브라우저
브라우저(구글 크롬, 인터넷 익스플로러, 파이어폭스, 사파리, 오페라)의 주소창에 웹 주소를 입력하면 => 브라우저는 HTTP GET 요청을 웹 주소의 서버로 전송한다. => (보통 프론트엔드가 있는 웹 서비스의 경우) HTML 파일을 결과로 반환한다.
브라우저란 : 웹 서버와 통신하여 인터넷 사이트 및 다양한 컨텐츠를 볼 수 있도록 지원해주는 소프트웨어 프로그램이다.
브라우저의 기본 구조
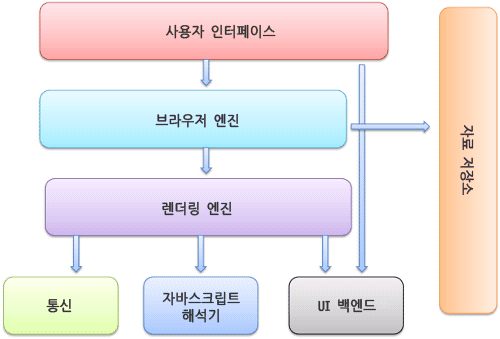
구조는 브라우저마다 조금씩 다를 수 있다.
- 사용자 인터페이스 - 주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등. 요청한 페이지를 보여주는 창을 제외한 나머지 모든 부분에 해당한다.
- 브라우저 엔진 - 사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어한다. Data storage 컴포넌트와 통신할 수 있다.
- 렌더링 엔진 - 요청한 콘텐츠를 표시. 예를 들어 HTML을 요청하면 HTML과 CSS를 파싱하여 요청받은 내용을 화면에 그려주는 일을 한다. 일반적으로 HTML+CSS를 보여주지만 플러그인의 도움으로 PDF, XML등의 문서도 나타낼 수 있다.
- 통신 - HTTP 요청과 같은 네트워크 호출에 사용된다.
- UI 백엔드 - 콤보 박스와 창 같은 기본적인 장치를 그린다. 플랫폼에서 명시하지 않은 일반적인 인터페이스로서, OS의 유저 인터페이스 메서드를 사용해 창이나 콤보박스, 체크박스 등의 기본적인 위젯을 그려준다.
- 자바스크립트 해석기(인터프리터) - 자바스크립트 코드를 해석하고 실행한다.
