🖇 왜 차원 축소를 해야 하는가?
🖇 다양한 차원 축소 방법
🖇 PCA란?
🖇 PCA로 차원 축소하기
K-Means 클러스터링을 적용하기 전, 또 하나 중요한 사전 작업이 남아 있다. 앞서 스케일링했던 데이터의 차원을 축소하는 것이다.
차원 축소(Dimensionality Reduction)는 고차원 데이터를 더 낮은 차원으로 요약하면서도,
데이터의 중요한 특징(분산, 구조, 패턴)은 최대한 보존하는 기술이다.
해당 프로젝트에서는 다양한 차원 축소 방법 중 주성분 분석(PCA)를 통해 차원 축소를 진행할 것이다.
먼저 왜 차원 축소가 필요한지, PCA를 선택한 이유는 무엇인지부터 정리해 보았다.
🖇 왜 차원 축소를 해야 하는가?
차원 축소가 무엇인지는 알았는데, 차원 축소가 왜 필요할까?
-
다중공선성 완화
이전 분석에서 확인했듯이, 특성들 간의 상관관계(다중공선성)가 존재한다. PCA를 통해 중복된 정보를 줄이고 독립적인 축으로 데이터를 변환할 수 있다. -
클러스터링 품질 향상
K-Means는 거리 기반 알고리즘이기 때문에, 불필요하게 많은 특성이 있으면 데이터의 의미 있는 기저 패턴을 희석시킬 수 있다. -
노이즈 제거
가장 중요한 특성에만 초점을 맞추면서 더 정확하고 안정적인 군집을 형성할 수 있다. -
시각화 가능
2차원 혹은 3차원으로 축소하면, 고객 그룹을 시각적으로 표현할 수 있어 직관적인 통찰을 얻어낼 수 있다. -
계산 효율 향상
특성 수가 줄어들면 연산 효율이 개선되어 모델 학습 속도도 빨라지고, 클러스터링 알고리즘을 더 효율적으로 만들 수 있다.
이제 차원 축소 방법을 비교해 보고, 데이터에 적합한 차원 축소 방법을 선택해 보자.
🖇 다양한 차원 축소 방법
차원 축소 방법에는 여러 가지가 있다.
해당 프로젝트에서는 아래의 방법 중 가장 널리 쓰이고 안정적인 PAC(주성분 분석, Principal Component Analysis)를 사용할 것이다.
| 기법 | 유형 | 특징 |
|---|---|---|
| PCA | 선형 | 분산 최대화 방향으로 차원 축소 |
| ICA | 선형 | 독립 성분 분리에 초점 |
| t-SNE | 비선형 | 고차원을 저차원으로 시각화용으로 주로 사용 |
| UMAP | 비선형 | 클러스터 유지에 강점, 속도도 빠름 |
| ISOMAP | 비선형 | 거리 기반으로 비선형 구조 유지 |
PCA가 데이터 내의 선형 관계를 잘 포착하고, 특히 다중공선성이 있는 데이터셋에 효율적이기 때문이다.
PCA가 해당 프로젝트에 적합하기는 하지만, 다른 차원 축소 방법을 사용할 가능성을 열어두는 것 역시 중요하다.
PCA를 적용한 후에 첫 몇 개의 구성 요소가 중요한 정보를 모두 다 담지 못한다면 중요한 정보가 손실되었다는 것을 의미하므로 다른 비선형 차원 축소 방법을 탐색할 수 있다. 계산 시간과 복잡성이 증가하더라도 PCA를 통해 포착하지 못하는 복잡한 패턴을 더 세밀하게 찾는 데에 도움을 줄 수 있다 :)
🖇 PCA란?
PCA는 고차원 데이터의 주요 특징들은 유지하면서 차원을 줄이는 기술이라고 했는데,
이 과정에서는 몇 개의 피처를 단순히 제거하는 것이 아니라, 원본 피처들을 조합한 주성분(Principal Component)이라는 새로운 변수들이 생성된다. 이 주성분들은 원본 데이터의 분산(variance)을 최대한 포착하는 방향으로 설정된다.
“각 주성분이 데이터의 전체 변동성 중 얼마나 많은 부분을 설명하는지”가 중요하다는 것이다. 예를 들어 원본 데이터가 여러 차원을 가지고 있을 때, 첫 번째 주성분(PC1)은 가장 많은 분산(데이터의 변동성)을 설명하고 두 번째 주성분(PC2)는 첫번째 주성분 다음으로 많은 분산을 설명한다. 이런식으로 각 주성분은 원본 데이터의 변동성을 최대한 포착하도록 생성된다.
