여러 Imagnet task에서 우수한 성적을 보인 모델들에 대해서 간략하게 짚고 넘어가봅시다!
Lenet-5
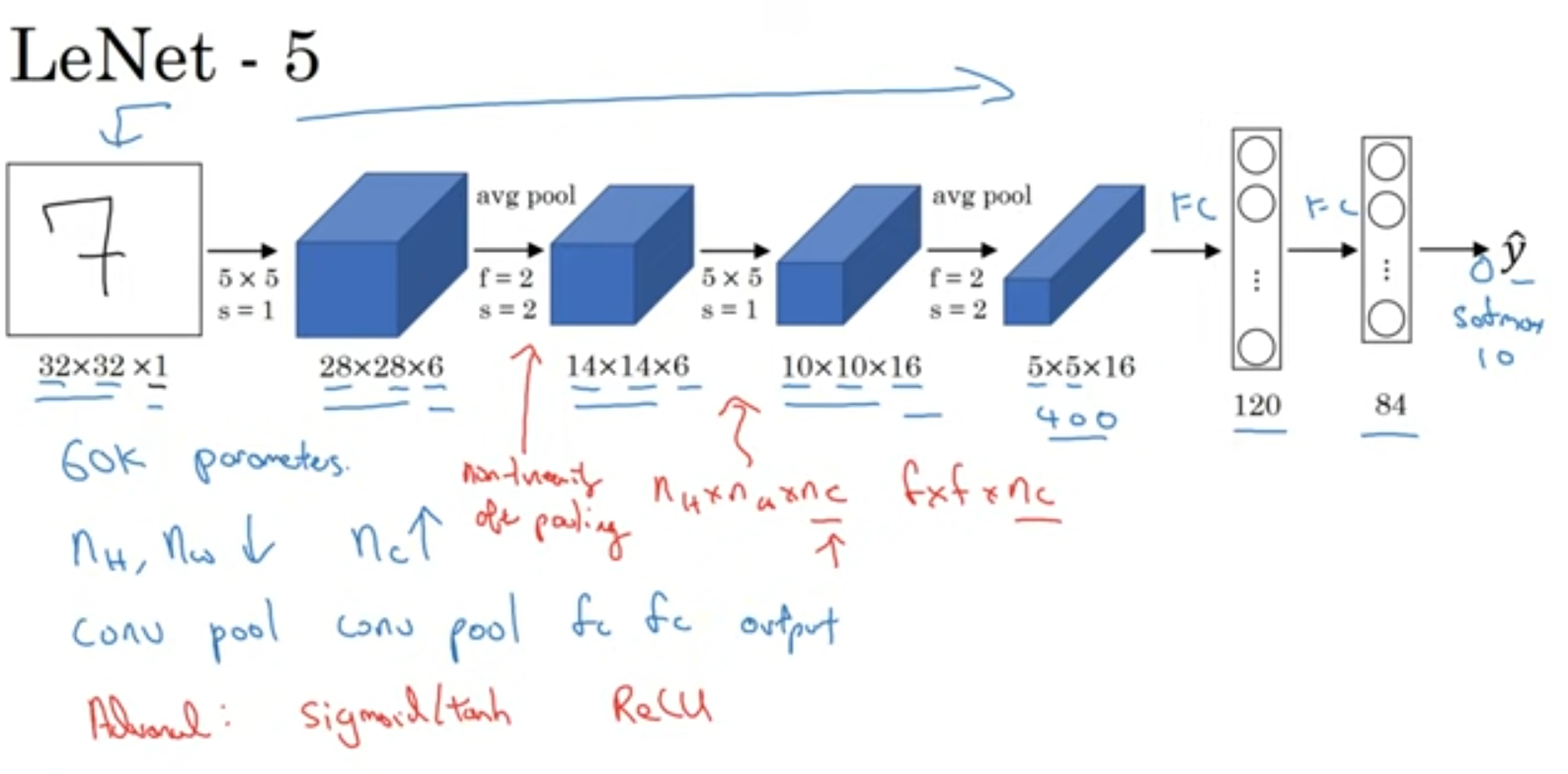
이 당시에는 ReLu가 없어서 sigmoid와 tanh를 이용해서 비선형성을 추가했습니다.
Alexnet
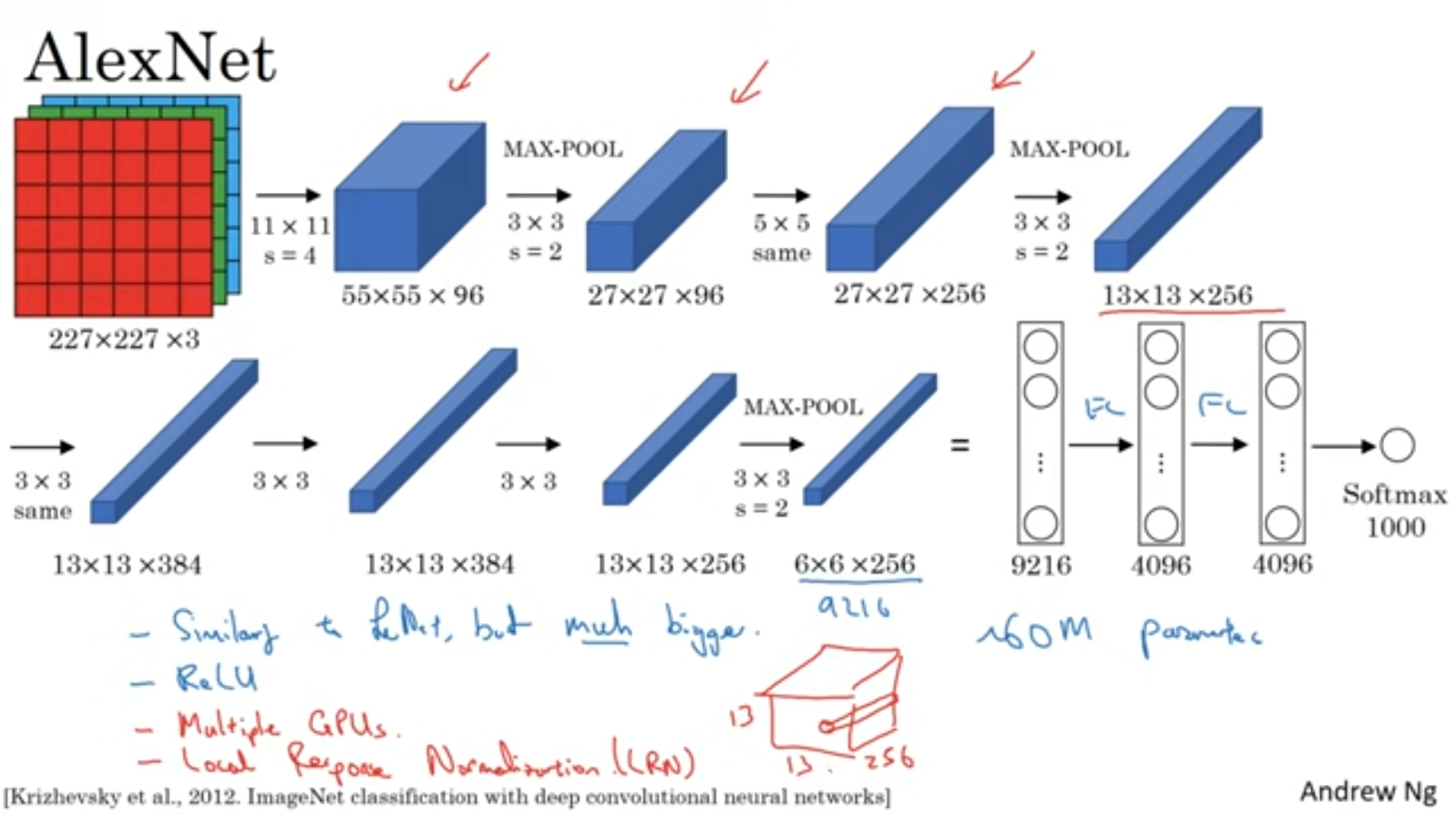
Lenet보다 규모가 커졌지만 구조는 비슷합니다.