- 자료 저장소 - 이 부분은 자료를 저장하는 계층
브라우저의 작동원리

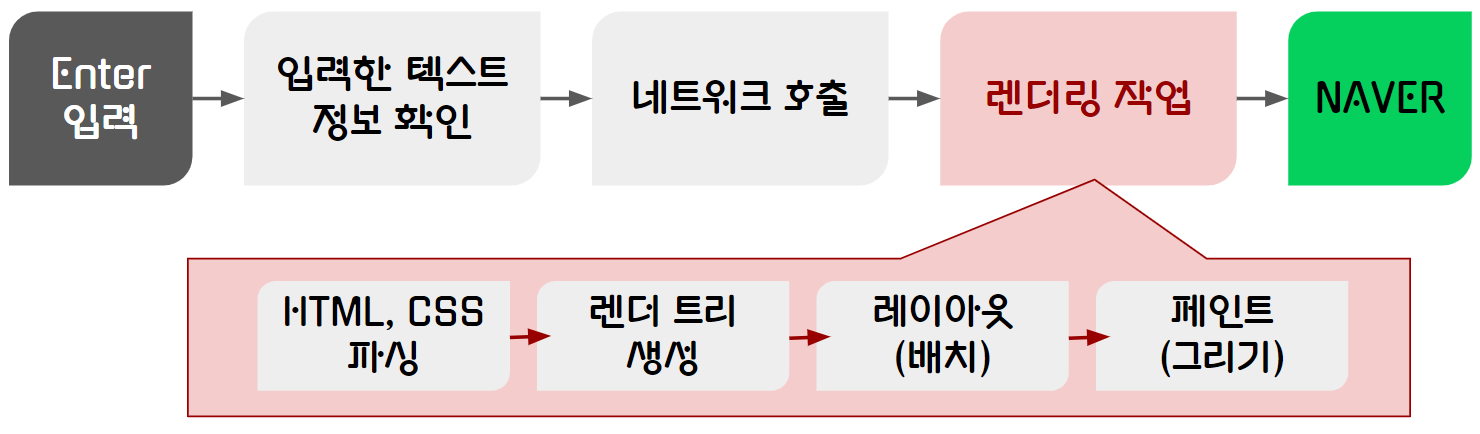
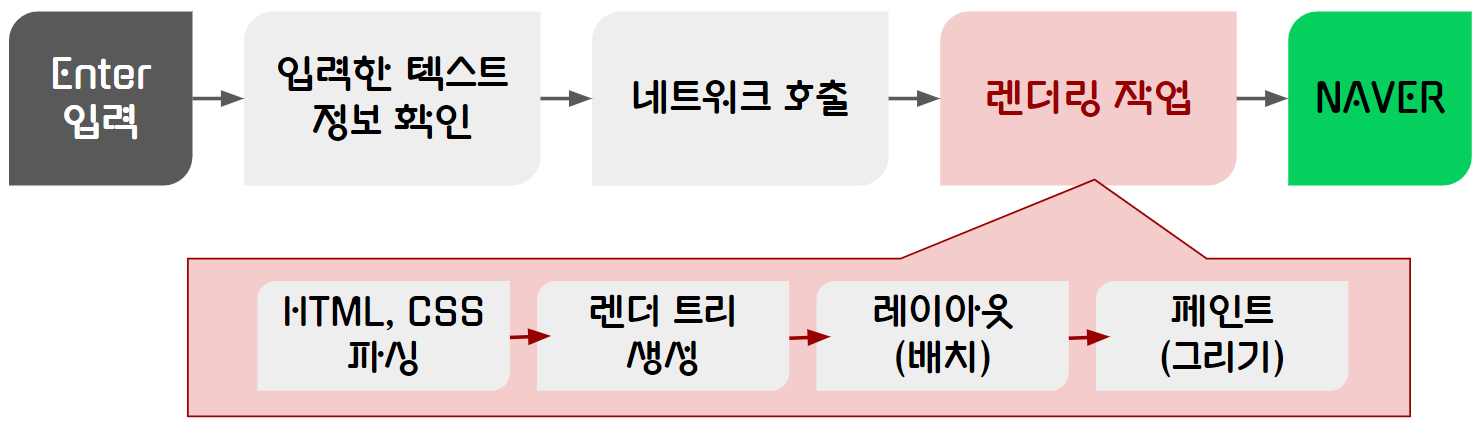
브라우저 주소창에 www.naver.com(웹 주소)을 검색하면?
1. 입력한 text 정보를 확인
- 내가 입력한 텍스트가 검색어인지, url 주소인지 확인한다.
- 대부분의 브라우저는 주소창을 검색엔진과 같이 사용한다. (크롬의 경우 검색어로 판단시 => 자동으로 구글 검색처럼 작동)
- url 주소일 경우 브라우저 엔진에게 네트워크 호출을 수행한다.
2. 네트워크 호출
2.1 IP주소 찾기
IP 주소 : 앞서 설명했듯이 사이트의 주소를 말한다.
DNS서버 : 도메인 주소에 대응하는 IP 주소를 찾아주는 역할을 수행한다.
인터넷 세상에서는 IP 주소를 기반으로 동작하지만 인간인 우리는 그것을 식별하기 어렵기 때문에 IP주소 대신 문자로 이루어진 도메인주소(naver.com)를 사용한다. 때문에 DNS서버가 필요!
IP 주소를 찾는 과정이다. 브라우저는 네이버 서버와 통신하여 데이터를 가져와야한다. 네이버 서버의 주소를 확인하기 위해 사용자(클라이언트)는 DNS 서버에 검색하기 전에 캐싱된 DNS 기록들을 먼저 확인한다. 만약 해당 도메인 (naver.com) 이름에 맞는 IP 주소 (125.209.222.142)가 존재하면, DNS 서버에 해당 도메인 이름에 해당하는 IP주소를 요청하지 않고 캐싱된 IP주소를 바로 반환한다. 만약 DNS 기록에 가려고 하는 URL과 일치하는 IP주소가 존재하지 않는다면 DNS 서버에 해당 사이트 IP주소를 요청한다.
