1. 로이터 뉴스 분류
이전 글에서는 간단하게 한번 해봤고, 이번에는 keras에서 제공하는 로이터 뉴스 분류 실습을 진행해보자.
11000개 정도의 뉴스 기사가 있고, 46개의 뉴스 카테고리로 분류 되어있다.
이는 전처리가 다 끝났고, 형태소 분류도 되어있다.
1.1. 데이터 전처리
(X_train, Y_train), (X_test, Y_test)=reuters.load_data(num_words=1000, test_split=0.2)
X_train.shape, Y_train.shape, X_test.shape, Y_test.shape((8982,), (8982,), (2246,), (2246,))인덱스값 자체를 1번지부터 1000번지 까지 가져온다는 건데,
11000개 중에서 자주 등장하는 상위 1000개만 가져온다.
이를 전체를 다 가져오면 메모리 문제로 다 돌아가지 않는다.
print(np.max(Y_train)+1)
print(type(X_train), type(Y_train))46
<class 'numpy.ndarray'> <class 'numpy.ndarray'>이번에는 판다스가 아닌 넘파이 배열로 처리한다.
print("첫번째 훈련용 뉴스 기사: ", X_train[0]) # 전처리 끝난 후, 토큰화 후 정수 인코딩 까지 한 내용
print("\n첫번째 훈련용 뉴스 기사의 길이: ", len(X_train[0]))
print("\n첫번째 훈련용 뉴스 기사의 레이블: ", Y_train[0])첫번째 훈련용 뉴스 기사: [1, 2, 2, 8, 43, 10, 447, 5, 25, 207, 270, 5, 2, 111, 16, 369, 186, 90, 67, 7, 89, 5, 19, 102, 6, 19, 124, 15, 90, 67, 84, 22, 482, 26, 7, 48, 4, 49, 8, 864, 39, 209, 154, 6, 151, 6, 83, 11, 15, 22, 155, 11, 15, 7, 48, 9, 2, 2, 504, 6, 258, 6, 272, 11, 15, 22, 134, 44, 11, 15, 16, 8, 197, 2, 90, 67, 52, 29, 209, 30, 32, 132, 6, 109, 15, 17, 12]
첫번째 훈련용 뉴스 기사의 길이: 87
첫번째 훈련용 뉴스 기사의 레이블: 3print("두번째 훈련용 뉴스 기사: ", X_train[1])
print("\n두번째 훈련용 뉴스 기사의 길이: ", len(X_train[1]))
print("\n두번째 훈련용 뉴스 기사의 레이블: ", Y_train[1])두번째 훈련용 뉴스 기사: [1, 2, 699, 2, 2, 56, 2, 2, 9, 56, 2, 2, 81, 5, 2, 57, 366, 737, 132, 20, 2, 7, 2, 49, 2, 2, 2, 2, 699, 2, 8, 7, 10, 241, 16, 855, 129, 231, 783, 5, 4, 587, 2, 2, 2, 775, 7, 48, 34, 191, 44, 35, 2, 505, 17, 12]
두번째 훈련용 뉴스 기사의 길이: 56
두번째 훈련용 뉴스 기사의 레이블: 4이제 X_train[0]과 [1]이 형태소로 나눈 단어 하나하나다.
뉴스 기사이기 때문에 길게 나오는 것은 당연하다.
물론 더 길수도 있다.
이제 패딩 후 훈련을 해주면 되기 때문에 우선 최대 길이와 평균 길이를 확인해보자.
# 이는 판다스가 아니라 numpy이기 때문에 for로 돌려야한다.
# -> 제너레이터 표현식(generator expression)
print("뉴스 기사의 최대 길이: {}".format(max(len(sample) for sample in X_train)))
# 풀어쓰면 다음과 같음
# len_=[]
# for sample in X_train:
# len_.append(len(sample))
# max_len=max(len_)
# print(f"뉴스 기사의 최대 길이: {max_len}")
# !! 중요 ==================================================
# map함수: X_train의 각 요소(뉴스 기사)에 대해 len()을 적용함 -> 길이 리스트를 생성하는 반복자(iterator)
# sum함수: map 객체로부터 하나씩 꺼내서 모두 더함
# /len(X_train): 전체 개수로 나눠서 평균 계산
print("뉴스 기사의 평균 길이: {}".format(sum(map(len, X_train))/len(X_train)))
# 풀어쓰면 다음과 같음
# total_len=0
# for sample in X_train:
# total_len += len(sample)
# avg=total_len/len(X_train)
# print(f"뉴스 기사의 평균 길이: {avg}")뉴스 기사의 최대 길이: 2376
뉴스 기사의 평균 길이: 145.5398574927633⭐ 제너레이터 표현식 vs 컴프리헨션
해당 내용을 잘 정리해 놓은 글을 참고하자.
