
전처리는 토큰화, 정제, 불용어, 어간추출 등이 있고,
이 이후 정수형 인코딩이 들어가서 패딩.
그리고 학습 -> 예측까지.
이렇게 연습해봤는데, 결국에는 다 정리된 것들을 load해서 사용했다.
정제 -> 토큰화 -> 정수형 인코딩의 순서에서 실제 중요한 부분은 정제다.
지금까지 keras를 이용했었는데, 이번에는 형태소 분석기를 사용한다.
가장 먼저 불용어(Stop Words) 처리
조사, 접속사 등의 의미 없는 정보를 제거 (a, the)
그 다음 정규화
어간 추출
표제어 추출
등의 순서를 가진다.
영문쪽 형태소 분석기는 NLTK(Natural Language Toolkit), 한글 형태소 분석기는 kiwi를 사용한다.
먼저 영문 형태소 분석기 부터 실습해보자.
1. 영문 형태소 분석기
1.1. NLTK 설치
# pip install nltkimport nltk
from nltk.tokenize import word_tokenize
from nltk.tokenize import sent_tokenize
from nltk.corpus import stopwords
from tensorflow.keras.preprocessing.text import Tokenizer, text_to_word_sequence#nltk.download()
이 창이 뜨면 Download 버큰을 눌러준다.1.2. 토큰화
tokens=word_tokenize("Hello World, This is a tokenization.")
tokens['Hello', 'World', ',', 'This', 'is', 'a', 'tokenization', '.']1.3. 정제
- 특수 문자 제거: . , !!! ~~~ 등
- 알파벳 문자로만 이루어졌는지 확인 -> python 명령어 사용
words=[]
for word in tokens:
if word.isalpha():
words.append(word)
words['Hello', 'World', 'This', 'is', 'a', 'tokenization'] 1.4. 불용어
- 문장에 많이 등장하지만 큰 의미가 없는 단어들
- '이', '그', '저', '수', '등', ... , 'a', 'am', 'this' 등
- 추가 및 제거할 수 도 있음
nltk.download('stopwords')# nltk가 가지고 있는 불용어 확인
stop_words_list=stopwords.words('english')
print("불용어 개수: ", len(stop_words_list), type(stop_words_list))
print("불용어 10개 출력:", stop_words_list[:10])불용어 개수: 198 <class 'list'>
불용어 10개 출력: ['a', 'about', 'above', 'after', 'again', 'against', 'ain', 'all', 'am', 'an']example="Hello World! Preprocessing is not an import thing~ It's necessary thing."
print(f"원본:\n{example}\n")
# 토큰화
tokens=word_tokenize(example)
print(f"원본 토큰화:\n{tokens}\n")
# 특수문자 제거
example_words=[]
for word in tokens:
if word.isalpha():
example_words.append(word)
print(f"특수문자 제거 후:\n{example_words}\n")
# 불용어 제거
stop_words=set(stopwords.words('english')) # set 저장
result=[]
for word in example_words:
if word not in stop_words:
result.append(word)
print(f"불용어 제거 후: \n{result}\n")
# 이후는 동일
# 정수형 인덱싱 -> 정수형 인코딩(패딩)
token=Tokenizer()
token.fit_on_texts(result)
seq=token.texts_to_sequences(result)
print(seq)
print(token.word_index)원본:
Hello World! Preprocessing is not an import thing~ It's necessary thing.
원본 토큰화:
['Hello', 'World', '!', 'Preprocessing', 'is', 'not', 'an', 'import', 'thing~', 'It', "'s", 'necessary', 'thing', '.']
특수문자 제거 후:
['Hello', 'World', 'Preprocessing', 'is', 'not', 'an', 'import', 'It', 'necessary', 'thing']
불용어 제거 후:
['Hello', 'World', 'Preprocessing', 'import', 'It', 'necessary', 'thing']
[[1], [2], [3], [4], [5], [6], [7]]
{'hello': 1, 'world': 2, 'preprocessing': 3, 'import': 4, 'it': 5, 'necessary': 6, 'thing': 7}2. 한글 형태소 분석기
- ⭐ KoNLPy (https://wikidocs.net/22488)
- kiwi
- Bareun
어떤 형태소 분석기를 쓰냐에 따라 정제 방법이 조금 다르다.
우선 간단하게 어떻게 동작하는지 보기위해서 이번에는 kiwi를 사용한다.
