
💻팀네이버 컨퍼런스
DAN 23은 팀네이버의 기술 비전과 비즈니스 계획을 사용자, 파트너와 함께 공유하는 행사다. 컨퍼런스 이름인 ‘단’은 플랫폼의 한국어 표현으로서, 플랫폼 역할에 대한 끊임없는 재해석과 비전을 시대에 올려놓고 공유하는 컨퍼런스 플랫폼이라는 의미를 담고 있다.
팀네이버 컨퍼런스 DAN 23에서는 네이버의 생성형AI,
HyperClova X가 최초로 공개되며 검색, 쇼핑 등 일상의 경쟁력을 높여줄 수 있는 다양한 기술 등을 소개했다.
이번에 들어볼 세션은 'CUE : 생성형 AI 기반 차세대 검색 서비스' 이다. 지난번에는 '초개인화 경험으로 연결된 생성형 AI 기반 광고' 라는 세션을 들었는데, 그때 CUE를 활용한 시연을 보며 CUE에 대해 궁금증이 커졌다. 그래서 이번 스터디에서는 CUE에 대해서 알아보고자 한다. 지난 세션과는 또 다른 인사이트를 얻을 수 있기를 기대한다.
CUE:, 생성형 AI 기반 차세대 검색 서비스
생성형 AI 기반 네이버 통합 검색 및 서비스의 변화

이번 세션에서는 검색에 특화된 생성형 AI 서비스인 CUE:에 대해 소개한다. CUE:를 통해 제공되는 새로운 검색 경험에 대해 이야기하고, 핵심 기술인 Multi-step-reasoning과 신뢰성 있는 답변 생성을 위해 개발된 기술들을 소개한다.
신뢰성 있는 답변이 참 중요한 문제라고 생각하는데, 신뢰성을 위해 어떤 기술들이 사용되었는지 너무 궁금해진다!!(●'◡'●)
이번 세션은 네이버에서 생성형 AI 기술 기반 검색 서비스인 CUE:를 총괄해서 개발하시는 김용범 Search US AI 기술 총괄님과 2021년부터 AI 검색 AiRSearch 리더로서 스마트 블록 등 새로운 네이버 검색을 위한 개발 업무를 총괄하고 계시는 최재호 책임 리더님께서 맡아주셨다.
CUE가 답변을 생성하는 핵심 과정
Reasoning(추론) ➡️ Searching(검색) ➡️ Cheaking Factual Consistency(사실적 일관성의 확인) ➡️ Generating(답변 생성)
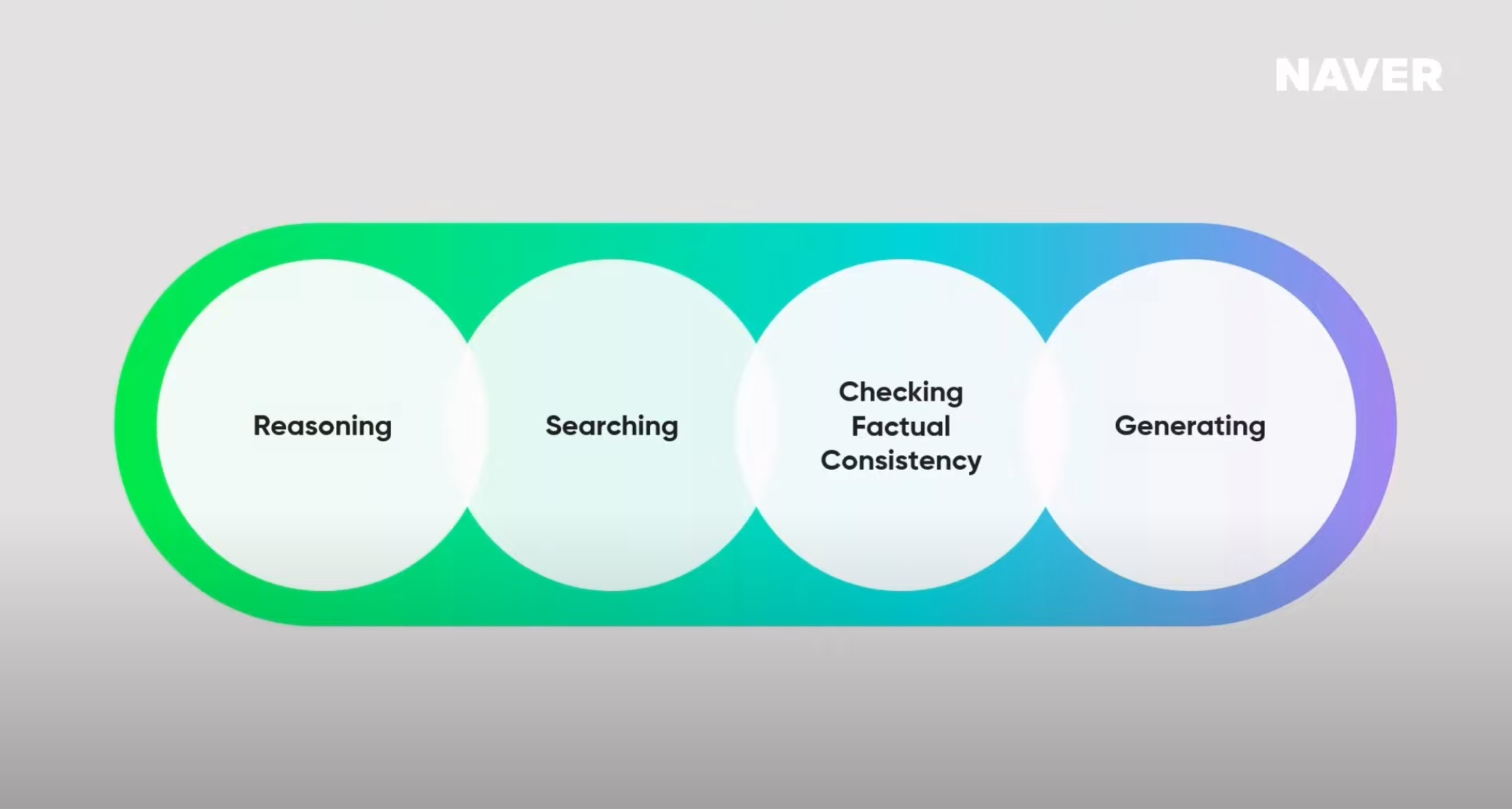

여기서 가장 중요한 과정은 바로 '검색'이다. 이것은 CUE:가 기존의 LLM과 달리, 학습 데이터에 의존한 것이 아니라 검색 결과에 그라운딩되어 답변을 생성하는 것을 의미한다. 그래서 네이버에서는 CUE:를 검색 목적 달성을 돕는 advisor라고 정의한다.
