
연구 주제를 찾으면서 icra2024논문을 뒤져보던중 재밌어 보이는 논문을 발견하여 리뷰를 진행했습니다.. 많이 모른다는 것을 알게된 논문 이었습니다. 내용이 부정확할 수 있으니 주의해주세요!!
Traditional & Proposal
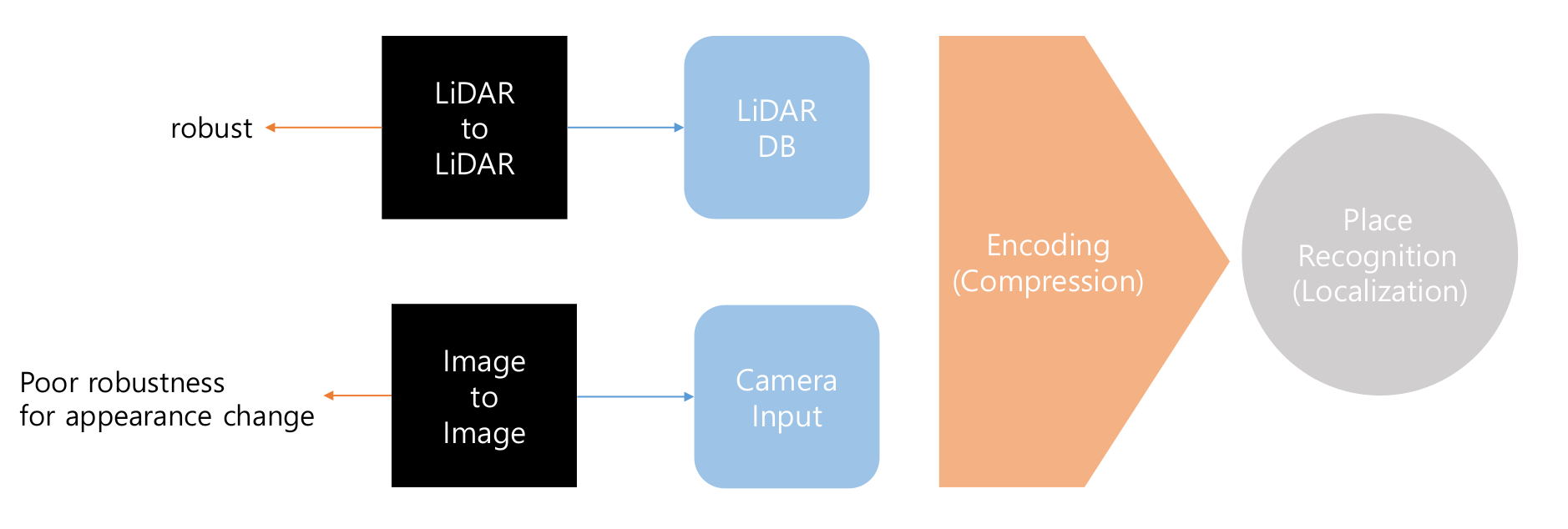
이 논문에서는 image to image querying 방식 혹은 LiDAR to LiDAR querying을 통해 해결하던 place recognition 문제를 image to LiDAR querying방식을 통해 해결하는 방법에 대해서 설명합니다.
크게, image to image방식에서는 햇빛 날씨 등에 민감하다는 이미지의 단점을 LiDAR DB로 구성된 map 에서는 비교적 강인하고 정확한 방식의 map을 구성할 수 있다는 장점을 이용하여 보완하고자 했습니다.
