Abstract
본 논문에서는 사전 학습된 word vector에 CNN을 사용한 sentence classification 모델을 제안한다. 특히 간단한 CNN 모델 + 약간의 하이퍼파라미터 튜닝과 static vector를 통해 여러 벤치마크에서 훌륭한 성과를 거두었다. word vector를 task-specific하게 튜닝시켜줌으로서 성능을 향상시킬 수 있다.
또한, 추가적으로 아키텍쳐의 간단한 수정을 통해 task-specific word vector와 static vector를 둘 다 사용하는 새로운 아키텍처를 제안한다. 이 모델은 7개의 태스크 중 4개의 태스크(감성분석, 질문 분류 문제 포함)에서 SOTA를 달성했다.
1. Introduction
CNN은 지역적 특징에 적용되는 convolving filter를 가진 layer를 활용한다. 원래는 비전 분야를 위해 고안되었지만, 이후 자연어처리에 대해서도 효과적임을 보여주었다.
본 논문에선 unsupervised neural language model에서 얻은 워드 벡터 위에 하나의 레이어를 갖는 간단한 CNN모델을 학습한다. 조금의 하이퍼파라미터 튜닝에도 불구하고, 이 간단한 모델은 여러 벤치마크에서 훌륭한 성과를 냈다. 이는 사전 학습된 벡터들이 다양한 분류 태스크에 활용될 수 있는 'universal' feature extractors라는 것을 보여준다.
2. Model
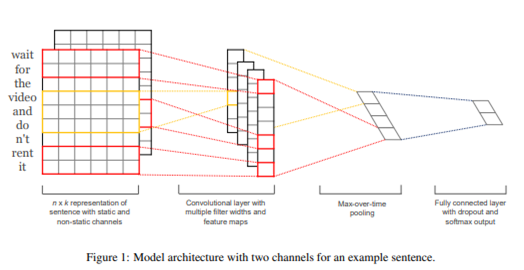
순서
1. input-> 2. convolution -> 3. max-pooling -> 4. fully connected layer and regularization
- convolution
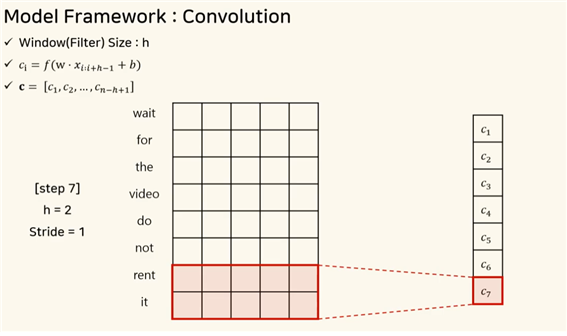
window(filter) size : h 몇 개의 단어씩 추출해서 특징을 추출할지 정한다.
convolution output으로 ci를 얻게 된다. 각각의 워드벡터에 필터 w와 셀을 곱하고 bias를 더한 연산을 수행한다.
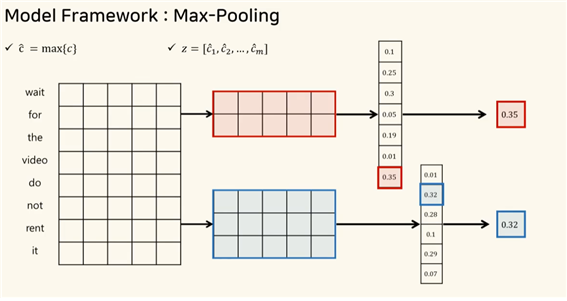
- max pooling
컨볼루션 연산을 통해 얻어진 피처맵에 max pooling을 수행한다.
피처맵은 특정 필터에서 뽑아낸 특징인데, 여기서 가장 큰 값을 추출하는 방식이다.
- fully connected layer
각각에 필터에서 나온 특징값 z 을 dropout을 통해 hidden unit에 co-adaptation을 방지한다. 또한 layer에 L2 norm을 이용해 특정 값 s를 넘는 대상에 rescaling을 수행하고 최종적으로 분류한다.
