이전부터 BERT관련된 모델들을 리뷰하며,,, GPT와 비교하는 결과가 많았고 이전에 논문을 읽었지만 다시읽으며 GPT 모델 발전과정과 차이점을 서술해본다~~!
GPT1
GPT1 배경
대부분의 딥러닝 task는 label을 만들기위해 비용이 많이 든 data가 필요하다. 하지만 실제 가지고 있는 건 unlabeled dataset이 더 많다. 이를 이용해보자!
기존 label data만 이용하는 것보다 unlabeled text corpus 사용해서 임베딩하고 label data로 fine-tuning하는게 성능이 좋다.
unsupervised pretraining과 supervised finetuning을 결합한 semi-supervise 접근을 사용한다. 모델 구조는 transformer 사용하고, 이는 Text의 long term dependency에 강한 결과를 나타내고, 기존 RNN에 비해 구조화된 memory를 쓸 수 있게 한다.
-
auto-regressive : 예측된 값이 다음 예측값을 예측하는 input을 들어가는 방식으로 LM이 만들어진다.
-
fine-tuning : 원하는 task에 한번더 gradient update하는 것
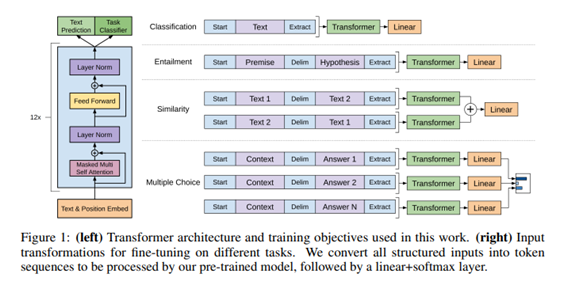
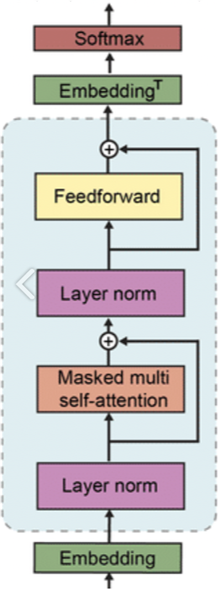
GPT 구조
- Transformer의 decoder 구조를 12개 쌓아올려 예측한다.
decoder block은 masked self-attention과 feed forward neural network로 구성된다.
여러 디코더 블록은 decoder 구조는 같으나 구조 안에서 학습된 weight는 다르다.
multi layer transformer decoder만 사용하는 not bidirection model
masked self attention(정보가 주어진 것 이전 정보까지만 사용) self attention 사용x
masked self attention-->encoder decoder self attention 안하고 바로 feedforward 수행
이것을 여러겹 쌓음 --> 마지막 linear output layer에서 softmax로 y값 나옴
- task-specific input transformation
transformer에 들어가기 전에 target task에 따라 transformer input 값을 변환한다.
task specific 아키텍처 목표에 학습하여 이러한 재구조 작업은 상당한 양의 커스터마이즈가 필요하고 transfer learning을 사용하지 않는다. GPT1는 pretraining model이 process할 수 있도록 input structured를 convert하는 방법을 사용.
GPT1 구조와 task-specific input transformation


모델 학습 순서
-
unsupervised data로 pretraining
LM을 대규모 corpus에서 학습한다. (pretraining) transformer decoder 구조 사용. -
supervised data 들어오면 이전L1과 같이 update (pretraining에서 만든 LM을 fine-tuning task에 맞춰 목표를 추가시킨다.)
같이 update 장점
1. supervised model에 대한 generalize ability 향상
2. 학습속도 빠름
unsupervised pre-training
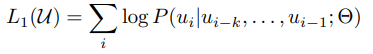
Transformer의 decoder 구조를 12개 쌓아올려 예측한다.
decoder block은 masked self-attention과 feed forward neural network로 구성된다.
여러 디코더 블록은 decoder 구조는 같으나 구조 안에서 학습된 weight는 다르다.
- 특징
masked self attention(정보가 주어진 것 이전 정보까지만 사용)
encoder decoder self attention 안하고 바로 feedforward 수행하고 이것을 여러겹 쌓음 --> 마지막 linear output layer에서 softmax로 y값 나옴
supervised fine-tuning
supervised fine-tuning은 pre-training이 끝난 후, target task에 맞게 parameter를 조정하는 단계이다. input token sequence와 label y로 구성된 target task의 labeled dataset C를 통해 학습이 진행된다.
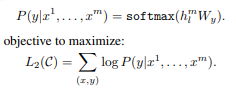
우선 C의 input token에 대한 GPT의 마지막 decoder block hidden state h값을 얻기위해 앞선 단계에서 얻은 pretrained model에 input token들을 통과시킨다. 그리고 파라미터 w를 갖는 하나의 linear layer에 h를 통과시켜 softmax probability를 계산한다. 이 결과로 token probability distribution을 얻을 수 있고, 따라서 label y에 대해서 지도학습을 진행할 수 있다.
지도학습의 목적함수 Likelihood L(2) 또한 일련의 구조로 모델링된 조건부확률 P를 통해 계산된다. 저자들은 또한 unsupervised pre-training의 목적함수 L(1)을 supervised fine-tuning을 위한 auxiliary objective로서 추가했다.
