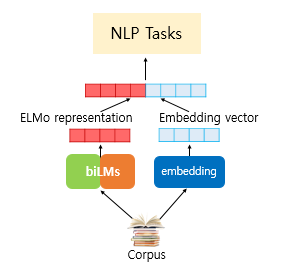
2019년에 나온 구글 BERT 모델에 대해서 알아봅시다.
0. Abstract
BERT는 모든 층에서 좌우 문맥을 동시에 고려한 비지도 학습을 통해 깊이 있는 양방향 표현을 pre- train 하도록 설계 되었다.
그 결과, 사전 학습된 BERT 모델은 하나의 추가 출력 층만으로 fine-tuned 되며 여러 task에서 SOTA 모델을 달성함.
1. Introduction
BERT 논문에서는 사전 학습된 언어 표현을 다운스트림 작업에 적용하는 두 가지 기존 전략(feature-based , fine-tuning)을 설명하고, 기존 방법의 한계점을 지적한다.
특히, 기존 언어 모델들이 단방향이어서 문맥을 양방향으로 통합하지 못하는 점을 문제로 삼았다.
BERT는 모든 층에서 좌우 문맥을 동시에 고려하는 양방향 트랜스포머 아키텍처를 사용하여 이 문제를 해결하고, 질문 응답 및 언어 추론과 같은 다양한 작업에서 Sota를 달성할 수 있음을 보여줌

GPT를 엄청디스함..
BERT의 핵심 아이디어는 "깊이 있는 양방향 문맥(deep bidirectional context)"의 중요성을 강조하는 거임. 기존의 단방향 모델들(예: 좌에서 우로 읽는 모델들)은 문맥을 충분히 이해하지 못한다는 단점을 가지고 있다고 주장.
Masked Language Model (MLM)
BERT는 이러한 단방향성의 한계를 극복하기 위해 "Masked Language Model(MLM)"을 사전 학습에 사용한다.
MLM의 동작 방식:
1. 토큰 마스킹: 입력 문장에서 임의의 몇몇 단어를 마스킹(masking)한다, 즉 가려서 숨겨버림.
- 예: "고양이는 [MASK]에서 잔다."
- 예측: 모델은 이 가려진 단어가 무엇인지 맞추려고 노력함. 즉, 전체 문맥을 보고 "[MASK]" 자리에 어떤 단어가 들어갈지 예측하는 거지.
- 예: "고양이는 침대에서 잔다."
양방향 문맥의 중요성
기존 단방향 모델과 달리, MLM은 문장의 앞뒤 모든 문맥을 사용해 예측을 하기 때문에 문맥을 더 깊이 이해할 수 있음. 이렇게 하면 모델이 더 정확한 언어 이해를 할 수 있게 된다고 주장.
Next Sentence Prediction
BERT는 MLM 외에도 "Next Sentence Prediction"이라는 추가 작업을 사용한다. 이는 두 문장이 주어졌을 때, 두 번째 문장이 첫 번째 문장의 다음에 오는 문장인지 아닌지를 맞추는 작업인데, 이를 통해 문장 간의 관계를 더 잘 이해할 수 있게 됨.
2.Related work
2.1 Unsupervised Feature-based Approaches
사전학습된 단어 임베딩의 중요함을 강조하고
word embedding을 통한 접근 방식은 자연스레 sentence embedding 혹은 paragraph embedding으로 이어졌다는 것을 언급함
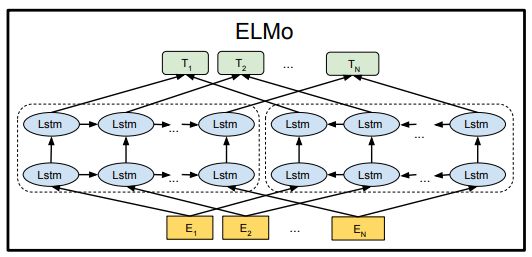
ELMo와 그 뒤의 모델들은 left-to-right와 right-to-left 언어 모델을 통해 context-sensitive feature들을 뽑아 내서 각 represevtation을 concat함 (shallow-bidirectional)
이런 방식으로 ELMO는 웬만한 NLP benchmark들을 다 때려잡으면서 SOTA로 등극 =>BUT 마음에 안듬 deep하게 bidirectional하지 않다.
