1. groupby(), pivot_table(), apply() 비교
참고사이트
데이터셋 로드
titanic = sns.load_dataset('titanic')
titanic.head(5)
groupby() : 특정 컬럼별 통계를 보고자 할때 사용
- 사용 형태:
df.groupby('컬럼A')['컬럼B'].통계함수()
- 반드시 aggregate 하는 통계함수와 일반적으로 같이 적용된다
titanic.groupby(['embark_town','sex'])[['survived']].mean(numeric_only = True)
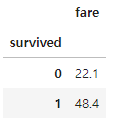
titanic.groupby(['survived'])[['fare']].mean()
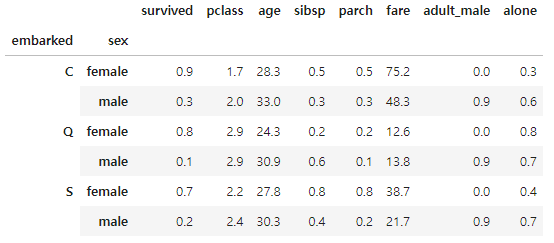
titanic.groupby(['embarked', 'sex']).mean(numeric_only = True)
pivot_table()
index, columns, values를 지정하여 피벗
titanic.pivot_table(index = ['embark_town', 'sex'], values = 'survived' )
titanic.pivot_table(columns = ['embark_town', 'sex'], values = 'survived')
titanic.pivot_table(index = 'sex', columns = 'embark_town', values = 'survived')
apply()
def transform_hanguel(x):
if x['sex'] == 'male':
return '남자'
else:
return '여자'
titanic.apply(transform_hanguel, axis = 'columns')
titanic['sex'].apply(lambda x: '남자' if 'man else '여자')

정규표현식
- 문자열 패턴을 찾아서 대체하기 위한 규칙의 모음
- 숫자 대응 정규 표현식 :
\d
- 숫자 제외 대응 표현식 :
\D
books_df.replace({'publication_year': {r'\d{2}(\d{2})' : r'\1'}}, regex = True).head(2)
books_df.replace({'publication_year': {r'\d\d(\d\d)':r'\1'}}, regex = True).head(5)
books_df.replace({'authors' : {r'지은이:(.*)':r'\1'} }, regex =True)