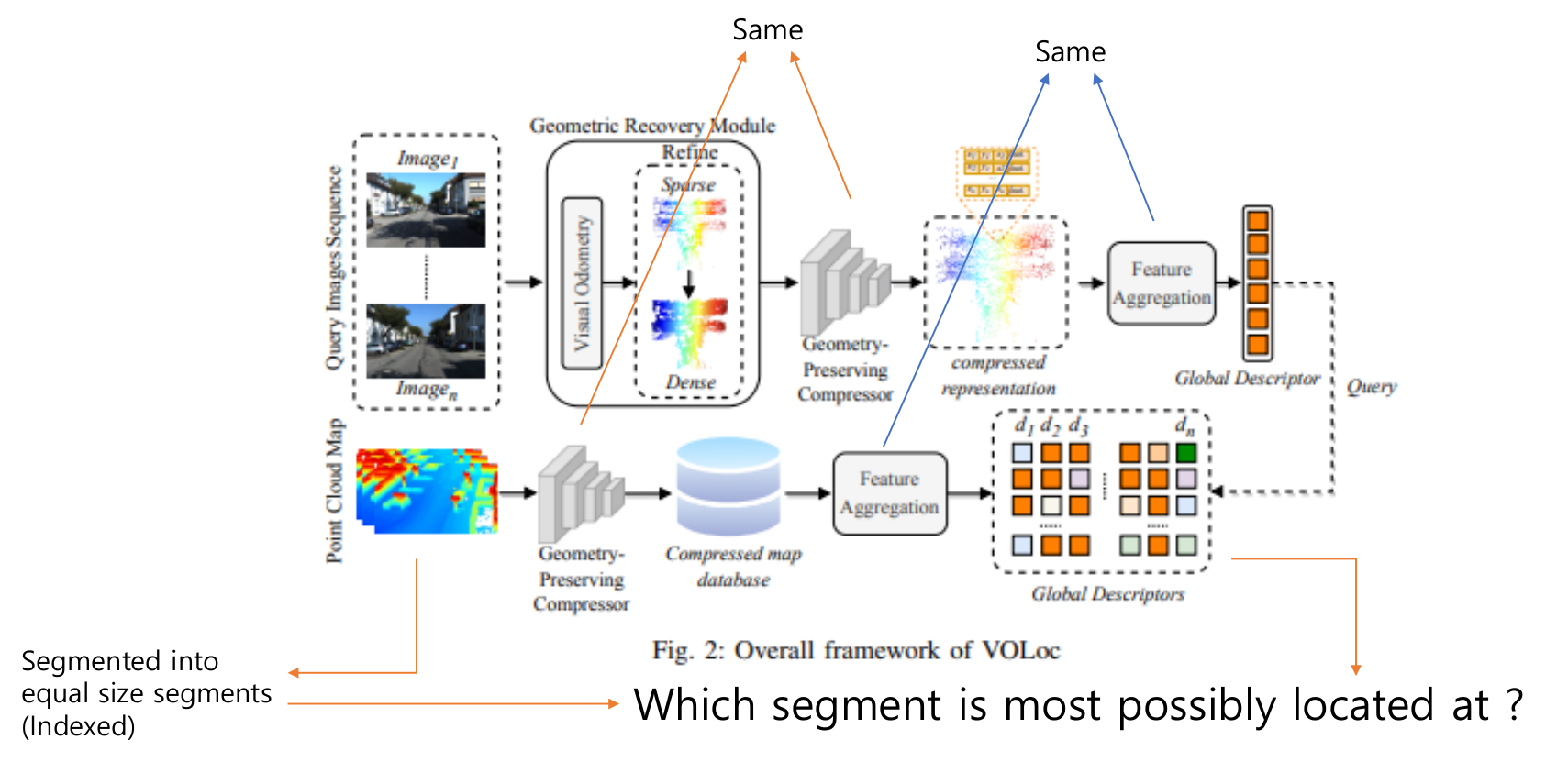
이 논문에서는 라이다 맵을 일정한 크기로 segmetation을 진행한 후, pre-train된 encoder를 이용하여 압축하여 global descriptor를 만들고, Visual Odometry(VO)의 output을 interpolation을 진행하여 해당 결과를 encoder를 이용하여 descriptor를 만들어 비교하는 방식으로 진행됩니다.
