
Matrix Factorization Revisited
- 사용자와 아이템의 저차원 표현을 학습하는 것으로 볼 수 있음
명시적인 feature를 사용하지 않고도 잠재 표현을 학습하기 때문에 latent factor model이라고도 함.
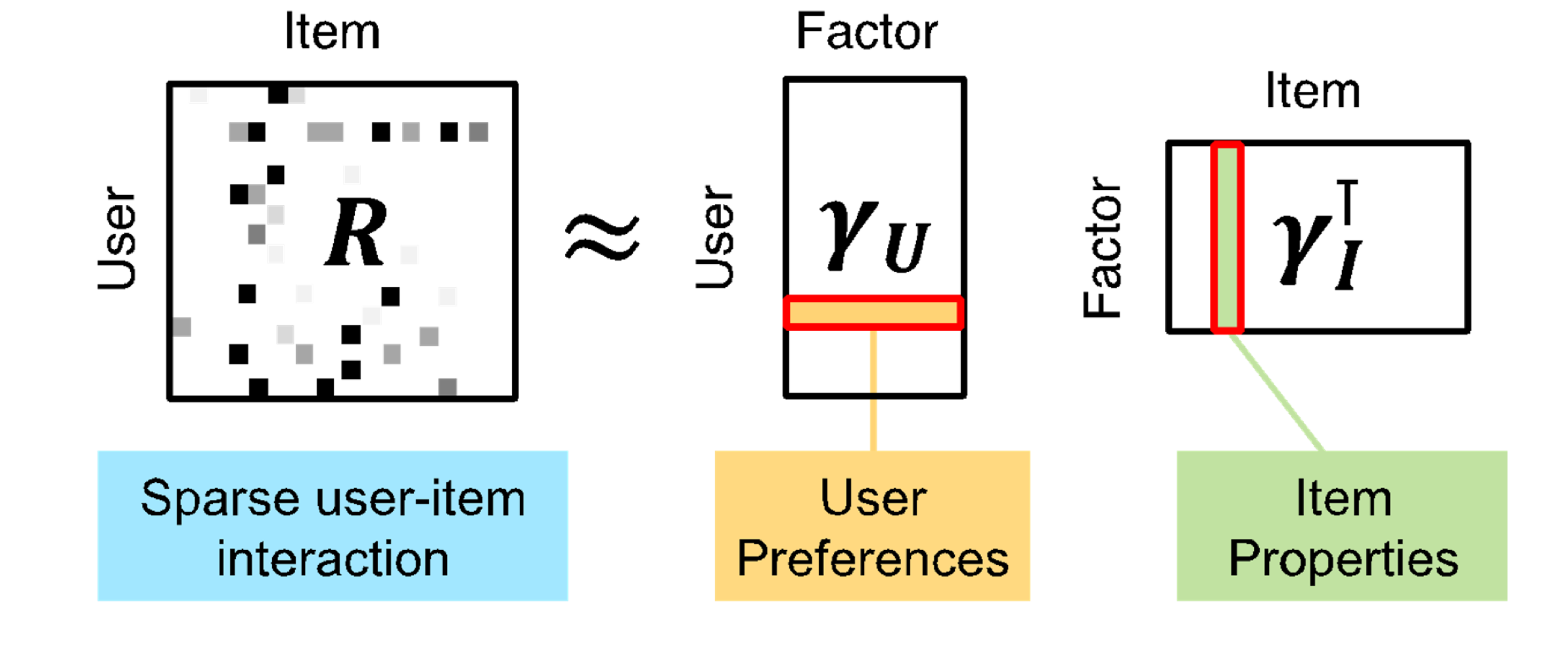
MF
- MF는 Explicit feedback (real-valued)으로 이루어진 rating으로 예측하는 데에도 쓰이지만, Implicit feedsback (binary outcome)으로 이루어진 데이터로부터 ranking을 수행하는 데에도 효과적임
- Implicit feedback을 다룰 때에는 행렬의 각 원소에 서로 다른 cofidence 값을 부여하는 Instance re-weighting scheme이 활용됨
Bayesian Personalized Ranking
- BPR은 사용자ㅡ이 선호도를 두 아이템 간의 pairwise-ranking 문제로 formulation함으로써 각 사용자 u의 personalized ranking function ()을 추청한다.
