
Architecture Design
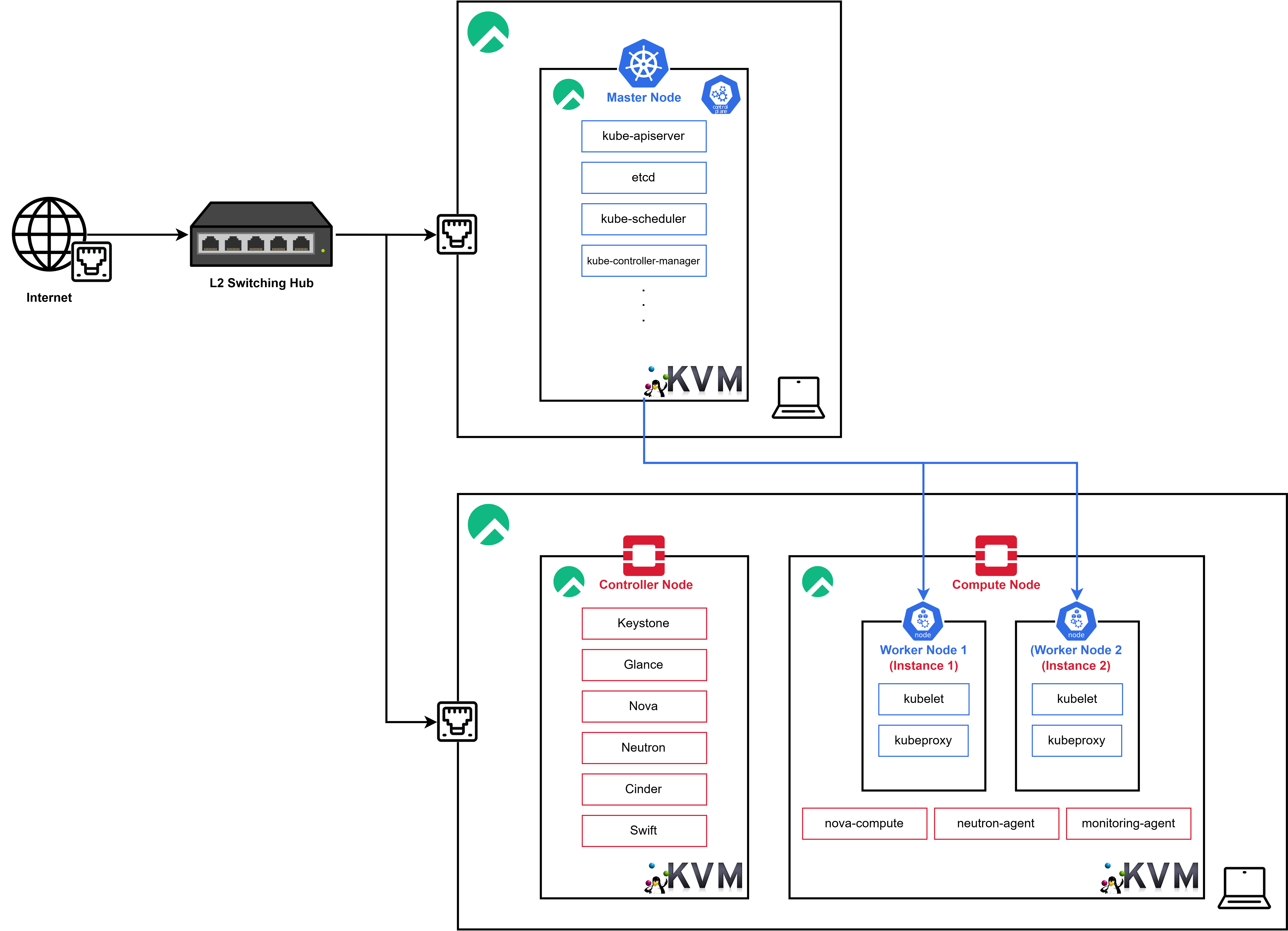 이전의 포스팅에서 위와 같은 아키텍처 디자인의 인프라를 구성하기 위해
이전의 포스팅에서 위와 같은 아키텍처 디자인의 인프라를 구성하기 위해 Opentack Controller Node와 Compute Node의 구성을 마쳤다.
따라서 현재 Swithching Hub를 통해 연결된 별도의 물리 컴퓨터에 Kubernetes Master Node를 구성하고 Openstack을 통해 2개의 Woker Node 인스턴스를 생성한 이후 해당 Kubernetes Clustering이 가능하도록 구성할 계획이다.
즉, 최종적으로 Openstack이 Kubernetes의 Orchestration을 위한 컴퓨팅 리소스를 제공하는 형태이다.
L3 Network Configuration
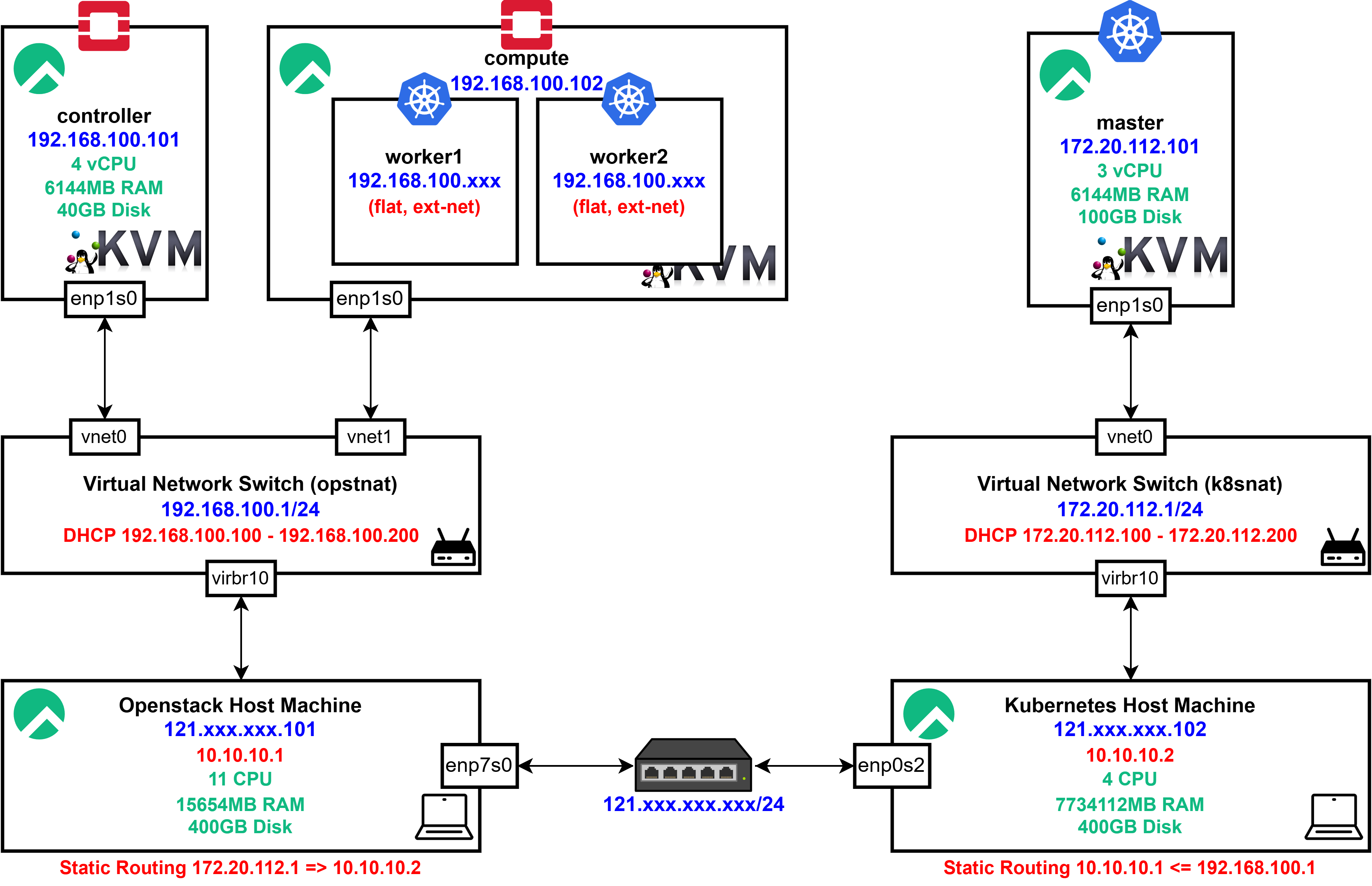 위 이미지는 최종적으로 구현하고자 하는 L2 Network Design이다.
위 이미지는 최종적으로 구현하고자 하는 L2 Network Design이다.
하지만 현재 OpenStack Node들이 구동되고 있는 KVM은 virsh NAT 네트워크를 사용하므로 이전의 네트워크에서 K8s Control Plane과 직접적인 통신이 불가능하다.
즉, 각 KVM에서 외부로는 통신이 가능하지만 외부에서 VM으로의 직접적인 접근이 불가능하다.
Possible Scenarioes
따라서 네트워크를 구성하기 이전 아래와 같은 가능한 시나리오들을 정리하였다.
GRE Tunnel

GRE(Generic Routing Encapsulation)은 IP 패킷을 다른 IP 패킷 안에 encapsulation하여 전송하는 터널링 프로토콜이다.
즉, 서로 다른 네트워크에 있는 호스트 간에 가상의 P2P 연결을 생성해서 데이터를 주고받을 수 있도록 한다.
이를 통해 서로 다른 서브넷 간 통신이 가능하며 서로 다른 호스트 A와 호스트 B가 마치 같은 네트워크에 있는 것처럼 동작한다.
-
주요 특징
L3 터널링 프로토콜: IPv4, IPv6, MPLS 등 다양한 프로토콜을 캡슐화 가능라우팅 가능: 터널을 통해서 서로 다른 네트워크 간에 직접 라우팅 가능IPsec과 함께 사용 가능: 보안이 필요한 경우 IPsec과 결합하여 암호화 가능오버헤드 발생: GRE 헤더(4바이트) + IP 헤더(20바이트) 추가됨
-
예상 네트워킹 시나리오
- VM1 (10.0.0.x) → GRE 터널 → VM2 (192.168.0.x)
- 호스트 A (192.168.1.10) → VM1 (10.0.0.100)
- 호스트 B (192.168.1.20) → VM2 (192.168.0.100)
- 호스트 A와 B는 물리적 네트워크(LAN)로 연결됨
- GRE 터널을 사용하여 10.10.10.x 대역의 가상 네트워크 연결 생성
하지만 위 방식은 설정이 복잡하고 현재 Openstack 서비스들이 virsh NAT Network에서 제공받은 고정 IP를 통해 작동하도록 설정되어 있기 때문에 선택하지 않았다.