2.2 Unsupervised Fine-tuning Approaches
contextual token representation을 만들어내는 (문장 혹은 문서) 디코더가 pre-training되고, supervised downstream task에 맞춰 fine-tuning 되는게 최근에 연구됨 (GPT-1)
2-3. Transfer Learning from Supervised Data
지도 학습 데이터로부터의 전이 학습을 하는 방식도 최근에 각광 받고있음 ( 자연어처리 , CV )
3.BERT
BERT도 마찬가지로 pre-training 방식과 fine-tuning 방식이 있음
Model architecture
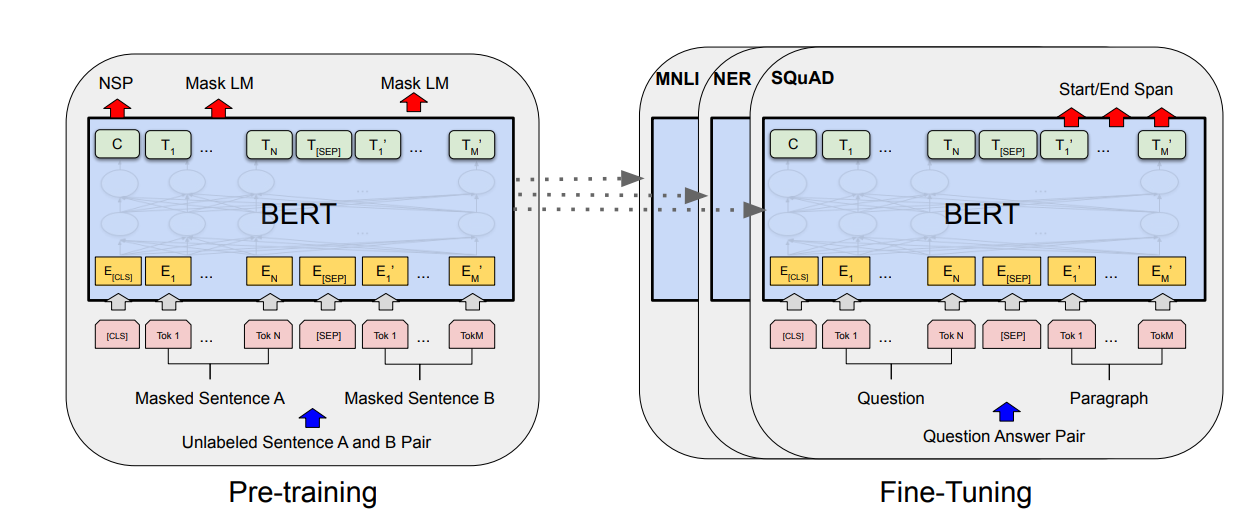
bidirectional Transformer encoder 임
BERT base 와 BERT large 두가지가 있음
BERT base의 경우 L = 12, H = 768, A = 12로 총 110M개의(약 1억1천만) 파라미터를 사용하였고 =>GPT와 유사함
BERT large의 경우 L = 24, H = 1024, A = 16으로 총 340M개의(약 3억4천만) 파라미터를 사용하였다.
Input/Output Representations
BERT가 다양한 down-stream tasks에 잘 적용되기 위해선 input representation이 애매하지 않아야 함
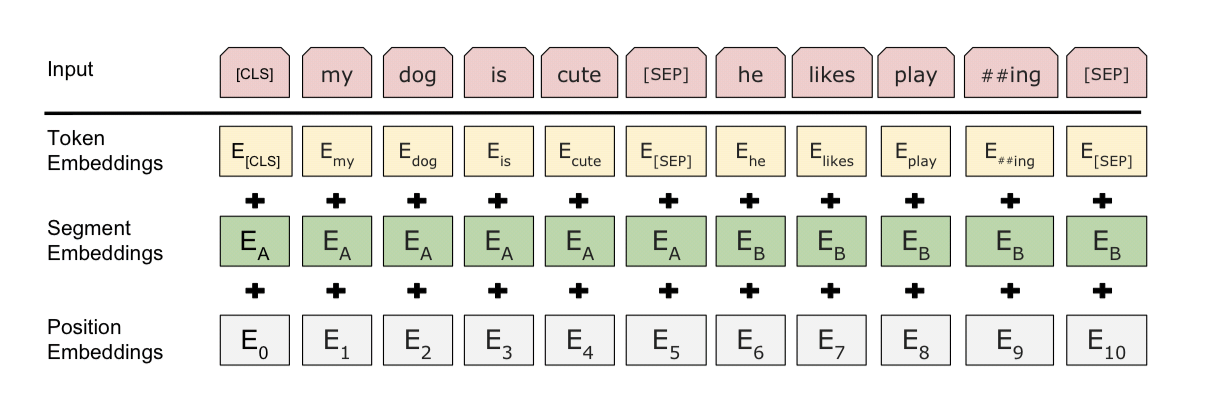
모든 시퀀스의 첫 번째 토큰은 항상 특별한 분류 토큰([CLS])
이 토큰에 해당하는 최종 히든 상태는 분류 작업의 시퀀스 전체를 대표하는 표현으로 사용됨.