이런 분석을 통해 데이터의 중요한 특성과 특징들은 유지하면서도 차원의 수를 줄일 수 있게 되는 것이다. 이는 특히 고차원 데이터를 시각화하거나 불필요한 정보를 줄여 더 효율적인 데이터 분석을 하고자 할 때 유용하게 활용할 수 있다.
| 용어 | 설명 |
|---|---|
| 주성분 (PC) | 데이터를 분산이 큰 방향으로 투영한 새 축 |
| 분산 (Variance) | 데이터의 퍼짐 정도. 클수록 정보량 많음 |
| Explained Variance Ratio | 각 주성분이 전체 데이터 분산을 얼마나 설명하는지 비율로 표시한 값 |
🖇 PCA로 차원 축소하기
우선 PCA를 적용하고 각 주성분이 데이터를 얼마나 잘 표현할 수 있는지 시각화하여 분석에 유지할 최적의 주성분 수를 파악해야 한다.
1. PCA 적용 준비
PCA를 진행하기 위해 필요한 라이브러리를 불러온다.
CustomerID를 제외하고 PCA를 적용한다.
from sklearn.decomposition import PCA
# CustomerID를 인덱스로 지정
data.set_index('CustomerID', inplace=True)
# PCA 학습
pca = PCA().fit(data)
2. 설명 분산 비율 계산
data에 대하여 학습한 PCA 결과를 활용하여 Explained Variance Ratio(explained_variance_ratio)와 누적분포를 계산해야 한다.
Explained Variance Ratio란?
각 주성분이 데이터의 분산을 얼마나 포착하는지를 나타내는 비율
# 각 주성분이 설명하는 분산 비율
explained_variance_ratio = pca.explained_variance_ratio_
# 누적합 계산
cumulative_explained_variance = np.cumsum(explained_variance_ratio)
3. 결과 시각화
plt.figure(figsize=(15, 8))
# 각 성분의 설명된 분포에 대한 막대 그래프
barplot = sns.barplot(x=list(range(1, len(cumulative_explained_variance) + 1)), y=explained_variance_ratio, alpha=0.8)
# 누적 분포에 대한 선 그래프
lineplot, = plt.plot(range(0, len(cumulative_explained_variance)), cumulative_explained_variance, marker='o', linestyle='--', linewidth=2)
# 레이블과 제목 설정
plt.xlabel('Number of Components', fontsize=14)
plt.ylabel('Explained Variance', fontsize=14)
plt.title('Cumulative Variance vs. Number of Components', fontsize=18)
# 눈금 및 범례 사용자 정의
plt.xticks(range(0, len(cumulative_explained_variance)))
plt.legend(handles=[barplot.patches[0], lineplot],
labels=['Explained Variance', 'Cumulative Explained Variance'])
# 두 그래프의 분산 값 표시
x_offset = -0.3
y_offset = 0.01
for i, (ev_ratio, cum_ev_ratio) in enumerate(zip(explained_variance_ratio, cumulative_explained_variance)):
plt.text(i, ev_ratio, f"{ev_ratio:.2f}", ha="center", va="bottom", fontsize=10)
if i > 0:
plt.text(i + x_offset, cum_ev_ratio + y_offset, f"{cum_ev_ratio:.2f}", ha="center", va="bottom", fontsize=10)
plt.grid(axis='both')
plt.show()
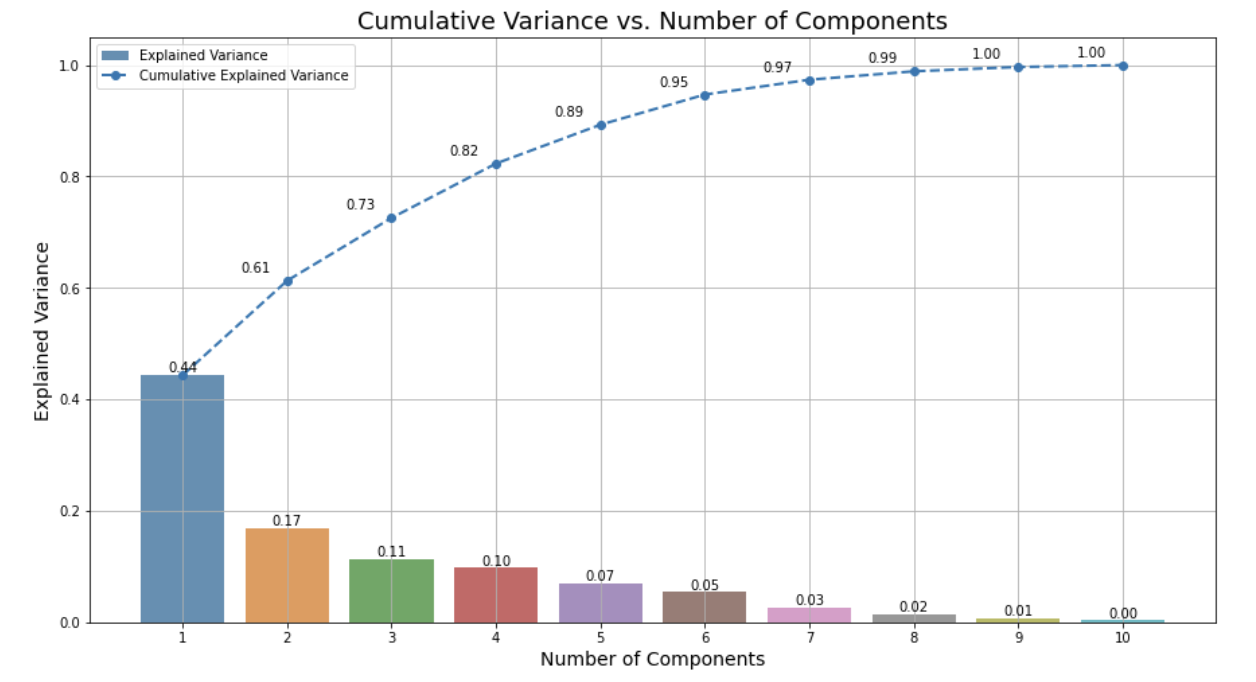
- PC1(첫 번째 주성분): 전체 분산의 약 47% 설명
- PC1 + PC2: 약 64% 설명
- PC1 + PC2 + PC3: 약 75% 설명
- PC1 ~ PC6: 약 95% 이상의 누적 분산 설명
최적의 주성분 수를 선택하기 위해 일반적으로 cumulative explained variance(누적 설명 분산)이 크게 증가하지 않는 지점을 찾는다. 이를 곡선의 '엘보우 포인트'라고 한다.