https://oculus.tistory.com/96
⭐ map() 추가 설명
- map(len, X_train):
X_train의 각 요소(뉴스 기사)에 대해 len()을 적용함
-> 길이 리스트를 생성하는 반복자(iterator)- e.g.,
X_train = [[1, 2], [3, 4, 5], [6]]
-> map(len, X_train) -> [2, 3, 1]
-> sum = 6
-> 평균 = 6 / 3 = 2.0
이제 시각화를 해보는데, 판다스에서는 x, y만 지정해줬으면 되는데 지금은 아래와같이 사용해야한다.
plt.hist([len(sample) for sample in X_train], bins=50)
plt.xlabel('샘플의 길이')
plt.ylabel('샘플의 수')
plt.show()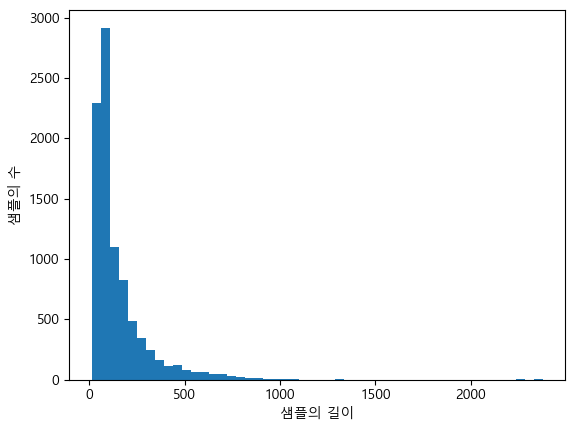
100~200 사이의 길이를 가진 뉴스들이 대부분이었다.
그리고 앞서 Y_train.shape을 보면 (8982,)로 나와 있는데,
이는 총 8982개의 뉴스 기사 샘플 각각에 대해 하나의 카테고리 정답(label) 이 할당되어 있다는 의미다.
그리고 이 레이블 값들은 1부터 시작해서, max가 45였기 때문에
총 뉴스 카테고리는 0 ~ 45까지로 하기 위해 max값+1을 두어 총 46개로 구성했다.
그렇다면 이렇게 총 46개의 카테고리 중
각 카테고리(label)가 데이터에 얼마나 포함되어 있는지도 확인해볼 수 있다.
이를 위해 np.unique()를 사용하면 고유한 레이블 값들과
각 레이블이 등장한 빈도수를 함께 확인할 수 있다.
# Y_train안에 있는 값들(뉴스 카테고리 번호들)을 중복 없이 뽑고
# 각각 몇 번 나오는지
unique_elements, counts_elements=np.unique(Y_train, return_counts=True) # tuple unpacking
print("각 레이블에 대한 빈도수")
unique_elements, counts_elements각 레이블에 대한 빈도수
(array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45]),
array([ 55, 432, 74, 3159, 1949, 17, 48, 16, 139, 101, 124,
390, 49, 172, 26, 20, 444, 39, 66, 549, 269, 100,
15, 41, 62, 92, 24, 15, 48, 19, 45, 39, 32,
11, 50, 10, 49, 19, 19, 24, 36, 30, 13, 21,
12, 18]))
# word_index=reuters.get_word_index() # 해당 단어가 몇번 등장했는지
# word_index # 너무 길어서 주석처리1.2. 학습 및 평가
그러면 이제 패딩을 진행하는데, maxlen을 잘 지정해줘야한다.
이번에는 평균이 140 정도니까 180으로 지정해서 진행한다.
원래는 비율을 봐가면서 해야하는데 지금은 간단하게 돌려본다.
