Abstract
- 우리는 최적의 앙상블을 학습하고 검색하는 반복적인 데이터 증강 프레임워크를 제시하고, 동시에 self-training 스타일로 새로운 학습 데이터에 주석을 달았음
- 이 프레임워크를 두 개의 SIGMORPON 2020 shared task에 족용: G2P변환과 morphological inflection
- 우리 시스템이 특히 저자원 언어에서 잘 작동함
1. Introduction
- 세계 대부분의 언어는 자연어 처리 모델을 학습하는 데 사용할 수 있는 주석이 달린 데이터셋이 거의 없음
- 저자원 언어를 다루는 것은 NLP 많은 관심
- 주석을 얻기 어려울 때, 데이터 증강은 강력한 모델에 합리적인 품질로 학습 데이터 크기를 늘리는 일반적인 관행
- 예를 들어 Anastasopoulos and Neubig의 data hallucination 방법은 morphological inflection data를 증강시키기 위해 존재하지 않는 "단어"를 자동으로 생성해 생성 모델의 레이블 편향 문제 완화
- 그러나 이러한 방법으로 생성된 데이터는 모델을 정규화하는데 도움이 될 뿐, 유효한 언어 단어로 볼 수 없음
- 아키텍처를 변경하지 않고 모델 성능을 향상시키기 위해 일반적으로 사용되는 또 다른 방법은 데이터 증강 방법과 직교하는 앙상블. 즉, 동일한 종류의 여러 모델을 학습시키고 다수결에 의해 출력을 선택
- 앙상블 성공의 키는 기본 모델의 다양성으로 나타남. 서로 다른 귀납적 편향을 가진 모델이 동일한 실수를 저지를 가능성이 낮아서
- 본 연구에서 최적의 앙상블을 검색하고 레이블이 지정되지 않은 데이터에 주석을 추가하는 프레임워크를 개발
- 제안하는 방법은 여러 다른종류들로 이루어진 모델의 앙상블을 사용해서 앙상블의 동의를 기반으로 레이블이 지정되지 않은 데이터를 선택하고 주석을 달고 주석이 달린 데이터를 사용해 새 앙상블의 잠재적 멤버인 새 모델을 학습하는 반복 프로세스
- 앙상블은 검증셋의 정확도를 최대화하는 모든 학습된 모델의 하위 집합이며, 유전 알고리즘을 사용해 모델 조합 찾음
- 이 접근법은 self-training의 한 유형으로 볼 수 있지만, 한 모델의 신뢰도를 사용하는 대신 많은 모델의 합의를 사용해 새로운 데이터에 주석 달음
- 주요 차이점은 앙상블의 모델 다양성이 일반적인 self-training 접근법의 confirmation bias를 완화
- 공유 작업에서 중간 또는 대규모 학습 데이터가 있는 언어에서 데이터 증강 방법이 결과 크게 향상❌
- 리소스가 적은 언어에는 데이터 증강의 이점이 두드러짐
GA(Genetic Algorithm)
출처: https://techblog-history-younghunjo1.tistory.com/92
GA: 생물체가 환경에 적응하면서 진화해나가는 모습을 모방한, 파라미터의 최적화 문제를 풀기 위한 방법
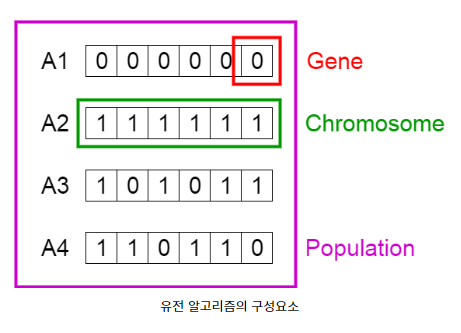
- 염색체(Chromosome): 여러개의 유전자를 담고 있는 하나의 집합. 하나의 해(파라미터)를 표현
- 유전자(Gene): 염섹체를 구성하고 있는 요소로서 하나의 유전 정보 나타냄
예를 들어 특정한 염색체가 [A,B,C,D]라고 정의되면 해당 염색체의 유전자는 A,B,C,D 4개 유전자 - 자손(Offspring): 특정 시간(t)에 존재했던 염색체들(ex. A,B 두 개 염색체 있다고 가정)로부터 생성된 새로운 염색체들(C,D라고 가정). C, D는 A, B 염색체들의 자손. 자손 염색체는 부모 염색체의 비슷한 유전 정보 가짐
- 정확도(Fitness): 특정한 염색체가 갖고 있는 고윳값, 특정한 염색체가 표현하는 파라미터가 해결하려는 문제에 대하 얼마나 적합한지 나타냄.
