
웹 크롤링(Web Crawling)을 진행하며 조금 더 난이도를 올려보고 싶어서 이번에는 인스타 그램을 크롤링 해보고자 했다.
삽질을 많이 하다보니 과정이 매끄럽지 못해 글을 둘로 나눠 설명하고자 한다.
이번 글에서는 인스타그램 크롤링의 과정을, 다음 글에서는 검색과 그 결과를 보이기까지의 과정을 담고자 한다.
⭐ 삽 질 주 의 ⭐
1. 목표 설정
- 인스타그램에서 해시태그 크롤링
- 빈도수를 기준으로 상위 10개의 해시태그 추출
- 네이버 쇼핑, 판매 많은순 상위 5개의 추출
최종 파일 구조
. └── dog_product_crawling/ ├── data/ │ ├── instagram_data.xlsx │ ├── instagram_top_10_naver_price.xlsx │ └── instagram_top_10_naver_price_result.xlsx ├── notebooks/ │ ├── 1_crawl_instagram.ipynb │ └── 2_price_naver.ipynb └── scripts/ └── crawl_instagram.py
2. 인스타그램 해시태그 크롤링
인스타그램에서 크롤링을 할때는 정..말 주의해야 한다.
사실 API를 이용하는 방법도 있지만 이번에는 Selenium을 이용하여 크롤링을 하기 위해서 일반 계정을 이용해서 크롤링을 진행했다.
우선 인스타그램에서 각 내용들을 크롤링하기 전에, 요소들을 파악해야한다.
인스타그램은 크롤링하기 위해서는 계정 로그인이 필요하다.
