
저번 글에 이어 상위 10개의 태그들을 기준으로 네이버 쇼핑에서 검색하고 판매 많은순으로 정렬한 상위 5개의 상품들을 크롤링하여 마무리 하고자 한다.
1. 네이버 쇼핑 요소 값 탐색
먼저, 판매 많은순의 url은 다음과 같다.
"https://search.shopping.naver.com/ns/search?query={tag}&sort=PURCHASE"
이 {tag} 부분에 읽어온 엑셀파일의 tag 부분을 넣어 검색한다.
이후 역시나 요소 값을 찾아야 한다.
-
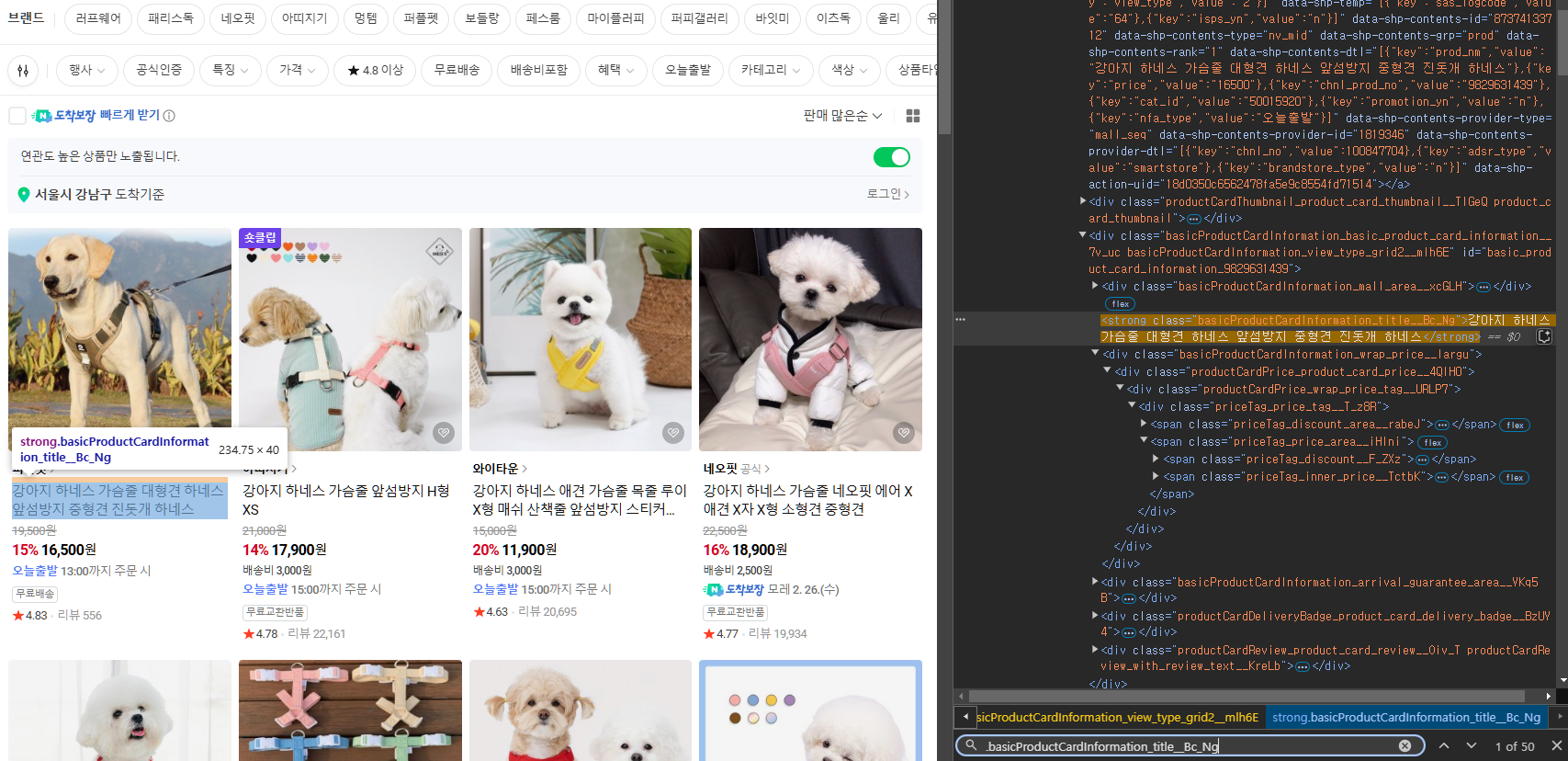
상품 리스트 요소
.basicProductCardInformation_title__Bc_Ng
-
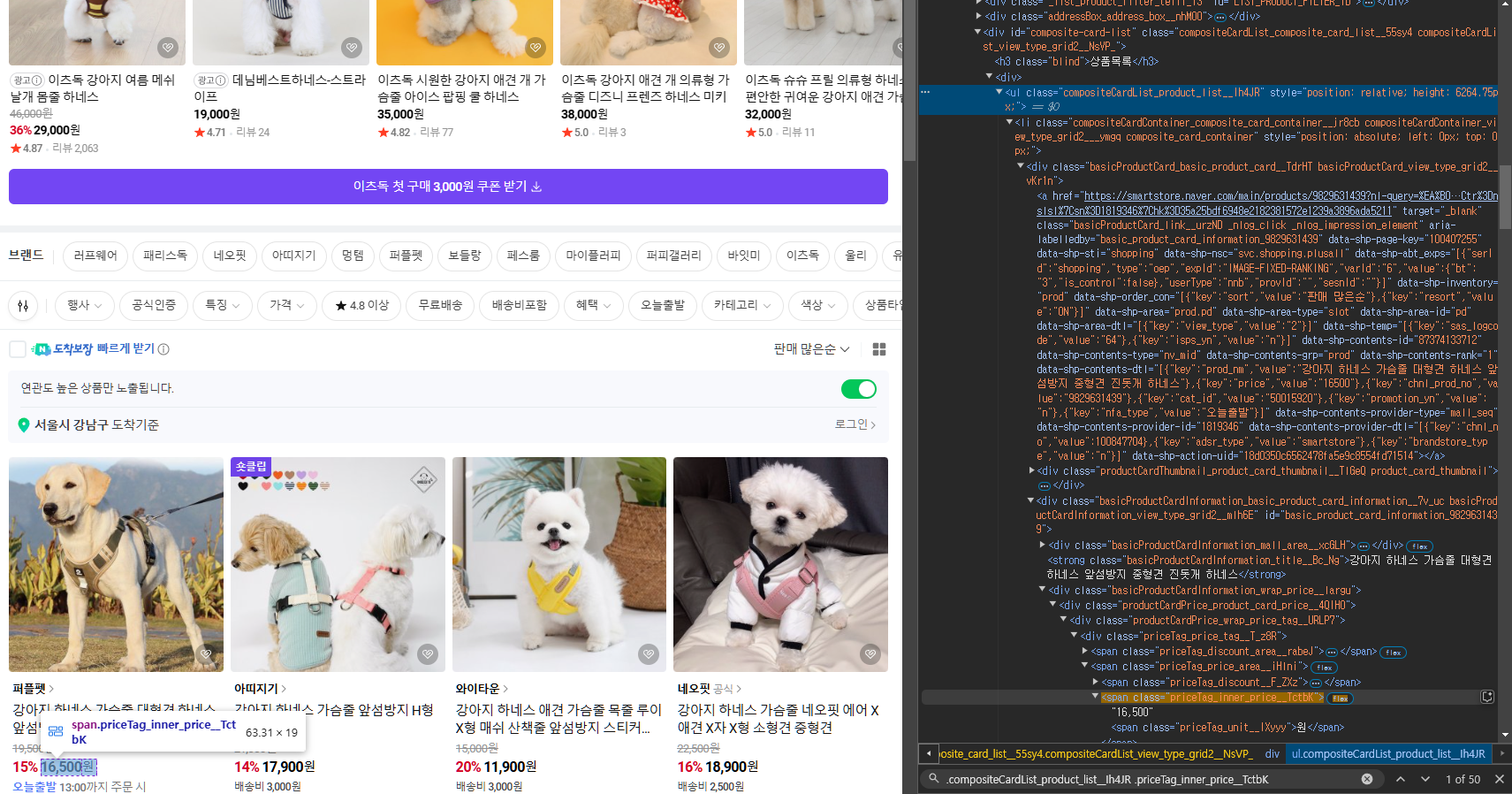
가격 요소
.compositeCardList_product_list__Ih4JR .priceTag_inner_price__TctbK
찾을 것은 이 둘 뿐이고 나머지는 그냥 크롤링만 하면 된다.
