abstract
본 논문에서는 짝을 이루지 않은 이미지 대 이미지 전환(image-to-image translation)의 새로운 도메인으로 아동 도서의 삽화를 탐구한다. 현재의 sota 모델이 스타일이나 콘텐츠 중 하나를 성공적으로 전환하지만 동시에 둘 다를 전환하지 못한다. 본 논문은 이 문제를 해결하기 위해 새로운 생성기 네트워크를 제안하고 결과 네트워크가 스타일과 콘텐츠 사이에 더 나은 균형을 유지하는 결과를 보여준다.
짝을 이루지 않은 이미지 대 이미지 전환에 대해 잘 정의되어 있지 않고 합의된 평가 지표가 없다. 지금까지 이미지 번역 모델의 성공은 제한된 수의 이미지에 대한 주관적이었고 질적인 시각적 비교를 기반으로 한다. 이 문제를 해결하기 위해 본 논문에서는 이미지-삽화 모델의 정량적 평가를 위한 새로운 프레임워크를 제안한다. 콘텐츠와 스타일이 모두 별도의 분류기를 사용하여 고려된다. 이 새로운 평가 프레임워크로, 우리가 제안한 모델은 삽화 데이터셋에서 현재의 최첨단 모델보다 더 나은 성능을 보인다.
introduction
image-to-image style transfer는 Gatys et al.의 이후 점점 더 주목받고 있다.
style transfer는 자연 이미지를 예술 작품으로, 뒤집기, 동물을 다른 동물로, 만화화하기 등 다양한 영역에 적용되었다. 본 논문에서는 삽화는 그림이나 만화와 질적으로 다르기 때문에 새로운 도메인이라고 주장한다. 삽화는 물체들(산, 사람들, 나무 등)이 포함되어 있기 때문에 더 높은 추상화 수준이 필요하다. 기존 모델은 추상화 스타일과 삽화의 내용 간의 균형을 조절하는 것이 어렵다.

CycleGAN은 입력 이미지의 내용을 보존하지 못하고, DualGAN은 스타일 변환에서 실패한다. GANILLA는 내용을 보존하면서 스타일을 변환한다.
[데이터]
"unpaired" 분리된 데이터셋이 필요하다. 두가지 필요. 자연적인 이미지와 삽화가 필요하고, 본 논문은 삽화 데이터셋 크기를 두배로 늘렸다. 웹을 스크랩하고 공공 도서관에서 책을 스캔하여 이미지를 만들며 데이터셋 크기를 늘렸다. 데이터셋에는 363개의 다른 책에서 가져온 24명의 예술가가 그린 9448개의 삽화가 포함되어 있다.
[기존에서 변경사항]
- residual layer에서 특징 맵을 다운 샘플링하는 새로운 생성기 네트워크를 제안한다.
- 콘텐츠를 잘 전송하기 위해 건너뛰기 및 업샘플링을 사용하여 낮은 수준의 피처를 높은 수준의 피처와 병합한다.
[평가부분]
일반적으로 이미지 대 이미지 전환 모델의 성공 여부는 정성적으로 평가된다. 생성된 이미지에 대해 쌍을 이루는 ground-truth가 없기 때문에 이 영역에서 직접 사용할 수 없다. 따라서
따라서 정량적 평가 프레임워크를 제안한다.
요약하자면, style transfer 문제 세가지에 기여한다. : 데이터셋, 아키텍처, 평가 방법
- 이미지 대 이미지 스타일 및 콘텐츠 전환의 새로운 도메인으로 아동도서의 삽화를 탐색한다.
- 24명의 예술가가 그린 약 9500개의 삽화로 구성된 데이터세트를 제공한다.
- 스타일과 콘텐츠의 균형이 맞는 새로운 generator network 제안한다.
- 이미지 생성 모델을 정량적으로 평가하기 위한 새로운 프레임워크를 제안한다.
GANILLA
콘텐츠를 보존함과 동시에 스타일을 전달하는 방식으로 새로운 생성기 네트워크를 설계했다.