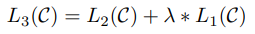
이때 기존의 L(1,U)은 unlabeled dataset U에 대한 L(1,U)으로 계산되었지만, auxiliary objective로서 L(1)은 Labeled dataset C에 대해 L(1,C)로 계산된다. lambda는 L(1,C)의 반영 정도를 정하기 위한 weight hyper parameter 이다. 이 방법은(같이 update) 1. supervised model에 대한 일반화 성능 향상 2. 학습속도 빠른 장점이 있다.
GPT1 결론 및 한계
RNN 같은 구조를 탈피해서 transformer 구조를 사용했다는 것에 의의가 있다. 하지만 한계는 unsupervised learning을 지향했음에도 특정 task에 적용할 때 성능 향상을 위해서 fine-tuning 과정과 input transformation이 들어갔다는 것이다. 결국 fine-tuning과정에서 supervised learning이 필요로하는 한계가 있다. 비지도 학습만으로 모델이 만들어지면 더욱 다양하고 범용적으로 사용할 수 있을 것이다. 따라서 비지도 기반의 언어 모델 GPT-2를 만듬. #변경됨에 따라 GPT-2부터는 fine-tuning 과정이 없다.
GPT2
변화1 - 구조
-
layer normalization was moved to the input of each sub-block, similar to a pre-activation residual network and additional layer normalization was added after the final self-attention block.
-
we scale the weights of resudual layers at initalization by a factor of 1/root N where N is the number of residual layers.
-
increase the context size 512->1024, a larger batchsize of 512 is used.
- layer normalization 위치가 변경됐다. LayerNorm(sublayer(x) + x) 형태였는데, x+sub-layer(LayerNorm(x)) 형태로 바뀌었다.
2.residual layer의 누적에 따라 initalization이 변경됐다. residual layer의 weight(가중치)는 weight*(1/N) (N=residual layer의 수) 값으로 초기화된다.
- 더욱 대용량 데이터를 사용해서 만듬, 배치 사이즈도 늘렸다. voca size가 5만대로 늘었고, context size 또한또한 512에서 1024로 증가했다.
변화2 - training dataset
GPT-2의 가장 큰 목적은 Fine-tuning 없이 unsupervised pre-training 만을 통해 Zero-shot으로 down-stream task를 진행할 수 있는 General language model을 개발하는 것이다.
따라서 기존과 다르게 하나의 도메인이 아니라 Web scraping dataset으로 다양한 도메인을 이용한 데이터를 사용했다. 논문에서는 데이터의 품질이 떨어지는 것을 방지하여 직접 필터링을 진행하여 만든 webtext dataset을 사용했다. (중복 제거, 대중적인 문서 제외 등으로 다양성 고려)
+토큰화 byte-pair-encoding 사용 : OOV 문제에 더 유연하게 대처할 수 있다는 장점이 있다.
GPT2 한계
zero-shot, few-shot learning에 대해서는 under-fit, 즉 좋지 않은 성능을 보였다.
특정한 task수행하려면 task-specific datasets, fine-tuning 필요했다. 하지만 새로운 테스크에 충분한 label이 없다.
GPT3
변화
gpt-2와 아키텍처 거의 비슷하지만 달라! 토큰과 토큰사이에 전부 attension 넣었지만 이번엔 sparse attention을 넣었다.
더 많은 데이터를 사용하였으며 Self-Attention Layer를 많이 쌓아 parameter 수를 왕창 늘림(175 billion). GPT-2의 Down-stream tasks in Zero-shot setting의 가능성을 보고 Few-shot setting으로 발전시켜 fine-tuning 없이도 좋은 성능을 낼 수 있도록 하였다. GPT3은 gradient update, fine-tuning을 전혀 사용하지 않는다.
-
Few-shot learning 학습할 때 몇 개의 예시를 보여주는거지 example로 학습을 하지 않는다(gradient update하지 않음)!
-
spurious correlations : 잠재된변수 같은 것처럼 사이에서 영향을 미칠 수 있는 결과
모델사이즈가 커지거나 학습 데이터가 충분하지 않으면 상관관계가 영향을 미칠 수 있다. -
meta-learning : 모델이 학습하는 과정에서 스킬과 패턴을 인지하는 능력을 개발하는 것
성과
번역, Q-A, cloze tasks 등 다양한 NLP 데이터셋에서 높은 성능을 보였다. 단어 순서 맞추기, 문장에서 새로운 단어 사용하기, 3자리 수리 연산하기와 같은 추론 혹은 도메인 적응이 필요한 태스크도 몇 개의 예제만 보고 잘 수행해냈다.
또한 사람이 구분못할 정도로 새로운 articles을 만드는데 성공했다.
training dataset
- 한번 필터링 된 dataset 사용
- duplicate 제거--> 하지만 결국 전부 다 제거하진 못함
- reference corpus를 augmentation 하는데 사용
GPT3 한계
- ANLI데이터와 RACE, QuAC와 같은 질의응답 데이터 셋에서는 few-shot learning 성능이 그다지 좋지 않았다.
- 특정 문서에서 특정 단어를 많이 쓴다던가, 후속으로 쓸 때 부자연스럽다.
- not bidirection, auto-regression
- scale이 크니까 결국 expensive and inconvenient to perform inference on
GPT1 : Improving Language Understanding
by Generative Pre-Training
GPT2 : Language Models are Unsupervised Multitask Learners