2.1. Kiwi 설치
#!pip install kiwipieyfrom kiwipiepy import Kiwi
from kiwipiepy.utils import Stopwords2.2. 토큰화 및 정제
kiwi=Kiwi()
kor_tokens=kiwi.tokenize("안녕하세요! 형태소 분석기 키위입니다~")
kor_tokens[Token(form='안녕', tag='NNG', start=0, len=2),
Token(form='하', tag='XSA', start=2, len=1),
Token(form='세요', tag='EF', start=3, len=2),
Token(form='!', tag='SF', start=5, len=1),
Token(form='형태소', tag='NNG', start=7, len=3),
Token(form='분석기', tag='NNG', start=11, len=3),
Token(form='키위', tag='NNG', start=15, len=2),
Token(form='이', tag='VCP', start=17, len=1),
Token(form='ᆸ니다', tag='EF', start=17, len=3),
Token(form='~', tag='SO', start=20, len=1)]
입니다. 같은 것을 '이'와 'ㅂ니다' 같이 나눠서 인식하는 것을 보니 그렇게 좋지는 않다.
tag=품사, start=시작 인덱스, len=길이, np:명사, vv:동사, jx:조사, mag:부사, va:형용사
참고로 세종 품사 태그가 있는데 엄청나게 많다. 다음 블로그를 참고하자.
https://blog.naver.com/aramjo/221404488280
이제 앞서 영문 형태소와 같이 정제.
구두점, 불용어 도 제거하자
kor_words=[]
for word in kor_tokens:
# 앞서 kor_tokens는 Token(form='안녕', tag='NNG', start=0, len=2)와 같기 때문에 key값인 form으로 써야함
if word.form.isalpha():
kor_words.append(word.form)
print("구두점 제거된 토큰: ", kor_words)구두점 제거된 토큰: ['안녕', '하', '세요', '형태소', '분석기', '키위', '이', 'ᆸ니다']stopword=Stopwords()
kiwi.tokenize("분석 결과에서 불용어만 제외하고 출력할 수도 있다.", stopwords=stopword)덧붙은 받침인 용ㅇㅇ, 앜ㅋㅋㅋ 과 같은 것들 때문에 분석 깨지는 경우가 있는데 이를 방지할 수도 있다.
kiwi.tokenize("ㅋㅋㅋㅋㅋ 이런 것도 분석할 수 있을지 볼까낰ㅋㅋㅋㅋㅋㅋ??", normalize_coda=True)[Token(form='ㅋㅋㅋㅋㅋ', tag='SW', start=0, len=5),
Token(form='이런', tag='MM', start=6, len=2),
Token(form='것', tag='NNB', start=9, len=1),
Token(form='도', tag='JX', start=10, len=1),
Token(form='분석', tag='NNG', start=12, len=2),
Token(form='하', tag='XSV', start=14, len=1),
Token(form='ᆯ', tag='ETM', start=14, len=1),
Token(form='수', tag='NNB', start=16, len=1),
Token(form='있', tag='VA', start=18, len=1),
Token(form='을지', tag='EC', start=19, len=2),
Token(form='보', tag='VX', start=22, len=1),
Token(form='ᆯ까', tag='EC', start=22, len=2),
Token(form='나', tag='VX', start=24, len=1),
Token(form='ㅋㅋㅋㅋㅋㅋㅋ', tag='SW', start=24, len=7),
Token(form='??', tag='SF', start=31, len=2)]
3. 네이버 쇼핑 리뷰 데이터 감성 분석
- https://github.com/bab2min/corpus/tree/master/sentiment
- 20만개의 네이버 쇼핑 리뷰 데이터
3.1. 데이터 로드
txt파일은 read_table로 읽을 수 있다.
또 이는 컬럼 이름이 없어서 names로 지정해준다.
data=pd.read_table('data/naver_shopping.txt', names=["평점", "리뷰"])
data.shape(200000, 2)data.head(2)| 평점 | 리뷰 | |
|---|---|---|
| 0 | 5 | 배공빠르고 굿 |
| 1 | 2 | 택배가 엉망이네용 저희집 밑에층에 말도없이 놔두고가고 |
data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200000 entries, 0 to 199999
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 평점 200000 non-null int64
1 리뷰 200000 non-null object
dtypes: int64(1), object(1)
memory usage: 3.1+ MBdata["평점"].value_counts()평점
5 81177
2 63989
1 36048
4 18786
Name: count, dtype: int64중간인 3은 없고 거의 5:5정도로 보인다.
그러면 3을 기준으로 긍정과 부정으로 나눠보자.
# 긍정 1, 부정 0
data["긍부정"]=np.where(data["평점"] > 3, 1, 0)
display(data.head(3))
display(data["긍부정"].value_counts())| 평점 | 리뷰 | 긍부정 | |
|---|---|---|---|
| 0 | 5 | 배공빠르고 굿 | 1 |
| 1 | 2 | 택배가 엉망이네용 저희집 밑에층에 말도없이 놔두고가고 | 0 |
| 2 | 5 | 아주좋아요 바지 정말 좋아서2개 더 구매했어요 이가격에 대박입니다. 바느질이 조금 ... | 1 |
긍부정
0 100037
1 99963
Name: count, dtype: int64# unique: 고유값들의 배열 -> [1,2,4,5]
# nunique: 고유값의 개수(정수) -> 4
print(data["평점"].nunique()) # 서로 다른 평점 4개 (1,2,4,5)
print(data["리뷰"].nunique()) # 중복 제거한 리뷰가 199908게
print(data["긍부정"].nunique()) # 고유값이 긍정, 부정으로 2개
# "굿" 이런식으로 중복값이 있으면 학습 가중치에 영향을 줄 수 있다.
# 리뷰의 중복이 있을 수 있다. 4
199908
2# 리뷰에서 중복인 내용(행) 삭제
# subset: 기준열 지정
data.drop_duplicates(subset=["리뷰"], inplace=True)
data.shape(199908, 3)3.2. 데이터 정제
3.2.1. 정규화
- 한글과 공백을 제외하고 모두 제거
앞서 isalpha()와 같이 간단한 것들을 처리할 수도 있지만, re를 사용하여 문자열을 정규화하는 방법을 사용하자.
