
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
해당 글은 혼자 공부하는 머신러닝+딥러닝 책의 실습 내용의 일부를 담고 있습니다.
0. 비지도학습(Unsupervised Learning)
비지도학습은 정답이 없이 데이터를 학습하여 그 속의 패턴 또는 각 데이터 간의 유사도를 학습한다.
그 종류에는 크게 군집분석(Clustering)과 차원축소(Dimensionality Reduction), 연관분석(Association Analysis) 등이 있다.
1. 군집화(Clustering)
데이터 포인트들을 비슷한 특성을 가진 그룹으로 나누는 방법
K-Means, 계층적 클러스터링, DBSCAN(밀도 기반 클러스터링 -> 이상치)
1.1. K-평균 군집화(K-Means Clustering)
K-Means 군집화는 각 데이터와 중심점의 거리를 측정한 후 가까운 그룹에 할당하여 K개의 군집으로 묶는 방법이다.
순서는 다음과 같다.
1. 군집 개수(K) 설정
2. 초기 중심점(Centroid) 랜덤으로 설정
3. 데이터를 가까운 군집에 할당
4. 데이터 평균으로 중심점 재설정
(3번과 4번을 반복하며 중심점 위치가 변화가 없으면 종료)
그리고 묶은 군집들을 label이라고 하여 각각 0, 1, 2와 같이 이름을 붙여준다.
이는 코드를 보며 이해해보자.
이제 필요한 라이브러리를 import해주고,
# 기본적인 부분
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_scoredata를 만들어보자.
data=np.array([[1, 2],
[1, 4],
[1, 0],
[4, 2],
[4, 4],
[4, 0],
[10, 2],
[10, 4],
[10, 0]])
dataarray([[ 1, 2],
[ 1, 4],
[ 1, 0],
[ 4, 2],
[ 4, 4],
[ 4, 0],
[10, 2],
[10, 4],
[10, 0]])📌 참고로 데이터가 작으면 경고가 나타난다.
OS위에 주피터랩, 크롬, 등이 켜져있다.
이렇게 여러개의 프로그램이 돌아가는 것을 멀티태스킹이라고 하고,
하나의 소프트웨어 안에 여러가지가 돌아가는 것은 스레드라고 한다.
게임에 영상, 음악, 채팅 등을 동시에 진행한다.그리고 이들에는 다들 스케쥴링이 있다.
동시에 느껴지지만 반갈아가며 실행한다.
하지만 동시에 돌아갈 수 있게끔 KMeans에서 스레드를 많이 만들어놨다.스레드를 많이 만들어놨는데 데이터를 조금만 넣었기 때문에 경고가 나온 것이다.
경고 없이 쓰려면 라이브러리 import 해주면 된다.
import warnings
warnings.filterwarnings("ignore")이제 생성한 data를 학습시키자.
kmeans=KMeans(n_clusters=3, random_state=42)
kmeans.fit(data)
그러면 이제 학습을 시켰으니 나눠졌을 것이고, 각각 묶인 군집의 레이블을 보자.
labels=kmeans.labels_
print(labels)[2 2 2 0 0 0 1 1 1] 이러면 각각 컴퓨터가 레이블을 뭐로 잡았는지 알 수 있다.
어떻게 묶였는지 보면 다음과 같다.
print(f"0번 label: \n{data[kmeans.labels_ == 0]}")
print(f"1번 label: \n{data[kmeans.labels_ == 1]}")
print(f"2번 label: \n{data[kmeans.labels_ == 2]}")0번 label:
[[4 2]
[4 4]
[4 0]]
1번 label:
[[10 2]
[10 4]
[10 0]]
2번 label:
[[1 2]
[1 4]
[1 0]]그러면 군집들의 중심 좌표를 확인해보자.
centers=kmeans.cluster_centers_
print(centers)[[ 4. 2.]
[10. 2.]
[ 1. 2.]] 이들을 중심점으로 잡은 것이다.
이제 새로운 데이터를 넣어서 군집을 예측해보면
new_data=np.array([[3,2]])
labels=kmeans.predict(new_data)
labelsarray([0], dtype=int32)이렇게 예측된 군집 번호를 반환해준다.
잘 예측한 것을 알 수 있다.
지금은 이렇게 간단하게 확인해봤는데, 그러면 이미지를 어떻게 처리하는지 알아보자.
1.1.1. 과일 분류
사과, 바나나, 파인애플
fruits=np.load("./data/fruits_300.npy")
fruits.shape(300, 100, 100)이렇게 3차원임을 알 수 있는데,
이는 개수, 너비, 높이인데
이미지 하나가 행이 100개, 열이 100개 인데, 이게 300개가 있는 거다.
그래서 이미지 하나를 찍어보면 다음과 같다.
plt.figure(figsize=(3,3))
plt.imshow(fruits[0]) # image show
plt.show()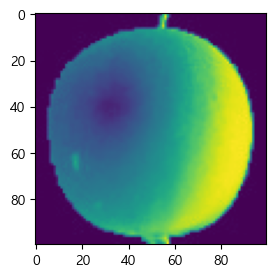
이런 100x100의 이미지가 300개가 있는 것이다.
색상이 보기 힘들다면 imshow에 cmap을 지정해주면 된다.
plt.imshow(fruits[0], cmap="gray")
그러면 이번에는 첫번째 이미지의 -> 첫번째 행의(이미지의 가장 위) -> 픽셀값(열)을 보자.
(이미지는 0~255의 값을 가진다.)
fruits[0,0,:]array([ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 2, 1, 2, 2, 2, 2, 2, 2, 1, 1,
1, 1, 1, 1, 1, 1, 2, 3, 2, 1, 2, 1, 1,
1, 1, 2, 1, 3, 2, 1, 3, 1, 4, 1, 2, 5,
5, 5, 19, 148, 192, 117, 28, 1, 1, 2, 1, 4, 1,
1, 3, 1, 1, 1, 1, 1, 2, 2, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1], dtype=uint8)이런게 한 이미지당 100행이 있는 것이다.
그러면 이번에는 0번째, 100번째, 200번째 이미지를 보면 다음과 같다.
fig, axs=plt.subplots(nrows=1, ncols=3) # 1행 3열
axs[0].imshow(fruits[0], cmap="gray_r") # _r 빼면 색 반전
axs[1].imshow(fruits[100], cmap="gray_r")
axs[2].imshow(fruits[200], cmap="gray_r")
plt.show()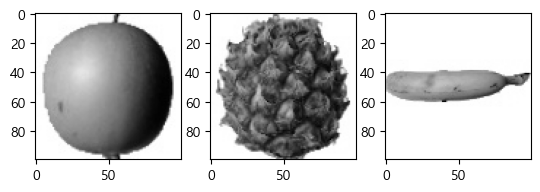
그런데 100x100이 300개가 있는데 이를 차원을 바꿔서 집어넣어야 한다.
즉 학습을 위해서 (300, 100, 100)의 3차원을 2차원으로 바꿔야하고, 각 이미지의 가로세로를 1차원 배열로 바꿔야한다.
fruits_2d=fruits.reshape(-1, 100*100)
fruits_2d.shape(300, 10000)kmeans=KMeans(n_clusters=3, random_state=42)
kmeans.fit(fruits_2d)
max_iter default로 300이 잡혀있다.
