
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
저번 Pandas 자료형과 DDA에 대한 글에 이어 이번에는 변형에 대한 부분이다.
1. 변형
데이터의 품질을 높이기 위해 불필요한 부분을 제거하거나 필요한 부분을 정리하는 과정
구조변경, 정렬, 필터링
1.1. 데이터 필터링 (추출)
indexing & slicing
iloc[row, column]: 위치 기반
loc[row, column]: 명칭 기반
boolean indexing: 조건 기반
query(): 조건 기반
1.1.1. row
- DataFrame 반환
employee_df[:2] # .head(2)
employee_df[248:] # .tail(2)
그런데 사실 이렇게 행만 가져오는 경우는 거의 없다.
1.1.2. column
- Series 또는 DataFrame 반환
1개의 열은 Series
employee_df["age"] # Series
# employee_df[["age"]] # 만약 DF로 가져오고 싶다면? 2개 이상의 열은 DataFrame
employee_df[["age", "identifynum"]].head()⭐ 중요!
row는 가능하지만, column을 이용해 행을 가져올때는 안되는 것이 있다.
바로 slicing인데, 열을 slicing을 하려면
iloc와loc를 사용해야한다.위 표의 첫번째 컬럼명들을 보면, age, identifynum이라고 있는데, 이들을 사실 위치(번지수)로 생각하면 각각 0번째, 1번째 이렇게 된다.
그리고 행으로 봤을때 index가 있는데, index에는 사실 이름을 붙일 수 있다.
하지만 데이터가 너무 많으면 이름을 다 달아줄 수 없기 때문에 보통 이름을 사용하지 않는다.그런데 이게 사실 위치(번지)를 나타내는 index이기도 하지만 동시에, index명(index 이름) 이 된다.
즉 0번지 행인 index의 이름은 0이 되는 것이다.이 개념을 알아야 iloc과 loc를 사용할 수 있다.
즉 iloc는 index기반(위치) location 이고,
loc는 명칭기반 location 이다.
1.1.3. iloc
- 위치 기반 인덱싱
employee_df.iloc[:, :3] # 모든 행, 열 0~2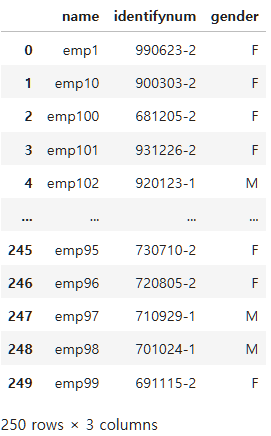
check_df1=employee_df.iloc[:3, :-1]
print(check_df1, type(check_df1)) name identifynum gender height age blood_type dept grades salary
0 emp1 990623-2 F 161.9 22 A A A 4100
1 emp10 900303-2 F 169.4 31 A A B 4720
2 emp100 681205-2 F 168.3 55 A A B 7280 <class 'pandas.core.frame.DataFrame'>check_df2=employee_df.iloc[:3, -1]
print(check_df2, type(check_df2))0 1975
1 2970
2 5905
Name: expenditure, dtype: int64 <class 'pandas.core.series.Series'>이를 보면 check_df1는 DataFrame이고, check_df2는 한 열만 가져오기 때문에 Series임을 알 수 있다.
또는 행열로 아래와 같이 가져올 수도 있다.
employee_df.iloc[[1,3,5,7,9], [0,2,4]]열을 기준으로 행을 다 가져오는 경우가 훨씬 많다는 것을 알아두자.
1.1.4. loc
명칭(이름) 기반
컬럼명, 인덱스명
⭐ 인덱스 [start,end]에서 end 까지 포함
여태까지 슬라이싱할때 [start:end] 라면 end 전 까지를 가져왔지만, loc는 end까지 포함한다.
