Object localization
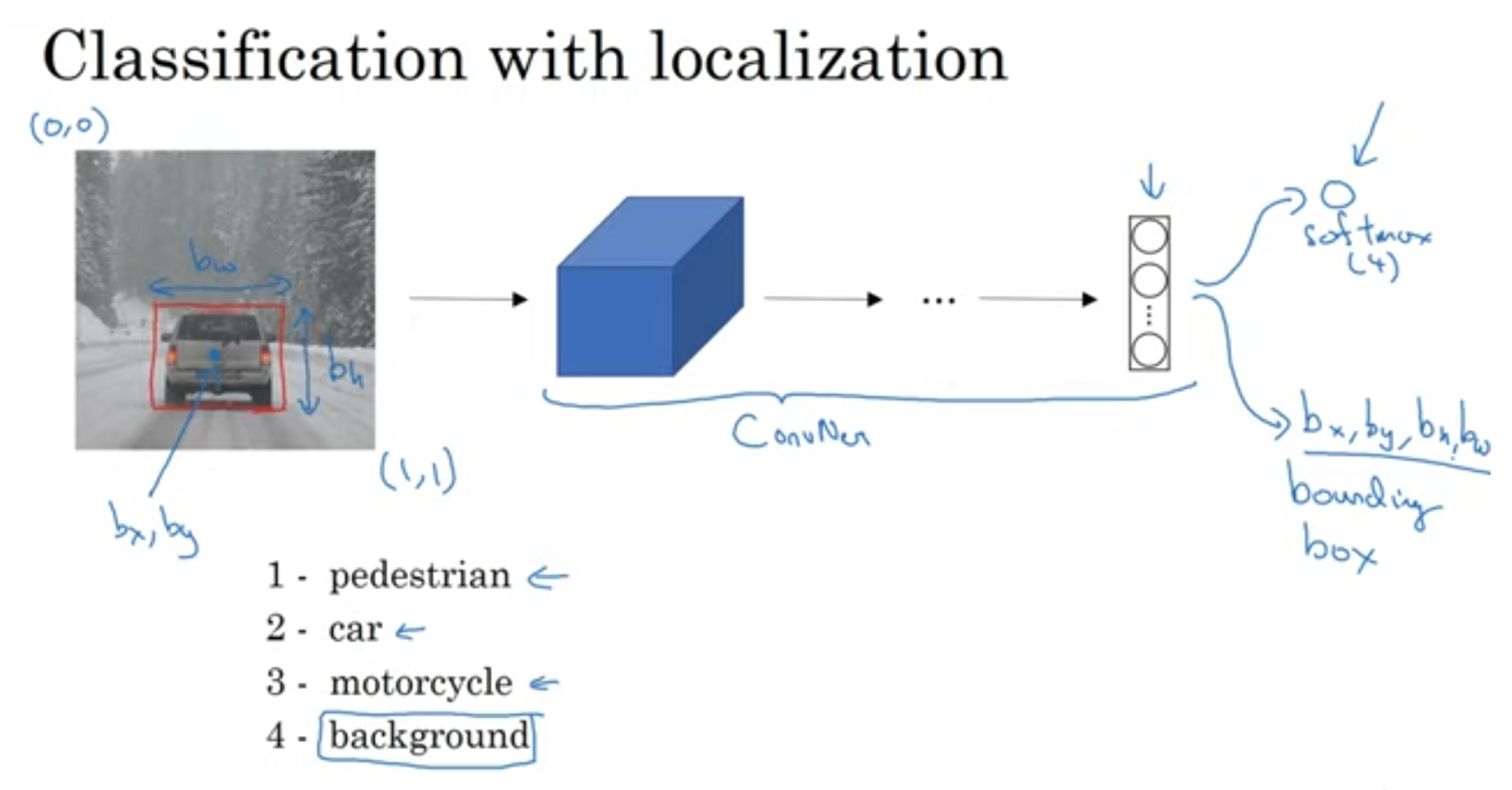
bounding box도 출력해주는 것을 볼 수 있습니다.
