
Kubernetes Networking
기본적으로 Kubernetes는 각 Pod에 고유한 IP를 할당하고, 다양한 방식으로 통신을 지원한다.
1. 서로 결합된 컨테이너와 컨테이너 간 통신
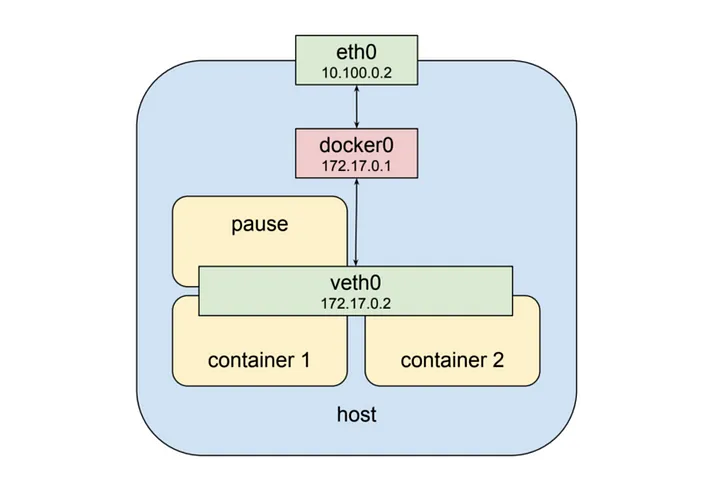
위 미이지와 같이 같은 Pod 내의 veth0 가상 네트워크 인터페이스에 두 개의 컨테이너가 동시에 할당되어 있다.
외부에서는 두 개의 컨테이너가 동일한 IP로 보이기 때문에 veth0 안에서 각 컨테이너는 고유한 port 번호로 서로를 구분한다.
따라서 Pod 내에서 컨테이너는 각자 고유한 port 번호를 사용해야한다.
- Pod 내부 컨테이너는 동일한 네트워크 인터페이스를 사용
localhost또는127.0.0.1로 직접 통신 가능localhost:<포트번호>형태로 접근 가능
2. Pod와 Pod 간의 통신
Pod는 쿠버네티스 네트워크에서 고유한 Internal IP를 가지며, 같은 클러스터 내에서 IP를 통해 서로 직접 통신할 수 있다.
하지만 Pod의 IP는 동적이므로 변경될 수 있기 때문에 DNS 기반의 서비스 검색(Service Discovery) 또는 Service를 사용하는 것이 일반적이다.
- 같은 네임스페이스 내에서는 Pod IP를 직접 사용 가능
- 클러스터 내의 모든 Pod는 L3 네트워크 계층에서 서로 접근 가능
- NetworkPolicy를 사용하면 특정 Pod 간 통신을 제한 가능
2-1. 싱글 노드 Pod 네트워크
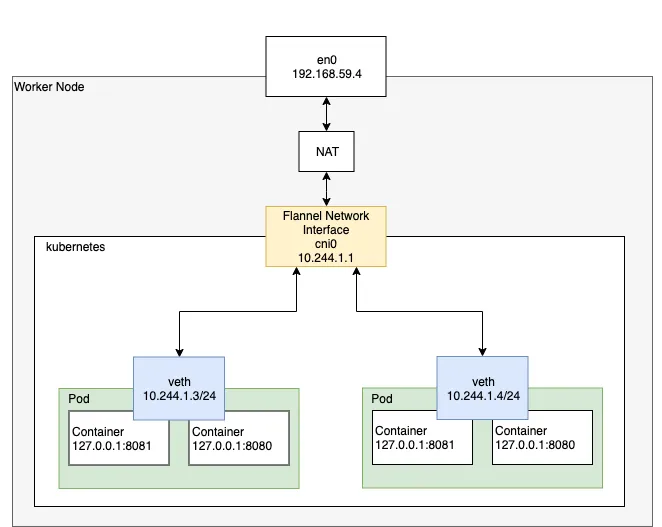 각 Pod는
각 Pod는 kubenet 혹은 CNI 로 구성된 네트워크 인터페이스를 통하여 고유한 IP 주소로 서로 통신할 수 있다.
2-2. 멀티 노드 Pod 네트워크
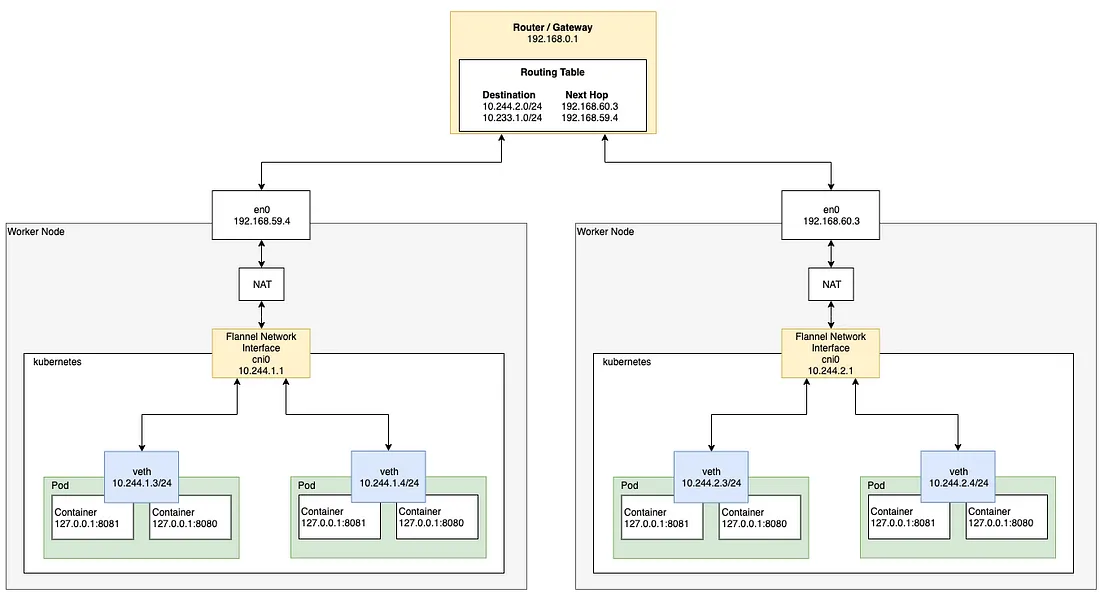 여러 개의 워커 노드 사이에 각각 다른 노드에 존재하는 Pod가 서로 통신하려면 라우터를 거쳐서 통신하게 된다.
여러 개의 워커 노드 사이에 각각 다른 노드에 존재하는 Pod가 서로 통신하려면 라우터를 거쳐서 통신하게 된다.
3. Pod와 Service 간의 통신
Service는 내부적으로 Pod의 로드 밸런서 역할을 하며, 여러 개의 Pod로 요청을 분산시킬 수 있다.
- ClusterIP (기본값): 클러스터 내부에서만 접근 가능
- NodePort: 클러스터 외부에서 접근 가능하도록 각 노드의 특정 포트를 열어줌
- LoadBalancer: 클라우드 제공자의 로드밸런서를 이용하여 외부에 노출
- ExternalName: 외부 DNS 이름을 반환
Service Network 작동 방식
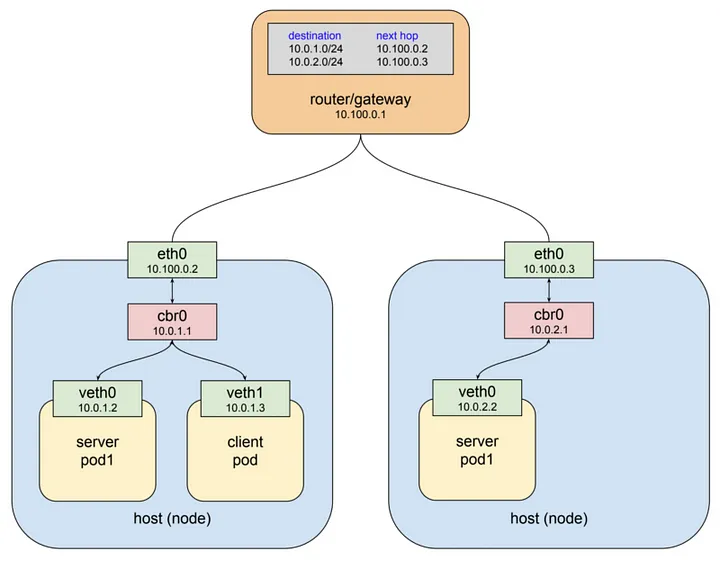 위 이미지의 상황에서 두 개의
위 이미지의 상황에서 두 개의 Worker Node가 있고 하나의 게이트웨이를 통해 서로 연결되어있다.
이때 Master Node에서 아래의 명세서를 통해 Service 네트워크를 생성했다고 가정한다.
apiVersion: v1
kind: Service
metadata:
name: service-test # Service의 이름
spec:
selector:
app: server_pod1 # 10.0.1.2와 10.0.2.2 주소의 Pod 라벨
ports:
- protocol: TCP
port: 80 # Service에서 서버 컨테이너 어플리케이션과 매핑시킬 포트 번호
targetPort: 8080 # 서버 컨테이너에서 구동되고 있는 서버 어플리케이션 포트 번호client pod가 Service 네트워크를 통해 server pod1으로 HTTP request를 요청하는 과정은 아래와 같다.
client pod가 http request를service-test라는DNS Name으로 요청한다.- 클러스터 DNS 서버(
coredns)가 해당 이름을service IP(ex.10.3.241.152)로 매핑한다. - HTTP 클라이언트는
DNS로부터 IP(10.3.241.152)를 이용하여 최종적으로 요청을 보내게 된다.
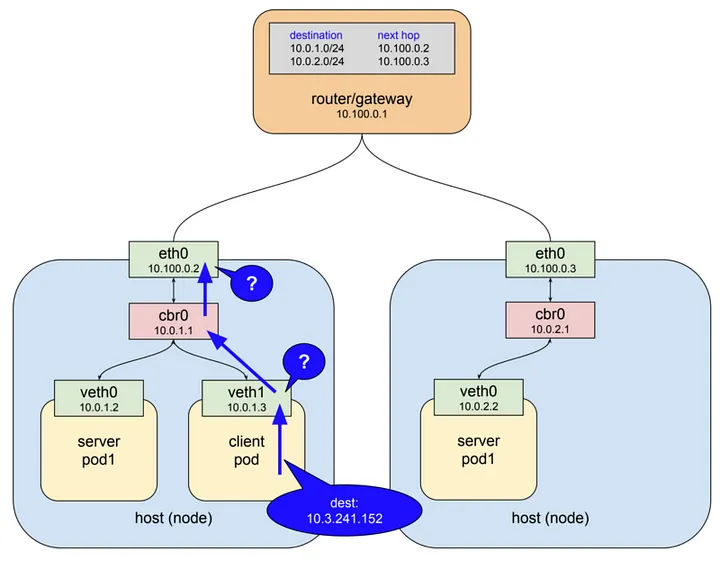 L3 네트워크는 기본적으로 자신의 host에서 목적지를 찾지 못하면 상위 게이트웨이로 패킷을 전달하도록 동작한다.
L3 네트워크는 기본적으로 자신의 host에서 목적지를 찾지 못하면 상위 게이트웨이로 패킷을 전달하도록 동작한다.
현 상황에서 client pod 안에 들어 있는 첫번째 가상 이더넷 인터페이스(veth1)에서 목적지 IP를 보게 되고 10.3.241.152라는 주소에 대해 전혀 알지 못하기 때문에 다음 게이트웨이(cbr0)로 패킷을 넘기게 된다.
cbr0는 bridge이기 때문에 단순히 다음 게이트웨이(eth0)로 패킷을 전달한다.
여기서도 마찬가지로 eth0라는 이더넷 인터페이스가 10.3.241.152라는 IP 주소에 대해서 모르기 때문에 보통이라면 최상위에 존재하는 게이트웨이로 전달될 것이다.
 하지만 예상과는 달리 위 이미지처럼 패킷의 Destination 주소가 변경되어
하지만 예상과는 달리 위 이미지처럼 패킷의 Destination 주소가 변경되어 server pod1 중 하나로 패킷이 전달되게 된다.