Bridge Network
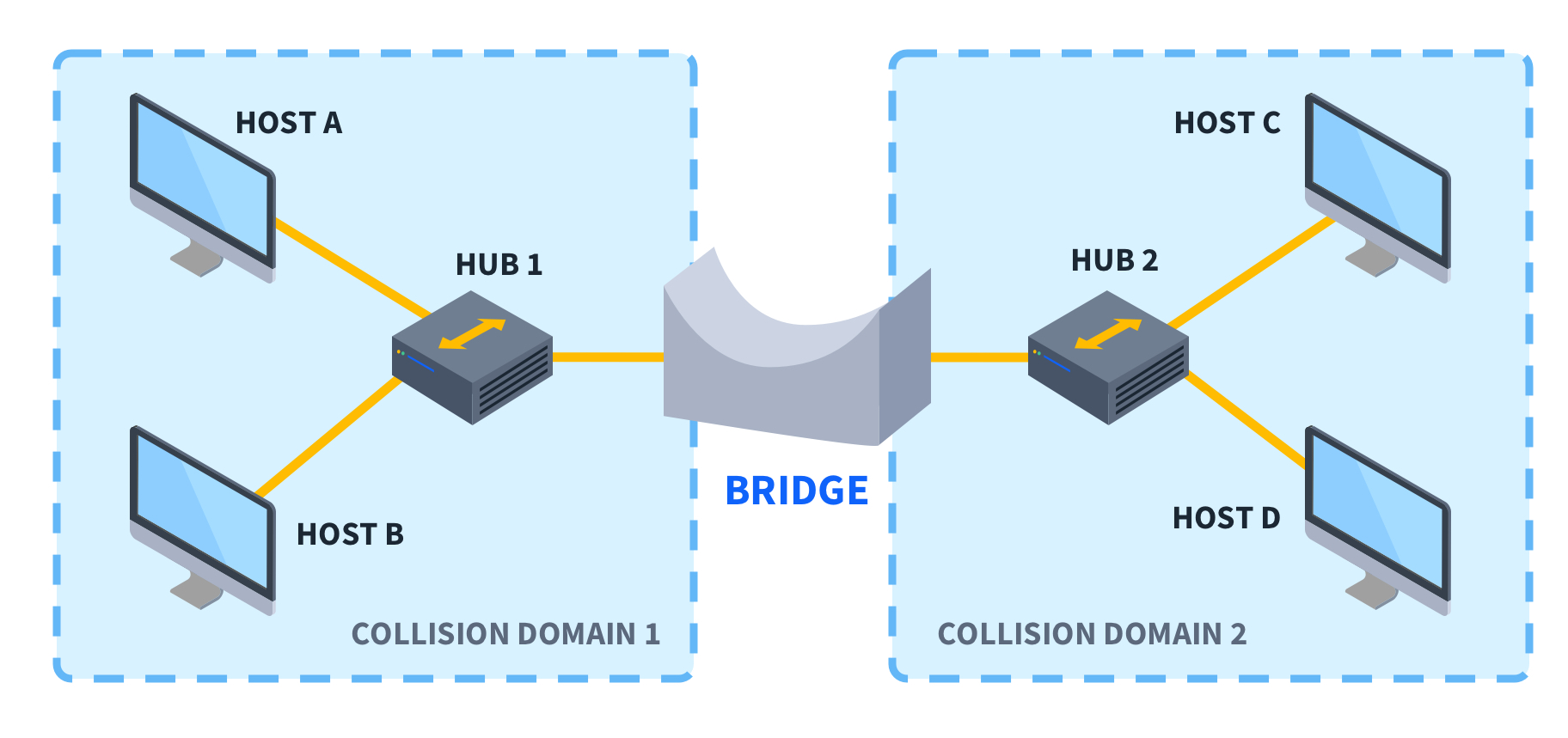
Bridge Network는 두 개 이상의 네트워크 인터페이스를 하나의 Bridge Interface로 묶어 동일한 네트워크 세그먼트처럼 동작하도록 만드는 방식이다.
Bridge는 물리적 Network Switch처럼 작동하며, 같은 브로드캐스트 도메인 내에서 트래픽을 전달할 수 있고 MAC 주소를 기반으로 프레임을 전달한다.
NAT는 프라이빗 네트워크(ex. 10.0.0.0/24)에서 퍼블릭 네트워크로 나가는 것을 위한 방식Bridge는 동일한 네트워크 세그먼트 내에서 자유롭게 통신하는 방식
또한 현 상황에서 Bridge를 사용하면서 아래 방법들을 통해 특정 IP를 강제할 수도 있다.
-
DHCP 예약(IP-MAC 바인딩)- 브릿지 네트워크에 연결된 디바이스의
MAC 주소를 기준으로 DHCP 서버에서 특정 IP를 할당
ex. dnsmasq를 이용한 MAC-IP 바인딩
- 브릿지 네트워크에 연결된 디바이스의
-
수동 Static IP 설정- 브릿지 내에서 사용하는 디바이스(VM, 컨테이너)에 수동으로 IP 지정
- NAT처럼 외부 네트워크에서 접근하려면 별도의 IP 포워딩 또는
iptables를 활용한SNAT(DNAT)설정 필요 - DNAT을 통해
Bridge Network를 사용하면서 특정 IP로 패킷을 변경 가능
iptables -t nat -A POSTROUTING -s 192.168.1.150 -j SNAT --to-source 203.0.113.10
현 상황에서는 libvirt의 네트워크의 virbr10이 Ethernet (enp) 인터페이스를 활용하고 있기 때문에 별도의 Bridge를 생성할 수 없다.
또한 Bridge Network를 사용하면 KVM이 호스트 네트워크와 동일한 서브넷에서 IP를 할당받고, 직접 네트워크에 접근할 수 있지만 이전에 보안 위협이 존재했던 만큼 해당 방식은 각 KVM Node들에게 위협이 되므로 배제하였다.
Static Routing
 네트워크 관리자가 직접
네트워크 관리자가 직접 Route를 지정하여 Routing Table에 수동으로 추가하는 방식의 라우팅 기법이다.
동적 라우팅과 달리 Router가 자동으로 경로를 학습하지 않으며, 관리자가 수동으로 경로를 설정해야 한다.
- 주요 특징
수동 설정- 관리자가 직접 네트워크 목적지와
Next Hop을 설정해야 함
ip route 192.168.1.0 255.255.255.0 192.168.2.1- 관리자가 직접 네트워크 목적지와
네트워크 변화에 따른 유지보수 필요- 링크 다운 또는 네트워크 구조 변경 시, 수동으로 업데이트해야 함
- 변화가 잦은 대규모 네트워크에서는 비효율적
낮은 오버헤드- 동적 라우팅 프로토콜(OSPF, BGP, RIP 등)과 달리 라우팅 업데이트 트래픽이 없음
- 소규모 네트워크에서 안정적으로 동작 가능
보안성 우수- 동적 라우팅보다 외부 공격에 덜 노출됨
- 예측 가능한 경로 설정이 가능하여 보안 정책 적용이 용이함
수동 설정이 번거롭고 네트워크 변화에 따른 유지보수가 필요하다는 단점이 존재하지만 낮은 오버헤드와 보안성이 우수하다는 장점을 수용하여 현재 아키텍처 디자인과 같이 소규모 호스트의 VM끼리 통신하기 위해서 Static Routing이 가장 효율적인 방법이라고 판단하였다.
따라서 Static Routing을 통해 현재 아키텍처의 L3 네트워크를 구성하였다.
IPv4 netmask /24 대역에서 특수한 IP 의미
- xxx.xxx.xxx.0 (Network Address): 해당 서브넷(네트워크 대역)을 식별하는 주소로, 호스트로 할당할 수 없음
- xxx.xxx.xxx.1 (Gateway Address, 선택적): 일반적으로 라우터 또는 게이트웨이 역할을 하는 장치에 할당됨
- xxx.xxx.xxx.2 ~ xxx.xxx.xxx.254 (Usable Host IPs): 실제로 사용할 수 있는 호스트(기기) IP 주소 범위
- xxx.xxx.xxx.255 (Broadcast Address): 서브넷 내 모든 호스트에게 메시지를 전달하는 브로드캐스트 주소
Network Configuration
K8s Master Node Configuration
호스트 머신에서 libvirt 및 KVM 설치 과정에 대한 내용은 생략하였다.
<network>
<name>k8snat</name>
<forward mode="nat"/>
<bridge name="virbr10" stp="off" delay="0"/>
<ip address="172.20.112.1" netmask="255.255.255.0">
<dhcp>
<range start="172.20.112.100" end="172.20.112.200"/>
<host mac="..." name="master" ip="172.20.112.101"/>
</dhcp>
</ip>
</network>우선 위와 같이 k8snat NAT Network를 생성하고
$ virsh net-list --all
Name State Autostart Persistent
--------------------------------------------
default active yes yes
k8snat active yes yes해당 네트워크를 active한 후 auto-start를 설정해준다.
[root@kubernetes-host ~]# ip a
...
5: virbr10: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:dc:30:07 brd ff:ff:ff:ff:ff:ff
inet 172.20.112.1/24 brd 172.20.112.255 scope global virbr10
valid_lft forever preferred_lft forever이후 kubernetes-host에서 정상적으로 virbr10가 생성된 것을 확인한다.
$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 3.7G 0 3.7G 0% /dev/shm
tmpfs 1.5G 9.2M 1.5G 1% /run
/dev/mapper/rl-root 70G 5.7G 65G 9% /
/dev/mapper/rl-home 398G 2.9G 396G 1% /home
/dev/nvme0n1p1 1014M 459M 556M 46% /boot
tmpfs 756M 4.0K 756M 1% /run/user/0
$ mkdir /home/libvirt
$ mkdir /home/libvirt/images
$ virt-install \
--name master \
--ram 6144 \
--vcpus 3 \
--disk path=/home/libvirt/images/master.qcow2,size=100 \
--os-variant rocky9.0 \
--location /var/lib/libvirt/images/Rocky-9.2-x86_64-minimal.iso \
--extra-args "inst.text console=ttyS0,115200n8" \
--network network=k8snat,model=virtio \
--graphics noneKVM을 생성해주기 위해 위와 같이 /home/libvirt/images 디렉터리를 생성하고 master.qcow2QCOW2 형태로 KVM을 생성해준 뒤
### MASTER
[root@master ~]# ip a
...