참고로 w3c에 정규화와 관련된 다양한 내용들이 있다.
https://www.w3schools.com/python/python_regex.asp
먼저 영문으로 테스트해보면 다음과 같다.
eng_text="do!!! you expect... people~ to~ read~ the FAQ, etc. and actually accept hard~! atheism?@@"
print(re.sub(r'[^a-zA-Z ]', '', eng_text))do you expect people to read the FAQ etc and actually accept hard atheismre.sub(정규 표현식 패턴, 대체, 처리할 문자열)
- r'[^a-zA-Z ]':
- r'[]': [] 안의 내용을 읽어와라
- ^: 부정문
- a-zA-Z : 영문자(a-zA-Z)와 공백( )
- -> 즉, 영문자와 공백을 빼고 읽어와라
- '': 읽어온 것들을 빈 문자열로 대체
- eng_text: 처리할 문자열
그렇다면 다시 돌아와서 리뷰 데이터의 이제 한글 데이터를 처리하자.
# regex: 정규화 작업을 해주겠다는 pandas 키워드로 정규표현식으로 인식하라는 옵션임
data["리뷰"]=data["리뷰"].str.replace(r'[^ㄱ-ㅎㅏ-ㅣ가-힣 ]', '', regex=True)
# 빈값은 null값으로 바꿔주고 null값이 있으면 drop하면됨
data["리뷰"]=data["리뷰"].replace('', np.nan)
print(data.isna().sum())평점 0
리뷰 0
긍부정 0
dtype: int643.2.2. 토큰화 및 불용어 제거
이전에는 그냥 stopwords 클래스에서 제공하는 불용어를 사용했는데 직접 지정할 수도 있다.
그냥 stopwords=Stopwords()를 써도 된다.
이런식으로 돌아간다.
train[0]['배공빠르고', '굿']근데 잘 인식하지 못했다.
kiwi는 간단하게 사용할 수는 있지만 정확히 하기 위해서는 KoNLPy를 사용하는 것이 좋다.
# 열 하나 더 만드는데 -> " " 공백을 중심으로 join
data["토큰화리뷰"]=[" ".join(tokens) for tokens in train]data.head()| 평점 | 리뷰 | 긍부정 | 토큰화리뷰 | |
|---|---|---|---|---|
| 0 | 5 | 배공빠르고 굿 | 1 | 배공빠르고 굿 |
| 1 | 2 | 택배가 엉망이네용 저희집 밑에층에 말도없이 놔두고가고 | 0 | 택배 엉망 네요 ᆼ 저희 집 밑 층 말 없이 놔두 |
| 2 | 5 | 아주좋아요 바지 정말 좋아서개 더 구매했어요 이가격에 대박입니다 바느질이 조금 엉성... | 1 | 아주 좋 어요 바지 정말 좋 어서 개 더 구매 었 어요 가격 대 박 ᆸ니다 바느질 ... |
| 3 | 2 | 선물용으로 빨리 받아서 전달했어야 하는 상품이었는데 머그컵만 와서 당황했습니다 전화... | 0 | 선물 용 으로 빨리 받 어서 전달 었 어야 상품 었 는데 머 그 컵 만 오 어서 당... |
| 4 | 5 | 민트색상 예뻐요 옆 손잡이는 거는 용도로도 사용되네요 ㅎㅎ | 1 | 민트 색상 예쁘 어요 옆 손잡이 거 용도 로 사용 되 네요 ㅎㅎ |
잘 들어간 것을 볼 수 있다.
3.2.3. 긍부정 단어 빈도수
이번에는 긍부정 단어의 빈도수를 보자.
