1월부터 캐글 스터디를 진행했다.
매주 캐글에서 데이터를 찾아 성능이 높거나, 알아보고 싶은 코드를 분석해서 발표하는 형식이다.
nlp에 관심이 있어 스팸 메일 관련 데이터를 골라 이번주에 발표를 준비했고, 공부하면서 알게 된 개념들을 간략히 정리한다.
개념 소개
TF-IDF
TFIDF란 특정 단어가 문서 내에 등장하는 빈도와 그 단어가 문서 전체 집합에서 등장하는 빈도를 고려하여 벡터화 하는 방법이다.
하나의 문서 단위로 벡터를 만들며 각 인덱스에 해당하는 단어가 문서에 등장하는 빈도와 문서 집합 전체에 등장하는 빈도의 역수를 곱하여 구한다. TF-IDF를 구하는 방법은 다음과 같다.

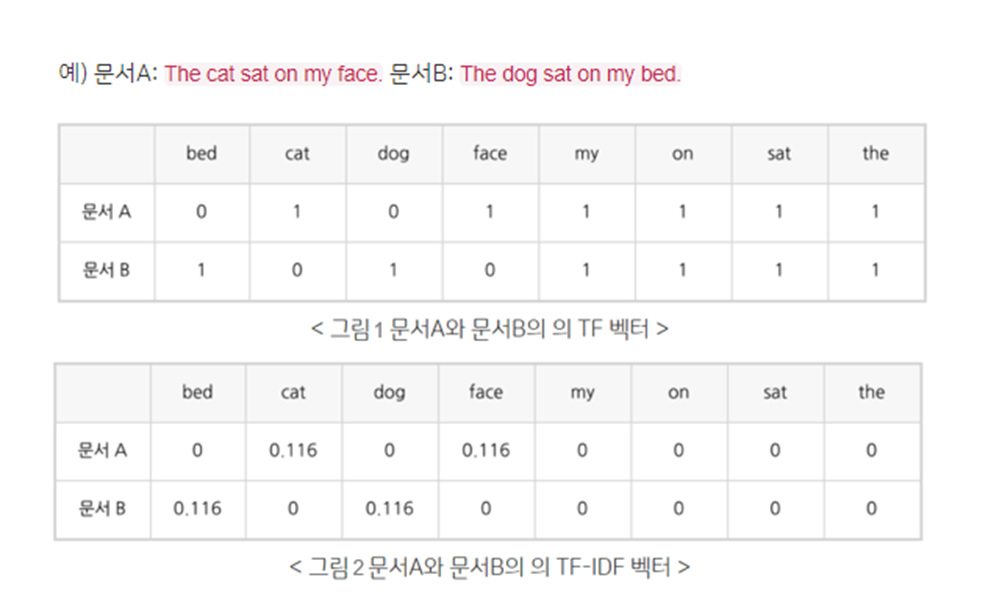
아래를 보면 문서 a,b의 예시가 있다. 그림을 보면 알 수 있듯이 TFIDF 벡터는 이러한 구조로 만들어지는 것을 알 수 있다.
TextVectorization
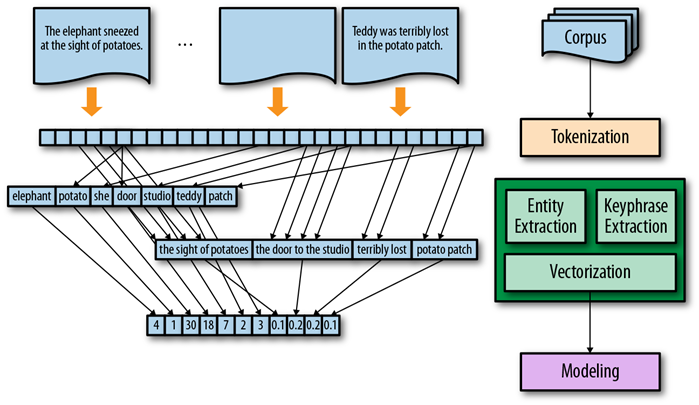
텍스트 벡터화는 텍스트를 숫자 표현으로 변환하는 프로세스.
각 단어는 하나의 벡터에 매핑되어 모델의 input 값으로 넣을 수 있다. 앞에서 한 TF-IDF 방식또한 텍스트 벡터화 방법 중 하나이다.
Word Embedding
워드 임베딩은 텍스트를 벡터화할 때의 문제점을 보완할 수 있다. TF-IDF같은 벡터화는 단어의 맥락을 고려하지 않은 벡터화 방식이다.
