📢대규모 원시 말뭉치의 철자오류 탐지 및 교정 방법
1. 대규모 원시 말뭉치의 철자 오류 탐지 및 교정 방법
- 오류어 탐지: 한글 코드체계와 n-gram 음절빈도 기준
- 탐지된 오류어를 기준으로 교정 후보어 생성
- 최적의 후보어 선택 위해 단어 임베딩 벡터
❗ n-gram 언어모델 보다 14.4% 향상
시스템 구조도
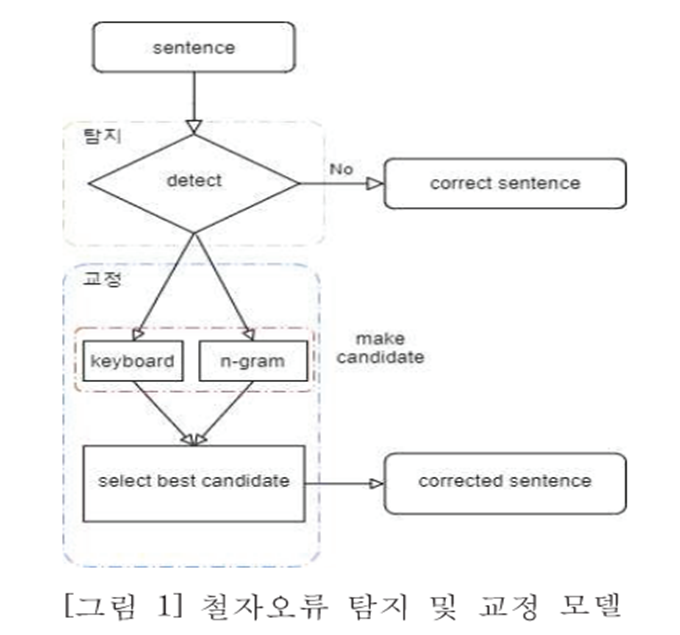
2. 철자 오류 탐지(어절 수준)
- KCC150 사용
뉴스기사 문장으로 이루어진 말뭉치, 철자 오류 별도 표기❌
KS완성형 사용해서 음절 코드값이 한글코드 범위에 속하지 않으면 철자오류로 판단 - 음절 빈도 사용
정타로 가정하는 음절의 빈도는 KCC150기준 500회, 범위에 미치지 못할 경우 철자오류로 판단
3. 철자 오류 교정
- 후보어 생성
-
교정어 후보 생성위해 키보드 거리를 통한 방법 사용(이웃된 키를 선택한 철자 오류)
-
좌우, 상하좌우, shift거리, 상하좌우와 대각선 거리 고려 (키보드 거리)
-
n-gram 언어모델 중 trigram을 적용하여 음절 출현 확률 계산
-
말뭉치에서 직전 음절 2개를 기준으로 현재 시점에 출현 가능한 음절들 미리 계산
-
계산된 음절값을 바탕으로 철자 오류로 탐지된 음절 기준, 직전 2개의 음절에서 출현 가능한 음절셋을 후보군으로 나열
-
철자오류로 판단된 음절과 후보군의 음절간 자소차이가 2이상이면 연관성이 낮아서 차이가 1인 경우를 선별하여 최종 후보군으로 선택
- 후보어 선택
- 후보어를 바탕으로 적합한 교정어 선택위해 단어 임베딩 기법인 Word2Vec Skip-gram사용
4. 실험 결과
- 단어벡터 : 위키피디아 말뭉치 + KCC150 말뭉치 => 2억 4천만 어절
- 교정 성능 평가위해 KCC150에서 KS완성형 한글코드 범위 벗어나는 음절이 포함된 문장 500
+저빈도 음절이 포함된 문장 500개 선정 - 1,000개의 문장 중 교정이 필요한 문장은 전문가에 의하여 교정
- 성능 지표는 문장 정확도

- KS완성형 > KS완성현 + 저음절
- n-gram > 키보드 + n-gram
- 저음절 기준 키보드 > n-gram
- 키보드+n-gram 정확도 떨어지고 KS완성현 > 저음절
❗ 저음절에 해당하는 음절이 출현빈도 낮아 단어를 교체하게 되면서 정답을 찾아내지 못했음을 의미 - KS완서형 + 저음절 > 저음절
📢NeuSpell: A Neural Spelling Correction Toolkit
1. Abstract
- 많은 시스템이 잘못된 토큰 주변 컨텍스트를 적절히 활용❌
- 본 논문에서 뉴럴 철자 교정을 학습하기 위해 text noising을 사용하여 컨텍스트에서 철자 교정을 위한 합성 학습 데이터 소개
- ELMO, BERT와 같은 사전학습 모델의 contextual representation을 실험하고 기존 뉴럴 아키텍처와 비교
- 이전의 철자 검사보다 적대적 공격에 더 나음
2. Models in NeuSpell
10개의 철자 교정 모델(뉴럴모델X 2개, 철자교정 위한 기존 뉴럴 모델4개, 확장한거4개)
-6개 모델 소개
-
GNU Spell: metapone phonetic 알고리즘 조합, Ispell의 near miss 전략 및 후보 단어 점수를 매기는 weighted edit distance 메트릭
metapone phonetic:유사하게 들리는 단어나 이름에 대해 영어 단어 소리의 대략적인 근사치를 반환하고 조회키로 사용 가능
Ispell: Damerau-Levenshtein 거리 1에 기반 보정만을 제안 -
JamSpell: SymSpell 알고리즘의 변형과 3-gram 언어 모델을 사용해 word-level correction 교정
SymSpell:Damerau-Levenshtein 거리에 대한 편집후보 생성과 dictionary 조회의 복잡성 줄임
-
SC-LSTM: Bi-LSTM 네트워크를 통해 semi-character를 사용하여 철자오류 수정. Semi-character 표현은 첫 번째, 마지막 및 bag of internal character에 대한 one-hot embedding의 concatenation
-
CHAR-LSTM-LSTM: 개별 문자를 bi-LSTM으로 전달해서 word representation 구축. 이러한 representation은 correction을 예측하도록 또 다른 bi-LSTM에 추가로 공급
-