그리고 row 부분에 다음과 같이 선언할때도 잘 보자.
employee_df.loc[:5, :]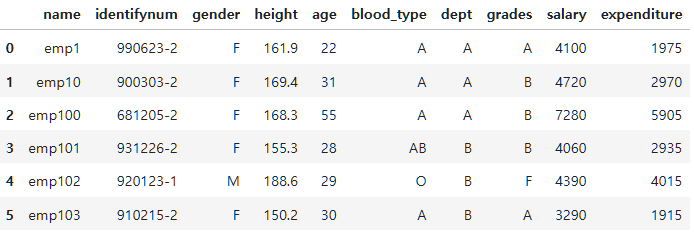
이때 인덱스의 이름이 0, 1, ... 이기때문에 위치라고 착각하지 말자.
employee_df.loc[[1,3,5], "gender":"blood_type"]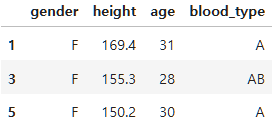
1.1.5. 조건기반 인덱싱(boolean indexing)
- 데이터 프레임의 조건식을 직접 사용하여 필터링
조건으로 age가 31인 사람을 주어 데이터프레임에서 찾아보면 다음과 같다.
employee_df["age"]==31근데 이는 T, F로 반환되며 이렇게 사용하는 경우는 없으니 위를 조건으로 주어 데이터프레임에서 필터링하는 것이다.
employee_df[employee_df["age"]==31]그리고 조건이 많을 때는 다음과 같이 하는데,
이런 형태가 가장 많이 사용하니 잘 보자.
print(employee_df.loc[(employee_df["age"]==30) & (employee_df["dept"]=="B"),:])그리고 보통 너무 길면 안에 다 안쓰고 조건(condition)을 따로 빼서 사용한다.
나이가 30이면서 B부서에 속한 사원이라는 조건(condition)을 하나 만들어보자.
cond=(employee_df["age"]==30) & (employee_df["dept"]=="B")
employee_df[cond]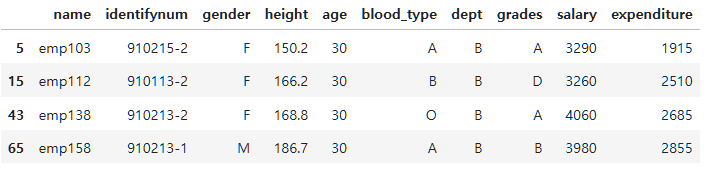
1.1.6. query()
조건에 맞는 데이터만 추출
문자열 표현식을 사용하여 필터링
SQL 스타일, 가독성 높음
위 boolean indexing과 비슷하지만 다르다.
우선 어떻게 쓰는지 보고 본인에게 맞는 것을 사용하면 된다.
employee_df.query("age >30").head()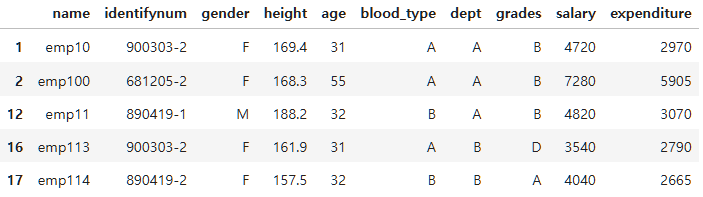
employee_df.query("age==30 & dept=='B'")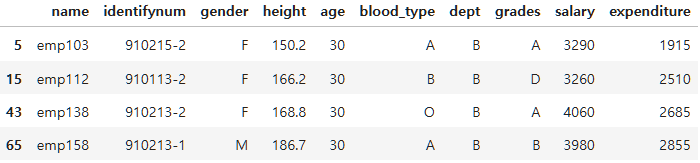
이렇게 df[]가 아닌 df.query()라는 형식으로 사용하는데, 위를 보면 조건식 자체에 쌍따옴표, 홀따옴표를 다 써야한다.
이런 경우에는 오히려 더 복잡해진다. 한 줄에 홀따옴표와 쌍따옴표가 반복되니까 이럴때는 차라리 boolean을 사용하는 것도 방법이다.
employee_df.query("age==30 & dept=='B'")["age"]5 30
15 30
43 30
65 30
Name: age, dtype: int64employee_df.query("age==30 & dept=='B'")[["name", "age"]]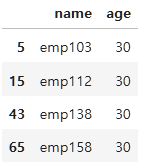
query()가 좋은 점은 이런 것이다.
1.2. 구조 변경
행은 추가 삭제할 필요가 없다.
