contrastive learning이란?
동일한거 가까이, 다른거 멀리 두고 pair비교하는 것--> positive pair인지 아닌지
NLP에서는 두 문장의 의미가 같은지를 확인한다. 가까운 이웃을 더 가깝게하고, 먼 이웃들은 더 pushing 하는 방법이다.
Abstract
Contrastive learning을 통해 최상의 문장 임베딩을 매우 향상시킨다.
두가지 방식을 제안한다.
비지도 방식으로, 오직 dropout을 noise로 사용해 constrastive objective에서 input sentence를 얻고 스스로를 예측한다. 여기서 dropout은 minimal data augmentation 역할을 하고, 이를 제거하는 것은 representation collapse로 이어진다.
지도방식으로, NLI 데이터셋에서 annotated된 pair(entailment pairs-> positive, contradiction pairs->hard negative)를 constrative learning framework로 통합한다.
본 논문은 contrastive learning objective가 사전 학습된 임베딩의 anisotropic space를 더 균일하게 정규화하고, supervised signal을 사용할 수 있을 때 postivie pair를 더 잘 align한다는 것(paired pair 사이의 거리를 더 짧게)을 보인다.
introduction
unsupervised CSE는 오직 dropout을 노이즈로 사용해 스스로 인풋 문장을 예측한다. 다시 말해, pred-trained encoder에 같은 문장을 두 번 통과시킨다. 이로써 두 개의 다른임베딩, positive pair을 얻을 수 있다. 그리고 우리는 같은 mini batch를 통해 negatives, 다른문장을 받고 모델은 여러 negatives 사이에 하나의 positive를 예측한다.
또한 우리는 dropout이 hidden representation의 minimal augmentation의 역할을 한다는 것을 알아냈다. 반면에 dropout을 제거하면 representation collapse이 발생하는 것을 알아냈다.
supervised CSE은 sentence embedding을 위해 NLI 데이터셋을 사용했다.
entailment pair를 positive instance로 사용할 수 있다는 사실을 최대한 활용했다. 또한, hard negatives로 contradiction pair을 추가하는 것이 성능 향상에 도움이 된다는 것을 알아냈다.
NLI 데이터셋은 다른 labeled sentence-pair 데이터셋에 비해 문장 임베딩을 학습하는데 특히 효율적이다.
unsupervised CSE는 기본적으로 균일성을 향상시키는 동시에, dropout noise를 통해 degenerated alignment을 막는다. 그래서 representation의 표현력을 향상시킨다. NLI training signal이 긍정적인 페어쌍에 alignment를 향상시키고 더 나은 문장 임베딩을 만들어낸다. 사전학습한 워드 임베딩에서 anisotropy 고통받는 것을 발견했고, contrasticve learning objective을 통해 sentence embedding space의 sigular value distribution을 flattens 하게 만들어 uniformity를 향상시킨다는 것을 증명했다.
Contrastive learning은 동일한거 가까이, 다른거 멀리 두어 representation을 효율적으로 학습하는 것을 목표로 한다.
학습목적함수
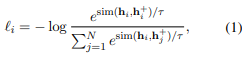
분자보면, similarity fuction으로 sentence embedding이 서로 얼마나 유사한지 판단,
분모는 나머지 값들의 representation에 대한 simliarity를 구한다.
미니배치안에 구성되는 negative pair 분모에 두고, positive pair 분자에 두고 similarity를 학습하는 contrastive loss를 구성한다.
-> positive pair을 잘 만들었기에 동일한 loss를 사용하더라도 성능이 좋아졌다.
label 없는상황(어떤 문장이 서로 비슷한문장인지 확인 x)에서 어떻게 positive pair를 구축할 것인가 중요함. semantically related 기대함(두 문장이 의미적으로 유사한지 기대)
Background: Contrastive Learning
Positive instances
positive instance 어떻게 구성할까?
vision
finetuning 이전에 reprentation 만들 때 contrastive learning으로 한번 더 학습하고 downtask 수행한다. 뒤집기, 자르기 등의 augmentation 중 2개의 랜덤한 augmentation을 적용하여 새로운 이미지를 확보한다. ex) Positive pair : (original data, augmented data)
Language
특정단어를 유의어로 교체, 임의의 단어 삽입하거나 삭제하는 방식, 문장 내 임의의 두 단어의 위치를 바꾸는 것 등의 augmentation technique들을 적용. 하지만 NLP는 이산적 성질 때문에 Augmentation에 내재적인 어려움이 존재한다. 문장에서 중요한 단어를 없애면 안되기 때문에 어렵다.
