Abstract
- 본 논문은 SIGMORMON 2020 shared task의 task 0과1에 대한 제출
- 모든 언어의 데이터에 대해 공동으로 학습하는 다국어 모델 제시
- 언어별 hyperparameter tuning❌, 모든 언어에 대해 동일한 모델 사용
- 기본 아키텍처는 entmax attention과 loss가 있는 sparse(희소) sequence-to-sequence 모델이며, 우리의 모델은 gradient-based 기술로 여전히 학습 가능하면서 희소(sparse)하고 local alignments(로컬 정렬)을 배울 수 있음
- Task 1의 경우, RNN 기반 및 transoformer 기반 sparse model 모두에서 강력한 성능
- Task 0의 경우, RNN 기반 모델을 별도의 모듈이 lemma와 inflection sequence를 인코딩하는 multi-enocder set-up으로 확장
- 우리 모델은 언어별 튜닝이 부족하지만 Task 0에서 공동 1위, Task 1에서 3위 차지
inflection(굴절)
굴절 형태소(inflectional morpheme): 단어의 형태를 살짝 '굴절'한다는 의미
He likes to play soccer라는 문장에서 like 뒤에 -s가 굴절 형태소
1. Introduction
- G2P 변환 및 morphological inflection과 같은 문자 변환 작업은 많은 실제 응용 분야에서 중요
- 그러나 대부분의 세계 언어에 대한 레이블링된 데이터가 부족하기 때문에 딥러닝으로 학습하기 어려움
- 이런 상황에선 non-neural 방법을 사용하거나 데이터 희소성 문제를 개선할 수 있는 합성 데이터 생성이 일반적이지만 만족스럽지 않음
- 첫째, 이전 SIGMORPON shared task는 neural 방법이 적당한 양의 데이터가 있어도 non-neural들을 능가
- 둘째, 데이터 증강이 morphological inflection에 도움이 되는것으로 입증되었지만 데이터 증강 절차는 언어 구조에 대한 암묵적인 가정을 함 : 서양 언어에 효과가 있는 기술은: 중복, 모음 조화 또는 비연결 형태에 직면할 때 실패할 수 있음
- 라벨링된 데이터가 부족한 언어는 NLP 하기 어려움
- 공유 작업에 대한 제출은 세 번째 대안인 다국어 학습을 사용
- 다국어 학습은 정규화 역활을 해서 low resource setting 결과를 개선
- 여러 언어에서 동시에 우수한 성능을 발휘할 수 있기 때문에 산출되는 모델은 다양
- 이 기술이 G2P와 morphological inflection에 대한 학습 데이터 크기와 관계 없이 SOTA 단일 언어로 학습된 모델과 경쟁적이라는 것을 보여줌
- 이는 우리의 접근 방식이 튜닝 관점에서 상당한 단점이 있음에도 불구하고, 기존의 단일 언어 모델은 각 언어에 대해 hyperparameters를 개별적으로 조정할 수 있지만, 제출 내에서 각 언어에 대해 동일한 모델을 사용
우리의 기여는 다음과 같음:
- gated sparse two-headed attention을 다시 구현하고 대규모 다국어 환경에 적용
softmax 대안으로 1.5-entmax와 sparsemax를 사용하여 제출
Task 0에선 공동 1등인데 다국어 모델은 우리 것이 유일 - 이전에 morphological inflection과 기계 번역에 사용된 srase seq2seq 기술이 다국어 G2P에도 효과적이라는 것을 보여줌
- softmax 대체(1.5-entmax 또는 sparsemax)와 아키텍처(RNN 또는 Transformer)의 선택에 따라 다른 Task 1 제출
- 가장 좋은 모델은 WER에서 3위, PER에서 2위
⇨ 낮은 확률값들을 0으로 만들어 계산의 필요성을 줄인다면, 크기가 증가하는 최신 모데들에서 보다 적은 계산량을 가질 수 있기에 Sparse attention제시
출처 : https://silverstar0727.github.io/paper%20review/2020/11/06/adaptively_sparse_transformer(1)/
Sparse Attention
transformer의 Multi Head Attetnion의 Scaled Dot Product는 softmax 사용
softmax function은 exponential function에 대입한 값들의 결과라 0이 나올 수 없어서 확률이 적은 단어에 확실한 0의 attention score가 주어지지 못함
=> softmax의 sparse한 버전으로, sparse한 데이터셋에 적용했을 때 좋은 성능을 보인 normalization 기법
Adaptively Sparse Attention
Sparse Attention이 softmax를 개선했지만 아직도 적으 확률들에게 0을 부여X,
특정 상황에 따라서는 적은 확률들이 많이 등장할 필요가 있기 때문에 Heads가 유연하고 상황에 맞도록 달라지는 문맥에 의존적인 Adaptively sparse attention제시
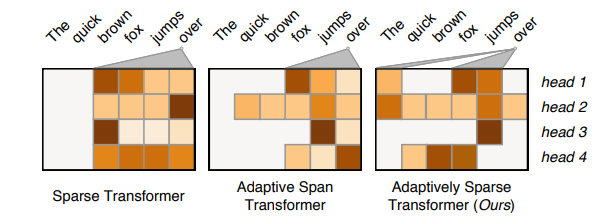
sparse attention은 모든 heads에서 'The', 'quick'에 0의 확률 할당
adaptive span transformer는 이를 어느 정도 개선했지만, adaptively sparse attention이 헤드 별로 유연하게 적용
즉, attention score가 미미한 단어에게 확실하게 zero-weight을 받을 수 있도로 하는 activation function도입.