예를 들어 즐겁다, 기쁘다라는 말은 비슷한 의미를 가짐에도 불구하고 벡터 공간 내 단어 할당이 다소 임의적이기 때문에 두 단어 사이의 정보를 포착하지 못할 수 있다.
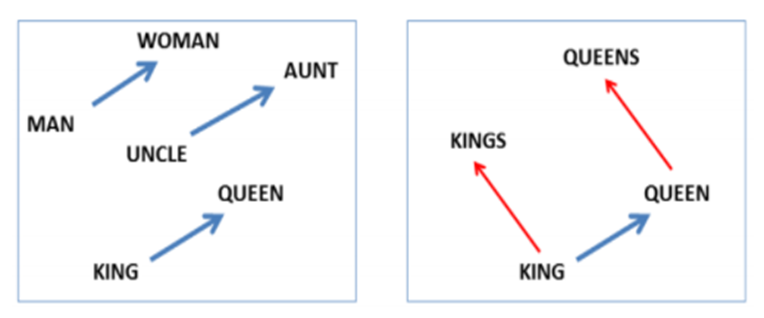
워드 임베딩 모델은 서로 비슷한 단어끼리 서로 가까운 점에 매핑하는 방식으로 각 단어의 벡터를 학습해 이러한 문제를 해결한다. 이로서 훨씬 더 작은 벡터 공간에서 전체 어휘를 표현할 수 있을 것이다. 이를 통해 차원을 줄일 수 있고 단어의 의미를 더 잘 포착할 수 있는 벡터가 생성된다.
Bidirectional LSTM
LSTM은 RNN이 입력 데이터가 많아질수록 은닉층에서 보관하는 과거정보가 마지막 레이어까지 충분히 전달되지 못하는 문제점을 해결한 RNN 계열 신경망이다.
양방향 LSTM은 순차적인 입력값에 대해 이전 데이터와의 관계뿐만 아니라 이후 데이터와의 관계까지도 학습한다. 하나는 입력을 순방향으로, 다른 하나는 역방향으로 사용해 네트워크에서 사용할 수 있는 정보의 양을 효과적으로 증가시킨다.
순방향으로 진행되는 것이 Forward, 역방향으로 진행되는 것이 Backward 레이어다.
양방향 LSTM 예시 코드
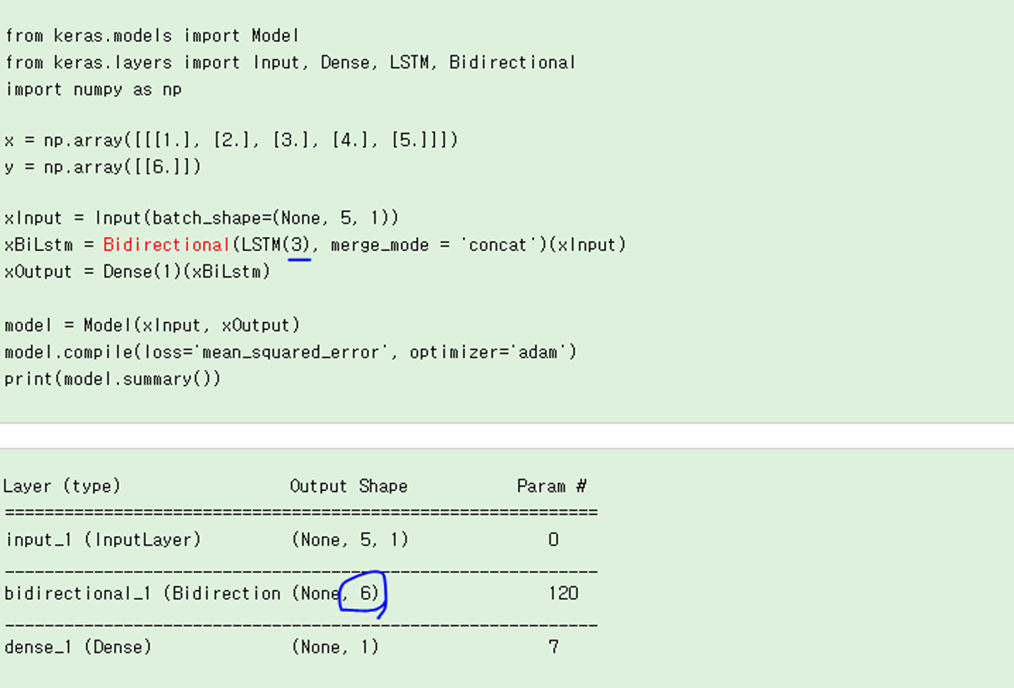
함수 x 가 {1,2,3,4,5} 이고 bidrectional layer에 3으로 지정하면
첫 번째 스텝으로, forward 레이어의 순차적으로 입력되면서 forward 레이어가 학습된다.