CHAR-CNN-LSTM: 이전 모델과 유사하게, convolutional network를 사용해 개별 문자로부터 word-level representation 구축
-
BERT: 사전학습된 transformer network사용. Word representation을 얻기 위해 sub-word representation을 평균화하고 correction 예측 위해 classifier에 추가로 공급
-
잘못된 철자 토큰 주위의 컨텍스트를 잘 파악하기 위해 사전학습된 ELMO, BERT의 심층 컨텍스트를 representation으로 SC-LSTM모델 확장
-
이러한 embedding을 통합하는 best point는 작업에 따라 다를 수 있어, biLSTM 또는 biLSTM의 출력에 공급하기 전에 semi-character embedding에 추가
-
툴킷에선 4가지 모델 제공: ELMO/BERT는 input/output에서 semi-character 기반 bi-LSTM 모델과 연결
3. Implementation Details
- NeuSpell의 신경모델은 맞춤법 교정을 시퀀스 레이블링 작업으로 지정하여 학습. 철자가 틀린 토큰은 교정된거로 레이블링
- out-of-vocabulary 레이블은 UNK
- 입력 텍스트 시퀀스의 각 단어에 대해 모델은 softmax layer를 사용해서 한정된 vocabulary에 대한 확률 분포를 출력하도록 학습
- 추론하는 동안 먼저 UNK 예측을 해당 입력 단어로 바꾼 다음 결과를 평가
4. Synthetic Training Datasets
맞춤법 교정 데이터 부족해서 misspelt-correct 문장 생성 위해 문장 노이즈 처리
말뭉치에서 토큰의 ~20%를 노이즈로 함
-노이즈 전력
- Random: 4가지 character-level 작업, 순서 바꾸기(permute), 삭제, 삽입 및 교체. 단어의 내부 문자만 조작. 순서 바꾸기 작업은 연속된 문자 쌍을 섞고, 삭제 작업은 문자 중 하나를 임의로 삭제, 삽입은 문자를 임의로 삽입, 교체는 문자를 랜덤하게 선택한 알파벳으로 바꿈. 원래 말뭉치의 모든 단어에 대해, 각각 0.1확률로 네 가지 연산 중 하나 수행. 길이가 3이하인 단어는 수정❌
- Word: 사전 구축된 조회 테이블에서 노이즈가 있는 단어로 교환. 다양한 공공 출처에서 17K의 흔한 단어에 대한 109K의 잘못된 철자 수정 단어 쌍을 수집. 원래 말뭉치의 모든 단어에 대해 조회 테이블의 해당 단어와 관련된 모든 철자 오류에서 랜덤한 철자 오류(확률 0.3)로 대체. 룩업 테이블에 없는 단어는 그대로 유지
- PROB: 철자오류 단어쌍의 말뭉치(https://aclanthology.org/N19-1326/)로 key가 <character, context>쌍이고 값이 해당 빈도로 대체될 수 있는 문자의 목록인 character-level confusion 사전을 구성. 이 사전은 주어진 context에서 character-level 오류를 샘플링하는데 사용.
- PROB+Word: Word전력과 Prob전력에서 얻은 학습 데이터 concatenate
5. Evaluation Benchmarks
- Natural misspellings in context: 많은 맞춤법 검사기는 개별 맞춤법 오류를 평가. 반면 우리는 문법오류 수정 작업을 위해 공개적으로 사용가능한 데이터셋(GEC: Grammatical Error Correction)사용해 맥락에서 맞춤법 오류를 사용해 시스템을 평가
- BEA-2019 task의 GEC 데이터셋은 능숙한 수준의 언어 학습자가 작성한 영어 텍스트(주로 에세이) 모음
- FCE(The First Certificate in English) 데이터셋은 언어 평가 시험을 치르는 비원어민 학습자가 영어로 작성한 에세이 모음
- Lang-8 데이터셋은 Lang-8 온라인 언어 학습 웹사이트의 영어 텍스트 모음
- 위의 데이터를 결합해 63044개의 문장에서 70,000개의 철자오류(6.8%)가 있는 BEA-60K 테스트셋 만듬
- JFLEG(JHU Fluency-Extended GUG Corpus) 데이터셋은 모국어가 다른 영어 학습자가 작성한 에세이 모음 => BEA-60K 및 JFLEG 데이터셋을 평가목적으로만 사용, 학습❌