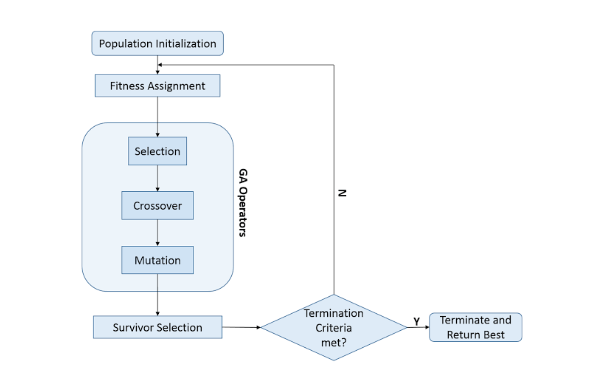
- 초기 염색체 집합 생성
- 초기 염색체들에 대한 적합도 계산
- 현재 염섹체들로부터 자손염색체 생성
- 생성된 자손들의 적합도 계산
- 종료 조건 만족하는지 판별
- 종료 조건이 거짓인 경우 3번으로 이동해서 반복
- 종료조건이 참인 경우 알고리즘 종료
1. 초기 염색체를 생성하는 연산
임의의 값으로 초기 염색체 생성
2. 적합도를 계산하는 연산
해결하려는 문제에 다라 다름
3. 적합도를 기준으로 자손 염색체를 선택하는 연산
적합도가 가장 높은 염색체를 선택하면 염색체의 다양성을 손상시켜 Global optimum을 찾기엔 부적합
룰렛 휠 선택(Roulette Wheel Selection)방법 이용
원판을 돌리면서 확률에 기반해 결과가 도출되는 룰렛의 개념과 비슷
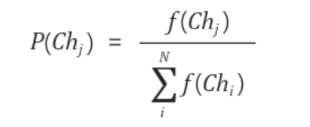
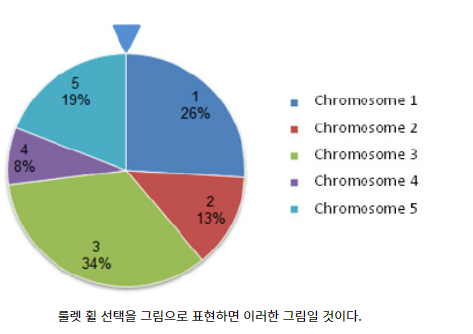
룰렛 그림에서 면적의 총합은 1(100%)
룰렛 휠 선택의 방법을 이용하게 되면 적합도가 높은 염색체가 룰렛에서 더 많은 비율의 면적을 차지해서 높은 적합도의 염색체가 선택될 확률이 높음.
동시에 염색체의 다양성을 훼손❌
4. 선택된 염섹체들로부터 자손 염색체들을 생성하는 연산
룰렛 휠 선택 방법으로 선정된 두 개의 부모 염색체들로부터 하나의 자손 염색체 생성
GA에서는 자손 염색체를 생성하는 연산으로서 주로 Crossover이라는 연산 사용
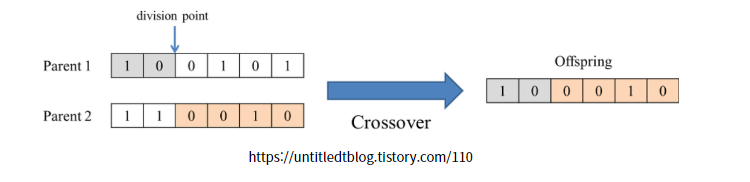
다음은 두 개의 염색체들로부터 두 개의 division point(crossover point)를 임의로 설정하고 두 개의 자손 염섹체를 생성
5. 돌연변이 연산
룰렛 휠 선택을 통해 Crossover연산만을 사용하면 Local optimum엥 빠지는 문제 발생
이러한 문제를 피하기 위해 자손 염색체에 0.1%나 0.05%등의 낮은 확률로 돌연변이 연산을 추가적으로 적용.
