[RAG 시리즈] PGVector 와 프롬프트를 이용한 RAG 고도화 포스팅에서
PDF 파일 로드 -> 청킹 -> vector store 에 저장하는 과정을 다루었는데요,
이번 포스팅에서는 vector store DB에 데이터가 어떤 형태로 저장되어 있는지 살펴보고,
데이터 활용도를 높이기 위해 DB테이블을 조작해 봅니다.
**튜토리얼 코드 : GitHub Rag Series
Langchain - Document 타입
LangChain 에서 제공하는 PyPDFLoader 를 사용하여 PDF 문서를 로드하면
Langchain 만의 데이터 타입인 Document 타입으로 변환됩니다.
ChatGPT 는 다음과 같이 간결하게 설명하네요.
langchain에서 사용하는 Document 타입은 자연어 처리 및 머신러닝 작업을 위해 데이터를 구조화하는 데 사용되는 기본적인 객체입니다. Document는 텍스트와 관련된 메타데이터를 포함할 수 있습니다.
다음과 같이 1페이지당 1개의 'Document' 타입으로 변환되는데
다시 말해 로더는 각각의 페이지를 읽어서 각 페이지마다 Document object 를 생성하고,
이 Object 들을 하나의 리스트에 모아(묶어) 줍니다.
from langchain.document_loaders import PyPDFLoader
# PDF 파일 로드
loader = PyPDFLoader("../data/[일반보험]_KB개인상해보험_보험약관.pdf")
document = loader.load()Document 타입을 구성하는 요소는 아래와 같이 여러 가지가 있는데,
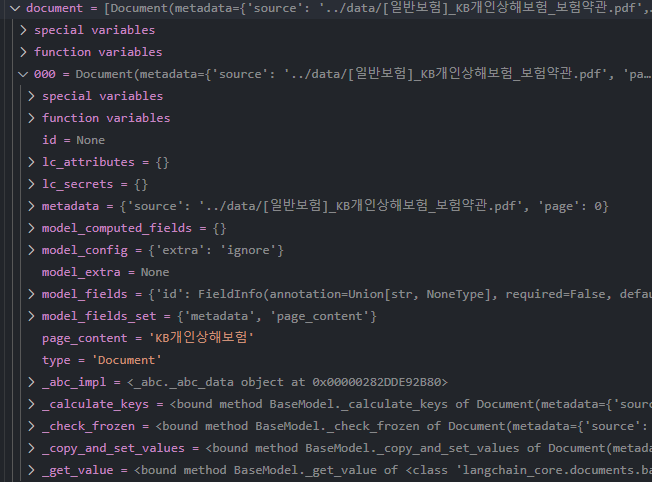
다음 요소만 알아도 실전에서 데이터를 활용하는 데에 충분했습니다. (아직까지는..)
page_content: 문서의 실제 텍스트 내용을 담고 있습니다. 이 필드는 분석, 검색, 임베딩 등 다양한 작업에 사용됩니다.metadata: 문서에 대한 추가 정보를 포함하는 딕셔너리입니다. 예를 들어, 작성자, 날짜, 문서의 카테고리 등과 같은 메타데이터를 저장할 수 있습니다. 이 정보는 문서의 의미를 더 풍부하게 하고, 특정 작업에 유용하게 활용될 수 있습니다.id (선택 사항): 문서를 고유하게 식별하는 ID입니다. 이 필드는 기본적으로 제공되지 않지만, 사용자 정의 ID를 추가할 수 있습니다.
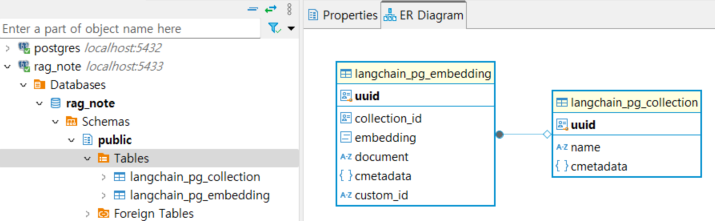
Vector Store DB
Document 타입으로 변환된 데이터는 vector store 에 저장되며
Langchain Vector Store 의 기본 DB 구조는 다음과 같이 크게 2개의 테이블로 이루어집니다.
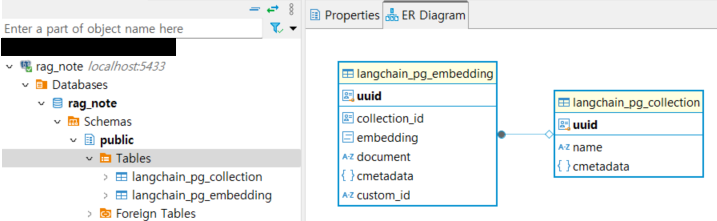
(langchain_pg_collection 테이블의 uuid 와
langchain_pg_embedding 테이블의 collection_id 로 서로 연결되어 있어서 같은 값을 가집니다.)
langchain_pg_collection 테이블에는 문서의 전체적인 정보,
예를 들어 db collection name, 문서의 uuid 가 저장되고
langchain_pg_embedding 테이블에는 문서의 각 페이지 정보,
예를 들어 embedding, document, cmetadata 등이 저장됩니다.

collection_id: 문서의 uuiddocument: 문서 페이지의 텍스트embedding:document(=문서 페이지의 텍스트) 를 임베딩한 값cmetadata: 문서 페이지 정보 (기본값으로 페이지 정보와 문서 경로가 들어간다.)
만약 문서에 대해 추가적인 정보를 저장하거나 수정하고 싶다면 이 컬럼을 조작하면 된다.
(custom_id 컬럼은 처음에는 없었는데 뭔가 작업을 하다 보니 생성되었다...!
