
KU어드벤처 전공탐험대
 현재 소속되어 있는 동아리가 KU 창업클럽 소속이기 때문에 신입생들을 위한 KU 어드벤처 전공탐험대 행사에 참가할 수 있게 되었다.
현재 소속되어 있는 동아리가 KU 창업클럽 소속이기 때문에 신입생들을 위한 KU 어드벤처 전공탐험대 행사에 참가할 수 있게 되었다.
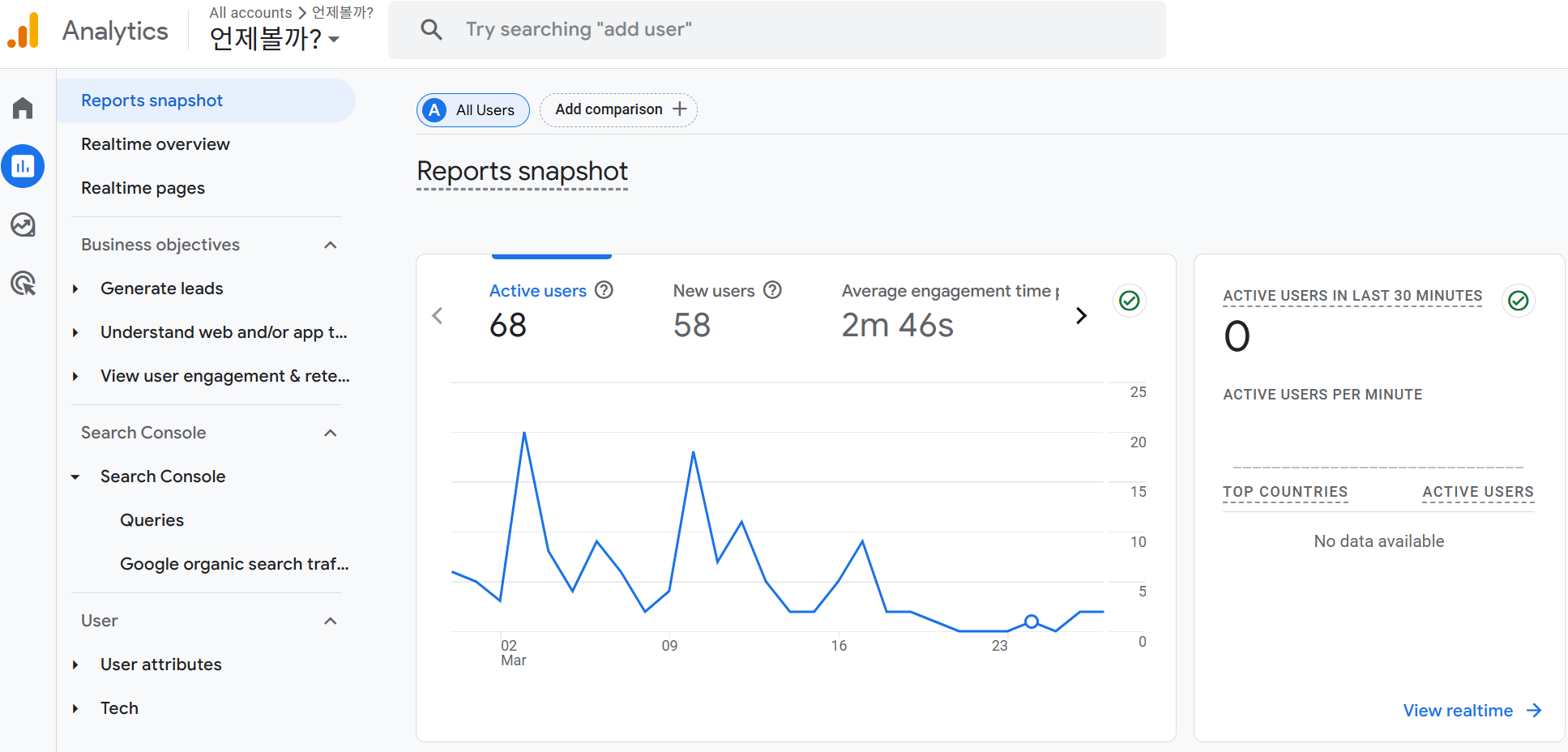 현 시점까지의 활성 사용자 수는 총 68명으로 해당 행사를 통해 100명 이상의 활성 사용자를 확보할 수 있을 것으로 기대한다.
현 시점까지의 활성 사용자 수는 총 68명으로 해당 행사를 통해 100명 이상의 활성 사용자를 확보할 수 있을 것으로 기대한다.
서버 최적화 및 대응 방안 마련
팜플렛 제작
 이때 위와 같이
이때 위와 같이 언제볼까? 서비스에 대한 데모 시연을 진행하고 팜플렛을 배부하는 등 서비스를 홍보하여 추가적인 사용자를 확보할 계획이다.
