
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
Pandas의 마지막, 데이터 요약과 병합에 대한 부분이다.
1. 데이터 요약
데이터를 간결하고 유의미한 형태로 요약하고 변형하는 작업
집계, 그룹화, pivot
1.1. 집계 함수
이제 컬럼별로 집계함수를 보자.
- 1개 컬럼에 대한 집계함수(평균)
먼저 1개 컬럼에 대한 집계함수(평균)을 보자.
employee_df["age"].mean() # 39.24
# 여기서 만약 1개의 컬럼만 한다면, `employee_df.age.mean()`과 같이 표현도 가능
employee_df.age.mean() # 39.24- n개의 컬럼에 대한 집계함수(평균)
employee_df[["age", "height"]].mean()
# ✅ 출력 결과
# age 39.2400
# height 169.5692
# dtype: float64- 1개의 컬럼에 대한 n개의 집계함수
employee_df["age"].agg(["mean", "max", "median"])
# ✅ 출력 결과
# mean 39.24
# max 55.00
# median 39.00
# Name: age, dtype: float64여기서 agg()라는 함수를 볼 수 있는데, 이는 aggregation의 약자로 집합이라는 뜻으로 집계함수를 볼 때 사용한다.
- n개의 컬럼에 대한 n개의 집계함수
employee_df[["age","height"]].agg(["mean", "max", "median"])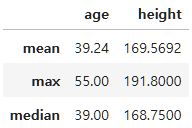
- n개의 컬럼에 대한 컬럼별 집계함수
마지막으로 n개의 컬럼에 대한 컬럼별 집계함수도 볼 수 있는데, 이는 사실describe()를 사용하는 것이 훨씬 좋다.
employee_df.agg({"age":"mean", "height":"max"})
# ✅ 출력 결과
# age 39.24
# height 191.80
# dtype: float641.2. ⭐ 그룹화
df.groupby("컬럼명1")["컬럼명2"].mean()
컬럼명1: 그룹화
컬럼명2: 그룹화된 각 그룹의 컬럼
mean(): 선택된 컬럼의 평균
# 1개의 컬럼에 대한 그룹화
dept=employee.groupby("dept")그럼 이제 묶였으니 묶인 애들로 집계함수를 사용하면,
dept["age"].mean()
# ✅ 출력 결과
# dept
# A 43.26
# B 38.83
# C 32.02
# Name: age, dtype: float64즉 부서별 나이의 평균이 나온다.
- index 변경(단일 컬럼)
먼저 단일 컬럼일때의 경우다.
dept["age"].mean().reset_index(name="dept_mean_age")- index 변경(n개의 컬럼)
n개의 컬럼의 index를 변경하려면 다음과 같다.
result=dept[["age", "salary"]].max().reset_index()
result.columns=["부서", "나이", "연봉"]
result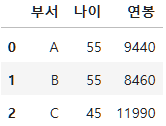
1.2.2. n개의 컬럼에 대한 그룹화
이번에는 회사별로 그룹화 후, 혈액형별로 그룹화해보자.
dept_blood=employee_df.groupby(["dept", "blood_type"])
dept_blood.size()
# ✅ 출력 결과
# dept blood_type
# A A 34
# AB 11
# B 22
# O 33
# B A 34
# AB 12
# B 21
# O 33
# C A 16
# AB 6
# B 11
# O 17
# dtype: int64# 그룹(부서,혈액형)의 나이, 연봉의 최대값
dept_blood[["age", "salary"]].max()
# 그룹(부서,혈액형)의 나이의 평균, 최소값, 중앙값
dept_blood[["age"]].agg(["mean","max","median"])
# 그룹(부서, 혈액형)의 나이와 키의 평균, 최대값, 최소값, 중앙값, 개수
dept_blood[["age", "height"]].agg(["mean","max","min","median","count"])
# 그룹(부서, 혈액형)의 나이의 평균, 키의 최대값, 연봉의 중앙값과 최대값
dept_blood.agg({"age":"mean", "height":"max", "salary":["median", "max"]})이렇게 각각 집계함수를 구할때는 딕셔너리 형태로 사용하며,
1개의 column에 2개 이상 agg를 적용하면 마지막 agg에 적용된다.
이렇게 groupby는 보통 범주형으로 묶어서 연속형을 집계함수로 처리한다.
1.3. pivot & pivot table
groupby는 원하는 형태로 행렬을 재구조화할 수는 없지만, 집계가 된다.
반대로 pivot은 원하는 형태의 행렬로 재구조화할 수 있지만, 집계가 안된다.