-> 기존 방법 : missing value를 0으로 처리했고 결과적으로 선호하지 않는 아이템과 사용자가 아직 접하지 않았지만 선호할만한 아이템이 0에 섞이게 되며, Regression obj.를 사용하므로 Unseen item에 negative scoring하는 케이스가 존재함 (추천 품질에 악영향)
=> positive instance (+)에는 높은 score를 주고 non-positive instance에는 낮은 score를 주고 ranking하는 형태로 변경
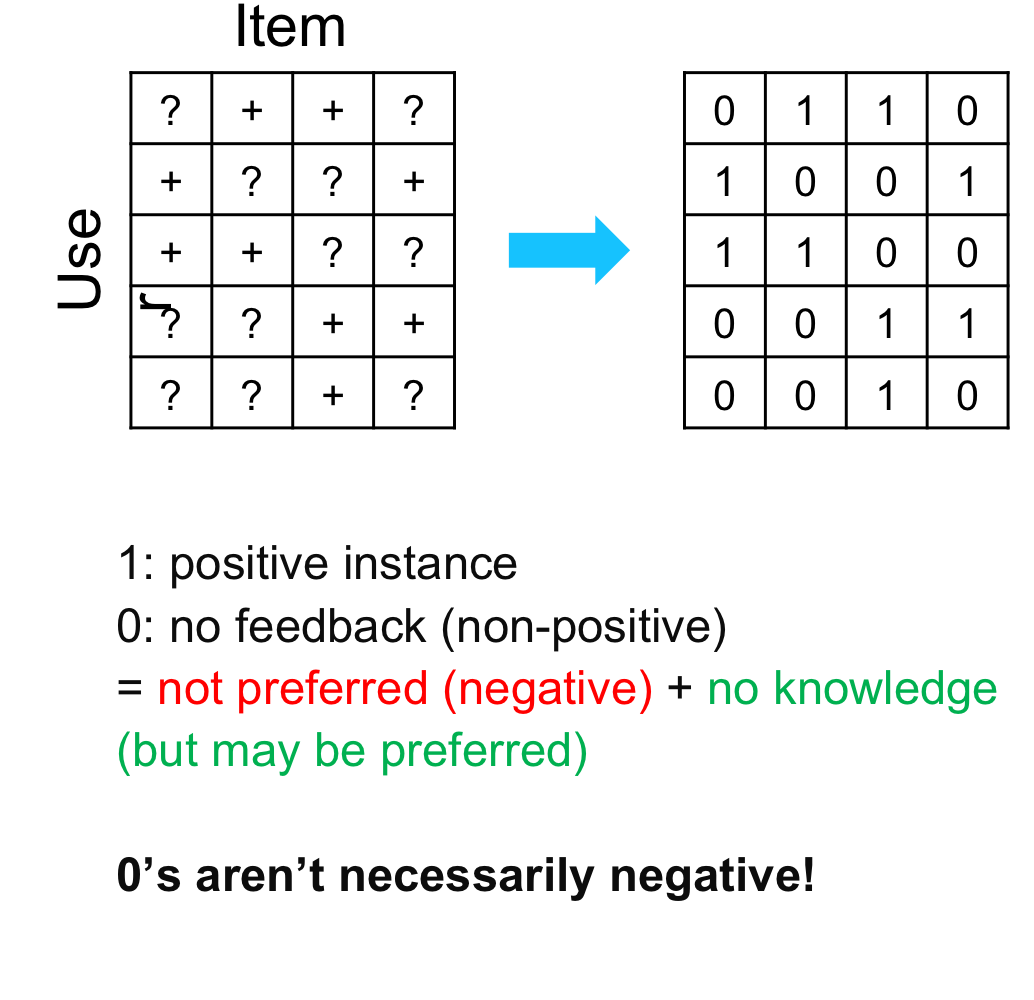
MF와 BPR 비교
MF : pointwise(one item) -> BPR : pairwise (two items) optimization
MF : MSE 를 optimize하는 regression -> BPR : classification objective
Factorizing Personalized Markov Chains
- FPMF는 MF와 Markov Chain을 결합한 모델로 사용자와 아이템 간의 관계 및 아이템과 바로 이전 아이템간의 관계를 함께 모델링함.