300번의 수행 후 제일 좋은 걸 골라줬다.
이렇게 군집 3개를 만들었다.
어떻게 만들었는지 label과 몇개들이 담겼는지 확인하자.
print(np.unique(kmeans.labels_, return_counts=True))(array([0, 1, 2], dtype=int32), array([112, 98, 90]))그러면 이제 각각 어떤 애들이 들어있는지 확인해보기 위해
0일때를 확인해보자.
len(fruits[kmeans.labels_==0])1120으로 분류된 112개를 찍어볼 것인데 112개를 10개의 열로 나누어 찍어보자.
def draw_fruits(arr, col_num=10): # 총 112개인데, 컬럼을 10개에 맞춰서 찍어주자
row_num=int(np.ceil(len(arr) / col_num)) # 필요한 행개수 계산 (ceil로 소수점 올리고 int형으로)
print(row_num)draw_fruits(fruits[kmeans.labels_==0]) # 0으로 분류된 과일을 전달12이렇게 12행을 찍을 수 있다.
def draw_fruits(arr, col_num=10):
row_num=int(np.ceil(len(arr) / col_num))
fig, axes=plt.subplots(nrows=row_num, ncols=col_num, figsize=(col_num, row_num)) # 12행 10열
print(axes)draw_fruits(fruits[kmeans.labels_==0])
axes를 그려보니 이렇게 나오는 것을 볼 수 있다.
그러면 fig에 그림을 각각 할당하며 그림을 보여야하는데,
행과 열을 for문을 돌면서 그리려면 for문을 두번 써야하는데,
for i in:
for j in:
axes[i][j]이를 flat을 이용하면 1차원으로 펼쳐서 찍기 편해진다.
즉 다음과 같다.
axes[0, 0] axes[0, 1] axes[0, 2] ... axes[0, 9]
axes[1, 0] axes[1, 1] axes[1, 2] ... axes[1, 9]
axes[2, 0] axes[2, 1] axes[2, 2] ... axes[2, 9]
...
axes[11, 0] axes[11, 1] axes[11, 2] ... axes[11, 9]
이를 아래와 같이 만드는 것이다.
axes.flat[0] axes.flat[1] axes.flat[2] ... axes.flat[119]
이렇게 되면 axes.flat[0]은 axes[0, 0]이고, axes.flat[1]은 axes[0, 1], axes.flat[2]은 axes[0, 2]와 같이 행을 기준으로 접근된다.
다음 행으로 넘어갈 때는 계속해서 다음 인덱스를 사용하여 접근하게 된다.
이렇게 하면 끝까지 다 찍기 때문에 없는 부분은 비워주자.
def draw_fruits(arr, col_num=10):
row_num=int(np.ceil(len(arr) / col_num))
fig, axes=plt.subplots(nrows=row_num, ncols=col_num, figsize=(col_num, row_num))
for i, ax in enumerate(axes.flat):
if i < len(arr):
ax.imshow(arr[i], cmap="gray")
ax.axis("off")
else:
ax.axis("off")
plt.show()draw_fruits(fruits[kmeans.labels_==0])
100퍼센트 분류는 아니지만 잘 분류했다.
label 0은 주로 파인애플들이 묶인 것이다.
그러면 label이 1인 애들을 보면,
draw_fruits(fruits[kmeans.labels_==1])
이는 거의 100퍼센트로 분류했다.
2인 경우는
draw_fruits(fruits[kmeans.labels_==2])
사과도 잘 분류했다.
그러면 이제 더 이상 둘 사이 평균으로 중심을 잡지 않은 마지막 중심은 뭐로 잡았을지 보자.
kmeans.cluster_centers_array([[1. , 1. , 1. , ..., 1. , 1. ,
1. ],
[1.10204082, 1.07142857, 1.10204082, ..., 1. , 1. ,
1. ],
[1.01111111, 1.01111111, 1.01111111, ..., 1. , 1. ,
1. ]], shape=(3, 10000))-1, 100*100
을 찍을때는 다시 자기형태로 바꿔서 보내줘야한다.
draw_fruits(kmeans.cluster_centers_.reshape(-1, 100, 100))
그러면 몇번째에 중심점이 더 나뉘지 않았는지를 보면,
kmeans.n_iter_44번까지 한 것을 알 수 있다.
1.1.2. 최적의 k 값
지금 한 것들을 보면 어찌됐든 KNN과 비슷하게 거리를 기준으로 했다.
그리고 군집을 k개로 나눴었는데, 이 군집의 개수를 정할때 마냥 많다고 할때 어떻고 적으면 어떨지 모르는데,
이 최적의 군집 개수 K를 결정하는 방법이 있다.
이는 엘보우 기법이라는 것을 사용한다.
이 엘보우 기법은 WCSS라는 값과 군집의 개수를 두고 비교한 그래프를 통해 최적의 K값을 선택하는 기법이다.
클러스터의 중심과 클러스터 내 데이터 사이의 거리가 있고, 이 거리의 제곱합, 즉 오차를 intertia라고 한다.
군집의 수가 늘어나면 클러스터 내 데이터들은 더 잘 맞춰지게 되어, 이너셔는 점차 줄어든다.
엘보우 방법은 클러스터 개수를 늘려가면서 이너셔의 변화를 관찰하여 최적의 클러스터 개수를 찾는 방법이다.
군집 수가 일정 이상으로 커지면 이너셔의 감소 속도가 급격히 완만해지는,
즉 군집의 수를 늘리는 것보다 이너셔 감소가 덜해지기 시작하는 지점이 존재하는데, 이 지점이 바로 엘보우 모양을 형성하는 지점이다.
그리고 그 지점이 바로 최적의 K 값이다.
inertia=[]
for k in range(2, 7):
km=KMeans(n_clusters=k, random_state=42)
km.fit(fruits_2d)
inertia.append(km.inertia_) # 거리의 제곱합(오차) 집어넣기
plt.plot(range(2, 7), inertia)
plt.xlabel("K")
plt.ylabel("INERTIA")
plt.show()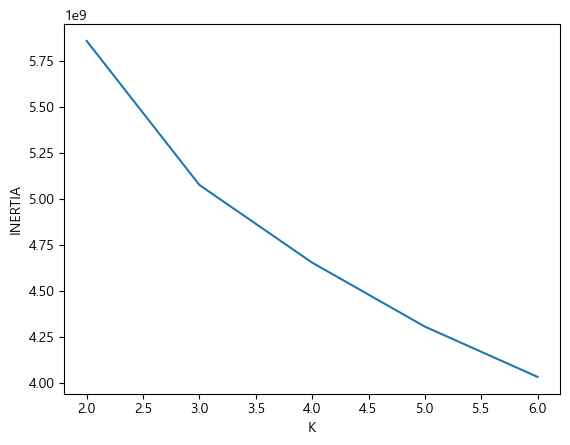
최적의 k는 3이다.
1.1.3. 평가지표
이제 군집의 평가를 해야하는데,
실루엣 계수라는 것을 이용한다.
