🏹 Intro
다음 두 가지 측면을 고려해서 데이터 모델을 작성했다.
SparkJob을 통해 데이터베이스에 데이터를 저장하기 위한 개념적 모델링과 논리적 모델링을 진행한다.
-
SparkJob을 통해 생성한 테이블을mysql에 저장한후, 서비스를 위한SQL문을 작성하는 과정에서 성능 향상을 위한인덱스설정과 같은물리적모델링을 진행하기로 한다. -
데이터 모델링을 진행하는 과정에서는
중복된데이터를 최소화 하고, 다른 테이블의join없이 각각의 테이블이 원하는 정보를 담고 있을 수 있도록 하는 것을 우선순위로 두었다.
🎯 데이터 분석을 위한 데이터 모델
- 이탈유저의 분류를 위한 데이터 모델링
- 패치에 따른
자유전직확인 및유저분포 시각화(직업및지역별 경험치 통계에서 반정규화를 통해 테이블을 따로 생성했다)
🎯 서비스를 위한 데이터 모델
- 직업별
사냥능력의 비교를 위한경험치 획득량비교
- 개인 경험치 획득량 추이 확인 및 예상 레벨업 일자 제공
- 일일 최고 경험치 획득
직업군or개인 랭킹
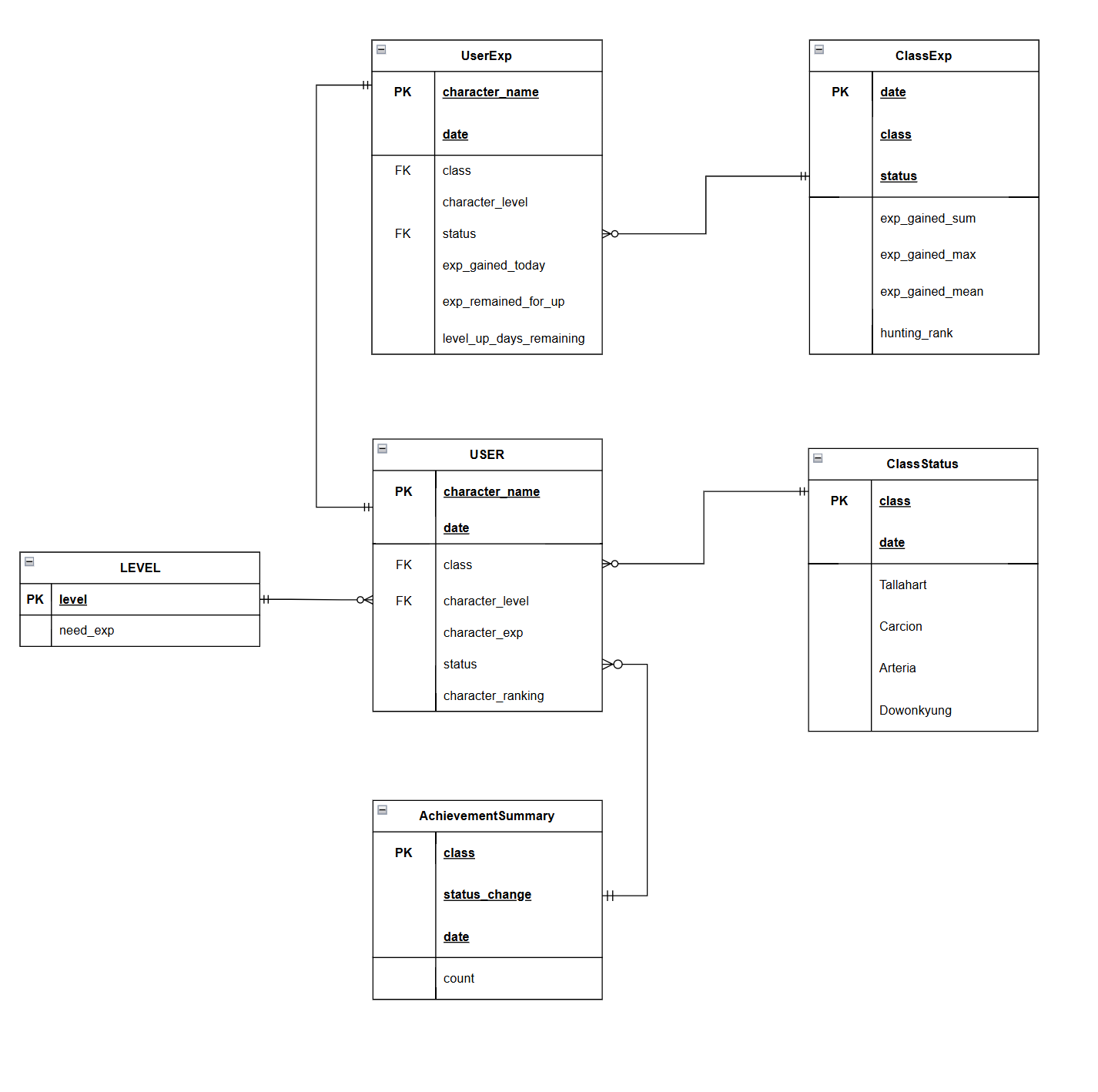
🏹 개념적 모델링
🎯 엔티티 기본 정의서
| 엔티티명 | 엔티티 설명 | 관련속성 |
|---|---|---|
| USER | API로부터 수집된 RAWDATA 이다.(DB에 따로 저장하지는 않는다.) | 캐릭터이름, 일자, 레벨, 직업, 보유경험치, 서버, 랭킹, 인기도 |
| LEVEL | 각 레벨에서 레벨업에 필요한 경험치의 양 | 레벨, 필요 경험치량 |
| UserExp | 유저별 경험치 통계량 | 캐릭터이름, 일자 레벨업에 필요한 경험치량, 금일 사냥으로 획득한 경험치량, 예상레벨업기간,직업,지역 |
| ClassExp | 직업및지역별 경험치 통계량 | 직업, 지역, 일자, 총 경험치 획득량, 최대 경험치 획득량, 획득 경험치 평균 |
| ClassStatus | 직업및지역별 유저분포 | Tallahart, Carcion, Arteria, Dowonkyung |
| AchievementSummary | 특정 지역 도달 상황 | count |
🎯 엔티티 간의 관계
| USER | LEVEL | UserExp | ClassExp | ClassStatus | AchievementSummary | |
|---|---|---|---|---|---|---|
| USER | - | 포함된다 | 생성한다 | - | - | 생성한다 |
| LEVEL | 포함한다 | - | - | - | - | - |
| UserExp | 생성된다 | - | - | 생성한다 | - | - |
| ClassExp | - | - | 생성된다 | - | 포함한다 | - |
| ClassStatus | - | - | - | 포함된다 | - | - |
| AchievementSummary | 생성된다 | - | - | - | - | - |
🏹 논리적 모델링
🎯 ERD 다이어그램