-
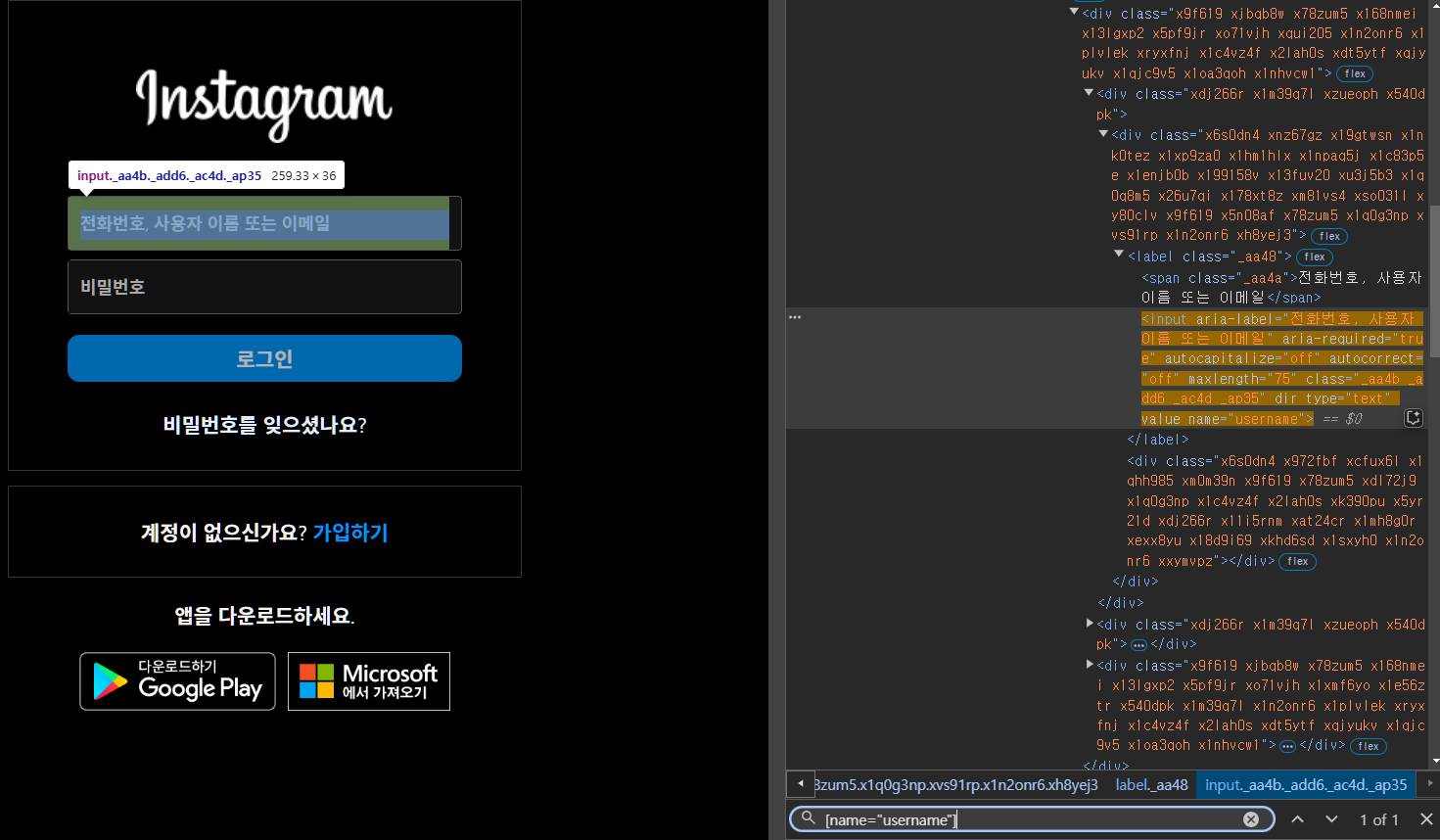
ID 입력부분: [name="username"]
-
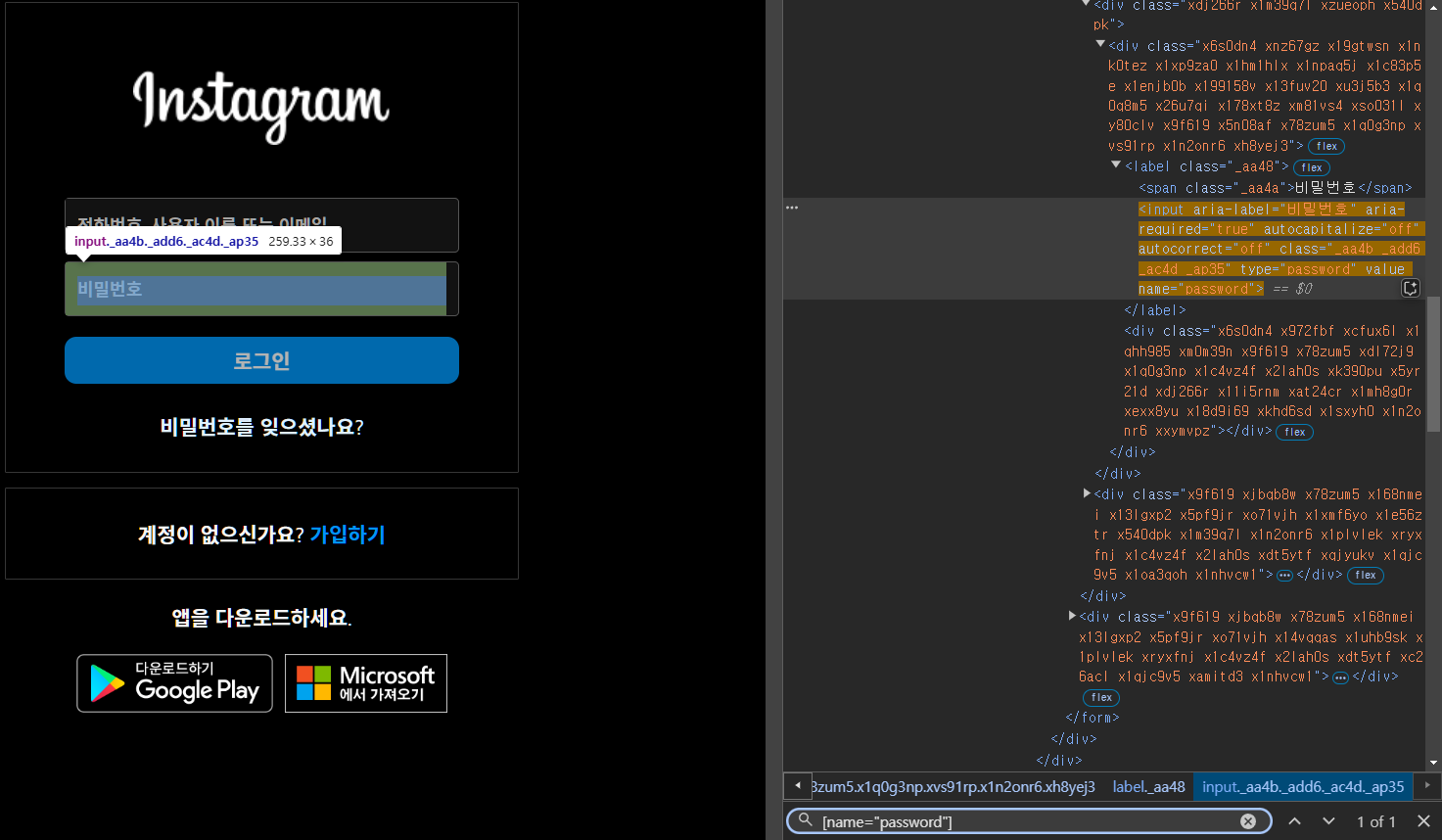
PW 입력부분: [name="password"]
-
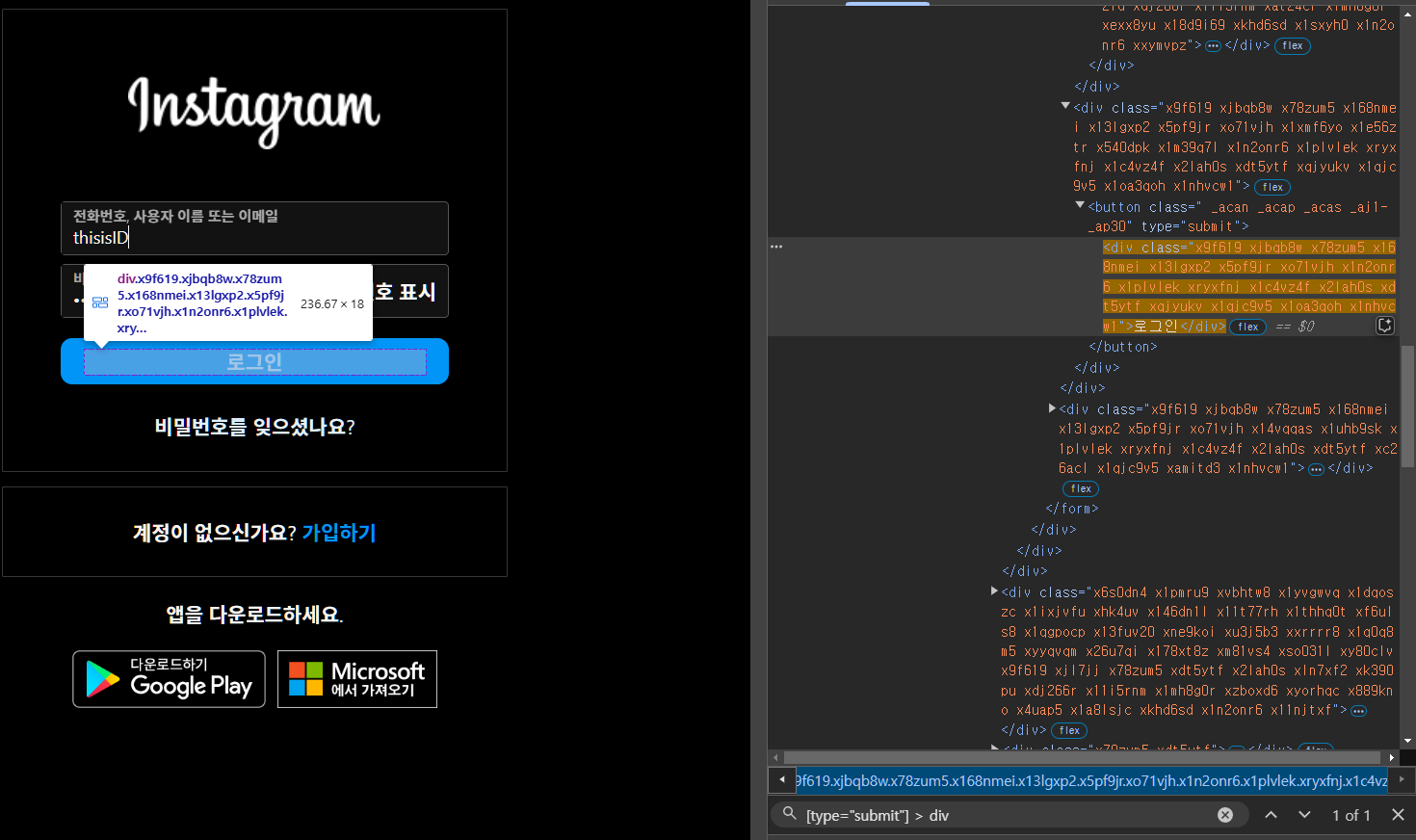
로그인 버튼: [type="submit"]
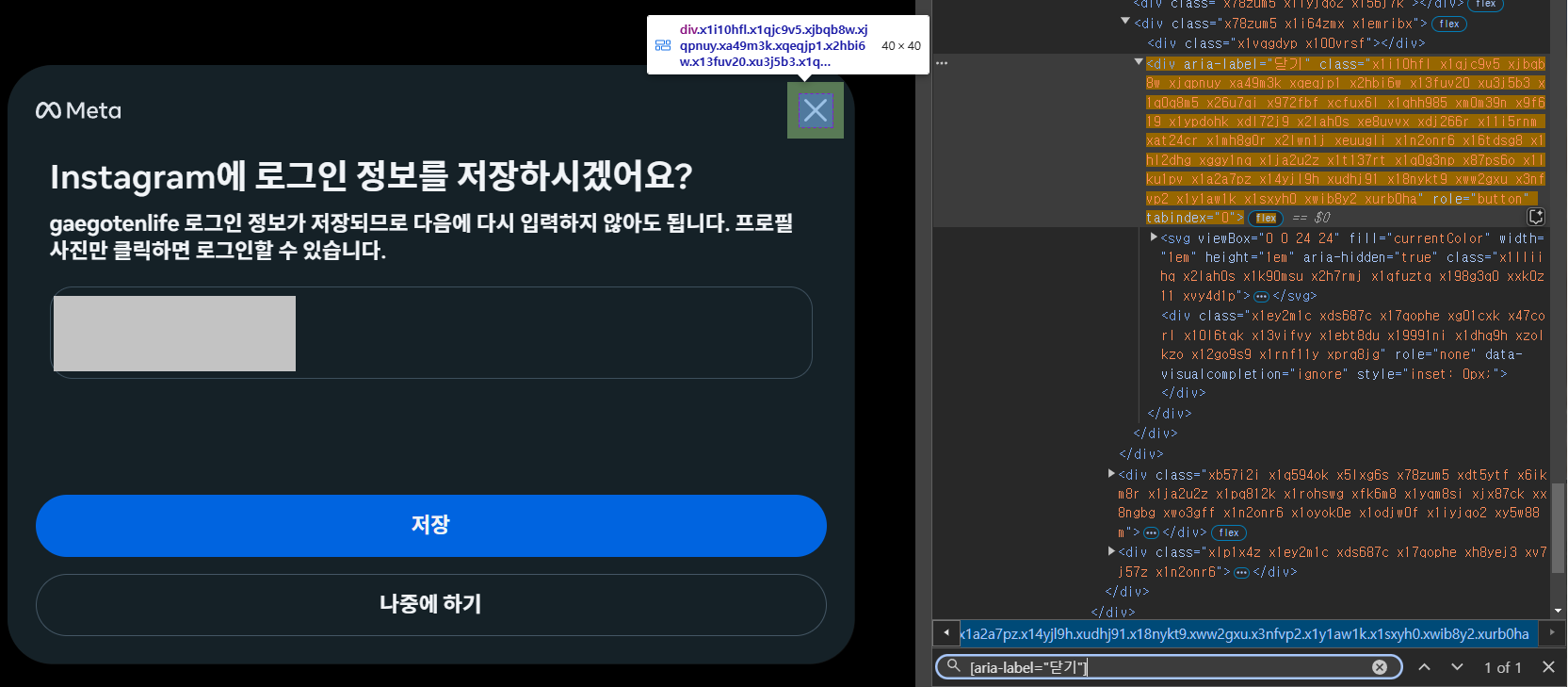
단 로그인한 후에는 웹 드라이버로 접속하기 때문에, 본인의 계정을 저장할지 나중에 저장할지에 대한 팝업이 나타난다. 따라서 어차피 기록이 안되기 때문에, 나중에 저장 버튼을 클릭해야한다.
