Abstract
기존의 인기있는 모델들은 단어마다 다른 벡터를 할당하여 단어의 형태를 무시한다. 큰 어휘들과 드물게 사용되는 단어에 한계가 있다. 이 한계를 극복하기 위해 본 논문에서는 skipgram 기반 모델로, 각각의 단어를 character n-gram 벡터의 조합으로 표현했다. 이 방법으로 학습속도가 빨라지고 학습데이터에 등장하지 않은 단어도 표현이 가능해졌다. 우리는 9개의 다른 언어에 대해 단어 유사도 및 추론 테스크로 평가한 결과 SOTA를 달성했다.
introduction
대부분의 기존 모델들은 파라미터를 공유하지 않는 다른 고유의 벡터로 각각의 단어를 표현했다.
하지만 이는 내부구조를 무시하게 되어 형태학적으로 복잡한 언어를 제대로 표현하지 못했다. turkish, finnish 같은 복잡한 언어를 표현하는데 한계가 있었다. 많은 단어의 정보는 일정한 규칙을 따르나, 철자 단위 정보를 사용하여 벡터 표현을 향상시키는 것이 가능하다. 본 논문에서는 문자 n-그램에 대한 표현을 학습하고 n-그램 벡터의 합으로 단어를 표현하는 것을 제안한다.
Model
3.1 General model
스킵그램 모델의 목적은 총 W개의 단어가 있을 때, 각 단어 w에 대한 벡터 표현을 배우는 것이다. = 로그 가능성을 최대화하는 것이다.
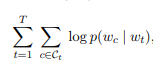
총 T개의 단어들이 있고 w_t(하나의 단어)가 주어졌을 때 w_c(주변의 문맥단어)에 어떤 단어가 와야 확률값이 가장 높은지를 최적화하는 방향으로 진행한다.
문맥에 있는 단어의 확률을 정의하는 한가지 방법으로는 softmaax 함수가 있다.
하지만 softmax 함수는 w_t에 대해 w_c 하나에 대해서는 잘 맞출 수 있지만 주위 다른 단어들은 잘 예측하지 못한다. 따라서 General model(word2vec)은 softmax함수 대신 negative sampling을 사용한다. 네거티브 샘플링을 사용하는 skipgram 모델을 사용한다.
3.2 Subword model
각각 단어에 대해 고유한 벡터 표현을 사용하여 skipgram 모델은 단어의 내부 구조를 무시한다. 단어의 양 끝에 <,>를 더하여 접두사와 접미사를 구별할 수 있도록 한다. 또한, 자신의 n-gram set에 자기 자신(즉 단어)도 포함한다.
예시) n=3, where --> <wh, whe, her, ere, re>
subword model은 한 단어에서 나올 수 있는 모든 n-gram을 추출한 다음 각각의 벡터들을 다 더해서 새로운 score를 만드는 것이다.
이 모델은 단어 간의 표현을 공유하여 드문 단어도 의미 있는 표현이 학습 가능하다.
4 Experimental setup
4.1 Baseline
Word2Vec(skipgram 모델, cbow 모델)과 비교한다.
4.2 Optimization
SGD(stochastic gradient descent)를 negative log likelihood에 적용하여 최적화 문제를 해결한다.
skipgram model에서는 선형적으로 감소하는 step size를 사용한다.
4.3 Implementation details
본 논문의 모델과 word2vec 모두 동일한 파라미터를 사용한다. - 300차원의 단어 벡터사용
또한 n-gram보다 1.5배 정도 느리다.
4.4 Datasets
9개의 언어로 된 위키피디아 자료를 사용한다. Matt Mahoney의 전처리 스크립트 사용하여 위키피디아의 데이터를 정규화한다. 데이터셋은 무작위로 섞여있다.
5. Results
5.1 Human similarity judgement
human judgement와 cosine similarity의 스피어만 상관계수로 평가
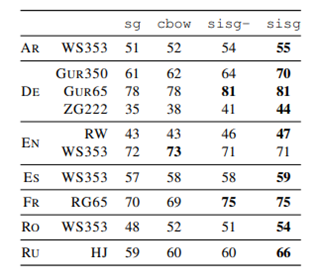
- sisg(subword information skip gram) : n-gram 벡터의 합으로 표현(n-gram으로 subword information을 사용한 모델)
- sisg- : OOV(out-of-vector)에 대해 null vector로 표현
sisg가 English WS353을 제외한 모든 데이터에 대해 우수한 성능을 보인다. 형태적으로 복잡하거나 합성어가 많은 언어에서 성능 개선이 더 많이 일어난다.
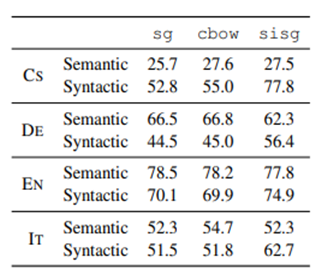
5.2 Word analogy tasks
syntatic(구조적 추론)task는 baseline보다 성능을 향상시켰다. semantic(의미적 추론) task는 성능이 뛰어나지 않는데, n-gram size를 적절히 조절하면 성능이 개선될 것으로 보인다.