Markov property
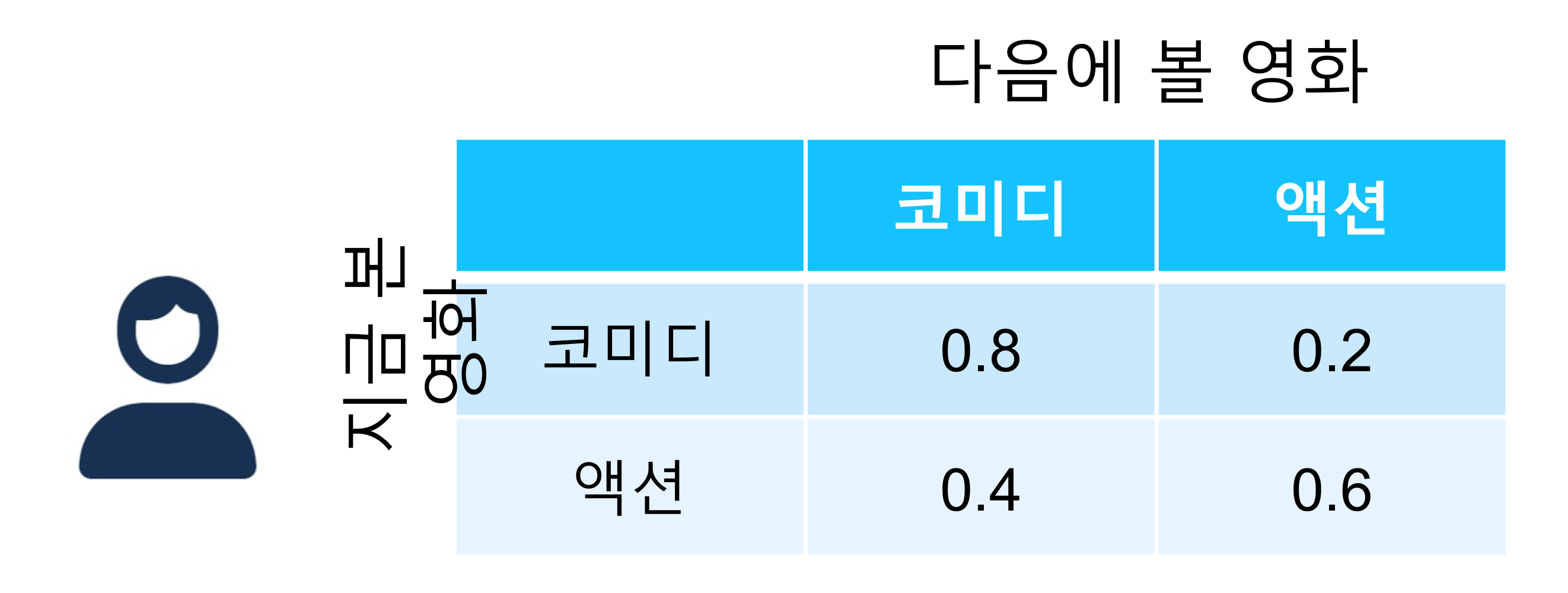
다음 스텝의 상태는 이전의 상태에만 영향을 받음
FPMC
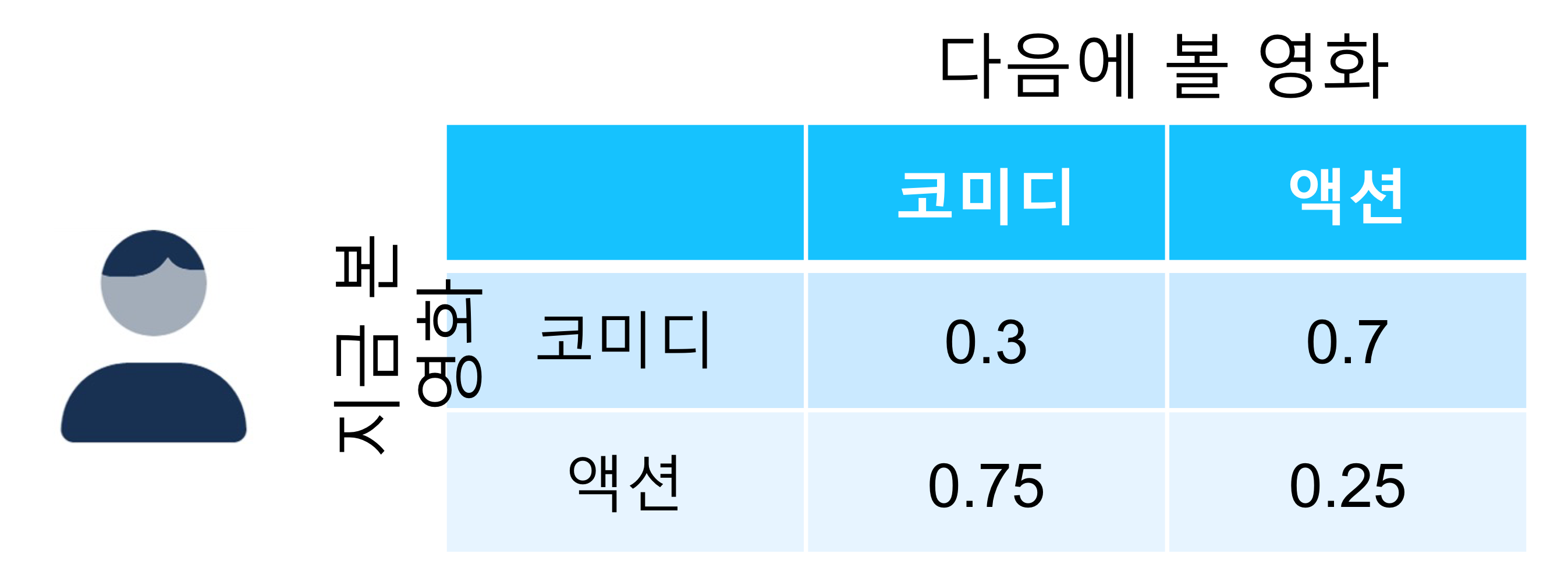
사용자 별로 개인화 된 형태의 user-specific Markov Chain을 가정함
Personalized Ranking Metric Embedding
- PRME는 compatibility function으로 inner product가 아닌 다른 distance metric(e.g., Euclidean distance)을 사용한다.
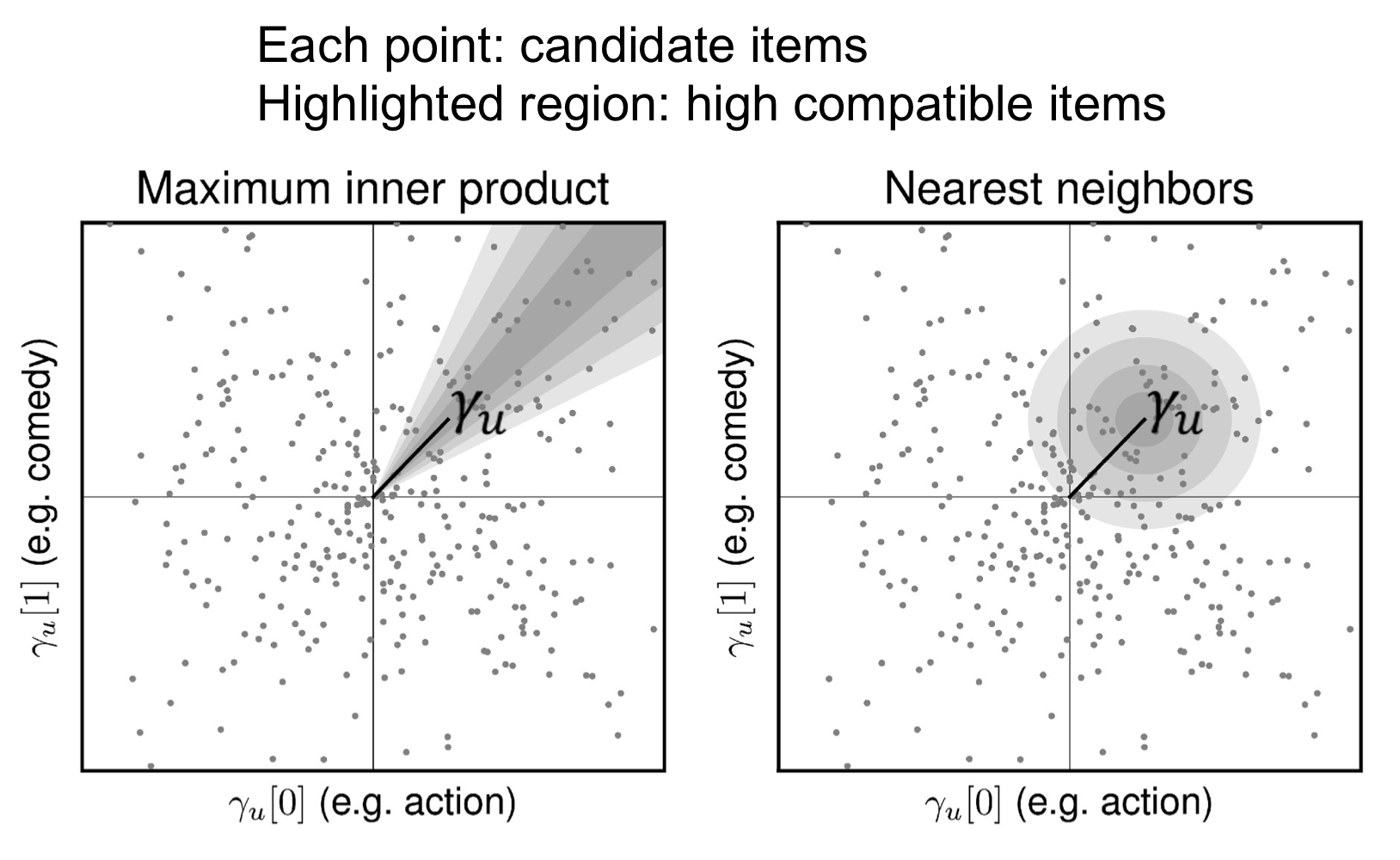
