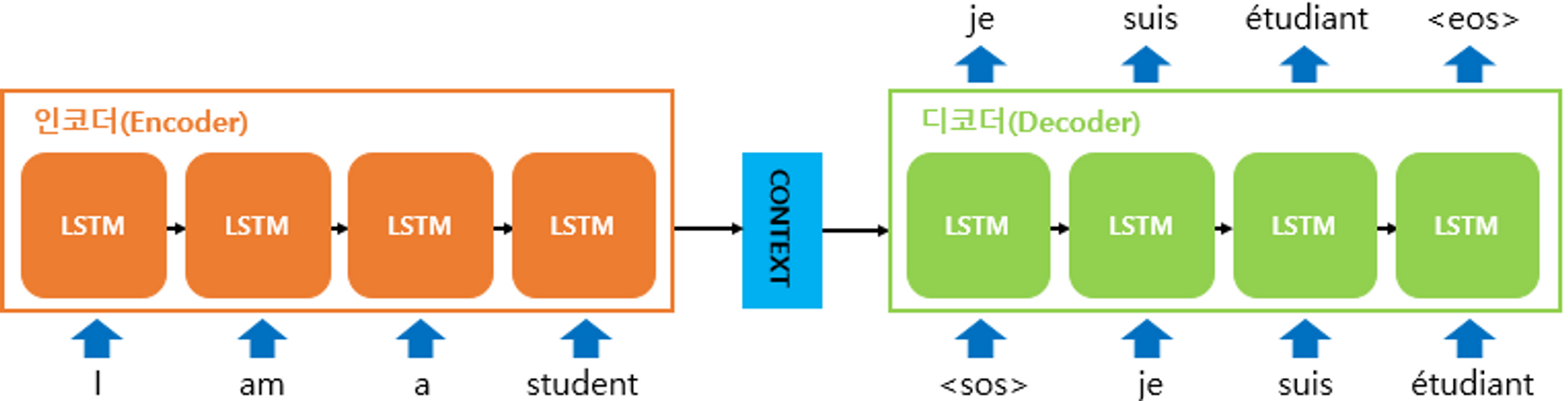
출처
feature scaling
**서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업**
표준화 (Standardization) : 데이터의 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 것.
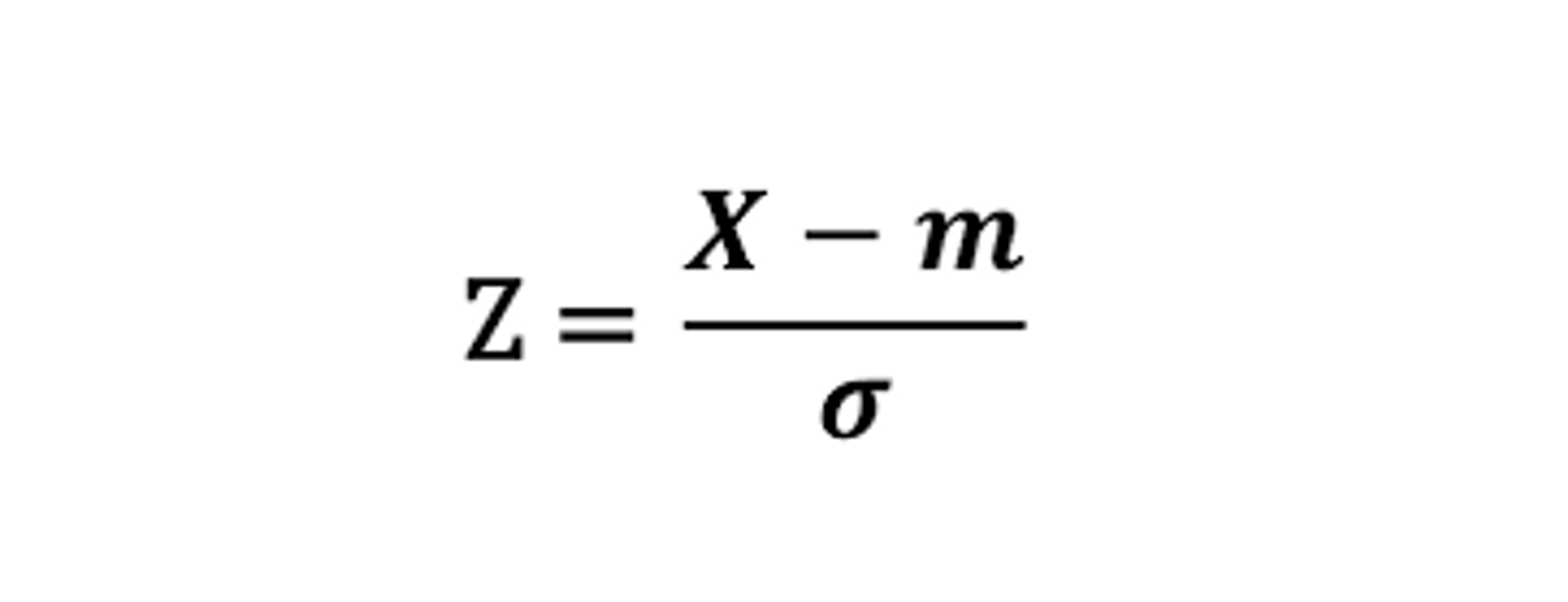
정규화 (Normalization) : 서로 다른 Feature의 크기를 통일하기 위해 크기를 변환
모두 최소 0 , 최대 1의 값으로 변환하는 것 -> 동일한 크기 단위로 변수 비교하기 위해
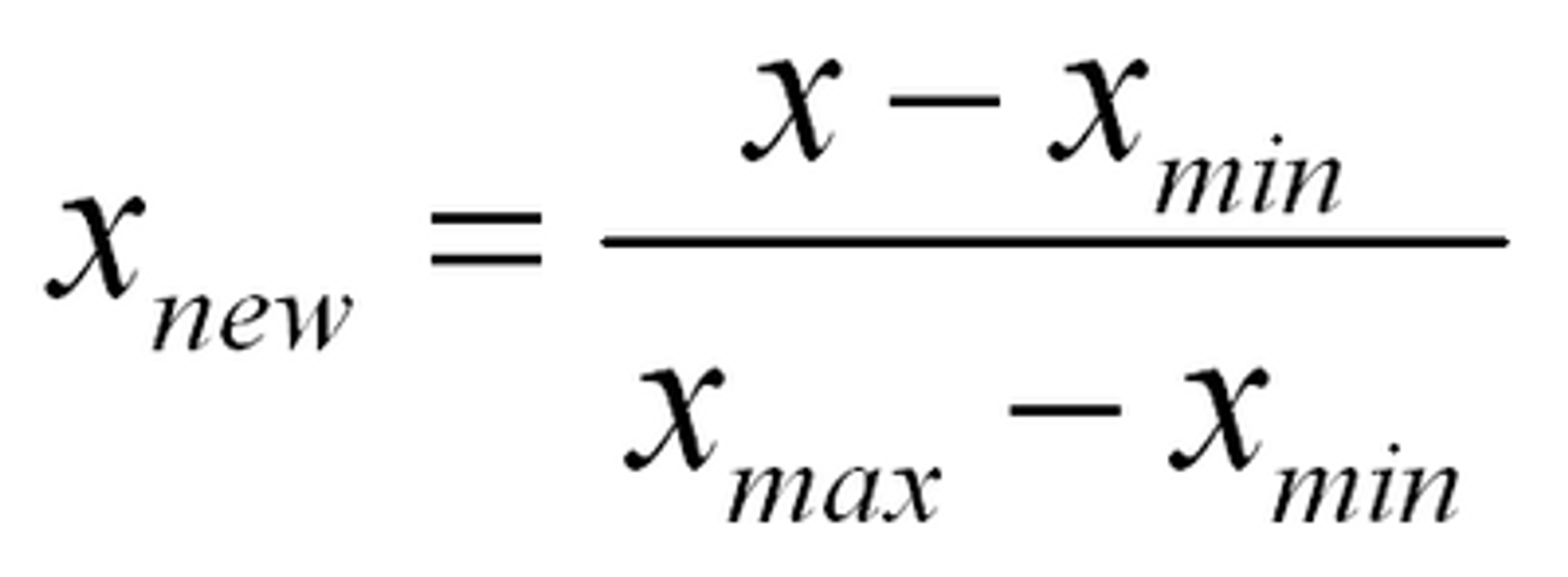
StandardScaler
: 표준화를 지원하기 위한 클래스, 평균이 0과 표준편차가 1이 되도록 변환.
모든 특성들이 같은 스케일을 가지게 된다.
MinMaxScaler
: 데이터 값을 0과 1사이의 범위 값으로 변환 (음수 존재 시, -1 ~ 1로 변환)
-> 분포가 가우시안 분포가 아닌 경우에 MinMaxScaler 사용할 수 있다.
느낀점
train_data만 scaling해주는 것이 아니라 test_data도 같이 scaling 해줘야하고 scaling을 했더니 성능이 향상된 것을 볼 수 있었다. 전에 적용되지 않았던 data augmentaion도 잘 적용되었다.