그리고 이 pivot처럼 재구조화가 가능하고, 집계까지 가능한 것이 pivot table이다.
1.3.1. pivot
DataFrame의 Column을 마음대로 바꿔서 새로운 테이블 형태로 변환
pivot의 형태는 다음과 같다.
DataFrame.pivot(index="", columns="", values="")
여기서 index에는 새 DataFrame에서 행으로 설정할 열을(index명) 지정하고
columns에는 새 DataFrame에서 열로 설정할 열(column명),
values에는 새 DataFrame에서 표시할 값을 지정한다.
우선 간단한 DataFrame을 만들어보자.
new_df=pd.DataFrame({"이름":["kim", "lee", "park", "jeong", "kim"],
"부서":["A", "B", "C", "A", "B"],
"연봉":[2800, 3000, 3500, 4000, 4500]})
new_df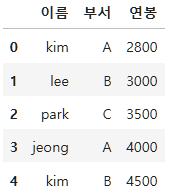
이를 pivot을 사용하여 재구조화 하면 다음과 같이 된다.
new_df_pivot=new_df.pivot(index="이름", columns="부서", values="연봉")
new_df_pivot.fillna(0).astype(int) # NaN -> 0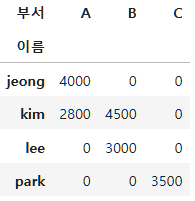
1.3.2. pivot_table
pivot_table의 형태는 다음과 같다.
DataFrame.pivot_table(index="", columns="", values="", aggfunc="", fill_value=)
여기서 index에는 새 DataFrame에서 행으로 설정할 열을(index명) 지정하고
columns에는 새 DataFrame에서 열로 설정할 열(column명),
values에는 새 DataFrame에서 표시할 값,
aggfunc에는 사용할 집계함수,
fill_value에는 결측값을 채워줄 값을 지정한다.
즉 이는 groupby() + pivot()이다.
new_df_pivot_table=new_df.pivot_table(index="이름", columns="부서", values="연봉", aggfunc="count", fill_value=0)
new_df_pivot_table
그렇다면 계속 이용했던 employee DataFrame을 pivot_table을 이용해 재구조화해보자.
employee_df.head()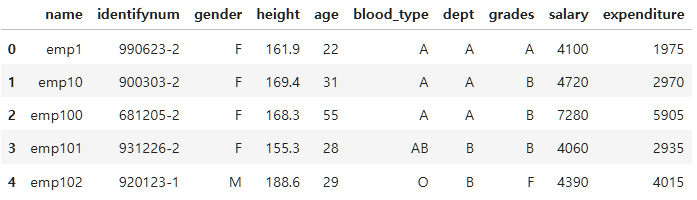
employee_df_pivot_table=employee_df.pivot_table(index="dept", columns="grades", values="salary", aggfunc="mean", fill_value=0)
employee_df_pivot_table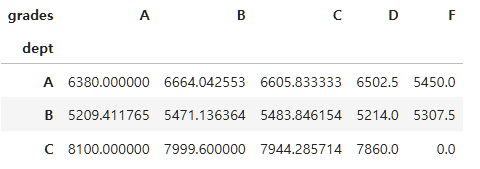
2. ⭐ 데이터 병합
- merge(): 두 개의 DataFrame을 특정 Column(index 또는 column)을 기준으로 결합
형식은 다음과 같다.
DataFrame.merge(left=df1, right=df2, left_on="병합 기준 컬럼명", right_on"병합 기준 컬럼명", how="join방법")
여기서 how="join 방법"에서 join이 병합한다는 뜻인데,
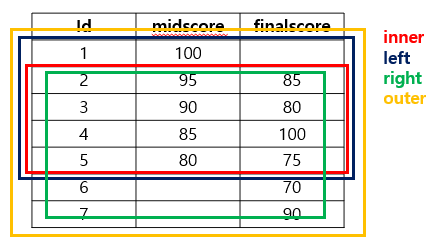
이 join을 하는 방법에는 inner, left, right, outer의 4가지가 있다.
midterm=pd.DataFrame([[1,100],
[2,95],
[3,90],
[4,85],
[5,80]],
columns=["id","midscore"])
midterm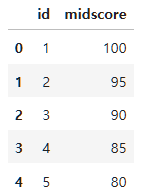
final=pd.DataFrame({"id":[2,3,4,5,6,7],
"finalscore":[85,80,100,75,70,90]})
final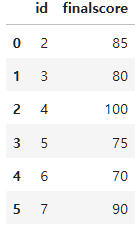
지금 보면 id라는 동일한 이름을 가지는 column이 있고, 이 column으로 합친다.