CUE의 3가지 특장점

사실 이번 네이버 컨퍼런스 DAN 23은 생성형AI 관련 세션이 많다. 디자인을 다루는 컨퍼런스는 아니다. 그렇지만 디자이너가 되고 싶다고 디자인 컨퍼런스만 들어야 하는 것도 아니라고 생각한다. 왜냐하면 위의 이미지에서 보다시피 장표 내의 디자인적인 요소들을 보며 많이 배울 수 있기 때문이다. 위의 장표도 보면 각각 다른 느낌으로 표현해서 시각적으로 아름답게 보여진다. 그리고 색상의 조합도 좋다고 생각한다. 그냥 검정색 배경이나 원에 키워드를 넣어서 표현하는걸 많이 봐왔는데 배경에 저런 효과를 주니 색달라보였다.
1. Human-like Searching : CUE 는 질문에 대한 답을 생성할 때 사람처럼 판단하고 검색한다.

CUE:는 질문에 대한 답을 생성할 때 사람처럼 판단하고 검색한다. CUE:가 어떻게 사람처럼 판단하고 답변하는지 이해를 돕기 위해 조금 복잡한 질문을 해보았다. 원룸에서 키우기 좋은 식물로 공기 정화 식물을 추론했고, 공기 정화 식물 3가지를 추천하며 관리법도 같이 알려주고 있다. 이렇게 답을 생성하려면 여러 단계의 검색과 추론이 함께 필요하다.

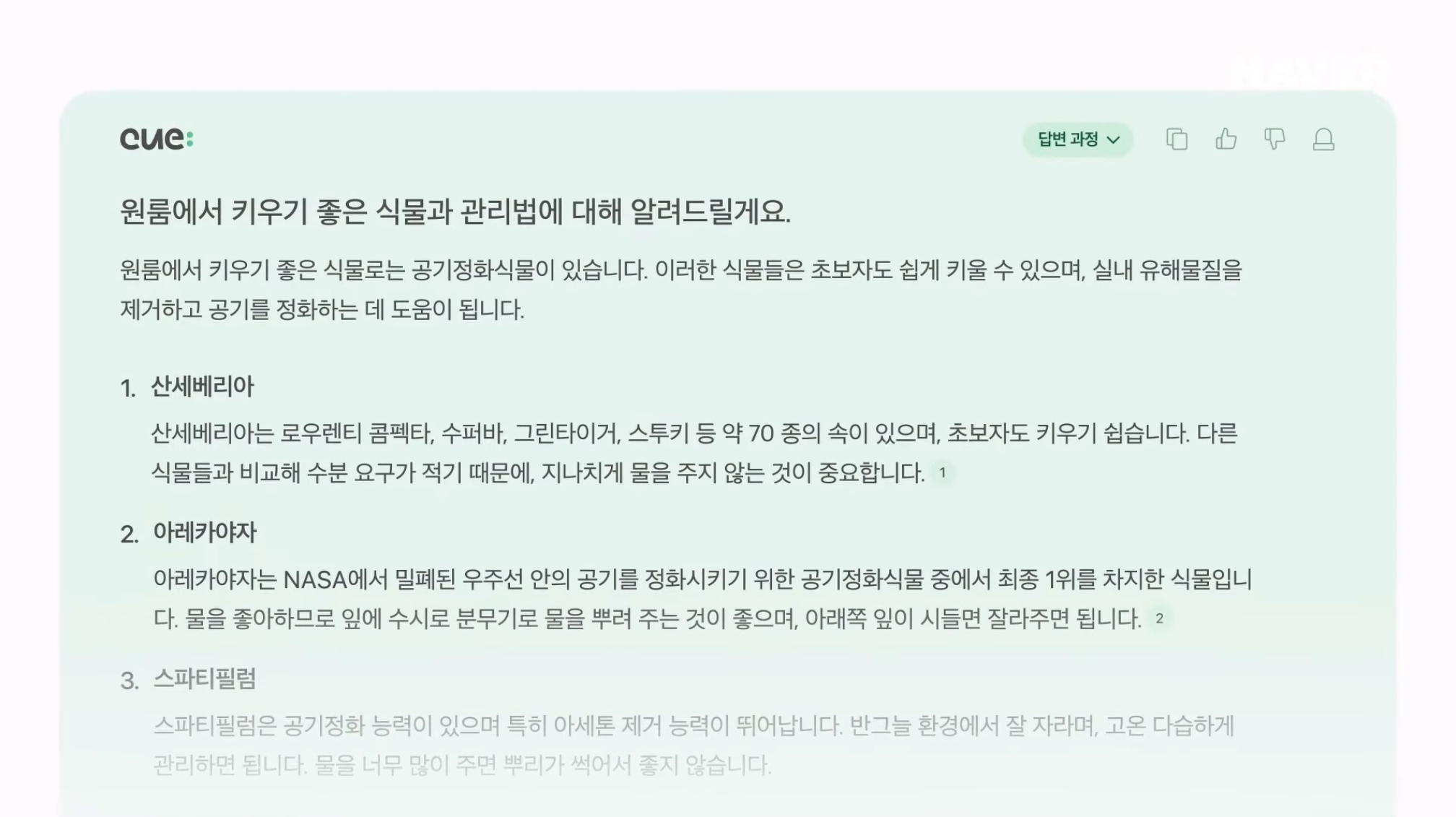
CUE:는 이러한 복잡한 질문에 답을 할 수 있도록 먼저 reasoning을 하고, 여러 단계의 검색을 스스로 계획한다.
