만약 저희의 모델이 Human-performance를 이뤄내지 못할 땐 어떻게 해야할까요?
Error anaylsis

Cat detection을 위한 classifier 모델을 학습시켰는데 10%의 확률로 에러가 나는 상황을 생각해봅시다.
개를 보고 고양이라 하는 것을 보고 모델을 만든 사람은 생각합니다. 개에 대한 정보가 부족한가? 개 이미지를 넣어야겠다!
무작정 데이터셋을 늘리는 것이 모델 성능향상에 도움은 되겠지만 저희는 trade-off를 고려해서 행동해야합니다.
이 때 도움을 주는 것이 Error analysis방식인데요.
잘못 추론한 100개의 dev set example들을 가져와서 이를 분석하는 것입니다. 말 그대로 error analysis죠.
예를 들어서 mislabeled data들 중 개 이미지는 5개밖에 없다면 개 이미지를 더 넣어주는 것은 효율적이지 않겠죠. 10%인 error가 고작 9.5%로 줄어드는 것이니까요.
물론 의미는 있으나 더 나은 방법이 있을 것입니다.
반면에 개 이미지가 50개였다면 error rate를 반으로 줄여주니 충분히 시도해볼만한 가치가 있을 것입니다.
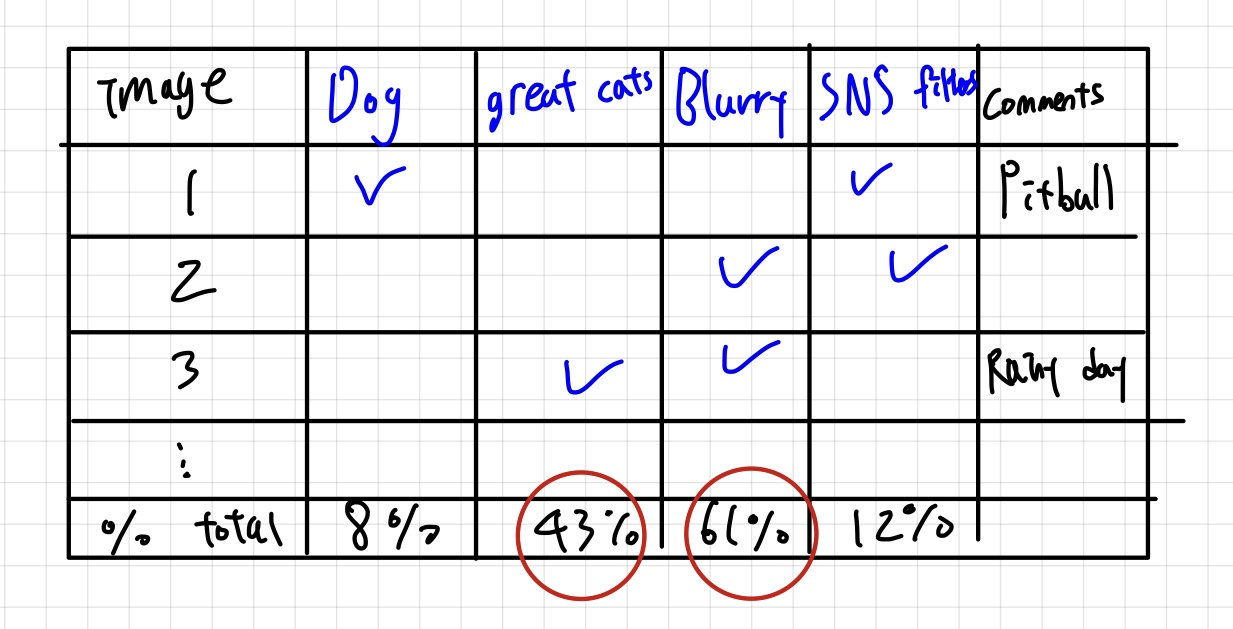
결과가 위와 같이 나왔다면 great cats와 blurry한 이미지들에 focus를 할 수 있겠죠.
Incorrectly labeled data
저희가 학습시킨 데이터중에는 labeling이 잘못된 데이터들도 분명히 존재할 것입니다.
