Generative model의 목표
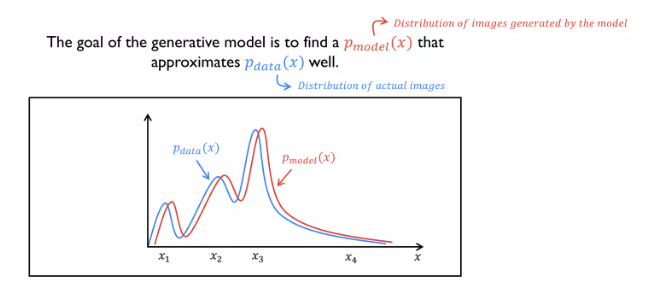
생성 모델은 데이터의 확률 분포에 근사하는 분포를 학습하여, 실제 데이터와 유사한 새로운 데이터를 생성하는 것을 목표로 합니다. 이를 통해, 생성 모델은 다음과 같은 작업을 수행할 수 있습니다
GAN
GAN은 두가지 모델로 이루어져있다.
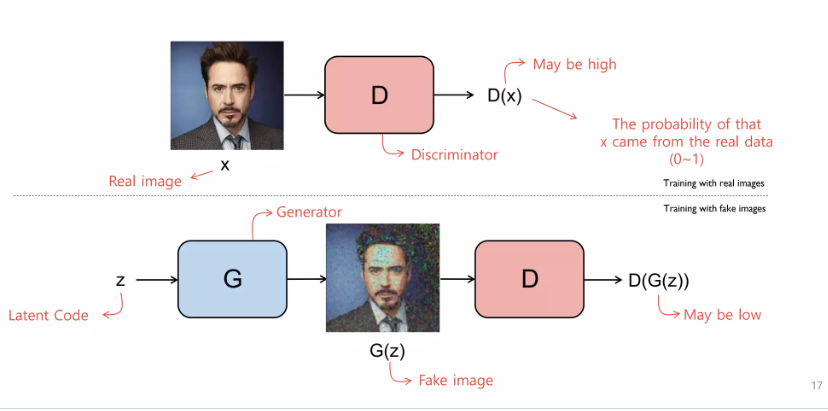
input의 진위를 판단하는 Discriminator 모델과
새로운 Data를 생성해내는 Generator 모델
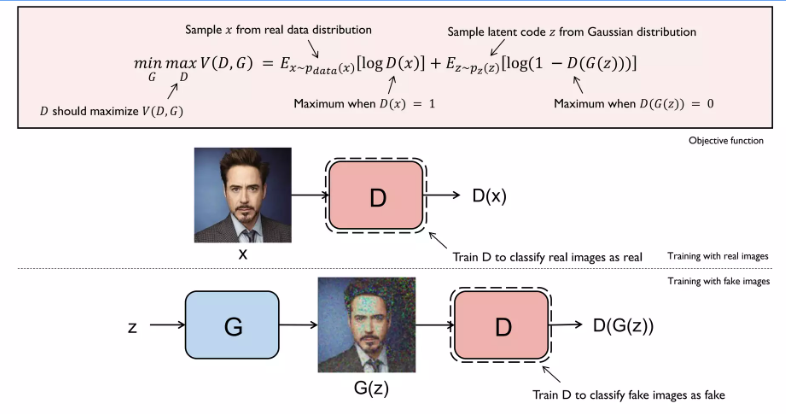
Discriminator 관점에선 위의 식을 Maximize해야함
가짜를 구분하는 task에선 0을 , 진퉁을 구분하는 task에선 1을 뽑도록 하는게 목표

반면 Generator는 뒤의 항을 minimize 해야 함
(잘 속이자!)
D와 G를 따로 학습한다. ( D 학습할땐 G parameter freeze)
D학습 - G학습 - D학습 - G학습 이런식으로
GAN의 종류
DCGAN

FC layer 대신 CNN을 사용한 GAN 모델
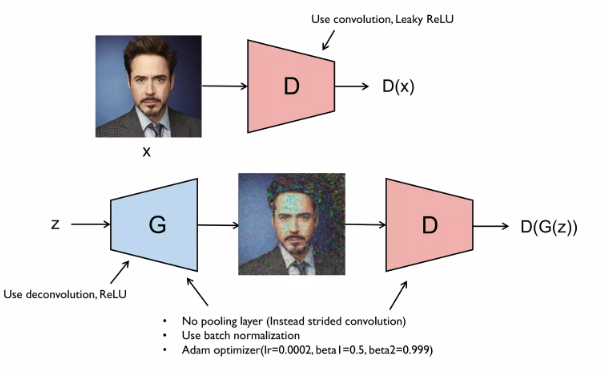
blurry 한 이미지를 방지하기위해 Pooling layer를 안썼다. batch Norm도 써줌 (논문이 2015년에 나왔나 그럴거다)