2개의 ablation models 제안한다.
details of GANILLA
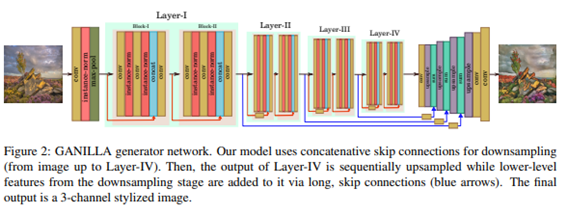
Generator network
모델은 다운샘플링 단계와 업샘플링 단계의 두 단계로 구성된다.
- 다운샘플링 단계는 수정된 ResNet-18 네트워크이다. -그림2
다운샘플링 단계에서 저수준 피처를 통합하기 위해 다운샘플링의 각 레이어에서 이전 레이어의 피처를 연결한다. 저수준 레이어는 형태적 특징, 가장자리와 모양과 같은 정보를 통합하기 때문에 전송된 이미지가 입력 콘텐츠의 하위 구조를 갖는다.
7 × 7 커널에 이어 instance-norm, ReLU, 최대 풀링 레이어로 이어진다. 그 다음 각 레이어에 2개의 residual 블록이 포함된 4개의 레이어로 이어진다. (그림 layer-I) 각 잔차 블록은 하나의 컨볼루션 레이어로 시작하여 인스턴스 표준 및 ReLU 레이어가 뒤따른다. 그리고 하나의 컨볼루션과 인스턴스 정규화 계층이 있다. stride가 2인 컨볼루션을 사용하여 Layer-I를 제외한 각 레이어에서 피쳐 맵 크기를 절반으로 줄인다. 잔여 레이어 내부의 모든 컨볼루션 레이어는 3 × 3 커널이 있다.
- 업샘플링 단계에서 업샘플링 전에 summation layers에 skip-connection을 통해 다운샘플링 단계에서 각 레이어의 출력을 사용하여 낮은 단계의 피처를 만든다. 이러한 연결은 콘텐츠를 보존하는 데 도움이 된다.
업샘플링 단계는 4개의 연속적인 컨볼루션, 업샘플 및 합산 레이어를 포함한다.
먼저 Layer-IV의 출력은 컨볼루션 및 업샘플링 레이어를 통해 나오고 이전 레이어의 피처 크기와 일치하도록 피쳐 맵 크기를 증가시킨다.
업샘플 단계의 모든 컨볼루션 필터는 1 × 1 커널을 갖고 있다. 마지막으로 7 × 7 커널을 가진 하나의 컨볼루션 레이어를 사용하여 3개의 채널 전환 이미지를 출력한다.
Discriminator network
이미지를 변환에 성공한 모델에서 가져온 70 × 70 PatchGAN으로 세 개의 컨볼루션 블록으로 존재한다. 각 블록은 두 개의 컨볼루션 레이어가 포함되어 있다. 필터 사이즈를 64로 시작하고 다음 연속적인 블록에서 두 배로 늘린다.
Training Option
[Cycle-consistency]
첫 번째 세트 (G): 소스 이미지를 대상 도메인에 매핑 시도한다.
두 번째 세트 (F): 대상 도메인 이미지로 입력 후 순환 방식으로 소스 이미지 생성 시도한다.
[손실함수]
각 Generator 및 Discriminator 쌍에 대한 두 개의 손실함수 사용. Minimax losses와 하나의 cycle consistency loss로 구성. Cycle consistency loss는 생성된 샘플이 소스 도메인에 다시 매핑될 수 있게 한다. L1 거리를 사용한다. 손실 함수에 대한 자세한 내용은 [3]을 참조!
[파라미터]
train image resized : 256×256
Epoch: 200
Solver: Adam
Learning rate: 0.0002
Evaluation
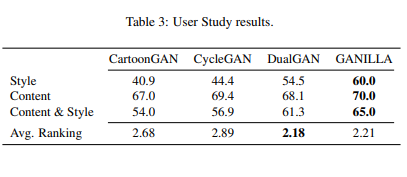
CartoonGAN , CycleGAN, DualGAN과 비교한다.
GAN이 만든 삽화의 품질을 결정할 수 있는 두가지 요인 : 스타일 갖고, 내용 유지
new framework to evaluate GANs quantitatively
- Style-CNN : 스타일 전달 측면에서 결과가 얼마나 좋은지 측정하는 것
스타일별 분류기를 훈련시키기 위해 스타일을 유지하며 시각적 콘텐츠에서 훈련 이미지 분리한다. 일러스트레이션 이미지에서 무작위로 자른 작은 패치(즉, 100 × 100 픽셀 패치)
이 패치를 사용하여 스타일 분류기인 Style-CNN을 훈련시킨다.