자기 군집 안에서의 평균거리와 가까운 군집과의 평균거리를 낸다.
그래서 군집 내의 응집도가 높고, 군집간 분리도가 높아야 좋다.
-1에서 1사이의 값이며, 1에 가까울 수록 군집화가 잘 된 것이다.
from sklearn.metrics import silhouette_scoremy_silhouette=[]
for k in range(2,7):
kmen=KMeans(n_clusters=k, random_state=42) # k개의 군집들의 경우들
kmen.fit(fruits_2d)
labels=kmen.predict(fruits_2d)
score=silhouette_score(fruits_2d, labels) # 지도학습의 score와 비슷
my_silhouette.append(score)
print(f"K={k}, 실루엣 계수:{score:.3f}")K=2, 실루엣 계수:0.393
K=3, 실루엣 계수:0.242
K=4, 실루엣 계수:0.210
K=5, 실루엣 계수:0.223
K=6, 실루엣 계수:0.2060부터 1사이의 값으로 1이 나오면 가장 좋다.
지표로서 좋은 점수는 안나왔다.
1.1.4. 예측
kmeans.predict(fruits_2d[[100]])array([0], dtype=int32)그러면 이제 100과 각 클러스터 중심 간의 거리
kmeans.transform(fruits_2d[[100]])array([[3400.24197319, 8837.37750892, 5279.33763699]])draw_fruits(fruits_2d[[100]].reshape(-1,100,100))
지금은 predict할때, 데이터를 지도학습처럼 훈련, 테스트를 나누지 않고 다 넣는데,
나중에는 나눈다.
비지도에서도 이렇게 할 수 있고, 또는 아예 나눠서 가져오는 경우가 있다.
1.2. 계층적 군집화
계층적 군집분석은 각 데이터를 유사한 군집으로 묶어가며 진행하는 방법으로, 응집형과 분리형이 있다.
먼저 응집형은 하나의 데이터를 하나의 군집으로 보고 가까운 군집끼리 병합해 나가는 방식으로,
즉 자신과 가장 가까이 있는 군집들이 하나 씩 묶여가며 계층을 이루는 것이다.
데이터간 거리 측정 방식은
수치형 데이터의 경우는 유클리디안, 맨하탄 등이 있었고,
범주형 데이터의 경우는 자카드 유사도와 코사인 유사도가 있다.
그리고 군집간 거리 측정 방식에은 다음과 같다.
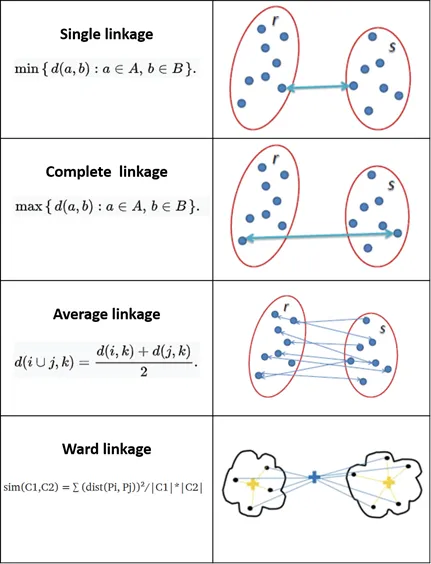
응집형과 반대로 분리형은 전체 데이터를 하나의 군집으로 보고 분할해 나가는 방식이다.
그렇다면 이제 코드로 보자.
from sklearn.preprocessing import StandardScaler
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.cluster import AgglomerativeClusteringdata=pd.read_csv("./data/person.csv")
data.shape(250, 10)data.columnsIndex(['name', 'jumin7', 'gender', 'height', 'age', 'blood_type', 'company',
'grades', 'salary', 'expenditure'],
dtype='object')
person=data[["gender","age","company","grades","salary","expenditure"]]
person.head()| gender | age | company | grades | salary | expenditure | |
|---|---|---|---|---|---|---|
| 0 | F | 22 | A | A | 4100 | 1975 |
| 1 | F | 31 | A | B | 4720 | 2970 |
| 2 | F | 55 | A | B | 7280 | 5905 |
| 3 | F | 28 | B | B | 4060 | 2935 |
| 4 | M | 29 | B | F | 4390 | 4015 |
배열의 2차원형태로 보내거나 Dataframe으로 보내야한다.
person_scaler=person[["age","salary","expenditure"]]
scaler=StandardScaler()
scaler=scaler.fit(person_scaler)person_number=pd.DataFrame(scaler.transform(person_scaler), columns=["age_scaled","salary_scaled","expenditure_scaled"])
person_number.head()| age_scaled | salary_scaled | expenditure_scaled | |
|---|---|---|---|
| 0 | -1.996162 | -1.222845 | -1.613278 |
| 1 | -0.954082 | -0.887000 | -1.077579 |
| 2 | 1.824798 | 0.499716 | 0.502599 |
| 3 | -1.301442 | -1.244513 | -1.096422 |
| 4 | -1.185655 | -1.065756 | -0.514960 |
이제 숫자형의 정규화를 마쳤으면, 범주형의 원핫인코딩을 진행하자.
이때 get_dummies를 이용하자.
person_dummy=pd.get_dummies(person[["gender","company","grades"]])
person_dummy.head()| gender_F | gender_M | company_A | company_B | company_C | grades_A | grades_B | grades_C | grades_D | grades_F | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | True | False | True | False | False | True | False | False | False | False |
| 1 | True | False | True | False | False | False | True | False | False | False |
| 2 | True | False | True | False | False | False | True | False | False | False |
| 3 | True | False | False | True | False | False | True | False | False | False |
| 4 | False | True | False | True | False | False | False | False | False | True |
이제 이 둘을 합쳐주자.
person_table=pd.concat([person_number, person_dummy], axis=1)
person_table.head()| age_scaled | salary_scaled | expenditure_scaled | gender_F | gender_M | company_A | company_B | company_C | grades_A | grades_B | grades_C | grades_D | grades_F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.996162 | -1.222845 | -1.613278 | True | False | True | False | False | True | False | False | False | False |
| 1 | -0.954082 | -0.887000 | -1.077579 | True | False | True | False | False | False | True | False | False | False |
| 2 | 1.824798 | 0.499716 | 0.502599 | True | False | True | False | False | False | True | False | False | False |
| 3 | -1.301442 | -1.244513 | -1.096422 | True | False | False | True | False | False | True | False | False | False |
| 4 | -1.185655 | -1.065756 | -0.514960 | False | True | False | True | False | False | False | False | False | True |
1.2.1. 모델 및 학습
군집들이 묶여가는데 크게 3개의 덩어리로 묶겠다.
clu=AgglomerativeClustering(n_clusters=3, linkage="ward") # n_clusters:최종적으로 형성할 군집의 개수, ward: 최소
clu.fit(person_table)
clu.labels_array([2, 1, 0, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1,
1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 2, 0, 1, 0, 1, 1, 0, 0, 0, 2,
2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2,
2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 2, 1, 1, 1, 1, 0, 1, 1, 1, 2,
2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 2, 1, 2, 2, 1, 2, 1, 1, 1, 1, 1, 2,
1, 2, 1, 1, 0, 0, 0, 0, 2, 2, 2, 2, 2, 1, 2, 2, 0, 0, 2, 0, 0, 2,
0, 0, 1, 0, 0, 0, 2, 2, 2, 2, 2, 2, 2, 1, 2, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 1, 0, 1, 0, 0, 1, 2, 0, 0,
0, 0, 0, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 2, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 2, 1, 1, 1, 1, 1, 1, 2, 1, 1,
1, 0, 0, 0, 0, 0, 0, 0])각각의 군집들을 그룹으로 묶었다.