그 개수가 많지는 않을 것이기에 training dataset에서는 이러한 random error에 꽤 견고합니다.
하지만 데이터 수가 적은 dev,test set에서는 이러한 random error가 성능을 나타내는 지표에 치명적일 수 있습니다. 모델 자체의 성능엔 크게 영향을 주지 않지만 운 없게 dev,test set에 들어가 버리면 지표가 안좋게 나오는 것이죠 :(
mislabeled data도 위에 설명한 것과 마찬가지로 차지하는 portion이 클때만 먼저 수정해주는 것이 좋다고 합니다. 100개중 2개만 mislabeled 되었다고 가정하면 우선순위가 밀리는 것이죠.
만약 수정할시엔 test set도 같이 바꿔주어야 합니다.
distribution이 같아야하니까요.
2.1%의 dev error의 모델 A VS 1.9%의 dev error의 모델 B
--> mislabeled data가 있을 수 있기에 누가 더 나은 모델인지 알 수 없음.
많은 엔지니어들이 이러한 과정들을 꺼린다고 합니다.
저도 hand-engineering을 귀찮아하지 않는 습관을 들여야겠어요.😊
When building brand new machine learning application
-
Set up Dev/test set and metric
-
Build initial system quickly
-
Use Bias and Variance analysis and Error analysis to prioritize next step
Mismatched training , dev set
Training and Testing on Different Distributions
고양이 분류기를 학습시키는 모바일 앱을 만드려고 합니다. 클라이언트가 실제로 입력으로 넣는 이미지는 오른쪽과 같은 이미지들이죠.
하지만 mobile data는 10,000개 밖에 없고 웹 페이지에서 온 data는 200,000개 정도입니다. 이러한 경우 어떻게 train/dev/test data를 구분하는게 좋을까요?
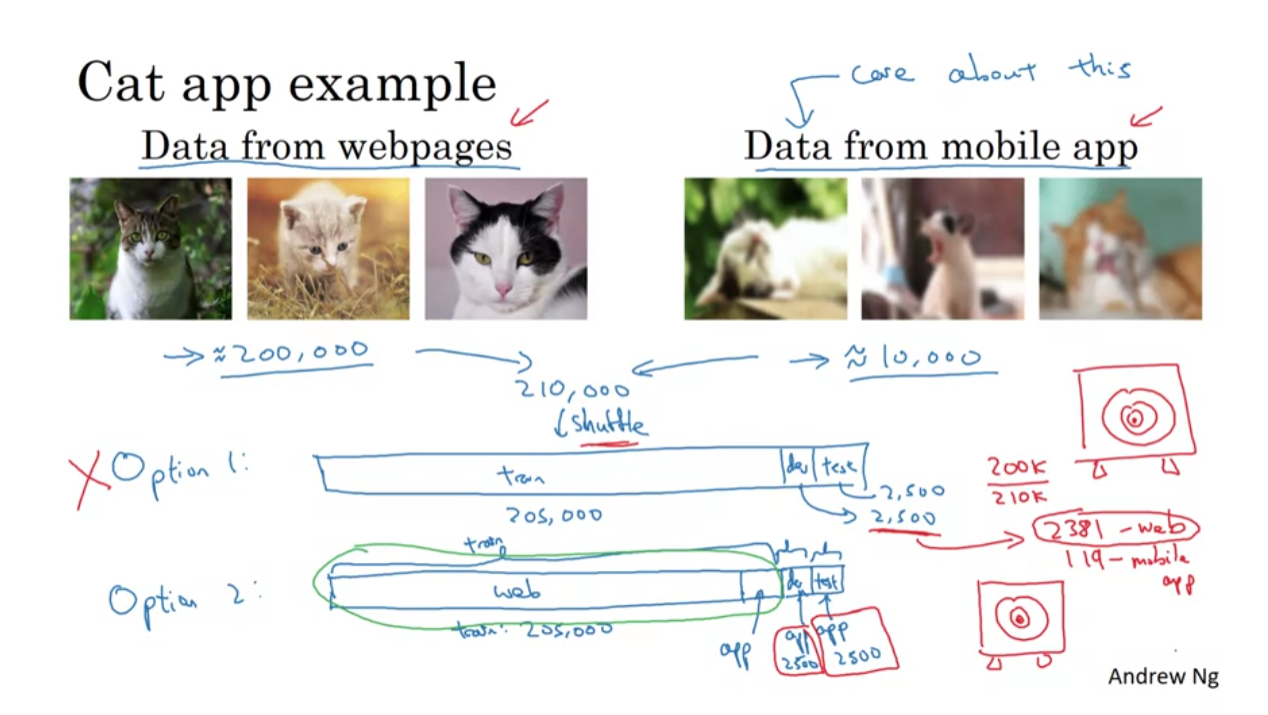
첫번째 방법은 무작위로 shuffle하는 것 입니다. 여기에는 문제가 있죠
저희는 mobile app에서 온 data를 잘 구분하는게 목적인데 이런식으로 분배를 하면 dev/test set에서는 2500개중 119개 정도만 mobile app data를 가지고 있는게 되어서 성능을 신뢰성있게 측정하기 어렵습니다.