이는 kube-proxy 컴포넌트 덕분인데, Kubernetes는 리눅스 커널 기능 중 하나인 netfilter와 user space에 존재하는 인터페이스인 iptables라는 소프트웨어를 이용하여 패킷 흐름을 제어한다.
iptables는 netfilter를 이용하여 chain rule이라는 규칙을 지정하여 패킷을 포워딩 하도록 네트워크를 설정하는데 Kubernetes는 netfilter를 kernel space에서 proxy(Destination proxy)형태로 사용한다.
즉, iptables의 DNAT(Destination NAT)를 사용하여 클러스터 IP → 실제 Pod IP로 변환한다
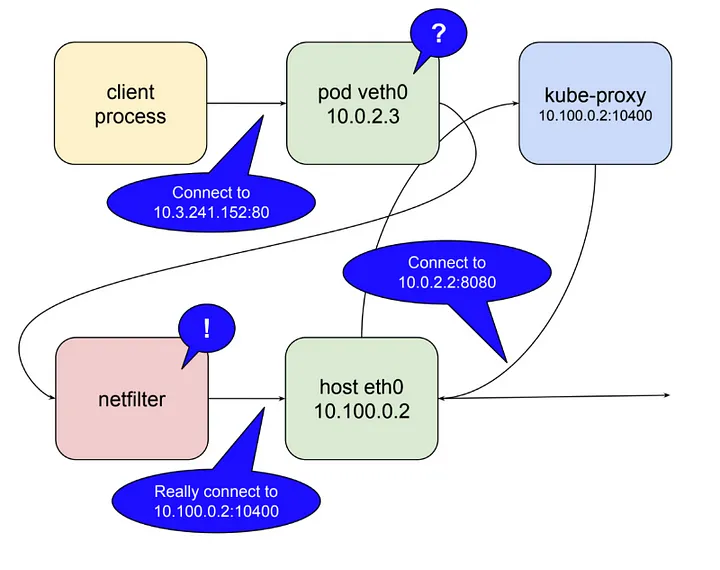
kube-proxy가 user space 모드로 동작할 때
kube-proxy가localhost인터페이스에서Service의 요청을 받아내기 위해10400 포트(임의)를 연다.kube-proxy가netfilter로하여금service IP(10.3.241.152:80)로 들어오는 패킷을kube-proxy자신에게 라우팅 되도록 설정을 한다.kube-proxy로 들어온 요청을 실제server pod의IP:Port(10.0.2.2:8080)로 요청을 전달한다.
이처럼 Kubernetes에서 kube-proxy는 클러스터 네트워크를 관리하기 위해 netfilter를 활용한다. 이를 위해 kube-proxy가 해야 할 일은 단순히 자신의 포트를 열고, 마스터 API Server로부터 전달받은 Service 정보를 기반으로 netfilter에 적절한 규칙을 입력하는 것뿐이다.
하지만 user space에서 proxying을 수행하는 방식은 모든 패킷을 user space에서 kernel space로 변환해야 하기 때문에 그만큼 성능 오버헤드가 발생한다. 이를 해결하기 위해 Kubernetes 1.2 버전부터 iptables 모드가 도입되었다.
이 모드에서는 kube-proxy가 직접 proxy 역할을 수행하지 않고, 모든 처리를 netfilter에게 맡긴다. 이를 통해 Service IP를 발견하고 실제 Pod로 전달하는 과정이 netfilter에서 이루어지며, kube-proxy는 단순히 netfilter의 규칙을 수정하는 역할만 담당하게 되었다.
4. 외부와 Service 간의 통신
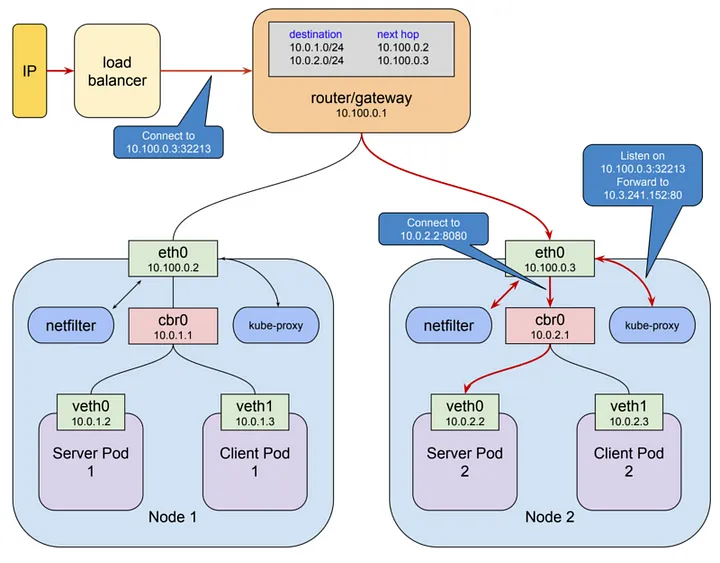
쿠버네티스 클러스터 외부에서 내부의 애플리케이션에 접근하려면 Service를 외부로 노출해야 한다. 이를 위해 NodePort, LoadBalancer, Ingress 같은 방식을 사용할 수 있다.
외부로 노출하는 방법
- NodePort: 각 노드의 특정 포트에서 접근 가능
- LoadBalancer: 클라우드 제공자의 로드밸런서를 이용하여 외부 IP 제공
- Ingress: 여러 Service를 하나의 도메인 기반으로 관리
Kubernetes Network Model
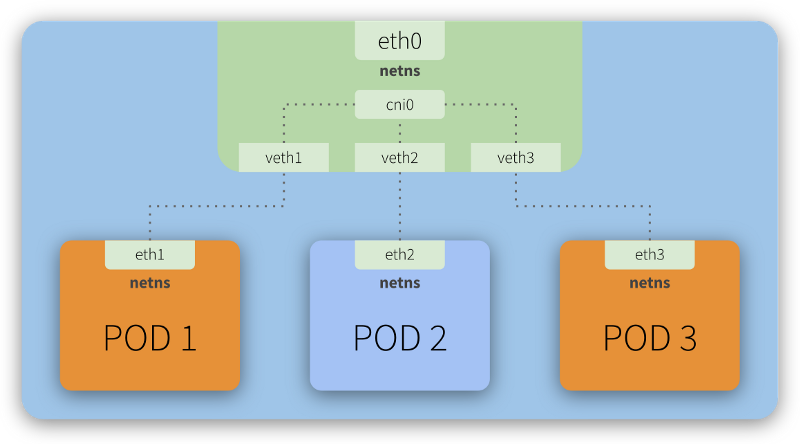 쿠버네티스에서 Pod들은 각각 독립적인
쿠버네티스에서 Pod들은 각각 독립적인 Network Namespace를 가지지만, CNI를 통해 Bridge Network를 공유한다.
이러한 네트워크 연결은 CNI 플러그인을 통해 설정되는데 이 구조 덕분에 Pod들은 클러스터 내에서 고유한 IP를 가지며, 직접 통신할 수 있다.
1. 네트워크 네임스페이스 (netns)
- 각 Pod는 자신만의 네트워크 네임스페이스 (
netns) 를 가진다. netns는 격리된 네트워크 공간으로, 각 Pod가 독립적인 네트워크 인터페이스를 갖도록 해준다.
2. 가상 이더넷 페어 (veth)
- Pod 간 통신을 위해 가상 이더넷 인터페이스 (
vethpair) 가 사용된다. veth1,veth2,veth3는 각 Pod의 인터페이스(eth1,eth2,eth3)와 연결되어 있다.veth인터페이스는 물리적으로 연결되지 않은 상태에서Tunnel처럼 동작하여 패킷을 전달한다.
3. CNI 브리지 (cni0)
cni0는 Pod들이 소속된 브리지 네트워크 인터페이스로, Pod들이 같은 네트워크를 공유할 수 있도록 한다.cni0는 쿠버네티스CNI플러그인이 설정하는 가상 네트워크 브리지다.eth0는veth를 통해cni0과 연결되며, 클러스터 외부 또는 노드 네트워크와 통신할 수 있도록 한다.
4. 통신 흐름 (Pod 1 <> Pod 2)
- Pod 1의
eth1네트워크 인터페이스에서 패킷을 전송 veth1을 통해cni0로 패킷 전달cni0가 목적지 IP를 확인하고veth2를 통해 Pod 2의eth2인터페이스로 전달
Network Containers
Kubernetes Network를 담당하는 주요 컨테이너들은 다음과 같다
| 컨테이너 | 역할 |
|---|---|
| CoreDNS | 클러스터 내 DNS 서비스 제공, Service 도메인 네임 해석 |
| kube-flannel | Pod 간 네트워크 관리, 오버레이 네트워크 구축 |
| kube-proxy | Pod와 Service 간 라우팅 관리, 트래픽 분산 |
1. CoreDNS
CoreDNS는 쿠버네티스 클러스터 내에서 서비스 검색(Service Discovery)을 위한 DNS 서비스를 제공하는 컨테이너다. 클러스터 내부에서 Pod가 다른 Pod 또는 Service에 접근할 때 DNS 기반으로 이름 해석을 가능하게 한다.
주요 기능
kube-dns를 대체하는 기본 DNS 서비스- 쿠버네티스 Service의 도메인 네임 해석 (ex.
my-service.default.svc.cluster.local) - 쿠버네티스 내부 및 외부 DNS 요청 처리
- 플러그인 기반 구조로 확장 가능
클러스터 내부 DNS 질의 구조
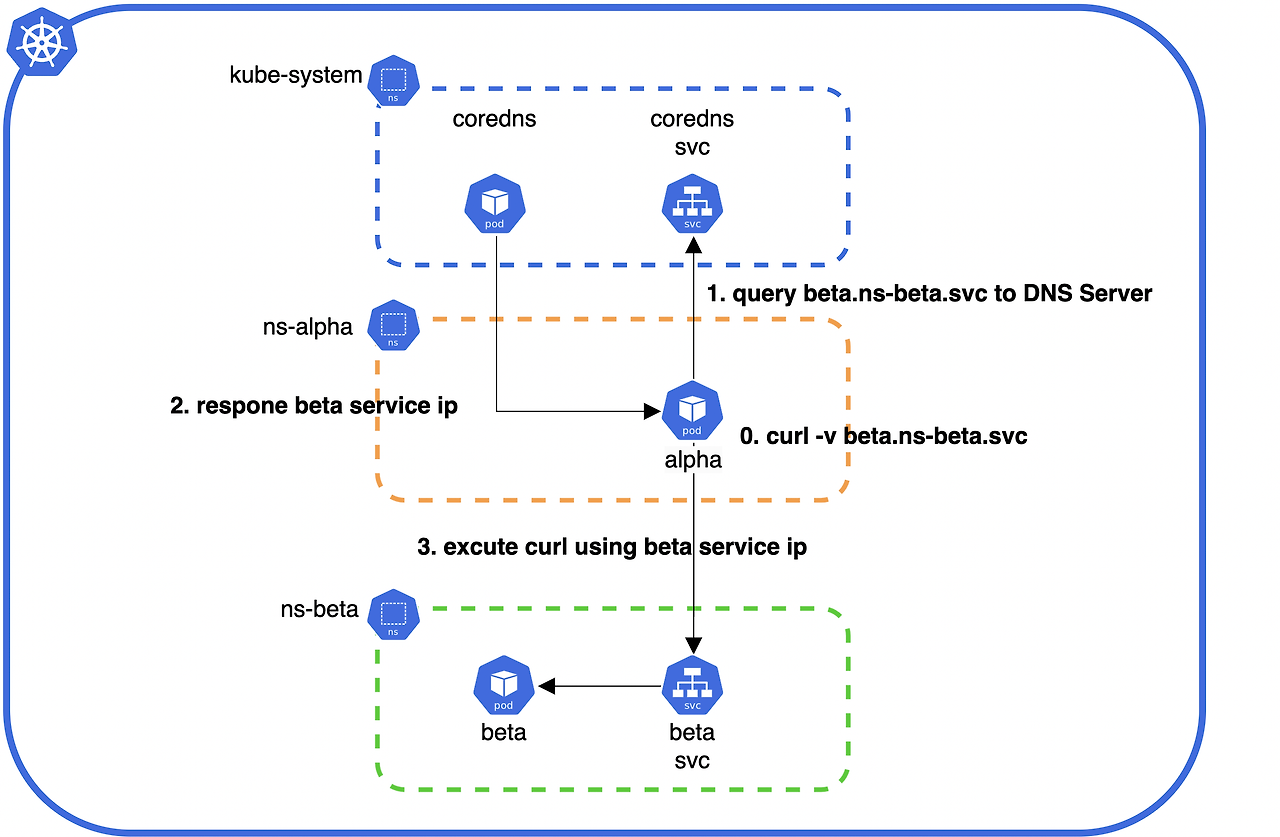
-
alpha Pod에서 beta 서비스로 요청 전송 :
alphaPod는beta.ns-beta.svc도메인으로curl -v beta.ns-beta.svc요청을 보낸다. -
CoreDNS에 DNS 질의 수행 :
alphaPod는CoreDNS서비스에beta.ns-beta.svc도메인의 IP를 요청한다. -
CoreDNS가 Service IP 반환 :
CoreDNS는beta서비스의 IP를 찾아alphaPod에 반환한다. -
alpha Pod가 beta 서비스로 직접 요청 전송 :
alphaPod는 반환된beta서비스의 IP를 사용하여 실제 요청을 보낸다.