열(Column) 생성, 수정, 삭제
행 & 열 단위별 결합
DB로 생각했을때, A테이블과 B테이블을 합칠때 join을 사용하는데,
우선 동일한 데이터프레임에서 짤라내서 결합하는 것을 할 예정이다.
A에서 데이터 가져오고, B에서 데이터 가져와서 합치는 경우가 있다.
이럴때 열을 기준으로 합친다. ex. 날짜
1.2.1. 추가
- 파생변수: 새로만든 컬럼
copy_employee_df["point"]=0이제 원하는 위치에 컬럼을 추가해보자.
age_plus10=copy_employee_df["age"]+10
copy_employee_df.insert(loc=copy_employee_df.columns.get_loc("age")+1,
column="age_plus_10",
value=age_plus10)이때 insert()의 내부를 보면 loc은 location, 어느 위치에다 저장할 것인지 column은 컬럼명을 지정해주는 것이다.
그리고 columns.get_loc("age")는 컬럼중에서 age의 위치를 가져오는 함수다.
그리고 거기 뒤에 삽입하려고 하기 때문에 +1을 붙여준다.
1.2.2. 수정
컬럼명을 변경해보자.
copy_employee_df.rename(columns={"gender":"sex"}, inplace=True)1.2.3. 삭제
삭제는 Columns 방향 삭제와 Row 방향 삭제가 있다.
그런데 사실 Row 방향 삭제는 결측치 제거를 제외하면(dropna()) 거의 안한다.
이런 삭제가 쓰이는 이유에 대해 조금 생각해보면,
예를들어 화이트와인인지 레드와인인지 맞춘다고 가정하자.
그러면 당도와 산미 등이 속성이 될 것이다.
그런데 모든 데이터프레임의 구조는 컬럼 맨 끝에는
y라는 예측결과를 나타내는 컬럼이 존재한다.
어찌됐든 이제 컬럼들중에 분명 쓸모없는 것들이 있을 것이다. 그러면 필요한 것들만 iloc이나 loc을 이용해서 골라내보니 5개 정도의 컬럼만 남았다고 하자.
그러면 y까지 총 6개의 컬럼일 것이다.
이렇게 전체를 다 골라내서 c1~c5까지 5개의 컬럼들이 있고 예측부분인 y가 있을 텐데,
이 y값은 c1~c5까지의 컬럼들을 가져와서 알고리즘을 통해서 y를 구하게 된다.
그런데 이렇게 iloc을 사용해서 iloc[c1:c5] 을 가져오기도 하지만,
반대로 그냥 y 하나를 날리고 사용하는 경우도 있다.
그래서 이런 삭제 부분도 배워야 한다.
- Column 방향 삭제
이제 그러면 먼저 Column 방향으로 삭제해보자.
copy_employee_df.drop(columns="point", axis=1, inplace=True)
copy_employee_df.drop(columns=["age", "salary", "expenditure"],
axis=1,
inplace=True) # 슬라이싱 안됨- Row 방향 삭제
이번에는 Row 방향으로 삭제해보자.
copy_employee_df.drop(index=0, axis=0, inplace=True)
copy_employee_df.drop(index=[1,2,3], axis=0, inplace=True)1.2.4. 행과 열 단위별 결합
동일한 table을 결합.
서로다른 table을 결합하는 것은 다음 글에서 merge()함수와 관련해서 다룰 예정이다.
합칠때는 .concat()함수를 사용하며, axis에 할당해주는 값으로 행단위인지, 열단위인지로 나뉜다.
- 행단위 결합
employee_df_up=employee_df.iloc[:5, :]
employee_df_down=employee_df.iloc[-5:, :]
employee_df_row_concat=pd.concat([employee_df_up, employee_df_down], axis=0)- 열단위 결합
employee_df_left=employee_df.loc[:5, :"age"]
employee_df_right=employee_df.loc[:5, "salary":]
employee_df_columns_concat=pd.concat([employee_df_left, employee_df_right], axis=1)1.3. 정렬
파이썬에서 제공하는 정렬을 사용해도 되지만, pandas에서 제공하는 정렬을 사용하면 for문도 안돌려도 되기 때문에 편리하다.