ReLu함수가 등장했죠.
당시에는 GPU가 느려서 Multiple Gpu를 이용한 복잡한 방식으로 훈련을 시켰다고 하네요.
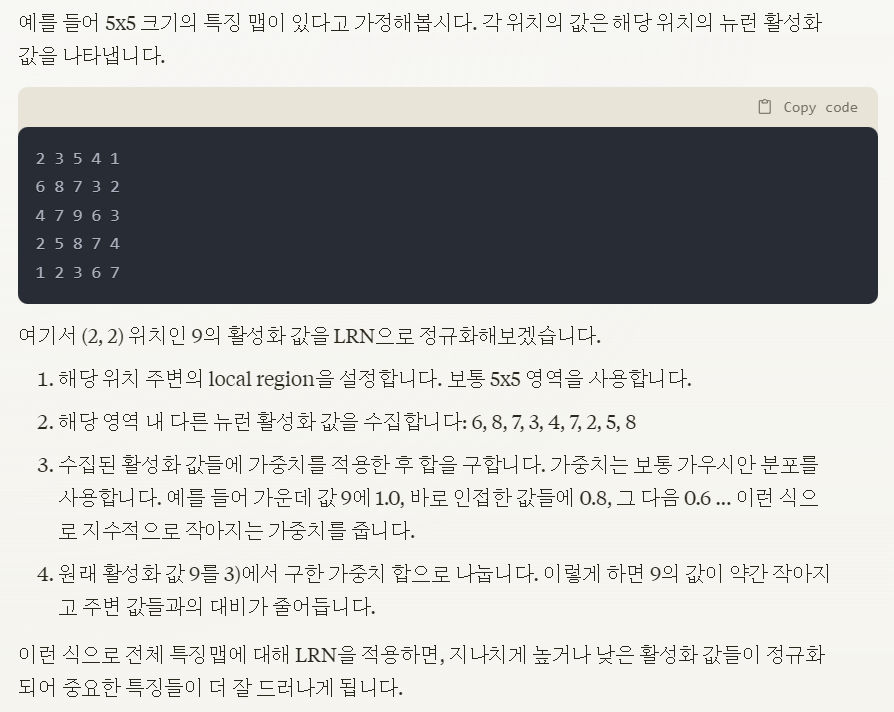
Local Response Normalization(LRN) 개념도 등장합니다.
클로드 3 가 설명하는 LRN의 동작
VGG-16
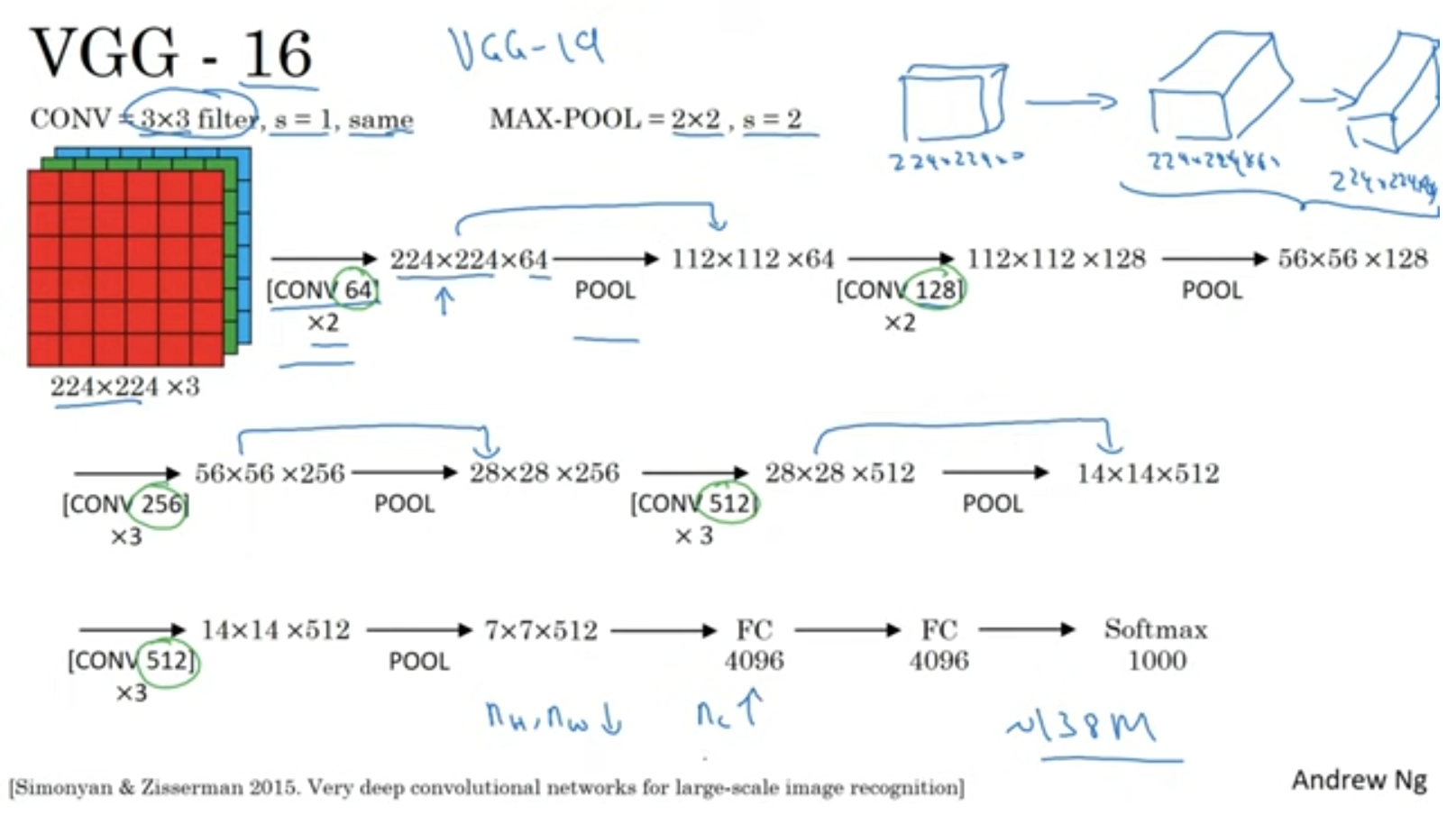
1.3억개의 파라미터를 가진 VGG-16입니다.
