
Landing Page Modification
서비스 운영을 위해 기존 랜딩 페이지의 연락처 탭인 Footer를 수정하고자 하였다.
//연락처 탭
const Footer = () => (
<footer className={`
h-[9rem] bg-[#171717] place-items-center
grid grid-cols-3 grid-rows-2 gap-4 w-full p-4
text-center text-[#BDBDBD] text-center
font-pretendard font-medium text-[1.4rem] leading-[1.6em]
`}>
<div className="">연락처정보</div>
<div className="">연락처정보</div>
<div className="">연락처정보</div>
<div className="">연락처정보</div>
<div className="">연락처정보</div>
</footer>
);위와 같이 개발을 시작하기 이전 FE, 디자인 팀원분께 별도로 레이아웃만 부탁드린 상태였으므로 저작권과 공식 팀 연락처를 기재하고자 한다.
Copyright stipulation
제10조(저작권)
①저작자는 제11조부터 제13조까지에 따른 권리(이하 “저작인격권”이라 한다)와 제16조부터 제22조까지에 따른 권리(이하 “저작재산권”이라 한다)를 가진다. <개정 2023. 8. 8.>
②저작권은 저작물을 창작한 때부터 발생하며 어떠한 절차나 형식의 이행을 필요로 하지 아니한다.
https://www.law.go.kr/%EB%B2%95%EB%A0%B9/%EC%A0%80%EC%9E%91%EA%B6%8C%EB%B2%95
대한민국 저작권법 제10조 2항에 따라 저작권은 창작과 동시에 자동으로 발생하므로 저작권 공지를 별도로 표기하지 않아도 보호받는다.
© 2025 언제볼까. All rights reserved.하지만 위와 같이 표기하여 저작권이 있음을 명확히 알리고, 저작권 침해를 방지하고자 한다.
이를 표기함으로써 아래와 같은 침해 방지 효과가 존재한다.
-
법적 보호의 고지
저작권 표기를 통해 콘텐츠가 법적 보호를 받고 있음을 명확히 하여, 제3자가 무단 복제, 전재, 배포, 번역 또는 2차적 저작물 제작 등 저작권 침해 행위를 하는 것을 경고하는 효과가 있음 -
침해 발생 시 증거 자료 제공
저작권 표기는 저작권자가 자신의 저작물을 보호받기 위한 의지를 명시하는 역할을 하며, 분쟁 발생 시 침해 행위에 대한 대응 및 법적 조치를 취할 수 있는 근거 자료로 활용될 수 있음 -
식별 정보 활용
도메인(https://when-will-we-meet.site/)과 업무 이메일(whenwillwemeet.dev@gmail.com)은 저작권자에 대한 추가 식별 정보를 제공하여, 저작물의 무단 사용 시 신속하게 연락 및 대응할 수 있는 기반을 마련함
const Footer = () => (
<footer className={`
h-[9rem] bg-[#171717] place-items-left
grid grid-cols-1 grid-rows-3 gap-2 w-full p-4
text-left text-[#BDBDBD] text-left
font-pretendard font-medium text-[1.4rem] leading-[1.6em]
`}>
<div>대표자: 민상연</div>
<div>대표 메일: whenwillwemeet.dev@gmail.com</div>
<div> © 2025 언제볼까. All rights reserved.</div>
</footer>
); 따라서 위와 같이 랜딩페이지를 수정하였다.
따라서 위와 같이 랜딩페이지를 수정하였다.
이때 위 표현은 대표자 명이 아닌 서비스명으로 귀속하는 것이기에 저작권을 "언제볼까"라는 이에 대한 법적 절차(ex. 권리 이전 계약, 법인 설립 등)를 고려해야 한다.
다만 현재 오픈소스 기록 등으로 충분한 개발 증빙을 갖추고 있기에, 서비스명으로 저작권 고지를 하는 방식도 법적으로 효력이 있을 수 있어 현 상황도 충분하다고 판단하였다.
Public Domain
Architecture
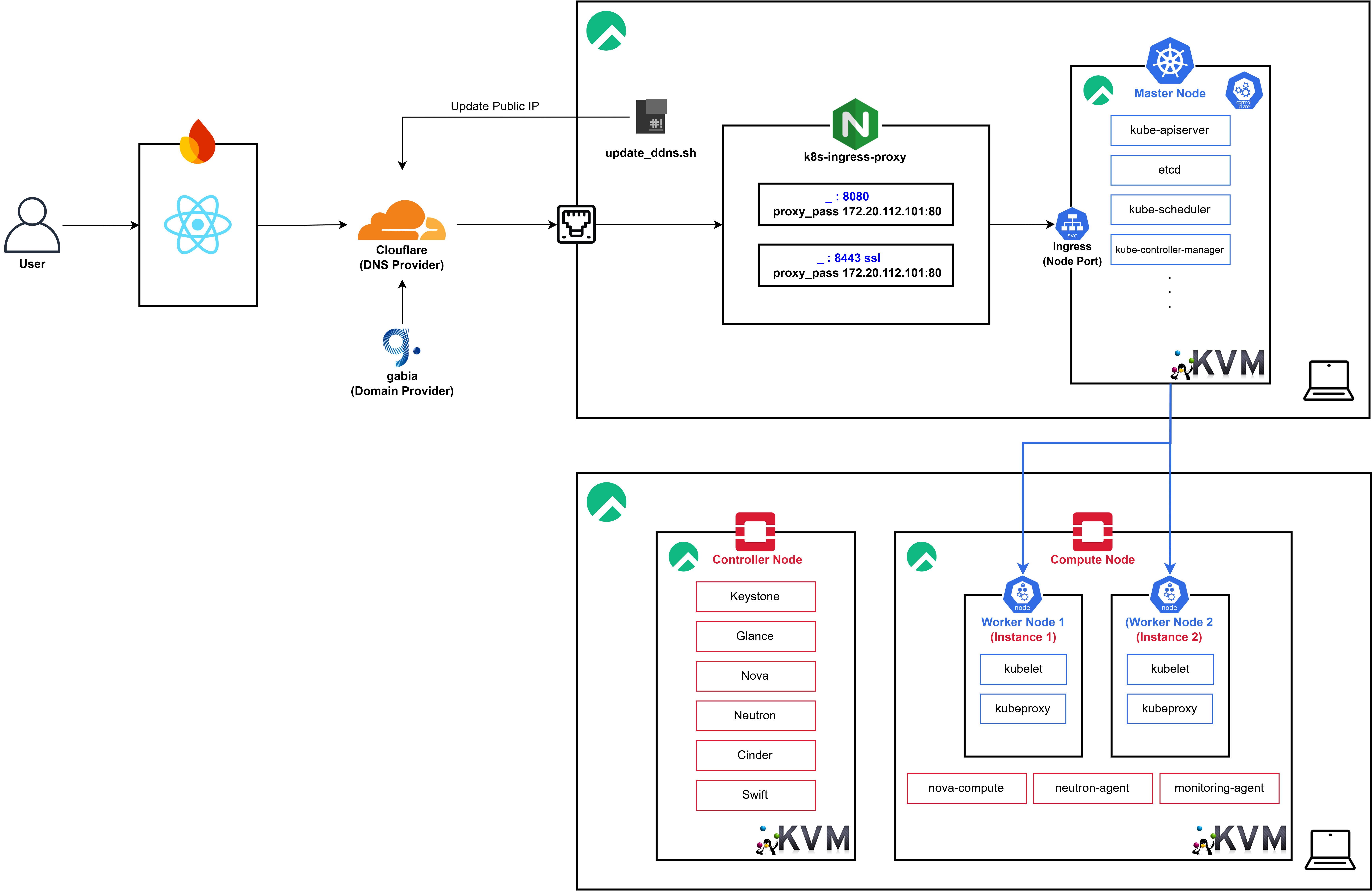 이전까지 K8s 구축을 마치고 유선 LAN을 통해 연결된 환경에서 정상적으로 작동하는 것을 확인한 이후 실 서비스를 위해 위와 같이
이전까지 K8s 구축을 마치고 유선 LAN을 통해 연결된 환경에서 정상적으로 작동하는 것을 확인한 이후 실 서비스를 위해 위와 같이 Cloudflare를 통해 Public Domain 연결을 진행해주었다.
