본 포스팅은 다음 저서와 사이트를 참고하여 작성하였습니다.
Do it! BERT와 GPT로 배우는 자연어 처리
https://www.yes24.com/Product/Goods/105294979
https://ratsgo.github.io/nlpbook/docs/language_model/transformers/
https://jalammar.github.io/illustrated-transformer/
Self-Attention?
Attention 먼저 설명하겠습니다.
Attention 은 '(문장을 구성하는 요소들 중) 중요한 요소에 더욱 집중하기' 입니다.
기계 번역에 attention 을 도입한다면 타깃 언어를 디코딩할 때 소스 언어의 단어 시퀀스 중 디코딩에 도움이 되는 단어 위주로 취사선택해서 번역 품질을 끌어올립니다.
즉, 어텐션은 디코딩할 때 소스 시퀀스 중 주요한 요소만 추립니다.
Self-Attention 은 자신에게 수행하는 어텐션 기법으로,
입력 시퀀스 중 태스크 수행에 의미 있는 요소들 위주로 정보를 추출합니다.
Attention 과 Self-Attention 의 주요 차이는 다음과 같습니다.
- Attn : 소스 시퀀스 전체 단어 - 타깃 시퀀스 단어 1개 연결.

Self-Attn : 소스(입력) 시퀀스의 전체 단어들 사이 연결


-
Attn 은 RNN 구조 위에서 동작하지만 Self-Attn 은 RNN 없이 동작
-
타깃 언어의 단어를 1개 생성할 때
Atten : 1회 수행
Self-Atten : 인코더, 디코더 블록의 갯수만큼 반복 수행
https://ratsgo.github.io/nlpbook/docs/language_model/transformers/
Self-Attention 계산식
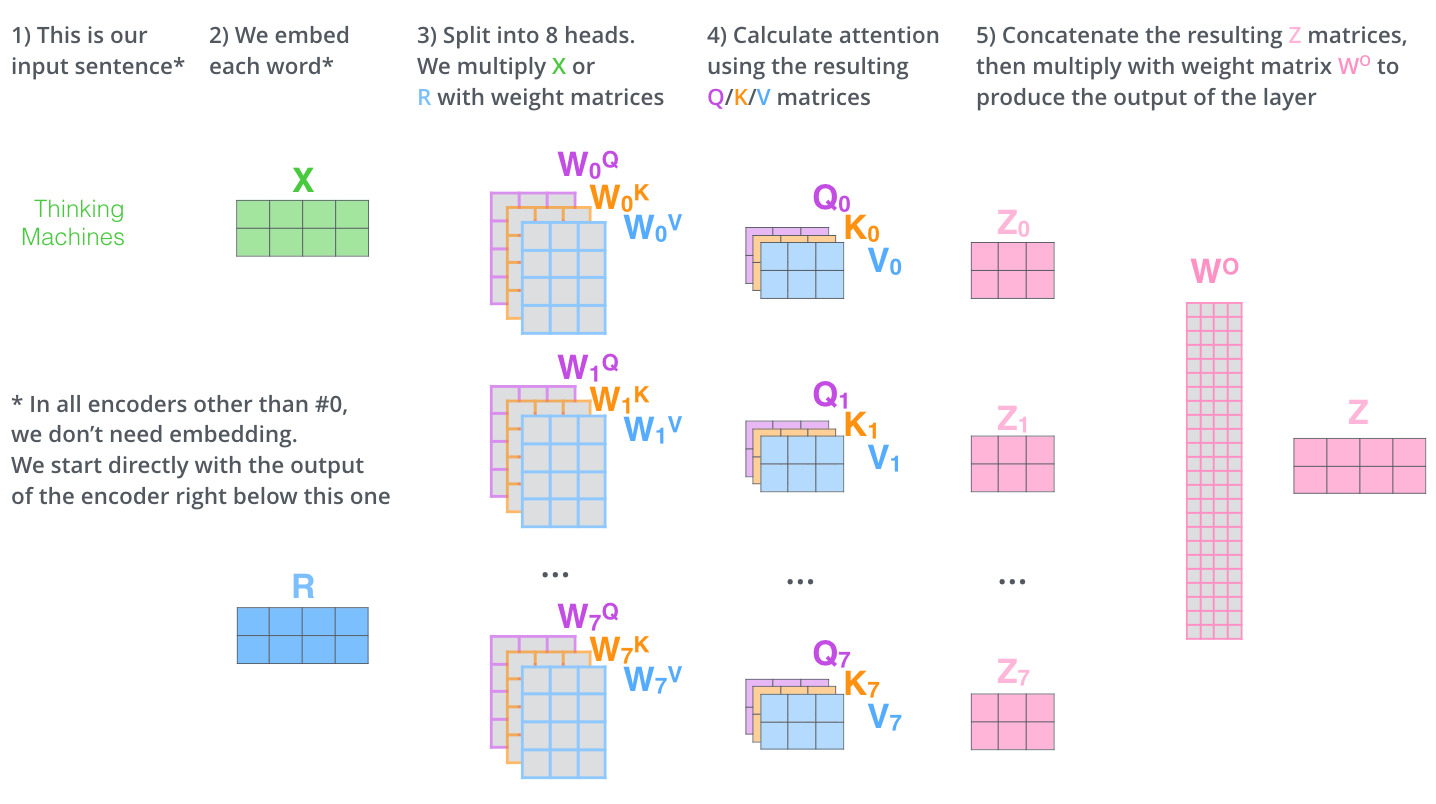
Self-Attention 은 Embedding vector 에 Query, Key, Value 를 이용해 계산합니다.
1. Query, Key, Value vector 생성
계산식 측면에서 self-attention 은 Query, Key, Value 3개 요소 사이의 문맥적 관계성을 추출하는 과정으로
인코더의 각 입력 벡터 시퀀스(이 경우 각 단어의 임베딩) 의 각 단어에 대해 Query 벡터, Key 벡터 및 Value 벡터를 만듭니다.
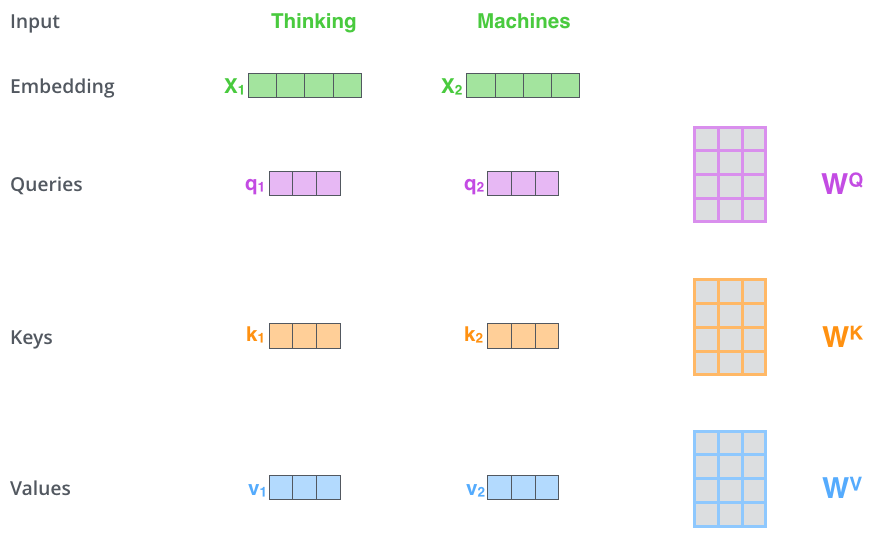