ResNet
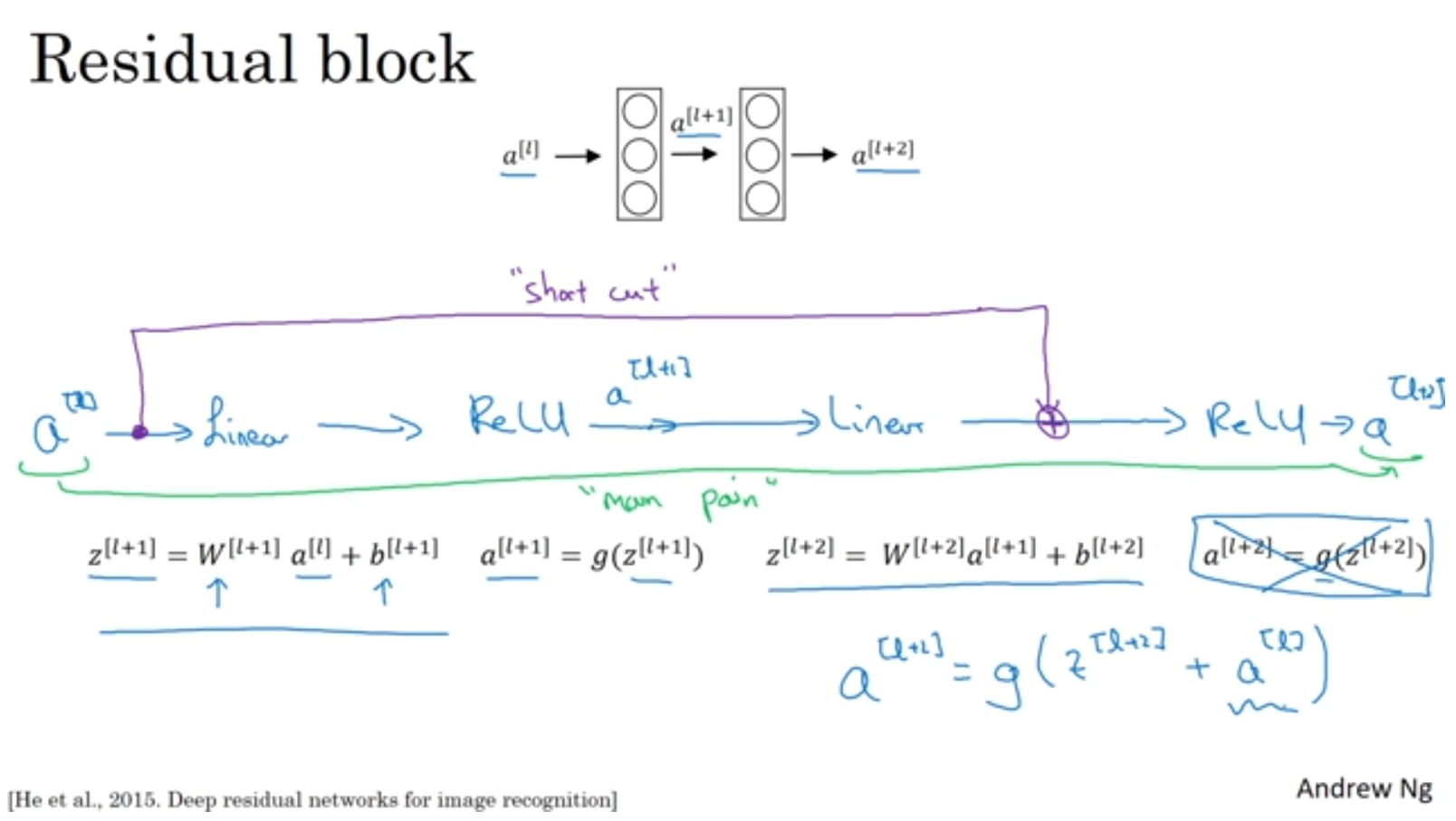
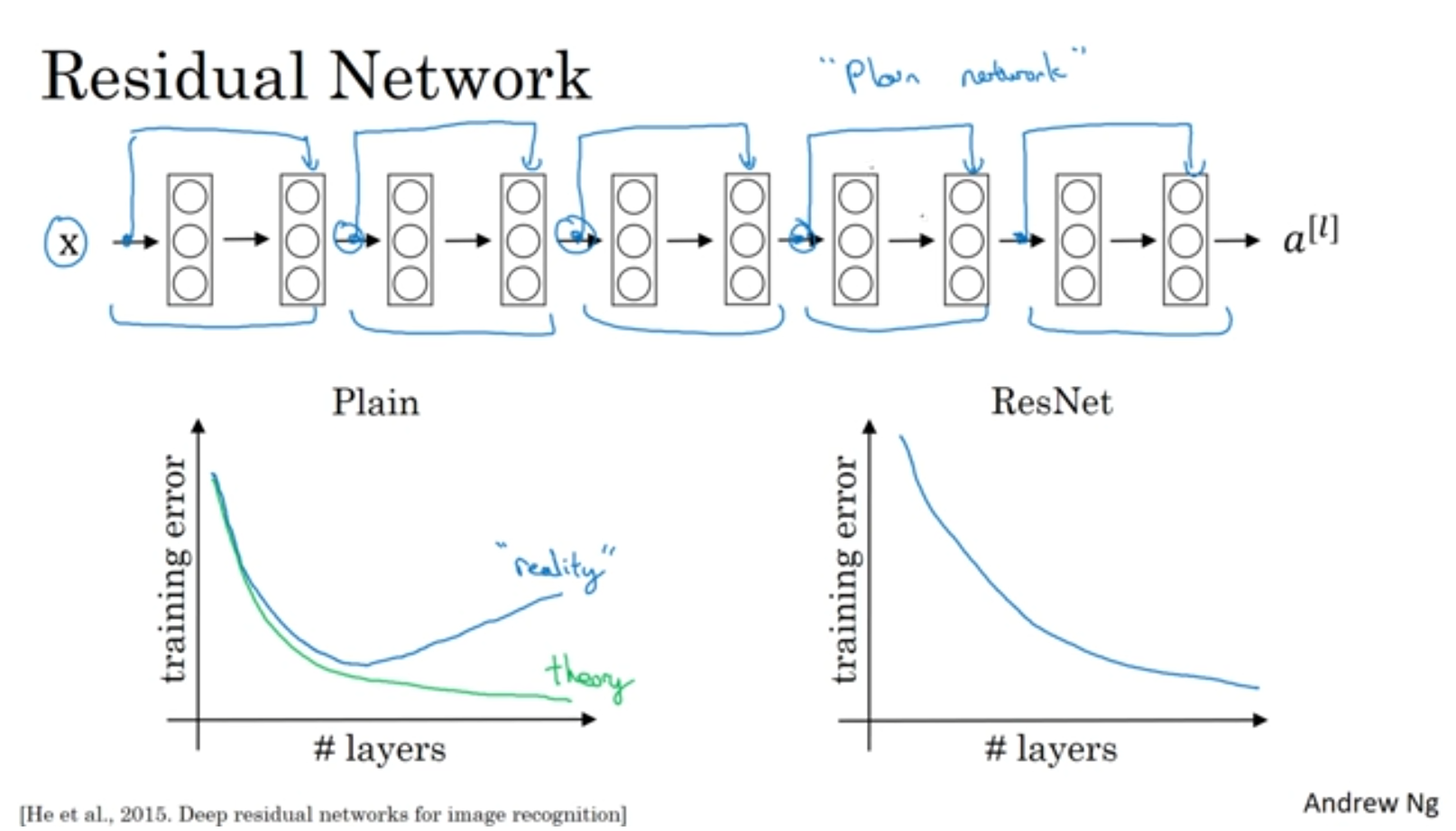
여기서 이해가 안되는 부분하나는 신경망이 깊어지는데 training error값이 증가한다는 것인데요.
논문에서는 단순 layer를 깊게 쌓는다면 모델의 학습 난이도가 높아진다고 나와있다고 하네요. 그래서 우리가 의도 했던대로 최적화를 시키는 것이 쉽지 않다고 합니다.
그렇다면 왜 Residual block이 잘 작동할까요?
H(x) = R(x) + x
위의 식을보면 잔차(R(x))만 학습하면 되기 때문에 최적화가 쉬워집니다.. 극단적으로 R(x)가 0이 되어도 indentity mapping이 되어 training error가 올라가지 않습니다. identity mapping이 optimal function에 가까울수록 잔차 학습이 수월해지겠죠.
즉,이전 layer의 activation으로 아예 새로운 함수를 추론하는게 아닌 "추가적으로 학습할게 없나?" 식의 접근을해서 없음 말고 있으면 좋고! 느낌의 해석을 하는 것 같습니다.