- Ambiguous misspellings in context: natural test set과 synthetic test set외에 모호한 철자 오류 수정 위해 추가 컨텍스트가 필요한 challenge set만듬. 예를 들어 단어 whitch는 문맥에 따라 witch 또는 which로 수정될 수 있음. 우리는 2개 또는 그 이상의 사전 단어에서 1-edit 거리가 떨어져 있거나 2개 또는 그 이상의 사전 단어와 동일한 음성 인코딩을 갖는 철자 오류를 모두 선택
- 또한 인위적으로 틀리게 만든 더 큰 테스트셋도 만듬
6. Result and Discussion
-
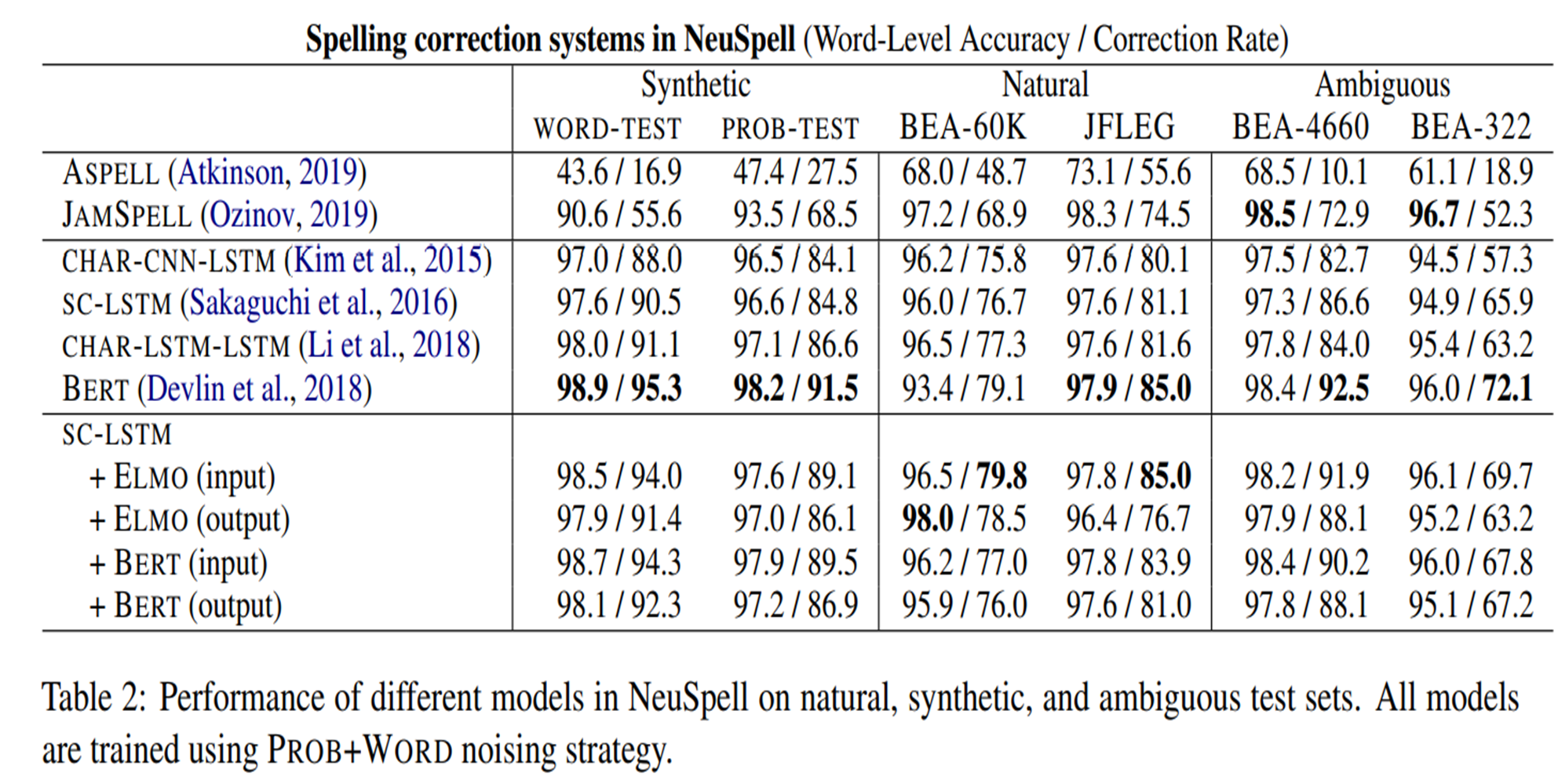
Spelling Correction: 6개의 데이터셋에서 NeuSpell에서 10개의 철자 수정 시스템 평가
-
뉴럴 모델은 PROB+WORD 합성데이터를 학습데이터로 사용
-Aspell, Jamspell은 합성 데이터셋에서 fine-tune❌ -
Deep contextual representation으로 구성된 모델(ELMO, BERT의 deep contextual representation으로 SC-LSTM 확장)이 다른 기존 뉴럴모델보다 철자 수정 작업을 잘함
-
BERT 모델은 모든 벤치마크에서 일관되게 우수한 성능
-
BEA-332 test set의 경우, Grammarly로 수정사항을 수동으로 평가
-
BERT가 Grammarly보다 우수한 성능(72.1% vs 71.4%)
-
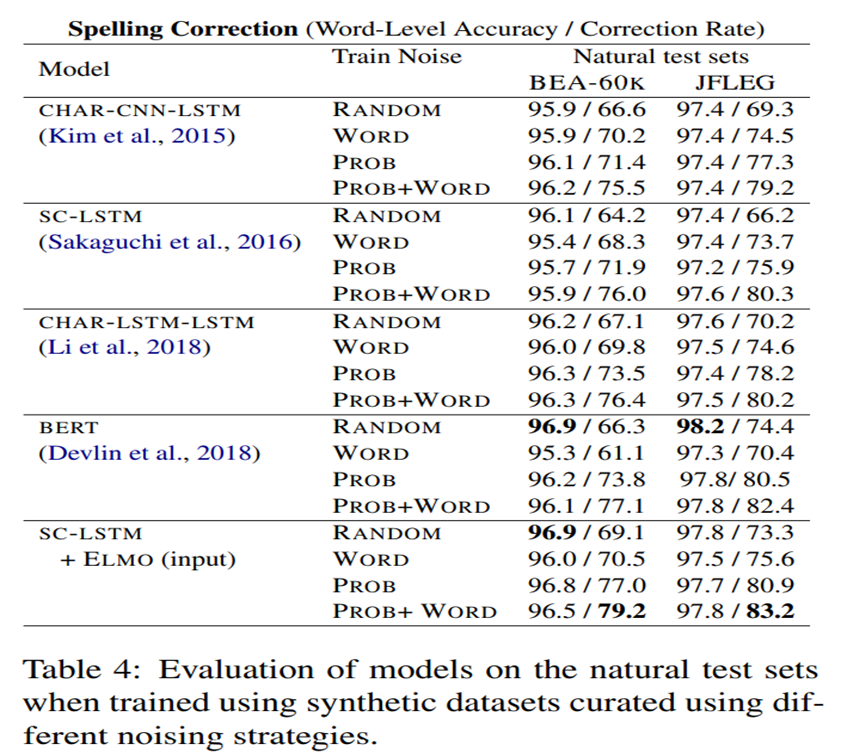
PROB 노이즈로 훈련된 모델이 WORD 또는 RANDOM 노이즈로 훈련된 모델보다 성능이 우수
-
모든 모델에서 PROB+WORD 전략을 사용하면 랜덤 노이즈에 비해 수정률이 최소 10%향상
7. Defense against Adversarial Mispellings

- SST의 영화 리뷰 데이터에 대해 SC-LSTM+ELMO(input) 모델을 finetune
- 표와 같이, NeuSpell toolkit(SCLSTM+ELMO(input)(F))는 대부분의 경우 Pruthi가 제안한 모델을 능가
8. Conclusion
- 10개의 다른 모델로 구성된 맞춤법 검사 NeuSpell 설명
- 우리 모델은 철자가 틀린 단어 주변의 맥락을 정화하게 알아챔
📢Self-Supervised Korean Spelling Correction via Denoising Transformer
1. Abstract
- 대부분의 철자 교정 모델은 철자가 틀린 시퀀스를 입력으로, ground truth를 출력으로 포함하는 병렬 말뭉치가 필요
- 한계 극복 위해 semi-supervised 한글 맞춤법 교정 작업을 위한 두가지 노이즈 생성 방법과 트랜스포머 기반 노이즈 제거 아키텍처 제안
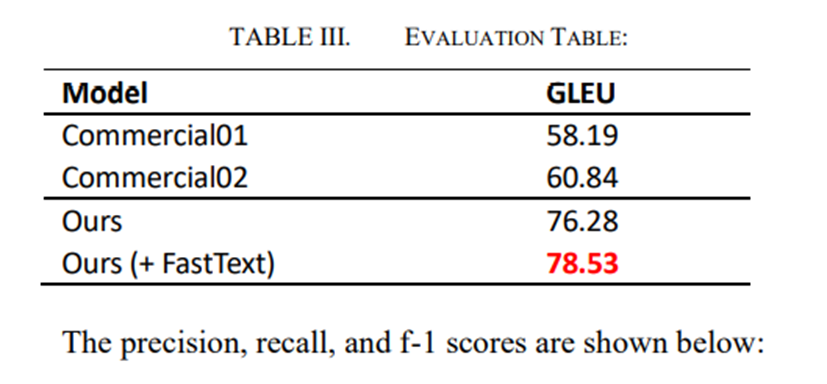
- 우리 모델은 GLUE에서 78.53, 이는 현재(2020년) 한국어 맞춤법 수정을 위한 두가지 대표적인 시스템 능가
2. Instroduction
- 현재 한국에선 부산대와 네이버가 성공적인 맞추법 교정 시스템 운영
- 이러한 서비스는 대규모 규칙 기반 시스템으로 구성
- 장점은 입력 문장의 구조를 바꾸지 않고 잘못된 부분을 고침
- 하지만 규칙에서 벗어난 구간은 수정❌, 대용량 규칙 구성 어렵다는 단점
- 본 논문에선 기계 번역 관점에서 맞춤법 교정 시스템 살핌
- 기계 번역은 소스 언어를 대상 언어로 번역하는 시스템
- 맞춤법 교정 시스템에 적용하면 소스는 철자 오류있는 문장, 대상 언어는 올바른 문장
- 본 논문에선 단일 언어 말뭉치를 활용하여 한국어 철자 병렬 말뭉치를 구축하고 기존 철자 수정 시스템보다 우수한 78.53점의 최고 GLUE점수를 얻은 Transformer 기반의 한국어 철자 수정 시스템 만듬
- 병렬 말뭉치를 사용하지 않고 철자 수정 작업을 수행하기 위한 semi supervised 접근법 제시
- 대신 RCR(Random Character Replacement)과 사전 정의된 ELN(Error List Driven Noising)이 입력 시퀀스에 통합
- 새로운 번역 모델인 트랜스포머를 한글 맞춤법 수정 작업에 적용
- 잘못된 철자의 토큰은 트랜스포머의 셀프 어텐션 레이어에서 더 많이 attend
- 우리 모델은 GLUE의 경우 78.53(17.69🔺), F1 71.13(18.70🔺)으로 맞춤법 교정 작업에서 SOTA
3. Related Work
- 과거에는 규칙기반, 통계기반, 머신러닝 최근에는 딥러닝 기반 맞춤법 교정 시스템에 대한 다양한 연구가 진행