시각화 결과로 볼 수 있듯이 누적 분산의 증가는 5-6번째 주성분 이후에 둔화되기 시작한다 (-> 전체 분산의 약 95%를 설명)
엘보우 포인트 기준, 6개의 주성분이면 충분히 정보 손실 없이 데이터를 요약할 수 있음을 알 수 있다.
4. 데이터 차원 축소
누적 분산의 증가는 5-6번째 주성분 이후에 둔화되기 시작하기 때문에, 처음 6개의 주성분을 유지하여 큰 정보 손실 없이 데이터의 차원을 줄여야 한다.
CustomerID 컬럼을 제외하고 10개의 특성으로 구성되었던 data를 압축하여, 6개의 특성으로 이루어진 data_pca를 생성하였다.
# 주성분 6개로 차원 축소
pca = PCA(n_components=6)
data_pca = pca.fit_transform(data)
# 결과를 데이터프레임으로 변환
data_pca = pd.DataFrame(data_pca, columns=[f'PC{i+1}' for i in range(pca.n_components_)])
# 인덱스에 있었던 CustomerID는 필요 시 다시 추가
data_pca.index = data.index
# 결과 확인
data_pca.head()
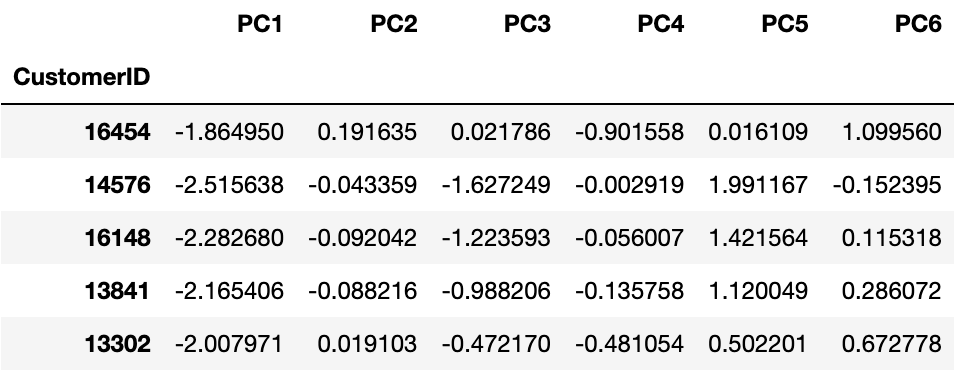
기존에는 10개의 특성이 있었던 데이터가
이제는 PC1 ~ PC6까지, 총 6개의 압축된 변수로 구성된 것을 확인할 수 있다.
지금까지 중복된 데이터를 제거하고 차원을 축소시키면서도 기존 데이터의 정보들을 유지하는 형태로 차원 축소를 진행해 보았다.
| 항목 | 설명 |
|---|---|
| 차원 축소 목적 | 중복 정보 제거, 계산 효율 향상, 노이즈 감소 |
| 사용 기법 | PCA (선형 차원 축소) |
| 주성분 선택 기준 | 누적 설명 분산 95% 기준으로 6개 선택 |
| 결과 | 기존 10개 → 6개 주성분(PC1 ~ PC6)으로 축소 |
이제 본격적으로 K-Means 클러스터링을 통해 더 명확한 고객 그룹을 도출해 볼 예정이다.
[해당 컨텐츠는 아이펠 캠퍼스 LMS에서 학습한 내용을 재해석한 것으로 무단 복제 및 사용을 금지합니다.]