클러스터 외부 DNS 질의 구조

-
alpha Pod에서 naver.com으로 요청 전송 :
alphaPod는naver.com도메인으로curl -v naver.com요청을 보낸다. -
CoreDNS에 DNS 질의 수행 :
alphaPod는CoreDNS서비스에naver.com도메인의 IP를 요청한다. -
외부 DNS 서버에 질의 및 응답 수신 :
CoreDNS는 외부 DNS 서버에naver.comIP를 요청하고 응답을 받는다. -
CoreDNS가 naver.com IP 반환 :
CoreDNS는naver.com의 실제 IP를alphaPod에 반환한다. -
alpha Pod가 naver.com으로 직접 요청 전송 :
alphaPod는 반환된naver.comIP를 사용하여 실제 요청을 보낸다.
2. kube-flannel
kube-flannel은 Flannel CNI 플러그인의 핵심 컨테이너로, 쿠버네티스 네트워크를 관리한다. 클러스터 내 Pod 간 통신을 가능하게 하는 Overlay Network를 제공한다.
- Pod 네트워크를 구성하여 각 노드 간 통신 가능하게 함
VXLAN(가상 네트워크 터널링)방식으로 패킷을 전달VXLAN(Virtual eXtensible LAN)은L2 네트워크를L3 네트워크위에서 확장할 수 있도록 설계된오버레이 네트워크기술이다.- 이를 이용하여 물리적으로 다른 노드에 있는 Pod들 간에도 마치 동일한 네트워크를 사용하는 것처럼 통신할 수 있다.
flanneld데몬을 통해 라우팅 정보 관리
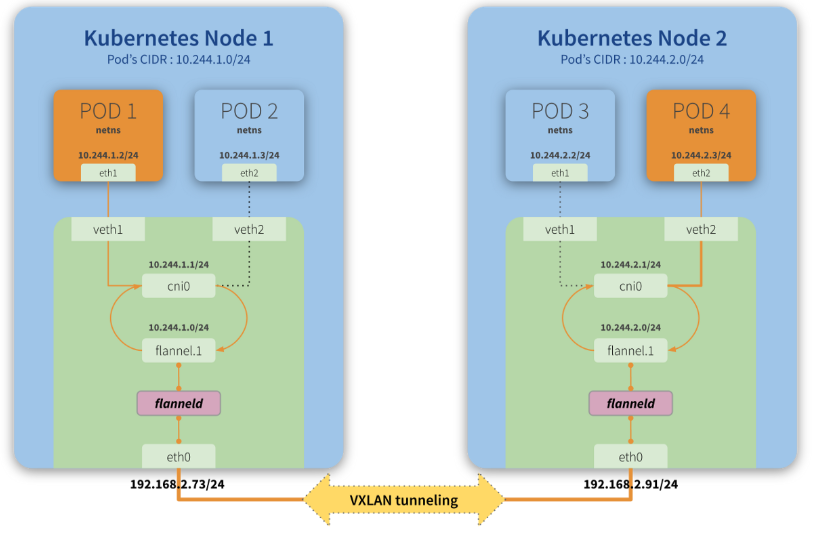
-
Pod1에서 Pod4로 패킷 전송 : Pod1(10.244.1.2/24)은 Pod4(10.244.2.3/24)로 패킷을 전송한다.
-
cni0 브리지를 통해 flannel.1로 전달 : Pod1의 패킷은
veth1을 거쳐cni0브리지로 전달되고,flannel.1인터페이스로 전달된다. -
Flannel 데몬(flanneld)이 패킷을 VXLAN 터널로 Encapsulation
flanneld는 패킷의 목적지인 Pod4(10.244.2.3) 가Node2(192.168.2.91)에 위치하고 있음을 확인한다.- 기존 패킷(원래 목적지:
10.244.2.3)을 VXLAN 헤더와 함께 새로운 UDP 패킷으로 감싸 Encapsulation한다. - UDP 헤더에는 VXLAN Network Identifier(VNI) 가 포함되며, 이는 가상의 네트워크 세그먼트를 식별하는 역할을 한다.
- Encapsulation된 패킷은
192.168.2.91(Node2의 Flannel 인터페이스)로 전송된다.
-
Node2에서 flanneld가 패킷을 해제 :
Node2의flanneld가 패킷을 수신하고,flannel.1을 통해cni0브리지로 전달한다.flanneld는 VXLAN 헤더를 제거하고, 내부의 원본 패킷(목적지:10.244.2.3)을 추출한다.- 복원된 패킷은
flannel.1인터페이스를 통해cni0브리지로 전달된다. cni0브리지는 해당 패킷을veth2인터페이스를 통해 최종적으로 Pod4(10.244.2.3)에 전달한다.
-
Pod4로 패킷 전달 :
cni0브리지는veth2를 통해 최종적으로 Pod4(10.244.2.3/24)에 패킷을 전달한다.
Underlay Network (eth0)
VXLAN 터널을 통해 패킷이 전달될 때, eth0 인터페이스는 실제 물리적인 네트워크(Underlay Network)를 담당하는 인터페이스이다.
Underlay NetworkVXLAN은Overlay Network이며, 이는 기존 네트워크 위에서 가상의 네트워크를 만드는 방식이다.- 이때 실제 패킷이 전송되는 물리적 네트워크는
Underlay Network라고 하며,eth0인터페이스가 이에 해당한다. - 즉,
VXLAN 패킷이encapsulation된 후 IP 네트워크를 통해 전달되는 역할을 수행한다.
- 각 쿠버네티스 노드(Node1, Node2)에는 노드 간 통신을 담당하는 물리적인 네트워크 인터페이스(
eth0) 가 있다. eth0는 VXLAN 터널을 통해 인캡슐레이션된 패킷을 다른 노드로 전송한다.- 실제로는
192.168.2.73/24(Node1) ↔192.168.2.91/24(Node2) 간 패킷을 전달하는 역할을 한다.
이를 실제 Linux Network 서비스 관점에서 바라보면 아래와 같다
Flannel이 VXLAN을 사용할 경우, flannel.1이라는 가상 인터페이스가 생성된다.
이 인터페이스는 실제 VXLAN 패킷을 전송하기 위한 가상의 네트워크 장치이며, eth0와 함께 동작한다.
ip link add flannel.1 type vxlan id 1 dev eth0 dstport 4789
ip link set flannel.1 upflannel.1이라는VXLAN 인터페이스를 생성한다.id 1:VXLAN Network Identifier(VNI)이며, 같은VNI를 사용하는 노드끼리 통신 가능하다.dev eth0: VXLAN 패킷을 전송할 물리 네트워크 인터페이스(Underlay Network)로eth0을 지정한다.dstport 4789: VXLAN의 기본 포트(UDP 4789)를 사용하여 터널링한다.
ip addr add 10.244.1.0/24 dev flannel.1
ip route add 10.244.2.0/24 via 192.168.2.91 dev eth010.244.1.0/24를flannel.1에 할당하여 Pod 네트워크 인터페이스로 사용한다.10.244.2.0/24(Node2 CIDR)에 대한 라우트를eth0을 통해192.168.2.91로 설정한다.
3. kube-proxy
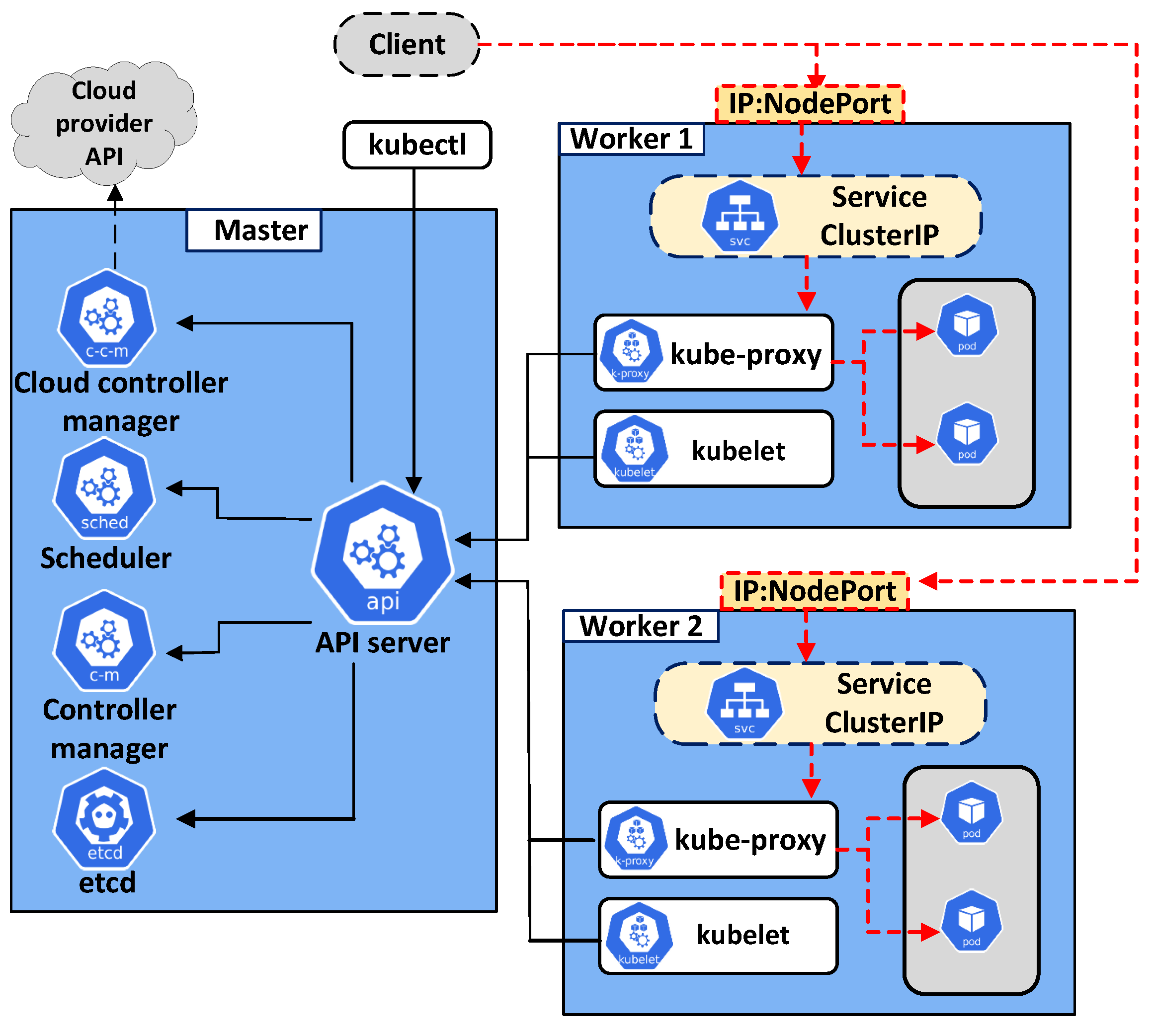
kube-proxy는 쿠버네티스에서 네트워크 트래픽을 관리하는 컨테이너이다.