- 이러한 형태의 Metric Embedding은 Next POI Recommendation (location-aware)뿐만 아니라 Playlist prediction과 같은 음악 도메인의 테스크에도 효과적임 (인접한 유사 장르의 음악을 추천)

Evalution of Rating Prediction
- Rating Prediction 문제는 real-value로 이뤄진 explicit feedback을 예측하는 태스크에 주로 사용됨.
Explicit feedback은 영화의 별정과 같이 사용자의 선호에 대한 명시적인 정보를 제공 - Top-k Ranking 문제는 0과 1의 binnary-value로 이뤄진 implicit feedback을 예측하는 태스크에 주로 사용됨. 클릭, 구매 등의 implicit feedback은 사용자의 선호에 대해 (모호한) 암시적인 정보만 제공
사용자에 대한 compatibility score를 아이템에 대해 ranking하여 추천 결과를 생성함
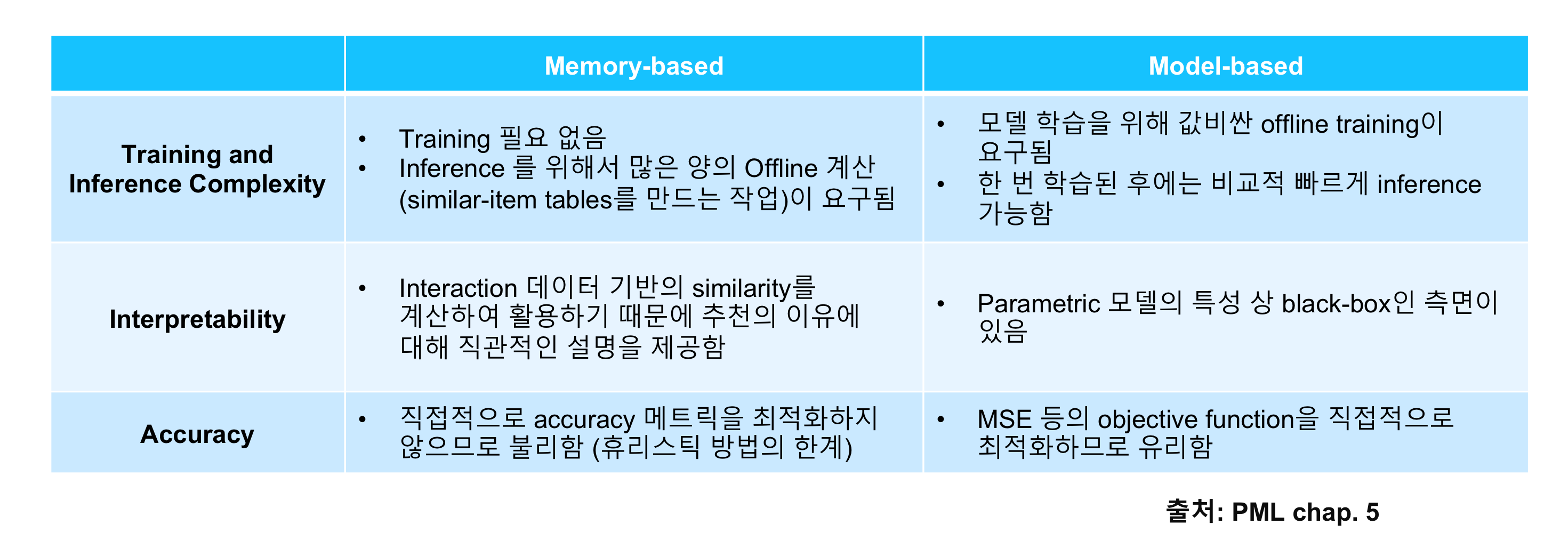
Memory-based Collaborative Filtering
Similarity Metrics
- Memory-based CF (a.k.a. neighborhood-based CF)는 사용자 또는 아이템 간의 similarity값을 계산하고 이를 rating prediction 또는 top-K ranking에 활용하는 방법. Similarity값은 계산하는 metric으로 Jaccard Similarity, Cosine Similarity, Pearson Similarity 등이 활용됨.
- Memory-based CF의 Rating Prediction은 다음과 같은 간단한 휴리스틱 룰에 의해 이루어진다.
- Idea : 사용자가 아이템에 부여할 평점은 다른 유사한 사용자가 부여한 또는 유사한 아이템에 부여된 평점을 기반으로 추정할 수 있을 것이다. 이때 유사한 사용자 또는 아이템일수록 더 높은 중요도를 가짐.
Model-based Collaborative Filtering
Latent Factor Models
-
사용자와 아이템의 저차원 표현을 학습하는 것으로 볼 수 있음. 명시적인 feature를 사용하지 않고도 잠재적인 의미를 갖는 representations을 학습하기 때문에 latent factor model이라고 함.