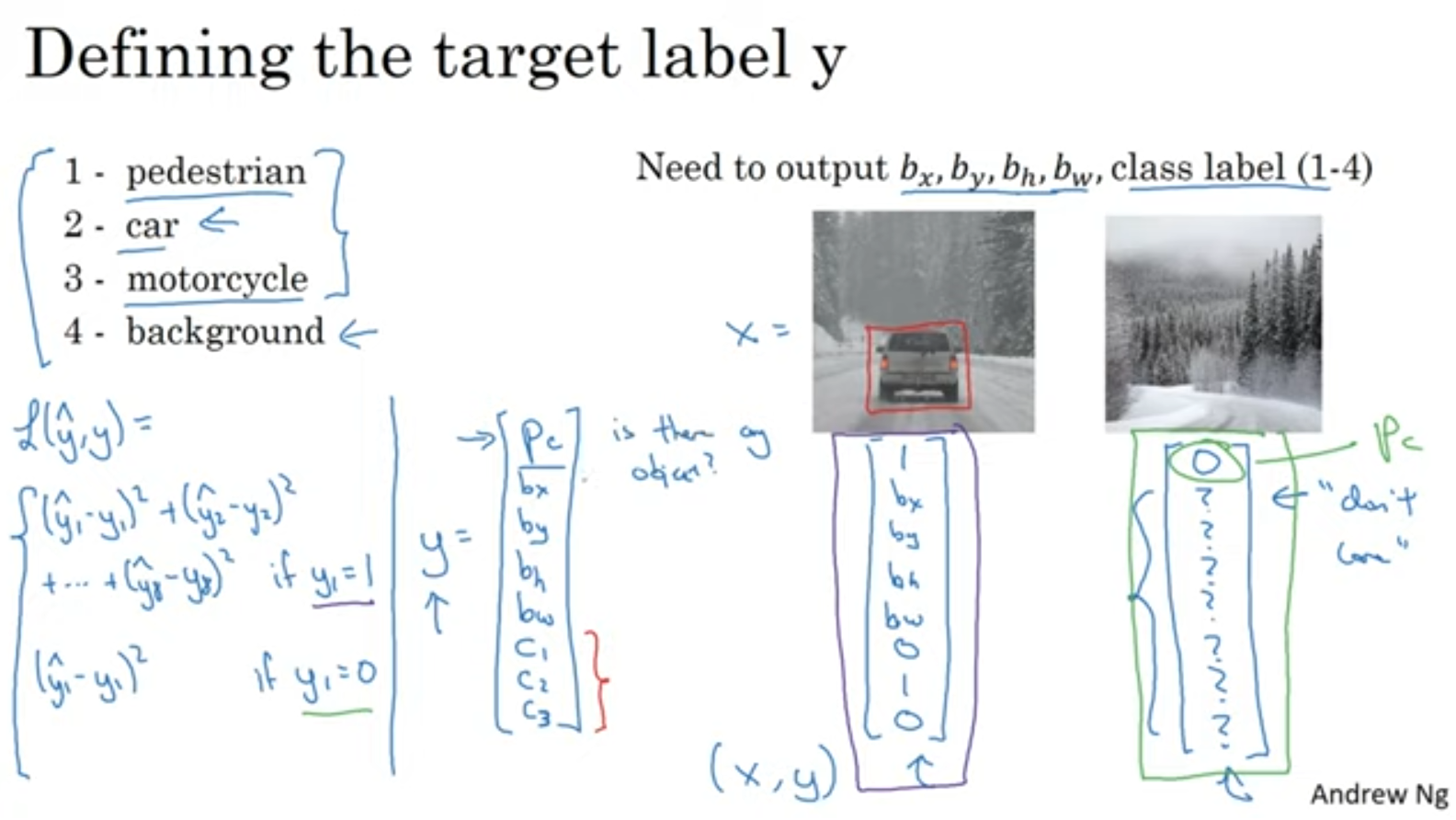
총 8개의 output이겠네요.