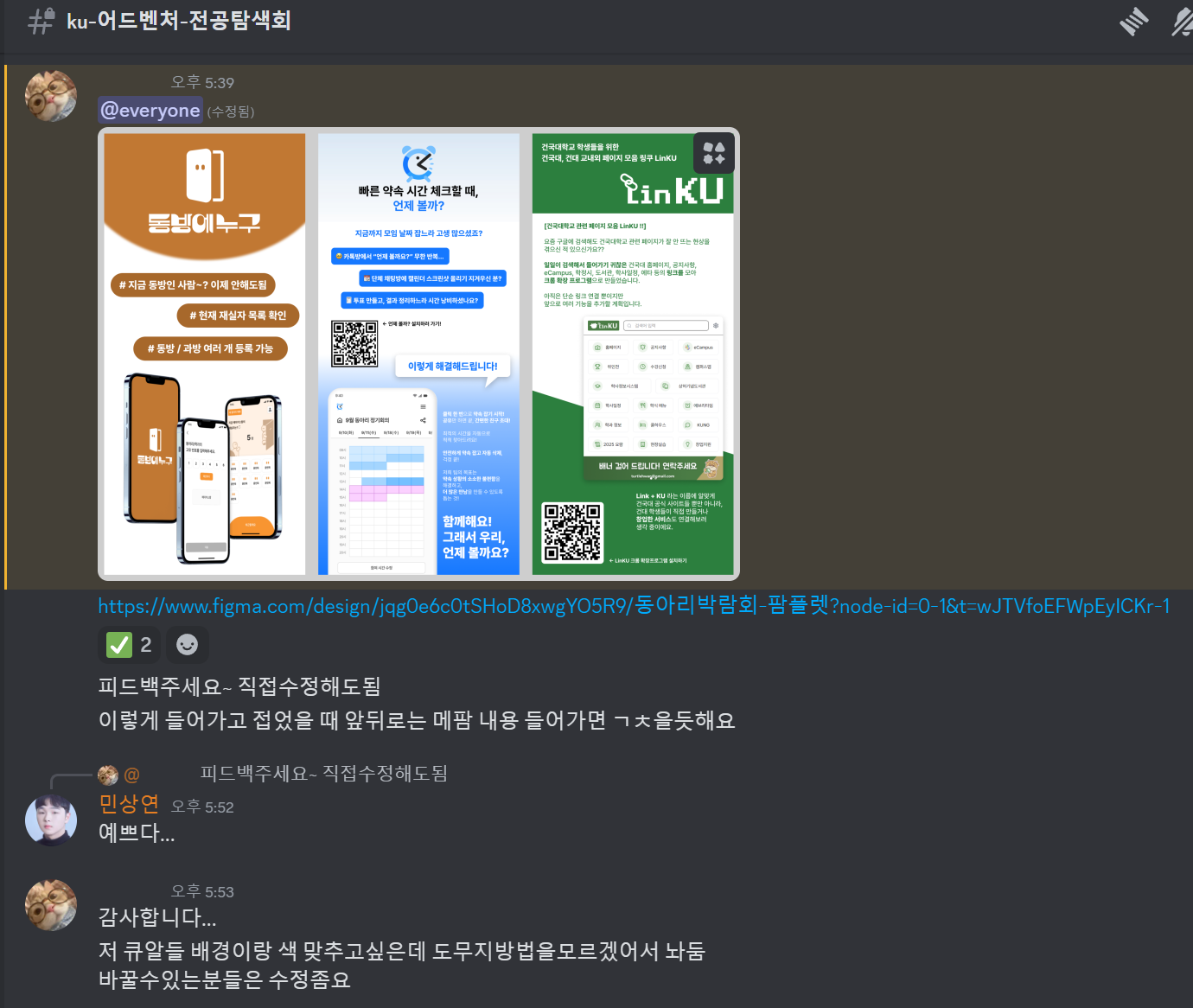 또한 이후 너무 감사하게도 같은 동아리 팀원분께서 홍보 자료를 수정해주셨다.
또한 이후 너무 감사하게도 같은 동아리 팀원분께서 홍보 자료를 수정해주셨다.
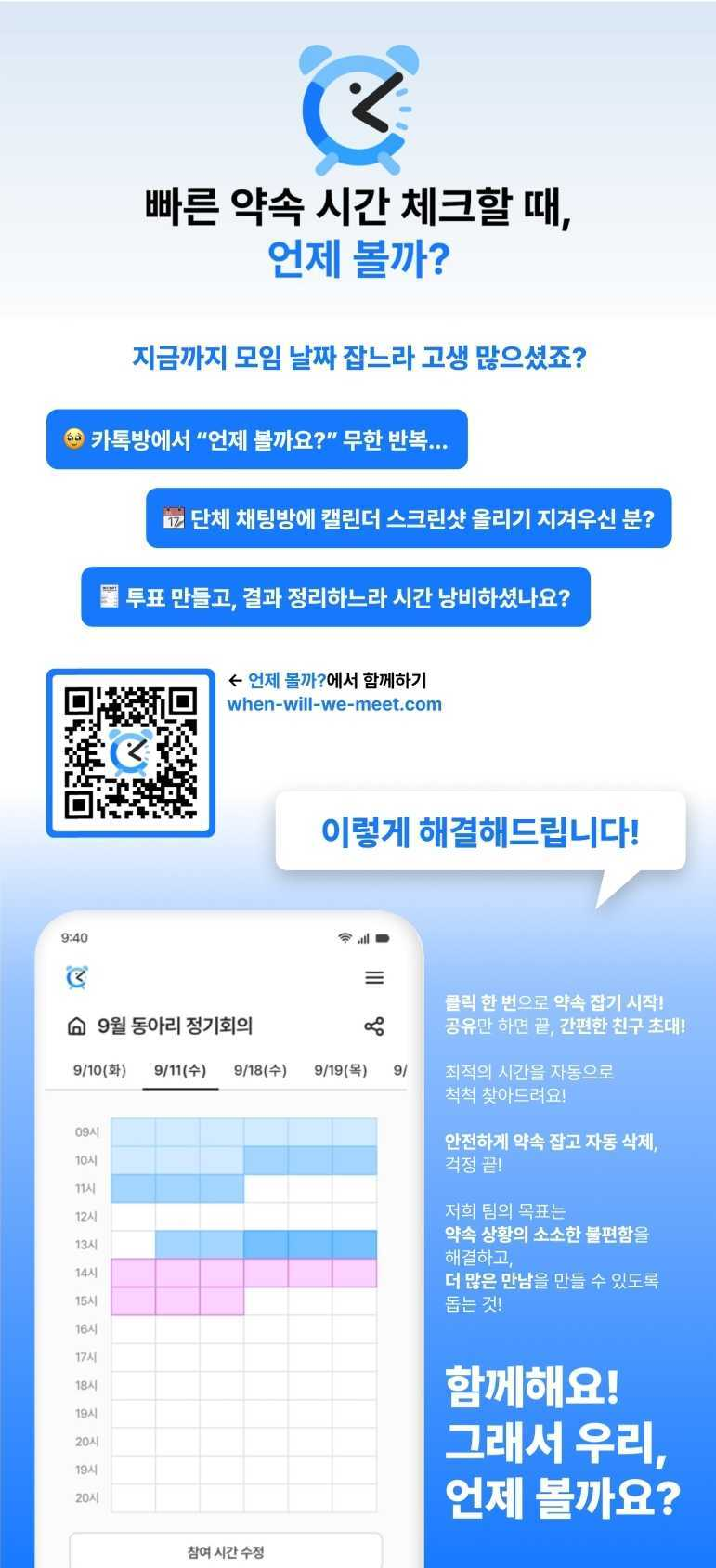 최종적으로 제작된 팜플렛은 위와 같다.
최종적으로 제작된 팜플렛은 위와 같다.
웹 서비스이니만큼 QR Code를 통해서 현장에서 직접 접속이 가능한 형태로 팜플렛을 구성하였다.