- Discrete Representation은 값 그 자체를 표현, 정수로 표현된 이산표현
- Continuous Representation은 관계, 속성의미를 내포하여 표현, 실수로 표현된 연속표현
Alignment and uniformity
Contrastive Learning을 통해 representation의 quality를 측정하기 위해 Alignment와 Uniformity를 사용한다.

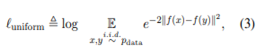
alignment : paired instance 사이의 거리를 계산한다. (짧을수록 좋다)
uniformity : embedding이 얼만큼 균일하게 분포하는지 (균일할수록 좋다)
Uniformity를 좋게 만드는게 왜 좋을까 ?
- isotropy : 벡터가 고르게 분포되어있음
PLM은 처음 token은 넓게 분포되어있다가 높은 layer로 학습할수록 의미가 좁아진다.(Anisotropic 하다.) =space가 좁아진다. embedding space 자체가 좁기 때문에 단어가 고유한 의미를 보존하기 어렵다.
anisotropy 문제 : embedding space가 줄어들면 단어가 사용할 수 있는 표현이 줄어든다. 서로 상이한 단어도 의미가 유사해지는 경향이 있고 ~~
Embedding space가 hypersphere에서 넓고, 고르게 분포하여 각 단어가 고유한 의미를 보존하는 것이 중요하다.
--> Contrastive learning을 통해 학습을 진행하다보면 Negative Pair를 Positive Pair와 멀게 강제하는 과정에서 embedding space를 균일하게 분포하도록 만들 수 있음
따라서 PLM의 문제인 Anisotropic완화 및 Uniformity 증가
SimCSE가 적용되는 방식
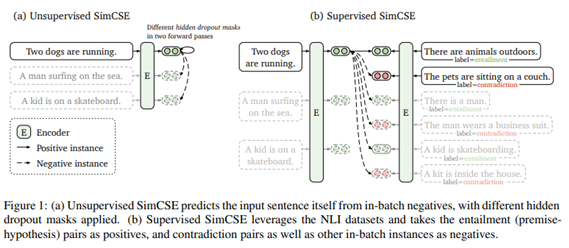
Unsupervised SimCSE
input : 동일한 문장을 positive pair로 활용 --> 결과로 hidden representation 생성
하지만 이 두 문장은 dropout이 다르기 때문에 output(hidden representation)이 동일하지 않다. 따라서 이 두문장으로 positive pair구성.
neg pair : in-batch(하나의 배치 안에 neg를 함께 넣는다.)를 통해 다른문장들을 negative pair로 구성
학습목적함수
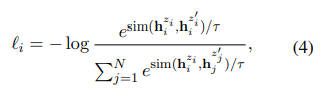
identical positive pairs으로 작동하도록 하는 키 포인트는 독립적으로 샘플링된 dropout mask를 사용하는 것이다. z는 dropout을 위한 랜덤 마스크를 의미한다. random sampling 한 dropout을 사용한다.
같은 input을 encoder에 2번 넣고 다른 dropout mask를 가진 2개의 임베딩을 얻는다.
dropout을 활용하여 minimal augmentation 적용이 가능하고 이를 제거하면 representation collapse가 발생한다.
분자는 같은 문장을 다르게 표현한 것들의 유사도, 분모는 다른 문장을 다르게 표현한 것들의 유사도의 합. 즉, 분자는 커지고, 분모는 작아질수록, 같은 것들의 유사도는 높아지고, 다른 애들 사이의 유사도는 낮아질수록 loss가 작아진다.
dropout rate를 변경하며 값 비교
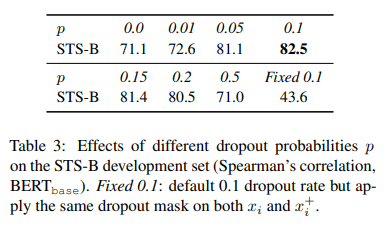
dropout 0.0은 두가지 동일한 representation이 나온다. (input을 동일한 것을 넣었으니까 당연하지!). fixed 0.1(same dropout masks for the pairs)은 dropout을 고정하면 positive pair가 더가까워지지 않기 때문에 alignment가 collapse된다. p=0.1일 때 가장 높은 값을 나타낸다. fixed 0.1, no dropout : 두 경우에서, pair에 대한 임베딩의 결과는 정확히 같았고, 이는 극적인 성능 저하로 이끌었다.