DDNS (Dynamic Domain Name System)
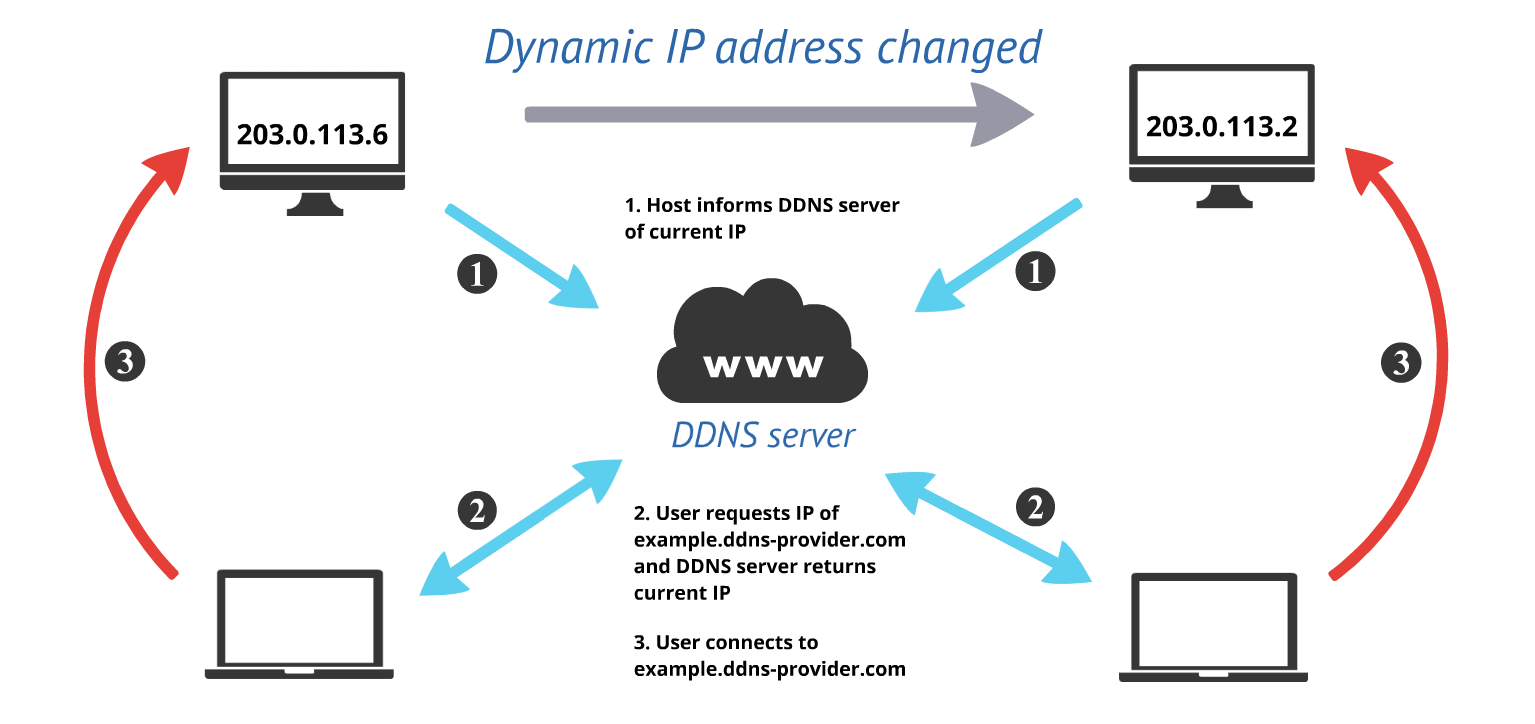
DDNS(Dynamic Domain Name System)는 IP 주소가 동적으로 변경되는 환경에서도 특정 도메인 이름을 지속적으로 해당 IP 주소와 연결해 주는 시스템
현재 별도의 AP없이 바로 호스트 머신들이 유선으로 연결되어 있는 형태이기에 별도로 각 호스트에 Static IP를 할당해주는 것은 어렵다고 판단하였다.
일반적으로DDNS를 통해 아래 과정을 거쳐 동적인 주소를 도메인에 연결해줄 수 있다.
- 클라이언트는
DDNS서비스 Provider에 가입하고, 고정된 도메인 이름을 설정 DDNS클라이언트 소프트웨어를 실행하여 현재의Public IP주소를DDNS서버로 전송DDNS서버는 해당 도메인의A 레코드(IPv4)또는AAAA 레코드(IPv6)를 업데이트- 사용자는 언제든지 동일한 도메인 주소로 접속 가능
A 레코드 - 도메인을 IPv4 주소와 매핑하는 레코드
AAAA 레코드 - 도메인을 IPv6 주소와 매핑하는 레코드
CNAME 레코드 - 도메인을 다른 도메인으로 연결하는 별칭(alias) 레코드
MX 레코드 - 이메일을 수신할 메일 서버를 지정하는 레코드
TXT 레코드 - 도메인에 대한 텍스트 정보를 저장하는 레코드 (예: SPF, DKIM)
NS 레코드 - 도메인의 네임서버를 지정하는 레코드
SRV 레코드 - 특정 서비스의 위치(호스트, 포트)를 지정하는 레코드
PTR 레코드 - IP 주소를 도메인으로 변환하는 역방향 DNS 레코드
SOA 레코드 - 도메인의 기본 정보(네임서버, 관리자 이메일 등)를 포함하는 레코드
CAA 레코드 - 특정 CA(Certificate Authority)만 SSL 인증서를 발급하도록 제한하는 레코드
DNSSEC 레코드 - 도메인의 보안 강화를 위한 인증 정보(DNSKEY, DS, RRSIG 등)를 저장하는 레코드
DDNS 특징
-
동적 IP 주소와 DNS 연결 유지
인터넷 서비스 제공업체(ISP)는 일반적으로 가정용 및 일부 기업용 네트워크에동적 IP를 할당DDNS는 이러한동적 IP주소 변경을 자동으로 감지하고, 미리 설정한 도메인과 매핑하여 유지
-
자동 업데이트 방식
DDNS 클라이언트 소프트웨어가 주기적으로현재 IP 주소를 확인하고, 변경이 감지되면DDNS 서버로 업데이트를 요청- 이를 통해 사용자는 항상 동일한 도메인 이름을 통해 네트워크에 접속할 수 있음
-
주요 사용 사례
원격 접속: 가정용 또는 소규모 기업용 서버(예: CCTV, NAS, 웹 서버)에 접속할 때 활용게임 및 스트리밍 서버: 개인 서버 운영 시 IP 주소 변경에 대응IoT 및 VPN: 원격지 장비 관리 및 VPN 서버 운영
DDNS 사용 이유
- 동적 IP 환경에서도 고정 도메인 사용 가능
- 원격 서버, NAS, CCTV 등에 안정적 접속 지원
- 고정 IP 비용 절감 효과
- 인터넷 회선이 변경되더라도 자동 업데이트 가능
DDNS Service Provider
| 서비스 | 특징 | 장점 | 단점 |
|---|---|---|---|
| No-IP | 무료 및 유료 플랜 제공, 전용 클라이언트(DDNS Updater) 지원 | 무료 플랜 지원, 다양한 플랫폼에서 사용 가능 | 무료 플랜은 30일마다 수동 갱신 필요 |
| DynDNS | 상업용 DDNS 서비스, 안정적인 업데이트 지원 | 신뢰성이 높고 기업용 서비스 제공 | 대부분 유료, 개인 사용자에게 부담될 수 있음 |
| DuckDNS | 간단한 API 기반 무료 DDNS 서비스 | 완전 무료, API 및 스크립트(cron + curl) 활용 가능 | 도메인 선택이 제한적이며, UI가 단순함 |
| FreeDNS (Afraid.org) | 다양한 무료 도메인 제공, 동적 업데이트 지원 | 여러 도메인 옵션 제공, 무료 사용 가능 | UI가 직관적이지 않고 설정이 다소 복잡함 |
| Cloudflare DDNS | Cloudflare API를 활용한 동적 DNS 업데이트 | 무료 플랜 제공, 강력한 보안 및 빠른 네트워크 | 직접 API 설정이 필요하며, 자체 도메인이 있어야 함 |
또한 각 DDNS Service Provider의 특징과 장단점은 위와 같다.
현재 AWS를 활용하여 가비아를 통해 별도의 Domain을 구매해 활용하고 있기 때문에 이와 유사하게 도메인 자체를 구매하는 것이 아닌 이미 구매한 도메인에 대한 DNS 설정을 가능하게 하는 Cloudflare를 선택하였다.
Cloudfare API
Cloudflare는 보안, 성능 최적화, 네트워크 안정성을 제공하는 글로벌 CDN(Content Delivery Network) 및 DNS 서비스 제공업체
웹사이트 보호, DDoS 방어, 빠른 네트워크 라우팅, DNS 관리 등 다양한 기능을 제공하며, 무료 및 유료 플랜을 운영하고 있음
Rocky Linux에서 Cloudflare API를 활용해 DDNS를 구현하면, 별도의 전용 DDNS 클라이언트 없이도 주기적으로 공인 IP를 확인하고 DNS 레코드를 업데이트할 수 있다.
https://developers.cloudflare.com/fundamentals/setup/account/create-account/
따라서 우선 위 링크를 통해 Cloudflare 서비스에 회원가입을 진행하였다.