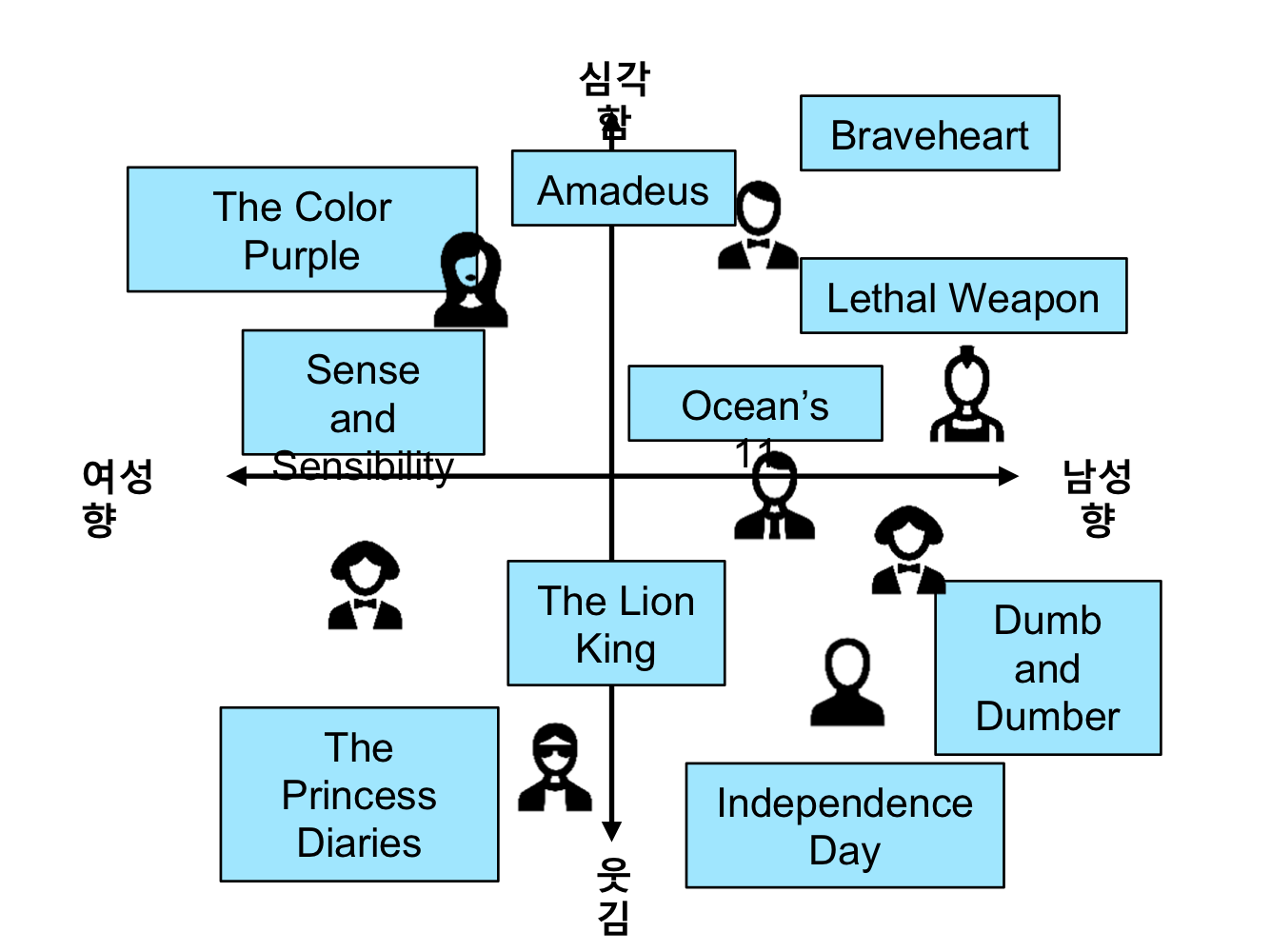
학습된 User Latent Factor, Item Latent Factor를 같은 공간에 도식화 할 경우 오른쪽 그림과 같이 잠재적인 의미를 갖는 형태로 분포되는 것을 알 수 있음. 영화의 장르 정보 (e.g., 여성향, 남성향,웃김, 심각함)를 제공하지 않더라도, 상호작용의 패턴을 통해서 이러한 잠재 정보를 발견할 수 있음.