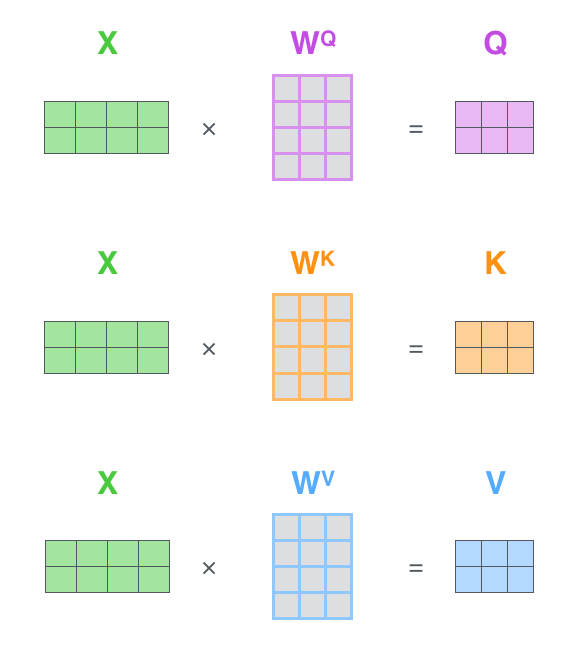
입력 벡터 시퀀스 X 에 W 행렬을 곱하여 각각 Q, K, V 벡터를 만드는데요,
이 W 행렬은 학습 과정에서 업데이트됩니다.
Q = X * WQ
K = X * WK
V = X * WV좀더 디테일하게 말하면 이래요.
, , 3가지 행렬을 이용해
각 단어 에 대한 , , 벡터가 생성되고
이 , , 3개 행렬은 학습 과정에서 업데이트됩니다.
q1 = x1 * WQ
k1 = k1 * WK
v1 = v1 * WV이러한 새 벡터는 64 차원이라서 임베딩 및 인코더 입/출력 벡터 차원인 512 보다 작습니다.
새 벡터의 차원수가 더 작을 필요는 없으며 이는 multiheaded attention 계산을 (대부분) 일정하게(constant) 만들기 위함입니다.
2. Self-Attention 계산
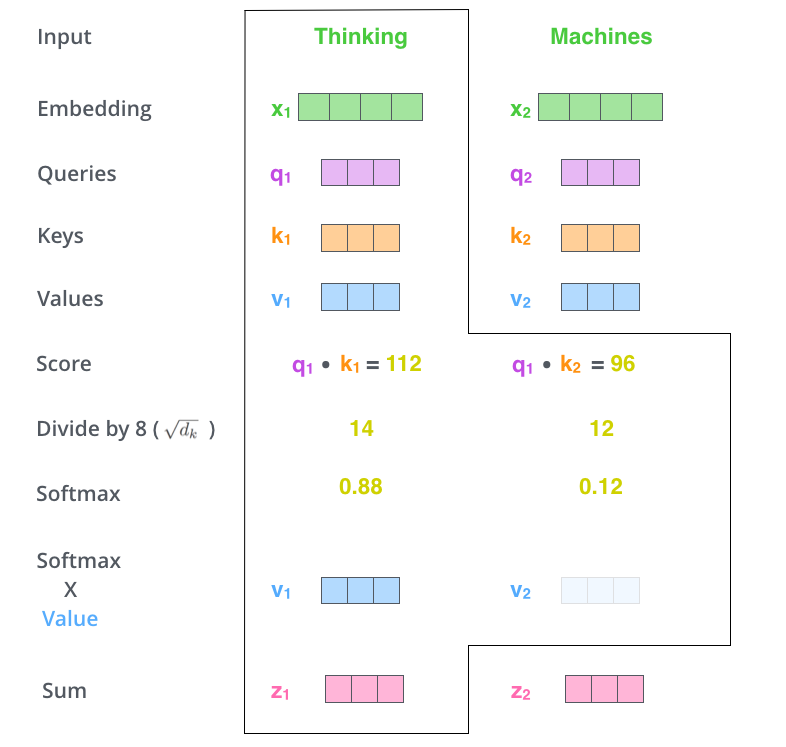
앞서 구한 K, Q, V 벡터를 Self-Attn 수식에 넣어 Self-Attn score 를 계산합니다.
score 는 특정 위치에서 단어를 인코딩할 때 입력 문장의 다른 부분에 얼마나 초점을 맞출지를 결정합니다.