훈련 세트는 11개 클래스 : 삽화 아티스트를 위한 10개 클래스와 자연 이미지를 위한 1개 클래스 존재. 분류기를 테스트하기 위해 생성된 이미지만 사용.
- Content-CNN : 입력 내용이 보존되었는지 여부를 감지하는 것
특정 장면 범주 (숲, 거리 등)을 콘텐츠로 정의
4150개의 훈련 이미지와 500개의 테스트 이미지 사용
특정 스타일로 산 이미지를 생성한다면 생성 이미지 또한 산 이미지로 분류되어야 한다.
Qualitative Analysis and User Study
CycleGAN은 일러스트레이터의 스타일을 잘 잡아내지만 내용이 뭔지 구분하기 어렵다.
또한 얼굴과 사물을 구분 하지못한다. 반면 CartoonGAN과 DualGAN은 콘텐츠를 보존한다.
그러나 많은 예에서 스타일을 바꾸는데 어렵다. GANILLA는 콘텐츠를 보존하면서 양식화된 이미지를 생성한다. 이미지는 바다, 숲, 계곡과 같이 10개의 카테고리로 구분되어 있다.
-
GANILLA
고유한 아티스트 스타일로 이미지 생성
약간의 결함 존재한다. -
CycleGAN
스타일을 잘 전달하지만 기존의 콘텐츠 변형 발생한다.
생성 이미지에 소스 illustration의 얼굴, 사물과 같은 것을 환각 -
CartoonGAN & DualGAN
시각적으로 호소력 있는 작업에서 DualGAN은 약간의 여백으로 GANILLA 성능을 능가한다. 콘텐츠를 잘 보존하지만 다양한 경우에서 스타일 전달 측면에서 저조하다.
Ablation Experiments
논문의 모델의 다른 부분의 효과를 자세히 평가하기 위해 두 가지 절제 실험을 수행한다.
모델을 두 부분으로 나눌 수 있는데, 첫 번째는 다운샘플링 부분이고 두 번째 것은 업샘플링 부분이다.
첫 번째 ablation 모델
수정효과를 확인하기 위해 다운샘플링 부분에 대해 다운샘플링 CNN을 원본 ResNet-18로 교체했다.
Ablation Model 1은 GANILLA와 유사한 콘텐츠 점수를 제공하지만 스타일 점수는 더 낮다. 이것은 원래 ResNet-18 아키텍처에 대한 수정으로 입력 이미지를 성공적으로 스타일화함을 의미한다.
두 번째 ablation 모델
CycleGAN 및 CartoonGAN과 유사한 업샘플링 부분에 대해 deconv 레이어가 있는 다운샘플링 CNN을 사용하여 구성된다.
GANILLA보다 스타일 점수가 높지만 내용 점수가 너무 낮다. 이는 업샘플링 부분에서 저수준 기능을 사용하는 것이 콘텐츠를 보존하는 데 도움이 된다는 것을 보여준다.
Limitations and Discussion
우리 모델은 스타일화 측면에서 일부 삽화에서 실패했다. 이유는 Dr. Seuss의 삽화는 대부분 목탄 드로잉이거나 단순한 채색이 포함되어 있기 때문이다. 또한 삽화는 주로 동물 또는 사람을 포함하는데 자연경관 이미지와는 매우 다르다.
Conclusion
아동도서 삽화는 매우 추상적인 대상과 형태를 포함하고 있기 때문에 현재의 최첨단 제너레이터 네트워크는 내용과 스타일을 동시에 전달하지 못한다. 이 문제를 극복하기 위해 우리 모델은 다운샘플링 상태와 업샘플링 부분에서 낮은 수준의 피처를 사용한다.
또한 콘텐츠와 스타일 면에서 이미지 전환을 정량적으로 평가하는 새로운 평가 프레임워크를 제안한다. 프레임워크는 스타일과 콘텐츠 측면을 별도로 측정하는 두 개의 CNN을 기반으로 한다. 이 프레임워크를 사용하여 논문에서 제안한 모델 GANILLA는 현재의 sota 모델에 비해 더 높은 성능을 달성한다.