먼저 질문 배경을 이해하여 공기정화 식물이 원룸에서 키우기 좋은 식물이라는 것을 추론한다. 이후 어떤 정보가 추가적으로 필요한지 파악하고 검색에 필요한 계획을 수립한다.
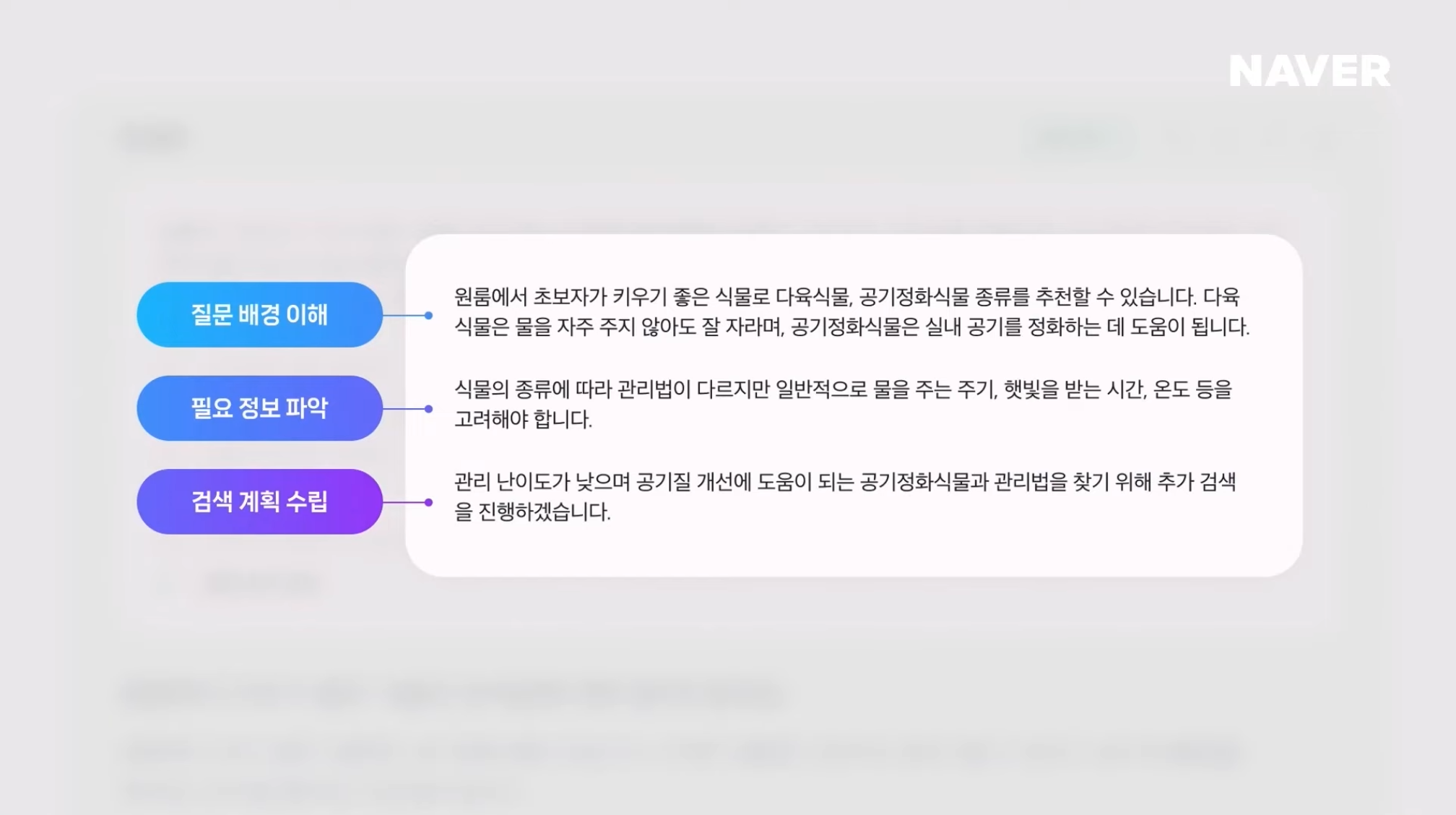
이렇게 추론된 결과를 바탕으로 공기정화 식물, 공기정화 식물 키우는 법, 원룸 반려식물 이라는 검색 계획을 세우고 답변에 필요한 문서를 먼저 확보한다. 이처럼 사람이 복잡한 질문에 답을 찾기위해 질문을 이해하고, 검색어를 결정해서 관련 문서를 찾고 답을 찾는 행동들을 CUE가 사람처럼 할 수 있다.

2. 검색 결과를 기반으로 답변하기 때문에 신뢰도가 아주 높다.

생성AI 모델은 어떤 질문이라도 답변을 생성하기 때문에 Hallucination(환각)이 발생할 수 있다. 하지만 CUE에서는 크게 3가지 기술을 이용해 Hallucination(환각)을 최소화하고 신뢰성 있는 답변을 생성한다.