- 각 노드에서 실행되며 Kubernetes Service의 라우팅 관리
iptables또는IPVS를 사용하여 트래픽 분산- 클러스터 내
Pod와Service간 통신을 가능하게 함 - 외부 요청을
NodePort,LoadBalancer등을 통해 처리
kube-proxy Mode
- iptables Mode: 네트워크 패킷을 iptables 규칙을 통해 처리 (기본값)
- IPVS Mode: 커널 레벨의 고성능 라우팅 방식 사용
Spring BE Deployment
sudo docker run -p 8080:8080 \
--network host \
--user 1000:1000 \
--cpus=0.8 \
--memory=400m \
--memory-swap=800m \
--restart=always \
--name wwwm-spring-be \
-d <Image>우선 현재 v1.0 서비스는 위와 같은 스펙으로 AWS EC2의 t2.micro 서버에 배포되고 있으며
 Google Analytics까지 적용되어 위와 같이 FE에서는 Metric을 수집하고 있다.
Google Analytics까지 적용되어 위와 같이 FE에서는 Metric을 수집하고 있다.
이를 Private Cloud에서 배포 가능하도록 하고 여러 Monitoring 및 Logging 오픈소스 프로젝트들을 현 K8s 및 Openstack Cluster에 추가하여 최종적으로는 Private Cloud에서 서비스할 수 있도록 하는 것을 목표로 하고 있다.
Deployment, Service
apiVersion: apps/v1
kind: Deployment
metadata:
name: wwwm-spring-be-deployment
spec:
replicas: 2
selector:
matchLabels:
app: wwwm-spring-be
template:
metadata:
labels:
app: wwwm-spring-be
spec:
containers:
- name: wwwm-spring-be
image: <Image>
ports:
- containerPort: 8080
resources:
requests:
cpu: "800m"
memory: "400Mi"
limits:
cpu: "1"
memory: "800Mi"
readinessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 60
periodSeconds: 10우선 위와 같이 Deployment 관련 yaml 파일을 생성해준다.
-
selector.matchLabels: app: wwwm-spring-be 레이블을 가진 Pod을 선택- 생성되는 Pod에는
app: wwwm-spring-be라는 레이블이 붙음 - 위
selector.matchLabels와 일치해야 해당 Pod이 Deployment에서 관리
- 생성되는 Pod에는
-
containerPort: 8080: 컨테이너 내부에서 애플리케이션이 8080 포트에서 실행 -
requests: 컨테이너가 실행될 때 최소한으로 보장받을 리소스cpu: "800m"→ 800m(0.8 vCPU)memory: "400Mi"→ 400MiB RAM
-
limits: 컨테이너가 사용할 수 있는 최대 리소스cpu: "1"→ 최대 1 vCPU 사용 가능memory: "800Mi"→ 최대 800MiB RAM 사용 가능
-
Readiness Probe: Pod이 트래픽을 받을 준비가 되었는지 확인httpGet: 8080 포트에서/actuator/health엔드포인트를 호출하여 상태 체크initialDelaySeconds: 30→ 컨테이너 시작 후 30초 대기 후 첫 번째 체크periodSeconds: 10→ 이후 10초마다 체크
-
Liveness Probe: 컨테이너가 정상적으로 실행 중인지 확인initialDelaySeconds: 60→ 컨테이너 시작 후 60초 대기 후 첫 번째 체크periodSeconds: 10→ 이후 10초마다 체크
### AWS EC2 (t2.micro)
$ free -h
total used free shared buff/cache available
Mem: 764Mi 377Mi 159Mi 13Mi 352Mi 387Mi
Swap: 1.0Gi 321Mi 702Mi
$ docker stats --no-stream
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
ee7d935c4b0f wwwm-spring-be 0.10% 86.39MiB / 400MiB 21.60% 0B / 0B 3.95GB / 1.68GB 40또한 현재 배포되고 있는 Public Cloud의 리소스를 추가적으로 확인해주었다.
t2.micro이니만큼 최대 1개의 CPU와 400MiB의 메모리를 사용할 수 있었는데, 현재 Deployment구성과 같이 배포를 진행하게 되면 약 4개의 EC2 인스턴스를 활용할 수 있는 형태가 된다.
kubectl apply -f wwwm-spring-deployment.yaml이후 위와 같이 kubectl apply를 통해 Deployment를 생성하면
[root@master k8s]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
wwwm-spring-be-deployment 0/2 2 0 10s
[root@master k8s]# kubectl get pods
NAME READY STATUS RESTARTS AGE
wwwm-spring-be-deployment-76fbc5d5f6-22r6x 0/1 CrashLoopBackOff 5 (86s ago) 7m46s
wwwm-spring-be-deployment-76fbc5d5f6-lv9zp 0/1 CrashLoopBackOff 5 (83s ago) 7m46s위와 같이 새로운 Deployment와 Pod가 생성되는 것을 볼 수 있다.
$ kubectl logs -f wwwm-spring-be-deployment-76fbc5d5f6-22r6x
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v3.3.2)
...
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'appointmentDAO' defined in URL [jar:nested:/app.jar/!BOOT-INF/classes/!/org/example/whenwillwemeet/data/dao/AppointmentDAO.class]: Unsatisfied dependency expressed through constructor parameter 0: Error creating bean with name 'appointmentRepository' defined in org.example.whenwillwemeet.data.repository.AppointmentRepository defined in @EnableMongoRepositories declared on MongoRepositoriesRegistrar.EnableMongoRepositoriesConfiguration: Cannot resolve reference to bean 'mongoTemplate' while setting bean property 'mongoOperations'하지만 현재 External Network로 접속이 불가능하기 때문에 MongoDB 서버와 연결할 수 없는 오류가 발생한다.
이는 추후 네트워크 설정이 진행됨에 따라 자연스럽게 해결된다.
apiVersion: v1
kind: Service
metadata:
name: wwwm-spring-be-service
spec:
selector:
app: wwwm-spring-be
ports:
- protocol: TCP
port: 8080
targetPort: 8080이후 위와 같이 Service를 정의한다.
-
selector.app: wwwm-spring-beapp: wwwm-spring-be레이블을 가진Pod들을 대상으로 트래픽을 전달함- 즉,
wwwm-spring-be라는Deployment에서 생성한Pod을 서비스가 관리
-
protocol: TCP: TCP 프로토콜을 사용하여 통신 -
port: 8080: Service가 외부에서 노출하는 포트 (클라이언트가 접속하는 포트) -
targetPort: 8080: Pod 내부에서 애플리케이션이 실행 중인 포트
즉,Service가8080포트로 요청을 받으면, 내부적으로Pod의8080포트로 전달
kubectl apply -f wwwm-spring-service.yaml$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 46h
wwwm-spring-be-service ClusterIP 10.111.26.42 <none> 8080/TCP 7s이후 위와 같이 서비스가 정상적으로 생성된 것을 볼 수 있다.
Kubernetes Ingress
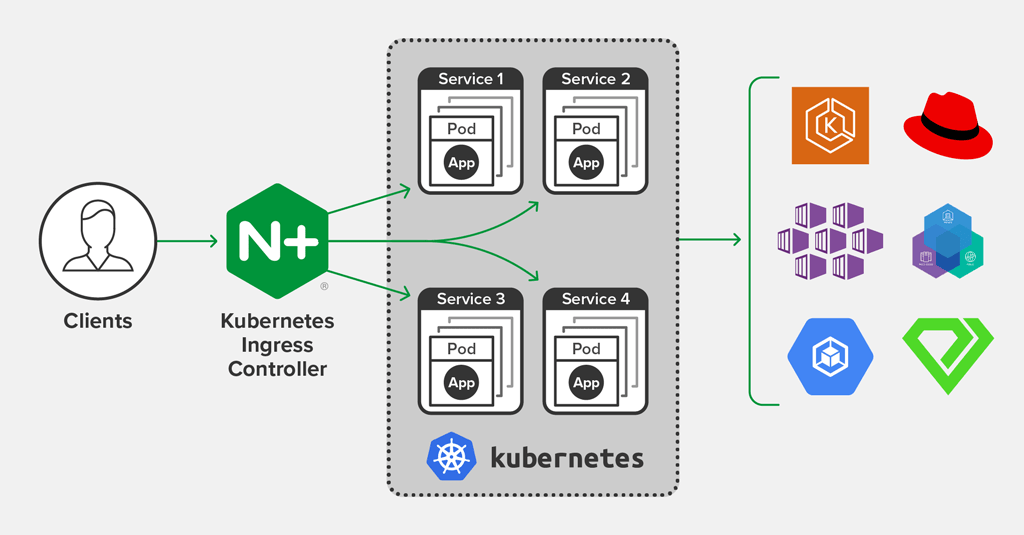
1. Ingress란?
Kubernetes의 Ingress는 외부에서 클러스터 내부로 들어오는 네트워크 요청(Ingress 트래픽)을 처리하는 방법을 정의하는 리소스이다. 쉽게 말해, 외부에서 Kubernetes 내부의 Deployment와 Service에 접근하기 위한 Gateway 역할을 담당한다.
2. Ingress를 사용하지 않을 경우의 대안
Ingress를 사용하지 않는다면, 외부 요청을 처리할 수 있는 방법으로는 다음과 같은 방법이 있다.
NodePort: 클러스터의 각 노드에서 특정 포트를 개방하여 요청을 전달ExternalIP: 특정 노드에 외부 IP를 부여하여 접근 가능하도록 설정LoadBalancer: 클라우드 환경에서 제공하는 L4 Load Balancer를 활용
하지만 이러한 방법들은 대부분 Layer 4(TCP, UDP)에서의 요청을 처리하며, HTTP 트래픽을 정교하게 제어하는 데 한계가 있다.
3. Ingress의 역할
Ingress는 Layer 7(HTTP, HTTPS)에서 동작하며, 다양한 기능을 제공한다.
로드 밸런싱: 다수의 백엔드 서비스로 트래픽을 분산TLS/SSL 처리: HTTPS 인증서 적용 및 TLS 종료경로 기반 라우팅: 특정 도메인 혹은 URL 경로에 따라 다른 서비스로 트래픽을 전달
NodePort, ExternalIP와 같은 기존 방법으로도 가능하지만, 이를 개별적으로 설정하면 서비스 운영이 복잡해진다. Ingress를 사용하면 Ingress Controller라는 특수한 웹 서버를 통해 추상화된 방식으로 라우팅 로직을 정의할 수 있다.
4. Ingress Controller
Ingress가 정상적으로 동작하려면 Ingress Controller가 필요하다. Ingress Controller는 클러스터 내에서 Ingress 리소스를 해석하고, 실제 트래픽을 관리하는 역할을 한다.
| Ingress Controller | 특징 | 장점 | 단점 |
|---|---|---|---|
| NGINX Ingress Controller | 가장 널리 사용되는 Ingress Controller로, NGINX를 기반으로 동작 | ✅ 안정적인 성능과 널리 검증된 기술 ✅ 다양한 커스터마이징 옵션 제공 ✅ Kubernetes와의 높은 호환성 | ❌ 고급 기능 사용 시 설정이 복잡 ❌ 대규모 트래픽 처리 시 튜닝 필요 |
| Traefik | 최신 트렌드에 맞춘 클라우드 네이티브 Ingress Controller | ✅ 자동 서비스 디스커버리 지원 ✅ 가벼운 구조와 빠른 속도 ✅ Kubernetes CRD 지원으로 유연한 설정 가능 | ❌ 설정이 상대적으로 생소함 ❌ 일부 복잡한 기능 부족 |
| HAProxy | 고성능 L7 로드 밸런서로, Kubernetes 환경에서도 사용 가능 | ✅ 매우 빠른 성능과 낮은 리소스 사용량 ✅ 높은 안정성과 효율적인 트래픽 관리 ✅ 강력한 보안 및 SSL 처리 성능 | ❌ 설정이 어렵고 학습 곡선이 높음 ❌ 기본 제공되는 문서와 예제가 부족 |
| Kong | API Gateway 기능을 갖춘 Ingress Controller | ✅ API 관리 및 인증, 라우팅 기능 내장 ✅ 플러그인 시스템을 통한 확장성 ✅ 높은 보안 및 성능 | ❌ 다른 Ingress Controller보다 복잡 ❌ API Gateway 기능이 필요 없는 경우 과한 기능 |
| Cloud Provider Load Balancer (AWS, GCP, Azure 등) | 클라우드 제공사의 Managed Load Balancer를 활용하는 방식 | ✅ 클라우드 네이티브 서비스와 완벽한 연동 ✅ 관리 부담이 적고 자동 확장 지원 ✅ 높은 안정성과 글로벌 네트워크 활용 가능 | ❌ 특정 클라우드 벤더 종속성이 강함 ❌ 비용이 높을 수 있음 |
Ingress Controller는 사용 중인 클라우드 환경이나 요구 사항에 따라 기능이 달라질 수 있으므로, 적절한 컨트롤러를 선택해야 한다.