- 머신러닝을 사용할 때 단점은 감지된 단어의 주변 컨텍스트가 정확하다는 잠재적으로 잘못된 가정이 있음
- 맞춤법 교정 시스템을 기계 번역의 관점에서 볼 때, 고품질의 병렬 코퍼스가 잘 구축되야만 규칙을 구성하지 않고 오류의 다양한 측면을 수정하는데 유리
4. Model Description
생성 딥러닝 모델인 트랜스포머를 한국어 맞춤법 교정 과제에 최초로 적용
A. Error Lists
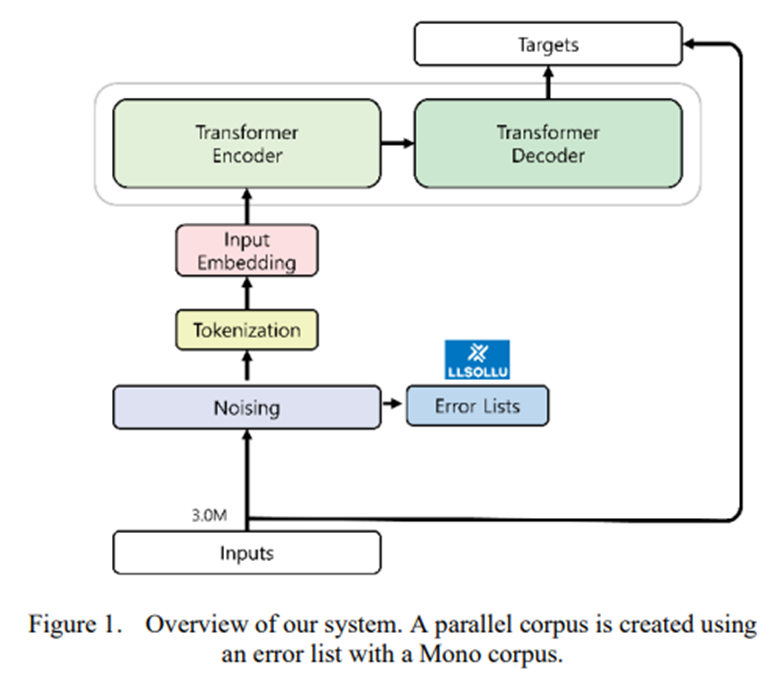
- 오류 목록은 'Hollo'와 'Hello'와 같은 잘못된 단어와 해당 단어의 올바른 대응 단어의 쌍
- 오류 목록의 경우 기존 실시간 통역 서비스를 사용해 자동으로 획득
- 오류 목록은 LLSoLu(https://www.llsollu.com/)가 상용화한 서비스인 ezTalky라는 통역비서 모바일 앱 시스템에서 가져옴
- 45,711 오류 목록 구축
B. Denoising Transformer
- "Attention is All You Need"에서 Transformer 모델 기반
- Transformer는 convolution과 recurrence 사용❌, Attention 기법만을 사용하는 sequence-to-sequence 모델
- FastText를 통해 사전 학습된 Embedding vector를 구성하고 학습에 사용
- FastText 모델에선 등록되지 않은 단어를 n-gram 형태로 보기 때문에 FastText가 오류에 강건한 n-gram을 사용해 유사한 단어를 추정할 수 있음
5. Experiments
- 본 논문에서 제안한 오류 목록을 이용해 병렬 말뭉치를 구성하고 트랜스포머에 적용하여 기존 한글 맞춤법 교정 시스템과 결과 비교
- 기존 시스템 능가, SOTA 성능
- 기계 번역 관점에서 접근했기 때문에 GLUE 점수를 지표로 사용
A. Dataset

- 신문기사 크롤링
- 다음 숫자들은 병렬 코퍼스 필터링 결과
B. Experimental Setting
- 4개 Gpu 80,000 steps 학습
C. Metrics

- GLUE는 BLUE와 비스사지만 소스 정보를 고려하는 반면 BLUE는 그렇지 않음
- 문법 오류 시스템에 특화된 수행 평가 지수
D. Delete symbol in source sentence
- 입력 데이터를 가져올 때, 원본 문장에서 모든 기호 삭제
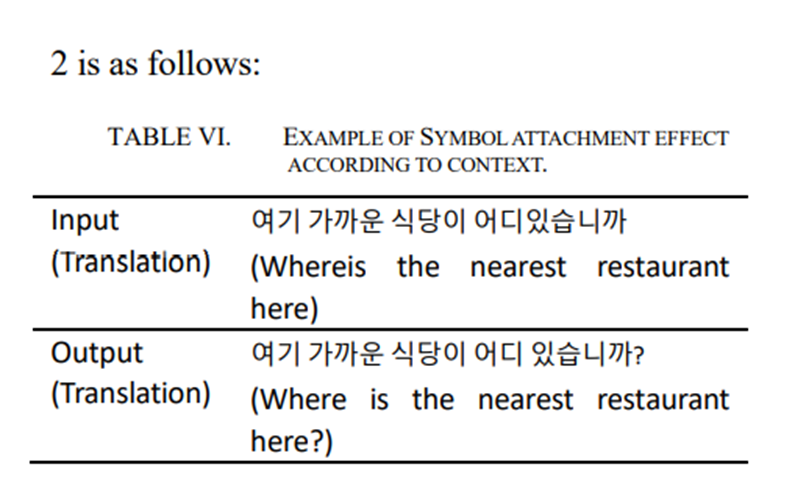
- 데이터 변형을 통해 문맥에 따라 문장에 기호 "?" 또는 ","를 넣는 효과를 볼 수 있음
6. Experimental results
- 실험은 학습 데이터에서 테스트셋 추출한 다음 테스트셋에서 알파벳 단위를 무작위로 교체하거나 삭제하는 방식 수행
- 노이즈 생성 이유는 데이터를 수정하지 않고 테스트셋을 추출하면 모델의 성능을 제대로 입증❌
- 그런 다음 성능을 현재 한국에서 상용화된 맞춤법 교정 시스템과 비교

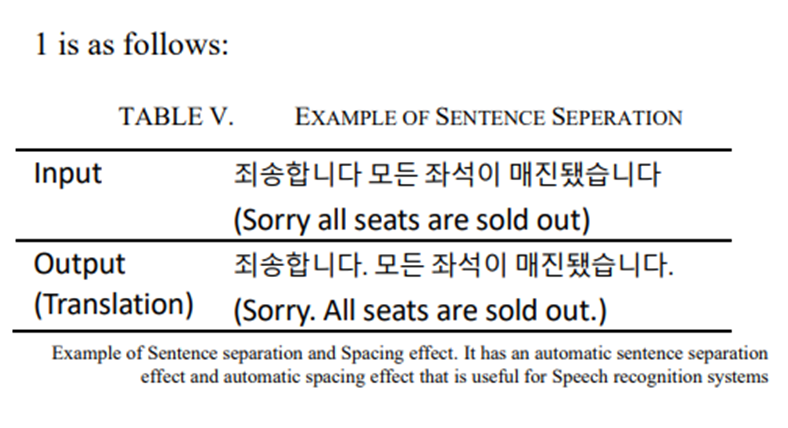
- 이 시스템엔 두 가지 추가 효과가 있음
- 문장 구분 및 띄어쓰기
- 문맥 기반 기호 삽입
- 1과 2는 결합되어 음성 인식을 위한 후처리 모듈로 사용 될 수 있음
- STT 결과는 일반적으로 기호를 포함하지 않으면 간격이 부정확할 수 있음
- 또한 STT처리 결과가 부자연스럽거나 입력 문장의 흐름과 맞지 않는다고 느끼는 문장을 생성하는 경우도 있음
- 이 경우, 제안된 맞춤법 교정 시스템을 이용해 문제점 해결
7. Conclusion
- 본 논문은 트랜스포머 모델을 한글 맞춤법 수정 시스템에 적용하려는 첫 시도
- 기존 상용화 시스템 성능 뛰어넘음
- 또한 나중에 오류 목록을 강화하는 방법 연구할 예정
📢Spelling Error Correction with soft-masked BERT
1. Abstract
- 맞춤법 수정은 인간 수준의 언어 이해 능력을 필요하기 떄문에 어려운 작업
- 언어 표현 모델 BERT를 기반으로 문장의 각 위치에서 수정 후보 목록(non-correction 포함)에서 문자를 선택
- 하지만 BERT는 마스크 언어 모델링을 사용하여 사전 학습하는 방식으로 인해 각 위치에 오류가 있는지 여부를 감지할 수 있는 충분한 기능이 없기 때문에 정확도는 차선일 수 있음