즉 0번째 행은 2번그룹, 1번째 행은 1번그룹과 같이 묶인 것이다.
1.2.2. 시각화
덴드로그램
이제 시각화해보자.
fig, ax=plt.subplots(figsize=(20,10))
linked=linkage(person_table.sample(60, random_state=42), "ward")
dendrogram(linked)
ax.tick_params(axis="x", labelsize=20)
plt.show()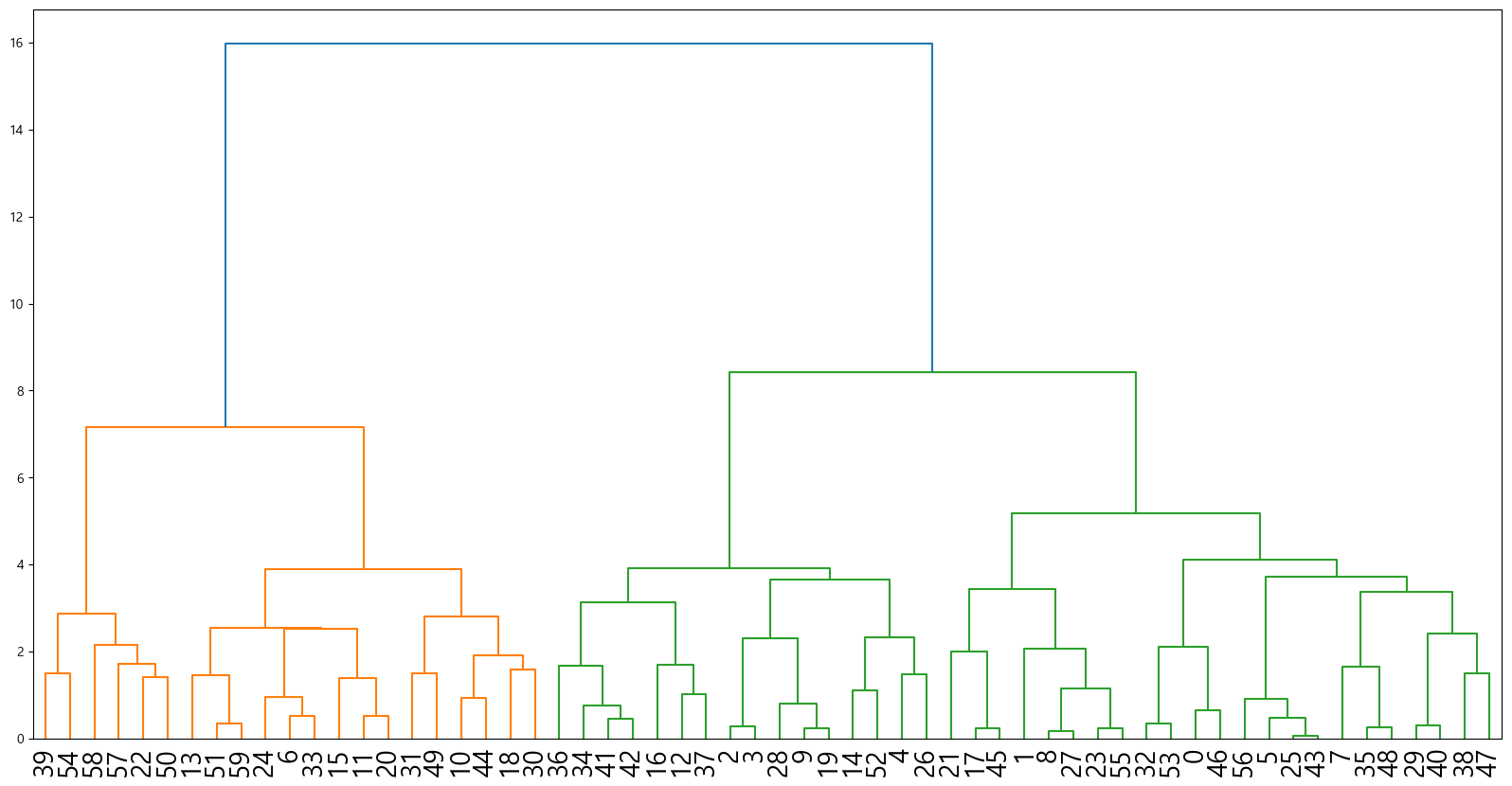
scatterplot
앞선 clu.labels_ 가 Y값이기 때문에 scatter로 보자.