1.3.1. 단일 컬럼
먼저 사용할 DataFrame의 구조를 살표보자.
원본 데이터에는 영향을 주지 않는다.
# 나이순 오름차순
employee_df.sort_values(by="age")
# 혈액형 내림차순
sort_blood_type=employee_df.sort_values("blood_type", ascending=False)1.3.2. 다수(n개) 컬럼
2개 이상의 n개의 다수 컬럼을 정렬도 가능하다.
먼저, 혈액형과 나이를 오름차순으로 정렬해보자.
sort_blood_type_age=employee_df.sort_values(["blood_type", "age"])먼저 혈액형으로 정렬한 다음, 나이로 다시 정렬한다.
반대로 내림차순 정렬은 ascending=False를 붙여주면 된다.
혈액형은 내림차순, 나이는 오름차순으로 정렬해보자.
sort_desc_asc=employee_df.sort_values(["blood_type", "age"], ascending=[False, True])먼저 혈액형을 내림차순으로 먼저 정렬한 다음, 나이를 오름차순으로 정렬한다.
1.4. 값 변경 및 등급화
replace()
apply()
map(): map(함수명, 데이터집합)
lambda: 함수명=lambda input:output
지금까지는 전체 틀을 변경하는 과정이었는데, 지금부터는 값을 변경하는 경우가 있다.
예를들어, 나이를 가져왔는데, 20살부터 55살까지의 데이터가 있다.
그런데 이 나이를 등급화 할 수 있다면? 20대, 30대, 이런식으로.
그러면 이제 20대는 평균적으로 얼마를 받더라. 이런 식으로 할 수 있다.
그러면 이제 저 값들을 가져와서 등급화를 해줘야한다.
또 변경은 어떤 때 많이 사용하냐면, csv파일을 가져왔는데, 남자는 1, 여자는 2 이런식으로 써져있는 경우가 있다.
근데 보통 이런 데이터를 dtype을 찍어보면 int형을 사용하는 경우가 많다.
그러면 1과 2를 뽑아서 작업해도 되긴하는데, 이걸 분석해서 고객사에게 전달해야하는데,
개발자의 입장에서는 1과 2가 뭔지 알지만, 다른 사람은 무슨 뜻인지 모를 수 있다.
위에서 한 rename()은 컬럼명을 바꿔준 것이고, replace()는 그 안에 있는 내용을 바꿔주는 것이다.
1.4.1. replace()
값 변경을 할거니까 copy를 하고 값 변경을 진행하는데, 먼저 치환.
df=employee_df.copy()
df["gender"]=df["gender"].replace("F", "Female")"F"가 아닌 "Female"을 사용해야 한다.
n개의 값을 변경할때는 딕셔너리 형태를 사용한다.
df["gender"]=df["gender"].replace({"Female":"여자", "M":"남자"})1.4.2. ⭐ apply(lambda input:output)
파이썬에서 제공하는 lambda를 그대로 가져왔는데 앞에 apply가 붙는 모습이다.
apply(lambda input:output)
이와 같은 형태인데, 특정 컬럼명에 해당하는 데이터를 input으로 넣어주고, input을 output으로 보내 결과를 출력한다.
df["name_length"]=df["name"].apply(lambda x:len(x))이렇게 x에는 name이 넘어오고, len(x)로 출력한 내용을 새로운열인 name_length에 할당한 것이다.
만약 이게 아니었다면 for문을 계속해서 돌렸어야 했을 것이다.
이렇게 한번쓰고 버릴 수 있어 간편하다.
이번에는 identifynum의 문자열에서 0~5번지까지 문자를 추출해보자.
df["identifynum"].apply(lambda x: x[0:6])그렇다면 주민등록번호 앞 6자리를 8자리로 만들어보자.
"19"라는 문자열과 x[0:6]의 6자리를 결합하여 새로운 문자열을 만들면 된다.
df["identifynum"]=df["identifynum"].apply(lambda x: '19' + x[0:6])이번에는 등급화를 해볼 것인데 이 apply(lambda)를 사용해볼 것이다.
