
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
1. 시계열 분석 (Time Sereis Analysis)
전통 시계열은 통계가 들어간다.
X 값이 많으면 잘 나오지 않는다.
알고리즘에는 AR, MA, ARIMA, SARIMA, ARIMAX, SARIMAX 등이 있다.
머신러닝 시계열은 랜덤포레스트는 잘 되는데, 선형회귀는 잘 안맞는다.
또 딥러닝 시계열이라는 것이 있다.
딥러닝은 인공신경망, 딥러닝, CNN, RNN, LSTM 등이 있다.
순차적으로 발생하는 사건들을 분석하는 것을 시계열 분석이라고 한다.
이런 순차적 데이터는 순서대로 발생되는 사건의 관찰 값 또는 측정 값을 말하며
등 간격이 있는 것과 없는 것으로 나뉜다.
등 간격이 없는 것은 자연어, Morse code, DNA 등을 예로 들 수 있으며,
등 간격이 있는 것이 시계열 데이터로 주식이나 기온과 같은 부분을 예로 들 수 있다.
이런 시계열 데이터의 구성 요소에는
전반적인 흐름을 말하는 추세변동(Trend),
시작 시점에서 내려가고 다시 올라가는 주기를 말하는 순환변동(Cycle),
Cycle에 계절적인 요인이 있는 것을 말하는 계절변동(Seasonal variations),
그리고 이 주기 변동은 Cycle이 크고, 계절 변동은 Cycle이 작다.
그리고 이 들이 섞여서 Trend와 Cycle이 같이 있는 Trend with seasonal pattern,
우연적으로 랜덤하게 패턴이 증가하거나 감소하는 우연변동(Random fluctuation) 등이 있다.
이 우연변동에서 백색잡음(White Noise) 이라는 것이 있는데, 이는 평균이 0이고 분산이 일정한 시게열 데이터를 말한다.
이렇게 우연변동은 트렌드를 가지고 있으면 예측이 안되기 때문에 트렌드를 제거하는 "차분"이라는 것을 한다.
차분을 통해 정상성을 확보해야한다.
이제 코드를 보며 각각 확인해보자.
# 기본적인 부분
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from scipy import stats1.1. No Trend Model
월별 물고기 어획량
fish_df=pd.DataFrame({
"Month": ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"],
"Year1": [362, 381, 317, 297, 399, 402, 375, 349, 386, 328, 389, 343],
"Year2": [276, 334, 394, 334, 384, 314, 344, 337, 345, 362, 314, 365]
})
fish_df.head()| Month | Year1 | Year2 | |
|---|---|---|---|
| 0 | January | 362 | 276 |
| 1 | February | 381 | 334 |
| 2 | March | 317 | 394 |
| 3 | April | 297 | 334 |
| 4 | May | 399 | 384 |
두 년도의 데이터들을 가지고 다음 년도를 예측하는 것이다.
따라서 이는 X가 Month가 되며, Y는 Year1과 Year2가 묶여서 하나가 된다.
year1=fish_df["Year1"]
year2=fish_df["Year2"]
fish=pd.concat([year1, year2], ignore_index=True)
fish, type(fish), type(fish.index), type(fish.values)(0 362
1 381
2 317
3 297
4 399
5 402
6 375
7 349
8 386
9 328
10 389
11 343
12 276
13 334
14 394
15 334
16 384
17 314
18 344
19 337
20 345
21 362
22 314
23 365
dtype: int64,
pandas.core.series.Series,
pandas.core.indexes.range.RangeIndex,
numpy.ndarray)이 fish.index는 RangeIndex라는 범위의 타입이다.
그래서 이 값중 index값을 가져오려면 list로 담아줘야한다.
list(fish.index)[0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23]그리고 이제 X값에 담아줘야 하는데
X값은 항상 2차원으로.
데이터프레임이나, 배열과 같이 들어가야한다.