+x 덕분에 gradient vanishing 없애는 효과는 덤 ㅋ
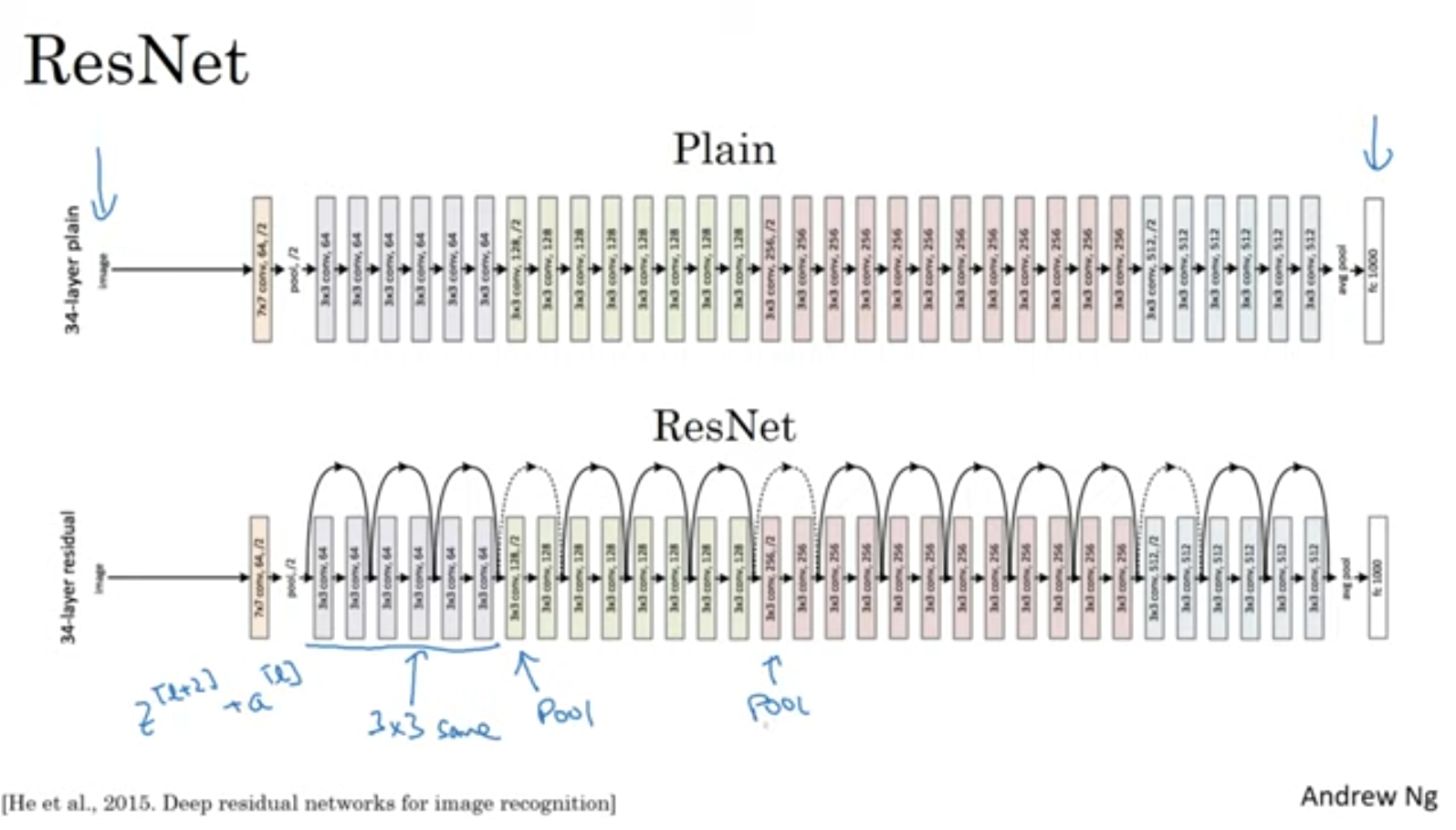
구조는 위와 같습니다.
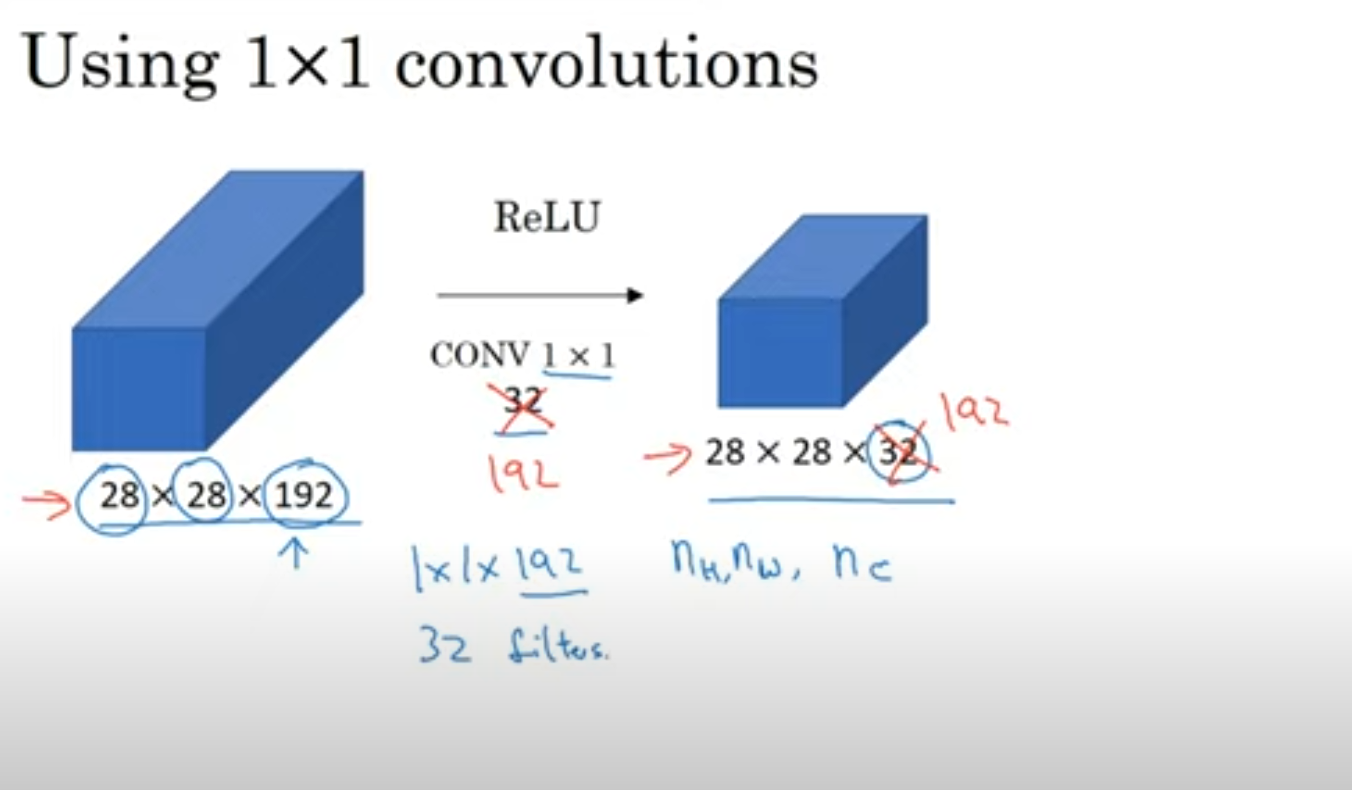
1x1 Convolution
네트워크에 비선형성을 추가해주고 채널수를 조절 할 수 있게 해줍니다.
INCEPTION Net
전부 합쳤네요.