5. Ingress와 Service의 관계
Ingress 요청을 처리하기 위해 연결되는 Kubernetes Service는 보통 클라우드 환경에서는 LoadBalancer 타입을 사용한다.
그러나 Private Cloud 환경에서는 Ingress를 직접 구축해야 하며, 아래와 같은 Service 타입을 사용할 수 있다.
NodePort: 각 노드의 특정 포트를 통해 접근ExternalIP: 특정 노드에 외부 IP를 부여하여 접근 가능MetalLB: 온프레미스 환경에서 LoadBalancer 기능을 제공하는 오픈소스 솔루션
6. 실무에서 Ingress를 사용하는 이유
기본적으로 Kubernetes 클러스터에서 외부 접근을 허용하려면, Service를 NodePort 타입으로 생성해야 한다.
이 경우 워커 노드의 IP:PORT로 직접 접근해야 하는데, Ingress를 사용하면 단일 도메인을 통한 요청 관리가 가능해진다.
Ingress 사용 시 장점
- 단일 지점에서 트래픽을 관리 (단순화된 네트워크 구성)
- 도메인 및 경로 기반 라우팅 지원
- SSL/TLS 인증서 관리 가능
- 클라우드 네이티브 환경에서 최적화된 트래픽 제어
이러한 이유로 실제 운영 환경에서는 Ingress를 주로 사용하며, Kubernetes 서비스의 표준적인 외부 노출 방식으로 자리 잡고 있다.
7. Node Port vs Ingress
-
Node Port
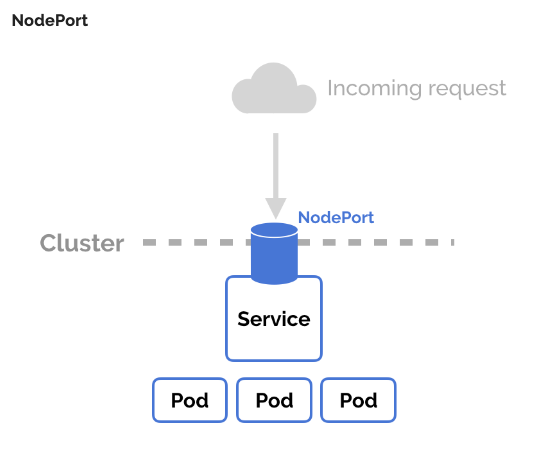
Worker Node에 대한 서버 IP와Node Port를 통해 연결된 서비스에 요청을 보내 해당Service에Selector로 연결된Pod로 라우팅한다. -
Ingress
 사전에 선언적으로 생성한
사전에 선언적으로 생성한 Ingress 규칙을 적용한nginx-ingress-controller의 서비스가 모든 요청을 받아host와endpoint를 통해 요청을 라우팅하여 각각 맞는 서비스에 연결지어 준다.
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.12.0/deploy/static/provider/cloud/deploy.yaml현 상황에서 Kubernetes와의 높은 호환성을 지닌 ingress-nginx를 선택하고 사용하였다.
현재 최신 릴리즈 버전은 v1.12.0이지만 시간이 지났을 경우 아래 링크에서 확인할 수 있다.
https://github.com/kubernetes/ingress-nginx/releases/tag/controller-v1.12.0
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: wwwm-spring-be-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: wwwm-spring-be.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: wwwm-spring-be-service
port:
number: 8080이후 위와 같이 Ingress 리소스를 생성해주었다.
해당 리소스는 Kubernetes에서 Nginx Ingress Controller를 이용해 외부 트래픽을 spring-be-service로 라우팅할 수 있도록 설정하였다.
-
annotations → nginx.ingress.kubernetes.io/rewrite-target: /- 경로 rewrite 설정
- 클라이언트가 특정 경로(
/api/test등)로 요청하더라도 백엔드에서는/로 처리됨
wwwm-spring-be.example.com/api/test 요청 → wwwm-spring-be-service:8080/로 전달 -
rules→ Ingress가 처리할 규칙을 정의host: wwwm-spring-be.example.com→ 해당 도메인(wwwm-spring-be.example.com)으로 들어오는 요청을 이Ingress가 처리http.paths→ HTTP 요청을 어떤 backend service로 보낼지 설정path: /→ 루트 경로 (/)에 대한 요청을 처리pathType: Prefix→ 경로가/로 시작하는 모든 요청을 처리 (/api,/users등 포함)backend.service:name: wwwm-spring-be-service→ 백엔드 서비스 이름port.number: 8080→ 백엔드 서비스의 포트
kubectl apply -f wwwm-spring-ingress.yaml이후 위 명령어를 통해 정의한 Ingress 생성해줄 수 있다.
Trouble Shooting: failed calling webhook "validate.nginx.ingress.kubernetes.io"
Error from server (InternalError): error when creating "wwwm-spring-ingress.yaml": Internal error occurred: failed calling webhook "validate.nginx.ingress.kubernetes.io": failed to call webhook: Post "https://ingress-nginx-controller-admission.ingress-nginx.svc:443/networking/v1/ingresses?timeout=10s": context deadline exceeded하지만 이를 적용하고자 할 때 위와 같은 오류가 발생하여
$ kubectl get pods -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-pxxqz 0/1 Completed 0 7m5s
ingress-nginx-admission-patch-tj4fv 0/1 Completed 0 7m5s
ingress-nginx-controller-d8c96cf68-spfkr 1/1 Running 0 7m5s우선 ingress-nginx 네임스페이스의 Pod들을 확인해주었다.
$ kubectl logs -n ingress-nginx -l app.kubernetes.io/name=ingress-nginx | grep err
{"err":"secrets \"ingress-nginx-admission\" not found","level":"info","msg":"no secret found","source":"k8s/k8s.go:229","time":"2025-02-22T04:46:15Z"}또한 ingress-nginx-controller의 로그를 확인할 결과 이 문제는 Ingress Controller의 admission webhook이 사용할 TLS 인증서(ingress-nginx-admission Secret)가 존재하지 않아서 발생했을 것이라 판단하였으나
$ kubectl get secrets -n ingress-nginx | grep ingress-nginx-admission
ingress-nginx-admission Opaque 3 9m45singress-nginx-admission Secret이 존재하는지 확인하고
$ kubectl get ValidatingWebhookConfiguration | grep ingress-nginx-admission
ingress-nginx-admission 1 11mIngress Controller가 Webhook을 사용하기 때문에, Webhook 설정이 제대로 적용되었는지 확인한 뒤
kubectl rollout restart deployment ingress-nginx-controller -n ingress-nginxWebhook을 다시 활성화하기 위해 Ingress Controller를 재배포하였지만 여전히 문제가 해결되지 않았다.
$ kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.107.164.176 <pending> 80:32459/TCP,443:32131/TCP 17m
ingress-nginx-controller-admission ClusterIP 10.106.8.118 <none> 443/TCP 17m
$ kubectl get endpoints -n ingress-nginx
NAME ENDPOINTS AGE
ingress-nginx-controller 10.244.2.8:443,10.244.2.8:80 17m
ingress-nginx-controller-admission 10.244.2.8:8443 17m또한 ingress-nginx-controller-admission 서비스도도 정상적으로 생성되었으며 엔드포인트도 정상적으로 연결된 것을 확인한 뒤
$ kubectl edit validatingwebhookconfigurations ingress-nginx-admission
...
service:
name: ingress-nginx-controller-admission
namespace: ingress-nginx
path: /networking/v1/ingresses
port: 443
failurePolicy: Ignore임시로 Ingress Webhook의 failurePolicy를 Fail에서 Ignore로 변경하여 문제를 우회하였으며
kubectl rollout restart deployment ingress-nginx-controller -n ingress-nginx
kubectl delete pod -n ingress-nginx -l app.kubernetes.io/name=ingress-nginxIngress Controller Pod에 변경사항을 반영하기 위해 재시작한 이후
$ kubectl apply -f wwwm-spring-ingress.yaml
ingress.networking.k8s.io/wwwm-spring-be-ingress created
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
wwwm-spring-be-ingress <none> wwwm-spring-be.example.com 80 55s위와 같이 정상적으로 wwwm-spring-be-ingress가 생성되는 것을 확인할 수 있었다.
MetalLB Configuration
1. OpenStack에서 LoadBalancer 타입 서비스의 문제점
$ kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.107.164.176 <pending> 80:32459/TCP,443:32131/TCP 78m
ingress-nginx-controller-admission ClusterIP 10.106.8.118 <none> 443/TCP 78mOpenStack 환경에서는 클라우드 제공자가 자동으로 외부 IP를 할당해주지 않기 때문에, LoadBalancer 타입 서비스의 외부 IP가 pending 상태로 남을 수 있다.
2. MetalLB 개요
MetalLB는 온프레미스 환경에서 Kubernetes의 Service(LoadBalancer 타입)를 지원하는 솔루션이다.
External IP를 전파하기 위해 ARP(IPv4)/NDP(IPv6), BGP를 사용하며, DaemonSet으로 동작하는 Speaker Pod를 통해 External IP를 관리한다.
일반적인 로드 밸런서와 마찬가지로 동일한 애플리케이션의 다수 Pod를 부하 분산할 수 있도록 지원한다.