# hstack: data 테이블에 있는 긍부정이 0, 1인 애들의 토큰화리뷰의 내용을 가지고와서, 두개의 열값을 합치는 거
negative_words=np.hstack(data[data["긍부정"]==0]["토큰화리뷰"].values)
positive_words=np.hstack(data[data["긍부정"]==1]["토큰화리뷰"].values)
# Counter: 빈도수 계산
negative_words_count=Counter(negative_words)
positive_words_count=Counter(positive_words)# 빈도수 기준 상위 20개
negative_words_count.most_common(20)[(np.str_('재 구매'), 26),
(np.str_('배송 너무 느리 어요'), 17),
(np.str_('그냥 그렇 어요'), 9),
(np.str_('좋 어요'), 9),
(np.str_('배송 빠르 좋 어요'), 9),
(np.str_('배송 빠르 어요'), 8),
(np.str_('생각 보다 별로 네요'), 7),
(np.str_('잘 받 었 습니다'), 7),
(np.str_('그저 그렇 어요'), 7),
(np.str_('그저 그렇 네요'), 7),
(np.str_('배송 겁나 느리 ᆷ'), 7),
(np.str_('별로 에요'), 7),
(np.str_('배송 너무 느리 ᆸ니다'), 7),
(np.str_('별로'), 6),
(np.str_('사이즈 작 어요'), 6),
(np.str_('딱 가격 만큼 ᆸ니다'), 6),
(np.str_('별루 ᆸ니다'), 6),
(np.str_('배송 느리 ᆷ'), 5),
(np.str_('냄새 심하 어요'), 5),
(np.str_('배송 너무 늦 네요'), 5)]
positive_words_count.most_common(20)[(np.str_('재 구매'), 29),
(np.str_('좋 어요'), 16),
(np.str_('좋 습니다'), 9),
(np.str_('만족 ᆸ니다'), 8),
(np.str_('감사 ᆸ니다'), 8),
(np.str_('배송 빠르 어요'), 7),
(np.str_('굿'), 6),
(np.str_('조아 요'), 6),
(np.str_('잘 받 었 습니다'), 6),
(np.str_('좋 네요'), 5),
(np.str_('빠르 ᆫ 배송 감사 ᆸ니다'), 5),
(np.str_('배송 빠르 네요'), 5),
(np.str_('재 구매 배송 빠르 좋 어요'), 5),
(np.str_('배송 빠르 좋 네요'), 5),
(np.str_('맘 어요'), 4),
(np.str_('괜찮 어요'), 4),
(np.str_('재 구매 빠르 ᆫ 배송 감사 ᆸ니다'), 4),
(np.str_('맛있 어요'), 4),
(np.str_('배송 빠르 좋 어요'), 4),
(np.str_('착용감 좋 어요'), 4)]
3.3. 훈련-테스트 데이터셋 분리
train, test = train_test_split(data, test_size=0.25, random_state=42)
train.shape, test.shape((149931, 4), (49977, 4))X_train=train["토큰화리뷰"].values
Y_train=train["긍부정"].values
X_test=test["토큰화리뷰"].values
Y_test=test["긍부정"].values
X_train.shape, Y_train.shape, X_test.shape, Y_test.shape((149931,), (149931,), (49977,), (49977,))3.4. 정수 인코딩
tokenizer=Tokenizer()
tokenizer.fit_on_texts(X_train)
total_count=len(tokenizer.word_index) # 단어의 수
total_count37762정수형 인코딩을 마친 단어의 수는 37762개 이다.
이제 빈도수가 낮은 애들을 제외하자.
1회 정도만 나온 단어들은 큰 역할을 하지 못하니까 그냥 제외하는 것이다.
# 빈도수가 낮은, 1회인 단어들은 자연어 처리에서 제외
threshold=2
total_freq=0 # 훈련데이터의 전체 빈도수 총합
rare_count=0 # 희귀 단어 수: 빈도수가 threshold보다 낮은 단어의 수
rare_freq=0 # 희귀 단어 빈도수 합: 빈도수가 threshold보다 낮은 단어의 빈도수 총합
# word_counts: (단어, 빈도수) 쌍 -> .items()로 뽑아서 -> key와 value로
for key, value in tokenizer.word_counts.items():
total_freq += value # 빈도수 총합
if(value < threshold): # 빈도수가 threshold보다 낮은 단어의 수
rare_count += 1
rare_freq += valueprint(f"전체 단어의 수: {total_count}\n")
print(f"빈도가 {threshold-1}번 이하인, 희귀 단어의 수: {rare_count}")
print(f"희귀 단어 비율 (희귀 단어 수/전체 단어 수): {(rare_count/total_count)*100}")
print(f"희귀 단어 빈도 비율 (희귀 빈도/전체 빈도): {(rare_freq/total_freq)*100}")전체 단어의 수: 37762
빈도가 1번 이하인, 희귀 단어의 수: 21121
희귀 단어 비율 (희귀 단어 수/전체 단어 수): 55.93188920078386
희귀 단어 빈도 비율 (희귀 빈도/전체 빈도): 0.8449812808701616# +2: index가 1번부터 시작하는데, 0부터 들어가게 되니까 +1이고,
# 이를 다시 index번호를 줘야하는데, OOV라고 학습할때 없는 단어가 나오면 OOV로 처리하게 되는데, 이는 아래서 설명한다.
vocab_size=total_count - rare_count + 2
vocab_size16643만약 데이터의 구성이 이렇게 되어있다고 가정하자.
X_train = ["배송 빠르네요", "재구매 의사 있어요"]
X_test = ["배송 진짜 느림"] # "진짜", "느림" → 훈련에 없던 단어들 (OOV)그럼 이제 Tokenizer를 준비하면,
tokenizer = Tokenizer(oov_token="OOV")
tokenizer.fit_on_texts(X_train)이렇게 하면 "OOV"라는 특수 토큰이 인덱스 1번에 자동 할당되고,
여기서 단어 인덱스를 확인해보면,
{
'OOV': 1, # 처음 보는 단어는 여기로 들어감 "진짜", "느림"
'배송': 2,
'빠르네요': 3,
'재구매': 4,
'의사': 5,
'있어요': 6
}이렇게 된다.