This paper proposes using image-to-LiDAR querying to solve the Visual Place Recognition (VPR) problem. Traditional image-to-image querying suffers from poor robustness against changes in illumination and weather. To address these issues, this paper proposes an image-to-LiDAR querying process.
For the introduction, VOLoc segments LiDAR maps and utilizes an encoder to extract geometrical features and create a global descriptor. Image input passes through Visual Odometry (VO) and is interpolated to be used as an encoder input (sparse VO output -> dense point cloud). After encoding, the image can be used as a descriptor, and the problem can be formulated by calculating the Euclidean distance between the descriptor and the global descriptor.
Method
Problem Description & Overview
위에서 간단하게 설명한 바와 같이, 문제는 global descriptor 와 이미지를 통과한 결과 사이의 유클라디안 거리를 이용하여 표현됩니다. 전체적으로 설명하자면 밑과 같습니다.
Image process(online) :
1. 이미지 입력을 VO의 입력으로 사용. 해당 이미지는 sparse하므로 interpolation과정을 거침
2. dense해진 pointcloud 를 이용하여 Geometry Preserving Comprocessor(GPC)의 입력으로 이용함
3. GPC의 결과를 feature aggregation과정을 통해 descriptor를 생성함
LiDAR process(offline) :
1. camera에서 사용한 것과 동일한 GPC를 이용하여 geometrical feature를 추출함.
2. database에 저장
3. feature aggregation모듈을 이용하여 global descriptor를 생성함
해당 논문의 point부분은 feature aggregation모듈에서 attention메커니즘을 이용한다는 것입니다. attention내용에 대한 내용에 대해 이 포스트에서 다루지만, 제 앎의 부족으로 깊게는 다루지 못했습니다...! :(
Like the brief introduction, the problem can be described as finding the Euclidean distance between the global descriptor from an image and the global descriptors from LiDAR.
The overall process of VOLoc is:
Image Process (online):
- The input image passes through the Visual Odometry (VO) algorithm, producing an interpolated point cloud.
- The dense point cloud is used as input for the Geometry Preserving Compressor (GPC).
- The output of the GPC passes through the feature aggregation module to generate a global descriptor.
LiDAR Process (offline):
- Apply the GPC to extract geometrical features.
- Use the feature aggregation module to generate global descriptors.
The feature aggregation module and GPC are used in both the image process and the LiDAR process. The key component of this paper is the feature aggregation module, which utilizes an attention mechanism. However, I must admit that my understanding of this post is limited, and I lack confidence in fully grasping the details.
Geometry Preserving Comprocessor (GPC)
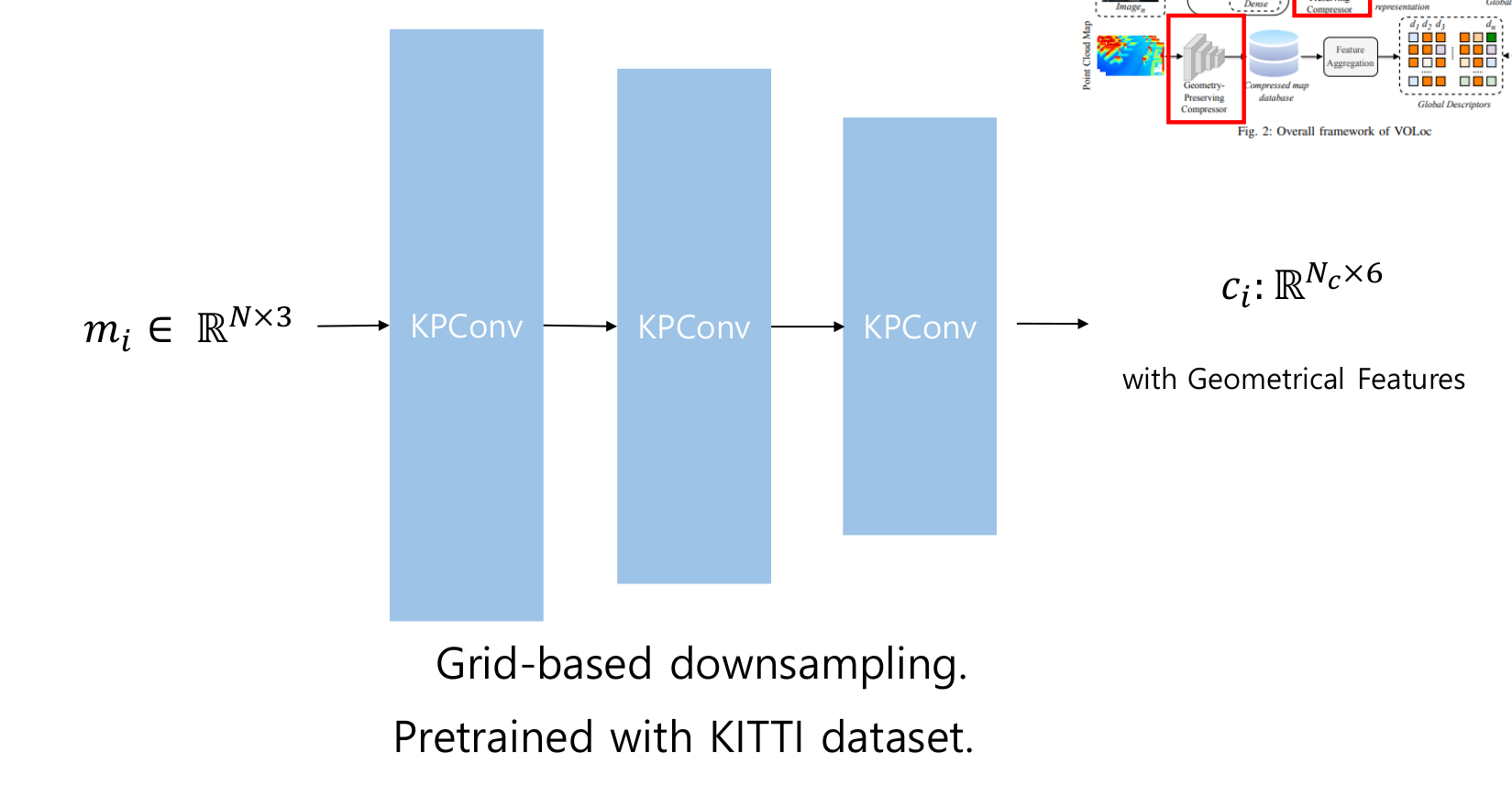
이 논문에서는 위처럼 구성된 GPC를 이용합니다. KPConv레이어 3개를 이용하여 encoder를 구성하고 학습 과정에서는 4개의 층으로 구성된 decoder를 이용하여 학습을 진행하였습니다. 입력을 에서 압축을 통해 크기로 압축을 합니다.
해당 압축 방법은 geometric feature의 손상이 적도록 하는 방법이고, feature aggregation모듈과 함께 사용하여 direct querying을 할 수 있도록 합니다.
해당 방법은 grid based downsampling을 이용하는데, Furthest Point Sampling방식보다 더욱 효과적이라고 합니다.
The GPC consists of three KPConv layers. The GPC is utilized as an encoder for point clouds to extract geometric features. During the learning process, a four layer is used for decoding.
This compression process allows for the preservation of geometric features, which can then be utilized with feature aggregation for direct querying.
This GPC uses grid-based downsampling, which is more efficient than Furthest Point Sampling.