또, 이 팝업이 두 개의 패턴으로 나타나는데 각각 다르기 때문에 둘 다 요소의 id를 알아야 한다.
-
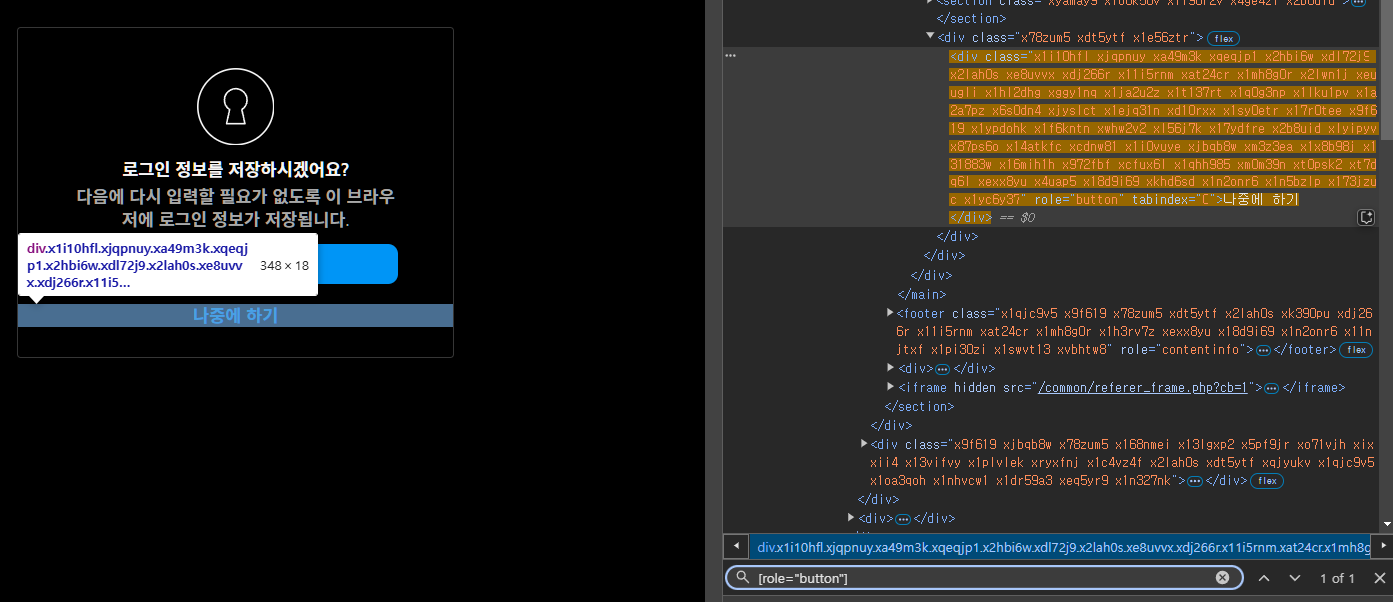
[role="button"]
-
[aria-label="닫기"]
이제 실제 로그인을 위한 부분으로 넘어가면 다음과 같다.
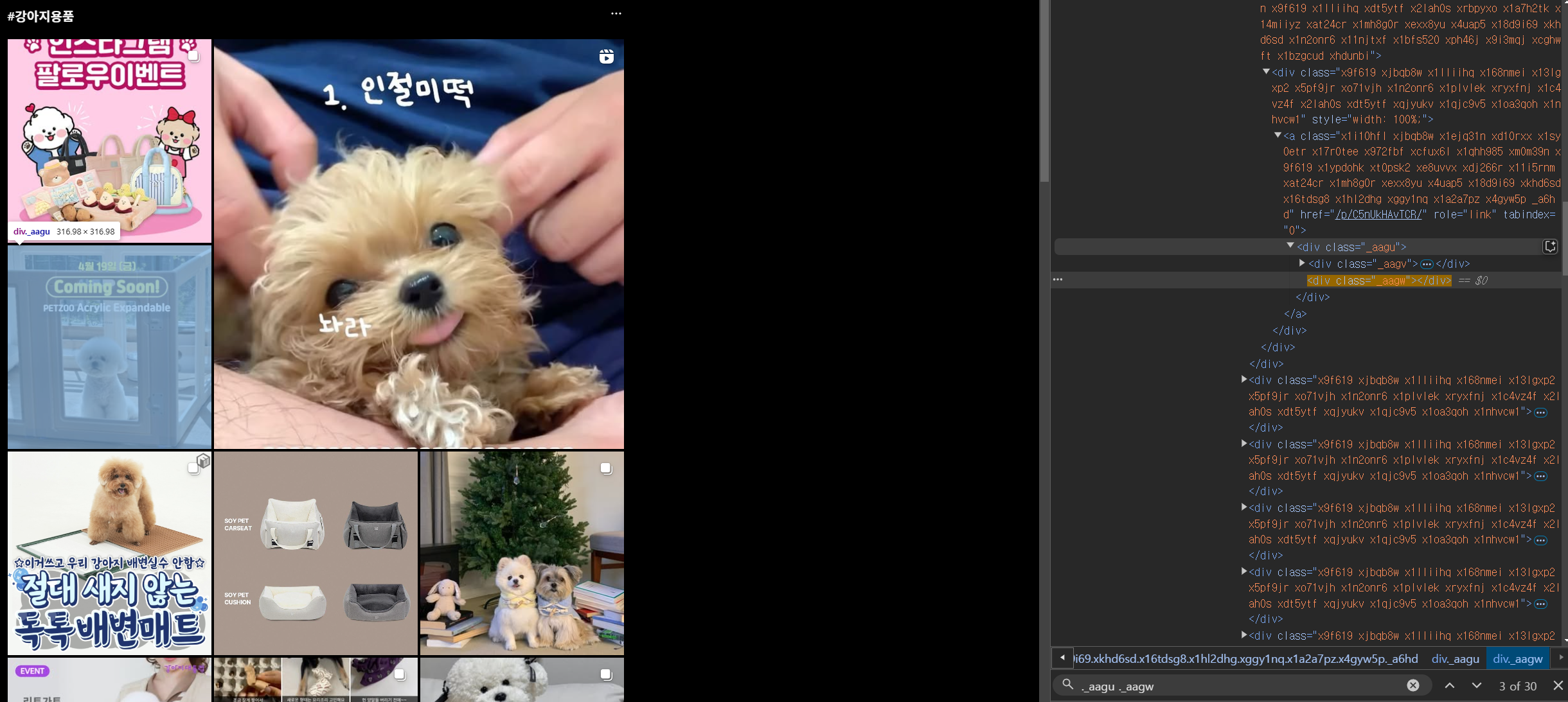
원하는 해시태그로 검색하는 부분으로 URL을 이용해 이동하면 게시글들이 나온다.