그리고 정수 인코딩이
tokenizer.texts_to_sequences(X_test)[['2', '1', '1']]
# "배송"은 훈련에 있어서 2번,
# "진짜", "느림"은 없으므로 OOV → 1번으로 대체이제 maxlen=5로 패딩하면 아래와 같이 되는 거다.
pad_sequences([[2, 1, 1]], maxlen=5)[[0, 0, 2, 1, 1]]tokenizer=Tokenizer(vocab_size, oov_token="OOV")
tokenizer.fit_on_texts(X_train)
X_train=tokenizer.texts_to_sequences(X_train)
X_test=tokenizer.texts_to_sequences(X_test)
print(X_train[:3])[[67, 1733, 299, 1943, 5, 13, 50, 70, 2, 236, 172, 143, 156, 2, 2564, 2487, 66, 7, 71, 61, 131, 44, 961, 347, 163, 8, 2], [2091, 301, 52, 1977, 3961, 2589, 316, 1977, 313, 78, 4, 32, 447, 7], [46, 17, 985, 113, 42, 1978, 165, 11, 16, 1409, 3, 2, 1200, 6, 127, 258, 4, 23, 57, 165, 127, 11, 1409, 7, 117, 13, 15, 491, 322, 124, 142]]이제 패딩을 위해 길이를 뽑아보고
print("리뷰의 최대 길이: ", max(len(review) for review in X_train))
print("리뷰의 평균 길이: ", sum(map(len, X_train))/len(X_train))리뷰의 최대 길이: 77
리뷰의 평균 길이: 16.67154891249975maxlen을 80정도로 지정한다.
# from tensorflow.keras.preprocessing.sequence import pad_sequences
max_len=80
X_train=pad_sequences(X_train, maxlen=max_len)
X_test=pad_sequences(X_test, maxlen=max_len)3.5. 모델 훈련
model=Sequential()
model.add(keras.layers.Input(shape=(max_len, )))
model.add(keras.layers.Embedding(input_dim=vocab_size, output_dim=100))
model.add(keras.layers.LSTM(128, activation="tanh"))
model.add(keras.layers.Dense(1, activation="sigmoid"))# min: 보통 loss에 사용. 손실 값은 작을수록 좋은 거니까, 최소값을 찾아가며 멈추겠다는 뜻
# max: 보통 accuracy에 사용. 값이 커지는 걸 기대
# auto: 자동 감지. monitor 값 보고 자동 판단
esc=EarlyStopping(monitor="val_loss", mode="min", verbose=1, patience=4)
# rmsprop: 딥러닝에서 자주 쓰이는 최적화 알고리즘으로, 가중치를 어떻게 업데이트할 것인가를 결정하는 역할
# 각 파라미터마다 다른 학습률을 자동 조절해서 RNN, LSTM처럼 시퀀스를 다룰 때 잘 작동함
model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["accuracy"])
history=model.fit(X_train, Y_train, epochs=3, batch_size=64, validation_split=0.2, callbacks=[esc])Epoch 1/3
[1m1875/1875[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m178s[0m 94ms/step - accuracy: 0.8465 - loss: 0.3597 - val_accuracy: 0.9135 - val_loss: 0.2377
Epoch 2/3
[1m1875/1875[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m187s[0m 100ms/step - accuracy: 0.9176 - loss: 0.2305 - val_accuracy: 0.9186 - val_loss: 0.2259
Epoch 3/3
[1m1875/1875[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m168s[0m 90ms/step - accuracy: 0.9234 - loss: 0.2115 - val_accuracy: 0.9162 - val_loss: 0.22983.6. 테스트 데이터
테스트 데이터는 학습 데이터와 같은 방식으로 바꿔줘야 한다.
def review_emotion_pred(new_sentence):
# 전처리
new_sentence=re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣 ]', '', new_sentence) # 정규 표현식
new_sentence=[token.form for token in kiwi.tokenize(new_sentence)] # 토큰화
new_sentence=[word for word in new_sentence if word not in stopwords] # 불용어 제거
encoded=tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩
pad_new=pad_sequences(encoded, maxlen=max_len) # 패딩 -> maxlen=80
# pad_new.shape: (1, 80)의 하나의 문장, 길이 80의 시퀀스 (패딩완료됨)
# model.predict(pad_new) -> Sequential 모델의 마지막 레이어가 Dense(1, activation="sigmoid") 였기 때문에
# 출력이 array([[0.8423548]], dtype=float32) 와 같은 2차원 배열이 됨
# 따라서 [0]은 첫번째 샘플 -> 그다음 다시 [0]으로 그 샘플의 예측 확률 값을 뽑아냄
# [[0.8423548]] → [0] → [0.8423548] → [0] → 0.8423548
score=float(model.predict(pad_new)[0][0])
if(score > 0.5):
print(f"긍정 확률 {score*100:.2f}% vs " + f"부정 확률 {(1-score)*100:.2f}%")
print(f"긍정 리뷰 입니다.")