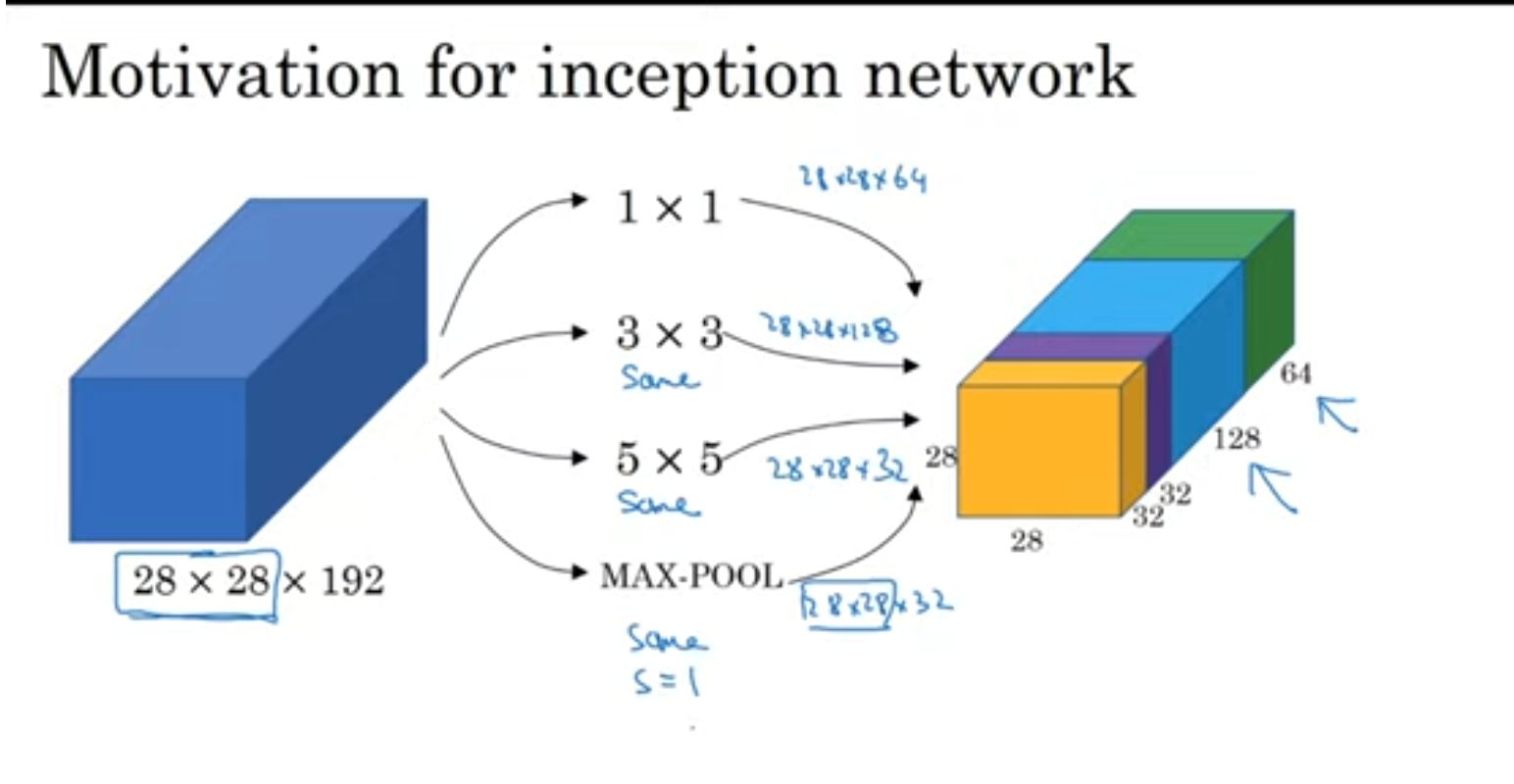
s=1인 것을 보니까 3*3 max_pooling인 것 같습니다.
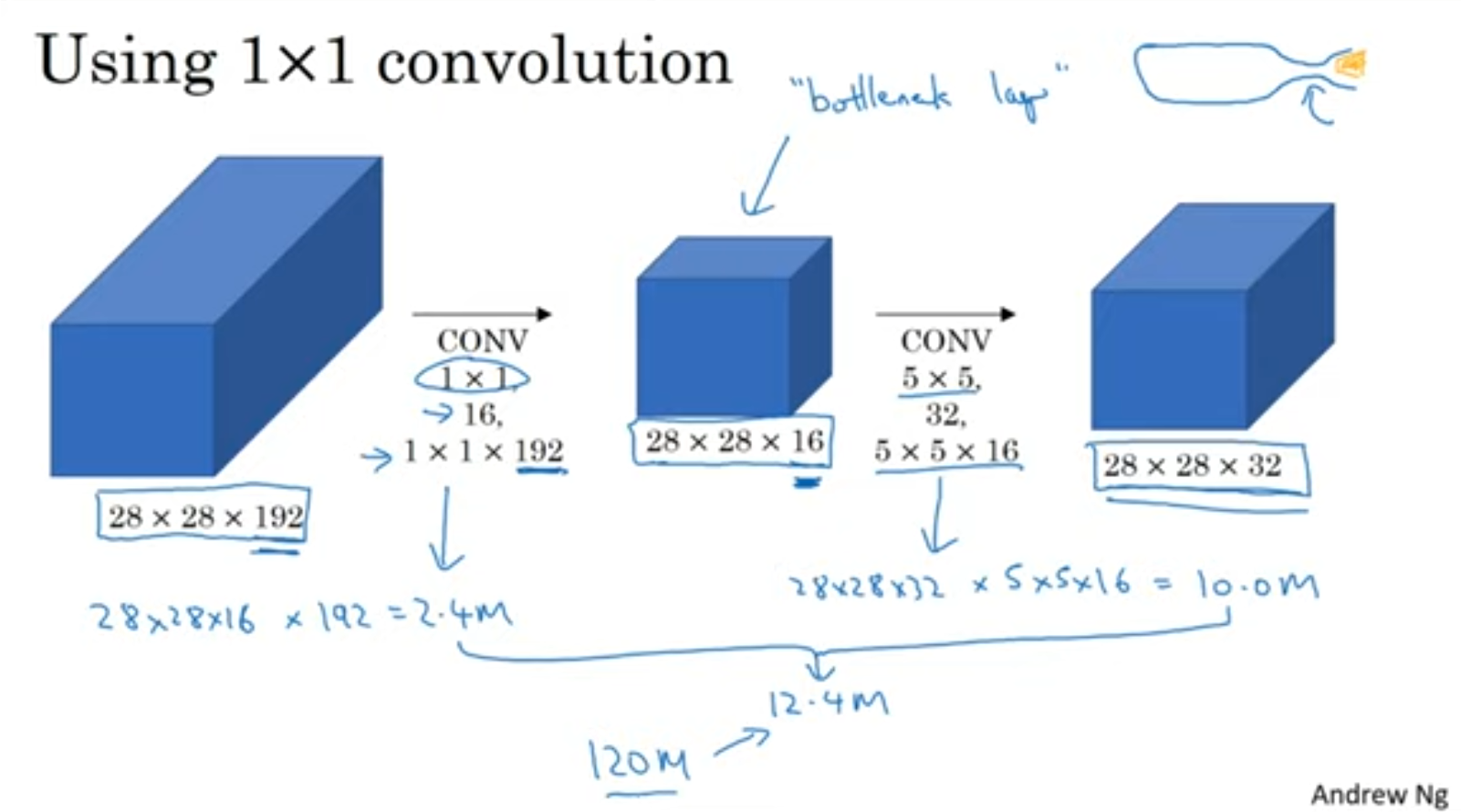
위와 같이 1x1 conv를 사용하면 computation양을 드라마틱하게 줄일 수 있습니다. 한번 확 줄이고 다시 규모를 키워서 bottleneck layer라고도 불린다고 하네요 😂
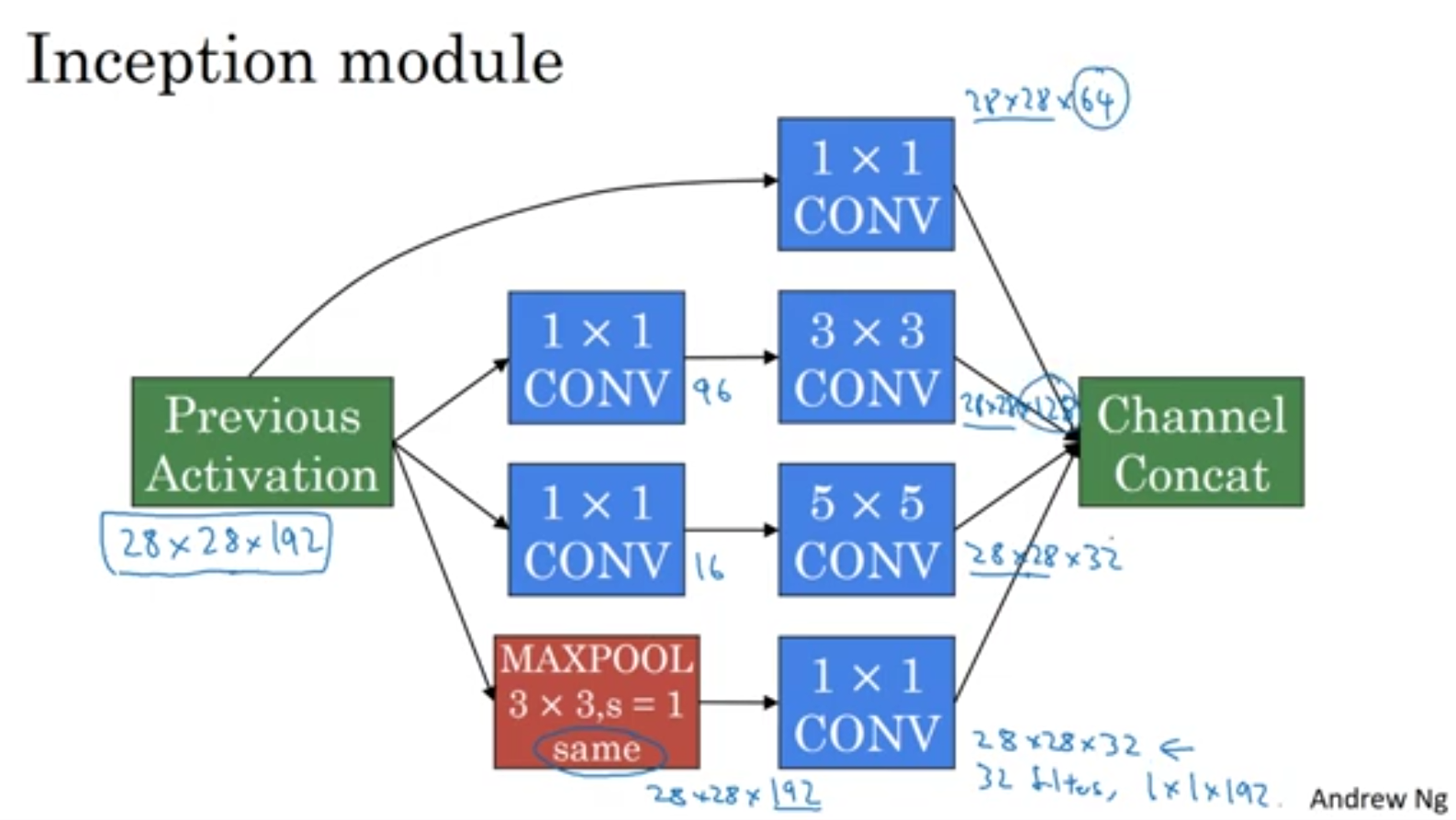
1x1 conv를 사용해서 연산량을 많이 줄인 것을 볼 수 있습니다.!