X_train=sequence.pad_sequences(X_train, maxlen=180) # default: padding='pre': 180이 안되는 애들은 앞부분 0으로 채우기
# default: truncating='pre': 180 넘는 애들은 앞부분 부터 짜르기
X_test=sequence.pad_sequences(X_test, maxlen=180)model=Sequential()
model.add(keras.layers.Input(shape=(180,)))
model.add(keras.layers.Embedding(input_dim=1000, output_dim=128)) # 전체길이 1000, 실수형으로 바꾸기
model.add(keras.layers.LSTM(100, activation='tanh'))
model.add(keras.layers.Dense(46, activation='softmax'))
model.summary()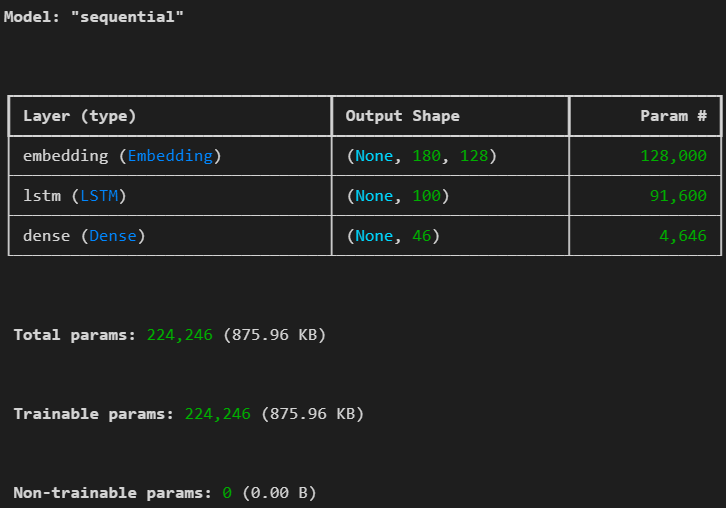
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
esc=EarlyStopping(monitor='val_loss', patience=5)
history=model.fit(X_train, Y_train, epochs=30, batch_size=128, validation_split=0.3, callbacks=[esc])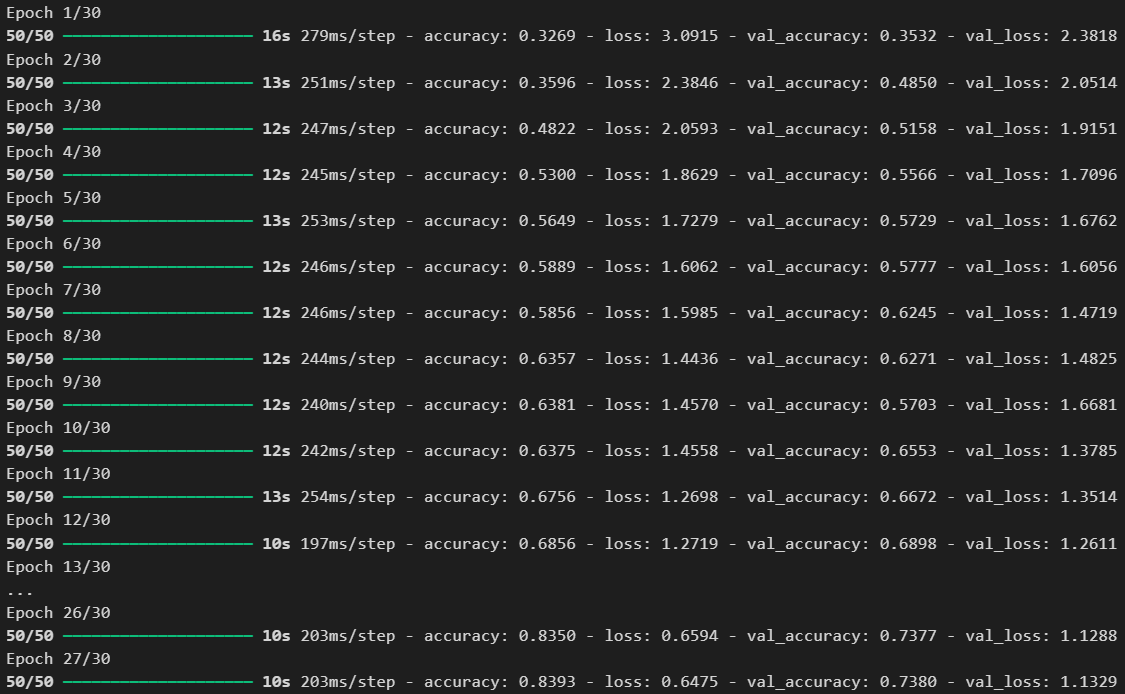
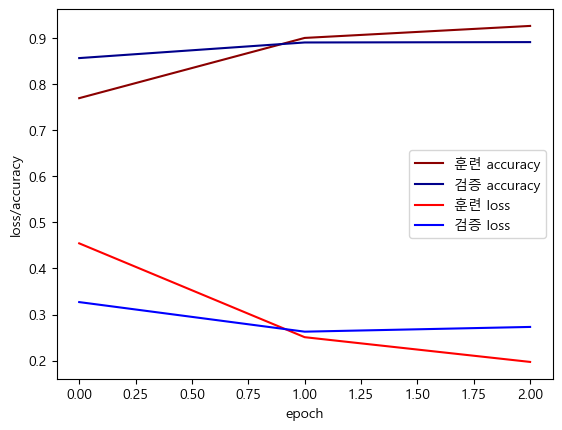
model.evaluate(X_test, Y_test)[1.1550880670547485, 0.7266250848770142]plt.plot(history.history['loss'], label='훈련 loss', c='red')
plt.plot(history.history['accuracy'], label='훈련 accuracy', c='darkred')
plt.plot(history.history['val_loss'], label='검증 loss', c='blue')
plt.plot(history.history['val_accuracy'], label='검증 accuracy', c='darkblue')
plt.xlabel('epoch')
plt.ylabel('loss/accuracy')
plt.legend()
plt.show()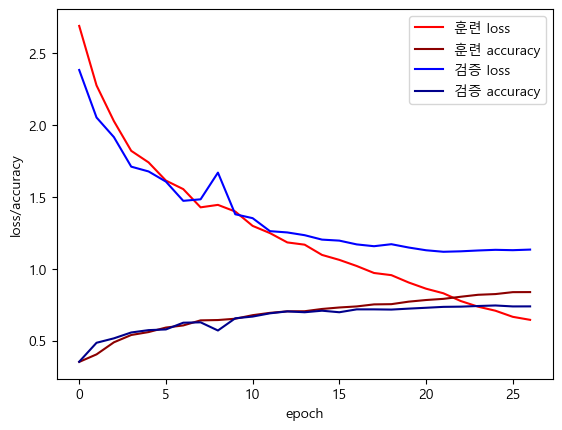
2. IMDB 리뷰 감성 분류
IMDB는 Movie Revies Sentiment Analysis을 말하며
스탠포드 대학에서 2011년에 낸 논문: http://ai.stanford.edu/~amaas/papers/wvSent_acl2011.pdf
훈련:테스트 50:50 비율이며 긍부정 1/0이다.
이 또한 케라스에서 제공한다.