MetalLB의 주요 기능L2 (Layer 2) 모드: ARP/GARP를 이용한 External IP 전파BGP (Border Gateway Protocol) 모드: L3 스위치를 통해 BGP 네이버 관계를 맺고 External IP를 전파Ingress Controller와의 연계: Ingress Controller 앞단에 배치하여 외부 트래픽을 효과적으로 라우팅
3. MetalLB 동작 방식
3.1 MetalLB L2 모드
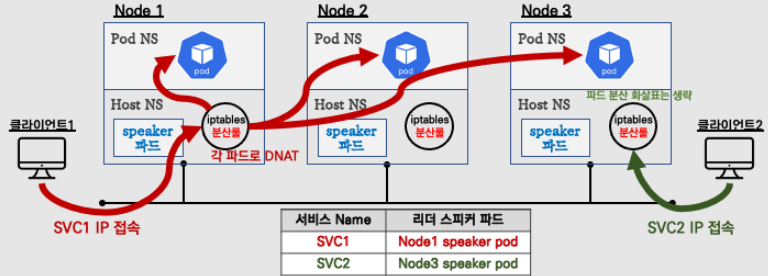
- Speaker Pod 중 1개가 리더로 선출됨
- 리더는 ARP(GARP, Gratuitous ARP)를 이용하여 External IP를 광고
iptables을 이용해 트래픽을 내부 노드로 전달
(+) L2 모드는 추가적인 네트워크 라우팅 설정이 필요하지 않아 설정이 간단한 것이 장점
(-) 하지만 동일 서브넷 내에서만 동작할 수 있는 제한이 있음
3.2 MetalLB BGP 모드
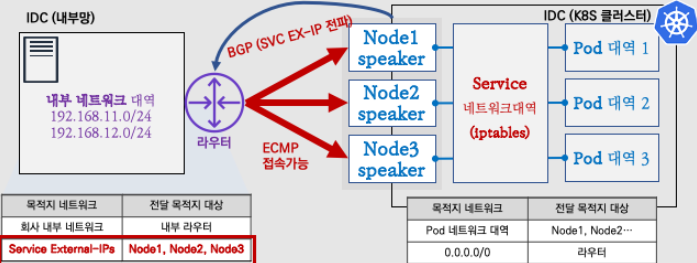
- 서버 상단에 있는 L3 스위치와 Speaker Pod이 BGP Neighbor를 맺음
- 서비스 External IP를 32비트 단위로 광고 (Network Summary 가능)
- 데이터센터 네트워크 장비의 설정을 통해 BGP Community 및 LocalPref 설정 가능
(+) BGP 모드는 대규모 네트워크 환경에서 적합하며, 여러 네트워크 대역을 통합하여 사용 가능
(-) 그러나 L3 네트워크 장비 설정이 필요하며, 운영 난이도가 높을 수 있음
4. MetalLB와 Ingress 연계
4.1 Ingress Controller Front-End 배치

- Ingress Controller를
NodePort타입 대신MetalLB 기반 LoadBalancer로 배치하는 것을 권장 NodePort보다 더 안정적인 서비스 제공 가능- 트래픽을 Kubernetes 내부 서비스로 라우팅
(+) MetalLB 방식이 Kubernetes 네트워크 설계에서 더 확장성이 높고 유지보수 용이
4.2 Ingress Controller Back-End 배치
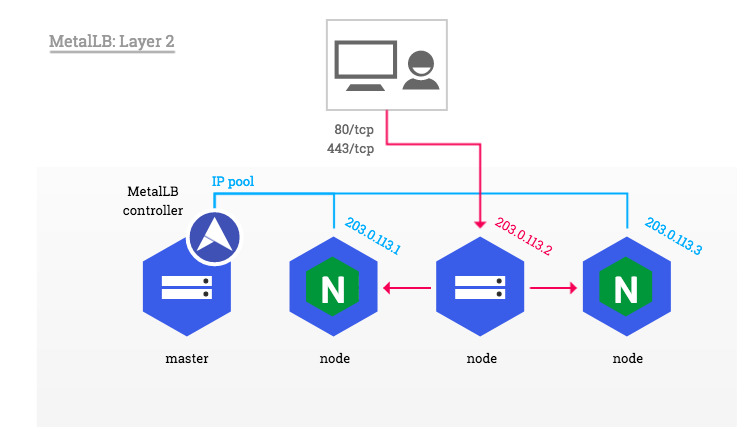
Ingress Controller에서 들어오는 트래픽을 MetalLB를 통해 전달하는 방법도 가능하다.
이 경우 다양한 접근 방식이 존재할 수 있다.
- MetalLB를 통한 직접 전달
- Host Network를 활용한 접근
- Self-Provisioned Edge 방식을 활용한 직접 라우팅
- External IPs 방식 활용
이러한 다양한 배포 방식 중 환경에 맞는 최적의 방법을 선택하면 된다.
5. 결론
결론적으로 아래와 같은 특징들에 의거하여 MetalLB를를 현 클러스터에 적용하는 것이 이상적일 것이라 판단하였다.
- OpenStack 환경에서는 기본적으로 LoadBalancer 서비스의 외부 IP가 할당되지 않음
- MetalLB는 온프레미스 환경에서 LoadBalancer 타입 서비스를 가능하게 하는 필수 솔루션
- L2 모드와 BGP 모드 중 네트워크 환경에 맞는 방식을 선택
- Ingress Controller와 MetalLB를 함께 활용하여 트래픽을 안정적으로 처리 가능
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.14.9/config/manifests/metallb-native.yaml우선 위와 같이 최신 버전인 v0.14.9를 현재 클러스터에 적용하고
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: wwwm-spring-be-ip-pool
namespace: metallb-system
spec:
addresses:
- 192.168.100.230-192.168.100.250
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: wwwm-spring-be-advertisement
namespace: metallb-system
spec:
ipAddressPools:
- wwwm-spring-be-ip-pool위와 같이 IPAddressPool, L2Advertisement 리소스를 생성한다.
-
addresses:→ MetalLB가 할당할 수 있는 IP 주소 범위를 지정192.168.100.230-192.168.100.250→ 이 범위 내에서 LoadBalancer 타입 서비스에External IP를 할당- IP 범위는 OpenStack 네트워크 내에서 외부 접근이 가능한 유효한 범위로 변경해야 한다
-
ipAddressPools:wwwm-spring-be-ip-pool→ 위에서 정의한 IP 풀을 사용하여MetalLB가External IP를 배포하도록 지정
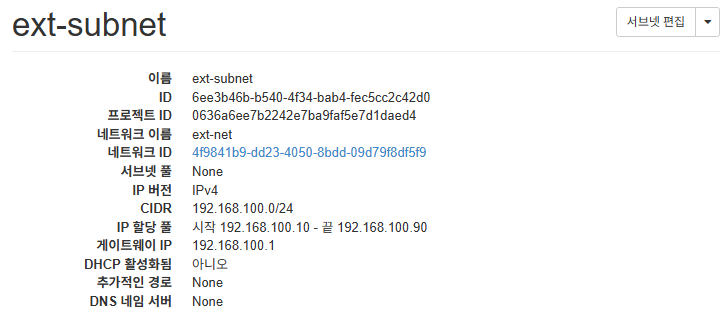 IPAddressPool
IPAddressPool의 경우 위와 같이 현재 Openstack의 Node 및 ext-net의 서브넷 모두 192.168.100.0/24대역을 활용하고 있기에, 같은 내역 내에서 겹치지 않도록192.168.100.230-192.168.100.250`를 할당하였다.
Trouble Shooting: failed to call webhook: Post "https://metallb-webhook-service.metallb-system.svc:443/validate-metallb-io-v1beta1-ipaddresspool?timeout=10s"
$ kubectl apply -f metallb-config.yaml
Error from server (InternalError): error when creating "metallb-config.yaml": Internal error occurred: failed calling webhook "ipaddresspoolvalidationwebhook.metallb.io": failed to call webhook: Post "https://metallb-webhook-service.metallb-system.svc:443/validate-metallb-io-v1beta1-ipaddresspool?timeout=10s": dial tcp 10.105.69.166:443: connect: connection refused하지만 해당 metallb-config.yaml를 적용하려고 하였을 때 이전과 동일하게 webhook과 관련된 오류가 발생하여, 우회하지 않고 문제를 파악하고자 하였다.
$ kubectl describe pod controller-bb5f47665-wqsrk -n metallb-system
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 6m23s default-scheduler 0/3 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }, 2 node(s) had untolerated taint {node.kubernetes.io/unreachable: }. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling.
Warning FailedCreatePodSandBox 3m7s kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to create pod network sandbox k8s_controller-bb5f47665-wqsrk_metallb-system_496fa70d-1ecc-45a7-8266-7a5592e4b08e_0(4138f56557d2d50df1f5e78f60d331ff8cb165f693148cf1ec3f1e91751dbaaf): error adding pod metallb-system_controller-bb5f47665-wqsrk to CNI network "cbr0": plugin type="flannel" failed (add): loadFlannelSubnetEnv failed: open /run/flannel/subnet.env: no such file or directory
Normal Scheduled 3m7s default-scheduler Successfully assigned metallb-system/controller-bb5f47665-wqsrk to k8s-worker-2.novalocal
Normal Pulled 84s (x5 over 2m54s) kubelet Container image "quay.io/metallb/controller:v0.14.9" already present on machine
Normal Created 84s (x5 over 2m53s) kubelet Created container: controller
Normal Started 84s (x5 over 2m53s) kubelet Started container controller
Warning BackOff 10s (x19 over 2m52s) kubelet Back-off restarting failed container controller in pod controller-bb5f47665-wqsrk_metallb-system(496fa70d-1ecc-45a7-8266-7a5592e4b08e)우선 metallb-system의 controller pod의 로그를 살펴보고 위와 같이 flannel에 관한 오류를 확인할 수 있었는데
$ kubectl auth can-i list services --as=system:serviceaccount:metallb-system:controller -n metallb-system
yesMetalLB가 Kubernetes API에 접근할 수 없으면 Crash가 발생할 수 있기에 위와 같이 controller pod의 권한이 정상적으로 있는지 확인해주고
kubectl delete pod -n metallb-system --selector=app=metallb,component=controllerPod를 삭제하여, Kubernetes가 자동으로 다시 생성할 수 있도록 하여 flannel에 관한 오류는 해결하였다. 이는 아직 Clutser 내에서 Flannel 관련 설정이 올라오지 않았어서 발생한 문제임을 확인할 수 있었다.
$ kubectl run debug --rm -it --image=busybox -- /bin/sh
/ # wget --no-check-certificate https://metallb-webhook-service.metallb-system.svc:443/validate-metallb-io-v1beta1-ipaddresspool?timeout=10s
wget: bad address 'metallb-webhook-service.metallb-system.svc:443'하지만 여전히 webhook과 관련된 오류는 해결되지 않아 클러스터 내부에서 실제로 metallb-webhook 서비스에 연결할 수 있는지 테스트해보았다.
이를 통해 네임스페이스 간 DNS 해석 및 포트 접근이 정상적으로 이루어지지 않음을 확인할 수 있었고
/ # cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local openstacklocal novalocal
nameserver 10.96.0.10
options ndots:5테스트 pod 내에서 cat /etc/resolv.conf를 확인하였다.
문제가 없음에도 불구하고 DNS가 제대로 작동하지 않는다는 것은 MetalLB Webhook 서비스의 FQDN도 해석되지 않고 클러스터의 DNS 서버(10.96.0.10, CoreDNS)와의 통신이 불가능하다는 가능성을 시사한 것이므로
$ kubectl get svc -n kube-system kube-dns
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 2dCoreDNS가 정상적으로 실행 중인지 확인하였다.
[root@master k8s]# kubectl logs -n kube-system coredns-668d6bf9bc-bd9nk
.:53
[INFO] plugin/reload: Running configuration SHA512 = 1b226df79860026c6a52e67daa10d7f0d57ec5b023288ec00c5e05f93523c894564e15b91770d3a07ae1cfbe861d15b37d4a0027e69c546ab112970993a3b03b
CoreDNS-1.11.3
linux/amd64, go1.21.11, a6338e9
[root@master k8s]# kubectl logs -n kube-system coredns-668d6bf9bc-ks9rr
.:53
[INFO] plugin/reload: Running configuration SHA512 = 1b226df79860026c6a52e67daa10d7f0d57ec5b023288ec00c5e05f93523c894564e15b91770d3a07ae1cfbe861d15b37d4a0027e69c546ab112970993a3b03b
CoreDNS-1.11.3
linux/amd64, go1.21.11, a6338e9또한 각 CoreDNS Pod의 로그를 확인하여 오류 메시지나 CrashLoopBackOff 상태가 있는지 확인해주었다.
$ kubectl -n kube-system get configmap coredns -o yaml
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30 {
disable success cluster.local
disable denial cluster.local
}
loop
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: "2025-02-20T07:39:17Z"
name: coredns
namespace: kube-system
resourceVersion: "218"
uid: 5bf1e890-cfc1-47bb-a19e-1031af60a73a더 나아가 coredns의 ConfigMap을 확인해주었다.
CoreDNS의 설정과 로그는 이상이 없어 보이며, 다른 클러스터 도메인(ex. kubernetes.default.svc.cluster.local)은 정상적으로 해석되는 것으로 가정할 수 있었다.
metallb-webhook-service.metallb-system.svc가 DNS에서 조회되지 않는 것이라 판단할 수 있었고 이는 기본적으로 MetalLB Webhook 서비스를 구성하는 Service 리소스가 생성되지 않았거나, 등록되지 않은 상태를 의미하여
[root@master k8s]# kubectl get svc -n metallb-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
metallb-webhook-service ClusterIP 10.105.69.166 <none> 443/TCP 58m
[root@master k8s]# kubectl get endpoints -n metallb-system metallb-webhook-service
NAME ENDPOINTS AGE
metallb-webhook-service 10.244.1.4:9443 58metallb-webhook-service 서비스와 Endpoint 모두 이상이 없음을 확인한 뒤
$ kubectl get pods -n kube-system -l k8s-app=kube-proxy
NAME READY STATUS RESTARTS AGE
kube-proxy-fbrtw 1/1 Running 2 47h
kube-proxy-hg2xn 1/1 Running 1 2d
kube-proxy-wvxw7 1/1 Running 1 47hClusterIP 서비스의 라우팅을 담당하는 kube-proxy 또한 문제가 없음을 확인하였다.