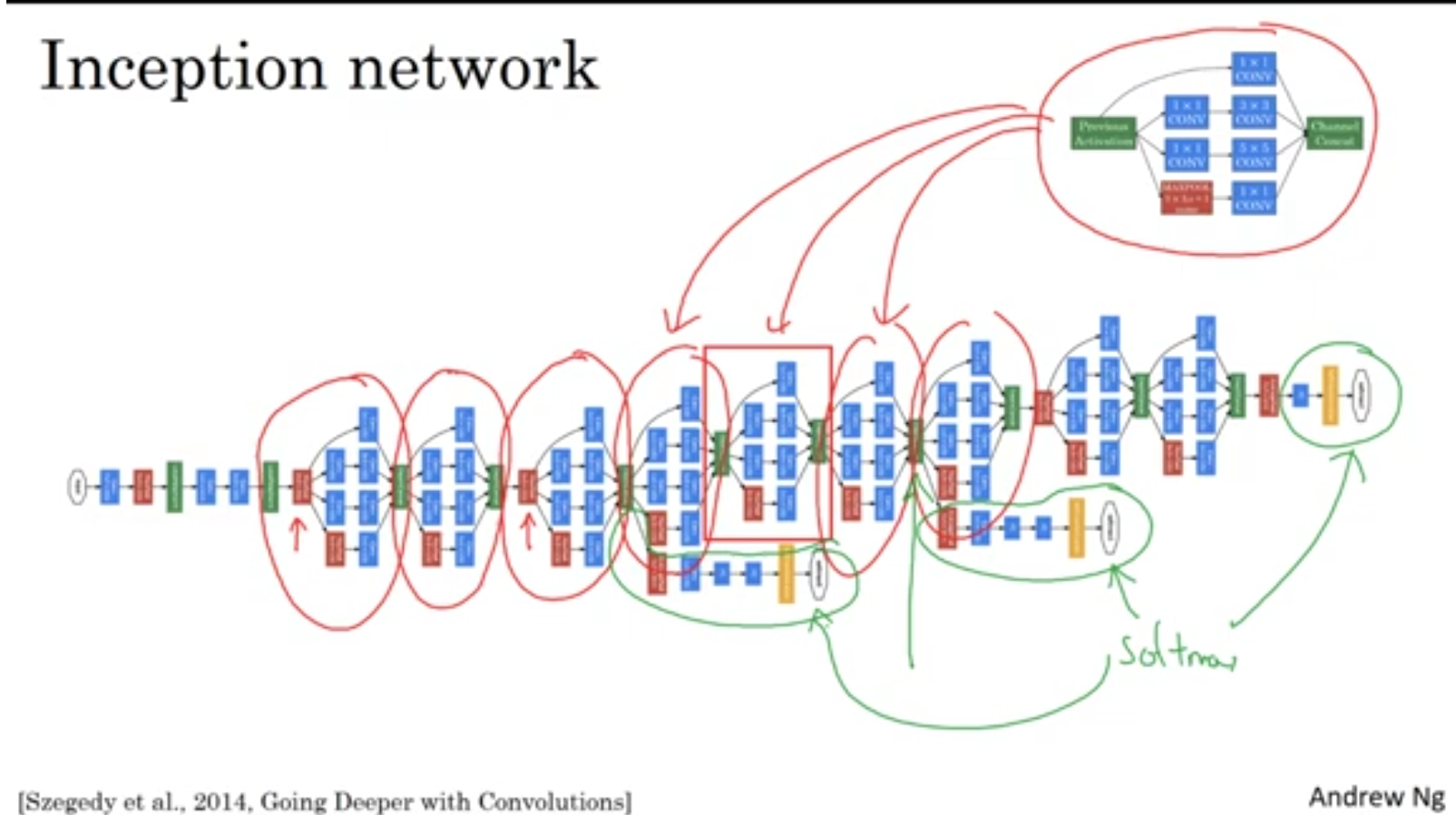
이걸 여러개 계속 붙여줍니다. 은닉층에서도 추론을 한다는게 눈여겨볼 점 인 것 같습니다.