X=np.array(list(fish.index))
Y=fish.values
X[:5], Y[:5](array([0, 1, 2, 3, 4]), array([362, 381, 317, 297, 399]))sns.scatterplot(x=X, y=Y)
plt.grid(True)
plt.show()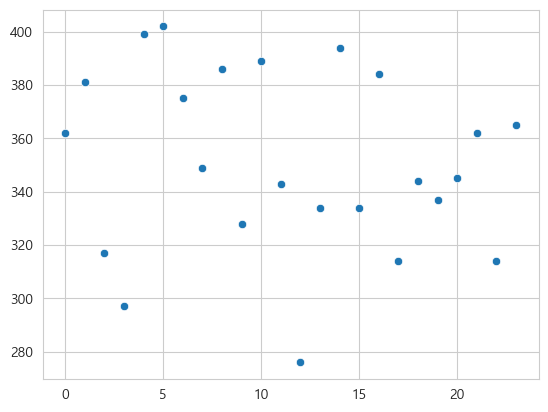
1.1.1. 통계적 확인
coef, intercept=np.polyfit(X, Y, 1) # 1차 회귀
print(f"기울기: {coef}, 절편: {intercept}")기울기: -0.8578260869565264, 절편: 361.1566666666668기울기가 0에 가까우면 일정한 방향으로 증가하거나 감소하지 않는다.
즉 이는 트렌드(Trend)가 없다.
이렇게 트렌드가 없을때는 예측은 평균값으로 낸다.
1.1.2. 예측
print(fish.mean())351.2916666666667이렇게 다음년도 1월의 어획량을 예측하게된다.
분산과 표준편차는
print(f"분산: {fish.var()}, 표준편차: {fish.std()}")분산: 1144.1286231884058, 표준편차: 33.8249704092761261.2. Trend Model
1.2.1. Linear Trend Model
이번에는 선형 트렌드를 가지는 데이터를 보자.
시간을 기준으로 25번째는 몇개가 팔릴지를 예측해보자.
calc=pd.DataFrame({
"Time": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24],
"Sales": [197, 211, 203, 247, 239, 269, 308, 262, 258, 256, 261, 288, 296, 276, 305, 308, 356, 393, 363, 386, 443, 308, 358, 384]
})
print(calc.head(), "\n", calc.tail()) Time Sales
0 1 197
1 2 211
2 3 203
3 4 247
4 5 239
Time Sales
19 20 386
20 21 443
21 22 308
22 23 358
23 24 384sns.lmplot(data=calc, x="Time", y="Sales")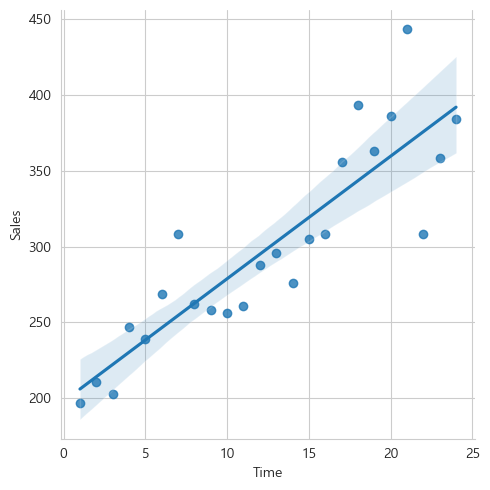
1.2.1.1. 통계적 확인
X=calc["Time"]
Y=calc["Sales"]coef, intercept=np.polyfit(X, Y, 1) # 1차 회귀
print(f"기울기: {coef}, 절편: {intercept}")기울기: 8.074347826086951, 절편: 198.02898550724632이렇게 기울기가 0이 아니기 때문에 1차식이라고 생각할 수 있다.
1.2.1.2. 선형회귀 모델 학습 및 평가
데이터가 얼마 없기 때문에 훈련과 테스트로 따로 나누지는 않는다.
