너무 길어져서 2편으로 넘겼다.
4. Experiments
4-1. GLUE
GLUE는 General Language Understanding Evaluation의 약자로 다양한 분야의 general language understanding task를 포함하고 이를 평가함
GLUE 벤치마크에 대해서 fine-tuning을 할때는 classification layer 하나만 추가했다고 한다.
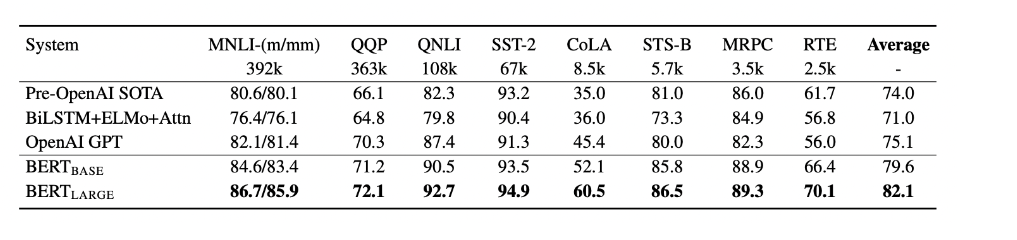
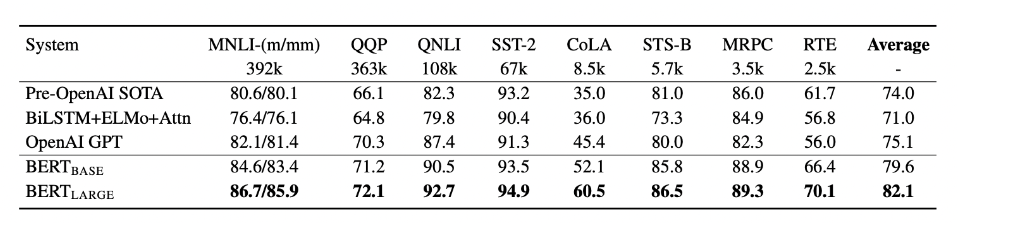
다 엄청 잘함
모든 GLUE task를 가각 3epoch씩 학습시켰다고 함
batch _size=32
Bert Large 모델은 작은 데이터셋에서 fine-tuning이 불안정해서 여러번의 재시작(random restarts) 후 Dev Set에서 가장 좋은 모델을 선택하는 과정을 거쳤다고 함
4-2. SQuAD v1.1
이건 100k 만큼의 crowd-sourced Q/A pair임
SQuAD는 질문-답 이아니라 질문 - 본문 형태로 되어있다는 것을 기억하자
여기서 특이한 부분이 있는데 살짝 헷갈리니까 집중
먼저 Start vector S 와 end vector E 를 초기화 함. 이는 각각 Answer의 시작과 끝을 에측하는데 사용된다.
만약 입력이
- " [CLS] What is the capital of France? [SEP] France is a country in Western Europe. Its capital is Paris, known for its art, fashion, and culture. [SEP]"
라 했을때 시작위치, 끝위치 target은 각각 14 , 17이 됨.
이 때 pre-trained 된 각 단어의 hidden state Ti 과 S가 내적한 값이 14에서 가장 크도록 학습함. 당연히 E는 17과 내적한 값이 가장 커야함. (Softmax - CE Loss)