두 번째 스텝으로, x = {5,4,3,2,1}이 (역순으로) backward 레이어로 순차적으로 입력되면서 backward가 학습된다.
마지막 스텝으로, forward의 출력(3개)과 backward의 출력 (3개)이 합쳐져서 (concatenate) 6개의 출력이 나오고, 이것이 FC의 입력층으로 들어간다.
Return_sequences=False 일 때,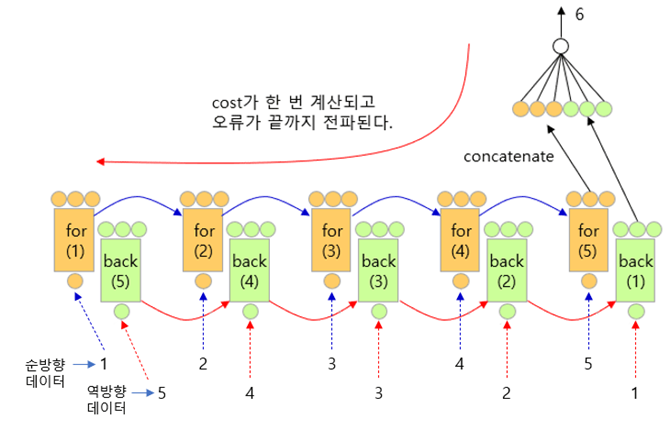
Return_sequences=True 일 때,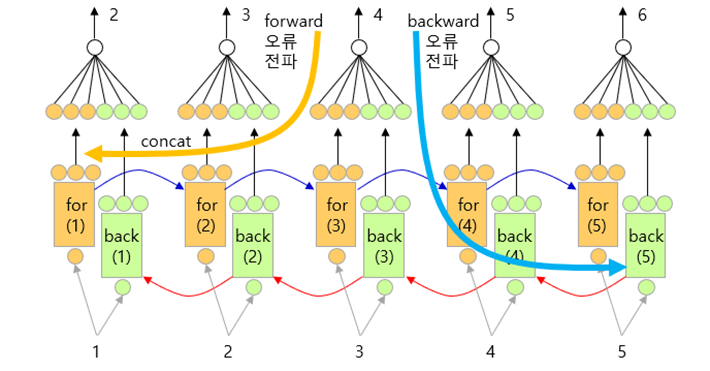
파란색 밑줄로 그어진 3옆에 return_sequences를 True로 설정하는 코드를 입력하면 중간 스텝의 출력값을 모두 사용하게 된다.
그래서 오른쪽 위에 그림은 여러 입력값을 이용해 하나의 결과를 만들어내는 (다 대 일)문제를 해결 할 수 있고(many-to-one), 두번째 사진은 여러 입력값을 이용해 여러개의 결과를 만들어 문제를 해결할 수 있음을(many-to-many) 알 수 있다.
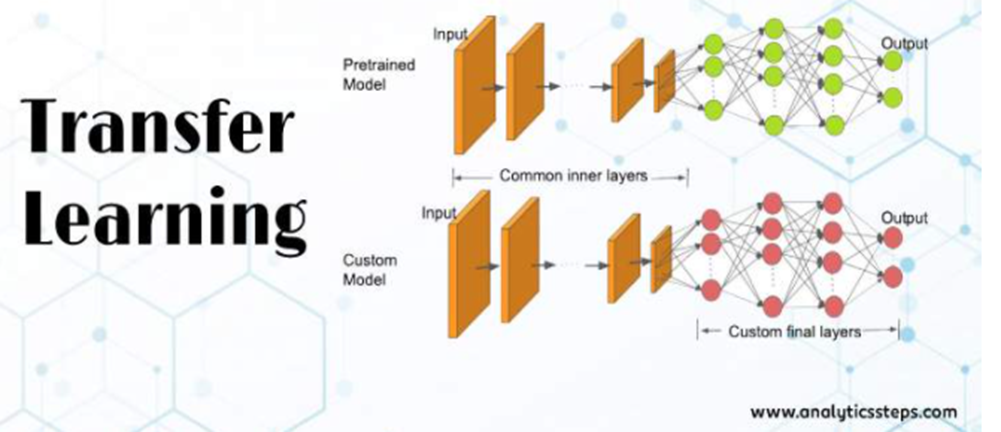
Transfer Learning with USE encoder
전이 학습(Transfer Learning)이란 특정 분야에서 학습된 신경망의 일부 능력을 유사하거나 전혀 새로운 분야에서 사용되는 신경망의 학습에 이용하는 것을 의미한다.