- 앞서 언급한 문제 해결 위해 새로운 뉴럴 아키텍처를 제안하는데, 이는 BERT 기반의 오류 감지 네트워크와 수정 네트워크로 구성되며, 전자는 soft-masking 기술이라고 하는 후자와 연결
- 'Soft-Masked BERT'를 사용하는 우리의 방법은 일반적이며, 다른 언어에도 사용될 수 있음
- 두 데이터셋에 대한 실혐 결과는 우리가 제안한 방법의 성능이 BERT만 기반한 것보다 우수
2. Introduction

- 본 논문에선 character-level 중국어 철자교정 고려
- Table 1엔 최소 두가지 challenges가 있음
1) 철자 오류 수정을 위해선 세계 지식이 필요
- 첫 문장의 字는 子로 잘못 쓰였는데, 여기서 金子塔는 황금탑 의미, 金字塔는 피라미드 의미
2) 추론 필요
- 두 번째 문장에서 4번째 글자인 生를 胜로 잘못 적음
- 실제 주변 단어들은 의도된 단어인 求胜欲(살아남으려는 욕구)가 아닌 새로운 유효어인 求生欲(이기려는 욕구)를 형성
- 최근에는 언어 표현 모델인 BERT가 CSC를 포함한 많은 언어 이해 작업에 성공적으로 적용
- character-level BERT는 먼저 레이블이 지정되지 않은 대규모 데이터셋을 사용하여 사전 학습된 다음 레이블이 지정된 데이터셋을 사용하여 미세 조정됨
- 레이블이 지정된 데이터는 대규모 confusion tabel을 사용하여 맞춤법 오류의 예를 생성하는 data augmentation을 통해 얻을 수 있음
- 마지막으로 모델은 주어진 문장의 각 위치에 있는 후보 목록에서 가장 가능성이 높은 문자를 예측하는데 사용
- BERT는 특정 15%만 마스킹 방법으로 학습해서 주변 단어는 수정X=> 맞춤법 수정과 같은 작업에선 적용하기 어려움
✔
- 문제 해결위해 본 연구에서 SoftMasked BERT라고 하는 새로운 뉴럴 아키텍처 제안
- Soft-Masked BERT는 BERT를 기반으로 하는 탐지 네트워크와 수정 네트워크 두 개 포함
- 수정 네트워크는 BERT만을 사용하는 방법과 유사
- 탐지 네트워크는 각 위치에서 문자가 오류일 확률을 예측하는 Bi-GRU 네트워크
- 그런 다음 확률을 활용하여 해당 위치에서 문자 임베딩의 soft-masking 수행
- 소프트 마스킹은 오류 확률이 1일 때 전자가 후자로 degenerate한다는 점에서 하드 마스킹 확장
- 그런 다음 각 위치의 소프트 마스크 임베딩이 수정 네트워크에 입력
- 수정 네트워크는 BERT를 사용하여 오류 보정 수행
- 이 접근 방식은 end-to-end간 공동 학습 중에 모델이 탐지 네트워크의 도움을 받아 오류 수정을 위한 올바른 컨텍스트를 학습하도록 할 수 있음
✔
- SoftMasked BERT와 BERT를 단독으로 사용하는 방법 포함 여러 baseline 비교 실험
-SIGHAn benchmark dataset 이용 - 또한 News Title이라는 평가용 대규모 고품질 데이터셋 만듬
- 뉴스 기사 제목을 포함하는 데이터셋은 이전 데이터셋보다 10배 더 큼
- 실험 결과는 Soft-Masked BERT가 정확도 측면에서 두 데이터셋의 baseline을 크게 능가
- (1) CSC 문제에 대한 새로운 신경 아키텍처 Soft-Masked BERT제안
- (2) Soft-Masked BERT의 효율성에 대한 실증적 검증이 포함
3. Our Appraoch
3.1 Problem and Motivation
- 중국어 철자 오류 수정(CSC)는 다음과 같은 작업으로 형식화 될 수 있음
- n개의 문자(또는 단어) 시퀀스가 주어지면, 목표는 그것을 같은 길이의 다른 문자 의 시퀀스로 변환 하는 것. 여기서 X의 잘못된 문자는 올바른 문자로 대체되어 Y얻음
- task는 모델이 매핑 함수 인 순차 레이블링 문제로 볼 수 있음
- 그러나 일반적으로 교체할 필요가 없거나 몇 개의 문자만 있고 문자의 전부 또는 대부분을 복사해야 한다는 점에서 작업이 더 쉬움
✔
- 일반적으로 BERT 기반 방법은 수정을 하지 않는 경향이 있음(또는 원본 문자를 복사하기만 함)
- 우리의 해석은 BERT 사전학습에서 15%의 문자만 마스킹되어 오류 감지를 위해 충분하게 학습❌
3.2 Model

- Figure 1과 같이 CSC용 Soft-Masked BERT라는 새로운 신경망 모델 제안
- Soft-Masked BERT는 Bi-GRU 기반의 탐지 네트워크와 BERT 기반의 수정 네트워크로 구성
- 탐지 네트워크는 오류의 확률을 예측하고 수정 네트워크는 오류 수정 확률을 예측하는 반면, 전자는 소프트 마스킹을 사용하여 예측 결과를 후자에 전달