SQL 작업을 하다 보면 custom_id 가 없어서 에러가 날 때가 있는데,
예제에서 설명할 langchain_pg_embedding 테이블에 컬럼 추가 + 데이터 넣어서 쓰려다가 custom_id 에러가 나서 실패했다.)
DB 테이블 활용 예제
벡터 스토어를 세팅하고 데이터를 로드하는 코드는 예제 모두 동일하게 사용합니다.
벡터 스토어 세팅
from langchain_postgres import PGVector
from langchain_postgres.vectorstores import PGVector
from langchain_openai import OpenAIEmbeddings
# See docker command above to launch a postgres instance with pgvector enabled.
# connection = f"postgresql+psycopg2://user:password@host:5432/name",
connection=f"postgresql+psycopg2://rag_note:rag_note@localhost:5433/rag_note"
collection_name = "my_db"
vector_store = PGVector(
embeddings=OpenAIEmbeddings(model="text-embedding-3-large"),
collection_name=collection_name,
connection=connection,
use_jsonb=True,
)데이터 로드
from langchain.document_loaders import PyPDFLoader
# PDF 파일 로드
loader = PyPDFLoader("../data/[일반보험]_KB개인상해보험_보험약관.pdf")
document = loader.load()
document[0].page_content[:200] # 내용 추출데이터 분할
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
texts = text_splitter.split_documents(document)1. 기본 임베딩 스토어 사용
vector_store.add_documents(texts)Langchain 이 두 개의 테이블을 생성하고, embedding table 에 기본 컬럼을 생성한 뒤
다음과 같이 데이터를 넣어 줍니다.
2. Document object 의 metadata 컬럼에 문서 정보 추가
기본적으로 cmetadata 컬럼에는 페이지 번호와 파일 경로만이 담겨 있는데,
추가적인 파일 정보를 저장하고 활용하기 위해 cmetadata 컬럼에 위해 보험의 상품명과 정보를 추가해 보겠습니다.
간단하게, 벡터 스토어에 저장하기 전의 Document object 를 조정하면 됩니다.
for text in texts:
text.metadata['product'] = "KB개인상해보험"
text.metadata['info'] = "보험약관"
# 위 for 문을 List Comprehension 으로 다음과 같이 한 줄로 쓸 수 있다!
# [text.metadata.update({'product': "KB개인상해보험", 'info': "보험약관"}) for text in texts]
vector_store.add_documents(texts)
3. Document object 의 metadata 컬럼에 문서 정보 추가 (클래스 오버라이딩 이용)
만약 실제 서비스를 개발하는 단계에서, 벡터 스토어에 CRUD 할 때 추가적인 작업을 매번 해야 한다면
예를 들어 2번 예제와 같이 특정 컬럼에 데이터를 반드시 추가해야 하는 등의 작업을 매번 해야 한다면
클래스 오버라이딩을 활용하는 편이 효율적일 수 있습니다.
- OverridingPGVector 클래스를 만들고, PGVector 클래스를 오버라이딩합니다.
- _add_documents 함수를 만들고, 필요한 데이터 작업을 수행한 뒤에 add_documents 메소드를 호출합니다.
from langchain_community.vectorstores.pgvector import PGVector
from langchain_openai import OpenAIEmbeddings
from langchain_core.documents import Document
from sqlalchemy import text
from typing import Any
from overrides import overrides
class OverridingPGVector(PGVector):
@overrides
def __post_init__(self):
super().__post_init__()
def _add_documents(self, documents: list[Document], **kwargs: Any) -> list[str]:
for doc in documents:
doc.metadata['product'] = "KB개인상해보험"
doc.metadata['info'] = "보험약관"
# 위 for 문을 List Comprehension 으로 다음과 같이 한 줄로 쓸 수 있다!
# [text.metadata.update({'product': "KB개인상해보험", 'info': "보험약관"}) for text in texts]
return self.add_documents(documents, **kwargs)OverridingPGVector 객체를 생성합니다.
(함수 인자 이름이 약간 달라진 점에 주의합니다.)
_vector_store = OverridingPGVector(
# embeddings=OpenAIEmbeddings(model="text-embedding-3-large"),
embedding_function=OpenAIEmbeddings(model="text-embedding-3-large"),
collection_name=collection_name,
# connection=connection,
connection_string=connection,
use_jsonb=True,
)_vector_store._add_documents(texts)
참고
vector_store.add_documents 메소드 실행 시 langchain_pg_embedding 테이블에 id 컬럼이 없어서 에러가 나는 경우가 있는데,
Langchain 의 버전 차이로 인해 uuid -> id 를 참조하게 되어 발생하는 에러입니다.
아래 글을 참고해 주세요. (테이블을 지우고 새로 Langchain 코드를 실행하면 됩니다)
https://github.com/langchain-ai/langchain/discussions/21557
Tip : 임베딩 테이블에 컬럼 추가하기
아래는 langchain_pg_embedding 테이블에 'product' 컬럼을 추가하는 예시 코드입니다.
class OverridingPGVector(PGVector):
@overrides
def __post_init__(self):
super().__post_init__()
self._add_embedding_culumn()
def _add_embedding_culumn(self):
with self._make_session() as session:
# 컬럼 추가 SQL
session.execute(text(f"""
ALTER TABLE {self.EmbeddingStore.__tablename__}
ADD COLUMN IF NOT EXISTS product varchar;
"""))
session.commit()__post__init__() 생성자를 이용해 클래스가 호출되어 객체가 생성될 때
_add_embedding_culumn 메소드가 자동으로 실행되어 product 컬럼이 테이블에 추가됩니다.
(깔끔하게 product 컬럼에 데이터를 넣는 코드는 못 짰습니다.. DB고수님들 헲미... ㅠㅠ)