이때 게시글들의 요소값을 얻어와 크롤링하고자 하는 개수만큼 스크롤을 내려줘야한다.
-
게시글들: ._aagu ._aagw
-
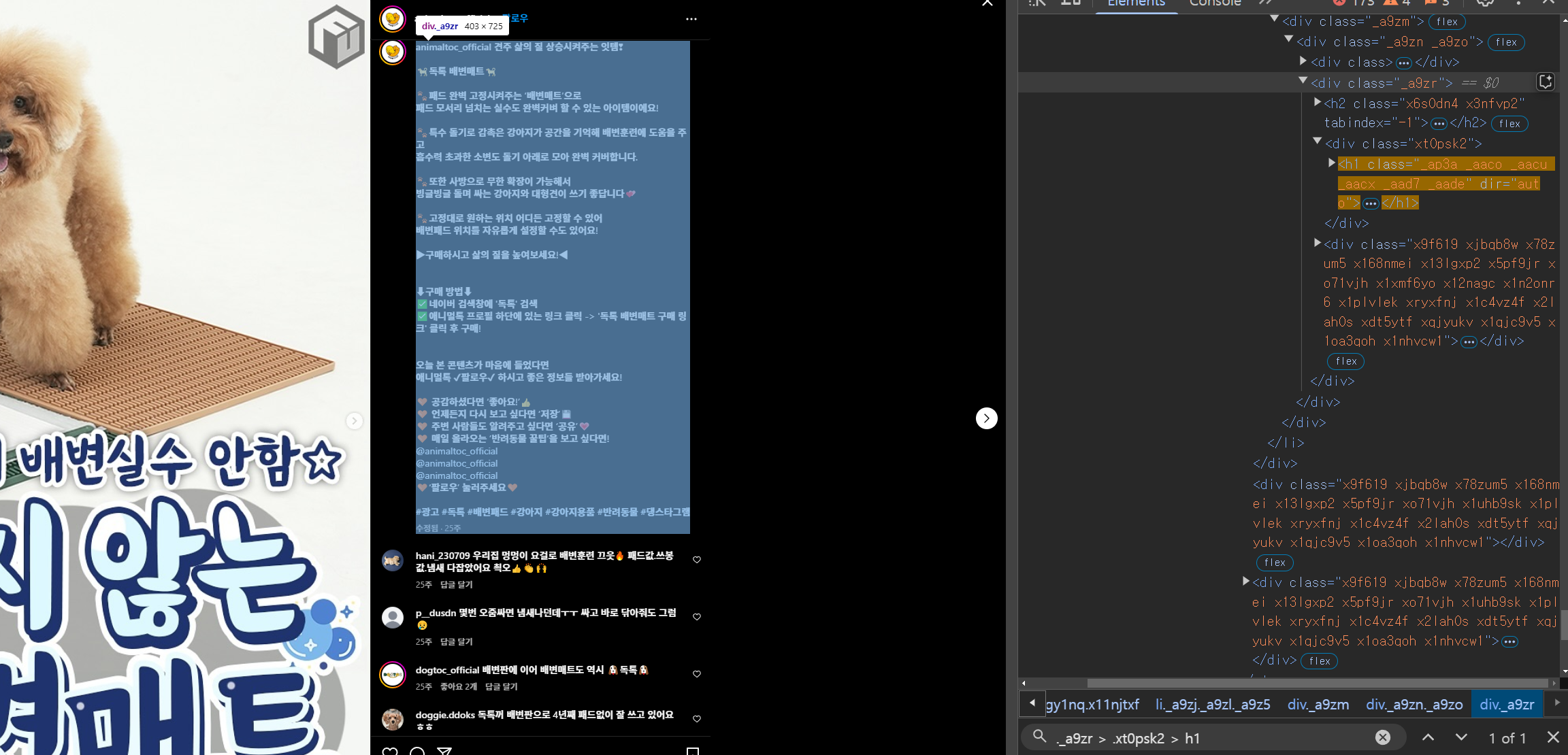
게시글 본문: ._a9zr > .xt0psk2 > h1
-
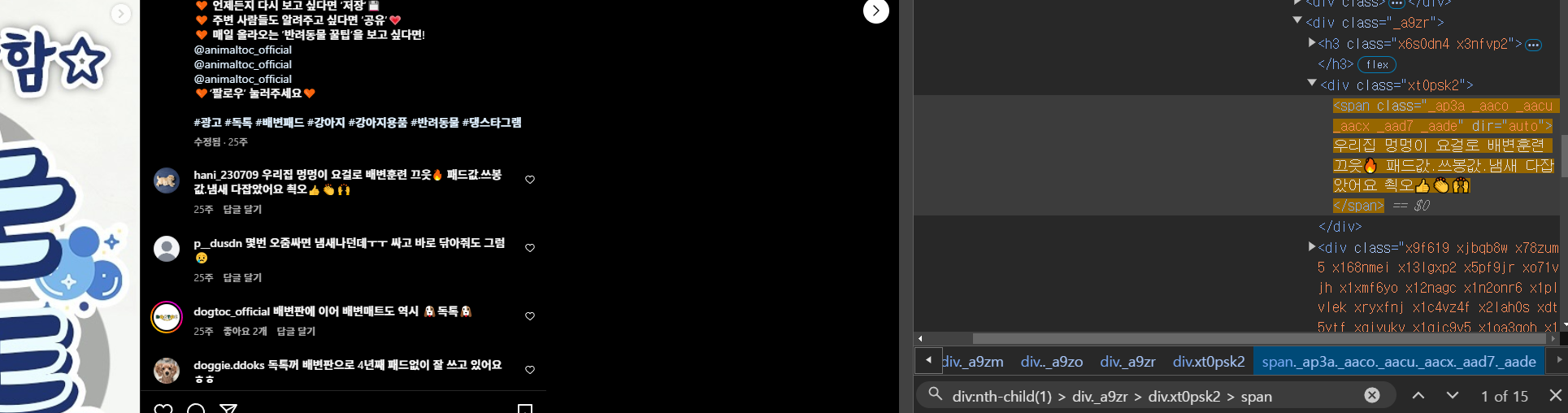
게시글 댓글: div:nth-child(1) > div._a9zr > div.xt0psk2 > span
-
다음 버튼: div._aaqg._aaqh > button
이들을 이용해 크롤링을 해보자!
2.1. crawl_instagram.py
import time
import re
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
# Browser setting
def setup_browser():
driver_path = ChromeDriverManager().install() # 크롬 드라이버 자동 다운로드 및 설치
service = Service(executable_path=driver_path) # 설치된 크롬 드라이버 실행
options = Options()
driver = webdriver.Chrome(service=service, options=options) # 웹 브라우저 실행
driver.implicitly_wait(0.5)
return driver
# Login
def login(driver, ig_id, ig_pw):
driver.get('https://www.instagram.com/accounts/login/')
time.sleep(3)
ig_login_id = driver.find_element(By.CSS_SELECTOR, '[name="username"]')
ig_login_id.click()
ig_login_id.send_keys(ig_id)
time.sleep(2)
ig_login_pw = driver.find_element(By.CSS_SELECTOR, '[name="password"]')
ig_login_pw.click()
ig_login_pw.send_keys(ig_pw)
time.sleep(2)
login_btn = driver.find_element(By.CSS_SELECTOR, '[type="submit"] > div')
login_btn.click()
# Save login info later
time.sleep(10)
try:
login_info_save_later_btn = driver.find_element(By.CSS_SELECTOR, '[role="button"]')
login_info_save_later_btn.click()
except:
try:
login_info_save_later_btn = driver.find_element(By.CSS_SELECTOR, '[aria-label="닫기"]')