- 좀 더 구체적으로, 먼저 입력 문장의 각 문자에 대한 임베딩을 입력 임베딩이라고 함
- 다음으로 임베딩 시퀀스를 입력으로 하고 탐지 네트워크를 사용해 문자 시퀀스(임베딩)에 대한 오류 확률을 출력
- 그런 다음 오류 확률에 의해 가중치가 부여된 입력 임베딩과 [MASK] 임베딩의 가중 합을 계산
- 계산된 임베딩은 시퀀스의 가능한 오류를 soft 방식으로 마스킹
- 그런 다음, 방법은 soft-masked 임베딩의 시퀀스를 입력으로 하고 최종 레이어가 모든 문자에 대한 softmax 함수로 구성된 BERT 모델인 수정 네트워크를 사용하여 오류 수정 확률 출력
- 또한 입력 임베딩과 최종 레이어의 임베딩 사이에는 residual connection이 있음
3.3 Detection Network
- 탐지 네트워크는 sequential binary labeling model
- 입력은 임베딩 시퀀스 이며 여기서 는 문자 의 임베딩을 나타내며, 이는 BERT에서와 같은 word embedding, position embedding, segment embedding
- 출력은일련의 레이블 이다. 여기서 는 문자의 레이블을 나타내며, 1은 문자가 잘못 되었음 0은 올바른 것을 나타냄
- 각 문자에 대해 1이 될 가능성을 나타내는 가 있음
- 가 높을수록 문자가 부정확할 가능성이 높음
- 본 연구에선 탐지 네트워크를 양방향 GRU(Bi-GRU)로 실현
- 시퀀스의 각 문자에 대해 오류 의 확률은 다음과 같음
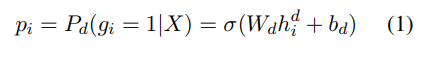
- 여기서 는 탐지 네트워크에 의해 주어진 조건부 확률, σ는 시그모이드 함수, 는 Bi-GRU의 hidden state, 와 는 파라미터
✔
- 또한 hidden state는 다음과 같음

- 여기서 는 두 방향에서 GRU hidden state의 연결, GRU는 GRU함수
- 소프트 마스킹은 오류 확률을 가중치로 하는 입력 임베딩과 마스크 임베딩의 가중 합
✔
- i번째 문자에 대한 소프트 마스크 임베딩 는 다음과 같음
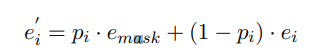
- 여기서 는 입력 임베딩, 는 마스크 임베딩
- 오류 확률이 높으면 소프트 마스크 임베딩 는 마스크 임베딩 에 가깝고, 그렇지 않으면 입력 임베딩 에 가까움
3.4 Correction Network
- 수정 네트워크는 BERT를 기반으로 하는 sequential multi-class labeling model
- 입력은 소프트 마스킹된 임베딩 시퀀스 이며 출력은 일련의 문자
- BERT는 전체 시퀀스를 입력으로 하는 12개의 동일한 블록의 스택으로 구성
- 각 블록은 다음과 같이 정의된 feed-forward network에 이어 multi-head self-attention작업 포함
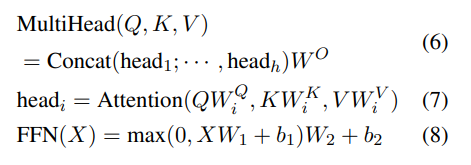
- 여기서 Q, K, V는 이전 블록의 입력 시퀀스 또는 출력을 나타내는 동일한 행렬, HultiHead, Attention, FNN은 각각 multi-head self-attention, self-attention, feedforward 네트워크를 나타내며 는 파라미터
✔
- BERT의 마지막 층에서 hidden state의 시퀀스를 로 나타냄
- 시퀀스의 각 문자에 대해 오류 수정 확률은 다음과 같음

- 여기서 는 후보 목록에서 문자 가 문자 로 수정되는 조건부 확률이고, softmax는 소프트맥스 함수, 는 hidden state, W와 b는 파라미터
- 여기서 hidden state 는 residual connection의 linear combination에 의헤 얻어짐
✔
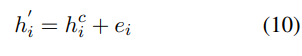
- 여기서 는 최종 계층의 hidden state이고 는 문자 의 입력 임베딩
- 수정 네트워크의 마지막 계층은 소프트맥스 기능 이용
- 확률이 가장 큰 문자는 목록에서 문자 의 출력으로 선택
3.5 Learning
- Soft-Masked BERT의 학습은 BERT가 사전학습되고 원래 시퀀스와 수정된 시퀀스의 쌍으로 구성된 학습 데이터가 제공될 경우에 end-to-end로 수행
- 학습 데이터를 만드는 한 방법은 인 confusion table을 사용하여 오류 없이 시퀀스 가 주어 졌을 때 오류가 포함된 시퀀스 를 반복적으로 생성