그래서 저희는 dev/test를 mobile app data로 고정시켜놓고 학습시키는 방법을 택합니다. 이런식이면 성능을 신뢰성있게 측정할 수 있게 되죠.
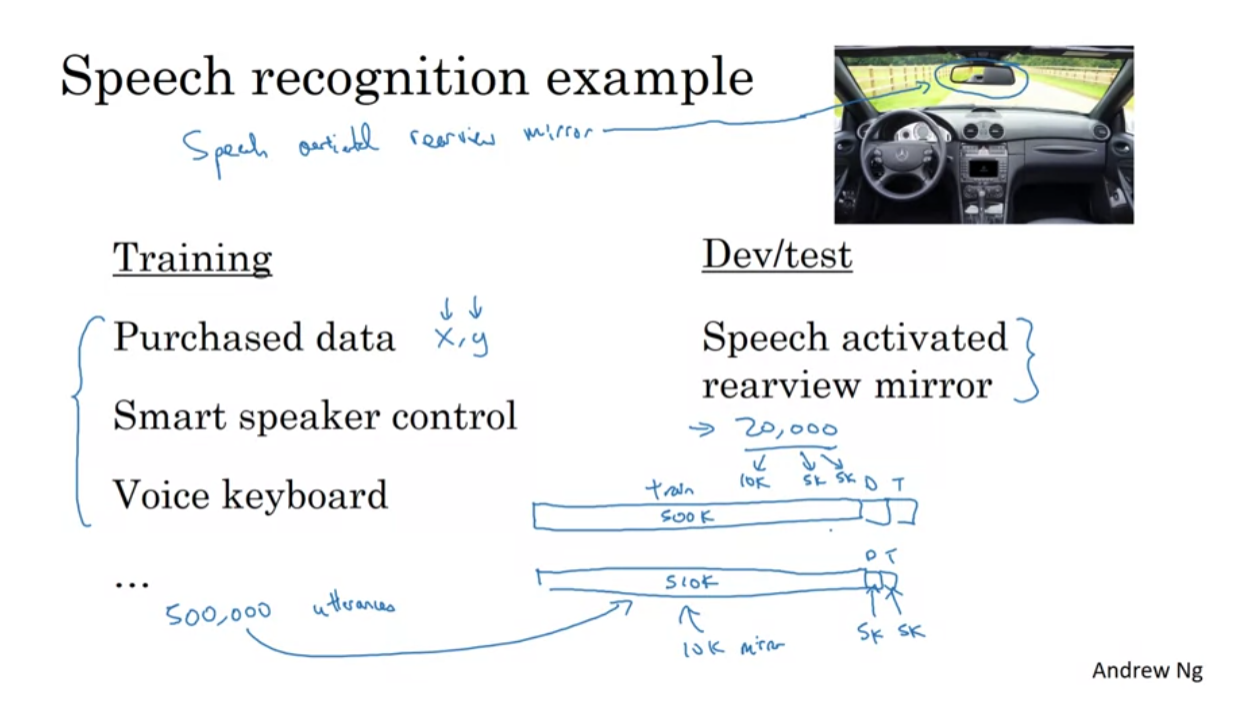
speech artificial rearview mirror 예시에서도 마찬가지 겠죠? 저희가 신경쓰는 건 차안에서의 audio data니까요.