latent vector들 끼 연산도 가능하다는 재밌는 관점을 보여줌 (굉장히 직관적이다)
LSGAN
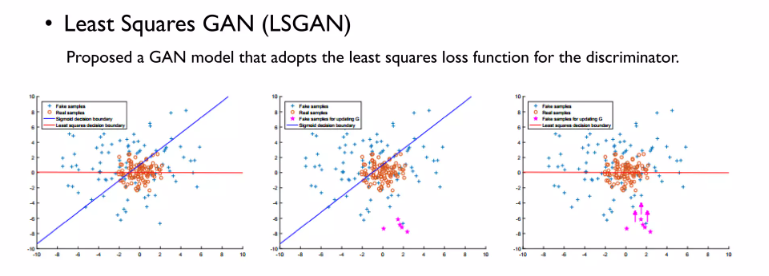
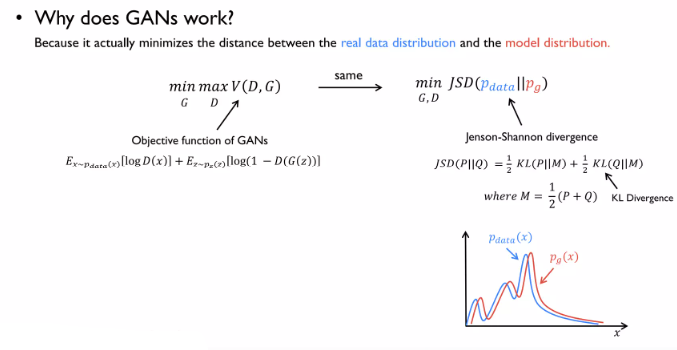
위와 같이 Discriminator은 속였지만 real data와의 분포와는 차이가나는 핑크색 데이터가 생김
생성 데이터의 분포를 real data쪽과 가까이 분포시키고자 함
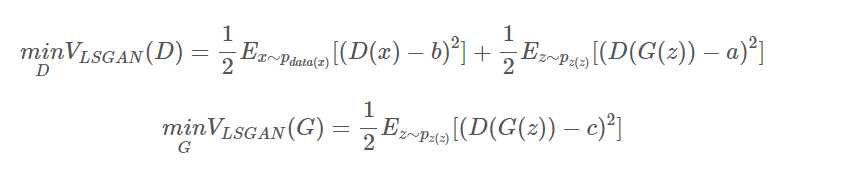
LSGAN의 손실 함수는 데이터 포인트가 목표값에서 얼마나 떨어져 있는지에 대해 더 큰 페널티를 부여한다.
CycleGAN
Image-to-image Translation에 쓰이는 모델

먼저 Discriminator에겐 말의 사진만 주고
Generator에게 얼룩말의 사진을 input해줌
근데 Generator가 말을 반환하지 않으면 Discriminator가 가짜라고 하니까 말을 출력하게 끔 학습을 한다.
근데 뛰는 말을 반환해도 Discriminator를 속일 수 있겠지?
근데 우린 이걸 원하지않음
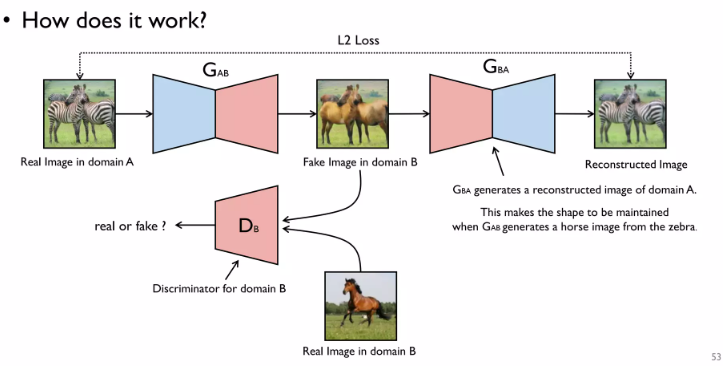
그래서 로스항을 추가함=> 이렇게 하면 얼룩말 =>뛰는 말 =>다시 얼룩말을 학습하기엔 굉장히 어렵기 때문에 무늬만 없애자라고 네트워크가 스스로 판단한다.