 햔재 Firebase 및 Google Analytics 계정이 관리되고 있는
햔재 Firebase 및 Google Analytics 계정이 관리되고 있는 whenwillwemeet.dev 계정을 통해 가입을 진행하고
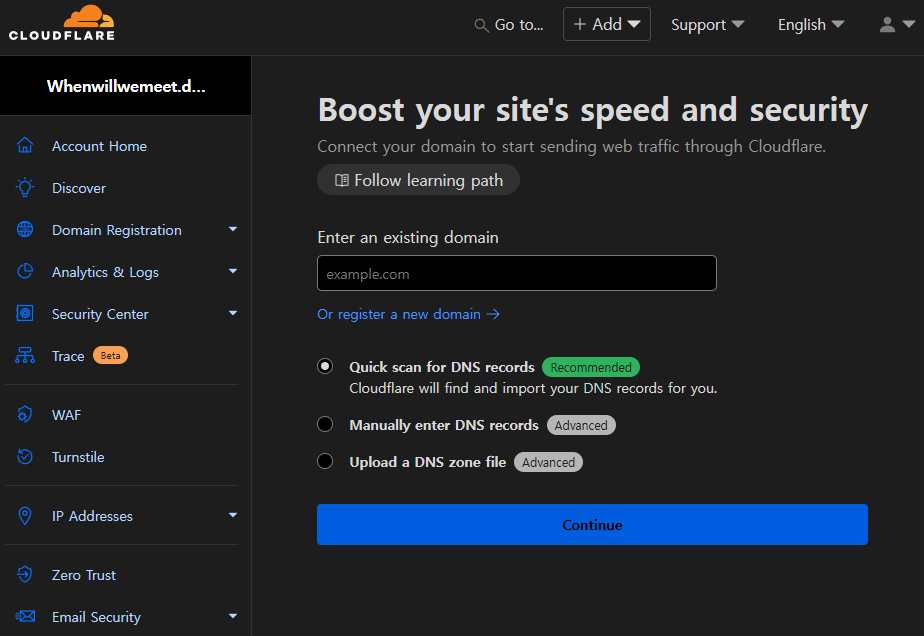
“Add a Site” 항목에서 도메인 입력하고 스캔한다.
스캔이 완료되면 스캔된 레코드를 확인 후 설정을 완료한다.
이후 Cloudflare는 해당 도메인을 위해 새로운 네임서버(ex. ns1.cloudflare.com, ns2.cloudflare.com 등)를 제공하게 된다.

이후 Gabia 계정에 로그인하고, 구매한 도메인의 DNS 관리 메뉴로 이동한다.
기존 네임서버를 Cloudflare에서 제공한 네임서버로 변경하여 Cloudflare에서 해당 도메인을 관리할 수 있도록 한다.
이때 네임서버 변경 후 전파까지 몇 시간이 소요될 수 있다.
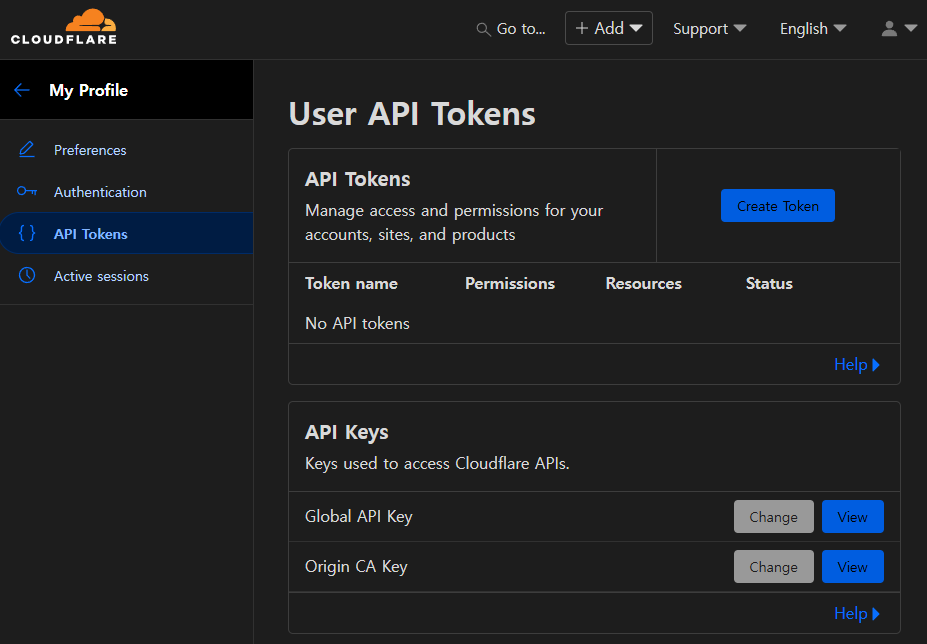
Cloudflare API를 활용할 수 있도록 위와 같이 API Token 항목에서 새로운 토큰을 생성한다.
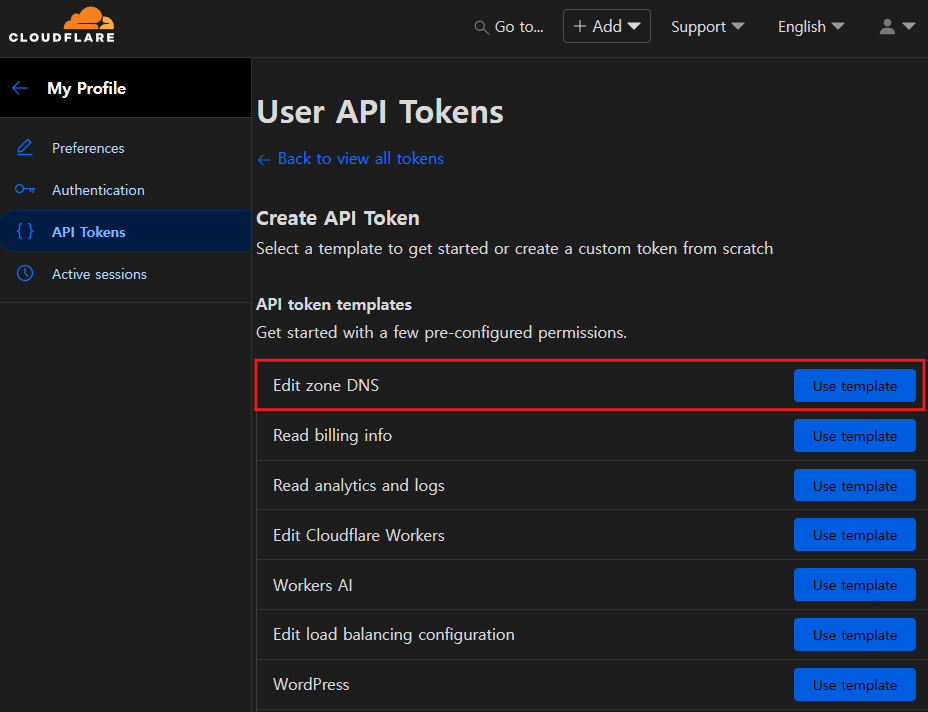 이때
이때 Edit Zone DNS 템플릿을 사용하여 토큰을 생성하여야 한다.
[root@kubernetes-host ~]# curl -X GET "https://api.cloudflare.com/client/v4/user/tokens/verify" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type:application/json"
{"result":{"id":"...","status":"active"},"success":true,"errors":[],"messages":[{"code":10000,"message":"This API Token is valid and active","type":null}]}토큰이 생성된 이후 kubernetes-host에서 생성한 토큰에 대한 직접적인 요청이 가능한지 확인한다.
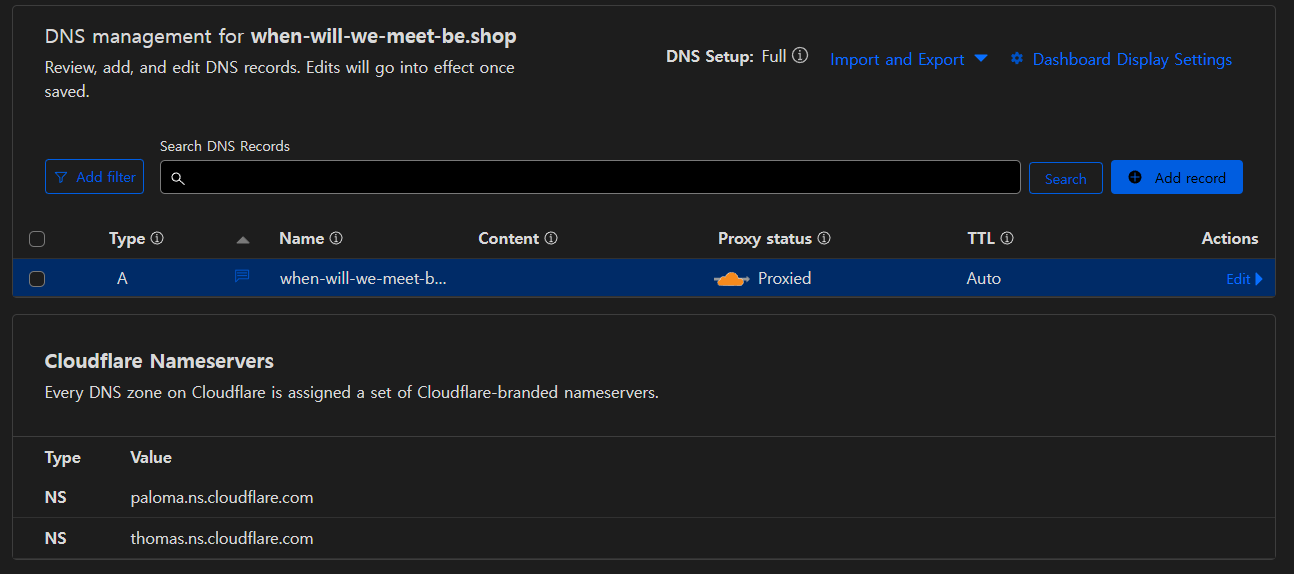 최초 1회는 수동으로 현재 공인 IP에 대한
최초 1회는 수동으로 현재 공인 IP에 대한 A 레코드를 생성하여준다.
vim update_ddns.sh#!/bin/bash
# Cloudflare API 설정
ZONE_ID="..." # Cloudflare에서 확인한 Zone ID
RECORD_ID="..." # 업데이트할 A 레코드의 Record ID
CF_API_TOKEN="..." # 생성한 API 토큰
CF_RECORD="..."