Bias and Variance with Mismatched Data Distributions
이렇게 distribution이 다를 경우
Train error :1%
Dev error:10%
위와 같이 나왔다면 우리는 이 문제의 원인이 오버피팅(variance problem) 때문인지 distribution의 차이 때문인지 알 방법이 없습니다. 그래서 우리는 train-dev set이라는 새로운 데이터 셋을 하나 만들어낼겁니다.
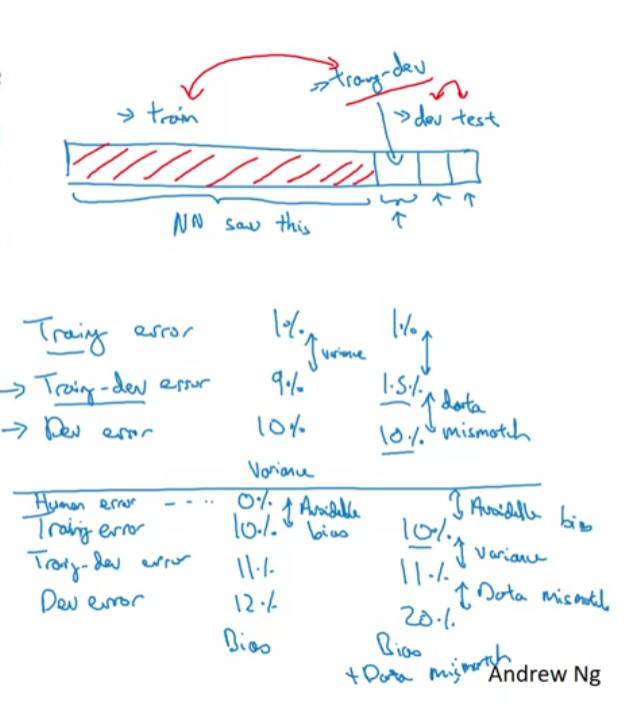
위의 그림에는 총 4가지 경우의 수가 있습니다.
-
Train : 1%
Train-dev: 9%
Dev : 10%이경우에는 distribution 때문이 아닌 오버피팅문제로 에러가 높게 나타납니다.
--->Variance problem -
Train : 1%
Train-dev: 1.5%
Dev : 10%이경우에는 distribution 불일치 문제로 에러가 높게 나타납니다.
--->Data mismatch problem -
Train : 10%
Train-dev: 11%
Dev : 12%이경우에는 그냥 학습이 잘 안되었습니다 (train error가 너무 높죠,).
--->Bias problem -
Train : 10%
Train-dev: 11%
Dev : 20%이경우에는 학습도 잘 안되었고, distribution 불일치 문제로 에러가 높게 나타납니다.
--->Bias+Data mismatch problem
Addressing Data Mismatch
음성인식 rearview mirror에 대해서 생각해봅시다.
rearview mirror가 실제 배포 되었을때 어떤 환경에 놓이게 될까요? 여러 car noise가 사람의 목소리에 섞일거고 주소 혹은 street number를 인식하는게 critical할 것입니다.
이에 따라 저희는 dev set을 유사하게 구성할거고요.(차 잡음+street number을 잘인식하냐에 대한 평가)
하지만 training set이 이와 너무 동떨어져 있으면 안되겠죠 그래서 저희는 dev set과 training set을 비슷하게 만드려는 노력을 해야합니다.
data synthesis
아래와 같이 의도적으로 car noise를 합성하여 훈련시킬 수 있습니다.
하지만 비교적 작은 portion의 carnoise를 반복해서 합성한다면 이 오버피팅이 일어날 수 있겠죠.

