Hybrid Search
설명을 위해 다음 포스팅 글 중 일부를 발췌하여 재구성했습니다.
[우아한 스터디] RAG 성능을 끌어올리는 Pre-Retrieval (Ensenble Retriever) 와 Post-Retrieval (Re-Rank)
하이브리드 검색 구현하기 (feat. EnsembleRetriever, Knowledge Bases for Amazon Bedrock)
Hybrid Search 는 다음과 같은 이유로 등장했습니다.
LLM은 특정 시간에 학습을 멈추고 배포되기 때문에 실시간 데이터와 일치하지 않는 경우가 많다. 또한, 모든 데이터를 학습시킬 수 없기 때문에 사실과는 다른 답변을 내놓는 경우도 다수이다. 이러한 문제를 해결하기 위해, LLM에 질문과 유사도가 높은 context를 답변 생성 전에 전달하여 보다 높은 정확도의 답변을 반환하도록 하는 RAG라는 기술이 대두되었다. 현재 LLM을 활용하는 대부분의 챗봇이 환각 현상을 줄이기 위해 RAG를 사용하고 있다.
하지만 이러한 유사도 기반 검색조차 단어 임베딩 품질에 따라 답변의 정확도가 떨어졌으며, 프로덕션 레벨에서 일반 RAG를 사용하기는 부족함이 있었다. 이를 해결하기 위해 유사도에 더해 키워드 기반 검색을 함께 활용하는 Hybrid Search라는 기술이 생겨나게 되었다
쉽게 말해 Hybrid Search 는 크게 Lexical Search 와 Semantic Search 를 결합한 방식으로,
키워드 기반 검색인 Lexical Search와 유사도 기반 검색인 Semantic Search는 각각 장단점이 있고 사용이 유리한 상황이 서로 다릅니다.
- Lexical Search :
OpenSearch와 같은 전통적인 검색 엔진에서 주로 사용되는 방법으로, BM25와 같은 희소 벡터 알고리즘을 통해 키워드 기반 매칭을 진행한다. 특정 도메인 용어를 검색하기에 용이하지만 오타 및 동의어에 취약하다. - Semantic Search :
키워드가 일치하지 않더라도 의미론적으로 유사한 검색 결과를 반환한다. 검색 결과는 임베딩 품질에 의존도가 높다.
'Hybrid Search는 각 검색 방법의 장점만을 추려 사용된다. 특정 도메인 용어나 제품 용어가 포함된 쿼리로 검색했을 때도 Lexical Search의 검색 결과를 통해 보조한다. 의미론적으로 유사한 동의어 검색의 경우 및 오타가 일부 포함되더라도 Semantic Search가 벡터 기반으로 가장 가까운 내용을 반환하기 때문에 보다 정확도를 높일 수 있다.'
각각의 검색 방법에 대해 예시와 함께 매우 쉽게 풀어서 설명한 글을 참고해 보세요.
키워드 검색, 시맨틱 검색 그리고 하이브리드 검색
Ensemble Retriever 를 이용한 Hybrid Search 구현
EnsembleRetriever는 여러 retriever를 입력으로 받아 검색 결과를 앙상블하고, Reciprocal Rank Fusion 알고리즘을 기반으로 결과를 재순위화합니다.
Ensemble Retriever 의 가장 일반적인 패턴은 sparse retriever (예: BM25)와 dense retriever (예: embedding similarity)를 결합하는 것인데, 이는 두 retriever의 장점이 상호 보완적이기 때문입니다. 이를 "hybrid search" 라고도 합니다.
Sparse retriever는 키워드를 기반으로 관련 문서를 찾는 데 효과적이며, dense retriever는 의미적 유사성을 기반으로 관련 문서를 찾는 데 효과적입니다.
출처 : 03. 앙상블 검색기(EnsembleRetriever)
일단, Retriever는 크게 두 가지 유형으로 나눌 수 있습니다:
- Sparse Retriever:
TF-IDF와 같은 기술을 사용하여 텍스트 데이터를 희소 벡터로 변환하고, 질의 벡터와의 유사성에 따라 문서를 검색합니다. - Dense Retriever:
BERT와 같은 신경망 모델을 사용하여 텍스트 데이터를 밀집 임베딩 벡터로 변환하고, 질의 벡터와의 유사성에 따라 관련 문서를 검색합니다.
두 가지 Retriever 유형은 각각의 장단점이 있으며, 검색 작업의 요구에 따라 선택해야 합니다.
Sparse와 Dense Retriever를 결합하여, 즉 서로 다른 알고리즘의 장점을 활용함으로써, EnsembleRetriever는 단일 알고리즘보다 더 나은 성능을 달성하고 검색 효율성을 최적화할 수 있습니다.
아래는 Sparse Retriever(Lexical Search) 중 BM25 와 Dense Retriever(Semantic Search) 중 FAISS 를 결합하여
Ensemble Retriever 를 생성하는 코드입니다.