2. price_naver.ipynb
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
import pandas as pd
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
options = Options()
driver = webdriver.Chrome(options=options)
def get_naver_shopping_data(tag):
# Sorted by most sold
url = f"https://search.shopping.naver.com/ns/search?query={tag}&sort=PURCHASE"
driver.get(url)
# Wait for load the page
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, ".basicProductCardInformation_title__Bc_Ng")))
try:
products = []
# 모든 상품 리스트 요소
product_elements = driver.find_elements(By.CSS_SELECTOR, ".basicProductCardInformation_title__Bc_Ng")
# 가격 요소
price_elements = driver.find_elements(By.CSS_SELECTOR, ".compositeCardList_product_list__Ih4JR .priceTag_inner_price__TctbK")
# 첫 5개
for i in range(min(5, len(product_elements))):
try:
name = product_elements[i].text.strip()
price = price_elements[i].text.strip()
# tuple type
products.append((name, price))
except Exception as e:
print(f"Error while extracting product {i}: {e}")
return products
except Exception as e:
print(f"Error occurred while scraping: {e}")
return []
# Read excel file and save to DF(dataframe)
df=pd.read_excel("../data/instagram_top_10_naver_price.xlsx")
# Get tag uniquely
tags=df["Tag"].unique()
results = []
for tag in tags:
print(f"{tag} 크롤링 중 ...")
products = get_naver_shopping_data(tag)
# 해당 Tag에 해당하는 Rank 값 가져오기
tag_ranks = df[df['Tag'] == tag] # 'tag'와 일치하는 행들을 가져오고
if not tag_ranks.empty: # 만약 'tag'에 해당하는 데이터가 존재한다면
rank = tag_ranks['Rank'].iloc[0] # 첫 번째 Rank 값을 가져오기
else:
rank = 'N/A' # 데이터가 없으면 'N/A'로 처리
# In products,
# [0]: product name / [1]: product price
for product in products:
results.append([rank, tag, product[0], product[1]])
driver.quit()
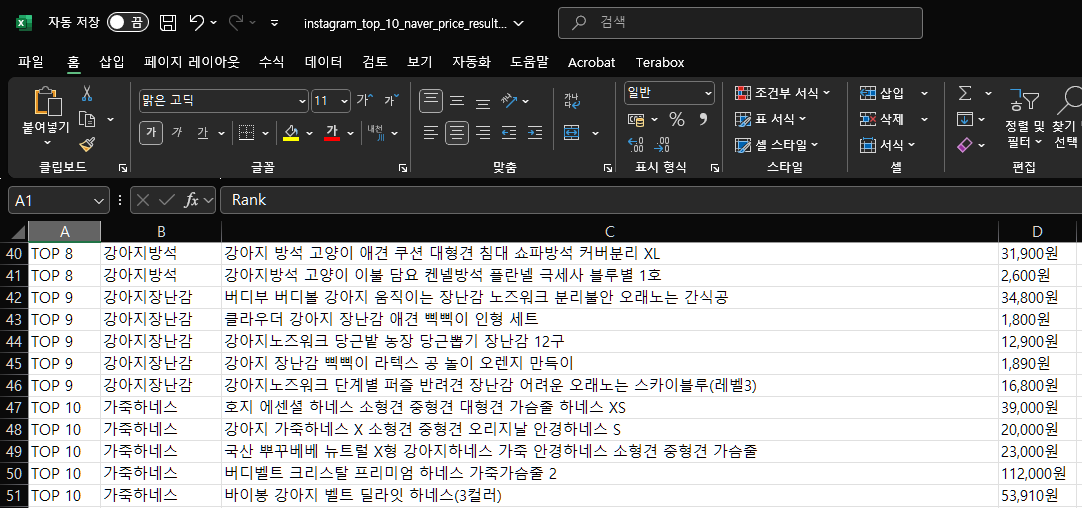
result_df=pd.DataFrame(results, columns=["Rank", "Tag", "Product", "Price"])
result_df.to_excel("../data/instagram_top_10_naver_price_result.xlsx", index=False)
print("크롤링 완료!")강아지하네스 크롤링 중 ...