Transfer learning
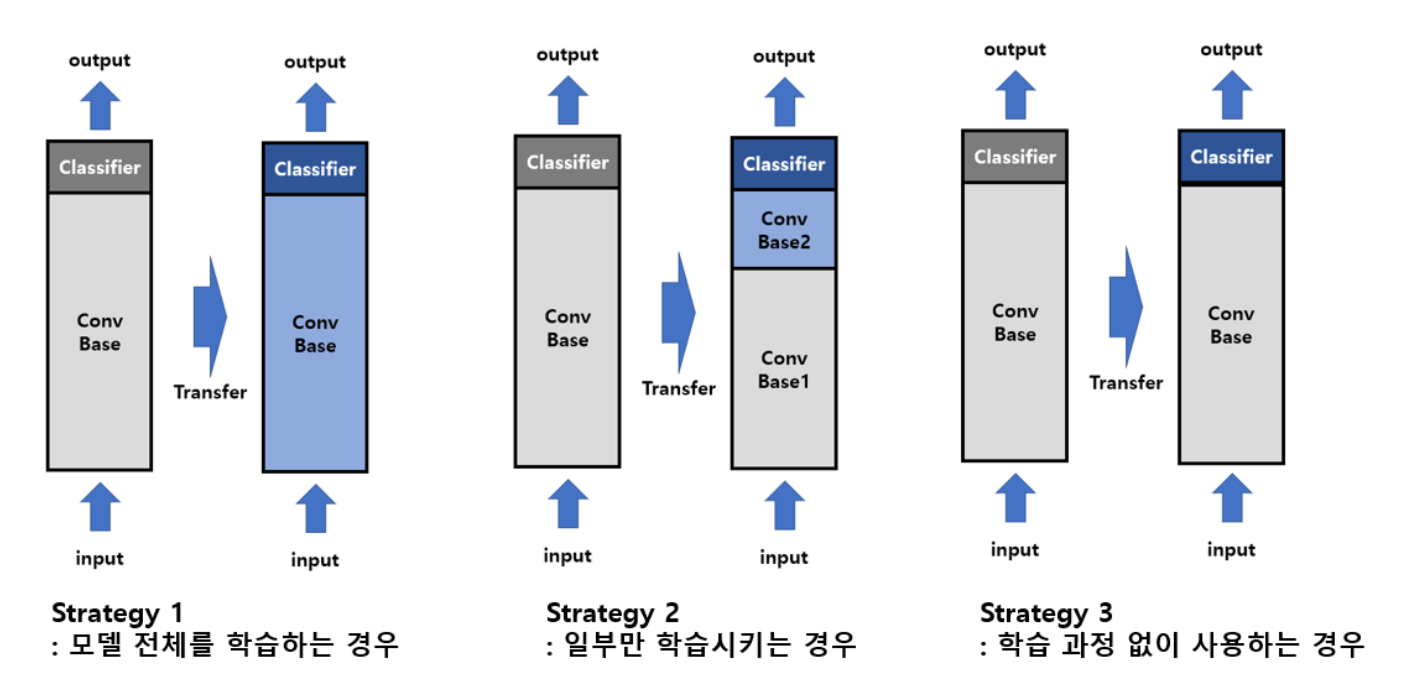
image recognition task를 위해서 훈련된 모델을 radiology dianosis problem에 적용할 수 있을까요?
정답은 YES입니다. 방사선 이미지 데이터셋이 적다면 기존 ImageNet 모델에 마지막 layer만 학습을 진행해도 좋습니다.전체적인 이미지에 대한 구조를 신경망이 이해하고 있기 때문에 weight들을 전부 갈아 엎지 않아도 성능이 잘 나오는 것이죠.
이렇게 마지막 몇개의 layer만 바꿔서 학습시키는 과정을 fine-tuning이라고 합니다.
Mulstitask learning
한개의 신경망이 여러개의 레이블을 가지는 것을 말합니다.
충분히 큰 신경망에 대해서는 Multi task learning이 낮은 성능을 보이는 경우는 거의 없다고 하네요.
각 task가 서로의 task에 좋은 영향을 준다고 생각하시면 됩니다. 보행자를 detect하는 task에 쓰이는 이미지 셋이 횡단보도를 detect하는 task에 도움을 주고 그런 것이죠. (비행기가 있는 장면에서는 보통 횡단보도가 없을 것이라는 암묵적인 규칙도 모델이 학습할 수 있겠죠.)