Geometric Recovery Module (GRM)
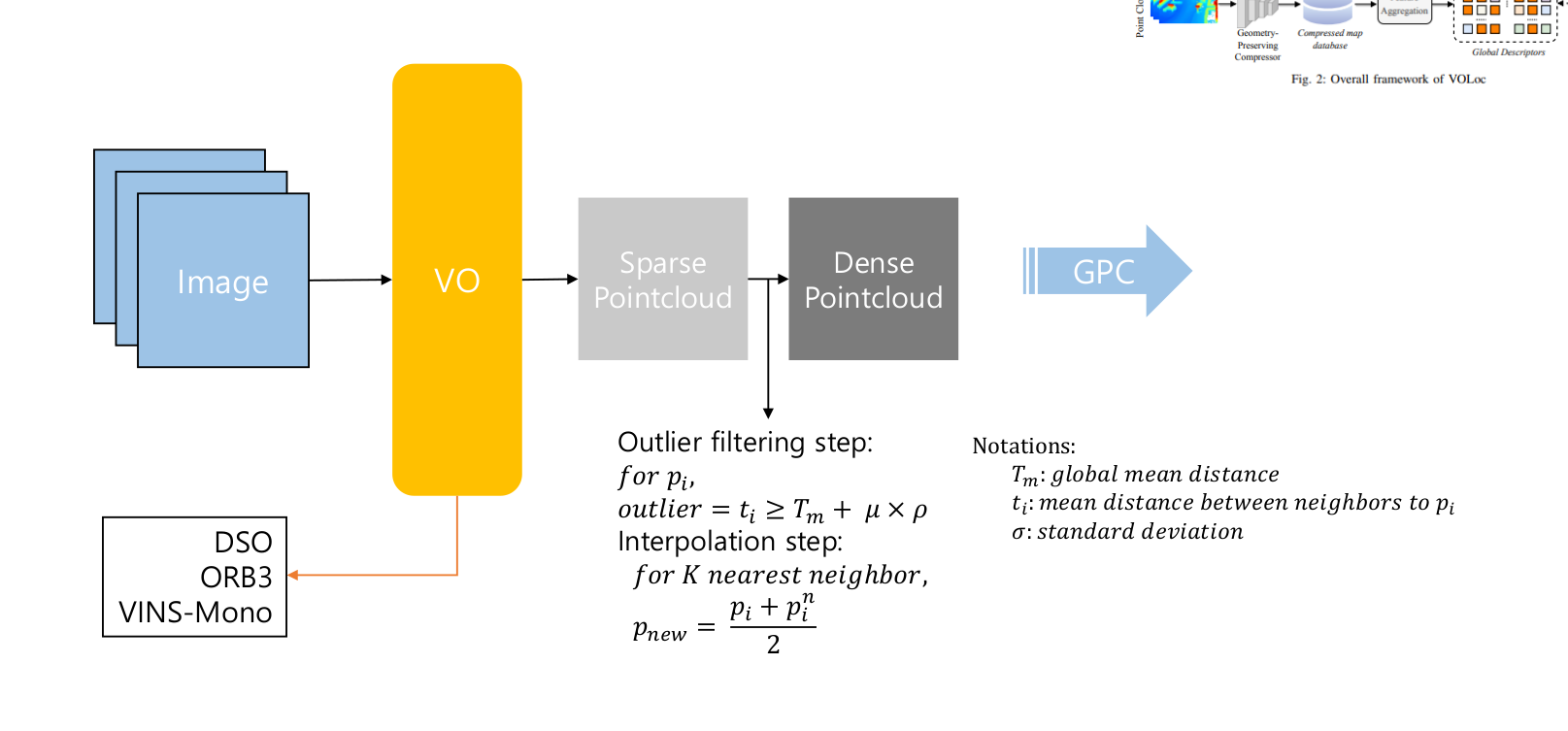
GRM에서는 VO의 출력 pointcloud를 dense하게 만들어 줍니다. 해당 과정에서 traditional한 방법에서는 모든 pointcloud를 이용하는 방식으로 interpolation과정을 진행했지만, 이 논문에서는 해당 방법이 outlier 나 noise를 포함하게되는 단점을 언급하고 K-NN알고리즘을 KDTree를 이용하여 적용 후 각 point들의 평균 거리와 어떤 두 point간의 거리 비교를 통해 noise와 outlier를 제거하는 방식을 적용한 후 interpolation을 진행합니다.