TTL=120 # DNS TTL (초)
# 현재 공인 IP 확인 (api.ipify.org 사용)
CURRENT_IP=$(curl -s https://api.ipify.org)
# Cloudflare에 등록된 현재 IP 조회
DNS_IP=$(curl -s -X GET "https://api.cloudflare.com/client/v4/zones/${ZONE_ID}/dns_records/${RECORD_ID}" \
-H "Authorization: Bearer ${CF_API_TOKEN}" \
-H "Content-Type: application/json" | jq -r '.result.content')
if [ "$CURRENT_IP" != "$DNS_IP" ]; then
echo "[CLOUDFLARE_UPDATE_DDNS] IP change detected: $DNS_IP -> $CURRENT_IP"
# Cloudflare에 A 레코드 업데이트 요청
# (proxied: false는 필요에 따라 true로 변경 가능)
RESPONSE=$(curl -s -X PUT "https://api.cloudflare.com/client/v4/zones/${ZONE_ID}/dns_records/${RECORD_ID}" \
-H "Authorization: Bearer ${CF_API_TOKEN}" \
-H "Content-Type: application/json" \
--data "{\"type\":\"A\",\"name\":\"${CF_RECORD}\",\"content\":\"${CURRENT_IP}\",\"ttl\":${TTL},\"proxied\":false}")
echo "[CLOUDFLARE_UPDATE_DDNS] Upadte Respone : $RESPONSE"
else
echo "[CLOUDFLARE_UPDATE_DDNS] Nothing updated, Current IP: $CURRENT_IP"
fi이후 위와 같이 Shell Script를 작성한다.
해당 스크립트는 현재 공인 IP를 확인하고 Cloudflare API를 통해 Cloudflare에 등록된 현재 IP 조회한 후 만약 [ "$CURRENT_IP" != "$DNS_IP" ]라면 Cloudflare에 A 레코드 업데이트 요청을 보내 최신화해줄 수 있는 즉, 일종의 DDNS 클라이언트 역할을 하는 스크립트이다.
chmod +x update_ddns.sh이후 해당 스크립트 파일에 실행 권한을 부여해주고
[root@kubernetes-host ~]# ./update_ddns.sh
[CLOUDFLARE_UPDATE_DDNS] Nothing updated, Current IP: 121.xxx.xxx.xxx스크립트가 정상 작동하는지 확인한다.
이전에 수동으로 A 레코드를 입력하였기 때문에, Nothing updated 메세지를 볼 수 있다.
mkdir ddns
mv update_ddns.sh ddns/이후 위와 같이 새로운 디렉터리를 생성해주고 해당 스크립트를 옮겨준 뒤
$ crontab -e
*/5 * * * * /root/ddns/update_ddns.sh >> /var/log/ddns_update.log 2>&1crontab을 수정하여 5분마다 스크립트를 실행해줄 수 있도록 하였다.
 이후 위와 같이 등록된 도메인으로 해당 호스트 머신의 nginx에 정상적으로 접근이 가능한 것을 확인할 수 있었으며
이후 위와 같이 등록된 도메인으로 해당 호스트 머신의 nginx에 정상적으로 접근이 가능한 것을 확인할 수 있었으며
 현재 배포되고 있는 서버에도 정상 접근이 가능한 것을 확인할 수 있었다.
현재 배포되고 있는 서버에도 정상 접근이 가능한 것을 확인할 수 있었다.
Resolve HTTPS Connection

하지만 기존 Host의 nginx은 HTTP에 대한 요청에만 응답하도록 설정되어 있었기 때문에, HTTPS에 대해서는 ERR_SSL_PROTOCOL_ERROR를 응답하는 것을 볼 수 있었다.
-
SSL Termination
- 외부 클라이언트와의 연결에서
SSL 인증서를 이용해암호화된 HTTPS연결을 처리 Host의nginx가HTTPS요청을 받아 암호 해제 후, 내부 네트워크(Kubernetes NodePort)로는 HTTP 요청으로 전달
- 외부 클라이언트와의 연결에서
-
내부 통신
Kubernetes master node와 클러스터 내의 노드 간 통신은내부 네트워크에서 운영되므로,SSL적용 여부와 무관하게 정상 작동- 일반적으로
SSL Termination를Ingress나외부 게이트웨이에서 처리한 후내부 통신은 보안 네트워크에서HTTP로 운용하는 것이 일반적 - 따라서 현재 인터넷으로의 Bridge 역할을 하는
Host에만SSL설정
 이를 설정해주기 위해 위와 같이
이를 설정해주기 위해 위와 같이 Cloudflare에서 해당 도메인에 대한 SSL 인증서를 생성해준다.
mkdir /etc/ssl/private
vim /etc/ssl/certs/when-will-we-meet-be.shop.crt
vim /etc/ssl/private/when-will-we-meet-be.shop.key이후 생성된 인증서를 /etc/ssl/certs/when-will-we-meet-be.shop.crt로, 개인키를 /etc/ssl/private/when-will-we-meet-be.shop.key로 저장하여 Host 머신에서 사용할 수 있게 한다.
이때 Cloudflare Origin Certificate는 오직 Cloudflare와의 프록시 연결을 위해 설계되었으며 직접 Origin 서버에 접근할 경우 브라우저에서 신뢰하지 않을 수 있으므로, 반드시 Cloudflare 프록시를 통해 접속되도록 구성해야 한다.
# HTTP 서버 블록 (직접 접근시 활용)
server {
listen 8080;
server_name _;
location / {
proxy_pass http://172.20.112.101;
proxy_set_header Host wwwm-spring-be.com;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
# HTTPS 서버 블록 (Cloudflare Public DNS 접근시 활용)
server {
# 8443 포트로 접근
listen 8443 ssl;
server_name _;
ssl_certificate /etc/ssl/certs/when-will-we-meet-be.shop.crt;
ssl_certificate_key /etc/ssl/private/when-will-we-meet-be.shop.key;
location / {
proxy_pass http://172.20.112.101;
proxy_set_header Host wwwm-spring-be.com;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}인증서 설정을 끝마친 이후 vim /etc/nginx/conf.d/k8s-ingress-proxy.conf에 HTTPS 서버 블록을 추가하면
 위와 같이 정상적으로 접속이 이루어지는 것을 볼 수 있으며
위와 같이 정상적으로 접속이 이루어지는 것을 볼 수 있으며
[root@master k8s]# kubectl logs wwwm-spring-be-deployment-76fbc5d5f6-2v292
...
2025-03-01T11:20:01.874Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-4] o.e.w.controller.IndexController : [IndexController]-[index] User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36kubectl logs를 통해 로그를 확인할 수 있다.
Trouble Shooting: ERR_CERT_AUTHORITY_INVALID
이는 Cloudflare Origin 인증서는 Cloudflare와의 통신에는 사용되지만, 브라우저에서는 신뢰되지 않기 때문에 발생하는 문제이다.
dnf install -y certbot python3-certbot-nginx따라서 Let's Encrypt를 활용하여 인증서를 발급받기 위해 위 패키지들을 설치한다.
certbot --nginx -d <yourdomain.com>
...
This certificate expires on 2025-06-02.
These files will be updated when the certificate renews.
Certbot has set up a scheduled task to automatically renew this certificate in the background.이후 위와 같이 도메인에 맞춰 인증서를 발급받고
ssl_certificate /etc/letsencrypt/live/yourdomain.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/yourdomain.com/privkey.pem;발급 후, nginx HTTPS 서버 블록에서 인증서 경로를 위와 같이 업데이트한다.
systemctl reload nginx이후 nginx 데몬을 reload해주면
 인증서가 정상적으로 적용된 것을 확인할 수 있고
인증서가 정상적으로 적용된 것을 확인할 수 있고
 이전에 발생한 SSL 관련 오류가 정상적으로 해결되어, 서비스가 정상 작동하는 것을 볼 수 있다.
이전에 발생한 SSL 관련 오류가 정상적으로 해결되어, 서비스가 정상 작동하는 것을 볼 수 있다.
24/365 IDC 구축
IDC(Internet Data Center)는 대량의 서버, 네트워크 장비, 스토리지 등 IT 인프라를 운영 및 관리하는 시설을 의미
IDC는 인터넷 서비스 제공업체(ISP), 기업, 클라우드 서비스 업체 등이 데이터를 저장하고 안정적인 네트워크 서비스를 제공하기 위해 사용
 실제 IDC의 형태는 아니지만 현재 구축한 Openstack 클라우드와 K8s 클러스터를 24/365 운영하기 위해서 위와 같이 별도의 공간에 호스트 머신들을 설치하여주었으며, L2 Switch를 통해 네트워크를 제공해주었다.
실제 IDC의 형태는 아니지만 현재 구축한 Openstack 클라우드와 K8s 클러스터를 24/365 운영하기 위해서 위와 같이 별도의 공간에 호스트 머신들을 설치하여주었으며, L2 Switch를 통해 네트워크를 제공해주었다.
또한 발열로 인한 기기 손상 및 처리 속도 감소 방지를 위해 별도의 쿨링 팬들또한 설치해주었다.