FE 수정 요청
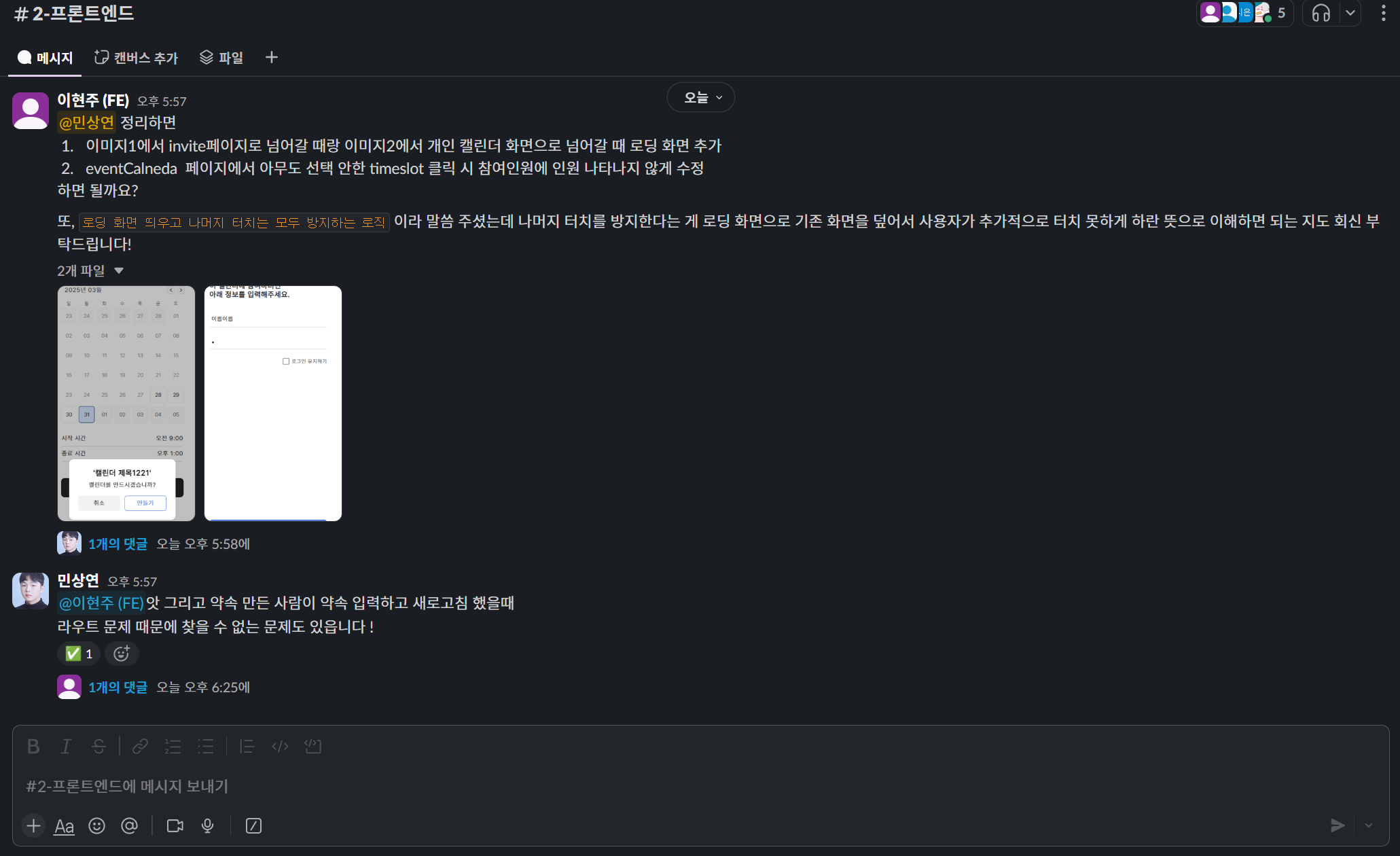 또한 학기 시작으로 인해 잠시 여유롭게 진행되었던 개발을 위와 같이 사용성 증가에 중요한 순으로 FE 개발자분께 요청드렸다.
또한 학기 시작으로 인해 잠시 여유롭게 진행되었던 개발을 위와 같이 사용성 증가에 중요한 순으로 FE 개발자분께 요청드렸다.
FE Public Domain 추가
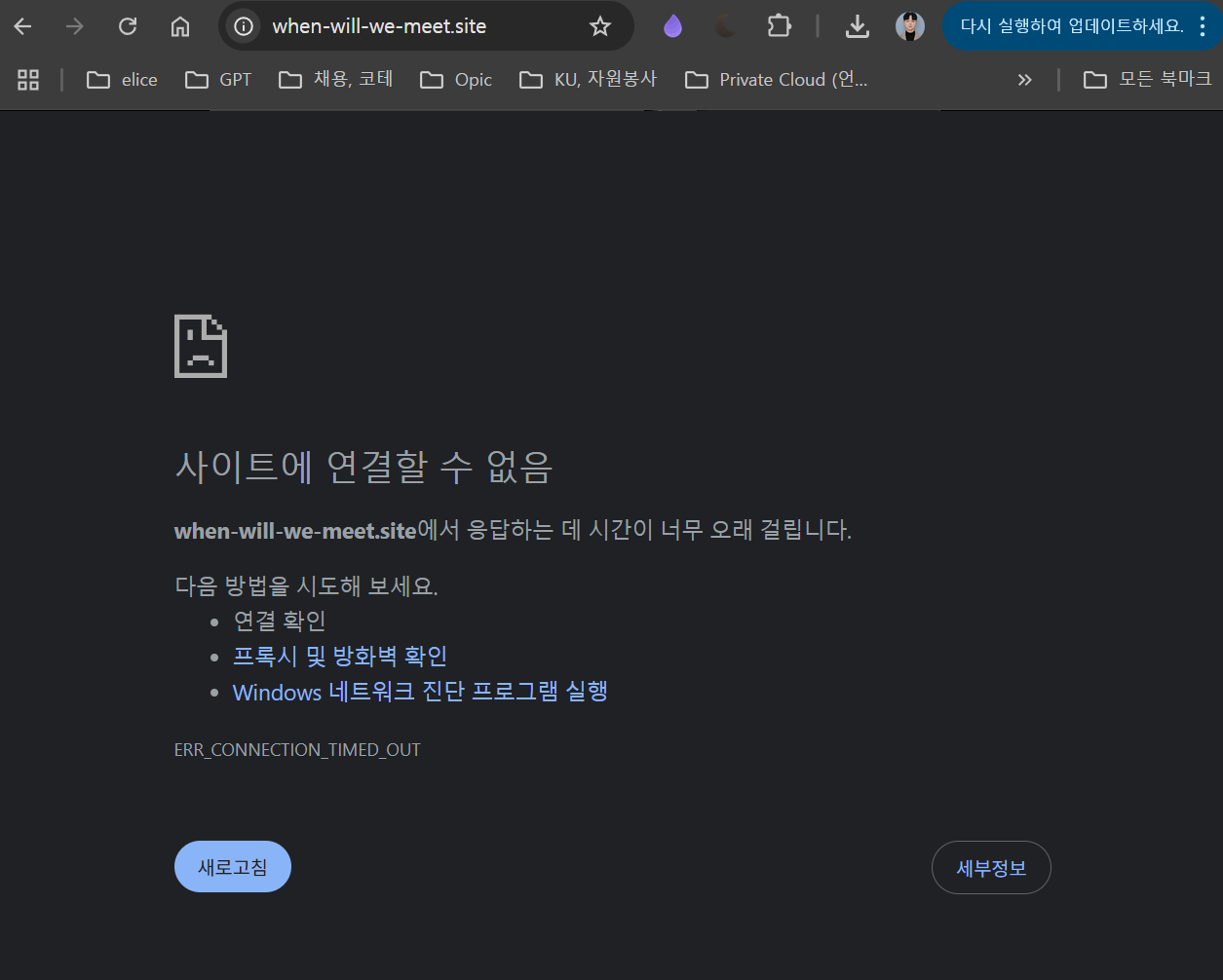 또한 LTE나 다른 와이파이에 연결되어 있으면 정상 접속이 가능하지만, KONKUK 와이파이에 연결되어 있으면 웹에 접속이 불가한 문제가 발생하였다.