#print("{:.2f}% 확률로 긍정 리뷰입니다.".format(score * 100))
else:
print(f"긍정 확률 {score*100:.2f}% vs " + f"부정 확률 {(1-score)*100:.2f}%")
print(f"부정 리뷰 입니다.")
#print("{:.2f}% 확률로 부정 리뷰입니다.".format((1-score) * 100))review_emotion_pred("강추!! 너무 좋습니다 ㅎㅎ")긍정 확률 97.61% vs 부정 확률 2.39%
긍정 리뷰 입니다.review_emotion_pred("배송이 3주가 걸렸습니다. 연락도 없었고요.")긍정 확률 3.87% vs 부정 확률 96.13%
부정 리뷰 입니다.review_emotion_pred("왆젆빟춯핳닣닿^^")긍정 확률 52.33% vs 부정 확률 47.67%
긍정 리뷰 입니다.마지막은 재미로 한번 넣어봤다. 그래도 나름 잘 분류했다.
4. 네이버 영화 리뷰 감성 분류
4.1. 데이터 로드
df=pd.read_table('data/ratings.txt')
df.shape(200000, 3)df.head()| id | document | label | |
|---|---|---|---|
| 0 | 8112052 | 어릴때보고 지금다시봐도 재밌어요ㅋㅋ | 1 |
| 1 | 8132799 | 디자인을 배우는 학생으로, 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산... | 1 |
| 2 | 4655635 | 폴리스스토리 시리즈는 1부터 뉴까지 버릴께 하나도 없음.. 최고. | 1 |
| 3 | 9251303 | 와.. 연기가 진짜 개쩔구나.. 지루할거라고 생각했는데 몰입해서 봤다.. 그래 이런... | 1 |
| 4 | 10067386 | 안개 자욱한 밤하늘에 떠 있는 초승달 같은 영화. | 1 |
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200000 entries, 0 to 199999
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 200000 non-null int64
1 document 199992 non-null object
2 label 200000 non-null int64
dtypes: int64(2), object(1)
memory usage: 4.6+ MBdocument에 결측치가 있으니까 떨궈주자.
4.2. 전처리
df["document"].nunique(), df["label"].nunique()(194543, 2)먼저 리뷰에 중복이 있으면 안되기 때문에 중복유무를 확인해보니
데이터가 실질적으로는 199992인데, 중복 데이터가 5000개 가량 있으니까 삭제해준다.
df.drop_duplicates(subset=["document"], inplace=True)
df["label"].value_counts()label
0 97277
1 97267
Name: count, dtype: int64label은 이상한 값이 없으니까 괜찮다.
이제 null 값을 확인해보고 떨궈주자.
df.isna().sum()id 0
document 1
label 0
dtype: int64df.dropna(inplace=True)
df.shape(194543, 3)4.3. 데이터 정제
4.3.1. 정규화
df_normalize=df.copy()
# 한글과 공백을 제외하고 모두 공백으로 대체
df_normalize["document"]=df_normalize["document"].str.replace(r"[^ㄱ-ㅎㅏ-ㅣ가-힣 ]", "", regex=True)
df_normalize.head()| id | document | label | |
|---|---|---|---|
| 0 | 8112052 | 어릴때보고 지금다시봐도 재밌어요ㅋㅋ | 1 |
| 1 | 8132799 | 디자인을 배우는 학생으로 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산업... | 1 |
| 2 | 4655635 | 폴리스스토리 시리즈는 부터 뉴까지 버릴께 하나도 없음 최고 | 1 |
| 3 | 9251303 | 와 연기가 진짜 개쩔구나 지루할거라고 생각했는데 몰입해서 봤다 그래 이런게 진짜 영화지 | 1 |
| 4 | 10067386 | 안개 자욱한 밤하늘에 떠 있는 초승달 같은 영화 | 1 |
띄어쓰기는 유지되면서 온점과 같은 구두점 등 제거완료됐다.
이제 순서가, 문자와 공백을 제외하고는 빈값으로 대체한 후에 제거하는데,
주의할점이 네이버 영화 리뷰는 한글이 아닌 영문, 숫자, 특문으로도 리뷰가 가능하다.
그래서 앞선 정규화로 인해서 기존에 한글이 없는 리뷰였다면 더 이상 아무런 값도 없는 빈(empty) 값이 되었을 것이다.
따라서 정규화 방식을 조금 바꿔서 이 부분도 처리해줘야한다.