# FAISS 벡터 스토어 생성
vectorstore_faiss = FAISS.from_documents(docs, embeddings)
# BM25 리트리버 생성 (Sparse Retriever)
bm25_retriever = BM25Retriever.from_documents(docs)
# FAISS 리트리버 생성 (Dense Retriever)
faiss_retriever = vectorstore_faiss.as_retriever(search_kwargs={'k': 5})
# 앙상블 리트리버 생성
self.retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever],
weights=[0.5, 0.5] # 가중치 설정 (가중치의 합은 1.0)
)Ensemble Retriever 를 사용할 수 없는 경우
Ensemble Retriever 는 retriever 들의 결합,
다시 말해 (Langchain 에서 제공하는) vector store 의 retriever,
또는 Langchain 에서 제공하는 retriever 를 결합하여 이용하게 되는데요.
만약 여러 가지 이유로 retriever 를 사용할 수 없어서 Ensemble Retriever 를 적용할 수 없다면 어떻게 해야 할까요?
이 경우 Lexical Search 결과와 Semantic Search 결과를 결합하기 위해 재순위화 알고리즘을 사용할 수 있습니다.
재순위화 알고리즘
데이터 샘플로 아래와 같이 2가지의 Retriver 로 얻은 [(문장, 유사도 점수), ...] 데이터셋을 사용하겠습니다.
lyrics1 = [
("Cause I-I-I'm in the stars tonight", 0.9),
("So watch me bring the fire and set the night alight", 0.8),
("Shining through the city with a little funk and soul", 0.7),
("So I'ma light it up like dynamite", 0.6)
]
lyrics2 = [
("Cause I-I-I'm in the stars tonight", 0.5),
("So watch me bring the fire and set the night alight", 0.4),
("Bring a friend, join the crowd", 0.3),
("Just move like we off the wall", 0.2)
]코드는 아래 깃헙에 올려두었습니다.
GitHub - Rag Series
RRF (Reciprocal Rank Fusion)
기본적으로 Hybrid Retrieval에는 크게 RRF와 CC 방법이 있습니다.
- RRF란?
- 서로 다른 관련성 지표(relevance indicators)를 가진 여러 개의 결과 집합(result sets)을 하나의 결과 집합으로 결합하는 방법 (= rank 사용)
- 튜닝을 필요로 하지 않으며, 서로 다른 관련성 지표들이 상호 관련되지 않아도 고품질의 결과를 얻을 수 있음
- 수식, 알고리즘 코드 및 설명

score = 0.0 for q in queries: if d in result(q): score += 1.0 / ( k + rank( result(q), d ) ) return score- N : 랭킹 리스트 갯수
- rank(d) : 문서 d의 rank (순위)
- result(q) : q(query) 를 질의했을 때 얻은 결과 문서 목록
- k : 랭킹 상수 (default = 60)
추가 설명과 코드는 다음 포스팅을 추천합니다.
[NLP]. Reciprocal rank fusion (RRF) 이해하기
[NLP] Reciprocal Rank Fusion(RRF)을 활용한 검색 시스템 성능 향상
[IR] RRF(Reciprocal Rank Fusion) 설명과 파이썬 코드
RRF는 특히나 Langchain 의 Ensemble Retriever 에서 사용하는데요,
Langchain 에서 사용하는 RRF 코드 분석은 아래 포스팅에서 잘 설명해 놓았습니다.
랭체인의 Ensemble Retriever, 이게 대체 뭐지?
Code
from typing import List, Tuple
def rrf_combination(
lyrics1: List[Tuple[str, float]],
lyrics2: List[Tuple[str, float]],
k: int = 60 # RRF에서 사용하는 상수 (기본값 60)
) -> List[Tuple[str, float]]:
combined_results = {}
# 첫 번째 결과의 Reciprocal Rank 계산 및 점수 합산
for rank, (text, score) in enumerate(lyrics1):
if text not in combined_results:
combined_results[text] = 0
combined_results[text] += score + 1 / (k + rank)
# 두 번째 결과의 Reciprocal Rank 계산 및 점수 합산
for rank, (text, score) in enumerate(lyrics2):
if text not in combined_results:
combined_results[text] = 0
combined_results[text] += score + 1 / (k + rank)
# 사전의 값을 리스트로 변환하고, 점수에 따라 내림차순으로 정렬
sorted_combined_results = sorted(combined_results.items(), key=lambda x: x[1], reverse=True)
return sorted_combined_results
rrf_combination(lyrics1, lyrics2)결과 (중복 제거 후 rrf score 계산)
[("Cause I-I-I'm in the stars tonight", 1.4333333333333336),
('So watch me bring the fire and set the night alight', 1.2327868852459019),
('Shining through the city with a little funk and soul', 0.7161290322580645),
("So I'ma light it up like dynamite", 0.6158730158730159),
('Bring a friend, join the crowd', 0.3161290322580645),
('Just move like we off the wall', 0.21587301587301588)]선형 결합 (Linear Combination)
사실 선형 결합은 완전 기초 개념이라 수식만 보고 바로 알아보는 분들이 많으실 텐데요,
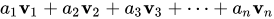
선형 결합은 보통 벡터에 적용하지만, 검색 결과를 점수 기준으로 결합할 때에도 사용할 수 있습니다.