2.2 HTTP 통신
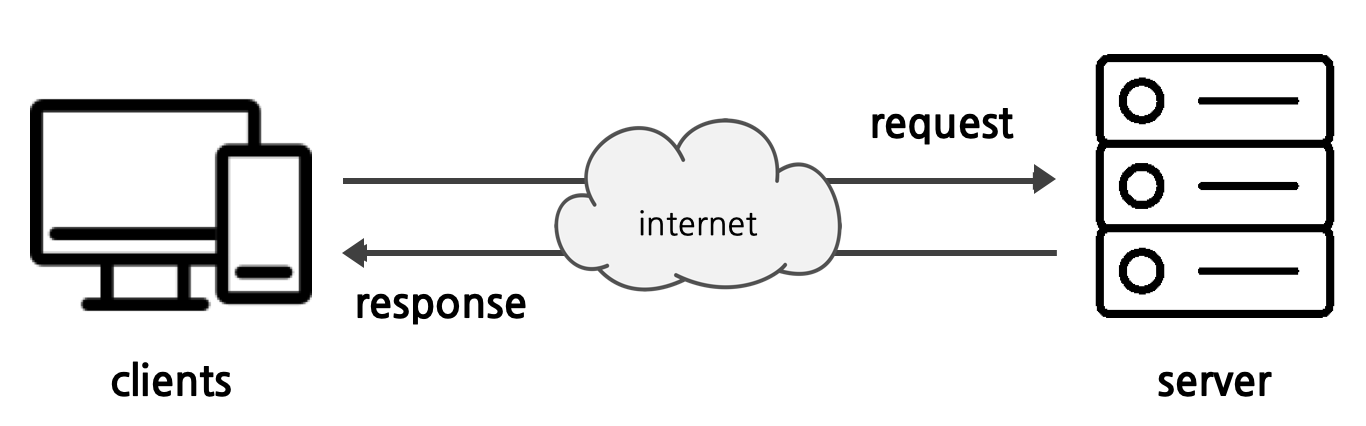
이제 브라우저가 네이버의 IP주소를 알게 되었으므로 네이버 서버와 통신할 수 있게 되었다! 클라이언트의 브라우저는 네이버 서버에 데이터를 요청하는 HTTP Request를 보낸다. request를 받은 네이버서버는 이를 바이트 형태 (1과 0으로 이루어짐) 로 변환하여, 클라이언트로 HTTP Response를 보낸다.
여기까지가 서버로부터 데이터를 불러와지는 과정이다!
이제 이 받아온 데이터를 화면에 그려야한다.!!
브라우저 렌더링 과정
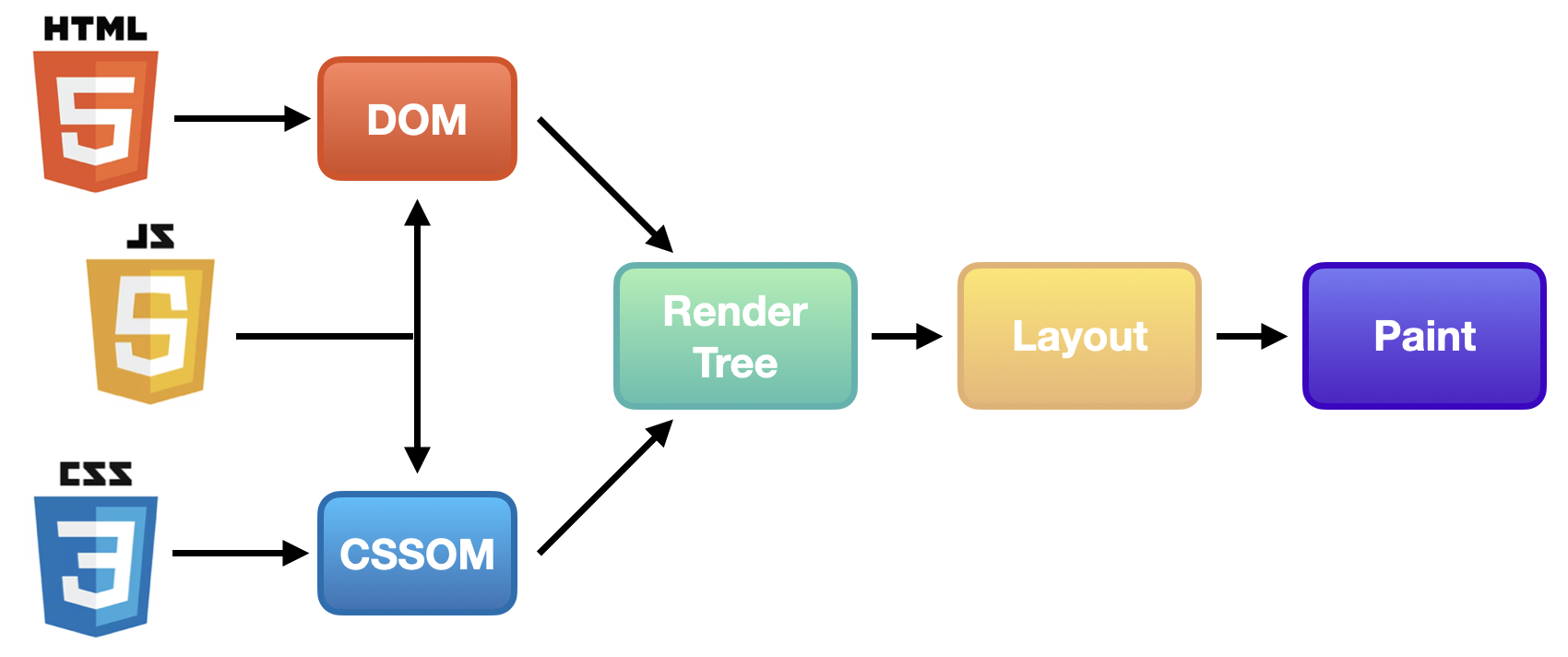
파싱
렌더링을 하기 위한 전처리 단계