End to End learning
end-to-end learning은 data set이 커짐에 따라
pipelining approach를 능가한다.
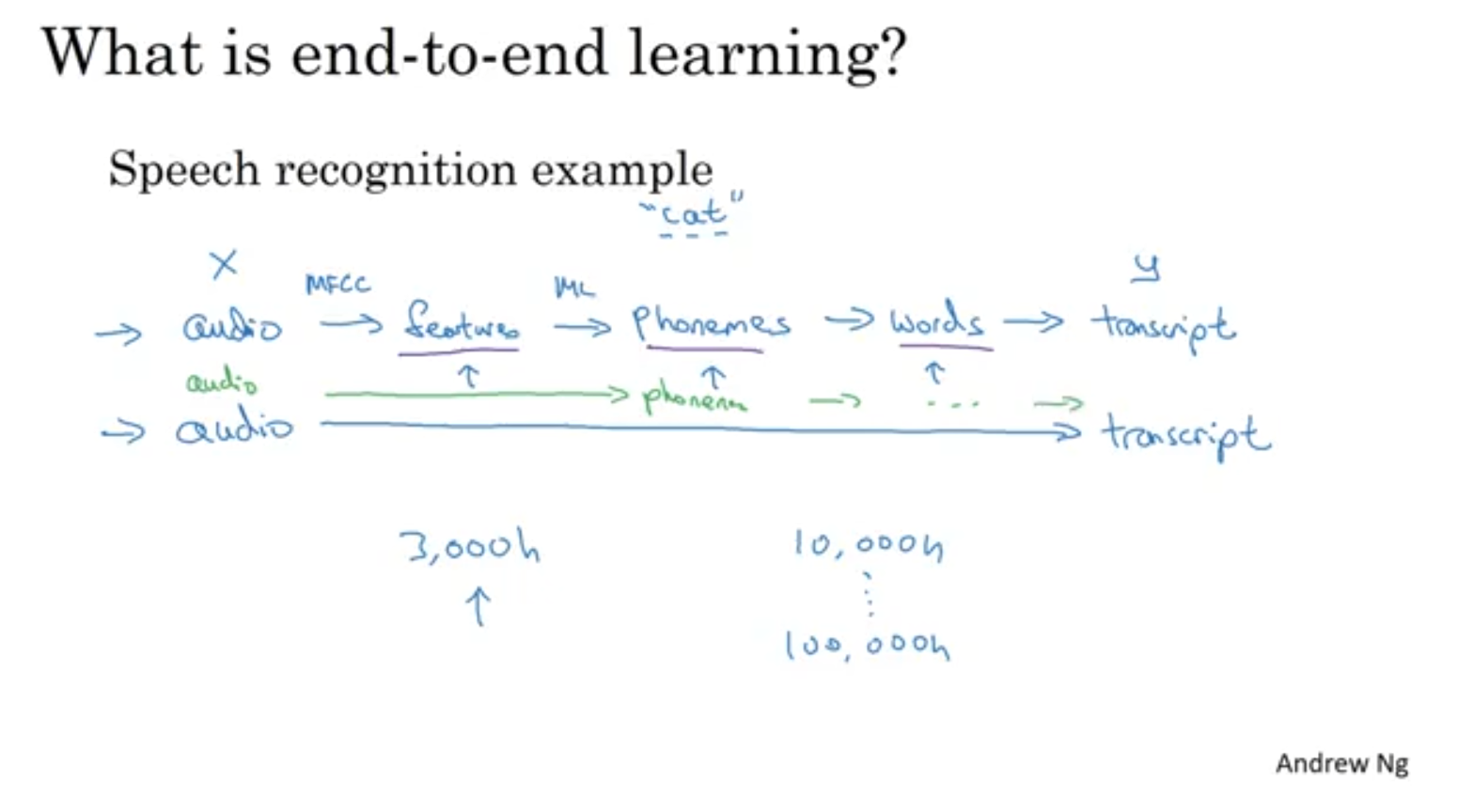
때로는 sub problem 단위로 나눠서 작업하는 > pipelining이 성능이 더 잘 나오기도함.