X=calc[["Time"]] # 2차원
lr=LinearRegression()
lr.fit(X,Y)
print("평가: ", lr.score(X, Y))
print(f"기울기: {lr.coef_}, 절편: {lr.intercept_}")평가: 0.7726052795315081
기울기: [8.07434783], 절편: 198.02898550724638그러면 이제 25번째를 예측해보면,
new_df=pd.DataFrame({"Time": [25]}) # X값 2차원
sales_pred=lr.predict(new_df)
sales_predarray([399.88768116])1.2.2. 비선형 모델
이번에는 비선형의 경우다.
시간을 기준으로 25번째는 몇개의 대출요청이 있을지를 예측해보자.
loan=pd.DataFrame({
"Time_squared": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24],
"Loan_request": [297, 249, 340, 406, 464, 481, 549, 553, 556, 642, 670, 712, 808, 809, 867, 855, 965, 921, 956, 990, 1019, 1021, 1033, 1127]
})
print(loan.head(2), "\n", loan.tail(2)) Time_squared Loan_request
0 1 297
1 2 249
Time_squared Loan_request
22 23 1033
23 24 1127sns.scatterplot(data=loan, x="Time_squared", y="Loan_request")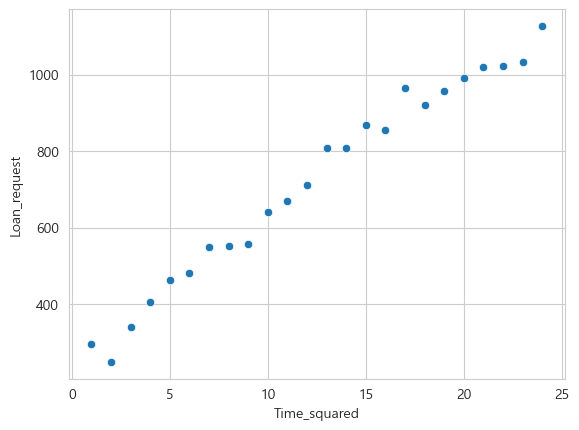
곡선의 형태를 보인다.
따라서 Polynomial을 사용한다.
1.2.2.1. 학습 및 예측
X=loan[["Time_squared"]]
Y=loan["Loan_request"]poly=PolynomialFeatures(degree=2) # 2차
X_poly=poly.fit_transform(X)lr=LinearRegression()
lr.fit(X_poly, Y)
print("평가: ", lr.score(X_poly, Y))
print(f"기울기: {lr.coef_}, 절편: {lr.intercept_}")평가: 0.9870821298214472
기울기: [ 0. 50.93662207 -0.56772575], 절편: 199.61956521739216new_df=pd.DataFrame({"Time_squared": [25]}) # X값 2차원
new_df_poly=poly.transform(new_df)
sales_pred=lr.predict(new_df_poly)
sales_predarray([1118.20652174])1.3. 자기상관 (AutoCorrelation)
선형회귀는 서로 독립적이어야 하며,
그리고 오차가 정규 분포를 따라야하고, 오차의 분산이 일정해야 한다.
그런데 이는 독립적일 수 없다.
지금까지는 서로 다른 열 사이의 상관성을 봤는데,
이는 하나의 열을 가지고 행 단위로 진행한다.
하나의 열에서 앞에 값들로 다음 값을 예측하는 것이다.
따라서 행단위기 때문에 독립적일 수 없다.
이렇게 자기상관은 과거의 값들이 현재 값에 영향을 미친다는 의미이다.
이전 시점의 값들이 현재 시점의 값고 일정한 관계를 갖는 경우를 말한다.
시각화는 Postivite Autocorrelation과 Negative Autocorrelation가 있으며,
각각 사진으로보면 다음과 같다.