또한 LTE나 다른 와이파이에 연결되어 있으면 정상 접속이 가능하지만, KONKUK 와이파이에 연결되어 있으면 웹에 접속이 불가한 문제가 발생하였다.
이는 행사 당일, 주로 신입생 분들께서 서비스에 접속해주실 것이므로 상당히 치명적인 문제라고 판단하여 이슈를 우선 생성해두었다.
https://github.com/TEAM-WHEN-WILL-WE-MEET/WWWM-INFRA/issues/2
이는 Firebase 호스팅을 포함한 Google 서비스는 HTTPS 프로토콜과 Google CDN 서버를 사용하는데, 대학이나 기관 내부의 네트워크 정책(방화벽, DNS 필터링 등) 에 따라 특정 도메인이나 IP가 차단될 가능성이 존재기 때문에 발생한 문제라고 판단하였다.
따라서 현재 https://when-will-we-meet.site/ 도메인을 활용하고 있어 .com 도메인으로 변경하는 방법이 가장 현실적일 것 같다고 판단하여 추가적으로 도메인을 구매하고 세팅을 진행하였다.
TimeSlot 업데이트 최적화
kubectl logs -f -l app=wwwm-spring-be모든 Pod가 동일한 라벨을 가지고 있기 때문에 해당 Deployment에 속한 모든 Pod의 로그를 볼 수 있었다.
...
2025-03-28T11:10:27.208Z ERROR 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-9] o.e.whenwillwemeet.data.dao.ScheduleDAO : Wed Apr 02 18:50:00 UTC 2025
2025-03-28T11:10:27.252Z ERROR 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-9] o.e.whenwillwemeet.data.dao.ScheduleDAO : Wed Apr 02 19:00:00 UTC 2025
2025-03-28T11:10:27.296Z ERROR 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-9] o.e.whenwillwemeet.data.dao.ScheduleDAO : Wed Apr 02 19:10:00 UTC 2025
2025-03-28T11:10:27.341Z ERROR 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-9] o.e.whenwillwemeet.data.dao.ScheduleDAO : Wed Apr 02 19:20:00 UTC 2025
2025-03-28T11:10:27.386Z ERROR 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-9] o.e.whenwillwemeet.data.dao.ScheduleDAO : Wed Apr 02 19:30:00 UTC 2025
2025-03-28T11:10:27.435Z ERROR 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-9] o.e.whenwillwemeet.data.dao.ScheduleDAO : Wed Apr 02 19:40:00 UTC 2025
2025-03-28T11:10:27.485Z ERROR 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-9] o.e.whenwillwemeet.data.dao.ScheduleDAO : Wed Apr 02 19:50:00 UTC 2025
2025-03-28T11:10:27.530Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-9] o.e.w.service.ScheduleService
: [ScheduleService]-[updateSchedule] Appointment [67e68328e1a9c0428682caa6] Schedule [2025-04-01T09:00], User [ 민상연]
2025-03-28T11:10:27.671Z INFO 1 --- [WHEN-WILL-WE-MEET] [nio-8080-exec-2] o.e.w.data.dao.AppointmentDAO
: [AppointmentDAO]-[getAppointmentById] Successfully fetched appointment [67e68328e1a9c0428682caa6] 이때 위와 같이 요청한 모든 TimeSlot에 대해서 각각 쿼리를 수행하는 비효율적인 로직을 발견하고 이를 수정하고자 하였다.
// ScheduleService
// 주어진 Schedule 정보를 기반으로 현재 Appointment 모델과 비교하여 사용자를 TimeSlot에 추가하거나 제거
// 즉, Frontend에서 발생한 이벤트를 전달해주면 자동으로 현재 DB의 데이터와 비교하여 Toggle
@Transactional
public CommonResponse updateSchedule(Schedule inputSchedule) {
try {
String appointmentId = inputSchedule.getAppointmentId();
// 현재 Appointment 정보를 데이터베이스에서 fetch
Optional<AppointmentModel> appointmentOpt = appointmentRepository.findById(appointmentId);
if (!appointmentOpt.isPresent())
throw new RuntimeException("Appointment not found with id: " + appointmentId);
// InputSchedule의 TimeSlot의 User들이 상이하면 Throw Exception
String userName = inputSchedule.getTimes().getFirst().getUsers().getFirst();
for (TimeSlot inputTimeSlot : inputSchedule.getTimes())
if(!Objects.equals(userName, inputTimeSlot.getUsers().getFirst()))
throw new RuntimeException("Different UserName Exists");
// User가 존재하지 않으면 Throw Exception
if(!scheduleDAO.isUserExistsInAppointment(appointmentId, userName))
throw new RuntimeException("User [" + userName + "] not found in " + appointmentId);
// appointment를 UTC로 변환
AppointmentModel appointment = TimeZoneConverter.convertToUTC(appointmentOpt.get());
// 입력 Schedule의 ID와 일치하는 Schedule을 찾기
Optional<Schedule> existingScheduleOpt = appointment.getSchedules().stream()
.filter(s -> s.getId().equals(inputSchedule.getId()))
.findFirst();
if (!existingScheduleOpt.isPresent())
throw new RuntimeException("Schedule not found in Appointment");
Schedule existingSchedule = existingScheduleOpt.get();
// 입력 Schedule의 각 TimeSlot에 대해 Toggle 작업을 수행
for (TimeSlot inputTimeSlot : inputSchedule.getTimes()) {
// TimeSlot 존재 여부를 검사할 때도 UTC를 기준으로 검사
Optional<TimeSlot> existingTimeSlotOpt = findTimeSlotByTime(
existingSchedule,
inputTimeSlot.getTime()
);
if (existingTimeSlotOpt.isPresent()) {
TimeSlot existingTimeSlot = existingTimeSlotOpt.get();
if (existingTimeSlot.getUsers().contains(userName)) {
// 사용자가 이미 존재하면 제거
scheduleDAO.removeUserFromTimeSlot(appointmentId, existingSchedule.getId(), inputTimeSlot.getTime(), userName, "UTC");
} else {
// 사용자가 존재하지 않으면 추가
scheduleDAO.addUserToTimeSlot(appointmentId, existingSchedule.getId(), inputTimeSlot.getTime(), userName, "UTC");
}
} else {
log.error("[ScheduleService]-[updateSchedule] Appointment [{}] Schedule [{}], User [{}] TimeSlot not found : [{}]",
appointmentId, inputSchedule.getDate(), userName, inputTimeSlot.getTime());
throw new RuntimeException("TimeSlot not found in existing Schedule");
}
}
...// ScheduleDAO
...