person_table["cluster_hier"]=clu.labels_
person_table["cluster_hier"]=person_table["cluster_hier"].map({0:"A",1:"B",2:"C"})
person_table.head()| age_scaled | salary_scaled | expenditure_scaled | gender_F | gender_M | company_A | company_B | company_C | grades_A | grades_B | grades_C | grades_D | grades_F | cluster_hier | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.996162 | -1.222845 | -1.613278 | True | False | True | False | False | True | False | False | False | False | C |
| 1 | -0.954082 | -0.887000 | -1.077579 | True | False | True | False | False | False | True | False | False | False | B |
| 2 | 1.824798 | 0.499716 | 0.502599 | True | False | True | False | False | False | True | False | False | False | A |
| 3 | -1.301442 | -1.244513 | -1.096422 | True | False | False | True | False | False | True | False | False | False | C |
| 4 | -1.185655 | -1.065756 | -0.514960 | False | True | False | True | False | False | False | False | False | True | C |
# 원래 데이터 scatter (회사별 나이와 연봉)
fig, ax=plt.subplots(nrows=1, ncols=2, figsize=(14,5))
sns.scatterplot(data=person, x="age", y="salary", hue="company", ax=ax[0])
ax[0].set_title("원래 데이터", fontsize=14)
# 이번에는 회사가 아닌 군집화 한 것으로 찍어보면,
sns.scatterplot(data=person_table, x="age_scaled", y="salary_scaled", hue="cluster_hier", ax=ax[1])
ax[1].set_title("계층적 시각화")
plt.show()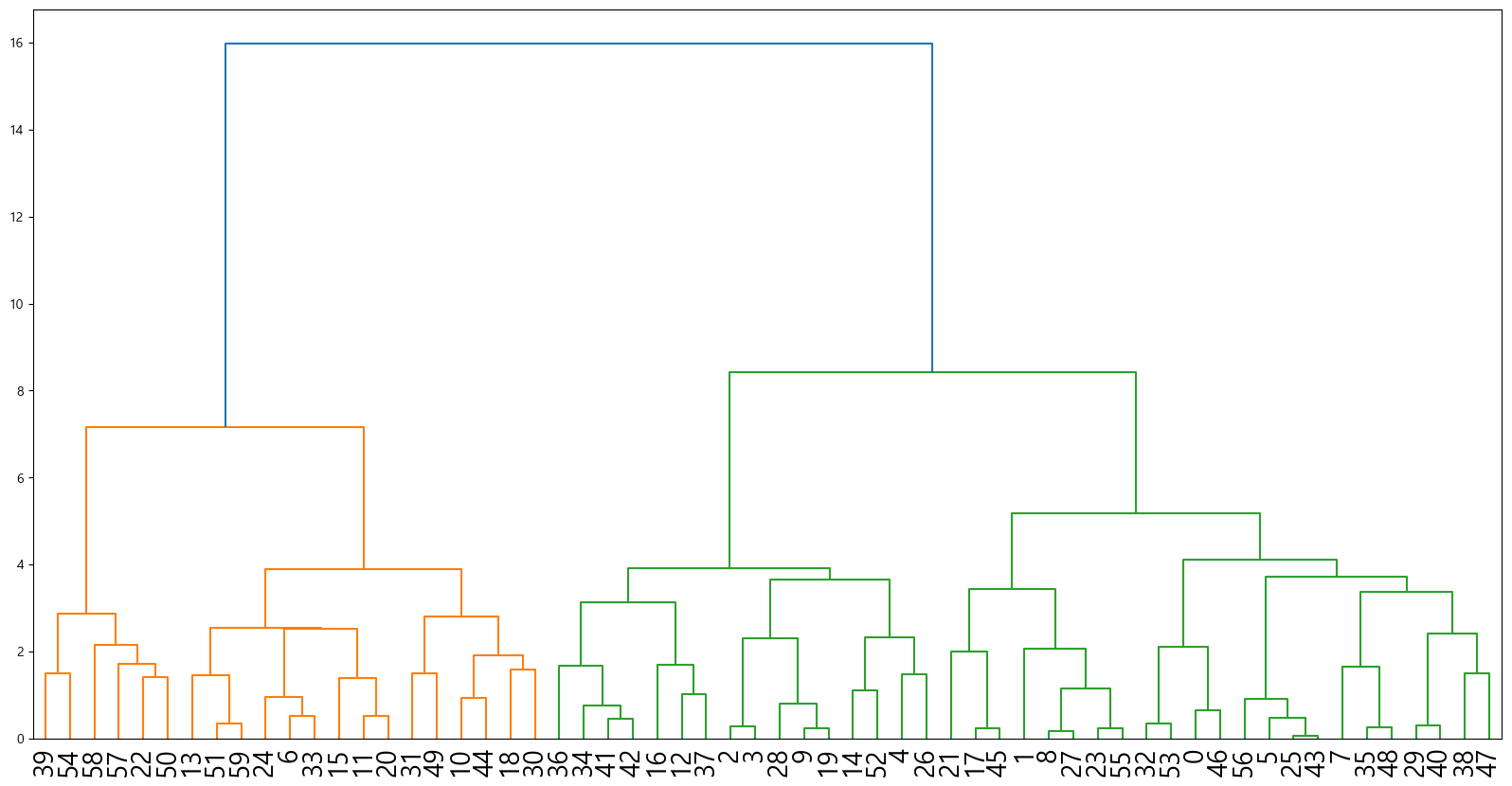
이를 보니 비슷한 형태를 보인다.
그러면 군집화가 어느정도 잘 이루어진 것이다.
지도학습과 다르게 Y값이 없어서 당황스럽지만 결국은 군집을 해서 Y값을 만들어 내는 것이다.
그 군집 하는 방법에 KMeans와 계층적이 있고, 밀도 기반까지가 있는 것이다.
KMeans는 덩어리
계층적은 X값이 많을떄,
밀도 기반은 이상치 탐지할때 많이 사용한다.
1.3. DBSCAN
데이터의 밀도를 기반으로 서로 가까운 데이터를 군집으로 묶는 방법
노이즈와 이상치 탐지
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons사이킷런의 반달 모양 데이터를 이용해서 진행한다.
이 값은 Y값이 정해져있다.
즉 지도학습 분류문제로 이용하기 좋은데, 이를 DBSCAN으로 사용해보자.
X, Y=make_moons(n_samples=300, noise=0.05, random_state=42)
X.shape, Y.shape((300, 2), (300,))moons_df=pd.DataFrame(X, columns=["X1","X2"])
moons_df["Y"]=Y
moons_df.head()| X1 | X2 | Y | |
|---|---|---|---|
| 0 | 0.622519 | -0.372101 | 1 |
| 1 | 1.904269 | -0.136303 | 1 |
| 2 | -0.069431 | 0.456117 | 1 |
| 3 | 0.933899 | 0.237483 | 0 |
| 4 | 1.180360 | -0.490847 | 1 |
sns.scatterplot(data=moons_df, x="X1", y="X2", hue="Y")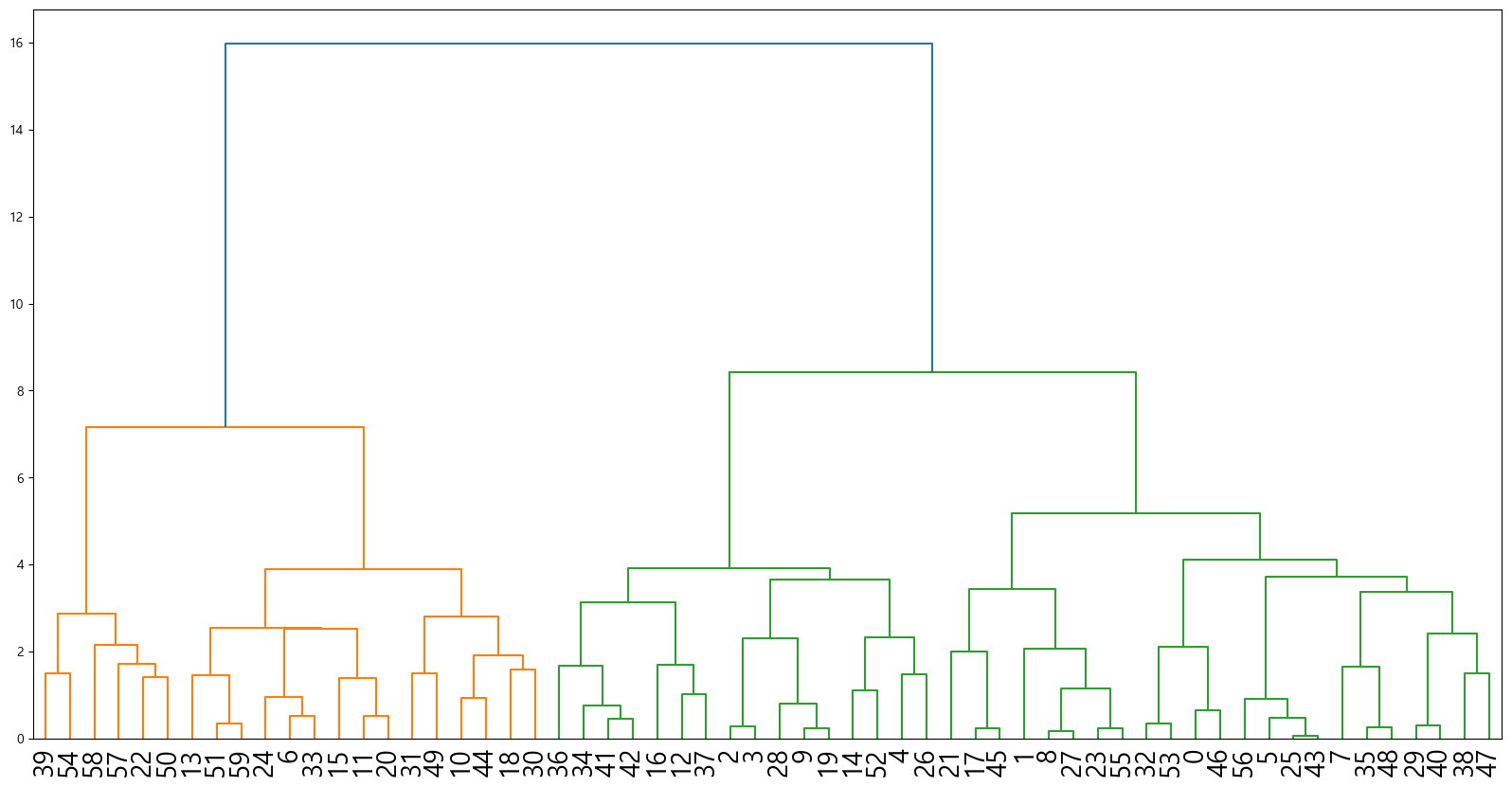
Y값이 있을때는 이렇게 분류해주는데,
그렇다면 Y값이 없을때는 잘 분류해줄지를 DBSCAN을 통해 보자.