Landmark detection
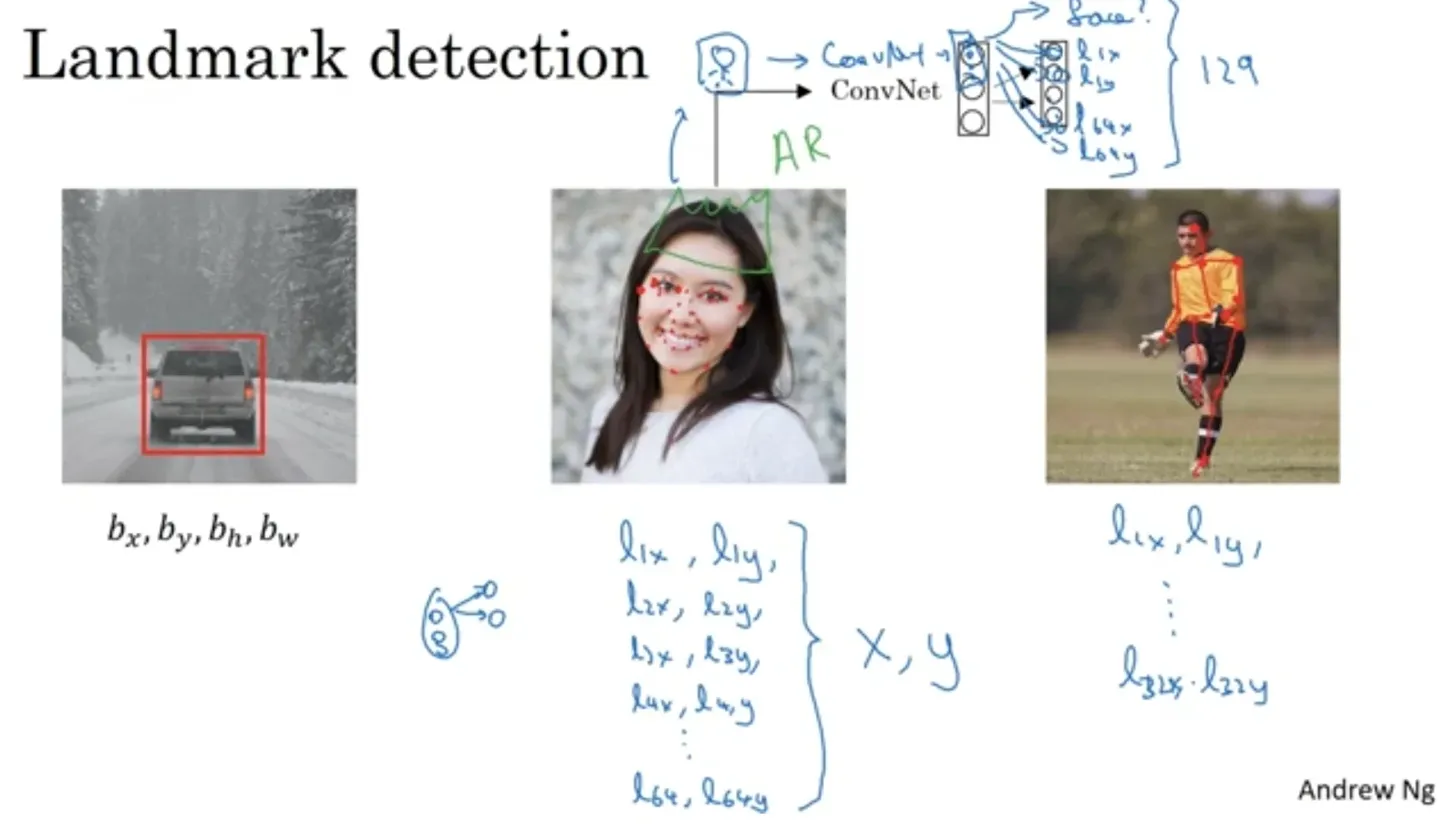
"랜드마크(landmark)"란 이미지 내에 존재하는 중요한 특징적인 지점들을 의미합니다. 랜드마크를 label로 주어서 학습시킬 수도 있겠죠.