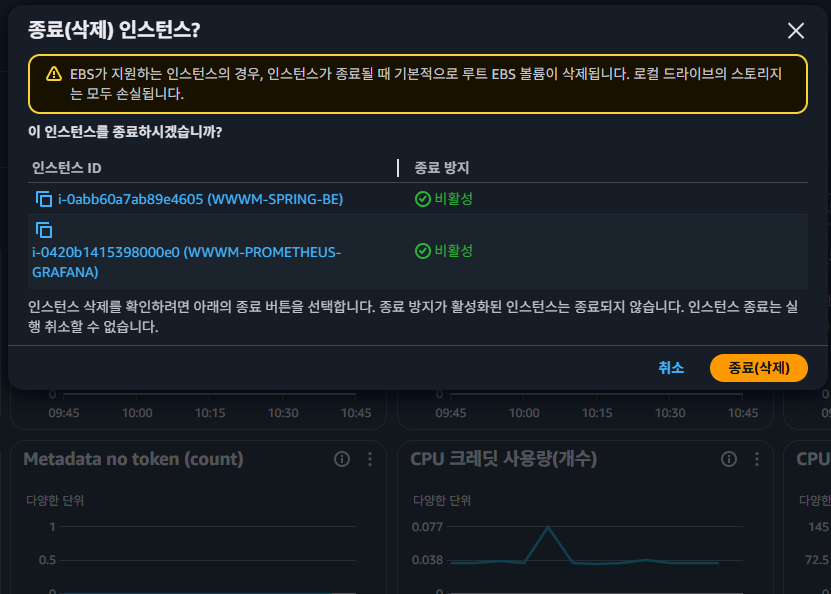
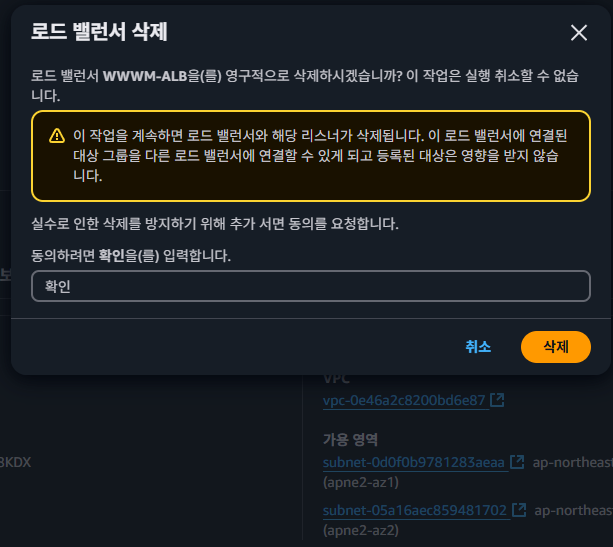 이후 위와 같이 이전에 서비스 운영을 위해 사용하고 있었던 AWS의 서비스들을 모두 삭제하고
이후 위와 같이 이전에 서비스 운영을 위해 사용하고 있었던 AWS의 서비스들을 모두 삭제하고
 이를 팀원분들께 공지하여, 본격적으로 약 2개월동안 구축한 클러스터를 통해 실제 서비스를 운영할 준비를 마쳤다.
이를 팀원분들께 공지하여, 본격적으로 약 2개월동안 구축한 클러스터를 통해 실제 서비스를 운영할 준비를 마쳤다.
Prometheus Stack Configuration
이후 안정적인 운영을 위한 모니터링 인프라 구축을 위해 Helm을 통해 K8s 클러스터에 Prometheus Stack을 설치하고자 하였다.
Helm
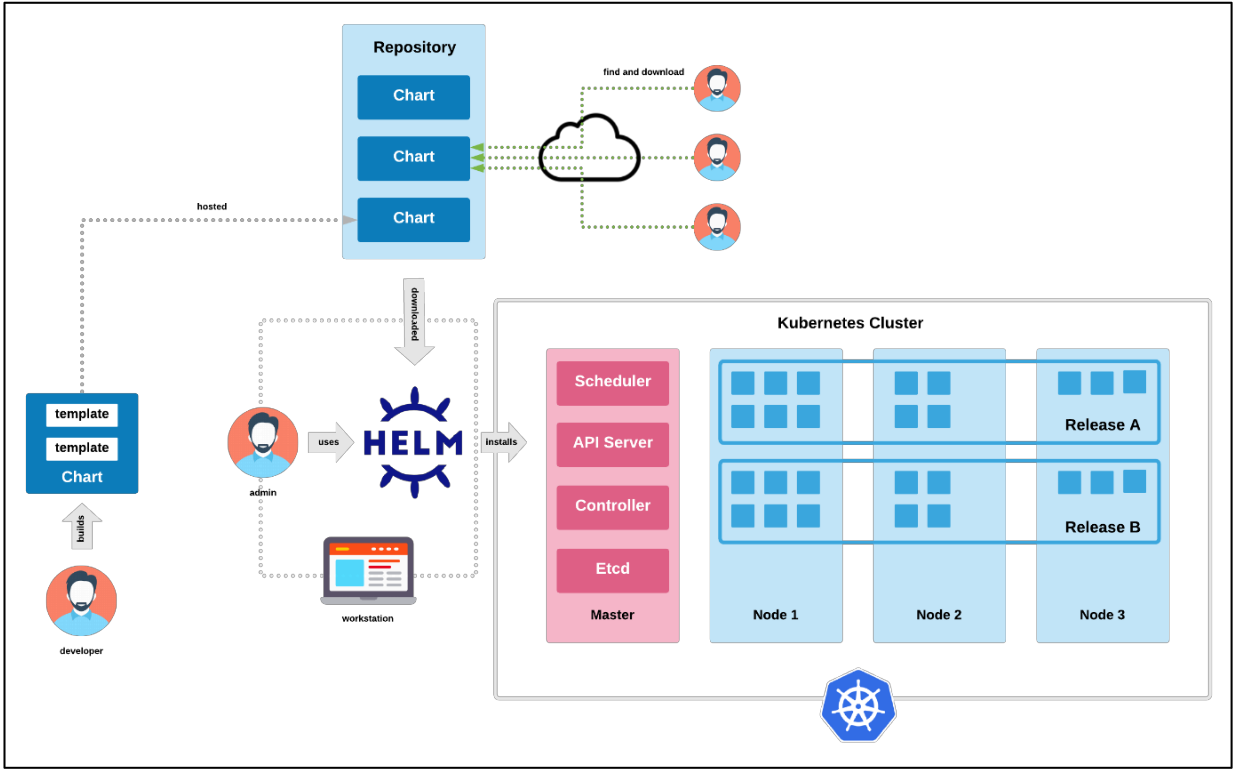
Helm은 Kubernetes 애플리케이션을 쉽고 효율적으로 배포, 관리 및 업그레이드할 수 있도록 해주는 패키지 관리자이다.
마치 리눅스의 apt(Debian/Ubuntu)나 yum(RHEL/CentOS)처럼 Kubernetes 환경에서 애플리케이션의 설치와 관리를 자동화하는 역할을 한다.
1. Helm Chart
Kubernetes 리소스(Deployment, Service, ConfigMap 등)를 템플릿화한 패키지- 하나의
Chart에는 애플리케이션을 배포하는 데 필요한 모든 설정이 포함 - 공식 및 커뮤니티 제공
Chart 저장소를 통해 쉽게 애플리케이션 배포 가능
2. Chart Repository
Helm Chart를 저장하고 공유할 수 있는 원격 또는 로컬 저장소- 대표적인 공식 Chart 저장소는
Helm Hub또는Artifact Hub
3. Values.yaml
Chart의 설정값을 정의하는 파일- 사용자 맞춤 설정을 위해 재정의 가능 (
--set옵션 사용 가능)
4. Release
- 특정 버전의
Helm Chart를Kubernetes 클러스터에 배포한 인스턴스 helm install명령을 통해 생성되고,helm upgrade로 업데이트 가능
주요 명령어
| 명령어 | 설명 |
|---|---|
helm repo add <이름> <URL> | Helm 저장소를 추가 |
helm search repo <패키지명> | 저장소에서 Chart 검색 |
helm install <릴리즈명> <Chart명> | 새로운 Helm Chart 배포 |
helm upgrade <릴리즈명> <Chart명> | 기존 배포된 Chart 업데이트 |
helm rollback <릴리즈명> <버전> | 이전 버전으로 롤백 |
helm uninstall <릴리즈명> | Helm으로 배포한 애플리케이션 삭제 |
helm list | 현재 배포된 Helm Release 목록 확인 |
Install Helm
curl -LO https://get.helm.sh/helm-v3.17.1-linux-amd64.tar.gz
tar -zxvf helm-v3.17.1-linux-amd64.tar.gzHelm을 사용하기 위해 위와 같이 바이너리 파일을 받아 압축을 해제하고
mv linux-amd64/helm /usr/local/bin/helm실행파일을 /usr/local/bin로 이동시키면
[root@master ~]# helm version
version.BuildInfo{Version:"v3.17.1", GitCommit:"980d8ac1939e39138101364400756af2bdee1da5", GitTreeState:"clean", GoVersion:"go1.23.5"}Helm을 사용할 준비를 마칠 수 있다.