1.3.1. 모델 및 학습
df=pd.DataFrame(X, columns=["X1","X2"])
df.head()| X1 | X2 | |
|---|---|---|
| 0 | 0.622519 | -0.372101 |
| 1 | 1.904269 | -0.136303 |
| 2 | -0.069431 | 0.456117 |
| 3 | 0.933899 | 0.237483 |
| 4 | 1.180360 | -0.490847 |
dbscan=DBSCAN(eps=0.3, min_samples=5)
dbscan.fit(df.values)
그룹화 했으니 label을 보자.
df["cluster"]=dbscan.labels_
df.head()| X1 | X2 | cluster | |
|---|---|---|---|
| 0 | 0.622519 | -0.372101 | 0 |
| 1 | 1.904269 | -0.136303 | 0 |
| 2 | -0.069431 | 0.456117 | 0 |
| 3 | 0.933899 | 0.237483 | 1 |
| 4 | 1.180360 | -0.490847 | 0 |
이제 이를 scatter로 보면,
sns.scatterplot(data=df, x="X1", y="X2", hue="cluster")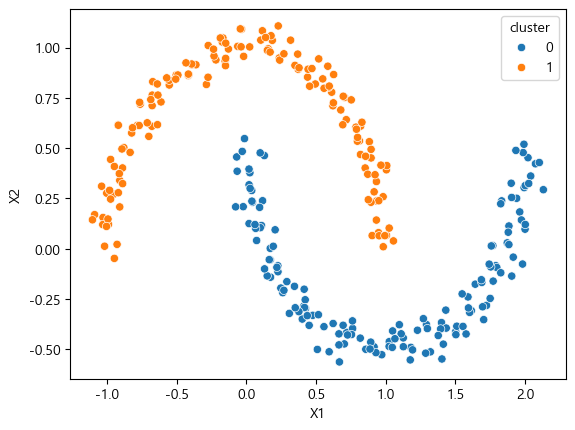
이렇게 잘 분류해줬다.
평균은 임의의 점을 선택해서 클러스터링 수에 따라 분류해가며 평균으로 군집해가는 과정이었다.
2. 연관분석(Association Analysis)
지지도: 맥주와 치킨을 동시에 구매할 확률
신뢰도: 맥주 구매시 치킨을 구매할 확률
향상도: 상관관계
#!pip install mlxtendfrom mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rulesstore=[["맥주", "오징어", "치즈"],
["소주", "맥주", "라면"],
["맥주", "오징어"],
["라면", "김치", "계란"],
["맥주", "소세지"]]
store[['맥주', '오징어', '치즈'],
['소주', '맥주', '라면'],
['맥주', '오징어'],
['라면', '김치', '계란'],
['맥주', '소세지']]이제 문자이니까 원핫인코딩을 해줘야하는데,
리스트 형태의 데이터를 원핫인코딩 형태로 변환할때는 TransactionEncoder를 사용한다.
encoder=TransactionEncoder()
encoder.fit(store)
encoder_onehot=encoder.transform(store)
encoder_onehotarray([[False, False, False, True, False, False, True, True],
[False, False, True, True, False, True, False, False],
[False, False, False, True, False, False, True, False],
[ True, True, True, False, False, False, False, False],
[False, False, False, True, True, False, False, False]])store_table=pd.DataFrame(data=encoder_onehot, columns=encoder.columns_)
store_table| 계란 | 김치 | 라면 | 맥주 | 소세지 | 소주 | 오징어 | 치즈 | |
|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | True | False | False | True | True |
| 1 | False | False | True | True | False | True | False | False |
| 2 | False | False | False | True | False | False | True | False |
| 3 | True | True | True | False | False | False | False | False |
| 4 | False | False | False | True | True | False | False | False |
2.1. Apriori 알고리즘
지지도(동시에 구매할 확률)를 활용하여 연관집합이 자주 발생하는지 빈도를 발견하는 알고리즘
이제 apriori알고리즘을 사용하는데,
이의 순서는 다음과 같다.
apri=apriori(store_table, use_colnames=True, min_support=0.1)
apri| support | itemsets | |
|---|---|---|
| 0 | 0.2 | (계란) |
| 1 | 0.2 | (김치) |
| 2 | 0.4 | (라면) |
| 3 | 0.8 | (맥주) |
| 4 | 0.2 | (소세지) |
| 5 | 0.2 | (소주) |
| 6 | 0.4 | (오징어) |
| 7 | 0.2 | (치즈) |
| 8 | 0.2 | (김치, 계란) |
| 9 | 0.2 | (라면, 계란) |
| 10 | 0.2 | (라면, 김치) |
| 11 | 0.2 | (라면, 맥주) |
| 12 | 0.2 | (라면, 소주) |
| 13 | 0.2 | (소세지, 맥주) |
| 14 | 0.2 | (소주, 맥주) |
| 15 | 0.4 | (오징어, 맥주) |
| 16 | 0.2 | (치즈, 맥주) |
| 17 | 0.2 | (오징어, 치즈) |
| 18 | 0.2 | (라면, 김치, 계란) |
| 19 | 0.2 | (라면, 소주, 맥주) |
| 20 | 0.2 | (오징어, 치즈, 맥주) |
최소 지지도 0.1로 10% 이상인 것들만 보인다.