Practical advice
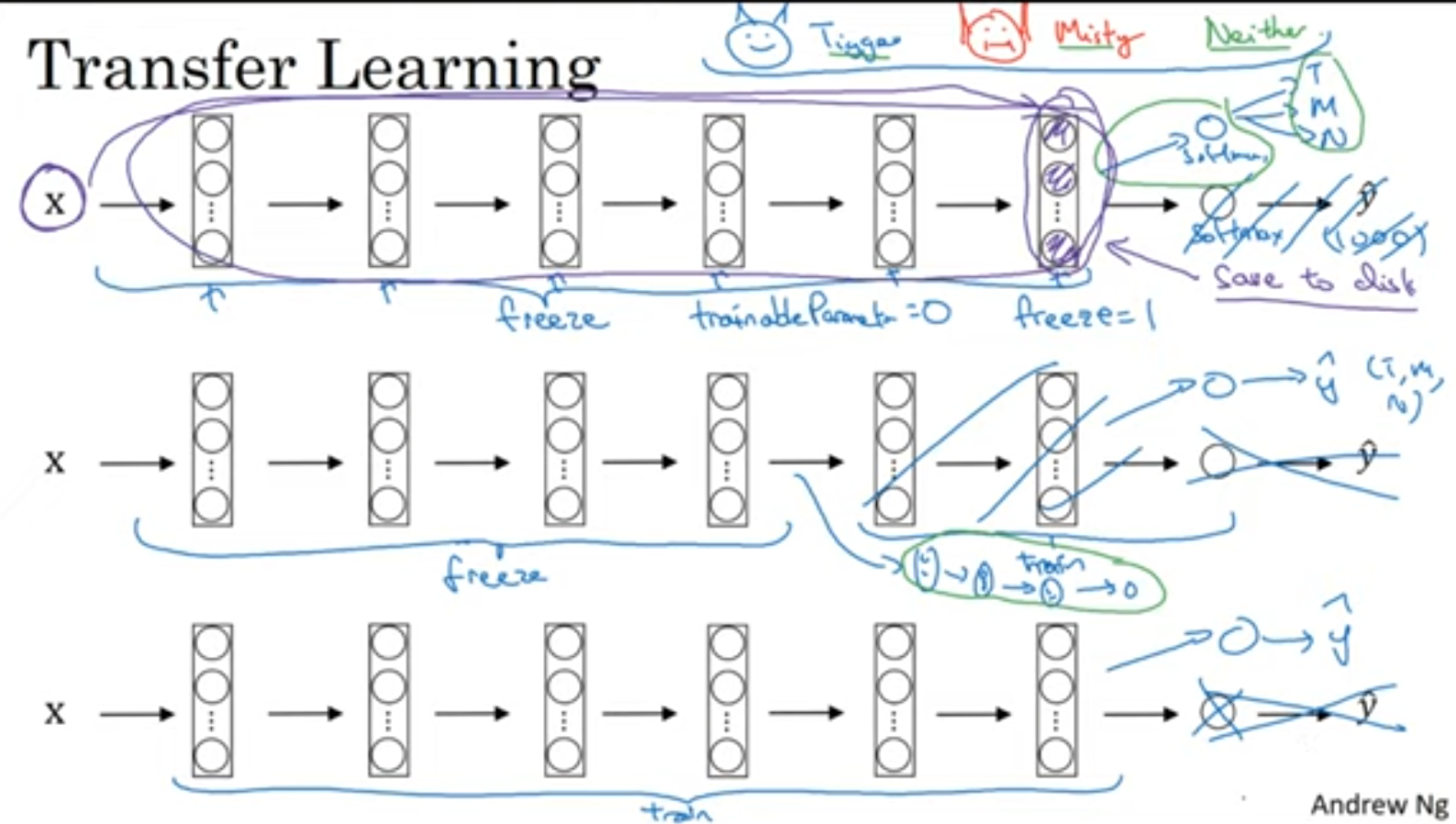
transfer learning
아래로 갈수록 데이터가 많다고 생각하면 됩니다.
Computer vision에서는 Transfer learning을 하는 것이 아주 중요하다고 하네요.
Data augmentation
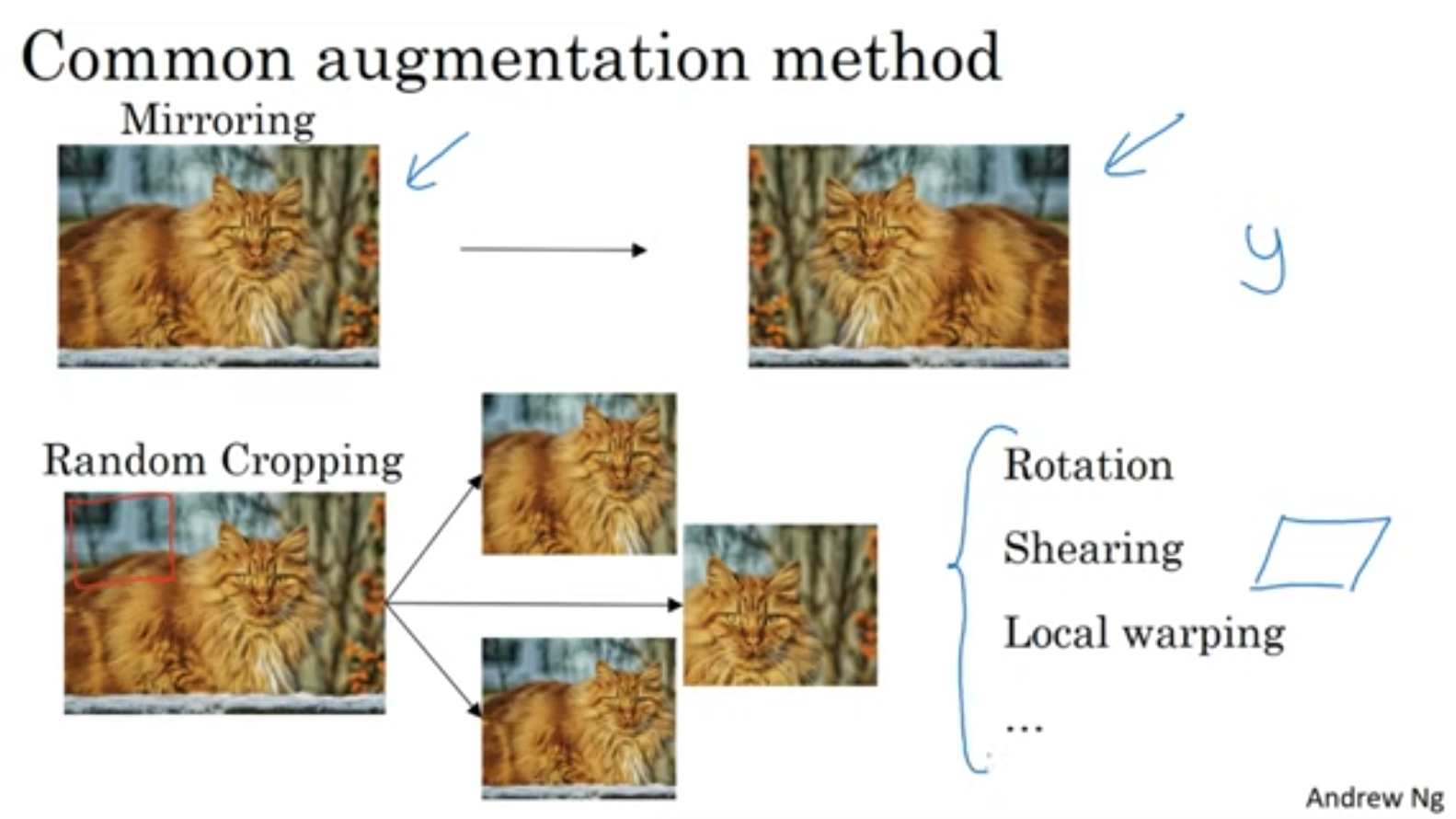
뒤집고 돌리고~ 짜르고 ~ 여러가지 방법들이 있습니다.