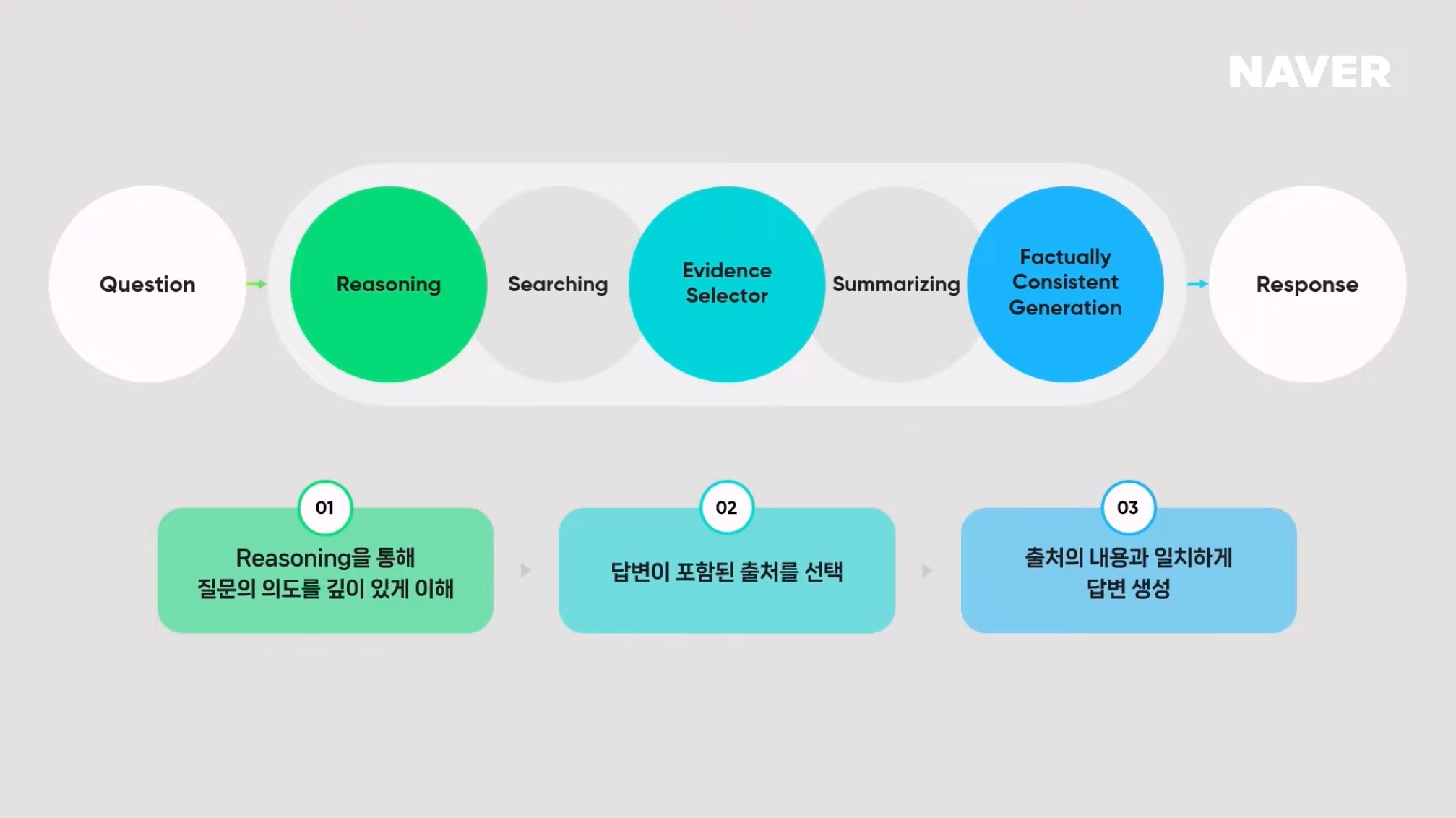
1) Reasoning : 정답이 포함된 검색 결과를 가져오기
Reasoning을 통해 질문의 의도를 깊이 있게 이해한다. 팀네이버는 모든 질문에 대한 대답은 네이버 검색 속에 있다고 믿고 있다. 때문에 올바른 답변을 하기 위해서는 정답이 포함된 검색 결과를 가져오는 것이 가장 중요하다.
2) Evidence Selector : 답변에 필요한 출처만 사용
하지만 검색된 결과에는 정답 뿐만 아니라 답변에 필요한 정보도 많이 포함되어 있다. 따라서 CUE:는 selector를 이용해서 답변에 필요한 꼭 필요한 출처만을 사용한다.
3) Factually Consistent Generation
Factually Consistent Generation 과정을 통해 다시 한번 Hallucination(환각)을 최소화한다.
Hallucination 이란 ?
위에서 Hallucination(환각)이라는 단어가 자주 등장했는데, 무엇인지 자세하게 알고싶어 서칭을 해보았다.
생성AI 모델에서 말하는 "hallucination"은 AI가 실제로 존재하지 않거나 정확하지 않은 정보를 생성하는 현상을 의미한다. 이는 마치 사람이 환각을 경험하는 것처럼, AI도 잘못된 정보를 "환각"하여 답변에 포함시키는 것과 유사하다.