Input 시퀀스는 문장의 한 쌍으로 구성된다.
문장 쌍의 각 문장들은 [SEP] 토큰으로 분리된다. 또한 각 문장이 A문장인지, B문장인지 구분하기 위한 임베딩(Segment Embeddings) 역시 진행한다.
Input representation은 이러한 대응되는 토큰(segment + token + position)을 전부 합치면 됨
3-1.Pre-training BERT
BERT는 두가지 unsupervised task를 사용해서
pre-train을 시킴
Masked LM
직관적으로 우리는 양방향 모델이 기존의 것들보다 더 강력하다고 믿을 수도 있지만 양방향 학습을 할때는 단어가 간접적으로 자기 자신을 볼 수 있게 되어서 목표단어를 쉽게 예측할 수 있게됨 (그냥 단서가 많아진다는 말임)
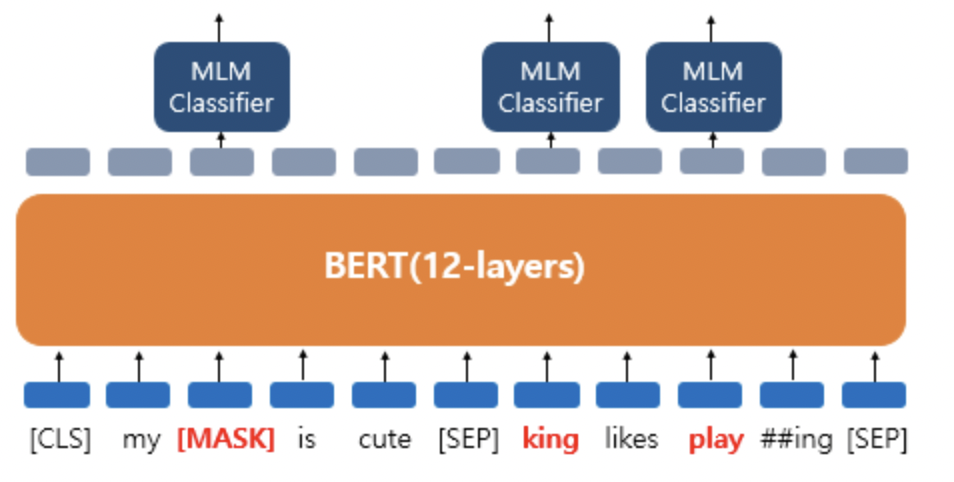
그래서 MLM이라는 기법을 도입한다.
마스크된 토큰에 해당하는 최종 hidden-vector => FC layer=>softmax=>CE-Loss
이를 통해 양방향으로의 학습이 가능해지지만, fine-tuning 중에 [MASK] 토큰이 나타나지 않기 때문에(빈칸 단어 예측은 그냥 빈칸 단어로 주어지기 때문), 사전 훈련과 fine-tuning 사이에 불일치를 만들어내는 단점이 있다.
그래서 아래와 같은 추가적인 작업을 해준다.
mismatch를 줄 일 수 있게
WordPiece 토큰의 15%를 무작위로 마킹하며 마킹한 것들의
- 80%의 경우 : token을 [MASK] token으로 바꾼다. ex) my cat is hairy -> my cat is [MASK]
- 10%의 경우 : token을 random word로 바꾼다. ex) my cat is hairy -> my cat is funny
- 10%의 경우 : token을 원래 단어 그대로 놔둔다. ex) my cat is hairy -> my cat is hairy
NSP (Next Sentence Prediction)
많은 NLP의 downstream task들은 두 문장 사이의 관계를 이해하는 것이 중요하다.