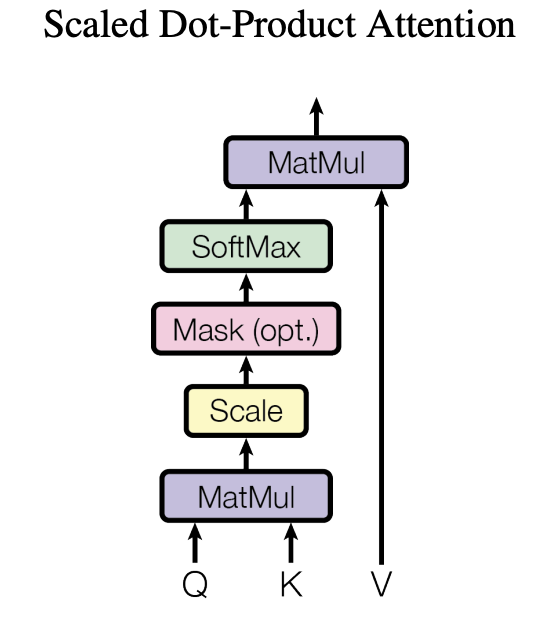
Self-Attention 수식 (Scaled-Dot Product Attention) :
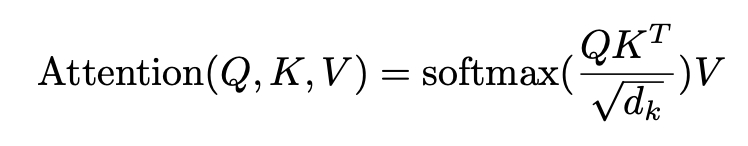
Self-Attn 을 계산하는 과정을 정리했습니다.
- Score (=, MatMul)
각 단어 : 모든 단어의 score 를 각각 구합니다.
Score 는 각 단어의 Q * K(dot product(행렬 내적 곱 연산)) 값입니다.
따라서 첫 번째 단어 x1에 대한 Self-Attention score 를 구하기 위해 를 모두 계산합니다.
- q1 * k1 (첫번째 단어의 score)
- q1 * k2 (두번째 단어의 score)
- ...
-
(Scale)
Score 를 , 즉 = 8 로 나눕니다.
만약 Query와 Key의 차원이 커지면 내적 값은 Attention score도 커지게 되어 모델의 학습에 어려움이 생깁니다.
때문에 이 문제를 해결하기 위해 만큼 나누어 주는 스케일링 작업을 진행합니다.
여기까지의 과정을 "Scaled dot-product Attention"이라고 합니다.
https://codingopera.tistory.com/43 -
각 score 벡터에 softmax 를 취해 줍니다.
softmax는 하나의 리스트 안에 들어있는 수치들을 정규화하는 함수로,
리스트 내의 수치들을 모두 양수로, 합쳐서 1이 되도록 바꾸어 줍니다.
이 softmax score 는 각 단어가 이 위치에서 얼마나 많이 표현되는지를 결정합니다. -
softmax * V (MatMul)
각 Value 벡터에 softmax score 를 곱합니다.
이는 집중하려는 단어의 값은 그대로 유지하고 관련 없는 단어를 제외하기 위함입니다.
예를 들어 0.001과 같은 작은 숫자를 곱하면 관련 없는 단어가 제외되겠지요. -
Sum
가중치 벡터를 합산하여 n번째 단어에 대한 self-attention 레이어의 output을 생성합니다.