브라우저는 HTML CSS 등의 단순한 텍스트 문서를 이해할 수 없기 때문에 브라우저가 읽을 수 있도록 변환하는 과정이 필요하다. 즉, 파싱은 서버로부터 전송받은 문서의 문자열을 브라우저가 이해할 수 있는 구조로 변환하는 과정이라고 할 수 있다.
1.1 HTML 파싱
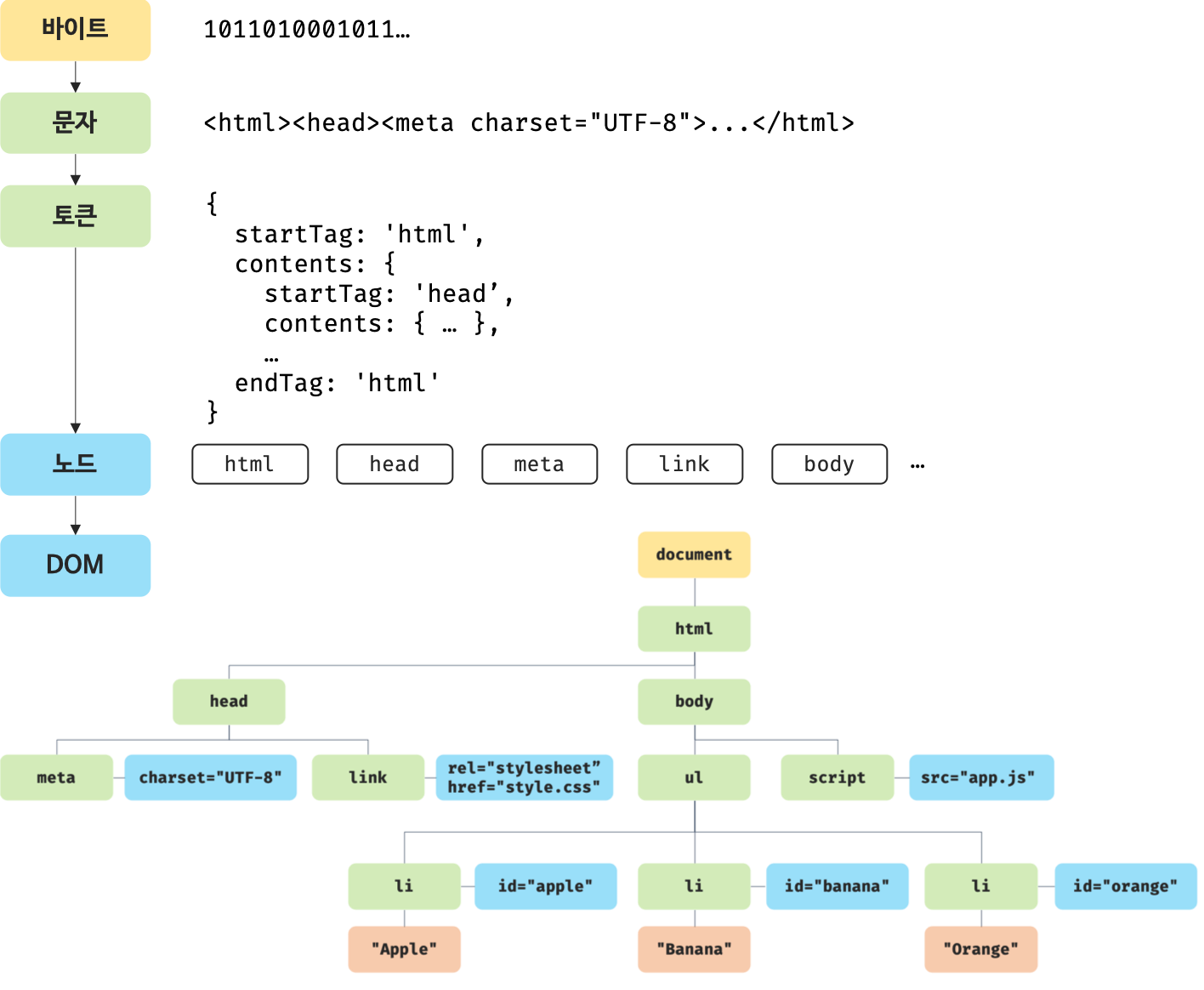
바이트 -> 문자 -> 토큰 -> 노드(객체) -> DOM
1.2 css 파싱
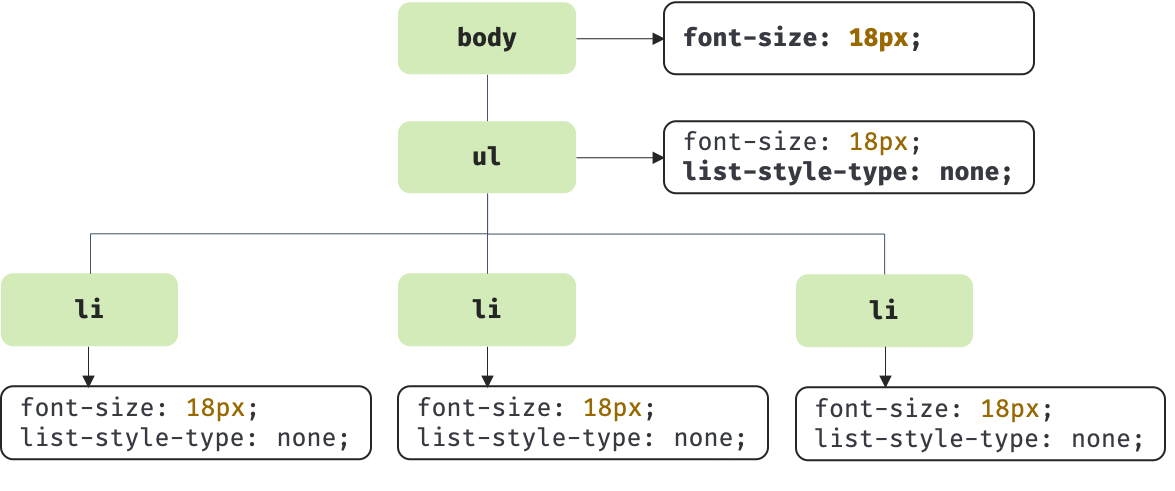
CSS 문서를 파싱하여 CSSOM 트리를 생성한다. 앞서 렌더링 엔진은 HTML문서를 한 줄 씩 파싱하면서 DOM을 생성한다고 했다. 이 과정에서 CSS 문서를 연결한 <link> or <style> 태그를 만나면 CSS문서를 파싱하여 스타일 규칙을 담고있는 CSSOM 트리를 만들기 시작하는 것이다.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8"> // 여기까지 해석 후,
<link rel="stylesheet" href="style.css"> //link를 만나면 DOM생성을 일시정지하고
//CSS파일을 서버에 요청한 후 응답받아 CSS파싱을 시작한다.
...CSS는 렌더링을 할 때 반드시 필요한 리소스이기 때문에 브라우저는 빠르게 CSS를 다운로드하는 것이 좋다. 그래서 <head> 태그 안에서 정의하여 빠르게 리소스를 받을 수 있도록 하는 것이다..!
1.3 JS 파싱
파싱 과정에서 <script> 태그 만나면 렌더링 엔진은 파싱을 잠시 중단하고 script를 읽는다. 그리고 JS파싱이 끝나면 렌더링 엔진은 다시 HTML 문서를 파싱한다.