login_info_save_later_btn.click()
except Exception as e:
print(f"버튼 클릭 실패: {e}")
time.sleep(10)
Search URL
def ig_search(hashtag):
ig_search_url = 'https://www.instagram.com/explore/tags/' + hashtag
return ig_search_url
# Crawling
def ig_get_content(driver):
soup = BeautifulSoup(driver.page_source, "html.parser")
# content
try:
post_content = soup.select("._a9zr > .xt0psk2 > h1")[0].text
except:
post_content = " "
# Comment
try:
post_comment = []
comment_elements = soup.select("div:nth-child(1) > div._a9zr > div.xt0psk2 > span")
for comment in comment_elements:
post_comment.append(comment.text)
post_comment = " ".join(post_comment)
except:
post_comment = " "
# Content + Commnet
content=post_content + " " + post_comment
# Get Hashtag
tags = re.findall(r"#[^\s#,\\]+", content)
data = [content, tags]
return data
# Next Button
def ig_post_next_btn(driver):
try:
right = driver.find_element(By.CSS_SELECTOR, "div._aaqg._aaqh > button")
right.click()
time.sleep(10)
except Exception as e:
print("다음 게시물이 없습니다!")
return False # Return "False" if there are no more posts
return True # Return "True" if there is a post
# Scroll to load posts
def ig_scroll_to_load_posts(driver, target_posts, posts):
# Number of loaded posts
post_count = len(posts)
# Return without scrolling
if post_count >= target_posts:
print(f"현재 로드된 게시물이 {post_count}개로 설정한 {target_posts}개 이상이므로 스크롤을 내릴 필요가 없습니다.")