$ kubectl run dns-debug --rm -it --image=alpine -- /bin/sh
/ # nslookup metallb-webhook-service.metallb-system.svc.cluster.local
;; connection timed out; no servers could be reached
/ # cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local openstacklocal novalocal
nameserver 10.96.0.10
options ndots:5또한 dns-debug Pod에서 DNS 요청이 10.96.0.10:53로 타임아웃 되어 클러스터 내부 네트워크(OpenStack 환경)에서 DNS 트래픽이 제대로 전달되지 않고 있음을 확인하였다.

따라서 OpenStack의 보안 그룹 설정을 재확인하여 UDP/TCP 53번 포트를 허용하고.
### dns-debug
/ # nslookup metallb-webhook-service.metallb-system.svc.cluster.local
Server: 10.96.0.10
Address: 10.96.0.10:53
Name: metallb-webhook-service.metallb-system.svc.cluster.local
Address: 10.105.69.166위와 같이 정상적으로 dns-debug Pod 내에서 metallb-webhook-service.metallb-system.svc.cluster.local를 조회할 수 있는 것을 확인한 뒤
$ kubectl apply -f metallb-config.yaml
ipaddresspool.metallb.io/wwwm-spring-be-ip-pool created
l2advertisement.metallb.io/wwwm-spring-be-advertisement createdmetallb 관련 리소스가 정상적으로 생성되고
$ kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
AGE
ingress-nginx-controller LoadBalancer 10.107.164.176 192.168.100.230 80:32459/TCP,443:32131/TCP 3h26m
ingress-nginx-controller-admission ClusterIP 10.106.8.118 <none> 443/TCP
3h26mingress-nginx-controller의 EXTERNAL-IP가 MetalLB에서 할당한 IP로 변경됨을 확인할 수 있었다.
더 나아가 이를 /etc/hosts에 등록하거나 DNS에 반영한다면 도메인(wwwm-spring-be.example.com)으로 접근할 수 있다.
Trouble Shooting: org.springframework.data.redis.RedisConnectionFailureException: Unable to connect to Redis
$ kubectl logs wwwm-spring-be-deployment-76fbc5d5f6-hxf79 -f
2025-02-22T08:14:36.657Z WARN 1 --- [WHEN-WILL-WE-MEET] [oundedElastic-1] o.s.b.a.d.r.RedisReactiveHealthIndicator : Redis health check failed
org.springframework.data.redis.RedisConnectionFailureException: Unable to connect to Redis
at org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory$ExceptionTranslatingConnectionProvider.translateException(LettuceConnectionFactory.java:1847) ~[spring-data-redis-3.3.2.jar!/:3.3.2]
...Pod까지 정상적으로 생성된 이후 위와 같이 RedisConnectionFailureException 오류가 발생하여
 현재 사용하지 않는
현재 사용하지 않는 redis에 대한 의존성을 제거해준 이후
$ kubectl get pod -w
NAME READY STATUS RESTARTS AGE
wwwm-spring-be-deployment-76fbc5d5f6-8bmzr 0/1 Running 0 40s
wwwm-spring-be-deployment-76fbc5d5f6-p4h5x 0/1 Running 0 40s
wwwm-spring-be-deployment-76fbc5d5f6-p4h5x 1/1 Running 0 48s
wwwm-spring-be-deployment-76fbc5d5f6-8bmzr 1/1 Running 0 49s모든 Pod들이 정상적으로 구동되는 것을 확인할 수 있었고
$ kubectl logs wwwm-spring-be-deployment-76fbc5d5f6-8bmzr
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v3.3.2)
...
2025-02-22T08:21:29.643Z INFO 1 --- [WHEN-WILL-WE-MEET] [ main] o.s.b.a.w.s.WelcomePageHandlerMapping : Adding welcome page template: index
2025-02-22T08:21:30.372Z INFO 1 --- [WHEN-WILL-WE-MEET] [ main] o.s.b.a.e.web.EndpointLinksResolver : Exposing 1 endpoint beneath base path '/actuator'
2025-02-22T08:21:31.870Z INFO 1 --- [WHEN-WILL-WE-MEET] [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8080 (http) with context path '/'
2025-02-22T08:21:31.942Z INFO 1 --- [WHEN-WILL-WE-MEET] [ main] o.e.w.WhenWillWeMeetApplication : Started WhenWillWeMeetApplication in 12.577 seconds (process running for 14.006)
2025-02-22T08:21:50.547Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'
2025-02-22T08:21:50.547Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
2025-02-22T08:21:50.549Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 2 ms로그를 통해 Spring BE 서버가 정상 구동중임을 확인할 수 있었다.
[root@master k8s]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
NOMINATED NODE READINESS GATES
wwwm-spring-be-deployment-76fbc5d5f6-8bmzr 1/1 Running 0 8m8s 10.244.2.25 k8s-worker-2.novalocal <none> <none>
wwwm-spring-be-deployment-76fbc5d5f6-p4h5x 1/1 Running 0 8m8s 10.244.1.6 k8s-worker-1.novalocal <none> <none>
[root@master k8s]# curl 10.244.2.25:8080
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Main Page</title>
<style>
body {
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
margin: 0;
}
img {
max-width: 100%;
max-height: 100%;
}
</style>
</head>
<body>
<img src="/images/logo.png" alt="Logo">
</body>
</html>
[root@master k8s]# kubectl logs wwwm-spring-be-deployment-76fbc5d5f6-8bmzr | tail -n 5
2025-02-22T08:21:50.549Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 2 ms
2025-02-22T08:29:05.064Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-5] o.e.w.controller.IndexController : [IndexController]-[index] Client IP: 10.244.0.0
2025-02-22T08:29:05.067Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-5] o.e.w.controller.IndexController : [IndexController]-[index] User-Agent: curl/7.76.1
2025-02-22T08:29:12.372Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-9] o.e.w.controller.IndexController : [IndexController]-[index] Client IP: 10.244.0.0
2025-02-22T08:29:12.373Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-9] o.e.w.controller.IndexController : [IndexController]-[index] User-Agent: curl/7.76.1또한 위와 같이 Internal IP인 10.244.2.25의 8080 포트로의 요청이 성공적으로 이루어지며 Pod의 로그 또한 정상 출력됨을 확인할 수 있었고
[root@master k8s]# curl -H "Host: wwwm-spring-be.example.com" http://192.168.100.230/
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Main Page</title>
<style>
body {
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
margin: 0;
}
img {
max-width: 100%;
max-height: 100%;
}
</style>
</head>
<body>
<img src="/images/logo.png" alt="Logo">
</body>
</html>위와 같이 Host 헤더를 지정해 Ingress Rule에 맞게 요청을 보내 Ingress가 올바른 서비스(wwwm-spring-be-service)로 요청을 라우팅하여 MetalLB에서 할당한 External IP를 통해서도 배포한 서버에 접근이 가능한 것을 확인할 수 있었다.
Host Machine Forwarding
[root@master k8s]# traceroute 192.168.100.230
traceroute to 192.168.100.230 (192.168.100.230), 30 hops max, 60 byte packets
1 _gateway (172.20.112.1) 3.044 ms 2.781 ms 2.662 ms
2 10.10.10.1 (10.10.10.1) 4.014 ms 3.910 ms 3.699 ms
3 10.10.10.1 (10.10.10.1) 3113.666 ms !H 3113.562 ms !H 3113.467 ms !H
[root@master k8s]# tcptraceroute 192.168.100.230 80
Running:
traceroute -T -O info -p 80 192.168.100.230
traceroute to 192.168.100.230 (192.168.100.230), 30 hops max, 60 byte packets
1 192.168.100.230 (192.168.100.230) 3.360 ms 3.254 ms 3.216 ms
2 192.168.100.230 (192.168.100.230) <syn,ack> 3.184 ms 3.157 ms 3.129 ms[root@kubernetes-host ~]# tcptraceroute 192.168.100.230 80
Running:
traceroute -T -O info -p 80 192.168.100.230
traceroute to 192.168.100.230 (192.168.100.230), 30 hops max, 60 byte packets
1 10.10.10.1 (10.10.10.1) 1.412 ms 1.367 ms 1.347 ms
2 10.10.10.1 (10.10.10.1) 3112.658 ms !H 3112.640 ms !H 3112.624 ms !H
[root@openstack-host ~]# tcptraceroute 192.168.100.230 80
Running:
traceroute -T -O info -p 80 192.168.100.230
traceroute to 192.168.100.230 (192.168.100.230), 30 hops max, 60 byte packets
1 openstack-host (192.168.100.1) 3095.683 ms !H 3095.570 ms !H 3095.521 ms !H하지만 현재의 구성으로는 192.168.100.230으로의 별도의 라우트가 존재하지 않고, 결국 Ingress로의 요청은 Flannel을 통해 이루어지기 때문에 위와 같이 연결이 정상적으로 이루어지지 않는다.
따라서, 192.168.100.0/24 대역을 지금처럼 유지해도 괜찮지만 추후 호스트 머신에서 K8s Cluster로 포워딩을 구성할 때 헷갈리지 않기 위해
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: wwwm-spring-be-ip-pool
namespace: metallb-system
spec:
addresses:
- 172.10.100.200-172.10.100.230
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: wwwm-spring-be-advertisement
namespace: metallb-system
spec:
ipAddressPools:
- wwwm-spring-be-ip-pool위와 같이 metallb의 L2Advertisement의 IPAddressPool을 172.10.100.200-172.10.100.230로 변경하였다.
[root@master k8s]# kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
wwwm-spring-be-ingress <none> wwwm-spring-be.com 172.10.100.200 80 88m
[root@master k8s]# curl -H "Host: wwwm-spring-be.com" http://172.10.100.200/
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Main Page</title>
<style>
body {
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
margin: 0;
}
img {
max-width: 100%;
max-height: 100%;
}
</style>
</head>
<body>
<img src="/images/logo.png" alt="Logo">
</body>
</html>curl -H "Host: wwwm-spring-be.com" http://172.10.100.200/를 통해 테스트가 가능하였다.
apiVersion: v1
kind: Service
metadata:
name: ingress-nginx-nodeport
namespace: ingress-nginx
spec:
type: NodePort
externalIPs:
- 172.20.112.101
selector:
app.kubernetes.io/name: ingress-nginx
ports:
- name: http
port: 80
targetPort: 80
nodePort: 30080
- name: https
port: 443
targetPort: 443
nodePort: 30443이후 기존 Ingress로 트래픽을 전달하도록 하는 별도의 NodePort Service를 생성한다.
해당 Service는 nginx-ingress-controller의 Pod들을 선택하여 클러스터 외부, 특히 172.20.112.0/24 대역에 있는 host)에서 접근할 수 있도록 한다.
외부에서 접근할 때는 클러스터 노드의 실제 IP(172.20.112.101)와 NodePort(30080, 30443)를 사용해야 한다.
-
Selector:
- 이
Service는app.kubernetes.io/name=ingress-nginx레이블을 가진Ingress ControllerPod들을 선택한다.
(실제Ingress ControllerPod들의label이 이와 일치해야 한다)
- 이
-
NodePort:
- 클러스터의 각 노드에서 지정한
NodePort를 통해 접근할 수 있습니다. 172.20.112.0/24대역에 있는K8s Host에서는Node의 IP와 이NodePort번호를 사용해 접속하면,Ingress Controller로 트래픽이 전달되어Ingress규칙에 따라backend 서비스로 포워딩된다.