Dropout noise as augmentation
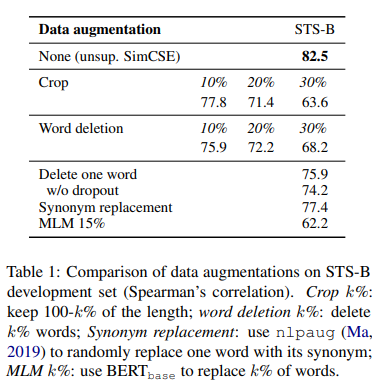
이전에 비전, language에서 사용하는 augmentation과 비교했을 때, dropout noise를 적용한 결과가 가장 뛰어남을 알 수 있다.
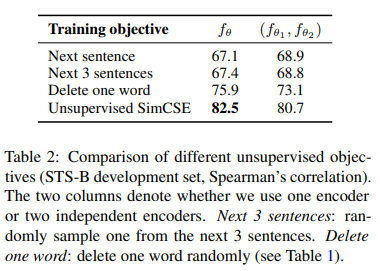
다른 unsupervised objective와 비교했을 때, unsupervised simCSE가 가장 높은 성능을 보임을 알 수 있다. 앞의 결과는 (one encoder, 뒤는 dual encoder 결과)
2개보다 1개의 encoder를 사용하는 것이 더 좋은 성능을 낸다는 것을 알 수 있다.
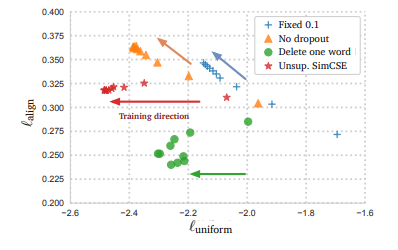
- uniform 클수록 균일, align 작을수록 pair쌍 가까움
supervised simSCE
input : 다른 문장을 positive pair로 활용
NLI 데이터셋을 활용하여 entailment label--> positive pair/ contradiction label--> hard negative pair로 사용
NLI 데이터 : 매칭되는 문장이 entailment, contradiction인지 classification 할 수 있도록 구성된 데이터이다.
여러 데이터셋을 비교해본 결과, NLI로부터 entailment pair와 hard neg를 사용한 것이 가장 성능이 좋았다.
Experiment
SimCSE는 모든 비지도, 지도학습 모델에서 결과를 크게 향상시켰다.
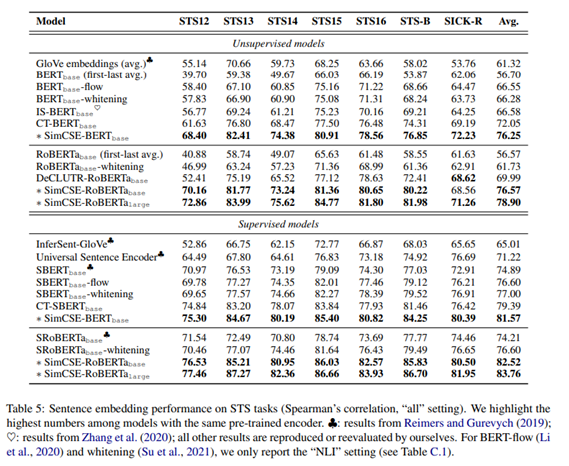
평가방법
STS task는 각 sentence의 output representation의 코사인 유사도 도출하고 사람들이 5점 척도로 평가한 Score와 유사도 점수로 Spearman’s , Pearson’s 상관계수를 계산한다.
결론
느낀점
이전에 코드 유사성 분류 경진대회에 나갔을 때 contrastive learning을 알게되어 문장 조합을 만들 때 positive pair는 가능한 모든 조합으로, negative pair는 bm25유사도 점수를 ranking 매겨서 유사한 pair를 만들었다. 이때 SimCSE를 알았다면 positive pair을 구축하는데 더 효과적인 방법으로 적용할 수 있었을 것이다. NLP분야는 비전분야와 다르게 discrete representation으로 augmentation 하는데 어려움이 있고 이때 dropout만을 이용해서 positive pair를 구축한다는게 큰 장점인 것 같다. sentence bert도 두개의 네트워크 구조를 이용해 sentence embedding을 학습했는데 이와 차이가 무엇인지 알아봐야겠다.
참고
논문
고려대학교 seminar