그런데 10대, 20대, 이렇게 조건을 걸어줘야하는 부분이 너무 많기 때문에 따로 빼주고,
lambda에서 input은 그대로고, output 부분에서 함수를 호출하면 된다.
def agediv(x):
if x<=20: return "10대"
elif x<=30: return "20대"
elif x<=30: return "30대"
elif x<=30: return "40대"
else: return "50대 이상"
df["age_div"]=df["age"].apply(lambda x: agediv(x))이게 없으면 age를 for문으로 돌려줘서 다 짜줘야 했다.
이렇게 함수만 따로 하나 정의해놓으면 apply(lambda)를 이용해서 for문을 돌리지 않고도 간단하게 해결 가능하다.
1.4.3. np.where()
np.where(조건, True, False)
np.where(조건1, True, np.where(조건2, True, False))
이번에는 numpy에서 제공하는 np.where이다.
이는 사실 if와 else와 같다.
age_div2=np.where(df["age"]<=30, "청년", "중년")
df.insert(loc=df.columns.get_loc("age")+1,
column="age_div2",
value=age_div2)df["age_div2"]=np.where(df["age"]<20, "초년",
np.where(df["age"]<=50, "중년", "노년")np.where(조건1, True, np.where(조건2, True, False)) 를 이용하면 이와 같이 np.where안에 np.where를 다룰 수도 있지만 이건 너무 복잡하다.
이럴때는 차라리 lambda를 사용해서 따로 함수로 꺼내는 것이 낫다.
2. 정리
결국은 표형태의 테이블에서 반복처리를 하면서 원하는 조건을 줘서 원하는 데이터를 추출하거나 바꿔줘야한다.
파이썬에서는 for와 if를 쓰지만 판다스는 그렇게 안해도 된다는 것이다.
이걸 판다스에서는 크게 두가지로 보면 된다.
- 조건을 줘서 원하는 데이터를 추출하는 boolean과, query.
- 원하는 데이터를 추출해서 그 공간에 새로운 내용을 추가하는 등의 테이블의 변화.
💪 혼합형 퀴즈
Q1. city 컬럼을 기준으로 내림차순으로 정렬하는 코드를 작성하시오.
df = pd.DataFrame({
"name": ["A", "B", "C", "D"],
"city": ['Seoul', 'Seongnam', 'Suwon', 'Yongin']
})A1. df.sort_values("city", ascending=False)
Q2. .query() 함수를 이용해 age가 20 이상인 사람들의 이름을 구하는 코드를 작성하시오.
df = pd.DataFrame({
"name": ["A", "B", "C", "D"],
"age": [19, 20, 21, 22]
})A2. df.query("age >= 20")['name']
Q3. age 컬럼의 값을 2배로 증가시키는 코드를 작성하시오.
df = pd.DataFrame({
"name": ["A", "B", "C", "D"],
"age": [19, 20, 21, 22]
})A3. df["age"]=df["age"]*2
Q4. 코드의 실행 결과로 옳은 것은?
employee_df[employee_df["age"] == 31] 1) age가 31인 행들만 출력한다.
2) age에 해당하는 데이터를 모두 31로 바꾼다.
3) age에 31이라는 새로운 데이터를 삽입한다.
4) 에러 발생
A4. 1
Q5. iloc와 loc의 차이를 설명하시오.
A5. iloc은 위치 인덱스를 사용하고, loc은 인덱스명을 사용한다.
Q5. "gender" 컬럼을 "sex"로 변경하기 위한 빈칸을 채워라.
copy_employee_df.____A____(columns={"gender": "sex"}, inplace=True)A5. A: rename
Q6. query() 함수의 결과로 옳은 것은?
employee_df.query("age == 30 & dept == 'B'")1) age가 30이고 dept가 B인 모든 행을 출력한다.
2) age와 dept열을 각각 30과 B로 전부 바꾼다.
3) age와 dept열에 각각 30과 B를 추가한다.
4) 에러 발생
A6. 1
Q7. age와 salary 컬럼을 삭제하기 위한 코드로, 빈칸을 채우시오.
copy_employee_df.drop(____A____, axis=____B____, inplace=True)A7. A: columns=["age", "salary"] / B: 1