Sliding window
슬라이딩 윈도우 기법에 대해서 알아봅시다.

먼저 위와 같이 모델을 학습시킨후

사진의 모든구간을 돌면서 차가 있는지 없는지 확인합니다.
무지막지한 연산량이 필요하겠죠 ㅠ
이를 해결하는 방법이 있다고 하는데요!
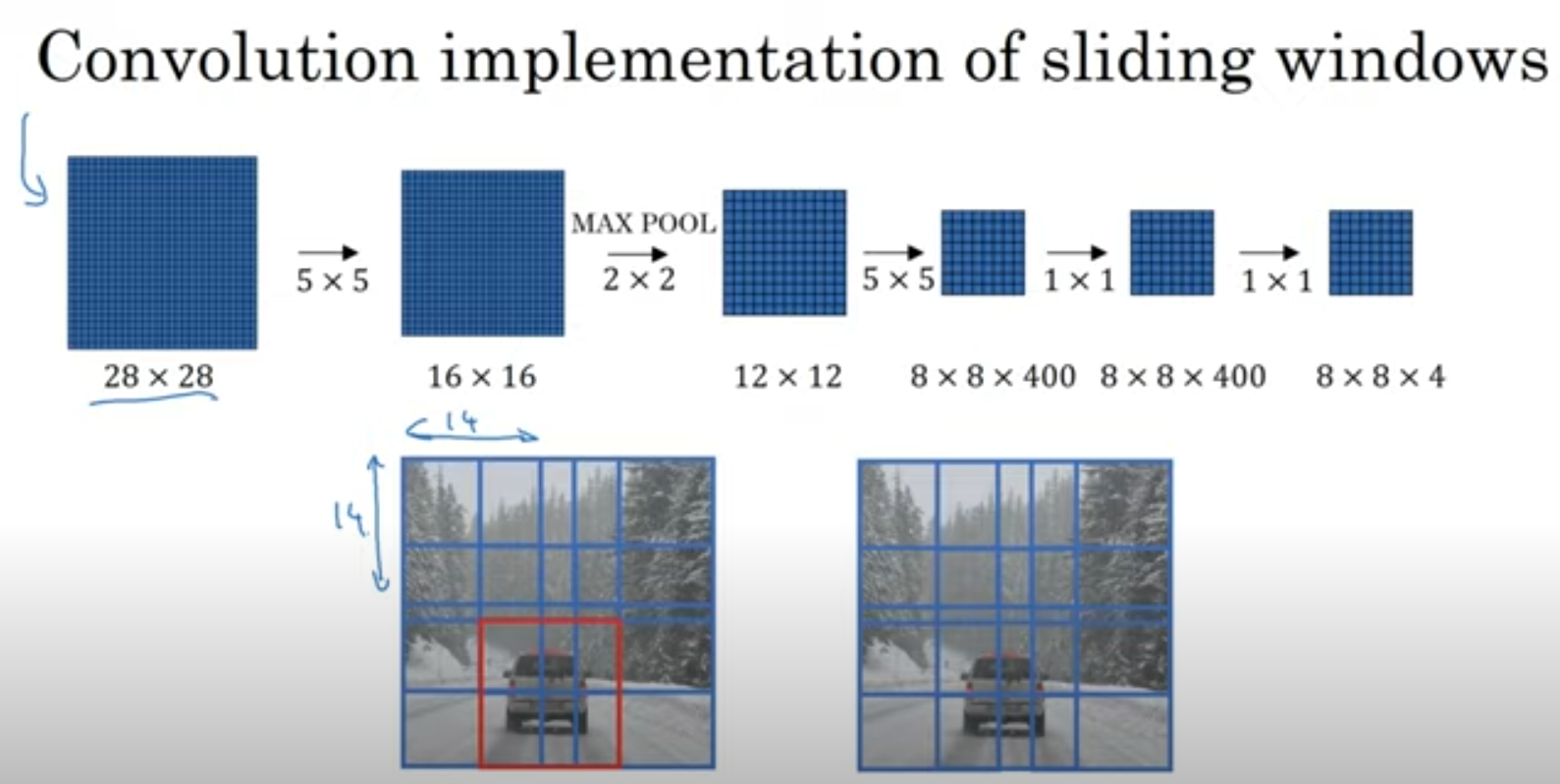
바로 이미지 하나라를 통채로 넣어서 동시에 모든 예측값을 계산하는 것입니다. 위와 같이 네트워크를 구성하면 각 crop의 예측값을 출력할 수 있겠죠. (맨 오른쪽 1x1하나가 곧 14x14하나를 의미함)
Evaluation

IOU를 이용해서 evaluate한다.