몇 가지 방법 살펴보면
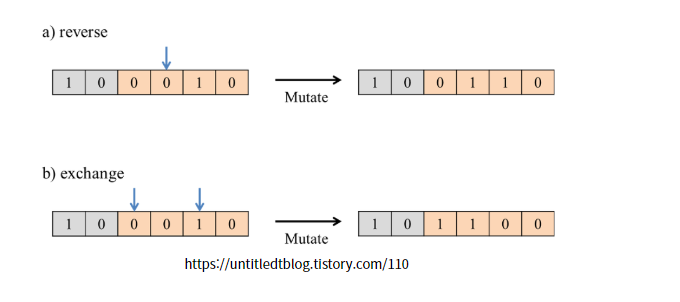
binary 값인 0과 1에서 0을 1로, 또는 1을 0으로 바꿔주는 reverse 방법
임의의 두 개의 유전자를 선택해 서로의 위치를 바꾸는 exchange방법
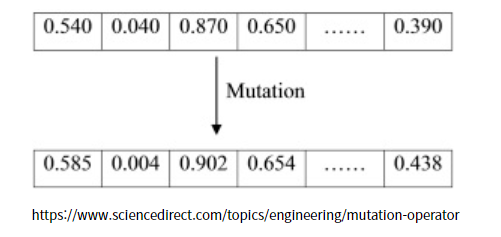
가우시안(정규분포) 연산 적용
가우시안 연산은 값이 작은 값들을 가장 likely하게 만들고 자주 generate하게 만들며 반면에 값이 큰 값들은 거의 generate되지 않도록 해주며 편차를 이용해 계산
다른 돌연변이 연산 방법보다 알고리즘 종료 조건(기준=criteria)에 converge하는데 더 효율적인 방법
2. Ensemble Self-Training Framework
2.1 General Workflow
- 필요한 구성 요소는 하나 이상의 기본 모델 유형과 레이블이 지정되지 않은 대량의 데이터가 포함
- 이상적으로, 기본 모델은 합리적인 성능으로 간단하고 신속하게 학습해야 하며 가능한 다양해야 함. 즉, 아키텍처가 다른 모델이 random seed가 다른 동일한 아키텍처보다 낫다
2.2 Ensemble Search
- 여러 다른 종류들로 이러진 앙상블 검색을 위해 유전 알고리즘 사용
- preliminary 실험에서 유전 알고리즘은 random sampling이나 모든 모델을 사용하는 것보다 일관되게 더 나은 앙상블을 찾음
- 이진 인코딩을 사용해 앙상블 조합(유전 알고리즘에서 개별료 표시)을 나타내며, 각 비트는 특정 모델을 사용할지 여부
- 앙상블의 예측 정확도를 최대화하는 것을 목표로 하기 때문에 개별 fitness 점수를 개별적으로 나타내는 앙상블에 의한 검증 셋에 대한 정확도로 개인의 fitness 점수 정의
2.3 Data Selection and Aggregation
- 각 반복에서, 현재 최적의 앙상블을 사용해 새로운 데이터 배치를 예측하고, 다음 반복에서 모델을 학습할 추가 데이터로 하위 집합 선택
새로운 데이터 선택 고려해야할 두 가지 주요 원칙
1. 정확할 가능성이 더 높기 때문에 모델 간에 더 높은 일치도를 보이는 인스턴스를 선호
2. 만장일치 동의가 있는 사례는 사소한 것일 수 있으며 모델을 학습시키는데 더 많은 새로운 정보를 제공하지 않음
3. Grapheme-to-Phoneme Conversion
3.1 Task and Data
- 전처리로서, 일본어와 한국어의 스크립트를 로마자로 표기
- 그 이유는 일본어 히라가나와 한글은 모두 음절문자로 하나의 grapheme이 일반적으로 여러 개의 phonemes에 해당하며 로마자로 표기함으로써 (1) 알파벳 크기를 줄이고 (2) 원어와 타깃의 길이를 1:1에 가깝게 하여 정렬 품질 향상
3.2 Models
- 네 가지 다른 유형의 기본 모델 사용
- 첫 유형은 pair n-gram 모델을 기반으로의 Finite-State-Transducer(FST) baseline
- 다른 세 가지 유형은 모두 Seq2Seq 모델의 변형, 동일한 BiLSTM 인코더를 사용해 입력 grapheme 시퀀스를 인코딩
- 첫 모델은 vanilla Seq2Seq 모델로, 디코더는 인코딩된 입력에 attention하고 attended input vector를 사용해 output phonemes 예측