3. datasets and experimental setup
-
데이터셋 : 7개 사용
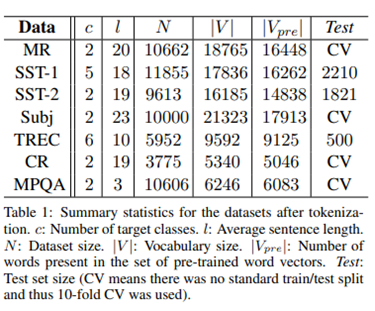
-
activation function : relu
-
filter window size : h=3,4,5로 각각 100개의 피처맵 사용한다.
-
dropout rate= 0.5
-
L2 constrain : 3
-
mini batch size : 50
4. Result & Discussion
4.1 Multichannel vs. Single Channel Models
model variations
4가지 모델을 만듬
1. CNN-rand(baseline) : 모든 워드백터를 임의로 초기화해서 업데이트함
2. CNN-static : pretrained word2vec사용 (=finetuning하지않고 static하게 남겨둠)
3. CNN-nonstatic : pretrained word2vec사용+ finetuning
4. CNN-multichannel : input이 두 개인 모델로 pretrained word2vec사용/ pretrained word2vec사용+ finetuning 두가지 합친 모델이다.
-> CNN-multichannel이 언제나 우수하진 않다.
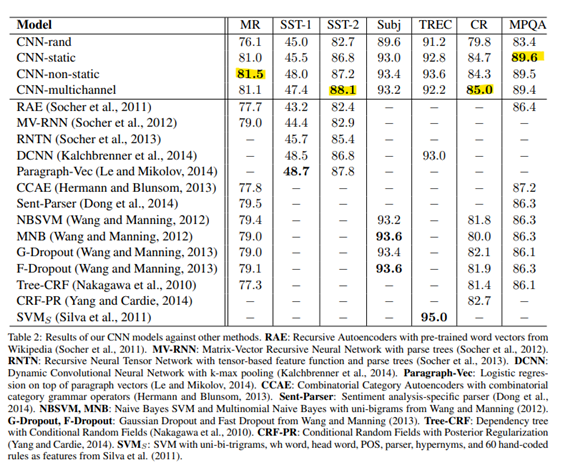
4.2 static vs. Non-static Representations
static과 Non static 모델을 비교할 때 최종 워드백터 비교해봄
파라미터 업데이트 하는 과정에서 non-static는 워드백터 바뀌고 static은 바뀌지 않는다.
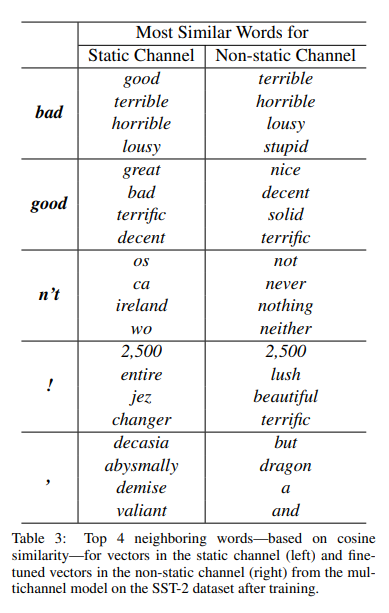
static channel은 어떤 단어를 같이 수식해주는 bad와 유사한 문법형태가 나타나지만,
non-static channel은 의미또한 유사한 단어를 잡아내는 것을 확인할 수 있다.
4.3 Further Observations
- 다양한 필터 사이즈와 여러 개의 피처맵을 사용할수록 모델의 성능이 좋아진다.
- dropout을 활용함으로써 성능을 2~4% 향상시킬 수 있다.
- word2vec에 없는 단어들의 경우, 다른 단어 벡터들의 variance와 유사하게 단어 벡터들을 초기화하면 성능을 향상시킬 수 있다.
- word2vec사용할 때 다른 prtrained word vector 사용한 것보다 성능이 좋은 것을 보아 universal한 feature extractor임을 확인할 수 있다.
5. Conclusion
약간의 하이퍼파라미터 튜닝에 불구하고 word2vec 위에 간단한 1개의 layer를 가진 CNN은 좋은 성능을 보인다. 결과는 단어백터의 비지도 pre-training이 NLP 딥러닝에 중요한 요소가 된다는 근거를 보인다.
참고
paper : Convolutional Neural Networks for Sentence Classification