실제 Self-Attn 은 행렬 연산을 통해 벡터 여러 개의 연산이 한방에 수행됩니다!
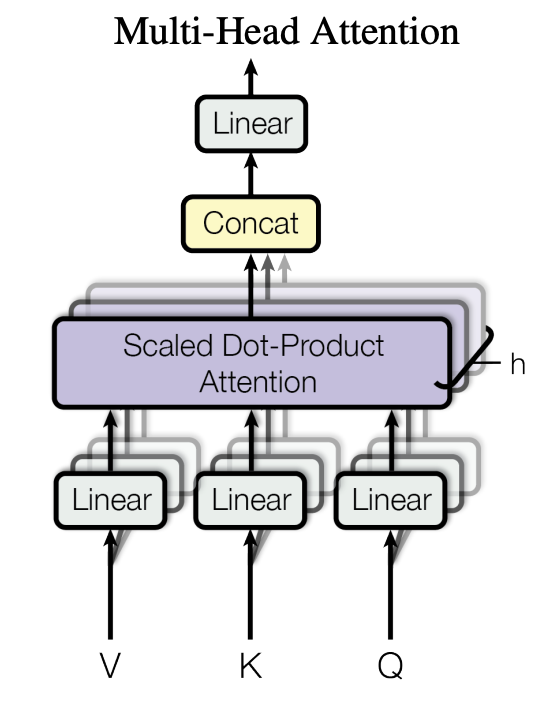
Multi-Head Attention
Self-Attn 을 동시에 여러 번 수행하는 것으로
여러 head가 독자적으로 Self-Attn 을 계산한다는 의미입니다.
더 쉽게 설명하면 같은 문서(input) 을 여러 명의 독자(head) 가 함께 읽는 구조이지요.
예를 들면 Transformer 의 기본값은 d_model(벡터 차원 수) = 64, head = 8이므로
길이가 64인 문서를 8명이 각각 8등분하여 8줄씩 읽는 셈입니다.
