
오늘 공부한 내용
< VGGNet >
-
3X3 convolution filters (stride 1)만 사용
-
1X1 convolution을 fully connected layer로 사용
-
Dropout (p=0.5)
-
왜 3X3 convolution을 사용할까?
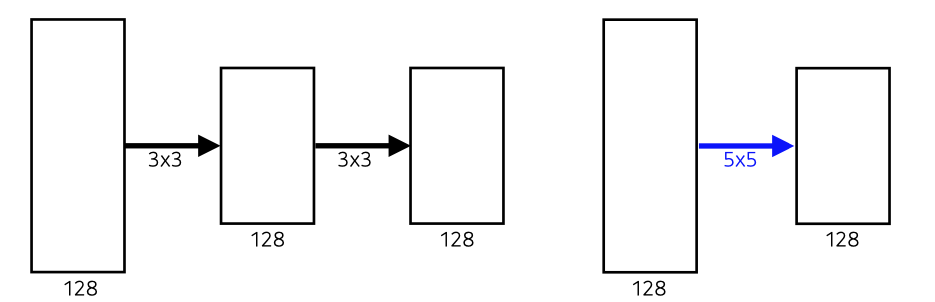
-
3X3을 2번 사용한 경우 : 3X3X128X128X2 = 18X128X128
-
5X5를 1번 사용한 경우 : 5X5X128X128 = 25X128X128
3X3을 2번 쓴 것과 5X5를 1번 쓴 것이 사이즈가 같기 때문에 파라미터수가 적은 3X3 filter를 2번 쓰는 것이 좋음.
< Optimizer >
Adam
- Momentum 최적화 + RMSProp
- 진행하던 속도에 관성을 주고, 최근 경로의 곡면의 변화량에 따른 적응적 학습률을 갖은 알고리즘.
Momentum :
EMA of gradient squares :
Momentum
- 이전 atach에서의 정보를 활용
- idea : g라는 gradient가 현재 들어왔다면 t+1번째에는 gradient 정보를 버려버리고 그 때 나온 만 사용하는 것이 아니라 a라고 불리오는 momentum에 해당하는 term이 그 값을 계속 들고 있는 것.
RMSProp
- 전체가 아닌 최근 반복에서 비롯된 gradient만 누적하여 문제해결
( : stepsize)
< Transformer >
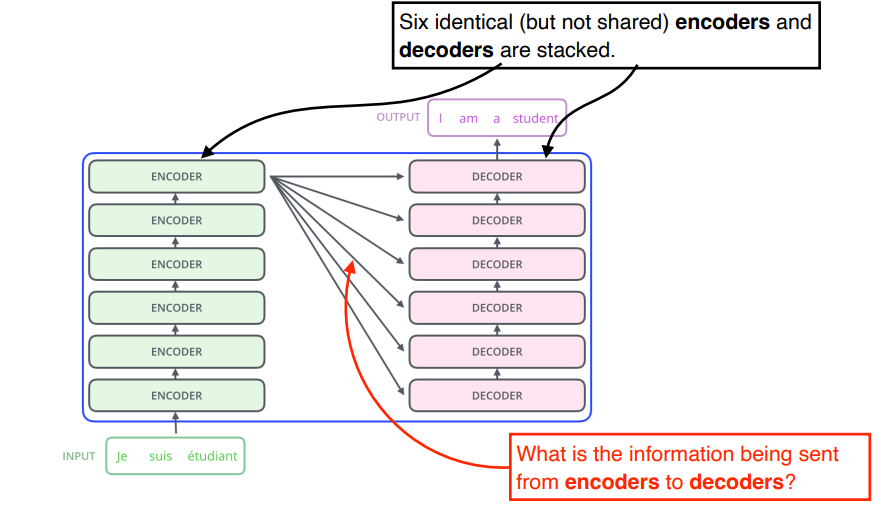
- RNN의 구조 : 하나의 입력이 들어가고 다른 입력이 들어가고 이때, 이전 Recurrent Neuron Network에서 가지고 있던 cell state가 다시 다음번으로 들어가고.. 재귀적으로 반복
- Transformer 구조 : 이런 재귀적인 구조가 없고, n개의 단어가 들어와도 한 번의 attention으로 모두 embdding됨.