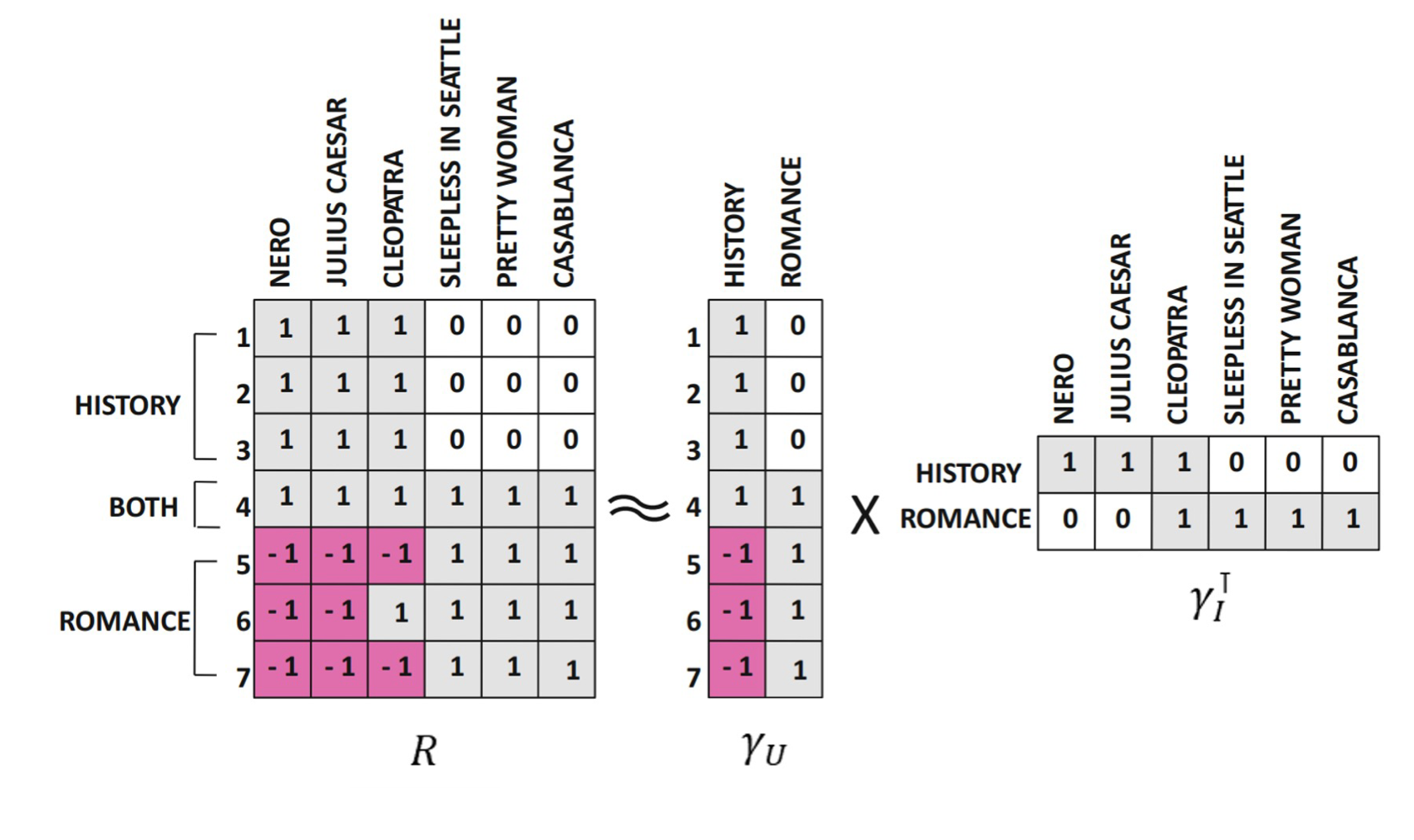
-
Latent Facotr Model로서 MF는 추천 시스템에만 적용할 수 있는 것이 아니라, dimension reduction 테크닉으로서 다양한 데이터 타입에 적용 가능함 : 이미지 -> 특징 추출, 문서 -> 토픽 추출
Implicit Feedback for Recommendation
- Implicit feedback (view, click, listen, purchase, etc.)은 Explicit feedback (positive or negative, 5-star ratings, etc.)과 달리 사용자의 선호에 대한 암시적인 정보만을 제공하지만, 그것의 수집 효율성 및 generalizability 덕분에 사용자의 실제 선호를 추정하는 데에 더욱 효육적일 수 있음.
최근 대부분의 추첮 연구도 rating prediction (with explicit feedback)보다는 top-K recommendation (ranking; with implicit feedback)문제를 주로 다루고 있음.
-> why? 보다 풍부한 데이터, 추천 테스크와의 적합성, 비즈니스 목표와의 직접적인 연관성
In-depth Discussion of Collaborative Filtering
CF에서 cold-start problem이 존재하는 이유?
- 새로운 행이나 열이 추가되는 상황에 해당함. 추가된 행이나 열은 기존의 학습된 모델에서 사용하던 feature에 대응하지 않으므로

끄적끄적