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:fd:74:63 brd ff:ff:ff:ff:ff:ff
inet 172.20.112.101/24 brd 172.20.112.255 scope global dynamic noprefixroute enp1s0
valid_lft 3594sec preferred_lft 3594sec
inet6 fe80::5054:ff:fefd:7463/64 scope link noprefixroute
valid_lft forever preferred_lft forevermaster 노드 내부에서 고정 IP가 할당된 것을 확인할 수 있다.
Openstack Controller Node Volume Reallocation
### HOST
$ virsh domblklist controller
Target Source
-----------------------------------------------------------------------
vda /var/lib/libvirt/images/controller.Controller-Node-Complete
sda -우선 Openstack에서 Kubernetes를 위해 컴퓨팅 리소스를 제공하기 전에 VM의 디스크 정보를 확인하고 해당 디스크의 Volume을 증가시키도록 한다.
### HOST
$ sudo qemu-img resize /var/lib/libvirt/images/controller.Controller-Node-Complete +20G
Image resized.이전에 생성한 Snapshot 디스크 이미지로 Controller Node가 동작하고 있기에 qemu-img resize 명령어를 통해 20G를 추가해주고
### HOST
$ qemu-img info /var/lib/libvirt/images/controller.Controller-Node-Complete
image: /var/lib/libvirt/images/controller.Controller-Node-Complete
file format: qcow2
virtual size: 60 GiB (64424509440 bytes)
disk size: 5.29 GiB
cluster_size: 65536
backing file: /var/lib/libvirt/images/controller.Installing-Nova
backing file format: qcow2
Format specific information:
compat: 1.1
compression type: zlib
lazy refcounts: false
refcount bits: 16
corrupt: false
extended l2: false
Child node '/file':
filename: /var/lib/libvirt/images/controller.Controller-Node-Complete
protocol type: file
file length: 5.28 GiB (5674566656 bytes)
disk size: 5.29 GiBqemu-img info를 통해 virtual size가 60 GiB까지 늘어난 것을 확인할 수 있었다.
### CONTROLLER
shutdown -h now### HOST
virsh start controller이후 디스크 용량 증가를 인식시킬 수 있도록 해당 VM을 완전히 종료했다가 다시 구동한 뒤
### CONTROLLER
sudo dnf install cloud-utils-growpart -ycloud-utils-growpart 패키지를 다운로드 받고
### CONTROLLER
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 1024M 0 rom
vda 253:0 0 60G 0 disk
├─vda1 253:1 0 1G 0 part /boot
├─vda2 253:2 0 4G 0 part [SWAP]
└─vda3 253:3 0 35G 0 part /lsblk를 통해 vda 디스크의 SIZE가 늘어난 것을 확인해준다.
### CONTROLLER
sudo growpart /dev/vda 3 이후 growpart로 vda3 파티션을 확장하고
### CONTROLLER
sudo xfs_growfs /dev/vda3XFS 파일시스템 크기를 조전하면
### CONTROLLER
$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 2.8G 0 2.8G 0% /dev/shm
tmpfs 1.2G 8.8M 1.1G 1% /run
/dev/vda3 55G 16G 40G 29% /
/dev/vda1 1014M 294M 721M 29% /boot
tmpfs 567M 4.0K 567M 1% /run/user/0위와 같이 정상적으로 /dev/vda3 볼륨의 크기가 늘어난 것을 볼 수 있다.
k8s-worker-1 Instance Deployment
openstack flavor create k8s.worker \
--vcpus 3 \
--ram 3072 \
--disk 18 \
--swap 0 \
--ephemeral 0 \
--public또한 이후 Compute Node의 Spec을 염두하여 위와 같이 k8s.worker flavor를 생성해준 뒤
openstack server create \
--flavor k8s.worker \
--image "Rocky Linux 9 Generic Cloud" \
--nic net-id=$(openstack network list --name private-net -f value -c ID) \
--security-group default \
--key-name mykey \
k8s-worker-1k8s-worker-1 인스턴스를 생성해주고
openstack server add floating ip k8s-worker-1 192.168.100.29 SSH 접속을 위해 Floating IP를 할당한다.
$ ssh -i mykey.pem rocky@192.168.100.29
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
Someone could be eavesdropping on you right now (man-in-the-middle attack)!
It is also possible that a host key has just been changed.
The fingerprint for the ED25519 key sent by the remote host is
SHA256:zK+WinjcErcDpxXBvjNu/AATYoXPU1Tbo2YIJ7vgbNk.
Please contact your system administrator.
Add correct host key in /root/.ssh/known_hosts to get rid of this message.
Offending ECDSA key in /root/.ssh/known_hosts:3
Host key for 192.168.100.29 has changed and you have requested strict checking.
Host key verification failed.이후 SSH 접속 시 호스트 키 충돌이 발생한 경우, 기존 키를 삭제하고 새 키를 받아와야 하기 때문에
$ ssh-keygen -R 192.168.100.29
# Host 192.168.100.29 found: line 1
# Host 192.168.100.29 found: line 2
# Host 192.168.100.29 found: line 3
/root/.ssh/known_hosts updated.
Original contents retained as /root/.ssh/known_hosts.oldssh-keygen -R 명령을 통해 known_hosts에서 이전 포스팅에서 테스트를 위해 할당한 192.168.100.29 IP의 키를 제거할 수 있다
[rocky@k8s-worker-1 ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether fa:16:3e:d5:0f:f2 brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname ens3
inet 10.0.0.205/24 brd 10.0.0.255 scope global dynamic noprefixroute eth0
valid_lft 86044sec preferred_lft 86044sec
inet6 fe80::f816:3eff:fed5:ff2/64 scope link
valid_lft forever preferred_lft forever
[rocky@k8s-worker-1 ~]$ ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=113 time=36.4 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=113 time=35.0 ms이후 k8s-worker-1 내부에 정상적으로 ssh를 통해 접근할 수 있었으며, 외부로 트래픽을 보내는 것 또한 정상적으로 작동하는 것을 확인할 수 있었다.
Static Routing Configuration
```bash
$ vim /etc/sysctl.conf
...
net.ipv4.ip_forward = 1
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.virbr10.rp_filter = 0Static Routing을 진행해주기 이전 ip_forward = 1 설정을 통해 패킷이 다른 네트워크로 포워딩될 수 있도록 하고 /etc/sysctl.conf 파일에 추가하여 재부팅 후에도 유지할 수 있도록 한다.
이때 rp_filter (Reverse Path Filtering)는 IP 패킷의 소스 유효성을 검사하여 spoofing 공격을 방지하는 기능이다.
| 값 | 동작 방식 |
|---|---|
0 | Reverse Path Filtering을 비활성화 (패킷 검사 없음) |
1 | Strict Mode (엄격 모드, 기본값) - 패킷이 들어온 인터페이스가 FIB에 기록된 유일한 경로가 아니면 폐기 |
2 | Loose Mode (완화 모드) - 소스 IP가 FIB의 어떤 인터페이스를 통해서라도 도달할 수 있으면 허용 |
위와 같이 값에 따라서 다르게 동작하기 때문에, 우선 각 호스트의 VM이 경유하는 인터페이스들에 대해서 Reverse Path Filtering을 일시적으로 비활성화한다.
Host Machine Internal IP Address
### Openstack Host
nmcli connection modify enp7s0 +ipv4.addresses 10.10.10.1/24### K8s Host
nmcli connection modify Ethernet +ipv4.addresses 10.10.10.2/24이후 각 호스트 머신의 NetworkManager Connection에 Static Routing을 위해 사용할 새로운 Internal IP 주소를 할당한다.
nmcli에서 +ipv4.addresses 구문을 사용하여, 기존 IP 설정을 그대로 유지하면서 새 IP 주소들을 추가한다.
+ipv4.addresses는 “append(덧붙이기)” 기능을 하며, ipv4.addresses는 “overwrite(덮어쓰기)” 개념이므로 이에 주의하여 설정을 진행해야 한다.
[root@openstack-host ~]# ping 10.10.10.2
PING 10.10.10.2 (10.10.10.2) 56(84) bytes of data.
64 bytes from 10.10.10.2: icmp_seq=1 ttl=64 time=3.29 ms
64 bytes from 10.10.10.2: icmp_seq=2 ttl=64 time=1.83 ms
[root@kubernetes-host ~]# ping 10.10.10.1
PING 10.10.10.1 (10.10.10.1) 56(84) bytes of data.
64 bytes from 10.10.10.1: icmp_seq=1 ttl=64 time=1.42 ms
64 bytes from 10.10.10.1: icmp_seq=2 ttl=64 time=1.80 ms이후 각 호스트에서 새롭게 등록한 Internal IP로의 연결이 정상적인지 확인한다.
libvirt NAT dst Static Routing
### Openstack Host
sudo ip route add 172.20.112.0/24 via 10.10.10.2### K8s Host
sudo ip route add 192.168.100.0/24 via 10.10.10.1이후 libvirt NAT의 dst (Destination)에 대한 라우트를 추가해주어야 하는데, 직접 통신 가능의 전제 조건이 충족되면 Private IP, Public IP 구분 없이 가능하다.
다만, Public IP를 사용하는 경우는 인터넷 경유 통신 구조가 되므로, 원하는 트래픽 흐름과 방화벽/포트포워딩 정책을 추가적으로 고려해주어야 한다.
[root@openstack-host ~]# ping 172.20.112.1
PING 172.20.112.1 (172.20.112.1) 56(84) bytes of data.
64 bytes from 172.20.112.1: icmp_seq=1 ttl=64 time=1.81 ms
64 bytes from 172.20.112.1: icmp_seq=2 ttl=64 time=1.81 ms
[root@kubernetes-host ~]# tcpdump -i enp0s20f0u2 icmp
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on enp0s20f0u2, link-type EN10MB (Ethernet), snapshot length 262144 bytes
22:20:47.512066 IP 10.10.10.1 > kubernetes-host: ICMP echo request, id 6, seq 1, length 64
22:20:47.512147 IP kubernetes-host > 10.10.10.1: ICMP echo reply, id 6, seq 1, length 64[root@kubernetes-host ~]# ping 192.168.100.1
PING 192.168.100.1 (192.168.100.1) 56(84) bytes of data.
64 bytes from 192.168.100.1: icmp_seq=1 ttl=64 time=1.49 ms
64 bytes from 192.168.100.1: icmp_seq=2 ttl=64 time=1.66 ms
[root@openstack-host ~]# tcpdump -i enp7s0 icmp
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on enp7s0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
22:21:22.899071 IP 10.10.10.2 > openstack-host: ICMP echo request, id 4, seq 1, length 64
22:21:22.899121 IP openstack-host > 10.10.10.2: ICMP echo reply, id 4, seq 1, length 64
22:21:23.900932 IP 10.10.10.2 > openstack-host: ICMP echo request, id 4, seq 2, length 64
22:21:23.900971 IP openstack-host > 10.10.10.2: ICMP echo reply, id 4, seq 2, length 64이후 각 호스트에서 상대방 libvirt NAT의 Gateway까지는 요청이 정상적으로 전달되는 것을 확인했지만
[root@master ~]# ping 192.168.100.101
PING 192.168.100.101 (192.168.100.101) 56(84) bytes of data.