public void addUserToTimeSlot(String appointmentId, String scheduleId, LocalDateTime time, String userName, String zoneId) {
log.error("" + Date.from(time.atZone(ZoneId.of(zoneId)).toInstant()));
Query query = new Query(Criteria.where("_id").is(new ObjectId(appointmentId))
.and("schedules._id").is(scheduleId)
.and("schedules.times.time").is(Date.from(time.atZone(ZoneId.of(zoneId)).toInstant())));
Update update = new Update().addToSet("schedules.$[sched].times.$[slot].users", userName);
update.filterArray(Criteria.where("sched._id").is(scheduleId));
update.filterArray(Criteria.where("slot.time").is(Date.from(time.atZone(ZoneId.of(zoneId)).toInstant())));
mongoTemplate.updateFirst(query, update, "appointments");
}
public void removeUserFromTimeSlot(String appointmentId, String scheduleId, LocalDateTime time, String userName, String zoneId) {
Query query = new Query(Criteria.where("_id").is(new ObjectId(appointmentId))
.and("schedules._id").is(scheduleId)
.and("schedules.times.time").is(Date.from(time.atZone(ZoneId.of(zoneId)).toInstant())));
Update update = new Update().pull("schedules.$[sched].times.$[slot].users", userName);
update.filterArray(Criteria.where("sched._id").is(scheduleId));
update.filterArray(Criteria.where("slot.time").is(Date.from(time.atZone(ZoneId.of(zoneId)).toInstant())));
mongoTemplate.updateFirst(query, update, "appointments");
}위와 같이 각각의 Schedule 업데이트 요청에 대해 하나하나 쿼리를 날리도록 구현되었던 코드를
for (TimeSlot inputTimeSlot : inputSchedule.getTimes()) {
Optional<TimeSlot> existingTimeSlotOpt = findTimeSlotByTime(existingSchedule, inputTimeSlot.getTime());
if (existingTimeSlotOpt.isPresent()) {
TimeSlot existingTimeSlot = existingTimeSlotOpt.get();
if (existingTimeSlot.getUsers().contains(userName)) {
timesToRemove.add(inputTimeSlot.getTime());
} else {
timesToAdd.add(inputTimeSlot.getTime());
}
} else {
log.error("[ScheduleService]-[updateSchedule] Appointment [{}] Schedule [{}], User [{}] TimeSlot not found : [{}]",
appointmentId, inputSchedule.getDate(), userName, inputTimeSlot.getTime());
throw new RuntimeException("TimeSlot not found in existing Schedule");
}
}
scheduleDAO.updateUserInTimeSlotsBulk(appointmentId, existingSchedule.getId(), timesToAdd, timesToRemove, userName, "UTC");
log.info("[ScheduleService]-[updateSchedule] Appointment [{}] Schedule [{}], User [{}] TimeSlot updated [{}] added, [{}] removed",
appointmentId, inputSchedule.getDate(), userName, timesToAdd.size(), timesToRemove.size());...
// MongoDB Driver의 Document를 직접 활용
public void updateUserInTimeSlotsBulk(String appointmentId, String scheduleId, List<LocalDateTime> timesToAdd, List<LocalDateTime> timesToRemove, String userName, String zoneId) {
List<WriteModel<Document>> bulkOperations = new ArrayList<>();
for (LocalDateTime time : timesToAdd) {
Document query = new Document("_id", new ObjectId(appointmentId))
.append("schedules._id", scheduleId)
.append("schedules.times.time", Date.from(time.atZone(ZoneId.of(zoneId)).toInstant()));
Document update = new Document("$addToSet",
new Document("schedules.$[sched].times.$[slot].users", userName));
UpdateOptions updateOptions = new UpdateOptions().arrayFilters(
Arrays.asList(
new Document("sched._id", scheduleId),
new Document("slot.time", Date.from(time.atZone(ZoneId.of(zoneId)).toInstant()))
)
);
bulkOperations.add(new UpdateOneModel<>(query, update, updateOptions));
}
for (LocalDateTime time : timesToRemove) {
Document query = new Document("_id", new ObjectId(appointmentId))
.append("schedules._id", scheduleId)
.append("schedules.times.time", Date.from(time.atZone(ZoneId.of(zoneId)).toInstant()));
Document update = new Document("$pull",
new Document("schedules.$[sched].times.$[slot].users", userName));
UpdateOptions updateOptions = new UpdateOptions().arrayFilters(
Arrays.asList(
new Document("sched._id", scheduleId),
new Document("slot.time", Date.from(time.atZone(ZoneId.of(zoneId)).toInstant()))
)
);
bulkOperations.add(new UpdateOneModel<>(query, update, updateOptions));
}
if (!bulkOperations.isEmpty()) {
mongoTemplate.getCollection("appointments").bulkWrite(bulkOperations);
}
}위와 같이 BulkOpenration을 통해 여러개의 TimeSlot 업데이트를 한번의 쿼리로 처리할 수 있도록 변경하였다.