⭐단! [] 안에 있을 떄는 "not"이라는 부정 의미가 되므로 []를 사용하면 안된다.
df_normalize["document"]=df_normalize["document"].str.replace(r"^ +", "", regex=True) # white space 데이터를 empty value로 변경이제 앞서 정규화 들로 인해 공백으로 대체했으니 공백들을 nan으로 대체하고 dropna로 삭제해주자.
df_normalize["document"]=df_normalize["document"].replace("", np.nan)
df_normalize.dropna(inplace=True)
df_normalize.shape(193518, 3)4.3.2. 토큰화
이제 불용어를 제거해서 토큰화하자.
df_tokenize=df_normalize.copy()
# kiwi가 가진 불용어가 너무 많기 때문에 임의로 지정해주자.
stopwords=['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
kiwi=Kiwi()
data_list=[]
for sentence in tqdm(df_tokenize["document"]):
tokens=kiwi.tokenize(sentence)
filtered_tokens=[token.form for token in tokens if token.form not in stopwords]
data_list.append(filtered_tokens)100%|██████████| 193518/193518 [03:54<00:00, 825.51it/s] df_tokenize["token_document"]=[" ".join(tokens) for tokens in data_list]
df_tokenize.head()| id | document | label | token_document | |
|---|---|---|---|---|
| 0 | 8112052 | 어릴때보고 지금다시봐도 재밌어요ㅋㅋ | 1 | 어리 ᆯ 때 보 고 지금 다시 보 어도 재밌 어요 ㅋㅋ |
| 1 | 8132799 | 디자인을 배우는 학생으로 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산업... | 1 | 디자인 을 배우 학생 외국 디자이너 그 일구 ᆫ 전통 을 통하 어 발전 하 어 문화... |
| 2 | 4655635 | 폴리스스토리 시리즈는 부터 뉴까지 버릴께 하나도 없음 최고 | 1 | 폴리스 스토리 시리즈 부터 뉴 까지 버리 ᆯ께 하나 없 음 최고 |
| 3 | 9251303 | 와 연기가 진짜 개쩔구나 지루할거라고 생각했는데 몰입해서 봤다 그래 이런게 진짜 영화지 | 1 | 연기 진짜 개쩔구 나 지루하 ᆯ 거 라고 생각 하 었 는데 몰입 하 어서 보 었 다... |
| 4 | 10067386 | 안개 자욱한 밤하늘에 떠 있는 초승달 같은 영화 | 1 | 안개 자욱하 ᆫ 밤하늘 뜨 어 있 초승달 같 영화 |
4.4. 훈련-테스트 데이터셋 분리
df_split=df_tokenize.copy()
train_data, test_data=train_test_split(df_split, test_size=0.3, random_state=42)
train_data.shape, test_data.shape((135462, 4), (58056, 4))X_train=train_data["token_document"].values
Y_train=train_data["label"].values
X_test=test_data["token_document"].values
Y_test=test_data["label"].values
X_train.shape, Y_train.shape, X_test.shape, Y_test.shape((135462,), (135462,), (58056,), (58056,))4.5. 정수형 인코딩
token=Tokenizer()
token.fit_on_texts(X_train)
total_count=len(token.word_index) # 단어의 수
total_count43331정수형 인코딩을 마친 단어의 수는 43331개. 빈도가 낮은 애들을 제외하자.
# 빈도수가 낮은, 1회인 단어들은 자연어 처리에서 제외
threshold=2
total_freq=0 # 훈련데이터의 전체 빈도수 총합
rare_count=0 # 희귀 단어 수: 빈도수가 threshold보다 낮은 단어의 수
rare_freq=0 # 희귀 단어 빈도수 합: 빈도수가 threshold보다 낮은 단어의 빈도수 총합
# word_counts: (단어, 빈도수) 쌍 -> .items()로 뽑아서 -> key와 value로 (key: 단어, value: 인덱스)
for key, value in token.word_counts.items():
total_freq += value # 빈도수 총합
if(value < threshold):
rare_count += 1 # threshold보다 낮은 단어의 개수
rare_freq += value # threshold보다 낮은 단어의 누적 합
print(f"전체 단어의 수: {total_count}\n")
print(f"빈도가 {threshold-1}번 이하인, 희귀 단어의 수: {rare_count}")
print(f"희귀 단어 비율 (희귀 단어 수/전체 단어 수): {(rare_count/total_count)*100}")
print(f"희귀 단어 빈도 비율 (희귀 빈도/전체 빈도): {(rare_freq/total_freq)*100}")전체 단어의 수: 43331
빈도가 1번 이하인, 희귀 단어의 수: 20915
희귀 단어 비율 (희귀 단어 수/전체 단어 수): 48.26798366065865
희귀 단어 빈도 비율 (희귀 빈도/전체 빈도): 1.0030564085544909빈도수 내림차순에 따라서 인덱스가 주어지기 때문에 전체단어카운트 - 희귀단어카운트 가 들어가고,
패딩과 OOV(Out Of Vocabulary)를 위한 자리(+2)를 마련 해주자.