- 범주형과 연속형 데이터를 나눠준다.
- 범주형은 LabelEncodin을 해주고 연속형은 StandardScaler를 해준다.
이번주 회고
이번 대회에서 모델링에 대한 실력 부족함을 느꼈다. 그래도 저번 대회보다는 모델 이해도가 높았고, baseline을 처음부터 다 뜯어보았다가는 것에 만족하였다. 마지막에 붙잡았던 모델은 lstm + attention이었는데, boosting과 graph model에 비해 한번 돌리는데 시간이 너무 오래걸려서 지치기도 했다. (돌릴때 기본 5시간?) 다음 대회는 sequence model이 아닌 다른 모델을 보고싶기도 했고, 또 다른 생각으로는 sequence model을 한번 더 보면 더 잘할 수 있지 않을까 생각이 들기도 했다.
대회는 우리 팀원들이 너무 잘해준 탓에 버스를 탔다고 생각한다. public에서 13팀 중 13등을 마지막에 기록해 낙담하였지만, 팀원들이랑 재밌게 대회를 했고 팀원들간의 사이도 좋아서 서로 위로하고 있었는데, Private에서 4등이라는 등수를 얻을 수 있었다. Private이 공개되고 팀원들과 다들 소리지르며 기뻐했다. 이번대회에서 어떤 모델을 내어도 public 점수가 오르지 않았는데 이런 반전이 숨겨져 있을 줄 몰랐다. 결과를 보고 대회를 헛되이 하지 않았다는 마음에 뿌듯한 대회였다.