2.1. 데이터 전처리
(X_train, Y_train), (X_test, Y_test)=imdb.load_data(num_words=5000)
X_train.shape, Y_train.shape, X_test.shape, Y_test.shape((25000,), (25000,), (25000,), (25000,))훈련과 테스트가 총 50000개 씩 있다.
num_words를 5000개로 걸면 shape를 5000개로 맞춰서 가져올거라고 생각하는데,
이는 내부적으로 단어 종류 수를 제한하는 것이다.
print("첫번째 훈련용 리뷰: ", X_train[0]) # 전처리가 끝난 정수형 인코딩
print("\n첫번째 훈련용 리뷰의 길이: ", len(X_train[0]))
print("\n첫번째 훈련용 리뷰의 레이블: ", Y_train[0])첫번째 훈련용 리뷰: [1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 22665, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 21631, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 19193, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 10311, 8, 4, 107, 117, 5952, 15, 256, 4, 31050, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 12118, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
첫번째 훈련용 리뷰의 길이: 218
첫번째 훈련용 리뷰의 레이블: 1print("훈련 데이터의 리뷰 최대 길이: {}".format(max(len(sample) for sample in X_train)))
print("훈련 데이터의 리뷰 평균 길이: {}".format(sum(map(len, X_train))/len(X_train)))
print("\n테스트 데이터의 리뷰 최대 길이: {}".format(max(len(sample) for sample in X_test)))
print("테스트 데이터의 리뷰 평균 길이: {}".format(sum(map(len, X_test))/len(X_test)))훈련 데이터의 리뷰 최대 길이: 2494
훈련 데이터의 리뷰 평균 길이: 238.71364
테스트 데이터의 리뷰 최대 길이: 2315
테스트 데이터의 리뷰 평균 길이: 230.8042plt.hist([len(sample) for sample in X_train], bins=50)
plt.xlabel('샘플 길이')
plt.ylabel('샘플 수')
plt.show()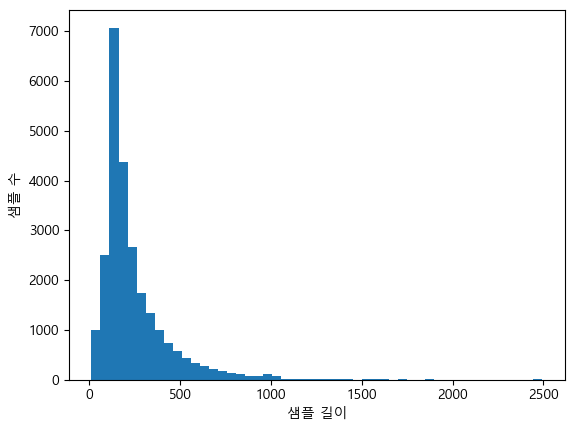
이번에는 거의 180~300 정도이다.