- 학습 과정은 각각 오류 탐지 및 오류 수정에 해장하는 목표를 최적화함으로써 구동
✔
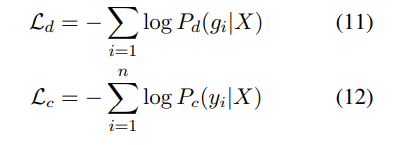
- 여기서 는 탐지 네트워크 학습의 목표, 는 수정 네트워크 학습의 목표(및 최종 결정)
- 두 함수는 학습의 전반적인 목적으로 선형 결합

- 여기서 λ ∈ [0, 1]는 계수
4. Experimental Results
4.1 Datasets
- CSC의 벤치마크인 SIHAN 데이터셋 사용
- SIHAN은 1,1000개의 텍스트와 461가지 유형의 오류(문자)를 포함하는 작은 데이터셋
- 본문은 Foreign Language로서의 중국어 시험의 에세이 부분
- 또한 테스트 및 개발을 위해 뉴스 제목이라고 하는 더 큰 데이터셋도 만듬
- 정치, 연예, 스포츠, 교육 등 다양한 콘텐츠를 가진 중국 뉴스 앱 'Toutiao'에서 뉴스 기사 제목 샘플링
- 데이터셋에 충분한 수의 잘못된 문장이 포함되도록 하기위해, 낮은 품지르이 텍스트에서 샘플링을 수행했고, 따라서 데이터셋의 오류율이 보통보다 높음
- 데이터셋은 15,730 텍스트 포함
- 오류가 포함된 텍스트는 5,423개로 3,441개 유형
- 데이터를 테스트셋과 검증셋으로 나누어 각각 7,865개의 텍스트 포함
✔
- 처음에 중국 뉴스 앱에서 약 500만개의 뉴스 제목 검색
- 또한 각 문자가 잠재적 오류로서 다수의 동음이의어(homophonous) 문자와 연관된 confusion table 만듬
- 다음으로 텍스트의 문자 중 15%를 다른 문자로 임의로 대체하여 인위적으로 오류 생성. 여기서 80%는 테이블의 동음 문자 20%는 랜덤 문자
- 실제로 중국어 철자 오류의 양 80%가 사람들의 Pinyin(병음) 기반 입력 방법 사용으로 인한 등음이의어이기 때문
4.2 Baselines
비교 위해 다음과 같은 방법을 baseline으로 채택
- NTOU는 n-gram 모델과 rule-based classifier를 사용
- NCU-NTUT는 단어 벡터와 조건부 랜덤 필드를 활용
- HanSpeller++는 hidden Markov model을 사용하여 후보를 생성하고 다시 순위를 매기는 필터를 사용하는 통합 프레임워크
- Hybrid는 생성된 데이터셋에 대해 학습된 BiLSTM 기반 모델 사용
- Confusionset은 pointer network와 copy mechanism으로 구성된 Seq2Seq 모델
- FASPell은 노이즈 제거 자동 인코더 및 디코더로 BERT를 사용하는 CSC에 Seq2Seq 모델
- BERT-Pretrain은 사전 학습된 BERT를 사용
- BERT-Finetune은 fine-tuned BERT 사용
4.3 Experiment Setting
- 평가 수단으론 문장 수준의 accuracy, precision, recall, F1
- 우린 탐지와 수정 모두에서 accuracy 평가
- 전자는 후자에 의지하기 때문에 탐지보다 수정이 더 어려움
- BERT의 fine-tuning은 기본 hyperparameter는 유지하고 Adam을 사용해 파라미터만 fine-tune
- 학습 트릭의 영향을 줄이기 위해 동적 학습률 전략X, 미세 조정에서 학습률 2e-5 유지
-Bi-GRU에서 hidden unit의 크기는 256, 모든 모델의 batch size는 320
4.4 Main Results

- 표2는 두 테스트 데이터셋에 대한 모든 방법의 실험 결과
- 표에서 제안된 모델 SoftMasked BERT가 두 데이터셋 모두에서 기본 방법을 크게 능가
- 특히 뉴스 제목에서 soft-masked BERT는 모든 측면에서 baseline보다 성능이 뛰어남
- News Title 데이터셋의 correction level recall의 best 결과는 54% 이상, 즉 54% 이상의 오류가 발견 correction level precision가 55%이상
- HanSpeller++는 SIHAN에서 가장 높은 precision 달성, 이는 수동으로 조작된 많은 규칙과 기능으로 잘못된 탐지를 제거할 수 있기 때문인 것으로 보임
- 규칙과 기능 사용이 효과적이지만 개발 비용이 높고 일반화 및 적응에 어려움
- 어떤 의미에선 Soft-Masked BERT를 포함한 다른 학습 기법과 직접 비교할 수 없음
- Confusionset을 제외한 모든 메서드의 결과가 문자 수준이 아니라 문장 수준에 있음(문자 수준의 결과가 더 잘 보일 수 있음)