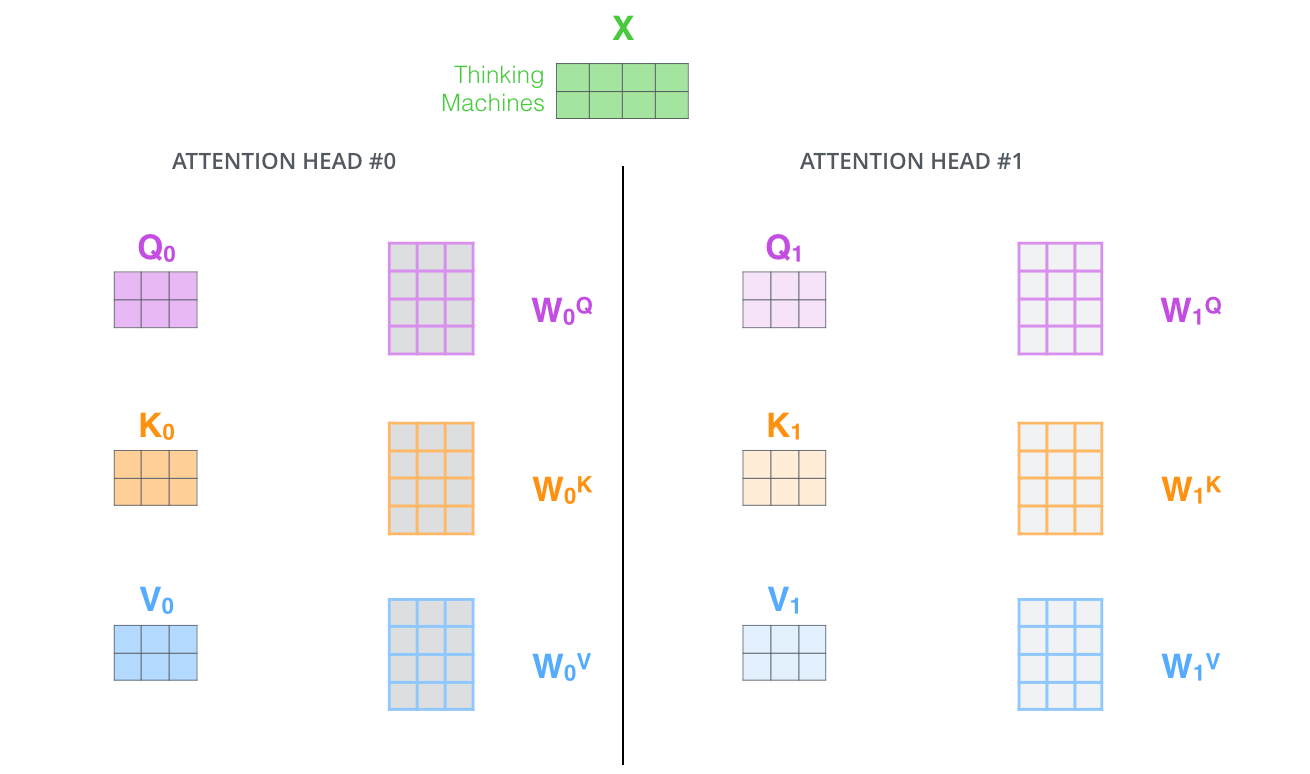
앞서 말한 수식을 따르면 가중치 행렬인 W가 head 갯수인 8개만큼 생기고
서로 다른 8개의 W을 이용해 서로 다른 8개의 Self-Attn score, 즉 Sum(Z) 를 얻게 됩니다.
그림으로 살펴볼까요?
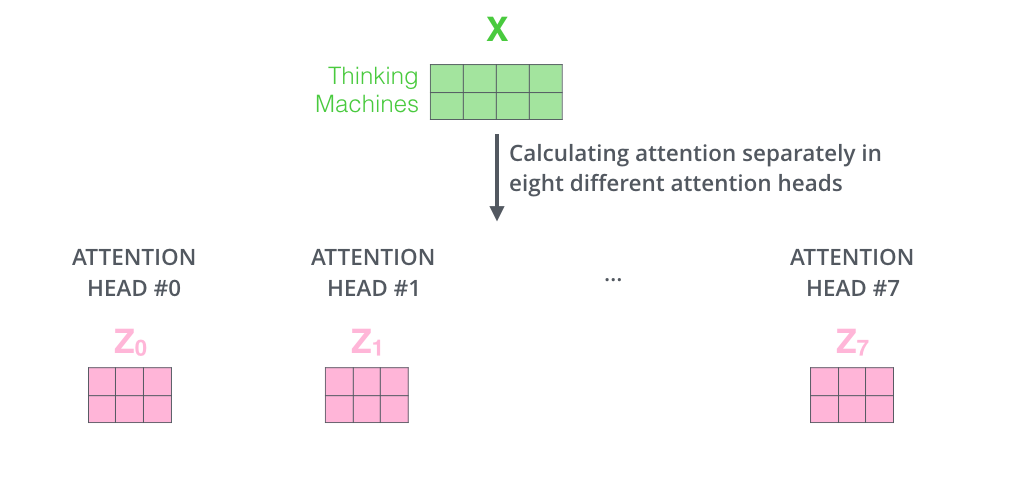
-
Scaled Dot-Product Attention
위에서 설명한 것과 동일한 self-attention 계산을 다른 가중치 행렬 Wn 으로 8번만 수행하면 결과적으로 8개의 다른 Z 행렬이 생성됩니다.