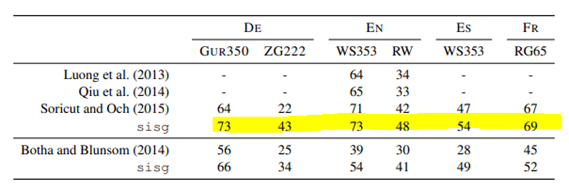
5.3 Comparison with morphological representations
이전 연구에 비해 제일 좋은 성능을 낸다. German(DE)에서는 명사 합성을 모델링하지 않았기 때문에 큰 발전이 있었다.
5.4 Effect of the size of the training data
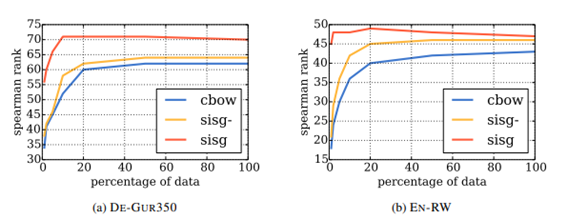
모든 데이터 세트와 모든 크기에서 sisg가 기준선보다 더 나은 성능을 보인다. 그러나 점점 더 많은 데이터를 사용할 수록 cbow 모델의 성능은 향상되지만 sisg는 빠르게 포화 상태가 된다. 즉, 더 많은 데이터를 추가한다고 결과가 개선되진 않는다.
sisg는 적은 train dataset을 사용할 때도 좋은 성능을 보인다.
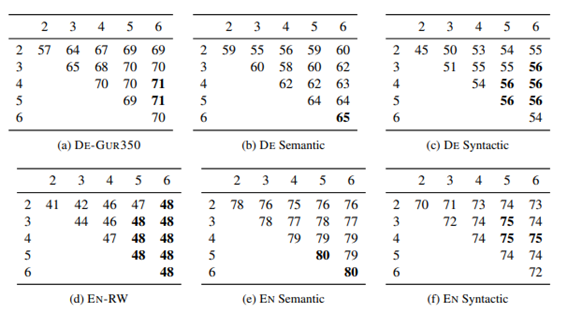
5.5 Effect of the size of n-grams
- n size 변경하면서 비교한다.
Syntatic task에서는 n을 작게 할 때 성능이 좋고 Semantic task에서는 n을 크게 할 때 성능이 좋다.
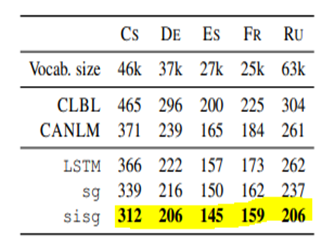
5.6 Language modeling
모든 언어에서 다른 모델보다 더 좋은 성능을 보인다. Perplexity는 작을수록 좋다.
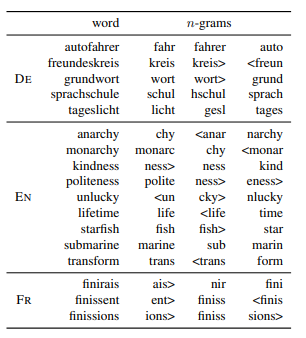
6. Quality analysis
주어진 단어에서 가장 중요한 3개의 n-gram 추출 결과 합성명사, 접두사와 접미사도 잘 표현한다.
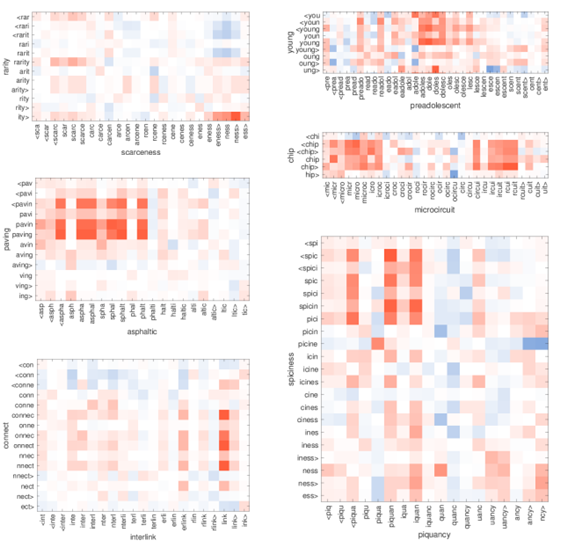
- X축 : OOV(등장하지 않은 단어)
- Y축 : 학습 데이터 셋 내 단어
- X, Y축 사이의 character n-gram 유사도를 나타낸다.
- 빨간색 = 양의 상관관계(비슷한 단어), 파란색 = 음의 상관관계(의미가 반대인 단어)
"ity>" - "ness>" : 명사형 접미사
"pav-" - "-sphal" : (아스팔트) 포장
“young”,“adoles” : 어린(이)
"nnect, onnect" - "link" : 연결
7. Conclusion
본 논문에선 subword 정보를 통해 단어 표현을 학습한다.
기존 skip-gram 모델 기반의 단어 표현에 character n-gram의 subword 정보를 고려했을 때 빠르게 훈련하며 전처리나 감독이 필요하지 않다. 또한 성능이 좋고 형태적 분석에 의존한 방법임을 알 수 있다.