From 10.10.10.1 icmp_seq=1 Destination Port Unreachable
From 10.10.10.1 icmp_seq=2 Destination Port Unreachable
[root@openstack-host ~]# tcpdump -i enp7s0 icmp
22:32:24.893961 IP 10.10.10.2 > 192.168.100.101: ICMP echo request, id 3, seq 1, length 64
22:32:24.894041 IP openstack-host > 10.10.10.2: ICMP 192.168.100.101 protocol 1 port 23840 unreachable, length 92
...
[root@openstack-host ~]# tcpdump -i virbr10 icmp
kubernetes-host의 master KVM으로부터 openstack-host의 controller KVM까지의 ICMP 요청이 정상적으로 도달하지 않는 것을 확인하였다.
ICMP(Internet Control Message Protocol)는 IP 네트워크에서 오류 메시지 전달과 네트워크 상태 정보를 교환하기 위해 사용되는 프로토콜이다.- IP 패킷 전송 중 문제가 발생하면,
ICMP메시지를 통해 송신자에게 알리는 역할을 한다.ICMP는 IP 패킷의 일부로 포함되며, 신뢰성이 필요한 데이터 전송에는 사용되지 않는다.ping명령어의 경우 매개변수로 받은 IP 주소로ICMP요청을 하는 명령어이다
iptables Rule Configuration
[root@openstack-host ~]# sudo iptables -L -n -v
...
Chain LIBVIRT_FWI (1 references)
pkts bytes target prot opt in out source destination
681 558K ACCEPT all -- * virbr10 0.0.0.0/0 192.168.100.0/24 ctstate RELATED,ESTABLISHED
11 924 REJECT all -- * virbr10 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
...
Chain LIBVIRT_FWO (1 references)
pkts bytes target prot opt in out source destination
664 52072 ACCEPT all -- virbr10 * 192.168.100.0/24 0.0.0.0/0
0 0 REJECT all -- virbr10 * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
...이에 iptables를 확인해보니 LIBVIRT_FWI 체인에서 REJECT Rule에 의해 11개의 패킷이 DROP되고 있는 것을 확인하였고 추가적으로 요청을 보내 LIBVIRT_FWI 체인의 문제임을 정확히 확인하였다.
이는 libvirt의 기본NAT 네트워크(virbr)는 외부에서 들어오는 NEW 연결을 기본적으로 차단하도록 만들어져 있기 때문이다.
즉, VM이 먼저 외부로 나가는 통신은 NAT를 통해 자동 허용되지만, 외부(10.10.10.2)에서 VM(192.168.100.101)으로 들어오는 신규 트래픽은 REJECT Rule에 걸려 destination unreachable을 보내는 것이다.
- 기본 체인
INPUT: 호스트로 들어오는 패킷을 처리하는 체인
FORWARD: 다른 네트워크로 전달되는 패킷을 처리하는 체인
OUTPUT: 호스트에서 나가는 패킷을 처리하는 체인- 사용자 정의 체인
LIBVIRT_INP: 가상 네트워크(virbr)에서 들어오는 패킷을 처리하는 체인 (DNS, DHCP 요청 허용)
LIBVIRT_FWX: 가상 네트워크 내부(virbr)에서 이루어지는 패킷을 처리하는 체인 (virbr 간 패킷 허용)
LIBVIRT_FWI: 가상 네트워크에서 들어오는 패킷을 필터링하는 체인 (RELATED, ESTABLISHED 패킷 허용, 불필요한 패킷 거부)
LIBVIRT_FWO: 가상 네트워크에서 나가는 패킷을 필터링하는 체인 (지정된 서브넷에서 나가는 패킷 허용, 나머지는 거부)
LIBVIRT_OUT: 가상 네트워크에서 나가는 패킷을 처리하는 체인
### Openstack Host
sudo iptables -I LIBVIRT_FWI 1 -s 10.10.10.0/24 -d 192.168.100.0/24 -j ACCEPT따라서 LIBVIRT_FWI Chain의 REJECT Rule 위에 ACCEPT를 삽입한다.
-I LIBVIRT_FWI 1:LIBVIRT_FWI체인의 첫 번째(1) 위치에 규칙 삽입-s 10.10.10.0/24: 소스 IP 주소 범위를10.10.10.0/24로 지정-d 192.168.100.0/24: 목적지 IP 주소 범위를192.168.100.0/24로 지정-j ACCEPT: 해당 트래픽을 허용(Accept)하도록 설정
### Openstack Host
sudo iptables -I LIBVIRT_FWO 1 -s 192.168.100.0/24 -d 10.10.10.0/24 -j ACCEPT또한 VM(192.168.100.0/24) -> 외부(10.10.10.0/24) outbound를 허용하기 위해 위와 같은 Rule을 LIBVIRT_FWO Chain에 삽입하고
### K8s Host
sudo iptables -I LIBVIRT_FWI 1 -s 10.10.10.0/24 -d 172.20.112.0/24 -j ACCEPT
sudo iptables -I LIBVIRT_FWO 1 -s 172.20.112.0/24 -d 10.10.10.0/24 -j ACCEPTK8s Host에서도 이와 같은 Rule을 동일하게 적용한다.
KVM (Node) Routing Table Configuration
### Openstack Controller Node
### Openstack Compute Node
sudo ip route add 172.20.112.0/24 via 192.168.100.1 dev br-ex
sudo nmcli connection modify br-ex-ip +ipv4.routes "172.20.112.0/24 192.168.100.1"### Kubernetes Master Node
sudo ip route add 192.168.100.0/24 via 172.20.112.1 dev enp1s0
sudo nmcli connection modify enp1s0 +ipv4.routes "192.168.100.0/24 172.20.112.1"이후 위와 같이 각 KVM에서 각각 호스트 머신으로의 네트워크 연결을 위해 사용하고 있는 인터페이스와 NetworkManager Connection에 Route 정보를 추가한다.
KVM (Node) Routing Table Check
### Openstack Controller Node
$ ip route
default via 192.168.100.1 dev br-ex
172.20.112.0/24 via 192.168.100.1 dev br-ex
192.168.100.0/24 dev br-ex proto kernel scope link src 192.168.100.101### Openstack Compute Node
$ ip route
default via 192.168.100.1 dev br-ex
172.20.112.0/24 via 192.168.100.1 dev br-ex
192.168.100.0/24 dev br-ex proto kernel scope link src 192.168.100.102### Kubernetes Master Node
$ ip route
default via 172.20.112.1 dev enp1s0 proto dhcp src 172.20.112.101 metric 100
172.20.112.0/24 dev enp1s0 proto kernel scope link src 172.20.112.101 metric 100
192.168.100.0/24 via 172.20.112.1 dev enp1s0 VM에서 라우팅이 올바르게 동작하려면, 기본 게이트웨이가 virbr10의 IP(호스트 머신의 NAT 게이트웨이)로 설정되어 있어야 하기 때문에 이를 한번 더 확인해준다.
KVM Connection Test
[root@controller ~]# ping 172.20.112.101
PING 172.20.112.101 (172.20.112.101) 56(84) bytes of data.
64 bytes from 172.20.112.101: icmp_seq=1 ttl=62 time=2.47 ms
64 bytes from 172.20.112.101: icmp_seq=2 ttl=62 time=1.99 ms
[root@compute ~]# ping 172.20.112.101
PING 172.20.112.101 (172.20.112.101) 56(84) bytes of data.
64 bytes from 172.20.112.101: icmp_seq=1 ttl=62 time=2.52 ms
64 bytes from 172.20.112.101: icmp_seq=2 ttl=62 time=1.97 ms[root@master ~]# ping 192.168.100.101
PING 192.168.100.101 (192.168.100.101) 56(84) bytes of data.
From 10.10.10.1 icmp_seq=1 Destination Port Unreachable
From 10.10.10.1 icmp_seq=2 Destination Port Unreachable
[root@master ~]# ping 192.168.100.102
PING 192.168.100.102 (192.168.100.102) 56(84) bytes of data.
64 bytes from 192.168.100.102: icmp_seq=1 ttl=62 time=2.08 ms
64 bytes from 192.168.100.102: icmp_seq=2 ttl=62 time=1.91 ms이후 위와 같이 각 KVM들에서 다른 호스트의 KVM으로 ICMP 요청을 정상적으로 수행하는 것을 볼 수 있다.
iptables-services Setup
sudo systemctl stop firewalld
sudo systemctl disable firewalld
sudo dnf install -y iptables-services이러한 iptables의 Rule을 영구적으로 유지하기 위해 기존의 firewalld 중지를 중지하고 iptables-services 설치한다.
sudo systemctl enable iptables --now
sudo systemctl enable ip6tables --now이후 각 데몬을 enable함과 동시에 실행시켜주고
### Openstack Host
sudo iptables -I LIBVIRT_FWI 1 -s 10.10.10.0/24 -d 192.168.100.0/24 -j ACCEPT
sudo iptables -I LIBVIRT_FWO 1 -s 192.168.100.0/24 -d 10.10.10.0/24 -j ACCEPT### K8s Host
sudo iptables -I LIBVIRT_FWI 1 -s 10.10.10.0/24 -d 172.20.112.0/24 -j ACCEPT
sudo iptables -I LIBVIRT_FWO 1 -s 172.20.112.0/24 -d 10.10.10.0/24 -j ACCEPT앞서 해결을 위해 사용했던 iptables 명령을 다시 실행한다.
sudo iptables-save | sudo tee /etc/sysconfig/iptables이후 현재 iptables Rule을 /etc/sysconfig/iptables 로 저장한다.