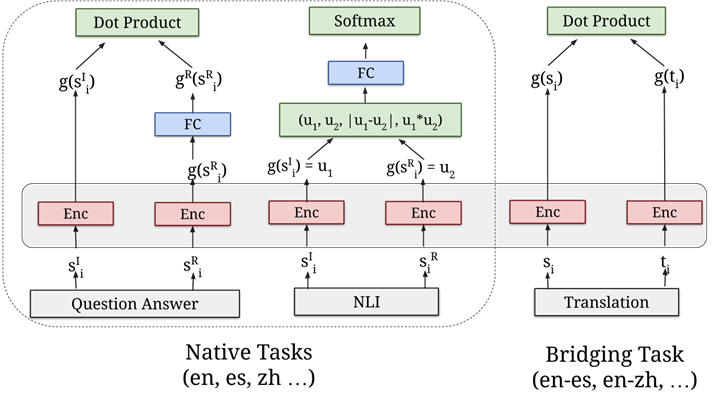
Universal Sentence Encoder는 텍스트 분류, 의미론적 유사성, 클러스터링 및 기타 자연어 처리에 사용할 수 있는 고차원 벡터로 텍스트를 인코딩하는 것이다.
-
Universal Sentence Encoder가 나온 배경
nlp 관련 일에서 제한적인 양의 훈련데이터가 쓰이고 있었고 실제 연구나 실무에서 nlp를 쓸 때 역시, 많은 양의 데이터셋을 쓰기 어려웠다.
이러한 이유로 낮은 성능을 갖게 되고 이를 해결하기 위해 특히 워드임베딩 부분에서 word2vec, glove와 같은 전이학습을 하곤 했는데 2017년 연구에서 단어 단위가 아닌 문장 단위의 임베딩이 성능에서 더 높다고 입증 되었다.아래 그림을 통해 연관성이 높다는 것을 알 수 있다.
Sentence embedding을 위한 transformer과 DAN 두가지 모델이 등장하였고 본 데이터셋 관련 코드에서는 이 중에 DAN(deep averaging network)을 사용했다.
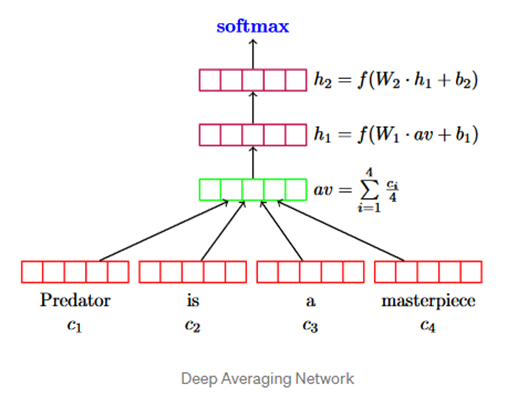
- DAN 진행방식
- 입력 임베딩의 벡터 평균을 구한다.
- 1개 이상의 피드포워드 레이어를 통과한다.
각 레이어가 단어 임베딩 평균에서 작지만 의미 있는 차이를 점점 더 확대할 것이다. - 최종 레이어에 대해 선형 분류를 수행한다.
마지막으로 교차엔트로피인 손실함수를 지난다.
또한, 문장 유사도 비교를 위해 angular distance를 사용한다.
아래 식은 angular distance를 나타낸다. 이는 코사인 유사도보다 더 좋은 비교성능을 갖고 있다.
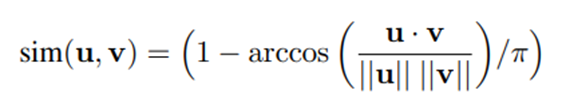
데이터 관련 코드
https://www.kaggle.com/cyruskouhyar/sms-spam-detection-99-acc-with-bi-lstm-use-rfc/notebook
그림 출처
https://sumniya.tistory.com/26
https://icim.nims.re.kr/post/easyMath/841
https://icim.nims.re.kr/post/easyMath/841
https://blog.naver.com/chunjein/221589656211
https://dodonam.tistory.com/204
USE encoder 관련 논문, 블로그
https://dodonam.tistory.com/204
https://mlgalaxy.blogspot.com/2021/03/universal-sentence-encoder-for-english.html
https://arxiv.org/pdf/1810.12836.pdf
DAN 이해하기 좋은 논문, 블로그
https://medium.com/tech-that-works/deep-averaging-network-in-universal-sentence-encoder-465655874a04
https://people.cs.umass.edu/~miyyer/pubs/2015_acl_dan.pdf