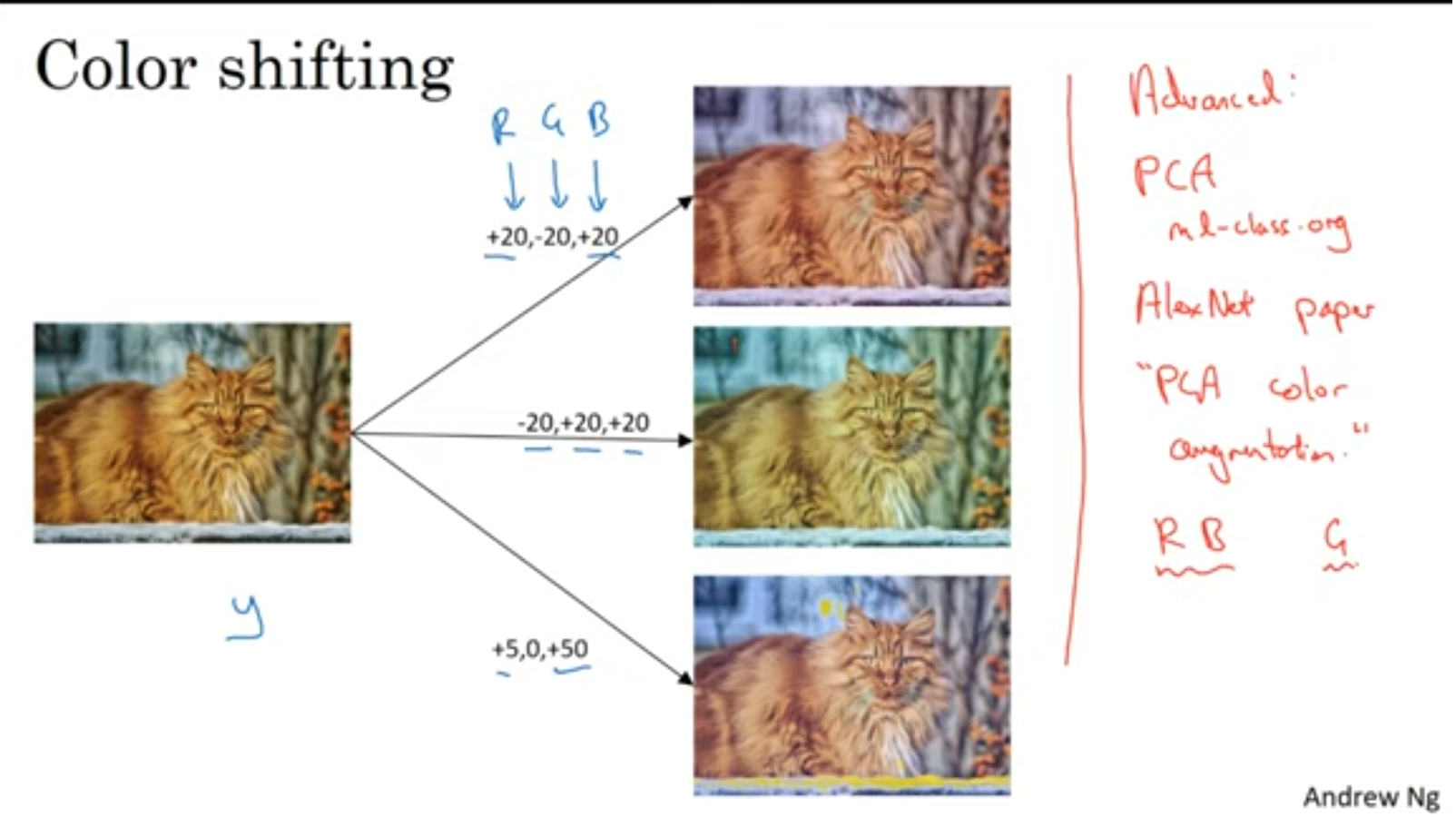
색깔도 바꿔줍니다. PCA 알고리즘을 적용해 볼 수 있겠네요.
데이타 augmentation을 할때도 hyperparameter들이 있습니다.(얼마나 크로핑 할지, 색은 얼마나 바꿀지) 오픈소스들을 사용해서 시작하는 것이 좋겠죠.
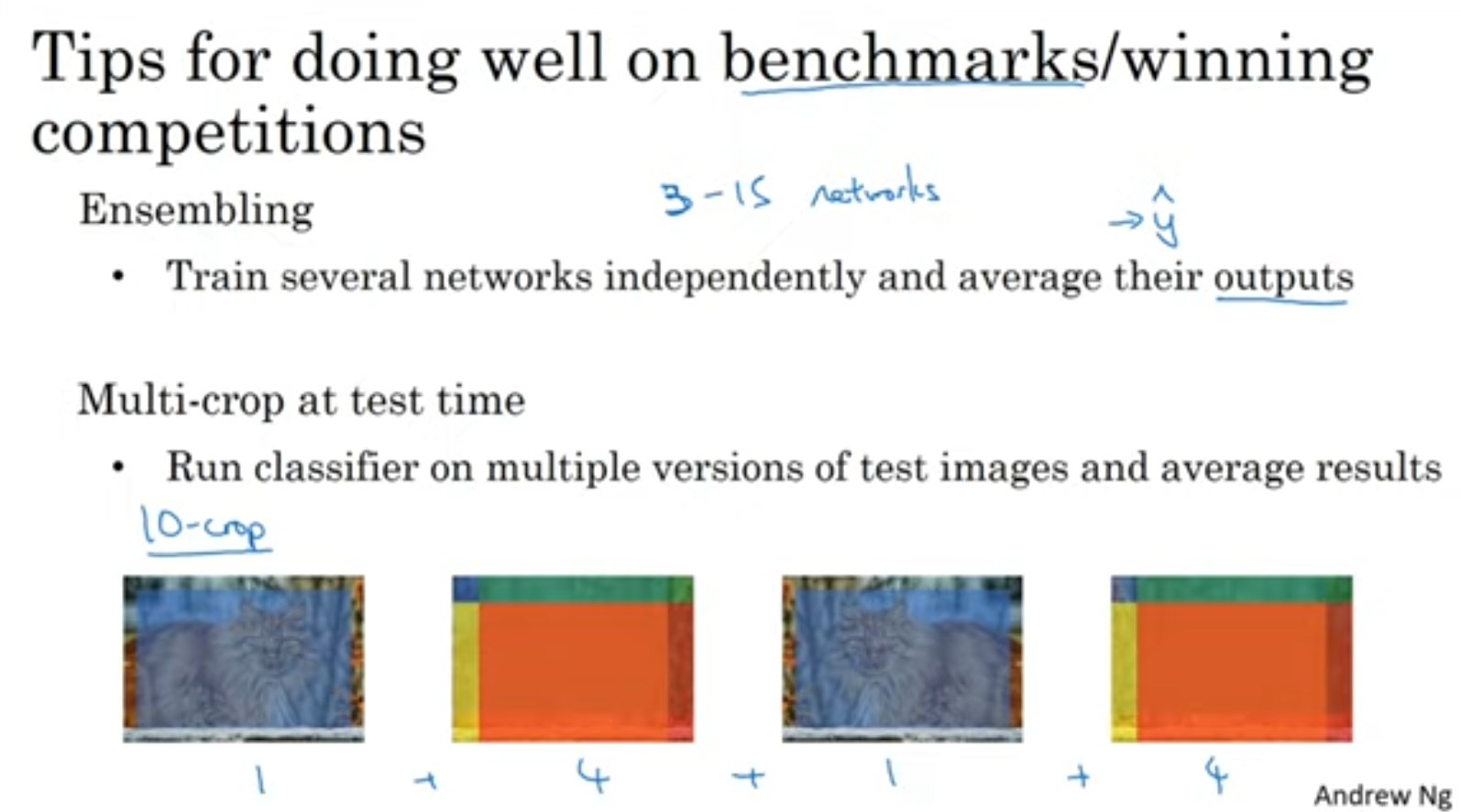
벤치마킹 성능을 높이는법입니다.
앙상블 기법은 그만큼 resource를 많이 잡아먹는다는 단점이 있겠죠.
반면에 다중 크로핑은 한개의 네트워크를 사용하기 때문에 리소스를 아낄 수 있습니다.(실행 시간은 꽤나 늦추겠지만요)
대회에서 밴치마킹 하는경우가 아닌 실제 Product를 제공할때는 위와 같은 방법을 쓰면 안되겠죠!
아래는 앙상블 기법의 두가지 Voting metric입니다.
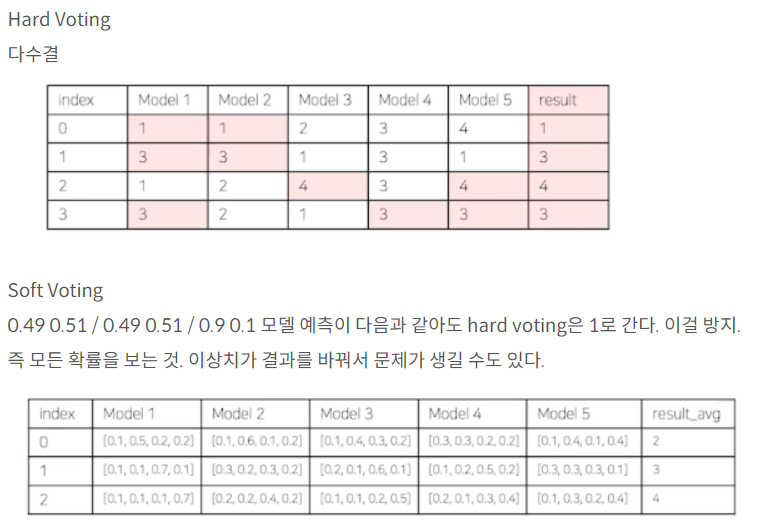
마무리