이제 평가 지표를 보는데, 상관관계를 보여주는 향상도로 보자.
result=association_rules(apri, metric="lift")
result.head()| antecedents | consequents | antecedent support | consequent support | support | confidence | lift | representativity | leverage | conviction | zhangs_metric | jaccard | certainty | kulczynski | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | (김치) | (계란) | 0.2 | 0.2 | 0.2 | 1.0 | 5.0 | 1.0 | 0.16 | inf | 1.00 | 1.0 | 1.000 | 1.00 |
| 1 | (계란) | (김치) | 0.2 | 0.2 | 0.2 | 1.0 | 5.0 | 1.0 | 0.16 | inf | 1.00 | 1.0 | 1.000 | 1.00 |
| 2 | (라면) | (계란) | 0.4 | 0.2 | 0.2 | 0.5 | 2.5 | 1.0 | 0.12 | 1.6 | 1.00 | 0.5 | 0.375 | 0.75 |
| 3 | (계란) | (라면) | 0.2 | 0.4 | 0.2 | 1.0 | 2.5 | 1.0 | 0.12 | inf | 0.75 | 0.5 | 1.000 | 0.75 |
| 4 | (라면) | (김치) | 0.4 | 0.2 | 0.2 | 0.5 | 2.5 | 1.0 | 0.12 | 1.6 | 1.00 | 0.5 | 0.375 | 0.75 |
근데 너무 많아서 필요한 거만 보자.
result.columnsIndex(['antecedents', 'consequents', 'antecedent support',
'consequent support', 'support', 'confidence', 'lift',
'representativity', 'leverage', 'conviction', 'zhangs_metric',
'jaccard', 'certainty', 'kulczynski'],
dtype='object')여기서 선행항목(원인)인 antecedents, 후행항목(결과)인 consequents, 지지도 support, 신뢰도 confidence, 향상도 lift까지 보자.
result[["antecedents", "consequents", "support", "confidence", "lift"]]| antecedents | consequents | support | confidence | lift | |
|---|---|---|---|---|---|
| 0 | (김치) | (계란) | 0.2 | 1.00 | 5.00 |
| 1 | (계란) | (김치) | 0.2 | 1.00 | 5.00 |
| 2 | (라면) | (계란) | 0.2 | 0.50 | 2.50 |
| 3 | (계란) | (라면) | 0.2 | 1.00 | 2.50 |
| 4 | (라면) | (김치) | 0.2 | 0.50 | 2.50 |
| 5 | (김치) | (라면) | 0.2 | 1.00 | 2.50 |
| 6 | (라면) | (소주) | 0.2 | 0.50 | 2.50 |
| 7 | (소주) | (라면) | 0.2 | 1.00 | 2.50 |
| 8 | (소세지) | (맥주) | 0.2 | 1.00 | 1.25 |
| 9 | (맥주) | (소세지) | 0.2 | 0.25 | 1.25 |
| 10 | (소주) | (맥주) | 0.2 | 1.00 | 1.25 |
| 11 | (맥주) | (소주) | 0.2 | 0.25 | 1.25 |
| 12 | (오징어) | (맥주) | 0.4 | 1.00 | 1.25 |
| 13 | (맥주) | (오징어) | 0.4 | 0.50 | 1.25 |
| 14 | (치즈) | (맥주) | 0.2 | 1.00 | 1.25 |
| 15 | (맥주) | (치즈) | 0.2 | 0.25 | 1.25 |
| 16 | (오징어) | (치즈) | 0.2 | 0.50 | 2.50 |
| 17 | (치즈) | (오징어) | 0.2 | 1.00 | 2.50 |
| 18 | (라면, 김치) | (계란) | 0.2 | 1.00 | 5.00 |
| 19 | (라면, 계란) | (김치) | 0.2 | 1.00 | 5.00 |
| 20 | (김치, 계란) | (라면) | 0.2 | 1.00 | 2.50 |
| 21 | (라면) | (김치, 계란) | 0.2 | 0.50 | 2.50 |
| 22 | (김치) | (라면, 계란) | 0.2 | 1.00 | 5.00 |
| 23 | (계란) | (라면, 김치) | 0.2 | 1.00 | 5.00 |
| 24 | (라면, 소주) | (맥주) | 0.2 | 1.00 | 1.25 |
| 25 | (라면, 맥주) | (소주) | 0.2 | 1.00 | 5.00 |
| 26 | (소주, 맥주) | (라면) | 0.2 | 1.00 | 2.50 |
| 27 | (라면) | (소주, 맥주) | 0.2 | 0.50 | 2.50 |
| 28 | (소주) | (라면, 맥주) | 0.2 | 1.00 | 5.00 |
| 29 | (맥주) | (라면, 소주) | 0.2 | 0.25 | 1.25 |
| 30 | (오징어, 치즈) | (맥주) | 0.2 | 1.00 | 1.25 |
| 31 | (오징어, 맥주) | (치즈) | 0.2 | 0.50 | 2.50 |
| 32 | (치즈, 맥주) | (오징어) | 0.2 | 1.00 | 2.50 |
| 33 | (오징어) | (치즈, 맥주) | 0.2 | 0.50 | 2.50 |
| 34 | (치즈) | (오징어, 맥주) | 0.2 | 1.00 | 2.50 |
| 35 | (맥주) | (오징어, 치즈) | 0.2 | 0.25 | 1.25 |
간단한 개념은 이런거고 이를 이용한 추천시스템이 어렵다.
이는 나중에 다루겠다.
3. PCA - 차원 축소
시계열, 딥러닝에서 필요한 개념
시계열에 많은 알고리즘이 있다.
차원(Dimension) 에는 여러가지가 있다.
- Scalar: a=10과 같은 변수 하나에 데이터 하나
- Vector: Series, List, Numpy와 같은 1차원 배열
- Matirx: List, Numpy, DataFrame과 같은 2차원 배열
- Tensor: 3차원 부터를 Tensor라고 하며, n차원 Tensor라고 함
이 3차원은 딥러닝에서 많이 사용한다.
차원은 데이터의 특성(Feature)를 표현하는 정보량, 데이터 공간의 크기를 의미한다.
차원이 클수록 데이터를 더 잘 표현할 수 있지만, 차원이 너무 커지게 된다면, 데이터 내 노이즈(데이터 사이 빈 공간)가 증가한다.
계산량이 커지게 되고, 모델을 훈련하고 예측하는데 시간이 길어진다.
DataFrame을 생각하면,
X1과 같은 부분을 차원으로 본다.
원핫 인코딩을 보면
1 0 0
0 1 0
0 0 1 의 3개의 차원이 있다고 보면,
그래프로 보면 다음과 같다.
이렇게 각 점들은 만날리가 없다.
그런데 이게 만약 원핫인코딩이 600개라면?
선이 600개가 된다.
그리고 600개의 선에 점이 하나씩 찍히는 것이다.
보통의 데이터들은 데이터가 많아도 1차원이라면 한 선에 점들이 찍히지만
그렇게 차원이 커지면 빈공간이 생기는 것이다.
100X100의 그림에 RGB가 3개 이므로, 30000개의 차원이 생기게 된다.