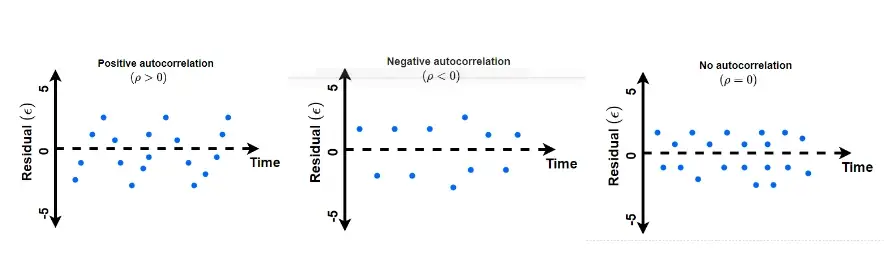
출처: https://www.reneshbedre.com/blog/durbin-watson-test.html
이렇게 ++++----와 같이 나오는 것이 Positive, +-+-+-와 같이 번갈아가며 반복되는 것이 Negative다.
이 +와 -가 랜덤으로 나온다면, 이는 No(Random) Autocorrelation으로 이는 자기상관이 없다.
from statsmodels.tsa.stattools import acf
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.stats.diagnostic import acorr_ljungboxcalc=pd.DataFrame({
"Time":[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24],
"Sales":[197, 211, 203, 247, 239, 269, 308, 262, 258, 256, 261, 288, 296, 276, 305, 308, 356, 393, 363, 386, 443, 308, 358, 384]
})calc_Y=calc["Sales"].valuesplot_acf(calc_Y, lags=20)
plt.show()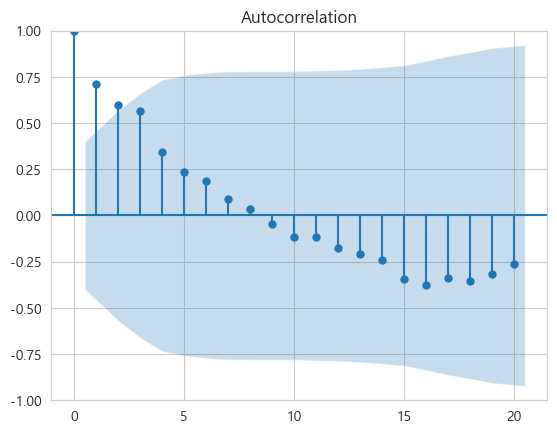
0시점은 24번째다. 자기는 상관관계가 무조건 1이다.
그리고 자신을 기준으로 멀어질수록 상관관계가 떨어진다.
검정을 해보면,
귀무가설: 자기상관 없다.
대립가설: 자기상관 있다.
box=acorr_ljungbox(calc_Y, lags=20, return_df=True)
box| lb_stat | lb_pvalue | |
|---|---|---|
| 1 | 13.680257 | 2.167209e-04 |
| 2 | 23.787714 | 6.832246e-06 |
| 3 | 33.369119 | 2.691999e-07 |
| 4 | 37.083038 | 1.731725e-07 |
| 5 | 38.922108 | 2.462126e-07 |
| 6 | 40.143530 | 4.268664e-07 |
| 7 | 40.429328 | 1.041670e-06 |
| 8 | 40.479569 | 2.607599e-06 |
| 9 | 40.559763 | 6.014276e-06 |
| 10 | 41.168221 | 1.053601e-05 |
| 11 | 41.841809 | 1.725069e-05 |
| 12 | 43.449886 | 1.894260e-05 |
| 13 | 45.920191 | 1.468214e-05 |
| 14 | 49.524337 | 7.333776e-06 |
| 15 | 57.741884 | 6.138847e-07 |
| 16 | 68.639415 | 1.725248e-08 |
| 17 | 78.699646 | 6.521121e-10 |
| 18 | 91.894368 | 6.588012e-12 |
| 19 | 104.286296 | 8.902799e-14 |
| 20 | 115.113838 | 2.273678e-15 |
pvalue < 0.05 이므로 자기상관이 있다.
이렇게 자기상관이 있을 경우에는 독립적이지 않기때문에 선형이나 다항회귀가 불가능하고,
RandomForest나 이후에 배울 ARIMA와 같은 알고리즘을 사용해야한다.