식은 위 figure의 내용과 같습니다.
논문에서 사용한 VO알고리즘으로는 DSO, ORB-SLAM3, VINS-Mono이고 여러가지 VO를 적용해 봄으로 더 다양한 알고리즘에 적용이 가능하다는 점을 언급합니다.
The GRM alternates the sparse point cloud output from the VO to a dense point cloud. Traditional approaches utilize all of the VO's output point clouds, but this approach has issues with handling outliers and noise points. For these reasons, this paper utilizes K-NN with Euclidean distance and KDTree to filter out noise and outlier points. After filtering, the GRM interpolates the sparse point cloud to obtain a dense point cloud using K nearest neighbors.
The details of the notations are shown in the figure above.
This paper adopts three VO algorithms (ORB-SLAM3, DSO, VINS-Mono), allowing it to be adapted to multiple algorithms.
Global feature aggregation
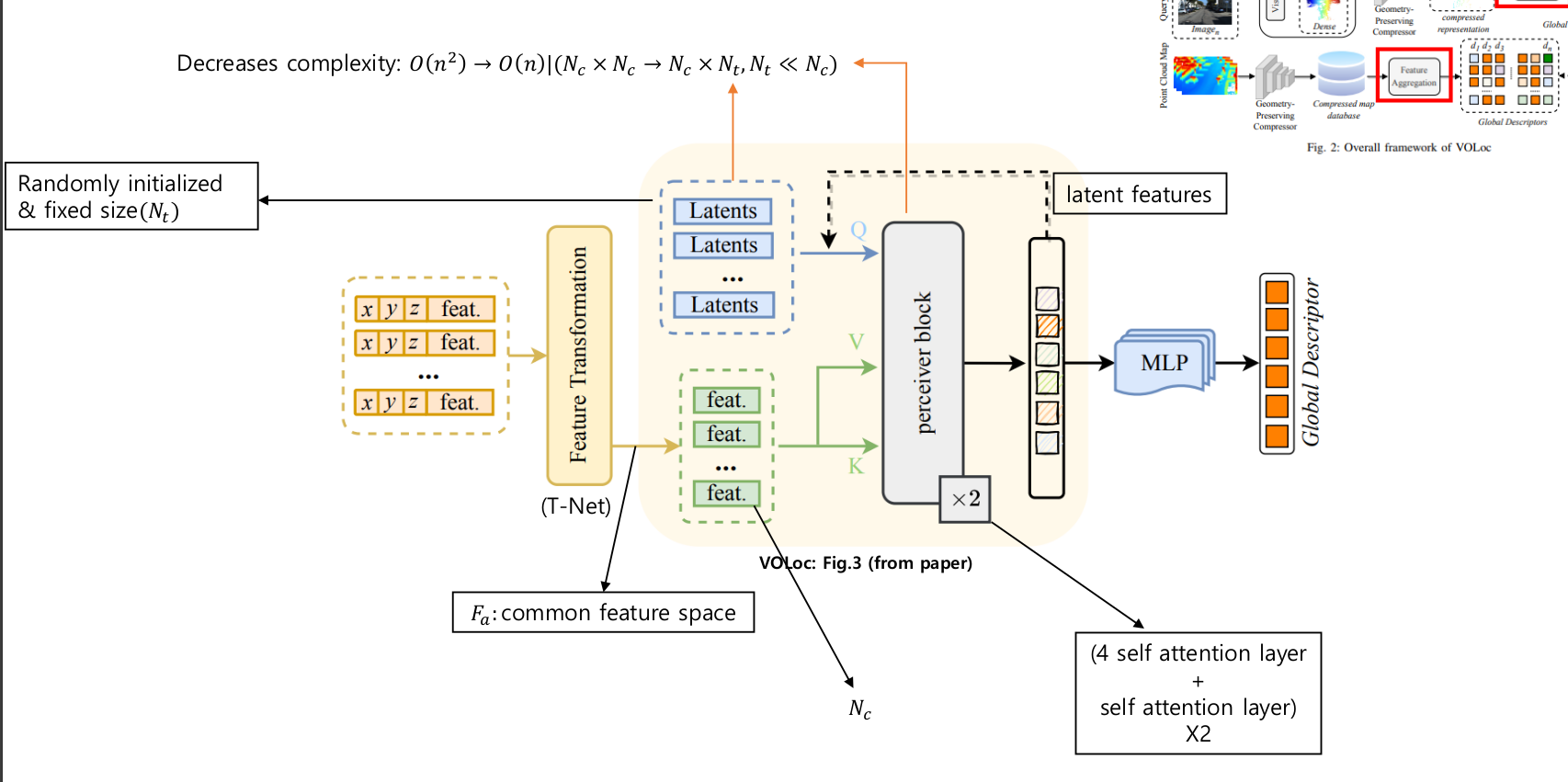
Global feature aggregation 단계에서는 GPC의 출력에 나온 geometric feature들을 이용하여 attention모듈의 학습에 이용합니다. 모든 feature들을 같은 feature space로 나타내기 위해 T-Net을 이용합니다. 해당 층을 통과한 feature들은 K행렬과 V행렬에 곱해지고, Q행렬에 곱해지는 Latentes 벡터의 경우엔 무작위 초기화된 고정길이 벡터로, 학습에 따라 옳바른 값으로 바뀌게 됩니다.
위와 같은 attention구조를 perciever-like attention이라고 하고, attention score matrix가 인 기존 방법을 로 시간 복잡도를 낮출 수 있습니다.
Perciever block은 4개의 cross-attention layer와 1개의 self-attention layer로 이루어진 블럭이 2개 존재합니다.
Latent feature는 이후 MLP의 입력으로 사용되어 global descriptor를 만드는데 이용됩니다. MLP에서는 Lazy quardruplet loss를 이용하여 학습을 진행합니다.
In the Global feature aggregation step, the geometric features output from the GPC are used to train the attention module. To represent all features in the same feature space, a T-Net is used. The features passing through this layer are multiplied by the K and V matrices, while the Latent vector multiplied by the Q matrix is a randomly initialized fixed-length vector that adjusts to the correct values through training.
This attention structure is called perceiver-like attention, and it reduces the time complexity by changing the attention score matrix from in traditional methods to
The Perceiver block contains two blocks, each consisting of four cross-attention layers and one self-attention layer.
The Latent feature is then used as the input for the MLP to create the global descriptor. The MLP is trained using Lazy quadruplet loss.