Non-max suppression

probability 가장 높은것 뽑은 후 IOU가 높은 나머지 사각형들 지워나가는 방식!

Anchor box
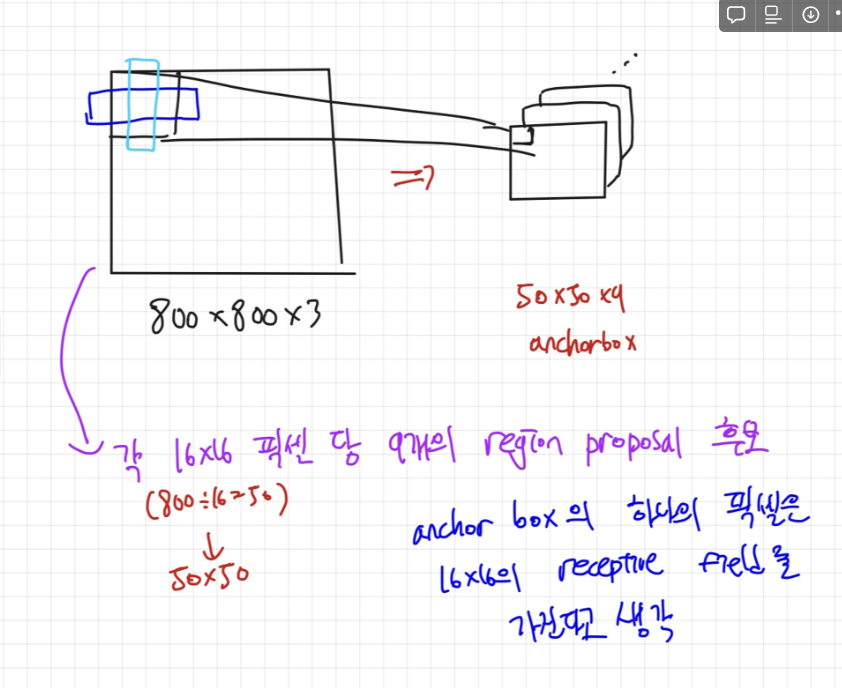
앵커박스는 어떻게 만들어질까요?
input이미지를 sampling ratio를 토대로 grid를 나누고, (그림에선 1/16)
나눠진 portion마다 서로 다른 3가지 scale([128, 256, 512])과 3가지 aspect ratio([1:1, 1:2, 2:1])를 가지는 총 9개의 서로 다른 박스를 정의해줍니다. 그러면 (800/16)(800/16)9개의 region proposal 후보가 만들어지죠.
이 후보들을 이용해서 나중에 region proposal을 진행합니다.
Training할 때는 ground truth값과의 IOU를 구해서 positive example 인지 negative example인지를 정하는데. IOU > 0.7 일 경우엔 Positive, IOU <0.3 일 경우엔 negative 입니다. (나머진 유기)
앵커박스에서 하나의 grid cell이 그럼 여러 객체를 포함할수도 있겠다 임계치 IOU값을 넘으면
하지만 앵커박스 1과 2가 둘다 자동차사진을 포함할 경우 IOU가 더 높은 값 하나가 선택됨 둘다 같은 객체에 labeling될 수는 없다.