<script> 태그가 <body> 태그 중간에 위치할 경우 HTML 파싱을 하는 도중에 갑자기 JS 파일을 읽게 되므로 오류 발생 위험이 있다. 그래서 우리가 <script> 태그를 <body> 태그 최하단에 쓰는거다~!
렌더링
2. Render Tree
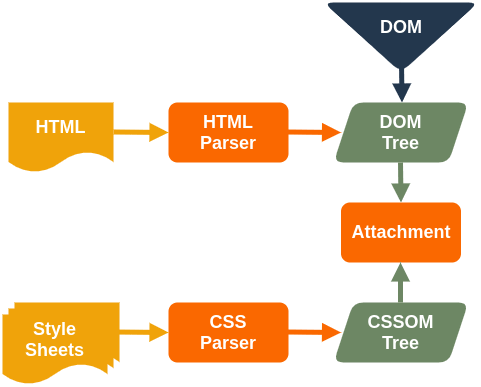
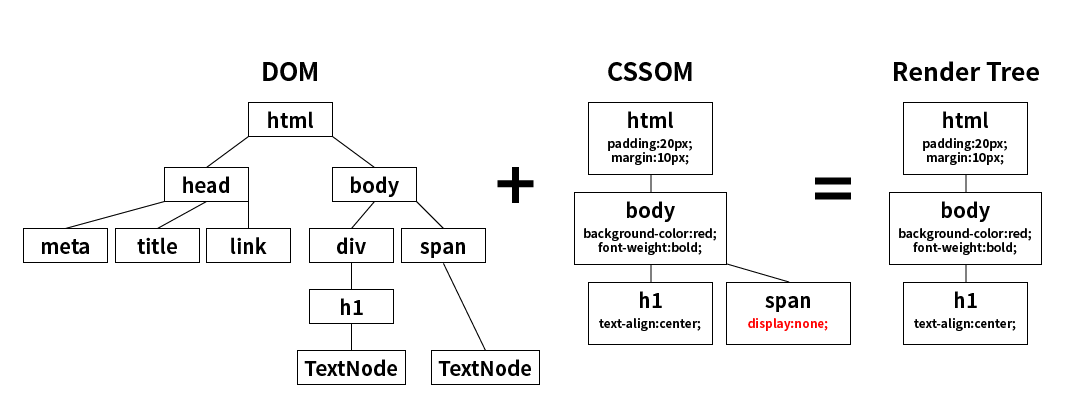
파싱하여 만든 DOM 트리와 CSSOM 트리를 결합하는 것을 Attachment 라고 한다. Attachment를 통해 Render Tree를 구축한다.
3. 레이아웃
렌더트리의 노드를 화면에 배치하는 과정을 레이아웃이라고 한다.
렌더트리 생성이 끝나면 웹페이지 화면 안에서 렌더트리에 있는 각 노드의 위치와 크기, 너비, 높이 등을 계산하고 화면에 배치하는 레이아웃 과정이 실행된다.
4. 페인트
레이아웃 과정에서 계산된 정보들을 바타응로 각 노드들을 화면에 그려주는 과정
렌더 트리의 각 노드를 화면의 실제 픽셀로 나타낼 때 Painting메서드가 호출된다. Painting 과정 후 브라우저 화면에 UI가 나타나게 된다. 브라우저 성능 개선을 위해 각 노드를 레이어별로 나눠서 준비한다. 그리고 변경되는 요소가 있을 경우 그 레이어만 업데이트한다.
정리

HTML을 받은 브라우저는 파싱과 렌더링을 거쳐 텍스트로 된 HTML을 브라우저에 보여준다.
파싱의 역할
- 브라우저는 HTML을 트리 자료구조의 형태인 DOM 트리로 변환한다.
- image, css, script 등 다운로드 해야 하는 리소스를 다운로드 한다.
- css의 경우 다운로드 하고 CSSOM 트리로 변환한다.
- 다운로드한 자바스크립트를 인터프리트, 컴파일, 파싱, 실행한다.
렌더링
- DOM 트리와 CSSOM 트리를 합쳐 렌더 트리를 만든다.
- 내용인 DOM과 다자인인 CSSOM을 합치는 것이다.
- 레이아웃을 정한다.
- 트리의 각 노드가 브라우저의 어디에 배치될지, 어떤 크기도 배치될지를 정하는 것이다.
- 브라우저 스크린에 렌더트리의 각 노드를 그려준다.
- 사용자는 브라우저상에서 시각화된 HTML 파일을 볼 수 있다.
참고 : 브라우저 렌더링