Kube-Prometheus-Stack
Architecture
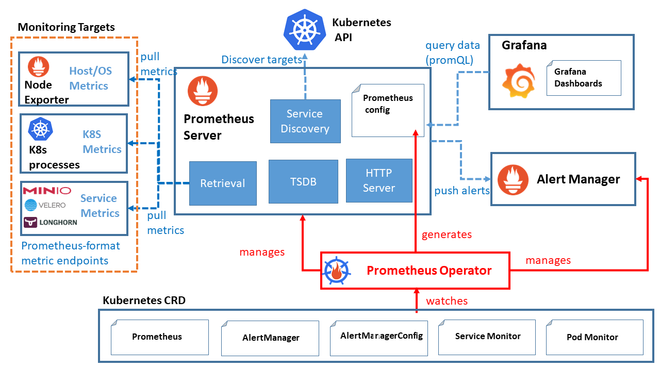
Helm의 Kube-Prometheus-Stack의 아키텍처는 위와 같이 구성되어 있다.
-
Prometheus Operator- 쿠버네티스 내에서 Prometheus 서버와 관련된 리소스들을 관리하기 위한 컨트롤러
- Prometheus와 관련된 설정, 서비스 디스커버리, 룰 및 대시보드를 관리
-
Prometheus Server- 고가용성을 제공하는 Prometheus 서버
- 메트릭 데이터를 스크랩하고 저장
-
Alertmanager- Prometheus가 수집한 메트릭 데이터를 기반으로 경고를 생성하고 관리하는 역할
-
Prometheus node-exporter- node-exporter는 Host의 metric을 수집하는 역할
- CPU, 메모리, 디스크 사용량 등의 데이터를 수집하여 Prometheus로 전달
-
Prometheus Adapter for Kubernetes Metrics APIs- 쿠버네티스의 메트릭 API와 연동하여 클러스터 내부의 리소스 메트릭 데이터를 수집하고 Prometheus로 전달
-
kube-state-metrics- 쿠버네티스 클러스터의 상태 정보를 메트릭으로 수집
- Pod, Deployment, Node 등의 상태 정보를 모니터링할 수 있음
-
Grafana- Grafana는 데이터 시각화 및 대시보드 생성 도구로, 수집한 메트릭 데이터를 그래프나 대시보드 형태로 시각화하여 사용자에게 제공
Installation
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo updateprometheus-community의 Helm 차트를 사용하기 위해 위 명령어로 리포지토리를 추가하고 업데이트한다
$ helm search repo prometheus-community
NAME CHART VERSION APP VERSION DESCRIPTION
prometheus-community/alertmanager 1.15.1 v0.28.0 The Alertmanager handles alerts sent by client ...
prometheus-community/alertmanager-snmp-notifier 0.4.0 v1.6.0 The SNMP Notifier handles alerts coming from Pr...
prometheus-community/jiralert 1.7.2 v1.3.0 A Helm chart for Kubernetes to install jiralert
...이후 helm search repo를 통해 추가된 리포지토리를 확인할 수 있다.
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --namespace monitoring --create-namespace이후 위 명령어로 kube-prometheus-stack을 설치한다.
만약 기본값 외에 사용자 정의 설정이 필요하면 values.yaml 파일을 작성하여 추가 옵션을 적용할 수 있다.
--namespace monitoring: 이 옵션으로 설치할 네임스페이스를 지정--create-namespace: 지정한 네임스페이스가 없을 경우 자동으로 생성
[root@master ~]# helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --namespace monitoring --create-namespace
NAME: kube-prometheus-stack
LAST DEPLOYED: Sat Mar 1 07:56:20 2025
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=kube-prometheus-stack"
Get Grafana 'admin' user password by running:
kubectl --namespace monitoring get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo
Access Grafana local instance:
export POD_NAME=$(kubectl --namespace monitoring get pod -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=kube-prometheus-stack" -oname)
kubectl --namespace monitoring port-forward $POD_NAME 3000
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.이후 위와 같이 설치가 정상적으로 진행된 것을 확인할 수 있었고
[root@master ~]# kubectl get pods -n monitoring -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 0 47s 10.244.2.38 k8s-worker-2.novalocal <none> <none>
kube-prometheus-stack-grafana-77769b4dc8-z5l2n 3/3 Running 0 57s 10.244.1.19 k8s-worker-1.novalocal <none> <none>
kube-prometheus-stack-kube-state-metrics-7f498cd54f-7w5pj 1/1 Running 0 57s 10.244.2.35 k8s-worker-2.novalocal <none> <none>
kube-prometheus-stack-operator-576fc8bff9-lcns6 1/1 Running 0 57s 10.244.2.36 k8s-worker-2.novalocal <none> <none>
kube-prometheus-stack-prometheus-node-exporter-gbhl4 1/1 Running 0 57s 192.168.100.29 k8s-worker-2.novalocal <none> <none>
kube-prometheus-stack-prometheus-node-exporter-m7kfv 1/1 Running 0 57s 172.20.112.101 master <none> <none>
kube-prometheus-stack-prometheus-node-exporter-xsxgq 1/1 Running 0 57s 192.168.100.44 k8s-worker-1.novalocal <none> <none>
prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 46s 10.244.2.39 k8s-worker-2.novalocal <none> <none>monitoring 네임스페이스의 Pod들도 확인할 수 있었으며
kubectl --namespace monitoring get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo로그의 위 명령어를 통해 기본적으로 설정된 Grafana 계정의 비밀번호를 확인할 수 있었다.
System Requirements
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-worker-1.novalocal NotReady worker 9d v1.32.2
k8s-worker-2.novalocal NotReady worker 9d v1.32.2
master Ready control-plane 9d v1.32.2하지만 설치가 진행되고 얼마 지나지 않아 위와 같이 모든 노드들이 NotReady State로 들어선 것을 볼 수 있었다.
| 구성 요소 | CPU 요청 | CPU 제한 | 메모리 요청 | 메모리 제한 |
|---|---|---|---|---|
| Prometheus | 500m | 2 | 2Gi | 8Gi |
| Alertmanager | 100m | 500m | 256Mi | 1Gi |
| Grafana | 100m | 500m | 128Mi | 512Mi |
| Node Exporter | 50m | 200m | 64Mi | 256Mi |
| Kube State Metrics | 100m | 500m | 128Mi | 512Mi |
따라서 Kube-Prometheus-Stack의 각 프로젝트들에 대한 요구사항을 확인해주었는데, 기본적인 value.yaml에서 요청하는 리소스가 현재 구축된 클러스터의 리소스보다 월등히 높아서 생긴 문제라고 판단하여
-
Prometheus 데이터 저장 (Persistent Volume)
- Prometheus는 많은 데이터를 저장하므로,
PersistentVolumeClaim(PVC)이 필요 - 기본적으로
Retain 정책을 설정하면, Helm을 삭제해도 데이터가 유지됨 - 장기 저장이 필요하면
Thanos같은 외부 스토리지 연동 필요
- Prometheus는 많은 데이터를 저장하므로,
-
Scrape Interval 설정 조정
- 기본적으로 15초 간격으로 데이터를 수집하지만, 수집 빈도를 줄이면 리소스 사용량 감소
scrape_interval을 30~60초로 설정하면 리소스 절약 가능
리소스를 적게 할당하는 것 뿐 아닌 추가적으로 리소스를 절약할 수 있는 방법을 정리하였다.
Independent Installation
현재 노드 수 10개 미만의 작은 Kubernetes 클러스터, 기본적인 모니터링 (메트릭 수집, 경고 기능) 등만 사용할 예정이기에 하나의 통합 스택 대신 Prometheus와 Grafana를 개별적으로 설치하고자 하였다.
helm uninstall kube-prometheus-stack우선 helm uninstall을 통해 기존에 설치된 통합된 스택을 제거하고
$ kubectl describe node master
...
Taints: node-role.kubernetes.io/control-plane:NoSchedulemaster 노드에 유휴 리소스가 많이 있기 때문에 Taint를 제거하지 않고, Helm 차트에서 toleration 설정을 추가해 master 노드에 파드를 스케줄링할 수 있도록 하였다.
helm install prometheus prometheus-community/prometheus \
--namespace monitoring --create-namespace \
--set server.resources.requests.cpu=250m \
--set server.resources.requests.memory=256Mi \
--set server.resources.limits.cpu=500m \
--set server.resources.limits.memory=512Mi \
--set server.global.scrape_interval=1m \
--set nodeExporter.enabled=true \
--set server.tolerations[0].key="node-role.kubernetes.io/control-plane" \
--set server.tolerations[0].operator="Exists" \
--set server.tolerations[0].effect="NoSchedule"\
--set server.persistentVolume.enabled=false이후 위와 같이 prometheus를 설치해주었다.
CPU: 요청 250m, 제한 500m메모리: 요청 256Mi, 제한 512Miserver.global.scrape_interval=1m: Prometheus의 수집 주기를 1분으로 늘려서 리소스 사용을 줄임nodeExporter.enabled=true: 각 노드에 node-exporter를 DaemonSet 형태로 배포server.nodeSelector & tolerations: Prometheus 서버를 master 노드에 스케줄링하도록 지정
또한 현재 임시로 Prometheus의 데이터를 영구 저장하지 않도록, persistence를 비활성화하여 PVC 생성을 건너뛸 수 있으며 이 경우 데이터는 Pod 재시작 시 사라진다.