[ScheduleService]-[updateSchedule] Appointment [67e687d7c1169c6568a09a67] Schedule [2025-01-27T00:00], User [당긴상연] TimeSlot updated [2] added, [1] removed
[ScheduleService]-[updateSchedule] Appointment [67e687d7c1169c6568a09a67] Schedule [2025-01-27T00:00], User [당긴상연] TimeSlot updated [1] added, [2] removed위와 같이 로컬 환경에서의 테스트가 정상적으로 수행되는 것을 볼 수 있었으며
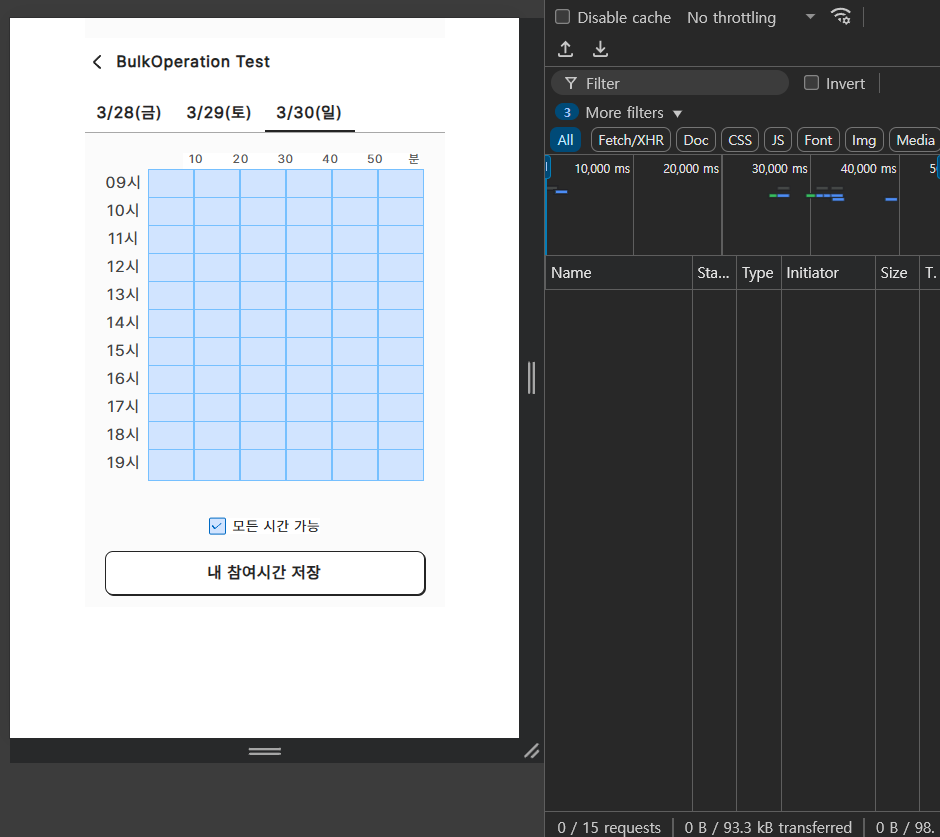 위와 같이 모든 TImeSlot을 선택한다고 하더라도
위와 같이 모든 TImeSlot을 선택한다고 하더라도
 이전과는 다르게 약 100ms 정도로 실제 반복문을 순회하며 List에 데이터를 저장하고 1회의 쿼리를 수행하는 시간만 걸리게 되어 훨씬 호율적으로 서버가 작동하는 것읋 확인할 수 있었다
이전과는 다르게 약 100ms 정도로 실제 반복문을 순회하며 List에 데이터를 저장하고 1회의 쿼리를 수행하는 시간만 걸리게 되어 훨씬 호율적으로 서버가 작동하는 것읋 확인할 수 있었다
K8s Pod Scaling

 우선 Grafana에서 위와 같이 현재 가용 가능한 CPU와 Memory를 확인해주었다. Worker Node들은 총 6개의 CPU, 그리고 약 5.4GB의 메모리를 보유하고 있다.
우선 Grafana에서 위와 같이 현재 가용 가능한 CPU와 Memory를 확인해주었다. Worker Node들은 총 6개의 CPU, 그리고 약 5.4GB의 메모리를 보유하고 있다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: wwwm-spring-be-deployment
spec:
replicas: 2
...
resources:
requests:
cpu: "800m"
memory: "400Mi"
limits:
cpu: "1"
memory: "800Mi"이후 현재 배포되고 있는 Deplotment의 스펙을 확인해주었다.
| 시간 | CPU/메모리 사용률 | Pod 개수 변화 |
|---|---|---|
| 초기 상태 | 50% | 2개 (유지) |
| 1분 후 | 92% (기준 초과) | 2개 → 3개 |
| 2분 후 | 93% (계속 초과) | 3개 → 4개 |
| 3분 후 | 87% (계속 초과) | 4개 → 5개 |
| 4분 후 (최대치) | 95% (계속 초과) | 4개 유지 (최대) |
| 이후 하락 | 40% (기준 이하) | 점진적으로 2개로 축소 |
Worker Node가 지닌 전체 리소스와 wwwm-spring-be Pod의 resources.requests에 따라 위와 같은 시나리오를 세워볼 수 있었고, 이를 바탕으로 HPA를 설정하고자 한다.
이때 HPA 설정을 위해 metrics-server가 필요하다.
apiVersion: v1
kind: ServiceAccount
metadata:
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: metrics-server:system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system이후 metrics-server의 권한 문제를 막기 위하여 위와 같이 RBAC관련 설정을 추가한 뒤
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-server
namespace: kube-system
labels:
k8s-app: metrics-server
spec:
selector:
matchLabels:
k8s-app: metrics-server
template:
metadata:
labels:
k8s-app: metrics-server
spec:
serviceAccountName: metrics-server # RBAC 추가
containers:
- name: metrics-server
image: registry.k8s.io/metrics-server/metrics-server:v0.7.2
args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
ports:
- name: https
containerPort: 4443
protocol: TCP
readinessProbe:
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
livenessProbe:
httpGet:
path: /livez
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi위와 같이 --kubelet-insecure-tls를 통해 Kubelet과의 TLS 인증 문제를 해결하고 --secure-port=4443를 통해 metric-server의 기본 보안 포트로 설정해준다.
또한 spec.serviceAccountName: metrics-server를 통해 metrics-server가 올바른 Role을 취득할 수 있도록 추가적으로 설정하면
[root@master k8s]# kubectget pods -n kube-system | grep metrics-server
metrics-server-7698f6b8ff-vltrh 1/1 Running 0 68s위와 같이 정상적으로 metrics-server가 기능하는 것을 볼 수 있으며
[root@master k8s]# kubectl top pods
NAME CPU(cores) MEMORY(bytes)
wwwm-spring-be-deployment-76fbc5d5f6-9wwhk 21m 270Mi
wwwm-spring-be-deployment-76fbc5d5f6-qc4kk 8m 243Mi 위와 같이 각 Pod의 CPU와 Memory 사용량을 모니터링 할 수 있다.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: wwwm-spring-be-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: wwwm-spring-be-deployment
# HPA는 급격하게 Pod 개수를 늘리지 않고
# 현재 상태를 지속적으로 모니터링하여 점진적이고 순차적으로 Pod를 확장 또는 축소
minReplicas: 2
maxReplicas: 5
# CPU나 메모리의 사용률은 각 Pod의 리소스 requests 값 대비 평균 사용량
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
# CPU 사용률 80% 이상일 때 scaling
averageUtilization: 80
- type: Resource
resource:
name: memory
target:
type: Utilization
# 메모리 사용률 80% 이상일 때 scaling
averageUtilization: 80이후 위와 같이 CPU 사용률 또는 메모리 사용률이 80% 이상일 때 최대 5대의 Pod까지 Scaling할 수 있도록 HPA를 설정하였고
[root@master k8s]# k get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
wwwm-spring-be-hpa Deployment/wwwm-spring-be-deployment cpu: 1%/80%, memory: 64%/80% 2 5 2 17mwwwm-spring-be-hpa가 정상적으로 기능하는 것을 볼 수 있었다.