Code
# None 값을 0으로 치환하는 함수
def safe_float(value):
return 0.0 if value is None else float(value)import math
def normalize_score(score, min_score, max_score):
"""
점수를 정규화합니다.
1. Min-Max 정규화를 통해 입력 점수를 0-1 범위로 조정
2. 로그 변환을 적용하여 점수 분포 조정
3. 지수 함수를 사용하여 최종 유사도 점수 계산
Parameters:
rank (float): 변환할 개별 문서의 점수
min_rank (float): 현재 검색 결과 세트의 최소 점수
max_rank (float): 현재 검색 결과 세트의 최대 점수
Returns:
float: 0-1 사이의 점수
"""
# 1. Min-Max 정규화
if (score - min_score) == 0 and (max_score - min_score) == 0:
normalized_rank = 0
else:
normalized_rank = (score - min_score) / (max_score - min_score)
# 2. 로그 변환 (1을 더해 0을 방지)
log_rank = math.log(1 + normalized_rank)
# 3. 지수 변환으로 0-1 범위로 매핑
cosine_like_similarity = 1 - math.exp(-log_rank)
return cosine_like_similarityfrom typing import List, Tuple
def linear_combination_search_results(
lyrics1: List[Tuple[str, float]],
lyrics2: List[Tuple[str, float]],
alpha: float = 0.3, # 두 결과 간의 가중치를 조정하는 파라미터
) ->List[Tuple[str, float]]:
# 결과를 결합하기 위한 사전 생성
combined_results = {}
# 첫 번째 결과 추가
for (text, score) in lyrics1:
if text not in combined_results:
combined_results[text] = alpha * safe_float(score)
else:
existing_score = combined_results[text]
combined_results[text] = safe_float(existing_score) + alpha * safe_float(score)
# 두번째 결과 추가
for (text, score) in lyrics2:
if text not in combined_results:
combined_results[text] = alpha * safe_float(score)
else:
existing_score = combined_results[text]
combined_results[text] = safe_float(existing_score) + alpha * safe_float(score)
# 결과 점수 추출
scores = list(combined_results.values())
# 최소값과 최대값 계산
min_score = min(scores)
max_score = max(scores)
# 점수 정규화 및 정렬
normalized_results = [(text, normalize_score(score, min_score, max_score)) for text, score in combined_results.items()]
# 사전의 값을 리스트로 변환하고, 점수에 따라 내림차순으로 정렬
normalized_results.sort(key=lambda x: x[1], reverse=True)
return normalized_results
linear_combination_search_results(lyrics1, lyrics2)[("Cause I-I-I'm in the stars tonight", 0.5),
('So watch me bring the fire and set the night alight', 0.4545454545454545),
('Shining through the city with a little funk and soul', 0.2941176470588235),
("So I'ma light it up like dynamite", 0.2499999999999999),
('Bring a friend, join the crowd', 0.07692307692307687),
('Just move like we off the wall', 0.0)]보르다 계산법 (Borda count)
다중 선호도 평가에서 사용되는 'Borda Count' 를 사용할 수도 있는데요,
위키피디아에서는 다음과 같이 설명합니다.
Borda 방식 또는 순위는 각 후보자에게 아래에 순위가 매겨진 후보자 수와 같은 점수를 부여하는 위치 투표 규칙 입니다 . 가장 낮은 순위의 후보자는 0점, 두 번째로 낮은 후보자는 1점 등입니다. 모든 투표가 집계되면 가장 많은 점수를 받은 옵션 또는 후보자가 승자가 됩니다.
Borda count - Wikipedia
Borda count (보르다 계산법)
pip install borda 로 패키지를 설치하여 사용할 수도 있는데,
제가 시도해 보니 unhashable type 에러가 납니다.
Code
def borda_count_combination(
lyrics1: List[Tuple[str, float]],
lyrics2: List[Tuple[str, float]],
) ->List[Tuple[str, float]]:
combined_results = {}
# 첫 번째 결과에 순위 점수 부여
for rank, (text, score) in enumerate(lyrics1):
if text not in combined_results:
combined_results[text] = 0
combined_results[text] = combined_results[text] + len(lyrics1) - rank
# 두 번째 결과에 순위 점수 부여
for rank, (text, score) in enumerate(lyrics2):
if text not in combined_results:
combined_results[text] = 0
combined_results[text] = combined_results[text] + len(lyrics2) - rank
# 사전의 값을 리스트로 변환하고, 점수에 따라 내림차순으로 정렬
sorted_combined_results = sorted(combined_results.items(), key=lambda x: x[1], reverse=True)
return sorted_combined_results
borda_count_combination(lyrics1, lyrics2)[("Cause I-I-I'm in the stars tonight", 8),
('So watch me bring the fire and set the night alight', 6),
('Shining through the city with a little funk and soul', 2),
('Bring a friend, join the crowd', 2),
("So I'ma light it up like dynamite", 1),
('Just move like we off the wall', 1)]Reference
https://medium.com/@dk02315/opensearch-키워드-벡터-기반-hybrid-search-구현-fe1426910b26
https://velog.io/@uiw_min/Hybrid-Search