return posts
while post_count < target_posts:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)
new_posts=driver.find_elements(By.CSS_SELECTOR, "._aagu ._aagw")
# Add newly loaded post link to existing list
posts.extend(new_posts)
# Update the number of loaded posts
post_count=len(posts)
print(f"현재 로드된 게시물 개수 >> {post_count}")
time.sleep(5)
# Click the first post
if posts:
posts = driver.find_elements(By.CSS_SELECTOR, "._aagu ._aagw")
first_post = posts[0]
driver.execute_script("arguments[0].click();", first_post)
time.sleep(5)
return posts
def crawl_instagram(target_posts, hashtag, ig_id, ig_pw):
driver = setup_browser()
login(driver, ig_id, ig_pw)
ig_search_url = ig_search(hashtag)
driver.get(ig_search_url)
# Wait for load search page
time.sleep(3)
posts = []
posts = ig_scroll_to_load_posts(driver, target_posts=target_posts, posts=posts)
results = []
for i in range(target_posts):
# Stop if there are no more posts
if not ig_post_next_btn(driver):
break
try:
data_posts = ig_get_content(driver)
results.append(data_posts)
except Exception as e:
print(f"게시물 {i+1}에서 오류 발생: {e}")
# Wait for 3 sec and continue
time.sleep(3)
return results2.2. crawl_instagram.ipynb
import time
import getpass
import sys
import os
# Add scripts folder path
sys.path.append("../scripts")
from crawl_instagram import crawl_instagram
hashtag="강아지용품"
# User input part
ig_id=input("Enter Instagram ID >> ")
ig_pw=getpass.getpass("Enter Instagram PW >> ")
target_posts=int(input("크롤링할 게시물 개수 >> "))
# Crawling
results=crawl_instagram(target_posts, hashtag, ig_id, ig_pw)
# Save data
import pandas as pd
ig_df=pd.DataFrame(results)
ig_df.columns=['contents', 'tags']
ig_df.to_excel('../data/instagram_data.xlsx', index=False, engine='openpyxl')
print("크롤링 완료! 데이터가 excel 파일로 저장되었습니다.")Enter Instagram ID >> thisisID
Enter Instagram PW >> ········
크롤링할 게시물 개수 >> 500
현재 로드된 게시물 개수 >> 18
현재 로드된 게시물 개수 >> 57
현재 로드된 게시물 개수 >> 87
현재 로드된 게시물 개수 >> 117
현재 로드된 게시물 개수 >> 147
현재 로드된 게시물 개수 >> 177
현재 로드된 게시물 개수 >> 207
현재 로드된 게시물 개수 >> 237
현재 로드된 게시물 개수 >> 267
현재 로드된 게시물 개수 >> 297
현재 로드된 게시물 개수 >> 348
현재 로드된 게시물 개수 >> 378
현재 로드된 게시물 개수 >> 408
현재 로드된 게시물 개수 >> 459
현재 로드된 게시물 개수 >> 510
크롤링 완료! 데이터가 excel 파일로 저장되었습니다.크롤링하고자 하는 해시태그는 강아지용품이다.

ig_df = pd.read_excel('../data/instagram_data.xlsx', engine='openpyxl')
ig_df['tags']0 ['#강아지후리스', '#강아지올인원', '#강아지크리스마스']
1 ['#광고']
2 ['#광고', '#순둥이', '#순둥이물티슈', '#순둥이와댕댕이', '#펫티슈',...
3 []
4 ['#강아지리드줄', '#강아지하네스', '#애견동반숙소', '#강아지장난감', '...
...
495 ['#광고🎉', '#마이리틀베어', '#MYLITTLEBEAR', '#강아지전문',...
496 ['#강아지리드줄', '#강아지가슴줄', '#강아지겨울옷', '#강아지하네스', '...
497 ['#강아지하네스', '#강아지겨울옷', '#강아지옷', '#강아지용품', '#강아...
498 ['#강아지용품', '#강아지옷']
499 []
Name: tags, Length: 500, dtype: objectig_df.drop_duplicates(subset=["contents"], inplace=<True)
tags_total = []
for tags in ig_df["tags"]:
tags_list = eval(tags)
for tag in tags_list:
tags_total.append(tag)
print(tags_total)['#강아지후리스', '#강아지올인원', '#강아지크리스마스', '#광고', '#광고', '#순둥이', '#순둥이물티슈', '#순둥이와댕댕이', '#펫티슈', '#펫티슈추천', '#반려견물티슈', '#반려견물티슈추천', '#강아지물티슈추천', '#강아지물티슈', '#애견물티슈', '#애견물티슈추천', '#순둥이와댕댕이', '#댕댕이물티슈', '#강아지발바닥', '#강아지눈물자국', '#강아지눈꼽', '#강아지목욕티슈', '#물티슈산도', '#중성물티슈', '#반려동물용품', '#강아지용품', '#물티슈ph', '#애견용품', ...from collections import Counter