따라서 이런 차원을 축소하게 되는 것이다.
고차원 공간의 데이터를 낮은 차원의 데이터로 변환하여 원본 데이터의 의미있는 속성을 잘 표현해줄 수 있어야 한다.
# 기본적인 부분
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False이번에는 데이터가 없어서 우선 iris 데이터를 가져와서 보자.
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
from sklearn.decomposition import PCA3.1. 데이터 로드 및 전처리
iris=load_iris()
# iris data to DF
iris_df=pd.DataFrame(data=iris.data, columns=iris.feature_names) # key, value
iris_df["label"]=iris.target_names[iris.target]
iris_df.head(2)| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | label | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
iris_df.shape(150, 5)sns.scatterplot(data=iris_df, x="sepal length (cm)", y="sepal width (cm)", hue="label")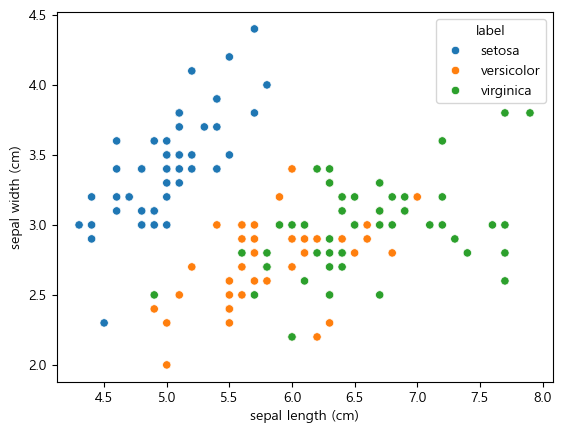
scaler=StandardScaler()
iris_scaled=scaler.fit_transform(iris.data)3.2. PCA 적용
- PCA에서 분산의 의미
- PCA에서는 데이터를 축소할 때, 정보를 최대한 보존. 이때 정보량의 기준이 분산
- PCA는 데이터의 분산을 가장 많이 보존하는 방향(축)을 찾음
- 분산이 클수록 데이터의 중요한 정보가 많이 포함되어 있다고 간주 즉, 데이터의 분산이 최재가 되는 방향으로 설정
pca=PCA(n_components=2) # hyper parameter
iris_pca=pca.fit_transform(iris_scaled)print("원본 데이터 형태: ", iris_scaled.shape)
print("PCA 적용된 데이터 형태: ", iris_pca.shape)원본 데이터 형태: (150, 4)
PCA 적용된 데이터 형태: (150, 2)pca.explained_variance_ratio_ # 정보량이 어느정도 있는지 배열로 반환 array([0.72962445, 0.22850762])PC1: 가장 많은 분산(정보량)
PC2: 남은 분산 중 가장 많은 부분
원본보다 조금 떨어질 것인데, 이건 열이 4개일 때기 때문이다.
만약 열이 10000개가 된다면?
예측률을 위해서 축소없이 돌리면 엄청난 시간이 걸릴 것이다.
pca_columns=["pca1", "pca2"]
pca_df=pd.DataFrame(data=iris_pca, columns=pca_columns)
pca_df["label"]=iris.target_names[iris.target]
pca_df.head()| pca1 | pca2 | label | |
|---|---|---|---|
| 0 | -2.264703 | 0.480027 | setosa |
| 1 | -2.080961 | -0.674134 | setosa |
| 2 | -2.364229 | -0.341908 | setosa |
| 3 | -2.299384 | -0.597395 | setosa |
| 4 | -2.389842 | 0.646835 | setosa |
sns.scatterplot(data=pca_df, x="pca1", y="pca2", hue="label")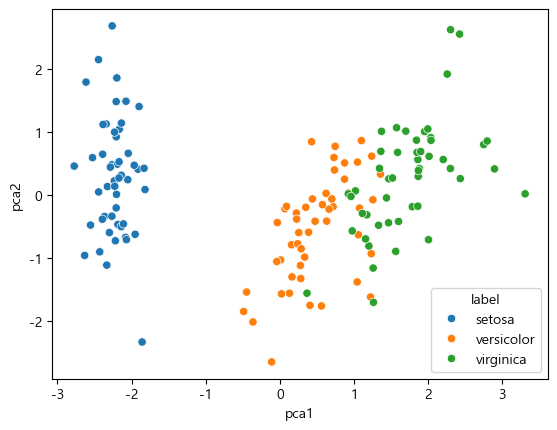
차원을 두개로 바꿨으니 축소되어 눈에는 더 잘 보인다.
하지만 예측율은 당연히 떨어질 것이다.
3.3. 학습 및 평가
rf=RandomForestClassifier(n_jobs=-1, max_depth=7, random_state=123)
scores=cross_validate(rf, iris_scaled, iris_df["label"], cv=5)
print(scores["test_score"])
print(scores["test_score"].mean())[0.96666667 0.96666667 0.93333333 0.93333333 1. ]
0.96pca_x=pca_df[["pca1", "pca2"]]
pca_y=pca_df["label"]
pca_scores=cross_validate(rf, pca_x, pca_y, cv=5)
print(pca_scores["test_score"])
print(pca_scores["test_score"].mean())[0.83333333 0.93333333 0.83333333 0.9 1. ]
0.9 원본과 0.06 정도의 차이가 난다.
데이터가 많으면 이렇게 사용한다는 것을 알아두자.
3.4. Elbow
이제 하이퍼파라미터를 위에서 n_components를 2로 뒀으니 이를 확인하기 위해 Elbow기법을 사용해보자.
pca_ex=PCA()
pca_ex.fit_transform(iris_scaled)
ratio_ex=pca_ex.explained_variance_ratio_
print(ratio_ex) # 주성분 분산 비율[0.72962445 0.22850762 0.03668922 0.00517871]'4번의 축이동을 했는데 2번정도만 하면 되겠다.'
그러면 이제 이를 시각화 해보기위해 우선 누적합을 해보자.
sum_ex=np.cumsum(ratio_ex) # 주성분 분산 비율의 누적합
print(sum_ex)[0.72962445 0.95813207 0.99482129 1. ]sns.lineplot(x=range(1, len(sum_ex) + 1), y=sum_ex) # x=5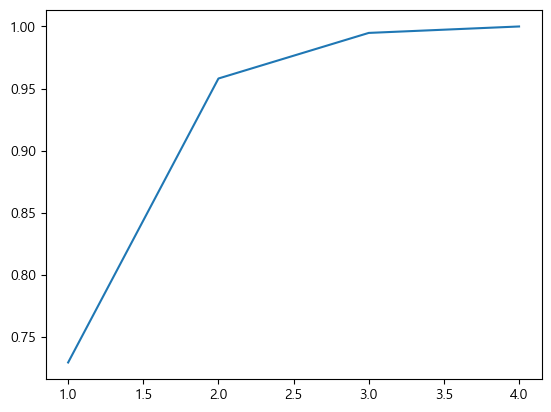
이를 보니 2번 정도 하면 된다는 것을 알 수 있다.
이런 차원축소는 딥러닝에서도 사용되기 때문에 계속해서 이어질 것이니 그때 자세히 더 다뤄보겠다.