이를 학습하기 위해 BERT는 NSP를 사용함.
pretraining-example을 구성할 때, 실제로 다음에 오는 문장 50% (labeled as IsNext) , 무작위로 선택된 문장 50% (labeled as NotNext)으로 dataset을 구성함
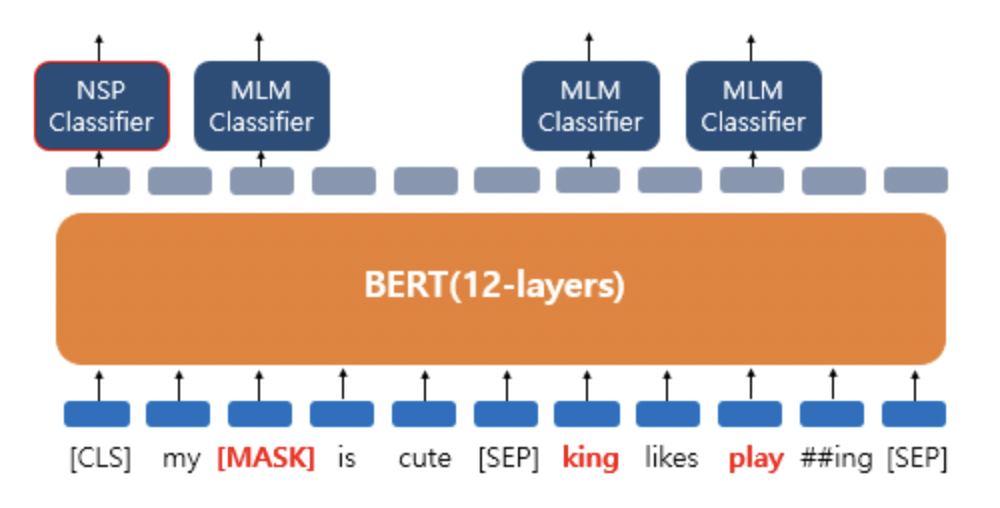
[SEP]을 통해서 문장을 구분하고
NSP 예측 헤드는 [CLS]토큰의 최종 히든벡터 C를 추출해서 이진분류 작업을 수행함
Data
BooksCorpus(8억 단어)와 영어 위키피디아(25억 단어)를 사용
3-2 Fine-tuning BERT
BERT는 텍스트 쌍을 연결(concatenate)하여 self-attention으로 인코딩함으로써 bidirectional cross attention을 포함한다.
1. Paraphrasing (의역)
- 목적: 두 문장이 같은 의미를 갖는지 여부를 판별.
- 입력 형식: 두 문장을
[CLS] 문장1 [SEP] 문장2 [SEP]형식으로 입력. - 출력:
[CLS]토큰의 히든 스테이트를 통해 두 문장이 같은 의미인지 여부를 예측하는 이진 분류.
2. Hypothesis-Premise Pairs in Entailment (함의 관계 분류)
- 목적: 두 문장(이론과 가설) 사이에 함의 관계가 존재하는지 분류.
- 입력 형식:
[CLS] 이론 [SEP] 가설 [SEP]형식으로 입력. - 출력:
[CLS]토큰의 히든 스테이트를 사용하여 함의 관계(엔테일먼트, 중립, 모순)를 예측하는 다중 클래스 분류.
3. Question Answering (질문 응답)
- 목적: 주어진 문맥에서 질문에 대한 답변을 추출.
- 입력 형식:
[CLS] 문맥 [SEP] 질문 [SEP]형식으로 입력. - 출력: 각 토큰의 시작 위치와 끝 위치를 예측하여 답변을 추출. 모델은 각 토큰에 대해 시작 score 와 끝 score를 출력함.
4. Tagging and Text Pair Classification (태깅 및 문장 쌍 분류)
-
Tagging:
- 목적: 문장의 각 단어에 대해 품사 태깅이나 개체명 인식 등의 작업 수행.
- 입력 형식:
[CLS] 문장 [SEP]형식으로 입력. - 출력: 각 토큰의 위치에 대한 예측을 통해 품사 태그 또는 개체명 태그를 예측.
-
Text Pair Classification:
- 목적: 두 문장 간의 관계를 예측 (예: 문장 유사도, 대화 응답 등).
- 입력 형식:
[CLS] 문장1 [SEP] 문장2 [SEP]형식으로 입력. - 출력:
[CLS]토큰의 히든 스테이트를 사용하여 두 문장 간의 관계를 예측하는 분류 작업.
fine-tuning작업은 짧게 끝난다고 한다
TPU에서 1시간
GPU에서 몇시간