이렇게 여러 Q-A 쌍으로 학습한 벡터 S,E는 inference 할 때 input 단어의 hidden state 별로 각각 내적을 해서 더한 값이 가장 큰 단어의 index 구함 => Answer의 시작과 끝 알게 됨
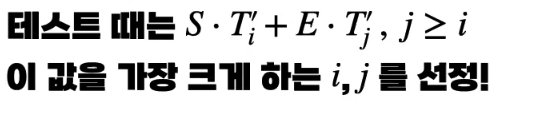
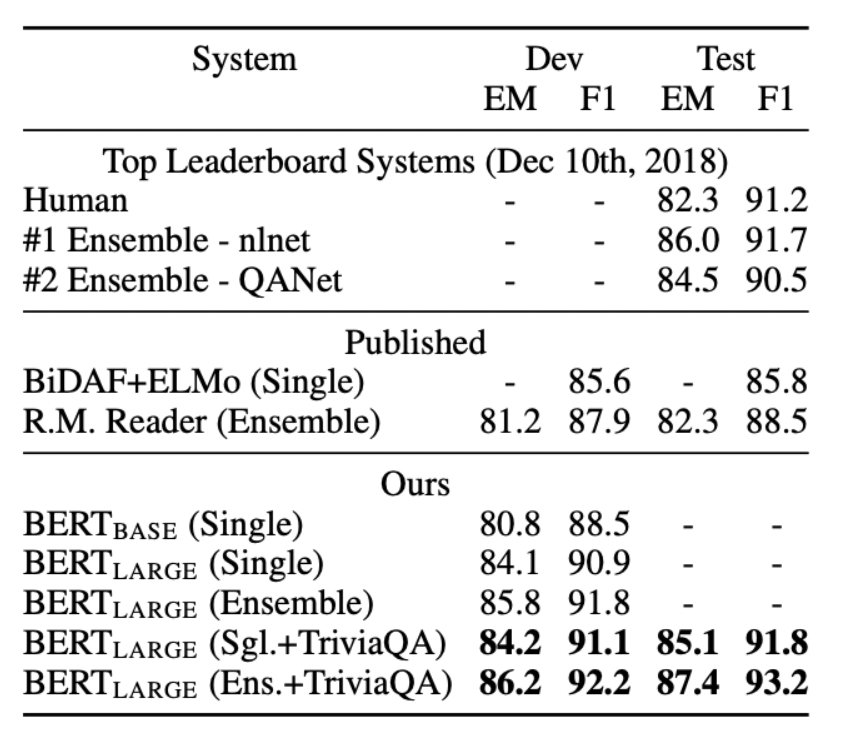
암튼 또 1등함
4-3. SquAD 2.0
세번째 실험은 SQuAD 2.0 dataset을 통해 진행됨.
근데 이건 아까랑 달리 답이 지문에 없다.
그래서 조금 더 까다로움
이런 경우에는 문장 전체의 의미를 담고 있다고 간주되는 CLS 토큰을 이용해야함

SC+EC가 그 어떤 단어의 hidden state와의 내적값 보다 크면 "답이 없다" 출력
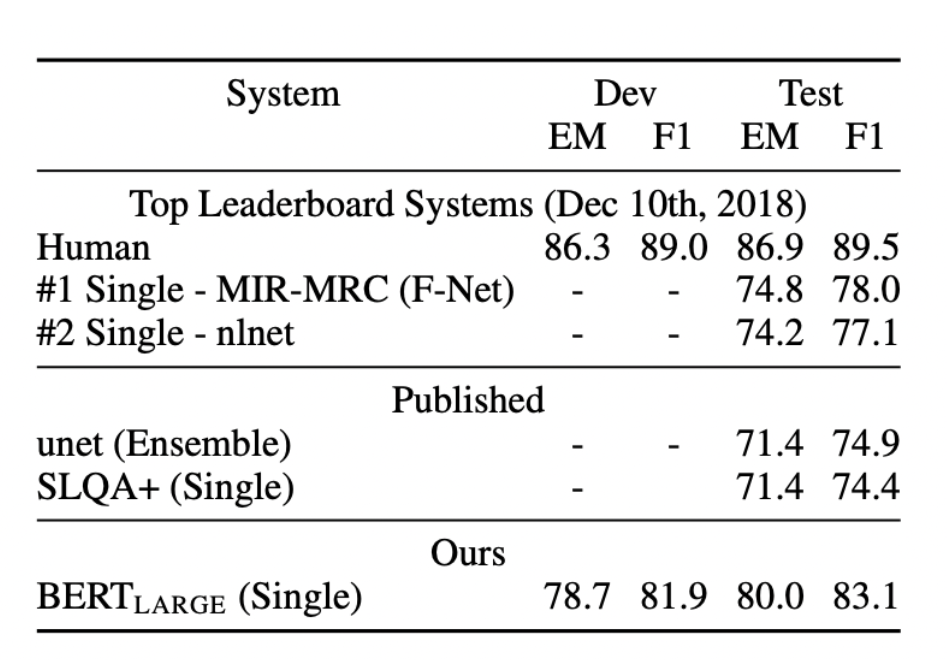
인간보단 못하지만 언어모델중 탑 ( unet도 있네?)
4-4. SWAG
쉽게 설명
SWAG(Situations With Adversarial Generations) 방식은 문장 쌍 추론 작업이다. 주어진 앞 문장에 이어지는 가장 잘 어울리는 문장을 4개의 보기 중에서 선택하는 작업이다. (재밌겠다..)
여기서 문장 4개를 concat해서 한번에 넣는게 아닌
따로따로 4번 넣기 때문에 네개의 C([cls]의 hidden state)가 나온다.
이때, 학습가능한 벡터 W를 도입해서 정답과의 내적한 값을 키우는 쪽으로 학습 시킴
(softmax + CE Loss)
5. Ablation Study
논문을 읽다 보면 Ablation Study라는 부분을 뺴놓을 수 없다. 이것은 연구자의 자존심임
Ai 시스템의 일부를 제거한후 제거한 부분이 전체적인 시스템의 성능에 어떻게 기여하는지 연구하는 것.