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm install grafana grafana/grafana \
--namespace monitoring --create-namespace \
--set resources.requests.cpu=100m \
--set resources.requests.memory=256Mi \
--set resources.limits.cpu=250m \
--set resources.limits.memory=512Mi \
--set tolerations[0].key="node-role.kubernetes.io/control-plane" \
--set tolerations[0].operator="Exists" \
--set tolerations[0].effect="NoSchedule" \
--set service.type=LoadBalancer또한 위와 같이 grafana를 설치해주었다.
CPU: 요청 100m, 제한 250m메모리: 요청 256Mi, 제한 512MinodeSelector & tolerations: Grafana도 master 노드에만 스케줄링되도록 설정
[root@master k8s]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana LoadBalancer 10.96.82.84 172.10.100.201 80:30101/TCP 66s이후 grafana 서비스가 LoadBalancer 형태로 정상 작동하고 있는 것을 확인할 수 있었고
$ kubectl describe pod grafana-7f8fbfb675-lvhm4 -n monitorig
...
Labels: app.kubernetes.io/instance=grafana
app.kubernetes.io/name=grafanagrafana Pod의 Labels을 확인하여주고
apiVersion: v1
kind: Service
metadata:
name: grafana-nodeport
namespace: monitoring
spec:
type: NodePort
externalIPs:
- 172.20.112.101
selector:
app.kubernetes.io/name: grafana
ports:
- name: http
port: 80
targetPort: 3000
nodePort: 30200이후 위와 같이 app.kubernetes.io/name: grafana를 selector로 가지는 grafana-nodeport 서비스를 생성하여주고
[root@master grafana]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana LoadBalancer 10.96.82.84 172.10.100.201 80:30101/TCP 9m1s
grafana-nodeport NodePort 10.105.77.232 172.20.112.101 80:30200/TCP 8s생성된 결괄르 확인해준 이후
[root@kubernetes-host ~]# curl 172.20.112.101:30200
<a href="/login">Found</a>.kubernetes-host에서 접근이 정상적으로 이루어지는지 확인한다.
server {
listen 3000;
server_name _;
location / {
proxy_pass http://172.20.112.101:30200;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}이후 nginx 프록시를 작성하여 외부에서도 접근할 수 있게 하고
sudo semanage port -a -t http_port_t -p tcp 30200
sudo systemctl restart nginx또한 최종적으로 SELinux에 30200 포트를 허용하여준다.
Nginx는 기본적으로 http 서비스에 허용된 포트(80, 443)만 바인딩할 수 있도록 SELinux가 제한하고 있기 때문에, 30200과 같이 사용자 지정 포트를 사용하기 위해 SELinux에 해당 포트를 허용해줘야 한다.
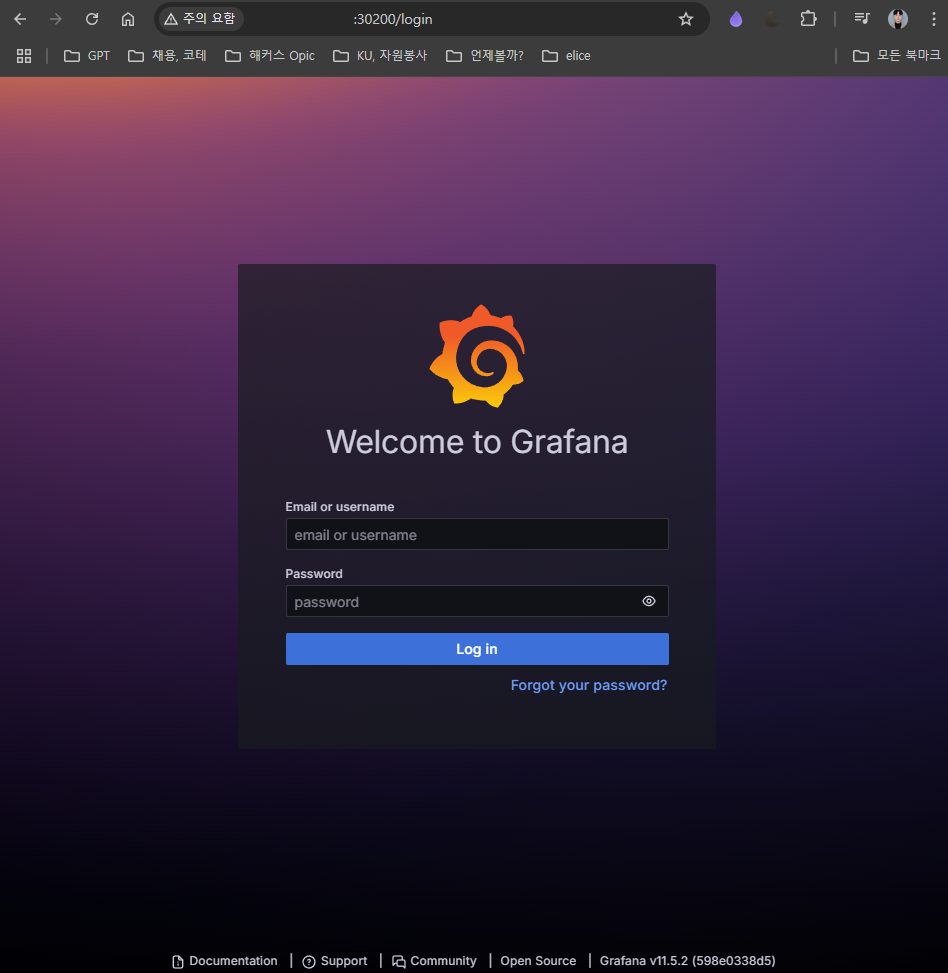 이후
이후 kubernetes-host의 공인 IP의 30200 포트로 접근했을 때 Grafana 서비스에 정상적으로 접근할 수 있었다.
Trouble Shooting: Grafana Data Source origin not allowed
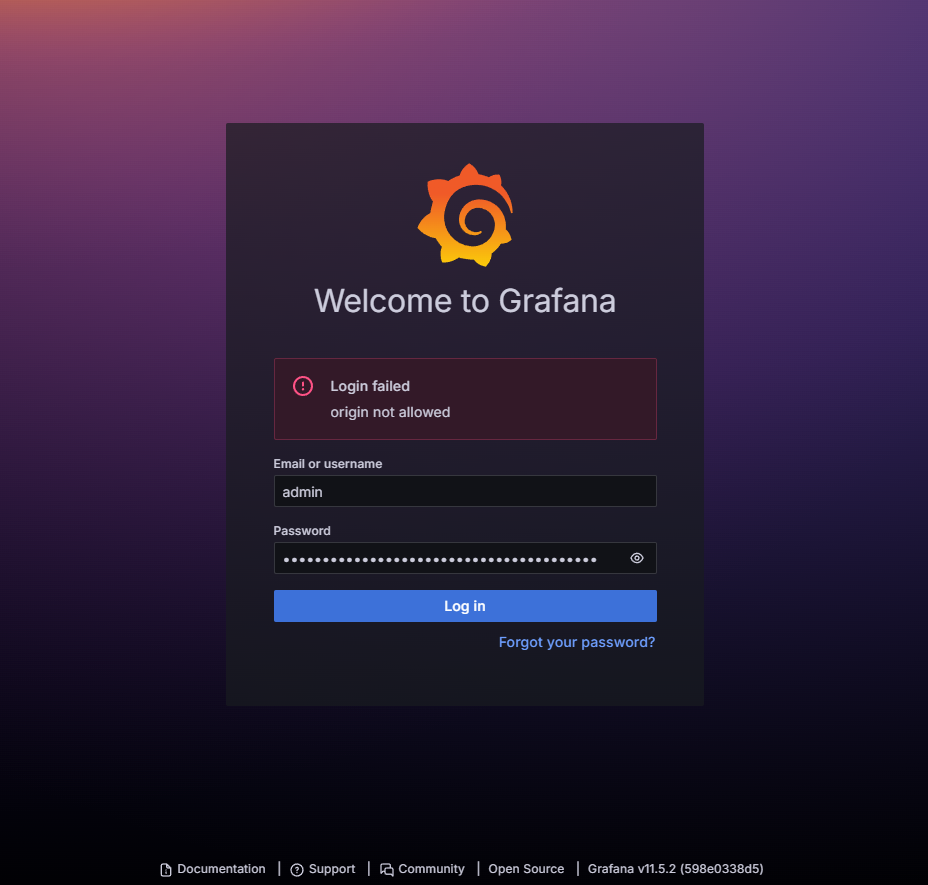
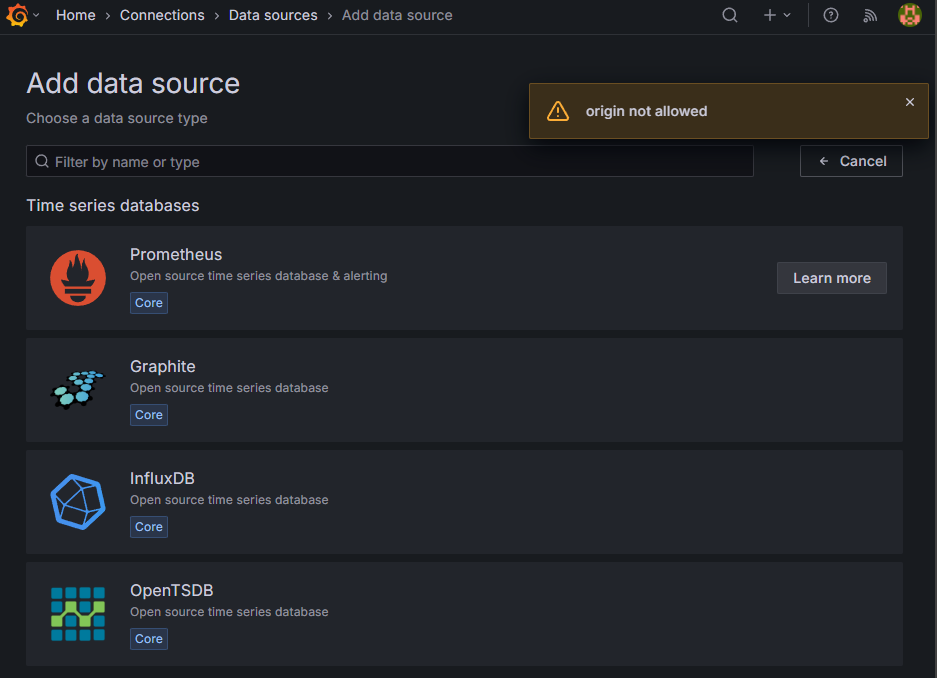 하지만
하지만 Grafana에서 Datasource를 추가하려고 할 때 위와 같이 origin not allowed 오류가 발생하였다.