YOLO
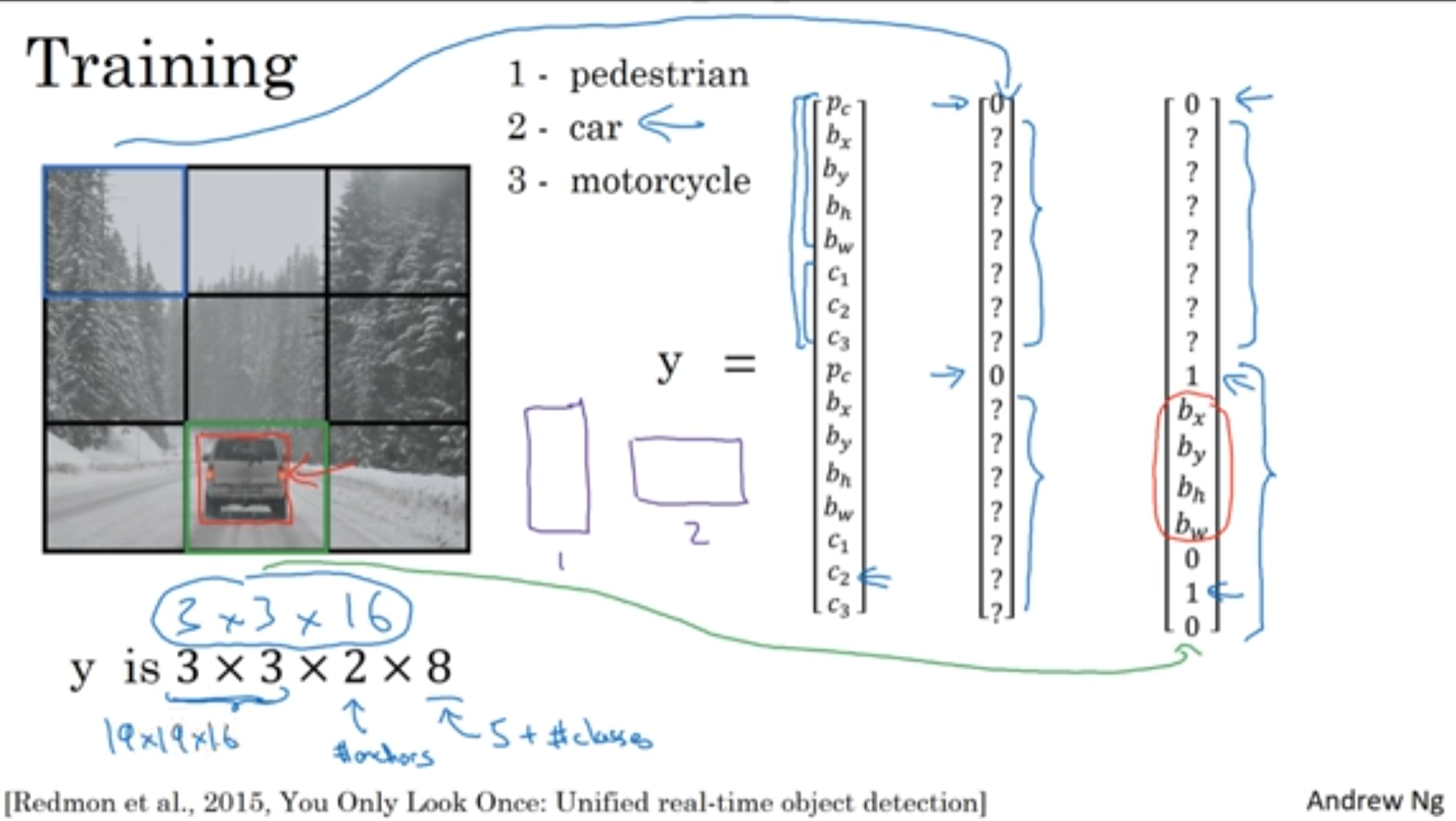
YOLO 알고리즘에 대해 알아보자

앵커 박스를 지워나가자!

Semantic Segmanatation with U-Net
Transpose Convolution
U-Net의 아키텍쳐를 이해하려면 Transpose Convolution에 대해서 이해해야 한다.