iptables Rule 삭제 문제
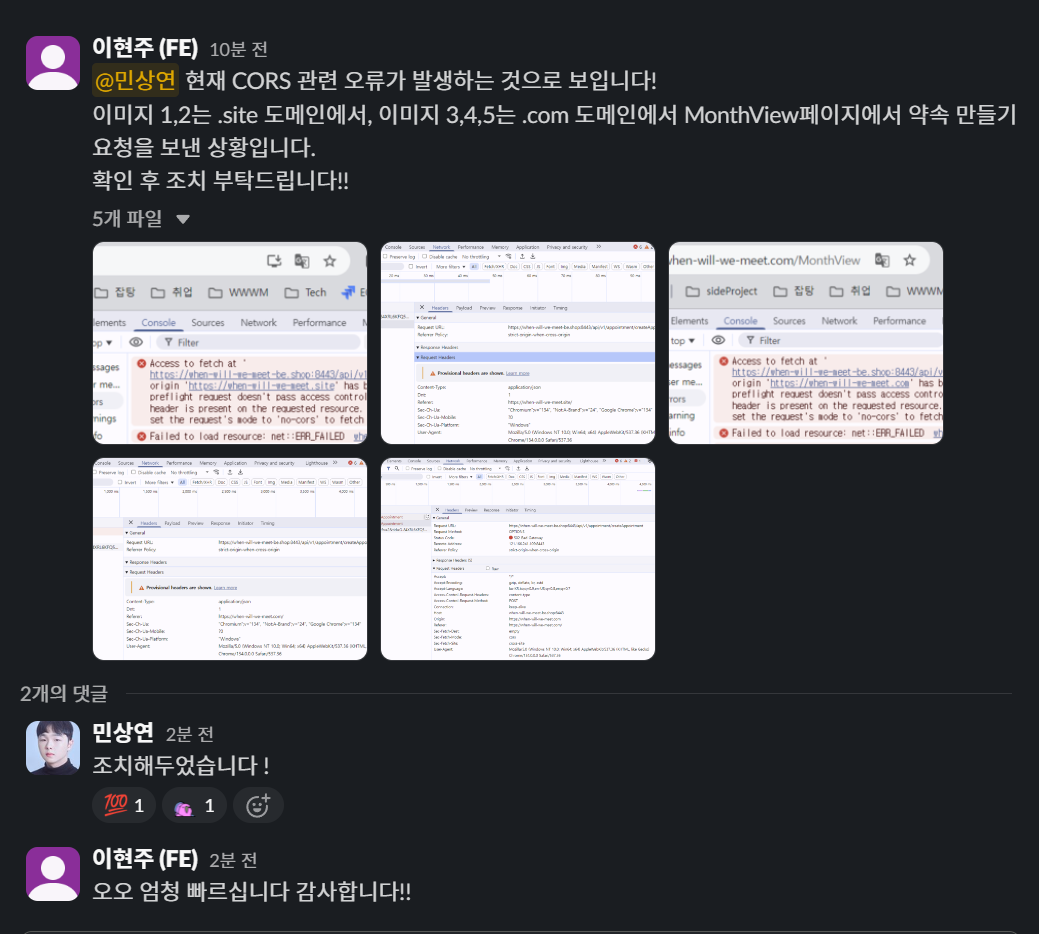 위와 같이 서버가 갑자기 정상적으로 작동하지 않는 문제를 보고받았다.
위와 같이 서버가 갑자기 정상적으로 작동하지 않는 문제를 보고받았다.
[root@controller ~]# openstack server list
+--------------------------------------+--------------+--------+------------------------------------------------+-----------------------------+------------+
| ID | Name | Status | Networks | Image | Flavor |
+--------------------------------------+--------------+--------+------------------------------------------------+-----------------------------+------------+
| 61b0f46e-651b-4564-bc37-0185ff7f18b2 | k8s-worker-2 | ACTIVE | ext-net=192.168.100.29; private-net=10.0.0.107 | Rocky Linux 9 Generic Cloud | k8s.worker |
| 6c59b812-2d8d-4da5-92d6-6bbe527926d6 | k8s-worker-1 | ACTIVE | ext-net=192.168.100.44; private-net=10.0.0.28 | Rocky Linux 9 Generic Cloud | k8s.worker |
+--------------------------------------+--------------+--------+------------------------------------------------+-----------------------------+------------+
[root@master k8s]# k get nodes
NAME STATUS ROLES AGE VERSION
k8s-worker-1.novalocal NotReady worker 36d v1.32.2
k8s-worker-2.novalocal NotReady worker 36d v1.32.2
master Ready control-plane 36d v1.32.2
[root@master k8s]# ping 192.168.100.101
PING 192.168.100.101 (192.168.100.101) 56(84) bytes of data.
From 10.10.10.1 icmp_seq=1 Destination Port Unreachable
From 10.10.10.1 icmp_seq=2 Destination Port Unreachable
...
[root@kubernetes-host ~]# ping 192.168.100.101
PING 192.168.100.101 (192.168.100.101) 56(84) bytes of data.
From 10.10.10.1 icmp_seq=1 Destination Port Unreachable
From 10.10.10.1 icmp_seq=2 Destination Port Unreachable
...이우 여러가지 테스트를 거친 결과 위와 같이 Openstack의 인스턴스는 정상 작동중임에도 불구하고 K8s Master와 해당 인스턴스간 통신이 중단되어 발생하는 문제임을 파악하였다.
이전까지는 이러한 상황이 호스트 머신 자체를 재부팅 할 때만 발생하여서, 수동으로 iptables Rule을 각각의 호스트 머신에 할당하는 것으로 해결하였지만, 서비스가 지속됨에 따라 OpenStack/Kubernetes 특정 이벤트(네트워크 인터페이스 재생성, 보안 그룹 정책 재적용 등)에 따라 이러한 문제가 발생할 수도 있음을 인지하고 자동적으로 이러한 상황을 방지할 수 있도록 조치하였다.