- 두 번째는 hard monotonic attention model(mono)로, 디코더는 포인터를 사용해 입력 벡터를 선택해 예측 : phoneme을 생성하거나 포인터를 다음 위치로 이동
- 세 번째 모델은 본질적으로 hard monotonic attention 모델과 tagging model(태그)의 혼합. 즉, 각 grapheme에 대해 정렬된 짧은 phonemes 시퀀스 에측
- 학습을 위해 동일한 monotonic 정렬에 의존
Monotonic Alignment
n번째의 input에 대해 몇 번째의 Output을 주목해야하는지 계산하는 방식
Predictive Alignment: Decoder의 Hidden state를 Sigmoid 함수를 이용해 몇 번째 output을 주목해야 하는지 계산
Monotonic Attention
멀리 떨어진 time step과의 attention weight 값을 인위적으로 낮춰줌
- self-attention weight:
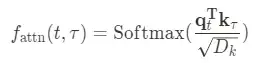
- Monotonic Attention:
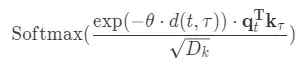
θ는 0보다 큰 learnabledecay rate parameter, 는 각각의 timestep t와 τ에 대한 거리를 재는 함수
⇒ 모델이 단순히 현재 보는 문제와 이전 문제들 간의 유사도만 볼 뿐 아니라 이전 문제들과의 거리도 본다는 측면에서 유용
4. Morphological Inflection
4.2 Models
- 왼쪽에서 오른쪽, 오른쪽에서 왼쪽으로 생성 순서와 쌍을 이루는 두 가지 유형의 기본 모델만 구현
- 첫 유형은 soft attention이 있는 Seq2Seq 모델로, morphological tag를 인코딩하는데 추가 BiLSTM을 사용한다는 점을 제외하곤 G2P 변환 작업의 모델과 매우 유사.
- 두 번째 유형은 hard monotonic attention 모델로 이전과 유사하지만 Levenshtein edit script를 사용해 대상 시퀀스를 얻음
- 각 단게에서 모델은 알파벳의 문자를 출력하거나 현재 가르키는 입력 문자를 복사하거나 입력 퐃인터를 다음 위치로 이동
- 총 8개의 모델을 각 iteration마다 학습. 즉, 각 변형에 대해 다른 random sed를 가진 2개의 모델 학습
5. Conclusion
- self-training 프레임워크를 제시하고 두 가지 sequence-to-sequence 생성 작업에 적용: G2P, morphological inflection
- 앙상블을 최적화하고 활용해서 보다 신뢰할 수 있는 학습 데이터를 얻음으로써 향상된 self-training 방법을 포함하고 있으며, 이는 저자원 언어에서 이점을 보여줌
- 유전자 알고리즘을 사용한 최적의 앙상블 검색 방법은 다른 언어에 대한 다른 모델 아키텍처의 귀납적 편향을 쉽게 수용
- 미래의 잠재적인 방향으로, 주석자 작업량을 줄이기 위해, 즉 수정의 필요성을 최소화하기 위해 그럴듯한 예측을 제안함으로써 프레임워크를 능동 학습 시나리오에 통합할 수 있음