tag_counts=Counter(tags_total)
print(tag_counts.most_common(50))[('#강아지용품', 160), ('#애견용품', 63), ('#강아지하네스', 49), ('#강아지목줄', 48), ('#하네스', 45), ('#강아지리드줄', 44), ('#리드줄', 44), ('#강아지옷', 44), ('#강아지가슴줄', 38), ('#목줄', 34), ('#애견동반카페', 30), ('#강아지겨울옷', 29), ('#강아지동반', 28), ('#애견', 27), ('#협찬', 15), ('#강아지악세사리', 14), ('#애견용품점', 14), ('#강아지목줄추천', 13), ('#하네스추천', 13), ('#강아지장난감', 12), ('#가죽하네스', 12), ('#고양이용품', 11), ...import re
# 동의어 매핑
replace_keywords = {
"애견": "강아지",
"반려견": "강아지",
"애견용품": "강아지용품",
"반려견용품": "강아지용품",
"하네스": "강아지하네스",
"가슴줄": "강아지하네스",
"애견가슴줄": "강아지하네스",
"강아지가슴줄": "강아지하네스",
"반려견가슴줄": "강아지하네스",
"애견하네스": "강아지하네스",
"반려견하네스": "강아지하네스",
"목줄": "강아지목줄",
"애견목줄": "강아지목줄",
"반려견목줄": "강아지목줄",
"리드줄": "강아지리드줄",
"애견리드줄": "강아지리드줄",
"반려견리드줄": "강아지리드줄"
}
# 해시태그에서 해당 키워드들을 바꾸는 함수
def replace_tags(tag):
for keyword, replacement in replace_keywords.items():
tag = re.sub(rf"#{keyword}", f"#{replacement}", tag) # '#'을 포함하여 교체
return tag
# 동의어 매핑 적용 후 해시태그 필터링
filtered_tags = []
for tag in tags_total:
filtered_tag = replace_tags(tag) # replace_tags 함수로 tag를 변환
filtered_tags.append(filtered_tag) # 변환된 tag를 filtered_tags 리스트에 추가
# 제외할 키워드 목록
exclude_keywords = ["추천", "할인", "세일", "광고", "협찬", "동반", "스타그램",
"말티즈", "일상", "테리어", "제공", "강아지용품", "애견용품", "소형견",
"대형견", "댕댕이", "커뮤니티", "이벤트", "고양이", "생일", "브랜드",
"선물", "모델", "멍팔"]
# STOPWORDS 리스트
STOPWORDS = ["#강아지"]
# final_tags 필터링
final_tags = []
for tag in filtered_tags:
# 제외할 키워드가 포함되었거나 STOPWORDS에 포함된 해시태그는 제외
if not any(keyword in tag for keyword in exclude_keywords) and tag not in STOPWORDS:
final_tags.append(tag)
tag_counts_selected = Counter(final_tags)
print(tag_counts_selected.most_common(50))[('#강아지하네스', 143), ('#강아지리드줄', 99), ('#강아지목줄', 82), ('#강아지옷', 50), ('#강아지겨울옷', 29), ('#강아지악세사리', 14), ('#강아지물티슈', 13), ('#강아지방석', 13), ('#강아지장난감', 12), ('#가죽하네스', 12), ('#반려동물용품', 10), ('#강아지매트', 10), ('#강아지하우스', 8), ('#펫티슈', 7), ('#강아지산책', 7), ('#반려용품', 7), ...# Visualization
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager, rc
font_name = 'malgun gothic'
rc('font', family=font_name)
#시각화에 필요한 데이터 추출
tag_counts_df=pd.DataFrame(tag_counts_selected.most_common(30))
tag_counts_df.columns=['tags', 'counts']
#시각화
plt.figure(figsize=(10, 8))
sns.barplot(x='counts', y='tags', data=tag_counts_df)
# 상위 5개 태그 출력
top_10_tags=tag_counts_selected.most_common(10)
print("상위 10개 태그:", top_10_tags)상위 10개 태그: [('#강아지하네스', 143), ('#강아지리드줄', 99), ('#강아지목줄', 82), ('#강아지옷', 50), ('#강아지겨울옷', 29), ('#강아지악세사리', 14), ('#강아지물티슈', 13), ('#강아지방석', 13), ('#강아지장난감', 12), ('#가죽하네스', 12)]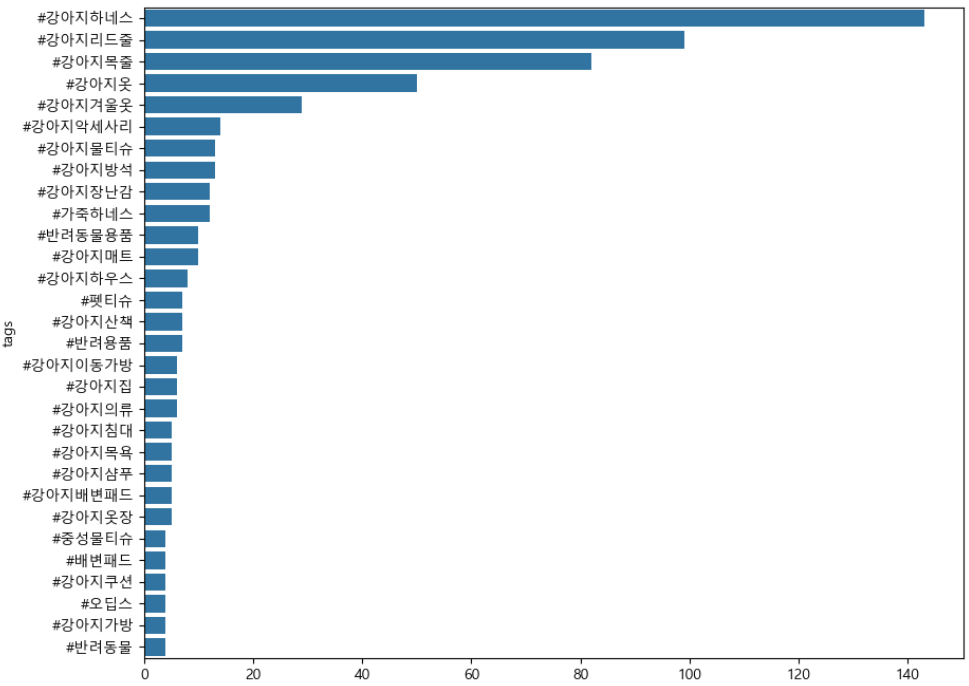
# # 제거한 이름 추출
top_10_tags_names = [tag[0][1:] for tag in top_10_tags]
tag_data = []
# 각 태그에 대해 5번씩 반복 / 순위 정하기
for i, tag in enumerate(top_10_tags_names, 1):
for _ in range(5): # 5번 반복
tag_data.append([f"TOP {i}", tag])
df_tags = pd.DataFrame(tag_data, columns=['Rank', 'Tag'])
# 엑셀로 저장
df_tags.to_excel("../data/instagram_top_10_naver_price.xlsx", index=False, engine='openpyxl')
print("상위 10개 해시태그 엑셀로 저장 완료")상위 10개 해시태그 엑셀로 저장 완료
이렇게 저장이 완료된 모습을 볼 수 있다.
이제 다음글에서는 네이버에서 각 태그들로 검색하여 나오는 상품들 5개 정도를 크롤링하는 부분으로 글을 마칠 예정이다.