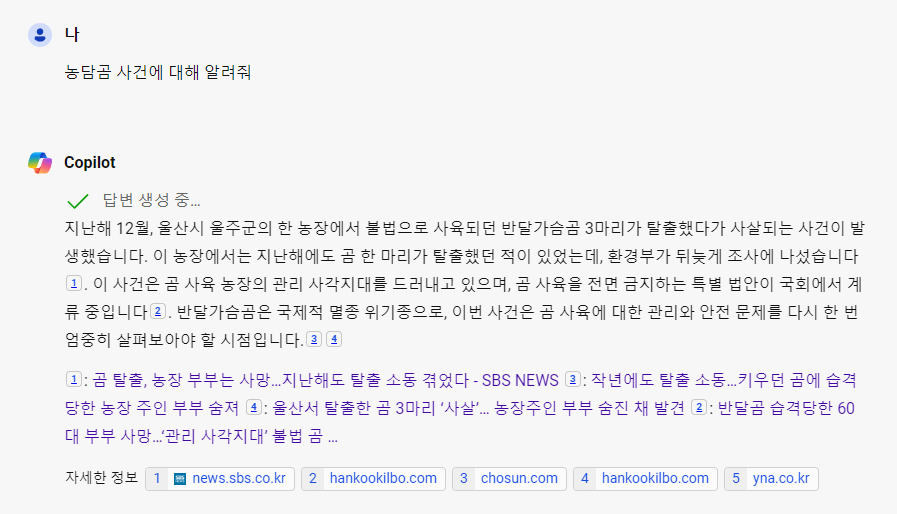
예를 들자면, Chat GPT(Copiliot)에게 '농담곰 사건에 대해서 설명해줘' 라고 질문을 한다면 AI는 이러한 데이터로 학습을 한 적이 없기 때문에 (애초에 존재하지 않았던 사건) 환각하여 잘못된 정보를 알려주는 것이다.
Hallucination의 종류
1. 정보 환각 (Factual Hallucination):
- AI가 질문에 대한 답변으로 잘못된 사실이나 허구의 정보를 제공하는 경우. 예를 들어, 실제로 존재하지 않는 사건이나 인물에 대해 이야기할 때 발생할 수 있다.
2. 논리적 환각 (Logical Hallucination):
- AI가 문법적으로는 맞지만 논리적으로는 맞지 않는 정보를 생성하는 경우. 예를 들어, "서울은 일본의 수도입니다"와 같은 문장을 생성하는 것
3. 망상 환각 (Semantic Hallucination):
- AI가 주제와 관련 없는 정보를 생성하거나 문맥에 맞지 않는 답변을 제공하는 경우. 예를 들어, 역사적인 사건에 대한 질문에 대해 날씨 정보를 제공하는 경우
Hallucination이 발생하는 이유
1. 훈련 데이터의 한계:
- AI 모델은 방대한 데이터셋을 기반으로 학습하지만, 이 데이터셋에 잘못된 정보나 편향된 정보가 포함되어 있을 수 있다.
2. 모델의 일반화 능력:
- AI 모델은 특정 패턴을 일반화하여 새로운 질문에 답변을 생성한다. 이 과정에서 일반화가 잘못되면 실제로 존재하지 않는 정보를 생성할 수 있다.
3. 정보의 부족:
- 질문에 대해 충분한 정보가 훈련 데이터에 없을 때, AI는 제한된 정보를 바탕으로 답변을 추론하게 된다. 이 과정에서 오류가 발생할 수 있다.
4. 언어 모델의 본질:
- 언어 모델은 문맥에 맞는 문장을 생성하는 데 초점을 맞추기 때문에, 문법적으로 맞는 문장을 생성하지만 내용적으로는 맞지 않는 답변을 할 수 있다.
CUE: 에게 기후변화와 관련된 질문을 해보았다.
1) Reasoning

먼저 사용자 질문이 입력되면 (Q. 기후 변화에 대해 알려줘) 추론을 한다. 신뢰성있는 답변을 생성하는데 있어 가장 중요한 단계이다. 해당 질문에 대해서는 기후변화의 원인과 문제점을 추론하고 관련 최신 정보 검색을 위해 Search Planning을 수행한다.
2) Searching

위의 세 가지 질의들을 활용해 반복적인 검색을 수행함에 따라 답변 생성에 충분한 문서들을 먼저 확보할 수 있다. 여기에 확보된 문서들은 뉴스, 지식베이스, 지식백과 등등 정말 다양하다.
3) Evidence Selector
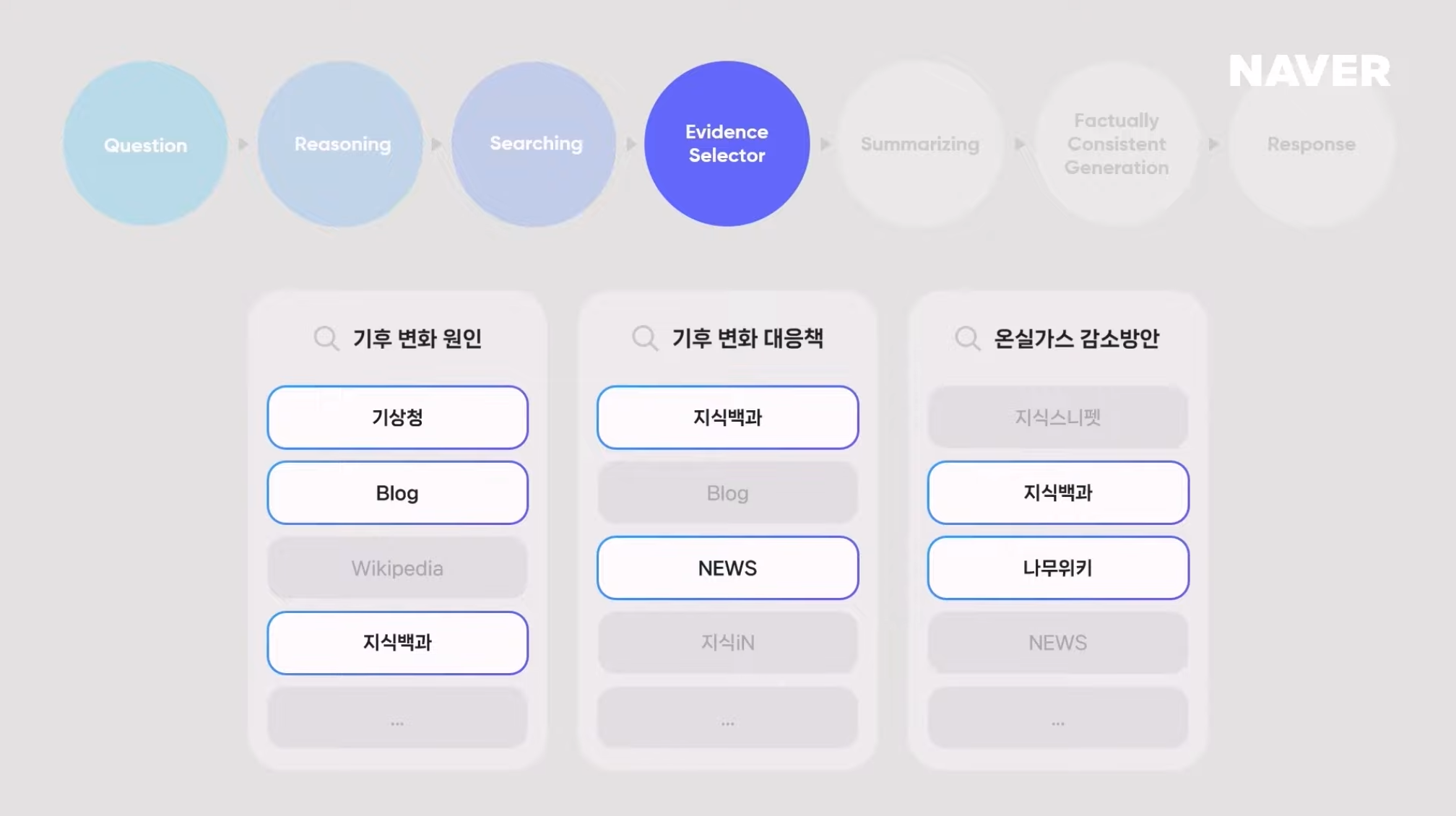
Evidence Selector는 수집된 문서들 중 정답이 포함된 문서들을 선택한다. ➡️ (그런데 여기서 '정답이 포함된 문서'라는 것을 어떻게 인식하는거지?)
4) Summarizing

선택된 문서들은 summarize model들이 요약해주고, 마지막으로 Reasoning 결과와 일치되는지 Factual Consistent를 높이면서 사용자의 질문에 포함된 기후 변화의 원인과 영향, 그리고 감소 방안에 대한 답변을 정리하여 보여준다.
CUE는 이렇게 세 가지 핵심 기능을 이용하여 신뢰할 수 있는 답변을 생성한다. 내부 평가 결과 LLM의 내부 지식으로만 답변을 생성했을 때 대비 Hallucination이 72% 감소되는 것을 확인할 수 있었다고 한다.
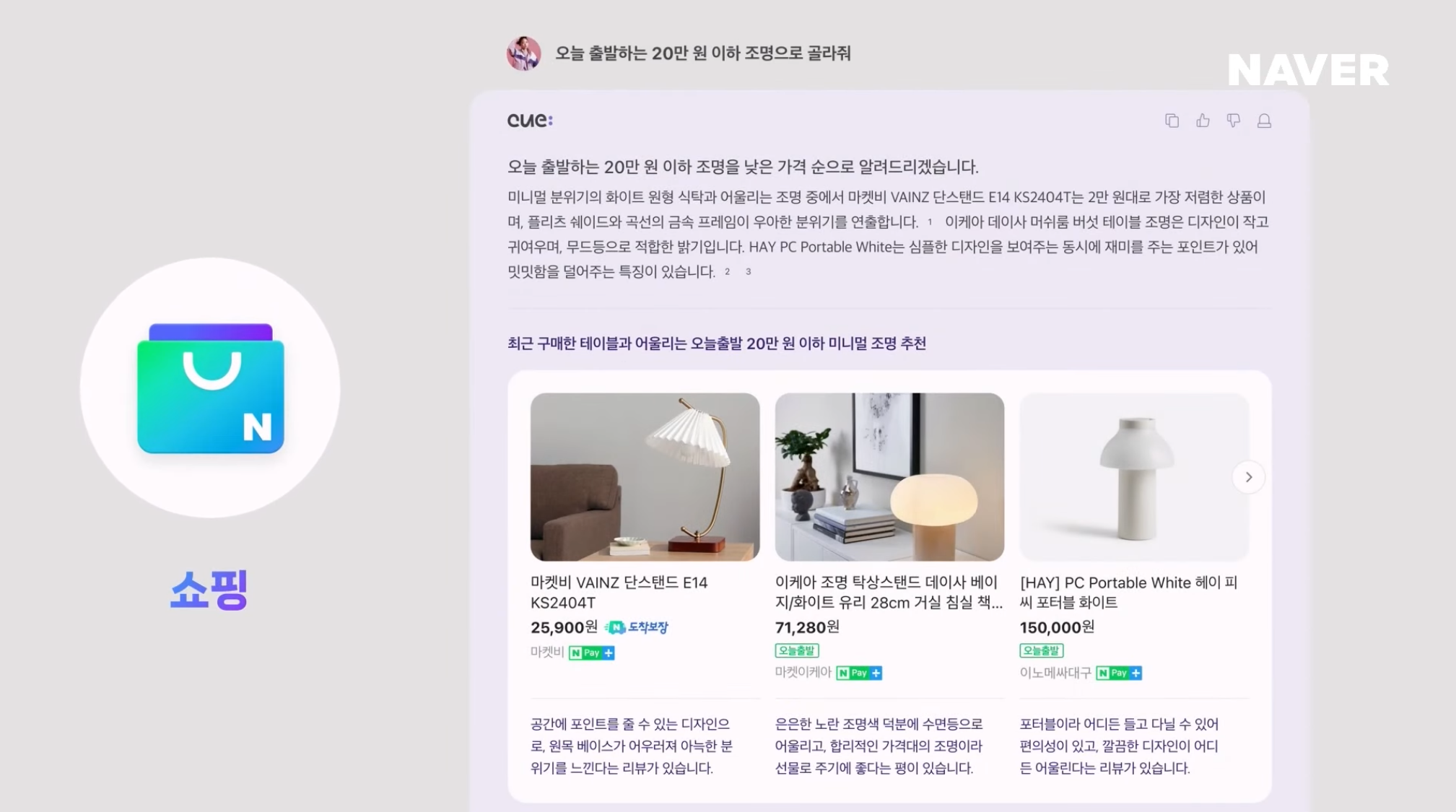
3. Connected

네이버 사용자들은 검색 목적을 달성하기 위해 4번의 다양한 vertical 서비스들을 오고 가며 복잡한 검색을 수행한다.