강아지리드줄 크롤링 중 ...
강아지목줄 크롤링 중 ...
강아지옷 크롤링 중 ...
강아지겨울옷 크롤링 중 ...
강아지악세사리 크롤링 중 ...
강아지물티슈 크롤링 중 ...
강아지방석 크롤링 중 ...
강아지장난감 크롤링 중 ...
가죽하네스 크롤링 중 ...
크롤링 완료!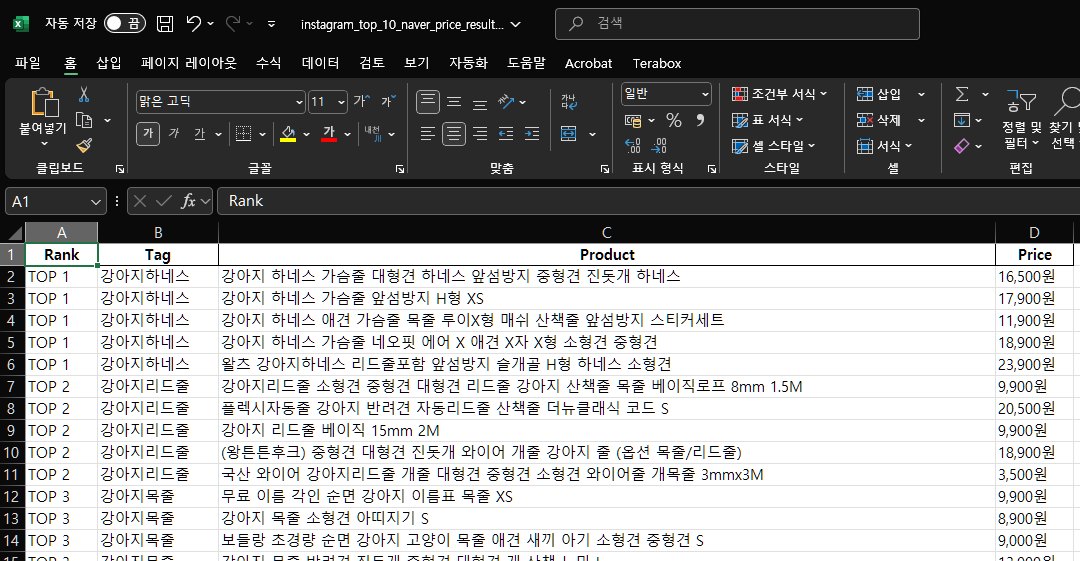
3. 결론
이렇게 간단하지만 굉-장히 삽질을 많이한.. 나름의 심화 크롤링을 마무리했다.
결과적으로 좀 후회가 많이 남는 부분은 한번에 너무 많은, 그리고 너무 짧은 시간에 반복해서 크롤링하는 실수로 한동안 차단을 당해 시간을 허비하기도 했던 부분이다.
인스타그램에서 크롤링을 진행하면서 해시태그를 여러번 바꿔서 진행했는데, 그만큼 광고글과 해시태그와는 별로 상관없는 게시물이 많이 나와서 버리게 되는 경우도 많았다. 많은 사람들이 사용하는 SNS 공간이기에 그만큼 더 수집범위를 넓히고 싶었는데, 차단이 되는 이유 때문에 크롤링하는 개수를 많이 늘리지 못해 아쉽다.
혹시 검토한 후 추가할 내용이 있다면 새로운 게시글에서! 🧐