- 클러스터의 각 노드에서 지정한
[root@master k8s]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.20.202 172.10.100.200 80:30526/TCP,443:32286/TCP 93m
ingress-nginx-controller-admission ClusterIP 10.106.8.118 <none> 443/TCP 3d3h
ingress-nginx-nodeport NodePort 10.110.140.108 172.20.112.101 80:30080/TCP,443:30443/TCP 8s 이후 ingress-nginx-nodeport NodePort서비스에 대해 EXTERNAL-IP에 172.20.112.101가 할당된 것을 볼 수 있었고
[root@kubernetes-host ~]# curl -H "Host: wwwm-spring-be.com" http://172.20.112.101/
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Main Page</title>
...kubernetes-host에서 http://172.20.112.101/로의 요청이 정상적으로 이루어진 것을 확인하였다.
K8s Host Port Forwarding
### kubernetes-host
sudo dnf install -y nginx
sudo systemctl enable nginx --now이후 kubernetes-host에서 nginx를 설치하고
 외부 브라우저에서 해당
외부 브라우저에서 해당 kubernetes-host로의 HTTP 접근이 정상적으로 이루어지는지 확인한다.
server {
listen 8080;
server_name _;
# 모든 경로에 대해 proxy 처리
location / {
# proxy 대상: 172.20.112.101의 포트 80
proxy_pass http://172.20.112.101;
# 원본 Host 헤더를 wwwm-spring-be.com으로 유지 (Ingress에서 호스트 매칭을 위해)
proxy_set_header Host wwwm-spring-be.com;
# 클라이언트의 실제 IP 정보를 전달
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}이후 wwwm-spring-be.com 도메인에 대한 외부 요청을 받아 172.20.112.101로 proxy하는 서버를 위와 같이 생성하고 /etc/nginx/conf.d/k8s-ingress-proxy.conf로 저장한다.
nginx -t && systemctl reload nginxnginx를 테스트한 이후 reload하여 새로운 프록시 서버를 적용하고
setsebool -P httpd_can_network_connect 1SELinux가 활성화되어 있다면, Nginx가 외부 네트워크로 연결할 수 있도록 위 명령어를 실행해 SELinux에서 httpd가 네트워크 연결을 할 수 있도록 설정하면
 최종적으로 K8s Cluster에서 배포되고 있는 BE 서버를 정상적으로 확인할 수 있다.
최종적으로 K8s Cluster에서 배포되고 있는 BE 서버를 정상적으로 확인할 수 있다.
Summary
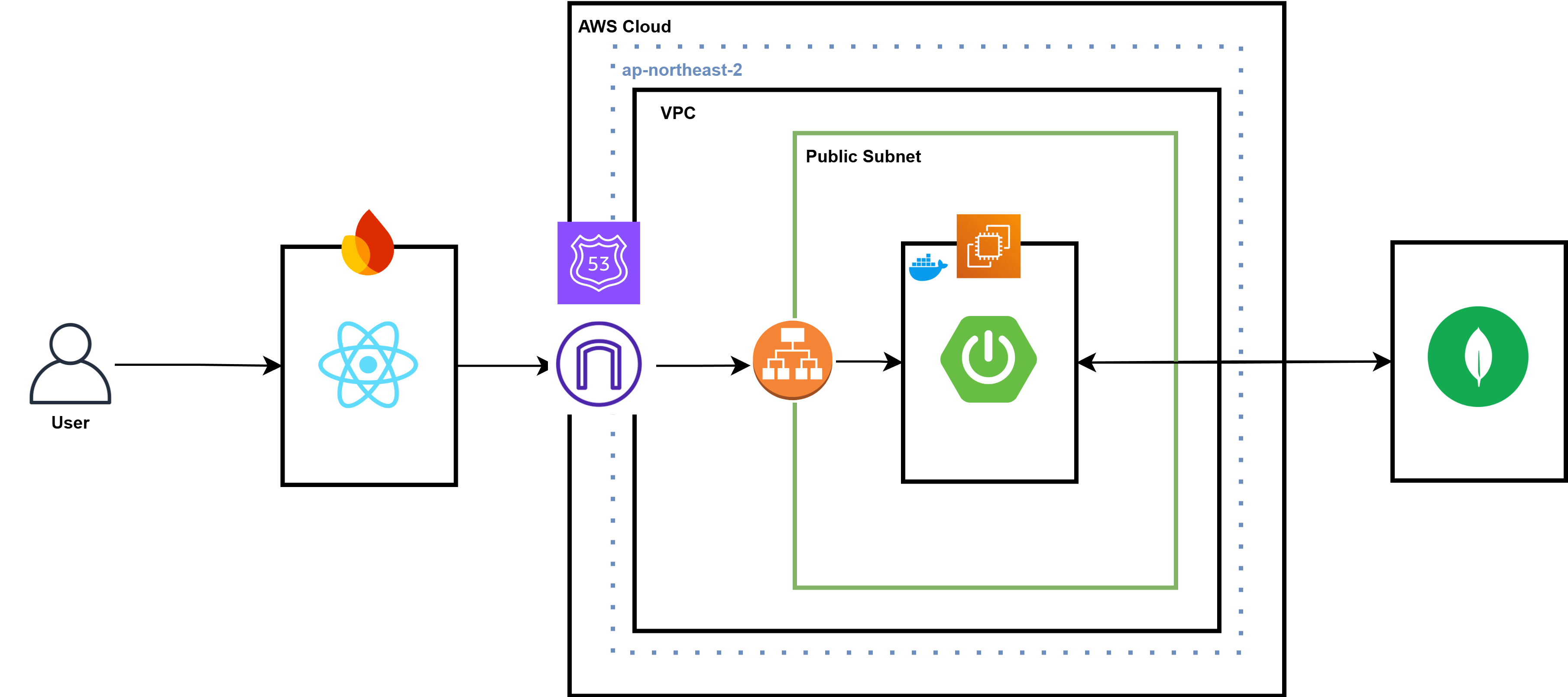
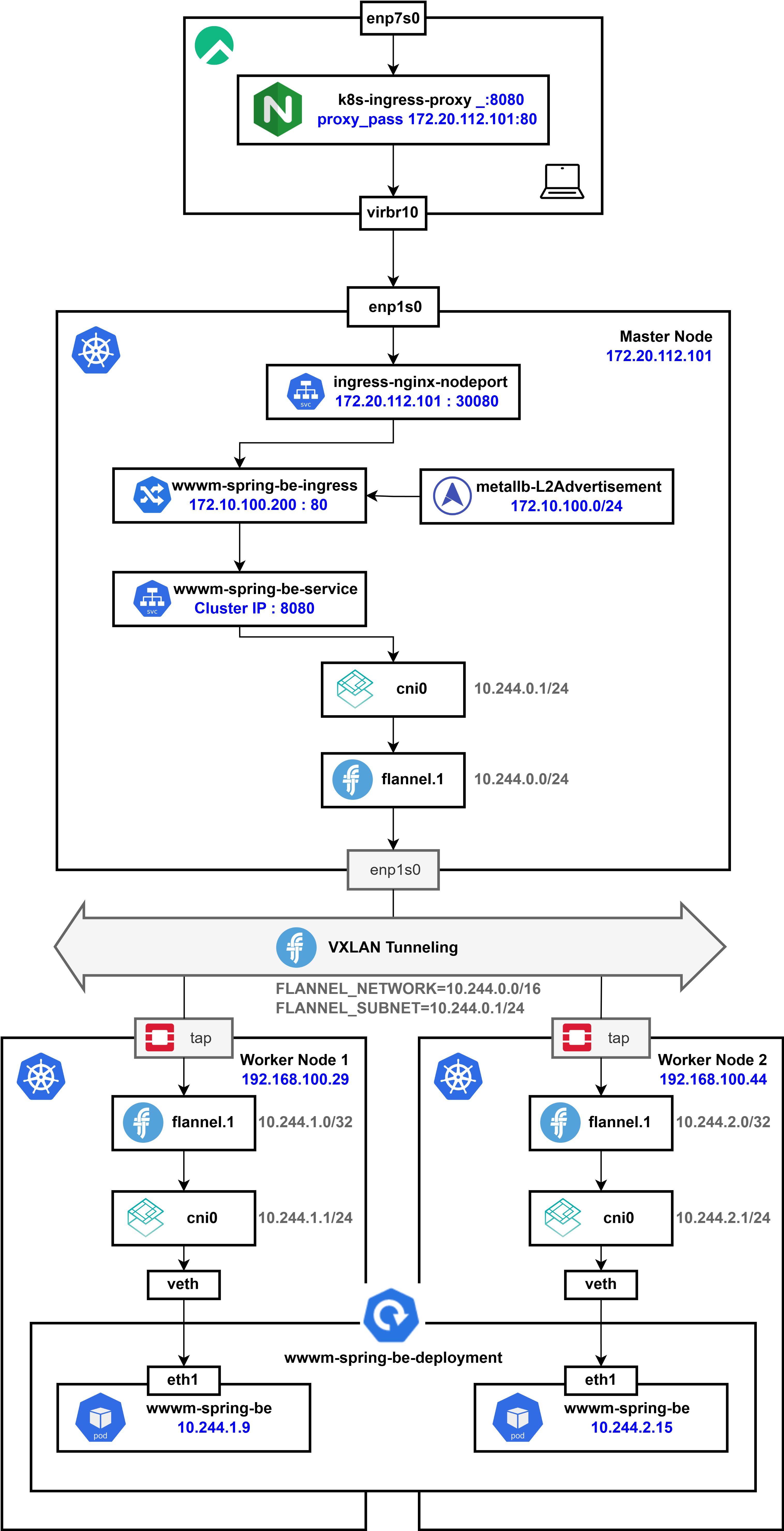 현재 클러스터의 최종적인 네트워크 아키텍처는 위와 같다.
현재 클러스터의 최종적인 네트워크 아키텍처는 위와 같다.
Flannel VXLAN Pod Network
Kubernetes에서 각 Worker Node는 Flannel을 통해 고유한 Pod 서브넷을 할당받는다.
이전에 Flannel을 설치할 때 정의한 FLANNEL_NETWORK=10.244.0.0/16이 IP 대역으로 설정되며, 각 Node는 /24 크기의 서브넷을 자동으로 할당받는다.
Pod 간 통신은 VXLAN Tunnel을 통해 이루어지는데 Flannel은 flannel.1 인터페이스를 생성하여 각 Node 간 가상의 L2 네트워크를 형성하고, 이 인터페이스를 통해 Pod 네트워크를 연결한다.
ClusterIP, kube-proxy
Kubernetes에서 Service는 Pod을 대상으로 하는 추상적인 네트워크 레이어를 제공한다.
ClusterIP는 Kubernetes가 자동으로 할당하는 가상의 IP이며, 실제 Pod IP와는 별개로 관리된다.
ClusterIP는 Kubernetes API 서버에서 --service-cluster-ip-range 플래그로 설정된 범위 내에서 kube-controller-manager가 자동으로 할당한다.
일반적으로 기본 CIDR 범위는 10.96.0.0/12이며, 서비스가 생성될 때마다 사용 가능한 IP 중 하나가 배정된다.
클라이언트가 ClusterIP로 요청을 보내면, kube-proxy가 해당 트래픽을 적절한 Pod으로 라우팅한다. 이는 iptables 또는 IPVS를 사용하여 요청을 적절한 Node의 Pod IP로 변환하는 방식으로 동작하며, 결국 Flannel VXLAN을 통해 해당 Pod으로 트래픽이 전달된다.
Ingress, MetalLB를 이용한 External Traffic 처리
Ingress Controller는 외부에서 유입된 HTTP/HTTPS 트래픽을 Kubernetes 내부 서비스로 전달하는 역할을 하며 기본적으로 Ingress는 NodePort 또는 LoadBalancer 타입의 Service를 통해 클러스터 외부와 연결된다.
MetalLB는 클러스터 외부에서 접근할 수 있도록 LoadBalancer IP를 할당해주는 역할을 수행한다. 이를 통해 내부 서비스에 공인 IP 또는 사설 IP를 부여할 수 있으며, L2 또는 BGP 모드를 통해 노드 간 로드밸런싱을 지원한다.
Ingress를 통해 외부 트래픽이 유입되면, Nginx Reverse Proxy가 해당 요청을 Ingress Controller로 전달하고, 이후 적절한 ClusterIP 서비스로 트래픽이 전달된다.
최종적으로 Flannel VXLAN을 통해 해당 요청이 적절한 Worker Node의 Pod으로 도달하게 된다.