-
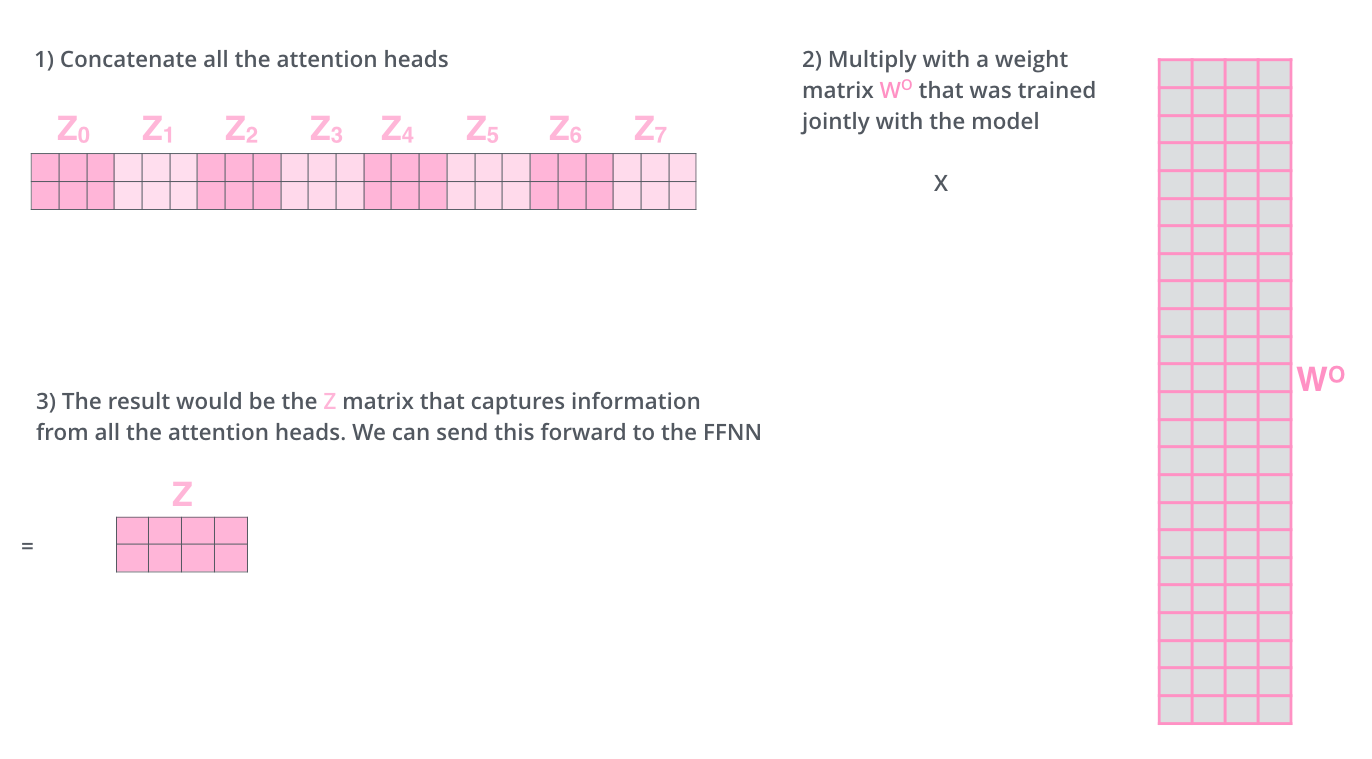
Concat & Linear
그런데 FFNN 레이어는 서로 다른 8개의 행렬이 아니라 단일 행렬(각 단어에 대한 벡터)을 처리하므로,
우리는 이 8개의 Z를 1개의 행렬로 압축하는 방법이 필요합니다.
방법은 간단합니다. 8개의 Z 행렬을 연결하여 1개로 만든 다음 다음 추가 가중치 행렬 WO를 곱합니다.
Conclusion
Reference
https://codingopera.tistory.com/43
https://codingopera.tistory.com/44?category=1094804
https://velog.io/@cha-suyeon/멀티-헤드-어텐션Multi-head-Attention-구현하기