그래서 합치면 전체 구조는 id, midscore, finalscore 되는데,
df2에는 1이 없고, df1에는 6,7이 없다.
먼저 inner join부터 살펴보자.
inner join으로 지정하면 NaN 값을 모두 제거하고 100% 일치하는 값들만 가져온다.
result_inner=pd.merge(left=midterm, right=final, left_on="id", right_on="id", how="inner")
result_inner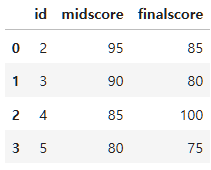
이번에는 left, right, outer 조인을 각각 해보면 다음과 같다.
- left join: 왼쪽 정보를 기준으로 결합
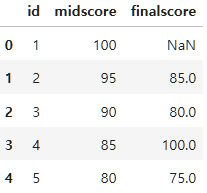
- right join: 오른쪽 정보를 기준으로 결합
result_right=pd.merge(left=midterm, right=final, left_on="id", right_on="id", how="right")
result_right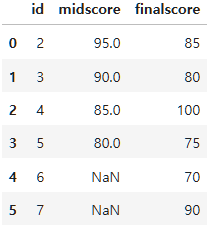
- outer join: 조인 조건에 일치하지 않는 데이터까지 모두 조회
result_outer=pd.merge(left=midterm, right=final, left_on="id", right_on="id", how="outer")
result_outer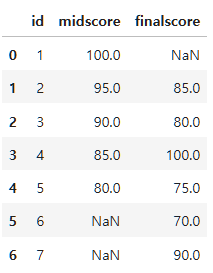
그리고 이들의 키워드를 지워줘도 괜찮다.
result_outer=pd.merge(midterm, final, on="id", how="outer")
result_outer
이렇게 left, right, outer 조인은 조건에 부합하지 않아도 모두 결합을 한다.
각각 왼쪽 데이터가 조건에 부합하지 않아도,
오른쪽 데이터가 조건에 부합하지 않아도,
양쪽 모두 조건에 부합하지 않아도 결합하는 것이다.
또한 만약 결합하는 기준이되는 컬럼을 제외하고 겹치는 이름이 있다면
df = pd.merge(left_df, right_df, on="id", suffixes=("_left", "_right"))
와 같이 suffixes를 붙여주면 된다.
만약 name이 겹친다면, name_left와 name_right와 같이 나온다.
즉 그림으로 보면 다음과 같다.
💪 코드 작성 퀴즈
Q1. age 컬럼의 mean, max, median을 구하기 위한 코드를 작성하시오.
employee_df=pd.read_csv("./employee.csv")A1. employee_df["age"].agg(["mean", "max", "median"])
Q2. 아래는 부서(dept)별 나이의 평균값을 구하기 위한 코드이다. 빈칸을 채우시오.
dept=employee_df____A____
dept["age"].mean()A2. .groupby("dept")
Q3. 아래 DataFrame을 변형할 때, index에는 이름, column에는 부서, 값으로는 연봉이 들어가는 코드를 작성하시오.
new_df=pd.DataFrame({"이름":["kim", "lee", "park", "jeong", "kim"],
"부서":["A", "B", "C", "A", "B"],
"연봉":[2800, 3000, 3500, 4000, 4500]})A3. new_df.pivot(index="이름", columns="부서", values="연봉")
Q4. 아래 DataFrame을 변형할 때, index에는 이름, column에는 부서, 값으로는 연봉의 "평균"이 들어가는 코드를 작성하시오.
(단, 이때 결측치는 0으로 채워라.)
new_df=pd.DataFrame({"이름":["kim", "lee", "park", "jeong", "kim"],
"부서":["A", "B", "C", "A", "B"],
"연봉":[2800, 3000, 3500, 4000, 4500]})A4. new_df.pivot_table(index="이름", columns="부서", values="연봉", aggfunc="mean", fill_value=0)
Q5. 아래 두 개의 DataFrame을 id를 기준으로 inner join하는 코드를 작성하시오.
midterm = pd.DataFrame([[1, 100],
[2, 95],
[3, 90],
[4, 85],
[5, 80]],
columns=["id", "midscore"])
final = pd.DataFrame({"id": [2, 3, 4, 5, 6, 7],
"finalscore": [85, 80, 100, 75, 70, 90]})A5. pd.merge(midterm, final, on="id", how="inner")