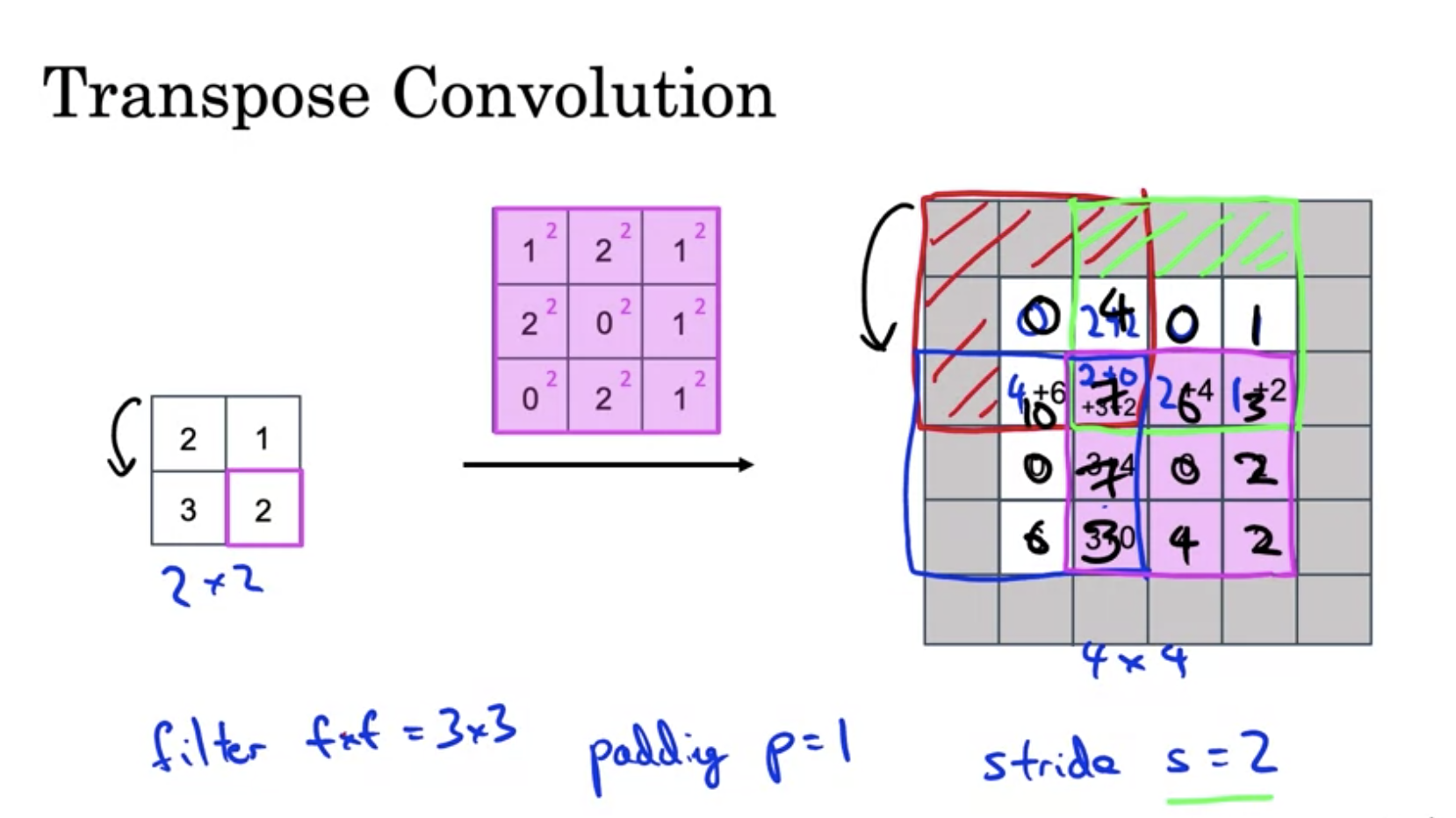
위는 패딩이 1, stride=2인 컨볼루션의 예시이다. 겹치는 부분은 값을 더해준다.

아키텍쳐는 위와 같다! Skip-connection을 해준다는 사실을 주목하자