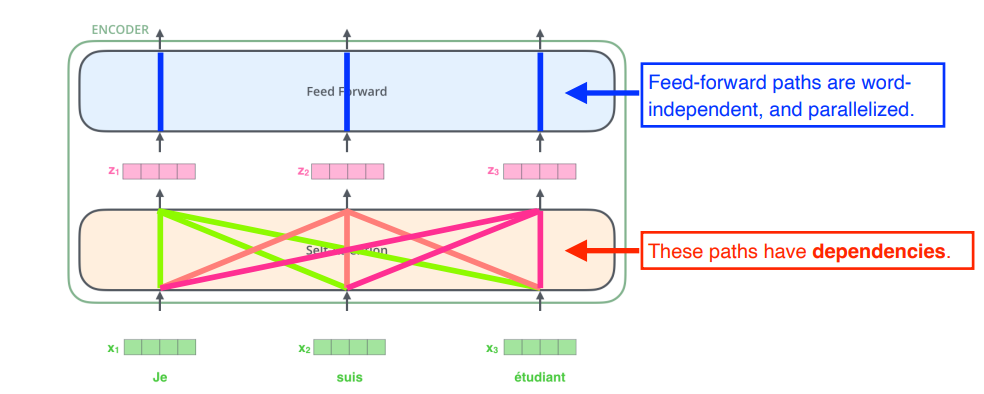
N개의 단어가 주어지고, N개의 z vector를 로 바꿀 때, 나머지 N-1개 vector를 같이 고려하는 것이 self-Attention의 가장 큰 특징
=> N개의 단어를 만들때 나머지 N-1개의 정보를 활용
(로 넘어갈 때 단순히 의 정보만 활용하는 것이 아니라 정보도 같이 활용
Self-Attention의 구조
- Query, Key, Value
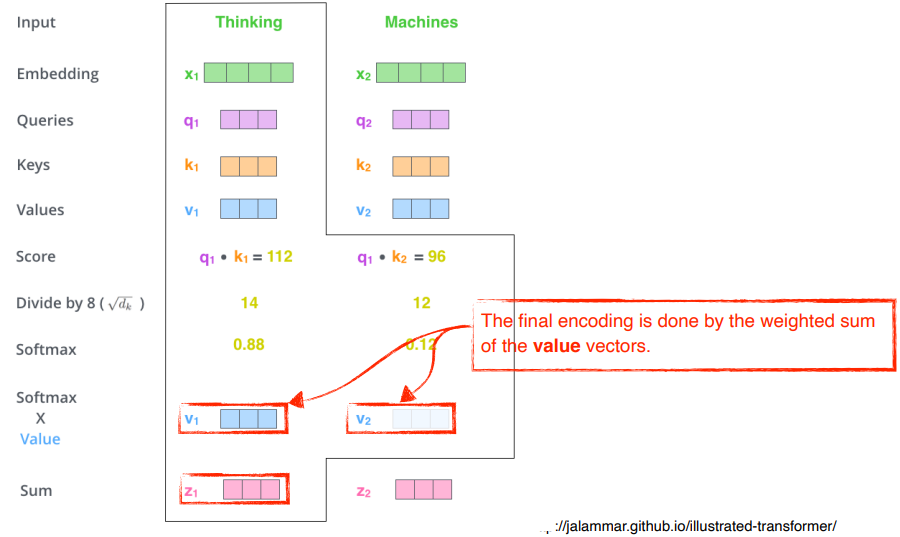
1. 단어 의 query vector 와 나머지 단어들의 key vector 를 내적
- Thinking에 대한 encoding을 하고자하는 query vector와 나머지 모든 N개의 단어에 대한 Key vector를 구하고 내적해줌
=> 번째 단어가 나머지 N개의 단어와 얼마나 관계가 있는지 확인
- 계산된 score vector를 dimension()으로 나눠줌
- 값이 너무 커지게 하는 것을 방지 (예시에서는 dimension이 64였고, 8로 나눠줌)
- Attention weights(interaction에 대한 값)을 구하기 위해 softmax 연산을 해줌
- 확률값으로 바꿔줌
- 예시에서는 Thinking은 자기 자신과 0.88의 interaction을 가지고, Machines과는 0.12를 가짐.
- Attention weightsw와 각각의 value vector와 weighted sum을 해줌
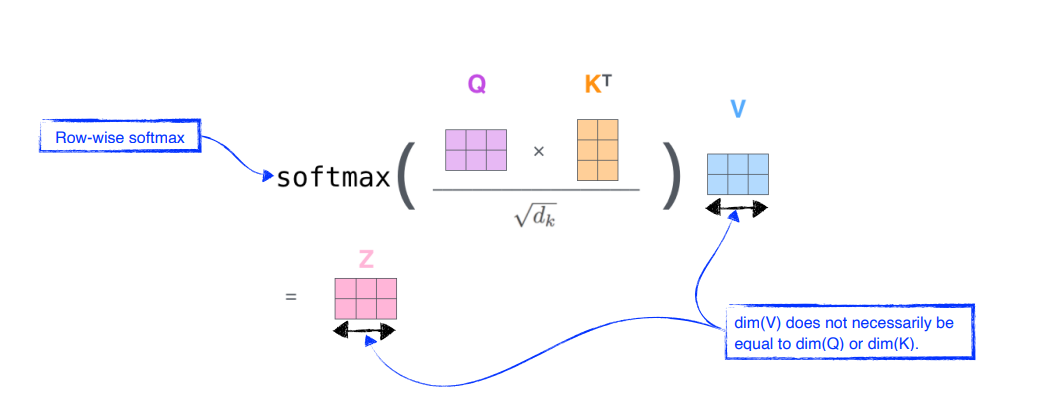
Query vector과 Key vector의 차원은 같아야함Value vector는 달라도 됨Value vector는 weighted sum을 하기만 하면 됨최종적으로 encoding된 차원은 Value vector과 동일해야함
궁금했던 내용 🧐
- [DL Basic 5강] Convolution에서 2x2 커널이 안쓰이는 이유가 궁금합니다.
홀수 커널을 사용하는 이유는, 그 전 이미지 레이어 픽셀의 정보를 symmetrical (대칭적)으로 뽑을 수 있기 때문입니다. 아래의 이미지처럼 홀수 커널은 중간의 output pixel 주위의 픽셀들을 elementwise multiplication과 sum을 통해 symmetrical하게 뽑아 주변의 픽셀 정보를 그 다음 레이어로 보내줍니다.
하지만 짝수의 경우에는 이렇게 주위에 있는 픽셀들을 대칭적으로 뽑을 수 없게 되죠. 그렇기 때문에 정보손실이 일어나 잘 사용하지 않습니다. (그렇다고 짝수를 사용하지 않느냐? 그건 또 아니라고 합니다. 결과를 보고 판단)
학습 회고 💁
- Transformer 퀴즈에서 어려움을 겪음😥
- 매번 지키지 못하는 주간학습정리 (바로바로 작성하자...!)
해야할 일
- d21 내가 맡은 부분 읽기
- 곧 다가올 Level2 팀 결성을 위해 하고싶은 프로젝트 생각해보기