- 그럼에도 불구하고 Soft-Mask BERT는 여전히 더 나은 성능
- BERT를 사용하는 세 가지 방법인 Soft-Mask BERT, BERT-Fintune, FASPell은 다른 baseline보다 성능이 우수하지만 BERT-Pretrain은 성능이 떨어짐
- Soft-Mask BERT는 두 데이터셋 모두 BERT-Finetune을 크게 능가
- 결과는 오류 탐지가 CSC에서 BERT의 활용하는데 중요하며 소프트 마스킹은 실제로 효과적인 수단임을 시사
4.5 Effect of Hyper Parameter
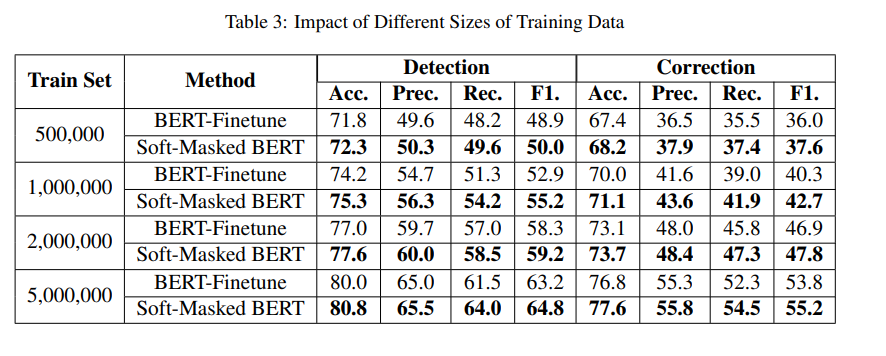
- parameter와 데이터 크기의 영향을 설명하기 위해(테스트 데이터) 뉴스 제목에 대한 소프트 마스크 BERT 결과 제시
- 표3은 다양한 크기의 학습 데이터로 학습된 BERT-Finetune뿐만 아니라 소프트 마스크 BERT의 결과를 보여줌
- 크기가 500만인 경우 Soft-Masked BERT에 대한 최상의 결과, 이는 학습 데이터를 더 많이 활용할 수록 더 높은 성능 달성
- Soft-Masked BERT가 BERT-Finetune보다 일관되게 우수
- λ값이 클수록 오류 수정에 대한 가중치가 높음을 의미
- 오류 감지는 본질적으로 전자가 이진 분류 문제인 반면 후자는 다중 클래스 분류 문제이기 때문에 오류 수정보다 쉬운 작업
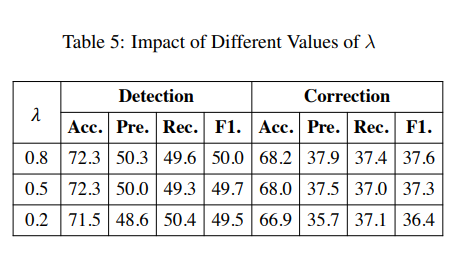
- 표5는 다양한 hyper parameter λ값에서 Soft-Masked BERT의 결과를 보여줌
- 가장 높은 F1은 λ가 0.8일 때
- 이는 탐지와 수정 사이에 적절한 타협점에 도달
4.6 Ablation Study
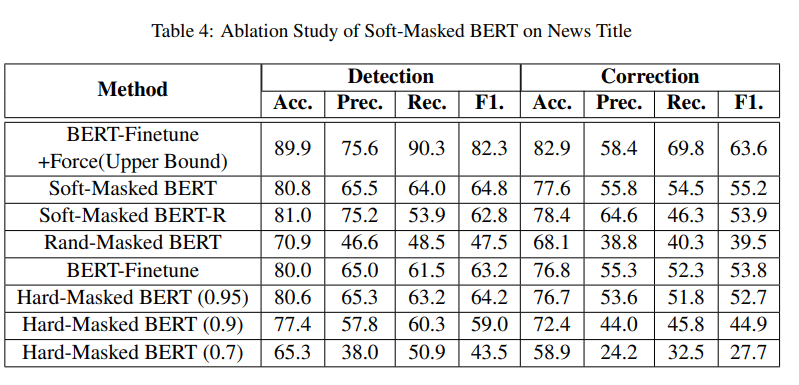
- 표4는 뉴스 제목에 대한 결과(SIGHAN에 대한 결과는 지면의 제약으로 생략했지만 유사한 경향을 보였음)
- Soft-Masked BERT-R에선 모델의 residual connection이 제거
- Hard-Masked BERT에서 탐지 네트워크에 의해 주어진 오류 확률이 임계값(0.95, 0.9, 0.7)을 초과하면 현재 문자의 임베딩이 [MASK] 토큰의 임베딩으로 설정되며, 그렇지 않으면 임베딩은 변경❌
- Rand-Masked BERT에선 오차 확률은 0과 1사이의 값으로 랜덤화
- 고성능을 달성하기 위해 Soft-Masked BERT의 모든 주요 구성 요소가 필요함
- 성능을 상한으로 볼 수 있는 BERT-Finetune+Force도 시도
- 이 방법에선 BERT-Finetune이 오류가 있는 위치에서만 예측하고 나머지 후보 목록에서 문자를 선택하도록
- 결과는 Soft-Masked BERT가 개선될 여지가 여전히 크다는 것을 보여줌
4.7 Discussions
- Soft-Mask BERT가 BERT-Finetune보다 global context 정보를 더 효과적으로 사용
- 소프트 마스킹을 사용하면 가능한 오류가 식별되며, 결과적으로 모델은 BERT의 성능을 더 잘 활용하여 로컬 컨텍스트뿐만 아니라 글로벌 컨텍스트를 참조하여 오류 수정에 대한 합리적인 추론 가능
- Soft-Masked BERT를 포함한 거의 모든 방법에서 성능에 영향을 미치는 두 가지 주요 유형의 오류가 있다는 것을 발견
- 오류 통계의 경우 테스트셋에서 100개의 오류를 샘플링
- 67%의 오류가 강력한 추론 능력 필요,11%는 세계지식 부족, 나머지 22%의 오류는 유형없음
- 첫 번째 유형의 오류는 추론 능력의 부족
- 오타를 정확하게 수정하려면 더 강력한 추론 능력 필요
- 두 번째 유형의 오류는 세계 지식의 부족
- 일반적인 AI 시스템의 기존 모델이 이러하 종류의 오류를 감지하고 수정하는 것은 여전히 매우 어려움
5. Conclusion
- 본 논문에서, 철자 오류 수정, 더 구체적으론 중국어 철자 오류 수정(CSC)을 위한 새로운 신경망 아키텍처 제안
- Soft-Masked BERT라는 모델은 BERT를 기반으로 한 탐지 네트워크와 수정 네트워크로 구성
- 탐지 네트워크는 주어진 문장에서 잘못된 문자를 식별하고 문자를 soft-mask함
- 수정 네트워크는 soft-masked 문자를 입력으로 사용하여 문자를 수정
- 소프트 마스킹 기술은 일반적이고 다른 탐지-수정 작업에서 잠재적으로 유용