vocab_size=total_count - rare_count + 2
vocab_size22418tokenizer=Tokenizer(num_words=vocab_size, oov_token="OOV")
tokenizer.fit_on_texts(X_train)
X_train=tokenizer.texts_to_sequences(X_train)
X_test=tokenizer.texts_to_sequences(X_test)
print(X_train[:3])[[1047, 443, 21, 17139, 317, 21, 17140, 17141, 3188, 9, 179, 8, 69, 45], [11020, 611, 21, 2410, 203, 20, 1635], [1, 1, 9147]]이제 maxlen을 설정하기 위해 리뷰의 최대 길이와 평균 길이 등을 확인해보자.
print("리뷰의 최대 길이: ", max(len(review) for review in X_train))
print("리뷰의 평균 길이: ", sum(map(len, X_train))/len(X_train))
plt.hist([len(review) for review in X_train], bins=50)
plt.xlabel("Length of Samples")
plt.ylabel("Number of Samples")
plt.show()리뷰의 최대 길이: 93
리뷰의 평균 길이: 15.39270791808773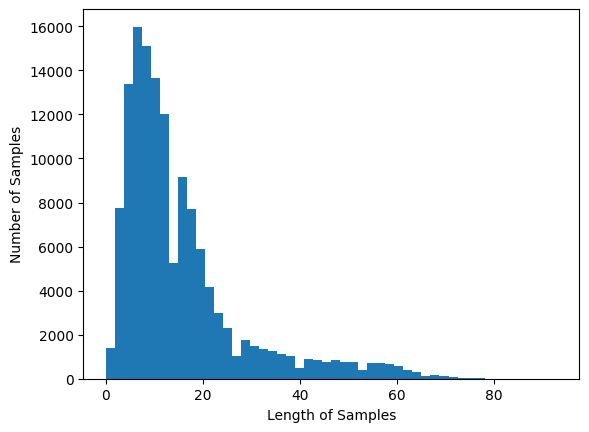
이제 패딩값을 고민을 좀 해봐야한다. 최대 93, 평균 15여서 차이가 좀 크다.
그러면 우선 시각적으로 봤을때 40 정도를 기준으로 둬서 비율을 확인해보자.
def under_max_len(max_len, X_trian):
count=0
for sentence in X_train:
if(len(sentence) <= max_len):
count=count+1
print(f"전체 샘플 중 {max_len} 이하인 샘플 비율: {(count/len(X_train))*100}")
max_len=40
under_max_len(max_len, X_train)전체 샘플 중 40 이하인 샘플 비율: 93.1907103099024이를 보니 40을 사용해서 패딩을 해주면 될 거 같다.
X_train=sequence.pad_sequences(X_train, maxlen=max_len)
X_test=sequence.pad_sequences(X_test, maxlen=max_len)4.6. 훈련 및 평가
model=Sequential()
model.add(keras.layers.Input(shape=(max_len, )))
model.add(keras.layers.Embedding(input_dim=vocab_size, output_dim=100)) # Embedding: 실수로 변환
model.add(keras.layers.LSTM(128, activation="tanh"))
model.add(keras.layers.Dense(1, activation="sigmoid"))esc=EarlyStopping(monitor="val_loss", verbose=1, patience=4)
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["acc"])
history=model.fit(X_train, Y_train, epochs=3, batch_size=64, validation_split=0.2, callbacks=[esc])Epoch 1/3
[1m1694/1694[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m101s[0m 58ms/step - acc: 0.7874 - loss: 0.4397 - val_acc: 0.8528 - val_loss: 0.3388
Epoch 2/3
[1m1694/1694[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m106s[0m 63ms/step - acc: 0.8751 - loss: 0.2928 - val_acc: 0.8584 - val_loss: 0.3267
Epoch 3/3
[1m1694/1694[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m95s[0m 56ms/step - acc: 0.9020 - loss: 0.2371 - val_acc: 0.8575 - val_loss: 0.3444model.evaluate(X_test, Y_test)[0.34854254126548767, 0.8532451391220093]4.7. 테스트 데이터
훈련 데이터와 같은 방식으로 바꿔주자.
def movie_review_sentiment_pred(new_sentence):
# 전처리
new_sentence=re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣 ]', '', new_sentence) # 정규 표현식
new_sentence=[token.form for token in kiwi.tokenize(new_sentence)] # 토큰화
new_sentence=[word for word in new_sentence if word not in stopwords] # 불용어 제거
encoded=tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩
pad_new=pad_sequences(encoded, maxlen=max_len) # 패딩 -> maxlen=40
score=float(model.predict(pad_new)[0][0])
if(score > 0.5):
print(f"긍정 확률 {score*100:.2f}% vs " + f"부정 확률 {(1-score)*100:.2f}%")
print(f"긍정 리뷰 입니다.")
else:
print(f"긍정 확률 {score*100:.2f}% vs " + f"부정 확률 {(1-score)*100:.2f}%")
print(f"부정 리뷰 입니다.")movie_review_sentiment_pred("몰입감 미침")긍정 확률 98.76% vs 부정 확률 1.24%
긍정 리뷰 입니다.movie_review_sentiment_pred("미친 라인업에 정신나간 대본 뿌리기")긍정 확률 0.25% vs 부정 확률 99.75%
부정 리뷰 입니다.