위와 같이 설정하면 하면 재부팅 후에도 iptables 서비스가 올라오면서 /etc/sysconfig/iptables에 저장된 규칙이 자동으로 로드되어 현재의 iptable이 영구히 적용된다.
k8s-worker-1 Network Setup
 추후
추후 K8s Cluster 구축과 각 Worker Node간의 CNI (Container Network Interface) 설정을 더 용이하게 하기 위해 위와 같이 인스턴스가 ext-net과 private-net에 동시에 연결되어, Master Node과의 통신은 ext-net을 통해 수행하고 내부적인 Pod 네트워킹은 private-net을 통해 수행할 수 있도록 구성하였다.
openstack server create \
--flavor k8s.worker \
--image "Rocky Linux 9 Generic Cloud" \
--nic net-id=$(openstack network list --name ext-net -f value -c ID) \
--nic net-id=$(openstack network list --name private-net -f value -c ID) \
--security-group default \
--key-name mykey \
k8s-worker-1따라서 이전의 라우터와 인스턴스를 제거하고 위와 같이 k8s-worker-1 인스턴스에 두 개의 NIC를 연결한다.
openstack server set --property "auto_start=true" 0d025cb5-09b0-4a5f-81a3-0c480849cc9f이후 위와 같이 auto_start 옵션을 설정해준 뒤
### k8s-worker-1
sudo ip route add 172.20.112.0/24 via 192.168.100.1 dev eth0
sudo nmcli connection modify "System eth0" +ipv4.routes "172.20.112.0/24 192.168.100.1"k8s-worker-1 내부에서 kubernetes-host로의 라우트를 설정한다.
[rocky@k8s-worker-1 ~]$ ping 172.20.112.101
PING 172.20.112.101 (172.20.112.101) 56(84) bytes of data.
64 bytes from 172.20.112.101: icmp_seq=1 ttl=62 time=2.87 ms
64 bytes from 172.20.112.101: icmp_seq=2 ttl=62 time=2.73 ms
[root@master ~]# tcpdump -i enp1s0 icmp
00:07:00.033731 IP 10.10.10.1 > master: ICMP echo request, id 7, seq 1, length 64
00:07:00.033815 IP master > 10.10.10.1: ICMP echo reply, id 7, seq 1, length 64
00:07:01.035844 IP 10.10.10.1 > master: ICMP echo request, id 7, seq 2, length 64
00:07:01.035925 IP master > 10.10.10.1: ICMP echo reply, id 7, seq 2, length 64이후 k8s-worker-1에서 master로의 연결은 정상적으로 수행되는 것을 볼 수 있었다.
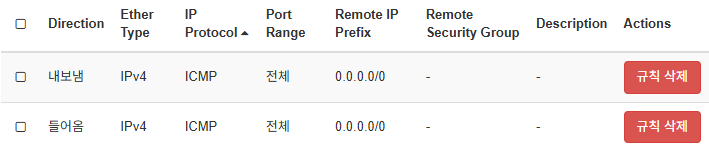 또한 추가적으로 외부에서의 ICMP 요청을 Openstack
또한 추가적으로 외부에서의 ICMP 요청을 Openstack Security Group을 통해 허용해준다.
[root@openstack-host ~]# ping 192.168.100.44
PING 192.168.100.44 (192.168.100.44) 56(84) bytes of data.
64 bytes from 192.168.100.44: icmp_seq=1 ttl=64 time=0.411 ms
64 bytes from 192.168.100.44: icmp_seq=2 ttl=64 time=0.371 ms하지만 이후 openstack-host에서 인스턴스에 할당된 192.168.100.44로의 요청은 정상적으로 이루어지지만
[root@master ~]# ping 192.168.100.44
PING 192.168.100.44 (192.168.100.44) 56(84) bytes of data.
From 10.10.10.1 icmp_seq=1 Destination Port Unreachable
From 10.10.10.1 icmp_seq=2 Destination Port Unreachablekubernetes-host의 master로부터 192.168.100.44 (k8s-worker-1)로의 요청은 정상적으로 이루어지지 않음을 확인하였다.
[root@master ~]# ping 192.168.100.44
PING 192.168.100.44 (192.168.100.44) 56(84) bytes of data.
From 10.10.10.1 icmp_seq=1 Destination Port Unreachable
[root@openstack-host ~]# tcpdump -i enp7s0 icmp
00:18:24.840032 IP openstack-host > 10.10.10.2: ICMP 192.168.100.44 protocol 1 port 39336 unreachable, length 92
[root@openstack-host ~]# tcpdump -i virbr10 icmp따라서 관련 인터페이스의 패킷을 캡처해본 결과 openstack-host의 물리 NIC인 enp7s0에서는 패킷은 보여지지만 virbr10로는 패킷이 전달되지 않음을 확인하였다.
### Openstack Host
$ sudo iptables -L -n -v
...
Chain LIBVIRT_FWI (1 references)
pkts bytes target prot opt in out source destination
8851 12M ACCEPT all -- * virbr10 0.0.0.0/0 192.168.100.0/24 ctstate RELATED,ESTABLISHED
126 10584 REJECT all -- * virbr10 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable따라서 iptables의 Rule을 다시 점검해본 결과 현 상황의 LIBVIRT_FWI Chain의 문제점은 아래와 같았다.
ACCEPT: 이미 VM 내부에서 시작된 연결이나 관련 패킷(RELATED/ESTABLISHED 상태)은 통과REJECT: 그 외(주로 NEW 상태의 inbound 트래픽)는icmp-port-unreachable로 거부- 외부(
kubernetes-host)에서 새롭게 들어오는 요청(NEW)은REJECT규칙에 매칭되어 카운터가 증가 “NEW 상태의 inbound”를 허용하는 규칙이 전혀 없으니 REJECT로 처리
- 외부(
### Openstack Host
sudo iptables -I LIBVIRT_FWI 1 -s 10.10.10.0/24 -d 192.168.100.0/24 -j ACCEPT따라서 위와 같은 규칙을 추가해, “NEW 상태의 inbound”을 특정 목적지(192.168.100.0/24)로 허용하였다.
[rocky@k8s-worker-1 ~]$ ping 172.20.112.101
PING 172.20.112.101 (172.20.112.101) 56(84) bytes of data.
64 bytes from 172.20.112.101: icmp_seq=1 ttl=62 time=2.87 ms
64 bytes from 172.20.112.101: icmp_seq=2 ttl=62 time=2.73 ms
[root@master ~]# ping 192.168.100.44
PING 192.168.100.44 (192.168.100.44) 56(84) bytes of data.
64 bytes from 192.168.100.44: icmp_seq=1 ttl=62 time=3.20 ms
64 bytes from 192.168.100.44: icmp_seq=2 ttl=62 time=2.77 ms이후 k8s-worker-1와 master에서 서로 연결이 가능한 것을 확인할 수 있었고
sudo iptables-save | sudo tee /etc/sysconfig/iptables현재 iptables 상태를 저장하여 위 규칙이 영구적으로 적용될 수 있도록 하였다.
Summary
 현재 최종적으로 구성된 네트워크는 위와 같다.
현재 최종적으로 구성된 네트워크는 위와 같다.
현재 Switch를 통해 물리적으로 연결된 openstack-host와 kubernetes-host는 임의로 추가한 10.10.10.0/24 대역을 통해 Internal하게 통신을 진행하고 있으며, 각각의 KVM 및 인스턴스의 통신 또한 해당 IP 대역을 통해 라우트된다.
또한 현재 ovs의 br-int는 각각의 인스턴스와 2가지의 tap포트를 통해 연결되어 있고, ext-net과 연결된 포트는 Compute Node의 enp1s0를 Slave 포트로 가지는 br-ex와 동일한 192.168.100.0/24 서브넷 대역의 IP를 할당받고 있다.
추가적으로 private-net과 연결된 포트의 경우 별도의 서브넷 대역인 10.0.0.x/24 내에서 IP를 할당받아 각 인스턴스들의 Internal한 통신이 가능하다.
kubernetes-host의 Master Node의 경우 Static Routing을 통해 각 Openstack 인스턴스인 k8s-worker-1과 k8s-worker-2의 192.168.100.0/24 서브넷 대역의 IP로 요청을 보내며, 반대 방향의 경우 172.112.20.0/24 대역으로 요청을 보내 통신한다.