Results
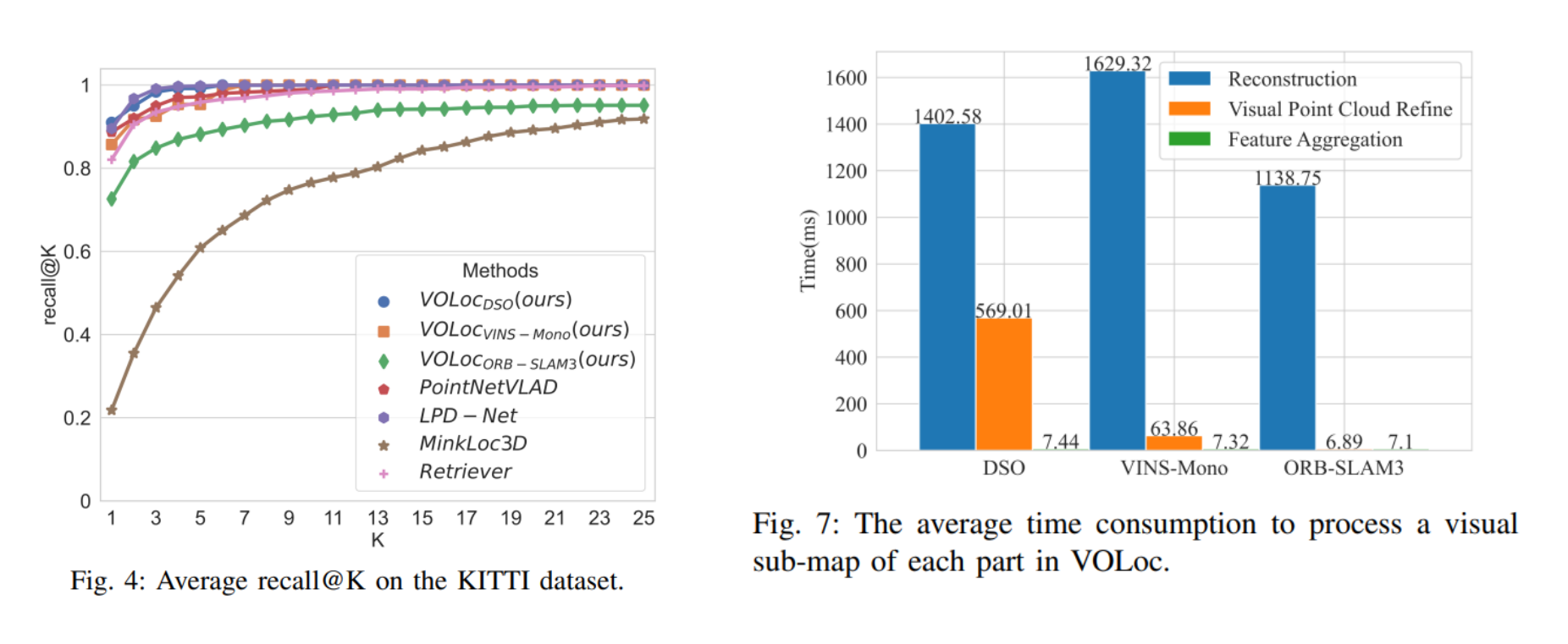
average recall@K 와 time consumption에 대한 결과 입니다.
LPD-Net에 준하는 성능을 보여주는 것을 확인할 수 있고, time consumption과 실행 결과를 고려했을 때 DSO와 함께 이용하면 준수한 성능을 보여줄 것을 유추할 수 있습니다.
The results of average recall@K and time consumption.
VOLoc performs comparably to LPD-Net. Considering both time consumption and performance, DSO can be a good choice for using the algorithm.
Review
구현을 해보려는 입장에서 논문을 읽으면서 실제 학습이 진행된 스펙이나 세부 파라미터들도 공개가 되었으면 하는 바람이 있었습니다. attention모듈에 대한 이해가 부족해 가장 중요하게 느껴진 feature aggregation 부분을 완벽하게 이해하지 못한 것에 대한 아쉬움이 남고, 해당 부분은 all you need is attention이라는 paper를 발견하여 그 문서를 읽고 다시한번 이해해 볼 예정입니다.
개인적으로 이해한 것을 바탕으로 작성된 포스트이고, 포스트에 나온 그림과 표는 논문과 직접 제작한 ppt를 기반으로 구성되어 있습니다.
From the perspective of someone trying to implement this, I wished that the specifications and detailed parameters used in the actual training process were disclosed in the paper. I feel disappointed that I couldn't fully understand the feature aggregation part, which seems the most crucial, due to my lack of understanding of the attention module. I plan to read the paper "All You Need Is Attention" to better understand this part.
This post is based on my personal understanding, and the images and tables in the post are composed based on the paper and the PPT I created.