[root@openstack-host ~]# vim /usr/local/bin/check_iptables.sh
#!/bin/bash
RULES=(
"LIBVIRT_FWI -s 10.10.10.0/24 -d 192.168.100.0/24 -j ACCEPT"
"LIBVIRT_FWO -s 192.168.100.0/24 -d 10.10.10.0/24 -j ACCEPT"
)
for rule_info in "${RULES[@]}"; do
# ex. "LIBVIRT_FWI -s 10.10.10.0/24 -d 192.168.100.0/24 -j ACCEPT"
CHAIN=$(echo "$rule_info" | awk '{print $1}')
RULE=$(echo "$rule_info" | cut -d' ' -f2-)
# iptables -C [체인] [조건] 으로 검사
# Rule이 없으면(exit code != 0) 추가
iptables -C $CHAIN $RULE 2>/dev/null
if [ $? -ne 0 ]; then
# Rule 추가 시 1번째 위치에 삽입
iptables -I $CHAIN 1 $RULE
echo "[$(date)] Missing rule added: $CHAIN $RULE" >> /var/log/check_iptables.log
fi
done[root@kubernetes-host ~]# vim /usr/local/bin/check_iptables.sh
#!/bin/bash
RULES=(
"LIBVIRT_FWI -s 10.10.10.0/24 -d 172.20.112.0/24 -j ACCEPT"
"LIBVIRT_FWO -s 172.20.112.0/24 -d 10.10.10.0/24 -j ACCEPT"
)
for rule_info in "${RULES[@]}"; do
# ex. "LIBVIRT_FWI -s 10.10.10.0/24 -d 192.168.100.0/24 -j ACCEPT"
CHAIN=$(echo "$rule_info" | awk '{print $1}')
RULE=$(echo "$rule_info" | cut -d' ' -f2-)
# iptables -C [체인] [조건] 으로 검사
# Rule이 없으면(exit code != 0) 추가
iptables -C $CHAIN $RULE 2>/dev/null
if [ $? -ne 0 ]; then
# Rule 추가 시 1번째 위치에 삽입
iptables -I $CHAIN 1 $RULE
echo "[$(date)] Missing rule added: $CHAIN $RULE" >> /var/log/check_iptables.log
fi
done위와 같이 이전까지는 각각의 호스트 머신에서 수동으로 검사하고 추가하였던 iptables Rule을 자동으로 감지하고 추가해줄 수 있는 sh 스크립트를 작성하였다.
sudo chmod +x /usr/local/bin/check_iptables.sh
crontab -e
# * * * * * root /usr/local/bin/check_iptables.sh이후 해당 스크립트의 실행 권한을 변경하고 crontab -e를 통해 매 분마다 해당 스크립트를 실행해줄 수 있게 설정하였다.
이로써, 인프라/백엔드 파트의 KU어드벤처 전공탐험대 부스 운영을 위한 서버 최적화 및 장애 대응 방안 마련이 완료되었다.
행사 기록
 다른 팀원분들의 노력, 그리고 동아리 부원분들의 노력으로 성황리에 신입생분들 그리고 재학생 분들께 동아리와
다른 팀원분들의 노력, 그리고 동아리 부원분들의 노력으로 성황리에 신입생분들 그리고 재학생 분들께 동아리와 언제볼까? 서비스에 대한 홍보를 마쳤다.
이미 스케일링 설정을 해두어서였는지, 서버는 이전과는 다르게 행사 이틀 중 단 한번도 다운되지 않았다.
 학교에서 자율전공학부 신입생분들을 위해 위와 같이 전공 설명회를 개최하고 메이커스팜 동아리 부스의 경우 해당 설명회 출구 바로 앞에 위치하여 다양한 학생분들을 만나뵐 수 있었다.
학교에서 자율전공학부 신입생분들을 위해 위와 같이 전공 설명회를 개최하고 메이커스팜 동아리 부스의 경우 해당 설명회 출구 바로 앞에 위치하여 다양한 학생분들을 만나뵐 수 있었다.

 고생하신 같은 동아리 분들께 감사의 말씀을 올리며, 방문자분들께는 팜플렛이 QR 코드가 기입된 팜플렛을 나누어 드렸기에 앞으로 더 많은 사용자 유입을 기대하게 되었다.
고생하신 같은 동아리 분들께 감사의 말씀을 올리며, 방문자분들께는 팜플렛이 QR 코드가 기입된 팜플렛을 나누어 드렸기에 앞으로 더 많은 사용자 유입을 기대하게 되었다.
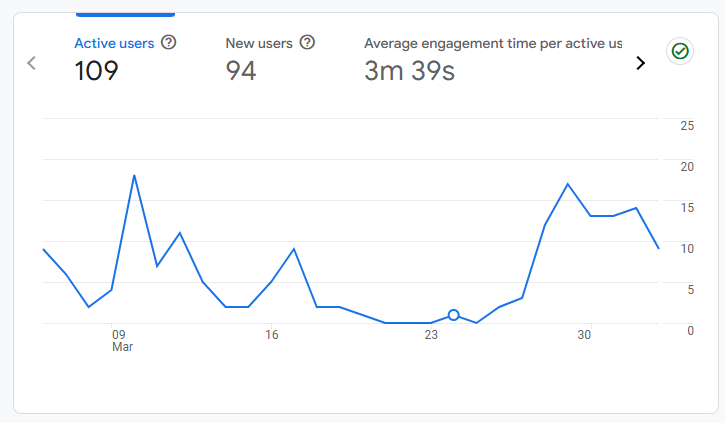
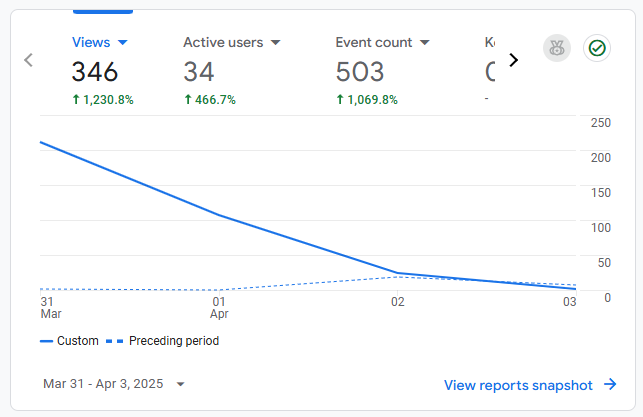 지금까지의 활성 사용자 및 전공탐색 페스티벌 기간의 트래픽과 사용자는 위와 같다, 해당 기간동안 34명의 유저의 346개의 트래픽을 확인할 수 있었다
지금까지의 활성 사용자 및 전공탐색 페스티벌 기간의 트래픽과 사용자는 위와 같다, 해당 기간동안 34명의 유저의 346개의 트래픽을 확인할 수 있었다
LinKU
 또한 위와 같이 같은 동아리 소속의 개발자분께서 건국대학교 교내 웹 사이트를 쉽게 접근할 수 있도록 개발하신 확장 프로그램에 홍보가 가능하도록
또한 위와 같이 같은 동아리 소속의 개발자분께서 건국대학교 교내 웹 사이트를 쉽게 접근할 수 있도록 개발하신 확장 프로그램에 홍보가 가능하도록 언제볼까? 프로젝트에 대한 배너를 추가해주셨다.