이러한 사용자들의 검색 흐름을 학습한 CUE:는 다양한 vertical 서비스들을 연결하여 사용자의 검색 목적을 달성할 수 있는 입체적인 답변을 제공한다.
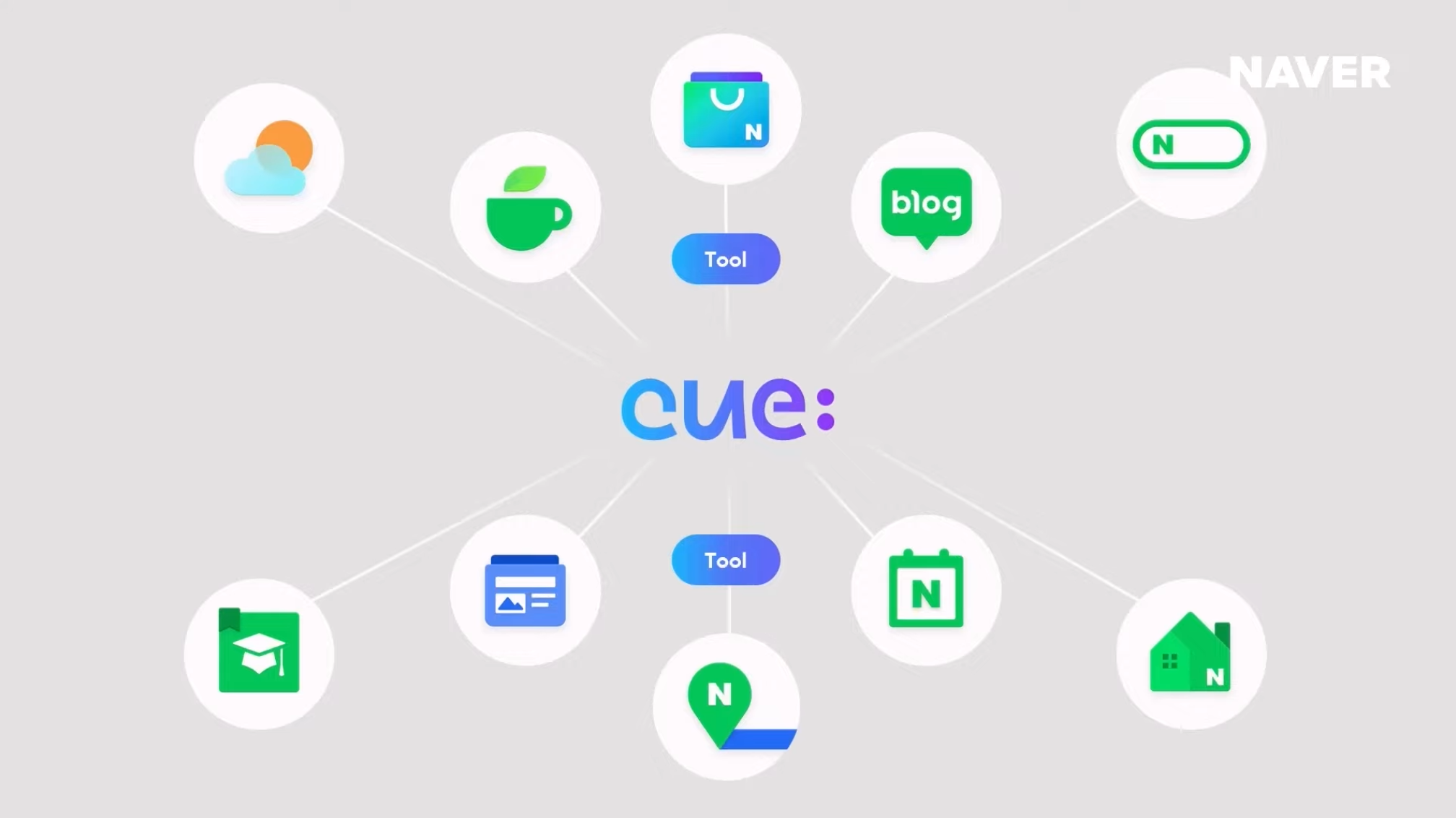
현재 cue:에는 쇼핑, 로컬, 지식 베이스 등 50개 이상의 서비스가 연결되어 있다. cue:는 이렇게 연결된 서비스들을 툴로서 활용할 수 있다.