본 논문에서 제안한 것들이 어떠한 영향을 미치는지 증명하는 section이다.
매우 중요하겟죠?
여기서는 NSP, model size , feature-based Approach with Bert 이렇게 세가지로 나눠서 Ablation Study를 진행했다
NSP
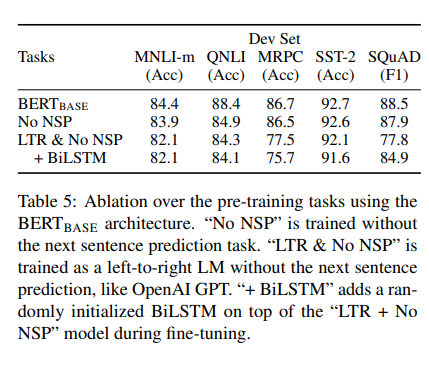
NSP를 안하자 문장 간의 논리적 연결성이 비교적 중요한 task들을(MNLI , QNLI ,SQuAD) 잘 못해짐
model-size
BERT 역시 모델이 클수록 좋더라
Feature-based-approach
Feature-based approach는 아래의 경우를 모두 고려하여 실험을 진행함
- Embedding만 사용
- 2번째 부터 마지막 Hidden을 사용
- 마지막 Hidden 만 사용
- 마지막 4개의 Hidden을 weighted sum 함
- 마지막 4개의 Hidden을 concat 함
- 모든 12개의 층의 값을 weighted sum 함
여기서 hidden만 사용했다는 것은 BERT 모델의 다양한 히든 레이어(hidden layer) 출력을 사용했다는 뜻
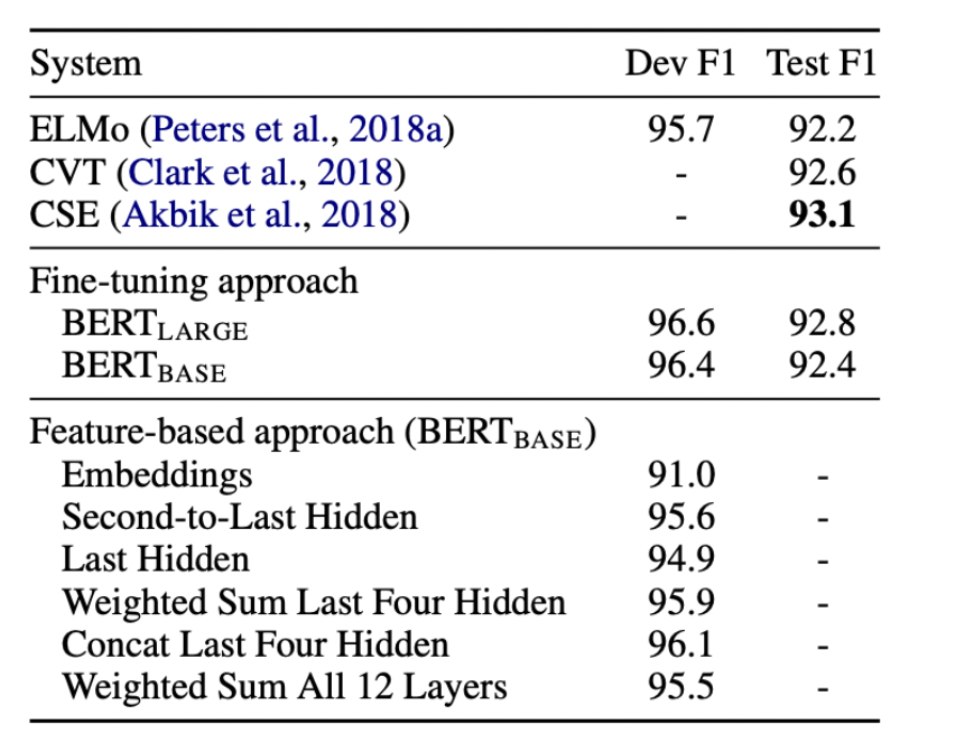
마지막 4개 layer concat한게 가장 성능이 잘 나왔다. (concat >> weighted sum)
후기
이번 논문은 읽는데 피로도가 거의 없었습니다.
너무 재밌게 잘 읽었고
다음엔 encoder-decoder Transformer 아키텍쳐를 기반으로 한 BART논문에 대해서 알아볼게요.
아직 2019년도 논문에 멈춰있는데 빠르게 진도를 빼야겠네요.
읽어주셔서 감사합니다. (꾸벅)