Kubernetes Configuration
K8s Architecture
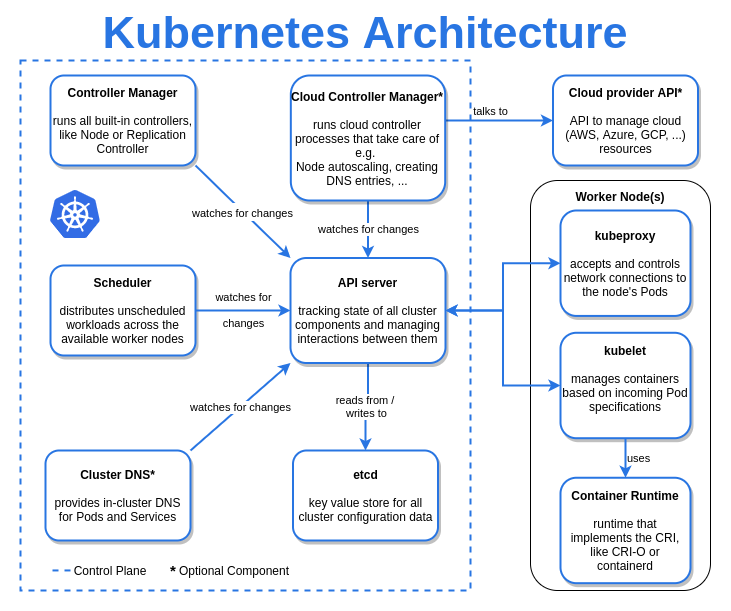
-
API ServerKubernetes클러스터의 핵심 구성 요소로, 클러스터 내부 및 외부 요청을 처리하는 중앙 API- 클러스터의 상태를 관리하고, 구성 요소 간의 통신을 조정하며, 인증과 권한 부여를 수행
kubectl, 내부 컨트롤러, 기타 클라이언트 요청을 받아 적절한 컴포넌트로 전달
-
etcdKubernetes의 모든 상태 데이터를 저장하는 key-value 저장소- 클러스터의
Node,Pod,Service,ConfigMap등의 정보를 저장하고 관리하며, 장애 복구 시 중요한 역할을 수행 - 고가용성을 위해 다중 노드로 구성할 수 있으며,
kube-api-Server가 지속적으로 상태를 조회하고 갱신
-
Scheduler- 생성된
Pod을 적절한Worker Node에 배치하는 역할을 담당 - 각 노드의 CPU, 메모리, 네트워크 상태를 평가하여 최적의 노드를 선택
- 리소스 사용량을 고려한 스케줄링 정책을 적용하며, 특정 노드 선호도나
taint/toleration설정도 반영 가능
- 생성된
-
Controller Manager- 클러스터의 다양한 컨트롤러(
Node Controller,Replication Controller등)를 실행하고 관리 - 클러스터 상태를 지속적으로 모니터링하고, 설정한 스펙과 실제 상태가 일치하도록 자동 조정
ReplicaSet을 통해 필요한Pod개수를 유지하고, 노드 장애 시 새로운 노드로 워크로드를 이동
- 클러스터의 다양한 컨트롤러(
-
Cloud Controller Manager- 클라우드 환경(AWS, GCP, Azure)에서
Kubernetes와 클라우드 리소스를 연동하는 역할 수행 - 노드 자동 확장, 로드밸런서 생성, 클라우드 네트워크 설정과 같은 작업을 처리
- 클라우드 제공 업체와의 API 통신을 통해 동적으로 리소스를 관리하며, 베어메탈 환경에서는 필요하지 않음
- 클라우드 환경(AWS, GCP, Azure)에서
-
Cluster DNS (선택)- 클러스터 내부에서
Pod와Service간의DNS를 제공하는 네트워크 컴포넌트 CoreDNS또는kube-dns를 활용하여 서비스명을 기반으로 IP 주소를 조회 가능- 클러스터 내에서 동적으로 변경되는 서비스의 네트워크 엔드포인트를 쉽게 관리할 수 있도록 지원
- 클러스터 내부에서
-
Worker Node- 애플리케이션 컨테이너가 실행되는
Kubernetes Cluster의 기본 단위 - 각 노드는
kubelet,kube-proxy,Container Runtime을 포함하며,API Server와 상호작용하여 워크로드를 실행 Master Node의 스케줄링에 따라 새로운Pod을 배포받고 실행하는 역할 수행
- 애플리케이션 컨테이너가 실행되는
-
Kubelet- 각
Worker Node에서 실행되며,API Server와 통신하여Pod을 관리하는 agent - 노드의 상태를 지속적으로 보고하고, 스펙에 따라 컨테이너를 실행 및 유지 관리
- 컨테이너가 비정상적으로 종료되었을 때 재시작하거나, 특정 조건을 만족하지 않으면 자동 복구 수행
- 각
-
Kube Proxy- 네트워크 규칙을 관리하고,
Pod간 통신 및 외부 트래픽을 처리하는 네트워크 컴포넌트 Kubernetes의 서비스 디스커버리와 로드 밸런싱을 지원하며,Pod에 대한 접근을 제어iptables또는IPVS를 활용하여 트래픽을 라우팅하고, 클러스터 내의 서비스와 외부 트래픽을 연결
- 네트워크 규칙을 관리하고,
-
Container Runtime- 컨테이너를 실행하는 역할을 담당하며,
Kubernetes의CRI(Container Runtime Interface)를 구현 - 대표적인 런타임으로
containerd,CRI-O,Docker등이 있으며, kubelet이 이를 사용해 컨테이너를 실행 Kubernetes스펙에 따라 컨테이너를 배포, 삭제, 재시작하는 기능을 수행
- 컨테이너를 실행하는 역할을 담당하며,
-
Cloud Provider API (선택)- AWS, GCP, Azure 같은 클라우드 서비스의 리소스를 관리하는 API
Kubernetes가 클라우드 환경에서 인프라를 동적으로 관리할 수 있도록 지원- 예를 들어, 로드 밸런서를 자동으로 생성하거나, 노드를 추가할 때 클라우드 API를 호출하여 자원을 할당
Continer Runtime
| Container Runtime | 설명 | 장점 | 단점 | 비고 및 참고 사항 |
|---|---|---|---|---|
| containerd | CNCF 주도의 산업 표준 런타임. 대부분의 K8s 배포판에서 기본 사용. | 안정성과 성능 우수 | 커스터마이징 한계 | Kubernetes 기본 런타임으로 널리 채택됨. |
| CRI-O | Kubernetes 전용 경량 런타임. | 경량화 및 빠른 시작 | 일부 기능 제한 가능 | OpenShift 등 Red Hat 기반 환경에서 주로 사용됨. |
| Mirantis Container Runtime | Docker 기술 기반 상용 런타임. | Docker 친화적, 기업 지원 우수 | 라이선스 비용 발생 가능 | 기존 Docker Engine의 후속 제품으로 기업 환경에서 활용됨. |
| Kata Containers | 경량 VM 기반 런타임으로 컨테이너 격리 강화 목적. | 높은 보안성과 격리성 | 성능 오버헤드 가능성 | 보안이 중요한 환경에서 선택 가능. |
| gVisor | 애플리케이션 샌드박싱 제공 런타임. | 추가 격리 및 보안 강화 | 네이티브 성능 저하 가능 | containerd와 연동하여 추가 격리 기능 제공. |
또한 K8s에서 사용 가능한 Continer Runtime은 위와 같다.
dockershim EOL
Kubernetes는 초기 Docker Engine을 통해 컨테이너를 실행할 수 있도록 dockershim이라는 어댑터를 사용했으나, 이후 Kubernetes의 Container Runtime Interface(CRI)에 맞춘 표준화된 방식으로 전환하기 위해 변화가 있었다.
Kubernetes 1.20부터 dockershim이 공식적으로 deprecated 되었으며, 이후 Kubernetes 1.24 버전에서 완전히 제거되었다.
이러한 결정은 아래와 같은 이유가 있었다.
- 표준화 및 유지보수 부담 경감:
Docker Engine은 자체적으로CRI를 지원하지 않기 때문에,Kubernetes에서는CRI준수 런타임(ex.containerd,CRI-O)으로 통일하는 것이 유지보수와 안정성 측면에서 유리하였다. - 불필요한 기능 제거:
Docker Engine은Kubernetes운영에 필요하지 않은 여러 기능(ex. 이미지 빌드 등)을 포함하고 있어, 경량화와 효율적인 운영을 위해 제거 결정이 내려졌다. - 생태계 최적화:
CRI기반의 런타임은Kubernetes의 요구사항에 보다 적합하도록 설계되어, 성능과 보안 측면에서 이점을 제공하였다.
Master Node Configuration
$ vim /etc/sysconfig/selinux
SELINUX=disabled
$ setenforce 0우선 Master Node를 설정하기 위해 위와 같이 SELINUX를 disable하였다.
systemctl stop firewalld
systemctl disable firewalld원활한 운영을 위해 firewalld 또한 disable하고
$ vim /etc/fstab
# UUID=3c57818d-6e2f-470d-86be-c315c913294c none swap defaaults 0 0
$ swapoff -a필수적으로 위와 같이 SWAP 메모리 설정을 off 해주어야한다.
sudo cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/repodata/repomd.xml.key
EOF이후 kubernetes yum repo 등록해준다.
현재 최신 LTS 버전인 v1.32 선택해주었는데, 자세한 버전에 대한 정보는 아래 링크를 참조하여 진행하면 된다.
cat <<EOF | tee /etc/yum.repos.d/cri-o.repo
[cri-o]
name=CRI-O
baseurl=https://pkgs.k8s.io/addons:/cri-o:/prerelease:/main/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/addons:/cri-o:/prerelease:/main/rpm/repodata/repomd.xml.key
EOF이후 Container Runtime Engine인 cri-o의 yum repo 등록하고
dnf install -y container-selinuxpackage 종속성들 중 container-selinux를 우선적으로 설치한 뒤
dnf install -y cri-o kubelet kubeadm kubectlkubernetes, cri-o package를 설치하여준다.
systemctl start crio.service
systemctl enable kubelet --now이후 cri-o와 kubelet을 실행시켜주면 cluster bootstrap을 위한 준비가 완료된다.
Cluster bootstrap
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# sysctl params required by setup, params persist across reboots
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# Apply sysctl params without reboot
sudo sysctl --system이후 br_netfilter 모듈을 load하여주고
kubeadm initkubeadm init을 통해 kubernetes control-plane을 설치한다.
Trouble Shooting: The HTTP call equal to 'curl -sSL http://127.0.0.1:10248/healthz' returned error
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is not healthy after 4m0.002528672s
Unfortunately, an error has occurred:
The HTTP call equal to 'curl -sSL http://127.0.0.1:10248/healthz' returned error: Get "http://127.0.0.1:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled) 이 과정에서 위와 같은 오류가 발생하여
$ journalctl -u kubelet --no-pager -n 50
Feb 20 02:35:34 master systemd[1]: Started kubelet: The Kubernetes Node Agent.
Feb 20 02:35:34 master kubelet[7974]: Flag --container-runtime-endpoint has been deprecated, This parameter should be set via the config file specified by the Kubelet's --config flag. See https://kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file/ for more information.
Feb 20 02:35:34 master kubelet[7974]: Flag --pod-infra-container-image has been deprecated, will be removed in 1.35. Image garbage collector will get sandbox image information from CRI.
Feb 20 02:35:34 master kubelet[7974]: I0220 02:35:34.060640 7974 server.go:215] "--pod-infra-container-image will not be pruned by the image garbage collector in kubelet and should also be set in the remote runtime"
Feb 20 02:35:34 master kubelet[7974]: I0220 02:35:34.066157 7974 server.go:520] "Kubelet version" kubeletVersion="v1.32.2"
Feb 20 02:35:34 master kubelet[7974]: I0220 02:35:34.066311 7974 server.go:522] "Golang settings" GOGC="" GOMAXPROCS="" GOTRACEBACK=""
Feb 20 02:35:34 master kubelet[7974]: I0220 02:35:34.066621 7974 server.go:954] "Client rotation is on, will bootstrap in background"
Feb 20 02:35:34 master kubelet[7974]: I0220 02:35:34.067910 7974 certificate_store.go:130] Loading cert/key pair from "/var/lib/kubelet/pki/kubelet-client-current.pem".
Feb 20 02:35:34 master kubelet[7974]: I0220 02:35:34.072081 7974 dynamic_cafile_content.go:161] "Starting controller" name="client-ca-bundle::/etc/kubernetes/pki/ca.crt"
Feb 20 02:35:34 master kubelet[7974]: I0220 02:35:34.075878 7974 server.go:1444] "Using cgroup driver setting received from the CRI runtime" cgroupDriver="systemd"
Feb 20 02:35:34 master kubelet[7974]: I0220 02:35:34.079645 7974 server.go:772] "--cgroups-per-qos enabled, but --cgroup-root was not specified. defaulting to /"
Feb 20 02:35:34 master kubelet[7974]: I0220 02:35:34.079829 7974 swap_util.go:115] "Swap is on" /proc/swaps contents=<
Feb 20 02:35:34 master kubelet[7974]: Filename Type Size Used Priority
Feb 20 02:35:34 master kubelet[7974]: /dev/vda2 partition 6201340 0 -2
Feb 20 02:35:34 master kubelet[7974]: >
Feb 20 02:35:34 master kubelet[7974]: E0220 02:35:34.079864 7974 run.go:72] "command failed" err="failed to run Kubelet: running with swap on is not supported, please disable swap or set --fail-swap-on flag to false"
Feb 20 02:35:34 master systemd[1]: kubelet.service: Main process exited, code=exited, status=1/FAILURE
Feb 20 02:35:34 master systemd[1]: kubelet.service: Failed with result 'exit-code'.kubelet의 로그를 살펴본 결과
E0220 02:35:34.079864 7974 run.go:72] "command failed" err="failed to run Kubelet: running with swap on is not supported, please disable swap or set --fail-swap-on flag to false"위와 같이 Kubernetes가 swap이 활성화된 상태에서 실행되지 않기 때문에 발생한 문제를 파악하였다.
mount -a따라서 이전에 진행해주었지만 /etc/fstab를 다시 확인하고 저장한 이후 fstab을 mount -a를 통해 다시 로드해주었다.