필요에 따라 spread-out이 요구될 때에는 softmax가 선택될 수 있도록 α-entmax를 채택해서 α값은 자동적으로 선택이 가능하도록
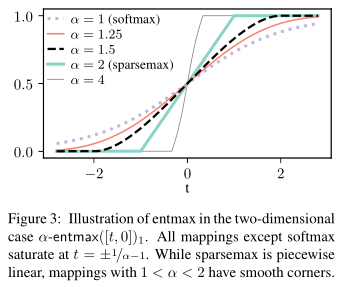
α가 1~4일 때 α-entmax를 그래프로 확인
α값이 커질수록 sparsity해지고, 경사가 급해짐
α-entmax가 heads에 붙는데 기존 에서 π를 α-entmax 로 치환
2. Models
- 모델의 공통된 주제는 softmax 대신 attention weight와 output distribution에 sparse 함수를 사용
sparse function은 다음과 같은 motivation을 가짐:
-
sparse attention은 이전에 morphological inflection에 대한 성공을 보여줌
dense sofmax와 달리 디코더가 각 time step에서 적은 수의 souce position에 attend할 수 있게 함
이전에는 문자 변환에 대한 hard attention이 잘 수행되었지만, 일반적으로 정교하고 느린 학습 절차
반면, sparse attention은 표준 seq2seq 모델에 사용되는 것 이상의 학습 기술 필요❌ -
sparse output distribution을 사용하면 probability mass이 소수의 가설에 집중
실제로, morphological inflection에 자주 발생하며, 때때로 beam search를 정확하게 만듬
2.1 Entmax and its loss
- sparse output layer가 있는 모델에 대한 중요한 점은 모델이 gold label에 확률을 0으로 할당할 때 cross entropy loss가 무한해지기 때문에 cross entropy loss로 학습❌
- 다행히 각 값 α에 대해 해당 loss function이 있음
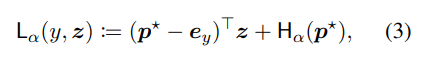
- 이고 이것은 Fenchel-Young loss의 한 예
2.2 Task 0 Architecture
- morphological inflection을 위해, gated attetnion이 있는 RNN 기반 2-encoder model 사용
- 이 모델에서, 두 개로 분리된 bidirectional LSTM은 lemma 문자 시퀀스와 inflectional tag 셋을 인코딩
- unidirectional LSTM 디코더는 target 시퀀스를 생성
- 디코더는 별도의 attention 메커니즘이 각 인코데에 대해 독립적으로 context vector를 계산한다는 점을 제외하고는 input feeding이 있는 기존 RNN deocder와 유사
- 그런 다음 gate function은 두 context vector를 채움
- sparse gate를 사용하여 모델이 각 time step에서 하나의 인코더 또는 다른 인코더를 완전히 무시할 수 있음
- 각 개별 attention head는 이중 선형 attention 사용
3. Experiments
3.1 Preprocessing
Task 1
- 학습에 앞서, 모든 언어의 grapheme 시퀀스에서 복합 문자를 분해
- 대부분의 언어에서 발음 구별 기호와 기본 문자를 별도의 토큰으로 나누는 것과 같음
- 한국어의 경우, 한글의 독특한 구조 때문에 큰 차이를 만듬
- 자모라고 불리는 한글의 개별 문자는 음절(syllables)을 나타내는 블록으로 구성
- 현대 한글은 40개의 자모를 포함하고 있지만, Korean phonotactics(한국어 음운론)에 의해 허가된 가능한 음절의 수는 훨씬 더 많음
- 결과적으로 한국어 학습 데이터의 naive 토큰화는 834개 유형의 vocabulary size를 제공하며, 그 중 30% 이상은 한번만 발생
- 자모 토큰화의 부족이 baseline의 한국어 성능 저하의 원인이라고 의심