Helm으로 Grafana를 배포한 경우, Grafana의 데이터 소스는 기본적으로 configuration provisioning을 통해 관리된다.
Prometheus 데이터 소스에서 CORS 에러가 발생하는 원인은 Grafana가 브라우저에서 직접 Prometheus로 요청할 때 발생하는 문제인데, 이를 해결하려면 데이터 소스의 Access 모드를 Server (proxy) 로 설정해야 힌다.
helm show values grafana/grafana > values.yaml기본 설정 파일을 로컬에 저장하여 수정하기 위해 위와 같이 실행한다.
[root@master grafana]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
prometheus-server ClusterIP 10.106.36.154 <none> 80/TCP 40m또한 이후 prometheus-server의 Cluster-IP를 확인한다.
kubectl run -i --tty --rm debug --image=busybox --restart=Never -- sh
/ # nslookup prometheus-server.monitoring.svc.cluster.local
Server: 10.96.0.10
Address: 10.96.0.10:53
Name: prometheus-server.monitoring.svc.cluster.local
Address: 10.106.36.154이후 busybox를 통해 Pod 내부에서 prometheus-server.monitoring.svc.cluster.local 도메인으로 접근 가능함을 확인한 뒤
$ vim values.yaml
...
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://prometheus-server.monitoring.svc.cluster.local:80
isDefault: trueGrafana Helm Chart의 values.yaml 파일에 위 datasource 설정(url)을 포함시킨다.
이 설정을 적용하면, Grafana는 배포 시 자동으로 해당 데이터 소스를 생성하고 Access 모드를 proxy로 설정하게 된다.
helm upgrade grafana grafana/grafana \
--namespace monitoring --install \
-f values.yaml이후 helm upgrade를 통해 이를 적용하고 Helm Chart 내에서 데이터 소스가 프로비저닝되고, Grafana는 백엔드에서 Prometheus로 요청하여 CORS 문제를 회피할 수 있다.
Trouble Shooting: Grafana Login failed : origin not allowed
현재 상황에서는 외부에서는 nginx가 3000 포트에서 요청을 받고, nginx가 172.20.112.101:30200 (Grafana NodePort)로 프록시하고 있으므로, 브라우저에서는 http://172.20.112.101:30200 으로 접속하게 된다.
이로 인해 요청되는 172.20.112.101의 Origin에 대한 CORS 오류가 발생한다.
$ vim values.yaml
...
grafana.ini:
paths:
data: /var/lib/grafana/
logs: /var/log/grafana
plugins: /var/lib/grafana/plugins
provisioning: /etc/grafana/provisioning
analytics:
check_for_updates: true
log:
mode: console
grafana_net:
url: https://grafana.net
server:
# domain: "{{ if (and .Values.ingress.enabled .Values.ingress.hosts) }}{{ tpl
(.Values.ingress.hosts | first) . }}{{ else }}''{{ end }}"
enforce_domain: falseGrafana는 기본적으로 보안상의 이유로 요청의 Origin이 root_url과 일치하는지 검사한다.
따라서 모든 Origin을 허용하기 위해 enforce_domain를 비활성화하여 도메인 검사를 해제한다.
$ vim value.yaml
...
server:
# domain: "{{ if (and .Values.ingress.enabled .Values.ingress.hosts) }}{{ tpl
(.Values.ingress.hosts | first) . }}{{ else }}''{{ end }}"
enforce_domain: false
root_url = http://172.20.112.101:3000/또한 현재 외부에서 접근하는 URL에 맞는 root_url을 명시적으로 지정해 주었다.
현재 상황에서는, 호스트 머신의 nginx를 통해 http://172.20.112.101:3000으로 접근하기 때문에 이를 root_url로 설정해주었다.
helm upgrade grafana grafana/grafana \
--namespace monitoring --install \
-f values.yaml이를 위와 같이 적용한 이후
$ vim /etc/nginx/conf.d/grafana-ingress-proxy.conf
server {
listen 30200;
server_name _;
location / {
proxy_pass http://172.20.112.101:30200;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}nginx 설정에서 Grafana로 요청 시 위 같이 Host 헤더를 명시적으로 전달하는 설정을 추가하였다.
[root@master grafana]# kubectl get svc --all-namespaces
...
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP
ingress-nginx ingress-nginx-nodeport NodePort 10.110.140.108 172.20.112.101 80:30080/TCP,443:30443/TCP 6d2h
monitoring grafana-nodeport NodePort 10.105.77.232 172.20.112.101 80:30200/TCP또한 현재 두 서비스가 같은 외부 IP(172.20.112.101)를 공유하면서 기본 포트(80)로 노출되어 있는데
-
ingress-nginx 서비스
- NodePort:
30080(HTTP)및30443(HTTPS) - 외부 IP:
172.20.112.101
- NodePort:
-
Grafana 서비스 (grafana-nodeport)
- NodePort:
30200 - 외부 IP:
172.20.112.101
- NodePort:
이는 두 서비스 모두 외부 IP인 172.20.112.101를 사용하기 때문에, nginx에서 proxy_pass에 포트 번호를 명시하지 않으면 기본 80번 포트로 접속하게 되고, 이 경우 어느 서비스로 요청이 전달될지 불분명해진다.
# HTTP 서버 블록 (직접 접근시 활용)
server {
listen 8080;
server_name _;
location / {
proxy_pass http://172.20.112.101:30080;
proxy_set_header Host wwwm-spring-be.com;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
# HTTPS 서버 블록 (Cloudflare Public DNS 접근시 활용)
server {
# 8443 포트로 접근
listen 8443 ssl;
server_name _;
ssl_certificate /etc/ssl/certs/when-will-we-meet-be.shop.crt;
ssl_certificate_key /etc/ssl/private/when-will-we-meet-be.shop.key;
location / {
proxy_pass http://172.20.112.101:30080;
proxy_set_header Host wwwm-spring-be.com;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}따라서 위와 같이 proxy_pass http://172.20.112.101:30080와 같이 정확하게 명시하여
 백엔드 서버로의 접근이 가능함과 동시에 Grafana 또한 접근할 수 있었다.
백엔드 서버로의 접근이 가능함과 동시에 Grafana 또한 접근할 수 있었다.
추후에는 PVC 및 alert-manager Rule 등을 추가해 모니터링 인프라를 개선하고자 한다.
Permenant prometheus-grafana stack
### Install Helm
dnf install -y git tar
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
### Install prometheus-stack
kubectl create namespace monitoring
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--set grafana.enabled=true \
--set prometheus.resources.requests.cpu="100m" \
--set prometheus.resources.requests.memory="200Mi" \
--set grafana.resources.requests.cpu="50m" \
--set grafana.resources.requests.memory="100Mi"
--set grafana.service.type=NodePort \
--set grafana.service.nodePort=30200
--set nodeExporter.enabled=true \
--set server.tolerations[0].key="node-role.kubernetes.io/control-plane" \
--set server.tolerations[0].operator="Exists" \
--set server.tolerations[0].effect="NoSchedule"\
--set server.persistentVolume.enabled=true
### Grafana Secret
kubectl get secret kube-prometheus-stack-grafana \
-n monitoring \
-o jsonpath="{.data.admin-password}" | base64 -d && echo
: << "END"
[root@k3s ~]# curl localhost:30200
<a href="/login">Found</a>.
END기존의 server.persistentVolume.enabled=false 상태는 지속적인 모니터링을 하기에는 너무 불편함지 많이 존재하여
독립적인 타 K3s 클러스터에서도 안정적으로 운영되는 helm 차트의 메타데이터를 기반으로 Prometheus와 Grafana를 재배포하였다.
apiVersion: v1
kind: Service
metadata:
name: grafana-nodeport
namespace: monitoring
spec:
type: NodePort
externalIPs:
- 172.20.112.101
selector:
app.kubernetes.io/name: grafana
ports:
- name: http
port: 80
targetPort: 3000
nodePort: 30200이후 위와 같이 기존의 서비스를 유지하면 정상적으로 Grafana 대시보드에 접근이 가능한 것을 볼 수 있었다.