$ systemctl restart kubelet
$ systemctl status kubelet
kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; preset: >
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Thu 2025-02-20 02:37:06 EST; 26ms ago
Docs: https://kubernetes.io/docs/
Main PID: 8171 (kubelet)
Tasks: 7 (limit: 36051)
Memory: 11.3M
CPU: 19ms
CGroup: /system.slice/kubelet.service
└─8171 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/boo>이후 위와 같이 kubelet 데몬이 정상 작동하는 것을 확인해준 이후
kubeadm reset -f
rm -rf /etc/kubernetes/
rm -rf /var/lib/etcd이전에 kubeadm init과정에서 설치된 모든 요소들을 리셋하고 제거해준 이후
kubeadm initkubeadm init으로 다시 control-plane을 구축할 수 있었다.
Cluster 설치 확인
kubeadm join 172.20.112.101:6443 --token kzn3b1.lqfuwz0bbdd7y5ex \
--discovery-token-ca-cert-hash sha256:57fb9d1378939e273ee653c73c40920a5dc0c0ea94f2c360be93d767154ef5f0control-plane을 구축이 완료되면 위와 같이 각 worker가 join할 때 사용할 수 있는 명령어를 확인할 수 있다.
mkdir ~/.kube
cp /etc/kubernetes/admin.conf .kube/config이후 kubectl 사용을 위해 /etc/kubernetes/admin.conf 파일을 .kube/config로 복사하고
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady control-plane 42s v1.32.2위와 같이 kubernetes가 설치된 상태를 확인할 수 있었다.
CNI Configuration
현재 control-plane의 status가 NotReady인 이유는 CNI를 설정해주지 않아서이다.
CNI(Container Network Interface)는 Kubernetes 클러스터 내에서 Pod 간의 네트워크를 관리하는 플러그인 시스템ㅇ이다. Kubernetes는 자체적인 네트워크 기능을 제공하지 않기 때문에, 별도의 CNI 플러그인을 설치해야 Pod 간의 통신이 가능하다.
| CNI 플러그인 | 주요 특징 | 장점 | 단점 |
|---|---|---|---|
| Flannel | 오버레이 네트워크 기반의 단순한 CNI | - 설정이 간단하고 가벼움 - 대부분의 환경에서 기본적인 네트워크 기능 제공 | - 기본적으로 네트워크 정책 지원 X - 대규모 트래픽 처리에 비효율적 |
| Calico | BGP 기반의 고성능 CNI | - 고성능 (네이티브 L3 라우팅) - 네트워크 정책(NetworkPolicy) 지원 - 보안 기능 (eBPF, 정책 제어 등) | - 설정이 비교적 복잡 - BGP 라우팅 이해 필요 |
| Cilium | eBPF 기반의 차세대 CNI | - eBPF 활용 (고성능, 보안 강화) - Kubernetes 네트워크 정책 및 서비스 메시 지원 - 서비스 간 가시성 제공 | - 상대적으로 설정이 어려움 - 기존 환경에서의 호환성 문제 가능 |
| Weave | 유저스페이스 기반의 네트워크 | - 간단한 설정 - 네트워크 정책 지원 | - 성능이 Flannel이나 Calico보다 낮음 |
| Canal | Flannel + Calico의 조합 | - Flannel의 간단함 + Calico의 네트워크 정책 기능 제공 | - 설정이 조금 복잡할 수 있음 |
CNI를 설치하기 이전 위와 같이 각 지원 가능한 CNI의 특징을 정리해준 이후 Flannel을 활용하는 것이 현재의 클러스터 구성에서는 가장 적합하다고 판단하였다.
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml따라서 위와 같이 kubectl apply를 통해 Flannel을 설정해주었지만
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-668d6bf9bc-bd9nk 0/1 ContainerCreating 0 19m
coredns-668d6bf9bc-ks9rr 0/1 ContainerCreating 0 19m
etcd-master 1/1 Running 1 19m
kube-apiserver-master 1/1 Running 1 19m
kube-controller-manager-master 1/1 Running 1 19m
kube-proxy-hg2xn 1/1 Running 0 19m
kube-scheduler-master 1/1 Running 1 19mcoredns Pod가 ContainerCreating 상태로 멈춰있는 것을 확인하였고 Flannel Pod 또한 생성되지 않은 것을 확인하였다.
Trouble Shooting:open /run/flannel/subnet.env: no such file or directory
$ kubectl describe pod -n kube-system coredns-668d6bf9bc-bd9nk
Warning FailedCreatePodSandBox 13s (x7 over 88s) kubelet (combined from similar events): Failed to create pod sandbox: rpc error: code = Unknown desc = failed to create pod network sandbox k8s_coredns-668d6bf9bc-ks9rr_kube-system_92f42788-93b1-4d78-9df1-ad2c3a3bca3d_0(fffee0f04c0cb8d55a191da0851f4e22d1331e7e2bd11491754991cbb29906e4): error adding pod kube-system_coredns-668d6bf9bc-ks9rr to CNI network "cbr0": plugin type="flannel" failed (add): loadFlannelSubnetEnv failed: open /run/flannel/subnet.env: no such file or directory이후 위와 같이 해당 Pod의 로그를 살펴보고 /run/flannel/subnet.env해당 파일을 열 수 없다는 로그를 확인할 수 있었다.
$ vim /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.0.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true따라서 우선 /run/flannel/subnet.env를 위와 같이 생성해주어
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-74fzj 0/1 CrashLoopBackOff 7 (23s ago) 11m
kube-system coredns-668d6bf9bc-bd9nk 1/1 Running 0 29m
kube-system coredns-668d6bf9bc-ks9rr 1/1 Running 0 29m
kube-system etcd-master 1/1 Running 1 30m
kube-system kube-apiserver-master 1/1 Running 1 30m
kube-system kube-controller-manager-master 1/1 Running 1 30m
kube-system kube-proxy-hg2xn 1/1 Running 0 29m
kube-system kube-scheduler-master 1/1 Running 1 30mcoredns Pod가 정상 작동하는 것은 확인했지만 kube-flannel Pod가 CrashLoopBackOff 상태가 되는 문제를 확인할 수 있었다.
Trouble Shooting: Flannel failed to acquire lease
$ kubectl logs -p kube-flannel-ds-74fzj -n kube-flannel
main.go:359] Error registering network: failed to acquire lease: node "master" pod cidr not assigned이후 해당 Pod의 로그에서 lease를 얻을 수 없다는 메세지를 확인할 수 있었다.
$ vim /etc/kubernetes/manifests/kube-controller-manager.yaml
...
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true # 추가
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=127.0.0.1
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-cidr=10.244.0.0/24 # 추가
...따라서 /etc/kubernetes/manifests/kube-controller-manager.yaml 설정 파일에 이전에 설정한 Flannel의 FLANNEL_NETWORK=10.244.0.0/16 환경변수 설정에 맞추어 Kubernetes의 Pod CIDR도 10.244.0.0/16 대역으로 맞추어주었다.
또한 Flannel이 Pod에 IP를 할당할 수 있게 --allocate-node-cidrs 파라미터도 true로 설정해주었다.
$ kubectl get pod --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-flannel kube-flannel-ds-74fzj 1/1 Running 13 (104s ago) 26m
kube-system coredns-668d6bf9bc-bd9nk 1/1 Running 0 44m
kube-system coredns-668d6bf9bc-ks9rr 1/1 Running 0 44m
kube-system etcd-master 1/1 Running 1 45m
kube-system kube-apiserver-master 1/1 Running 2 (6m15s ago) 45m
kube-system kube-controller-manager-master 1/1 Running 0 39s
kube-system kube-proxy-hg2xn 1/1 Running 0 44m
kube-system kube-scheduler-master 1/1 Running 2 (6m34s ago) 45m이후 모든 kube-system과 kube-flannel NS의 Pod이 정상 작동하는 것을 확인할 수 있었고
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master Ready control-plane 45m v1.32.2 172.20.112.101 <none> Rocky Linux 9.2 (Blue Onyx) 5.14.0-284.11.1.el9_2.x86_64 cri-o://1.33.0control-plane이 Ready 상태인 것도 확인할 수 있었다.
Worker Node Configuration
setenforce 0
# 방화벽 비활성화
systemctl stop firewalld
systemctl disable firewalld
# swap 해제
swapoff -a
vi /etc/fstabWorker Node를 설정하기 위해 위와 같이 SELINUX, 방화벽, SWAP을 모두 해제하여준다.
sudo tee /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.32/rpm/repodata/repomd.xml.key
EOF
sudo tee /etc/yum.repos.d/cri-o.repo <<EOF
[cri-o]
name=CRI-O
baseurl=https://pkgs.k8s.io/addons:/cri-o:/prerelease:/main/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/addons:/cri-o:/prerelease:/main/rpm/repodata/repomd.xml.key
EOF이후 Kubernetes 및 CRI-O 리포지토리 등록한다.
이때 Master Node와 동일한 버전의 패키지를 사용해 버전 불일치 문제를 피해야 한다.
dnf install -y container-selinux
dnf install -y cri-o kubelet kubeadm kubectl이후 위와 같이 필수 종속성 및 패키지를 설치하고
systemctl start crio.service
systemctl enable kubelet --now각 데몬을 실행시킨 이후
sudo tee /etc/modules-load.d/k8s.conf <<EOF
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilteroverlay 및 br_netfilter 모듈을 /etc/modules-load.d/k8s.conf에 등록한다.
sudo tee /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system이후 /etc/sysctl.d/k8s.conf 파일에 위 파라미터를 등록해주는데, 해당 설정은 Flannel과 같은 CNI가 정상 동작하기 위해 필요하다.
kubeadm join 172.20.112.101:6443 --token kzn3b1.lqfuwz0bbdd7y5ex \
--discovery-token-ca-cert-hash sha256:57fb9d1378939e273ee653c73c40920a5dc0c0ea94f2c360be93d767154ef5f0이후 Master Node에서 출력된 Token과 ca-cert-hash를 사용하여 Worker Node를 클러스터에 등록한다.