그렇다면 각 레이블에 대한 빈도수를 확인해보면,
unique_elements, counts_elements=np.unique(Y_train, return_counts=True)
print("각 레이블에 대한 빈도수")
#print(unique_elements)
#print(counts_elements)
print(np.asarray((unique_elements, counts_elements))) # 이렇게 정돈되게 표현할 수도 있다. 각 레이블에 대한 빈도수
[[ 0 1]
[12500 12500]]
딱 5:5로 잘 나와있다.
2.2. 학습 및 평가
이제 패딩을 해주는데, 그래프를 보니 500까지 어느정도 있기 때문에 maxlen, 리뷰의 최대 길이를 500 정도로 잡겠다.
X_train=sequence.pad_sequences(X_train, maxlen=500)
X_test=sequence.pad_sequences(X_test, maxlen=500)⭐ 주의점
이번에는 CNN을 사용해볼 예정인데 주의해야할 점이 있다.
자연어를 다룰때는 이미지를 다뤘던 2D가 아닌 1D로 가야한다.
이미지: (높이, 너비, 채널) -> 2D Convolution
텍스트: (단어 시퀀스 길이, 단어 벡터 차원) -> 1D Convolution
따라서 Conv1D, MaxPooling1D, LSTM 모두 1D 전용 레이어 사용해야 한다.Embedding을 거친 후 입력은 (500, 100) 크기의 2D 배열 (500단어 × 100차원 벡터)
이때 시퀀스 길이가 '시간축', output_dim이 '특징 채널' 역할을 한다.좀 더 정리하자면,
자연어 처리를 CNN으로 다룰 때는 이미지와 달리 1D 구조를 사용해야 하며,
Conv1D와 MaxPooling1D 같은 1D 전용 레이어를 사용해야 한다.
Conv1D는 단어 간의 국소적인 특징을 추출하는 데 유용하며,
이후 LSTM을 추가하면 문맥 정보(순서)까지 함께 학습할 수 있다.
마지막에는 sigmoid를 이용해 이진 분류를 수행한다.
model=Sequential()
model.add(keras.layers.Input(shape=(500,)))
# input_dim=5000: 너무 길어서 전체 단어 수 중에서 상위 5000개 단어만 사용
# 주의!!
# 앞서 그냥 load_data()로 사용했는데 이렇게하면 에러가 발생함!!
# 지금 input_dim=5000으로 뒀는데, 이건 단어 인덱스가 0부터 4999까지만 허용되는 것
# 그런데 load_data()를 그냥 사용할 경우에는 전체 단어 인덱스를 다 포함해서 가져오게 됨
# IMDB 원본 데이터는 단어 인덱스가 최대 88000 이상까지 존재
# 따라서 5000 이상 값이 X_train에 포함되면 Embedding 레이어에서 index out of range 에러가 내부적으로 발생
# 그래서 num_words=5000로 load_data를 해서 상위 5000개의 자주 쓰이는 단어만 포함해서 데이터를 가져오면
# 최대 인덱스가 4999 이하로 보장됨 -> input_dim=5000과 일치
# output_dim=100: 각 단어를 100차원 실수 벡터로 표현
model.add(keras.layers.Embedding(input_dim=5000, output_dim=100))
# 과적합을 방지하기 위해 임베딩된 일부 뉴런을 무작위로 50% 제거
model.add(keras.layers.Dropout(0.5))