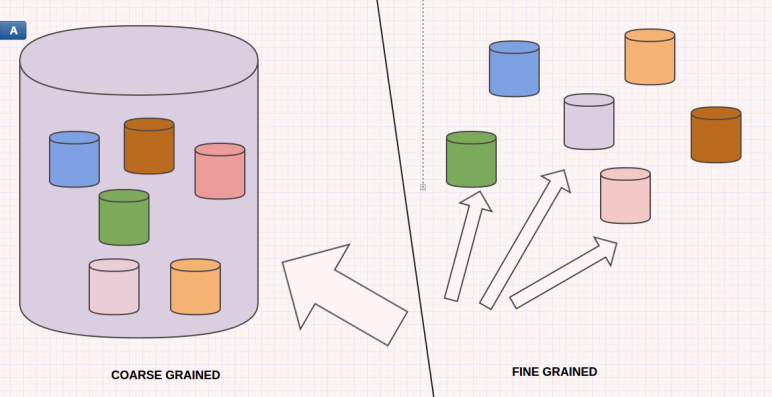
그 결과 사용자 질문에 대해 다양한 서비스에 풍부한 컨텐츠를 Fine Grained api를 활용하여 입체적인 답변을 제공한다.
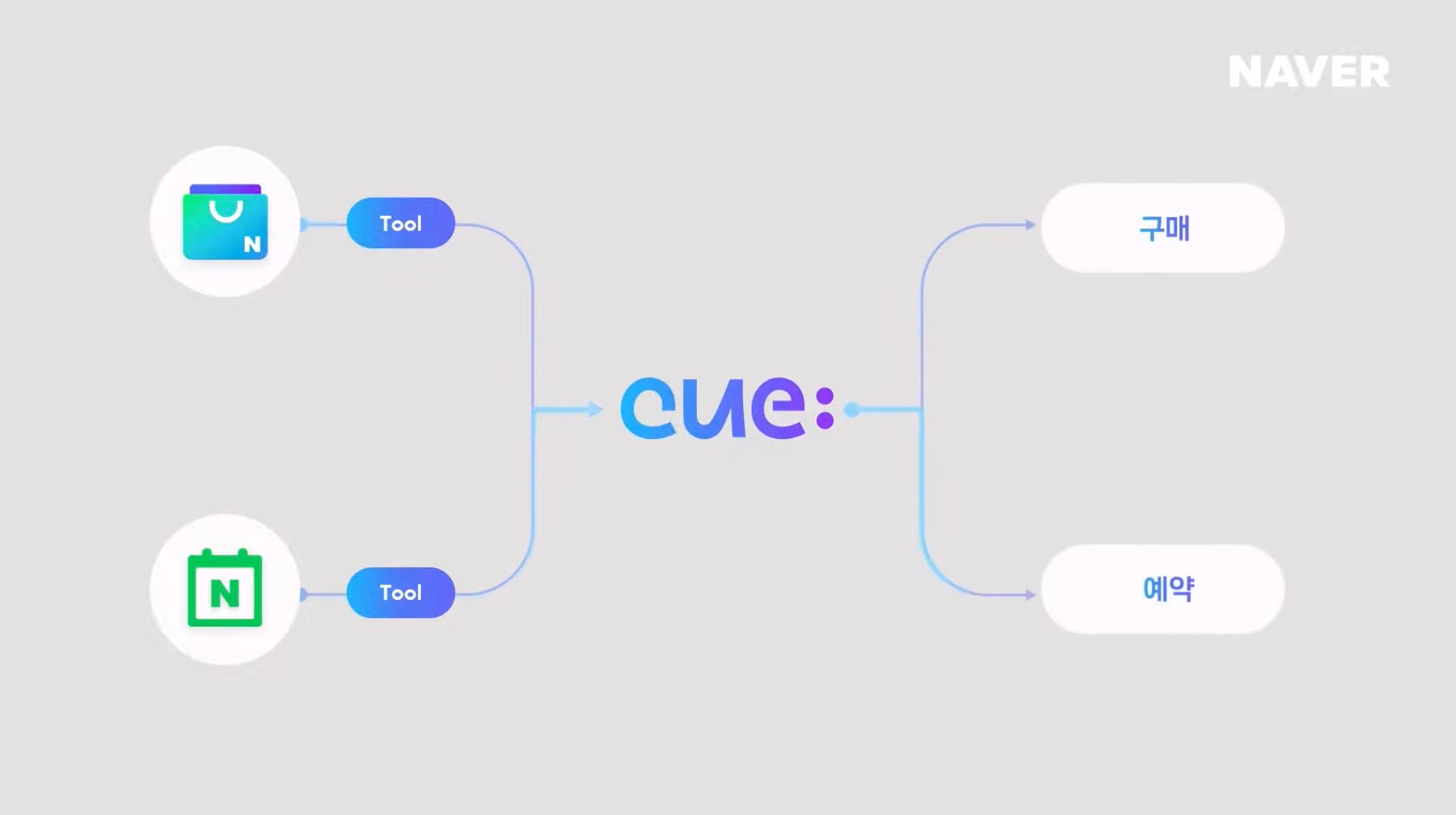
뿐만 아니라 End Point까지 제공하여 목적을 달성 시켜준다.여기서 말하는 End Point는 쇼핑 목적의 질문 ➡️ 구매까지 연결시켜 주고, 장소를 검색하는 질문 ➡️ 장소 정보 + 예약까지 해주는 것 처럼 사용자의 검색 목적을 달성할 수 있는 End Point까지의 연결을 제공한다.
정리
정리해보면 cue:는 답을 생성할 때 사람처럼 판단하고 검색한다. 그리고 cue:만의 기술력으로 Hallucination을 최소화한 신뢰성 있는 답변을 생성한다. 그리고 마지막으로 네이버 서비스가 연결되어 입체적인 답변을 제공한다. 더 나아가 검색 목적을 달성할 수 있게 end point를 제공한다.