[preflight] Reading configuration from the "kubeadm-config" ConfigMap in namespace "kube-system"...
[preflight] Use 'kubeadm init phase upload-config --config your-config.yaml' to re-upload it.
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 1.001987077s
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.정상적으로 등록되었을 경우 위와 같은 메세지가 나오며
### MASTER
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-worker-1.novalocal Ready <none> 30s v1.32.2
master Ready control-plane 60m v1.32.2kubectl get nodes를 통해 Node를 확인할 수 있다.
이때 Worker Node에 별도의 role 레이블이 기본적으로 할당되지 않기 때문에 none으로 표시된다. Kubernetes에서는 control-plane 노드에는 자동으로 node-role.kubernetes.io/control-plane 레이블이 부여되지만, worker 노드는 기본적으로 역할 레이블이 없다.
kubectl label node k8s-worker-1.novalocal node-role.kubernetes.io/worker=따라서 위 명령어를 통해 Worker Node의 ROLE을 worker로 명시해줄 수 있다.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-worker-1.novalocal Ready worker 2m17s v1.32.2
master Ready control-plane 62m v1.32.2위와 같이 정상적으로 하나의 Control Plane과 하나의 k8s-worker-1 노드를 가진 K8s Cluster가 구축된 것을 볼 수 있다.
k8s-worker-2 Configuration
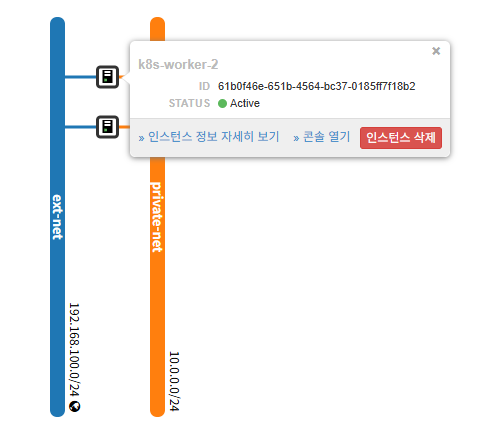
openstack server create \
--flavor k8s.worker \
--image "Rocky Linux 9 Generic Cloud" \
--nic net-id=$(openstack network list --name ext-net -f value -c ID) \
--nic net-id=$(openstack network list --name private-net -f value -c ID) \
--security-group default \
--key-name mykey \
k8s-worker-2이후 위와 같이 두번쨰 Woker Instance를 생성해준 뒤
ssh-keygen -R 192.168.100.29
ssh -i mykey.pem rocky@192.168.100.29ssh-keygen -R로 기존 Floating IP의 SSH 정보를 초기화하고
[root@master ~]# ping 192.168.100.29
PING 192.168.100.29 (192.168.100.29) 56(84) bytes of data.
64 bytes from 192.168.100.29: icmp_seq=1 ttl=62 time=3.45 ms
64 bytes from 192.168.100.29: icmp_seq=2 ttl=62 time=2.84 msmaster 노드에서 새롭게 생성된 인스턴스에 접속이 가능한지 확인한 이후
$ kubectl get nodes get node
NAME STATUS ROLES AGE VERSION
k8s-worker-1.novalocal Ready worker 12m v1.32.2
k8s-worker-2.novalocal Ready worker 48s v1.32.2
master Ready control-plane 72m v1.32.2worker node 설치 과정을 동일하게 반복하여 위와 같이 클러스터를 구축할 수 있었다.
Pod Deployment Test
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deployment
spec:
replicas: 4
selector:
matchLabels:
app: test
template:
metadata:
labels:
app: test
spec:
containers:
- name: busybox
image: busybox
command: ["sh", "-c", "echo Hello from $(hostname); sleep 3600"]
nodeSelector:
node-role.kubernetes.io/worker: ""Pod가 정상적으로 Deploy되는지 확인하기 위해 위와 같이 4개의 busybox Pod Replica를 생성하는 Deployment를 define하고
kubectl apply -f test-deployment.yamlkubectl apply를 통해 해당 Deployment를 생성하여준다.
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
test-deployment 4/4 4 4 14s이후 위와 같이 새롭게 생성된 4개의 Pod 모두 READY상태임을 확인할 수 있었고
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-deployment-6d998d9656-98jft 1/1 Running 0 21s 10.244.1.2 k8s-worker-1.novalocal <none> <none>
test-deployment-6d998d9656-rcxzk 1/1 Running 0 21s 10.244.1.3 k8s-worker-1.novalocal <none> <none>
test-deployment-6d998d9656-sjqj2 1/1 Running 0 21s 10.244.2.3 k8s-worker-2.novalocal <none> <none>
test-deployment-6d998d9656-tnn8l 1/1 Running 0 21s 10.244.2.2 k8s-worker-2.novalocal <none> <none>k8s-worker-1.novalocal, k8s-worker-2.novalocal Node에서 각 Pod들이 정상적으로 구동되는 것을 확인할 수 있었다.
기본적으로 control-plane 노드는 taint(node-role.kubernetes.io/control-plane:NoSchedule)가 설정되어 있어 일반적인 Pod는 스케줄되지 않는다.
따라서 현재 가용 가능한 리소스가 제한적인 상황이기 때문에 추후 서비스 운영을 위한 리소스가 부족해질 경우 아래와 같이 추가적으로 리소스를 확보할 계획이다.
Toleration 추가: 특정Pod에control-plane taint를 허용하는toleration을 추가하면control-plane에도 스케줄 가능Taint 제거: 만약control-plane에도 기본적으로Pod가 스케줄되길 원한다면,control-plane노드의taint를 제거
일반적으로는 control-plane에 Pod를 스케줄링하지 않는 것이 맞지만, K8s 호스트 머신에 유휴 리소스가 많이 존재하여 위와 같이 판단하였다.
Host Machine Full Backup
Openstack Cloud와 K8s Cluster를 모두 구축한 이후 추후 프로젝트를 진행하기 전 전체 디스크를 Full Backup해두어 만약의 상황을 방지하고자 하였다.
[root@openstack-host ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 931.5G 0 disk
├─sda1 8:1 0 529M 0 part
├─sda2 8:2 0 100M 0 part
└─sda3 8:3 0 930.9G 0 part
nvme0n1 259:0 0 476.9G 0 disk
├─nvme0n1p1 259:1 0 1G 0 part /boot
└─nvme0n1p2 259:2 0 475.9G 0 part
├─rl-root 253:0 0 70G 0 lvm /
├─rl-swap 253:1 0 7.8G 0 lvm [SWAP]
└─rl-home 253:2 0 398.1G 0 lvm /home
[root@openstack-host ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 7.7G 0 7.7G 0% /dev/shm
tmpfs 3.1G 9.5M 3.1G 1% /run
/dev/mapper/rl-root 70G 32G 38G 46% /
/dev/nvme0n1p1 1014M 595M 420M 59% /boot
/dev/mapper/rl-home 398G 19G 380G 5% /home
tmpfs 1.6G 4.0K 1.6G 1% /run/user/1000
tmpfs 1.6G 4.0K 1.6G 1% /run/user/0[root@kubernetes-host ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
nvme0n1 259:0 0 476.9G 0 disk
├─nvme0n1p1 259:1 0 1G 0 part /boot
└─nvme0n1p2 259:2 0 475.9G 0 part
├─rl-root 253:0 0 70G 0 lvm /
├─rl-swap 253:1 0 7.8G 0 lvm [SWAP]
└─rl-home 253:2 0 398.2G 0 lvm /home
[root@kubernetes-host ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 3.7G 0 3.7G 0% /dev/shm
tmpfs 1.5G 9.2M 1.5G 1% /run
/dev/mapper/rl-root 70G 5.8G 65G 9% /
/dev/nvme0n1p1 1014M 459M 556M 46% /boot
/dev/mapper/rl-home 398G 5.2G 393G 2% /home
tmpfs 756M 4.0K 756M 1% /run/user/0우선 위와 같이 lsblk와 df -h를 통해 현재 어떠한 디스크에 Rocky Linux가 설치되어있는지 파악한 이후
mkdir /home/backup
sudo dd if=/dev/nvme0n1 bs=64K conv=sync,noerror | gzip -c > /home/backup/250221-backup-nvme0n1.img.gz각각의 호스트에서 dd를 사용해 gzip을 통해 압축하며 이를 백업할 수 있도록 하였다.
if=/dev/nvme0n1: 백업 대상 디스크bs=64K: 블록 사이즈conv=sync,noerror: 에러 발생 시에도 가능한 한 계속 진행gzip -c: 표준 입력을 받아 압축/home/backup/250221-backup-nvme0n1.img.gz: 백업 이미지를 /home/backup/ 디렉터리에 저장
scp /backup/backup-nvme0n1.img.gz <Windows계정>@<WindowsIP>:/경로/전체 디스크를 백업하는 만큼 3시간 이상의 시간이 소요되었으며, 백업이 완료된 이후 위와 같이 해당 img.gz 파일을 현재 사용하고 있는 Window Host에도 별도로 저장해두었다.
Future Plan
 현재 Auth가 존재하지 않는
현재 Auth가 존재하지 않는 v1.0이 개발되고 BE 서버가 Public Cloud를 통해 배포되고 있는 상황에서 위와 같이 기능하고 있다.
 현재 FE 개발자분께 Google Analytics 적용을 통해 사용자 지표를 얻을 수 있도록 작업을 부탁드린 상황이며 우선 위와 같이 인스타그램을 통해 홍보하였다.
현재 FE 개발자분께 Google Analytics 적용을 통해 사용자 지표를 얻을 수 있도록 작업을 부탁드린 상황이며 우선 위와 같이 인스타그램을 통해 홍보하였다.
추후 홍보 또한 대대적으로 진행할 계획을 가지고 있으며 현 시점의 Infra의 관점에서의 계획은 아래와 같다.
✅ Private Cloud (K8s Cluster)를 통해 배포
✅ Public DNS 관련 설정 및 HTTPS 연결을 위한 SSL 설정
✅ 부하 테스트 진행
✅ HA Cluster 구축을 위한 방안 마련
✅ K8s Prometheus + Grafana 모니터링 인프라 구축
✅ Private Cloud 내 ELK 구축을 통한 로깅 인프라 구축
✅ 로깅 인프라 데이터 별도 학습 및 AIOps를 위한 데이터 수집
✅ AIOps 구축 및 별도 인공지능 모델 서빙 인프라 구성 (리소스 가용 가능시)또한 현재 서비스는 아래 링크에서 사용이 가능하다.