# 실수형태로 Conv로 넘어옴
# 커널 사이즈가 5라는 건, 5개의 연속된 단어에서 특징을 뽑는다는 의미다.
# 64개의 필터를 통해 다양한 특징 추출
model.add(keras.layers.Conv1D(64, kernel_size=5, activation='relu'))
# 풀링 사이즈가 4라는 건, 4개의 단어 단위로 특징 중 최대값만 추출해서 시퀀스를 줄인다는 의미
model.add(keras.layers.MaxPooling1D(pool_size=4)) # 열 4개
# 최종값을 가지고 LSTM으로
# Conv1D는 국소적 특징(근처 단어)을 뽑아서 모델이 중요한 특징을 먼저 학습한다.
# 그 후 LSTM은 이 특징을 바탕으로 긴 시퀀스에 걸친 의존성을 학습하는 것이다.
# 그래서 LSTM은 전체 시퀀스의 흐름과 문맥(순서 정보)를 잘 반영한다.
# -> 그래서 둘을 함께 쓰면 "단어 패턴 + 문맥 정보"를 모두 반영할 수 있다.
model.add(keras.layers.LSTM(55, activation='tanh'))
model.add(keras.layers.Dense(1, activation='sigmoid')) # 긍정/부정
model.summary()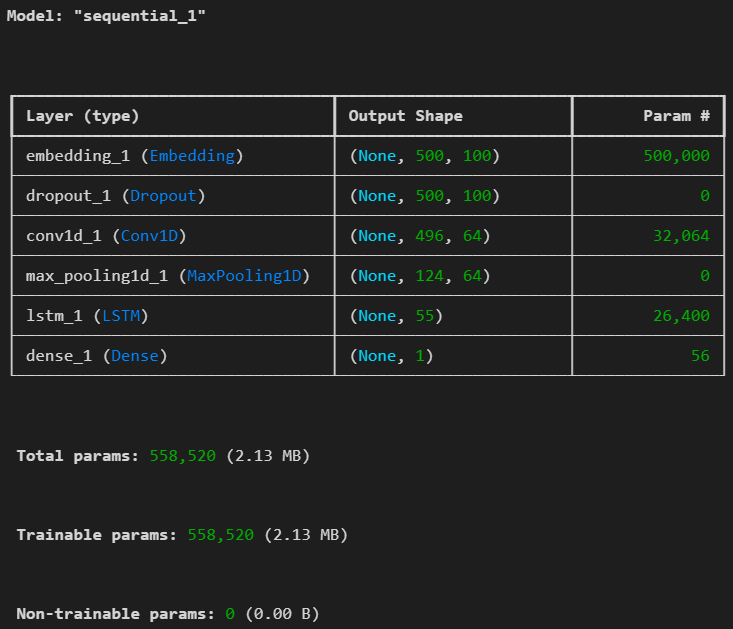
# 이진 분류 -> binary_crossentropy 사용
# 다중 클래스 분류 (원핫 인코딩) -> categorical_crossentropy
# 다중 클래스 분류 (정수 인코딩) -> sparse_categorical_crossentropy
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
esc=EarlyStopping(monitor='val_loss', patience=5)history=model.fit(X_train, Y_train, epochs=3, batch_size=64, validation_split=0.25, callbacks=[esc])Epoch 1/3
[1m293/293[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m36s[0m 114ms/step - accuracy: 0.6550 - loss: 0.5767 - val_accuracy: 0.8570 - val_loss: 0.3270
Epoch 2/3
[1m293/293[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m31s[0m 107ms/step - accuracy: 0.9015 - loss: 0.2561 - val_accuracy: 0.8909 - val_loss: 0.2628
Epoch 3/3
[1m293/293[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m33s[0m 113ms/step - accuracy: 0.9331 - loss: 0.1877 - val_accuracy: 0.8917 - val_loss: 0.2730model.evaluate(X_test, Y_test)782/782 ━━━━━━━━━━━━━━━━━━━━ 16s 20ms/step - accuracy: 0.8795 - loss: 0.2958
[0.29275086522102356, 0.8817999958992004]plt.plot(history.history['accuracy'], label='훈련 accuracy', c='darkred')
plt.plot(history.history['val_accuracy'], label='검증 accuracy', c='darkblue')
plt.plot(history.history['loss'], label='훈련 loss', c='red')
plt.plot(history.history['val_loss'], label='검증 loss', c='blue')
plt.xlabel('epoch')
plt.ylabel('loss/accuracy')
plt.legend()
plt.show()