우리가 모델을 구현하고 학습하는 과정에서 다양한 문제에 직면합니다.
모델의 성능을 끌어올리기 위해 우리는 다양한 adjustment들을 고려해볼 수 있는데요.
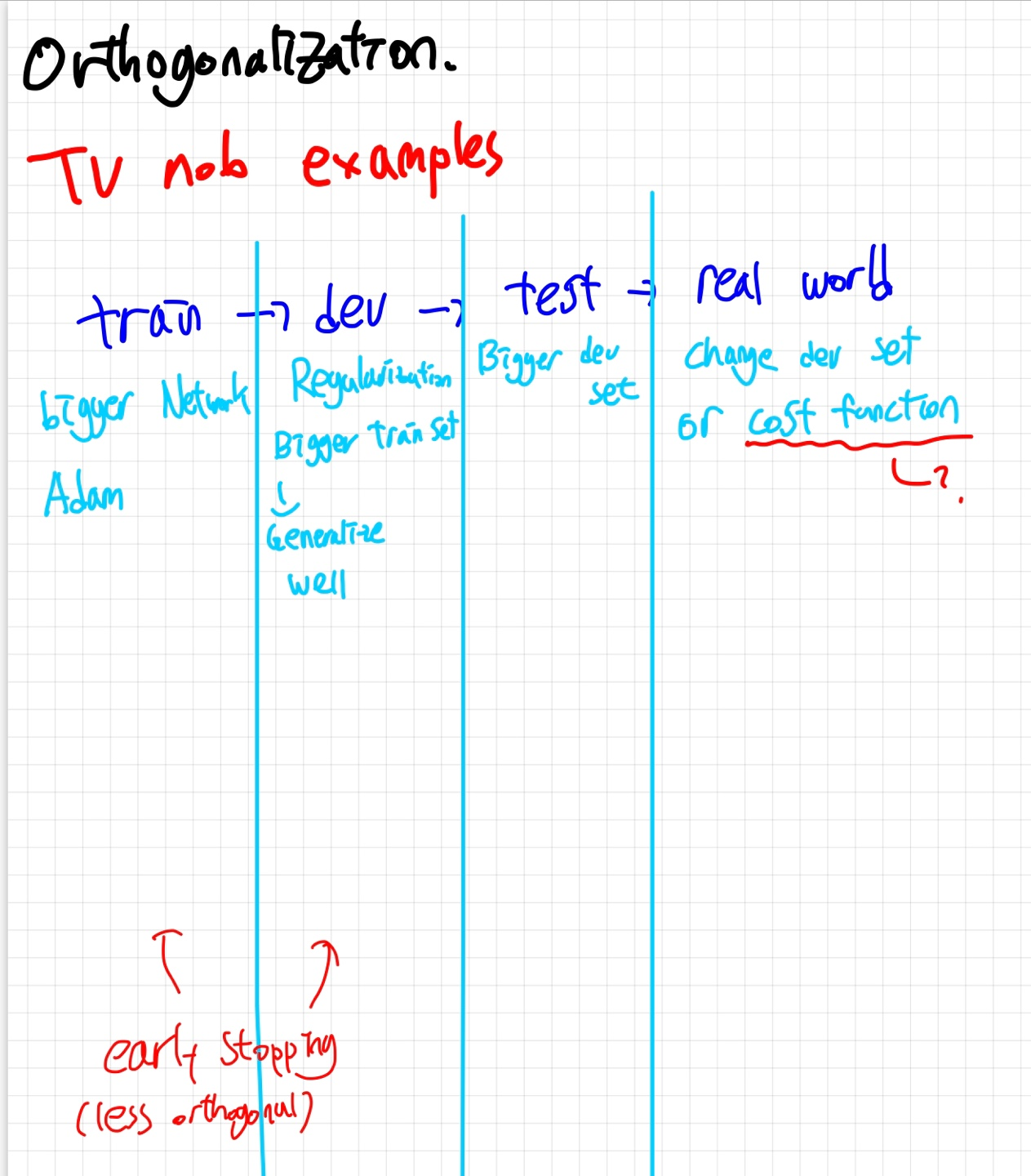
위의 그림은 각 단계에서 성능이 안나올때 적용 할 수 있는 방법들을 적어둔 것 입니다.
- 밑줄 친 cost function부분은 운좋게 학습이 잘 되었어도 real world에서 general한 성능이 안나올때는 logic을 점검해 볼 필요가 있다~ 정도로 생각하면 될 것 같아요.
(개인적인 의견)
예를 들어 dev,test set에 잘동작하였지만 real world dataset에서 잘 동작하지 못하면 dev set을 늘려줍니다. Dev set의 distribution이 real world에 있는 데이터들 만큼의 다양성을 확보하지 못했다고 판단을 하는 것이죠.
Orthogonal하게 영향을 주는 그러한 adjustment들이 좋다고 해요.
TV 볼륨만 줄이고 싶은데 노브를 돌렸더니 화면밝기까지 올라가면 곤란하잖아요?
그래서 early stopping은 잘 안쓰려고 하신다고 하네요 교수님께서는
Single Number evaluation metric
여러개의 모델을 훈련시켰는데 결과가 아래 표와 같이 나오면 무엇을 골라야 할까요?

precision값은 모델 B가 높지만 recall 값은 모델 A가 높아서 뭘 고를지 모르겠죠 :(
이럴 때 필요한 것이 Single Number evaluation metric인데요!
표에선 F1 score이라는 metric을 사용하였습니다.
Dev set과 single number evaluation metric이 함께 있다면 모델을 고르기 수월하겠죠.
그 아래는 error rate를 평균낸 값입니다. 이것도 이용할 수 있겠죠.
Statisficing and optimizing
다음 예시를 봅시다.
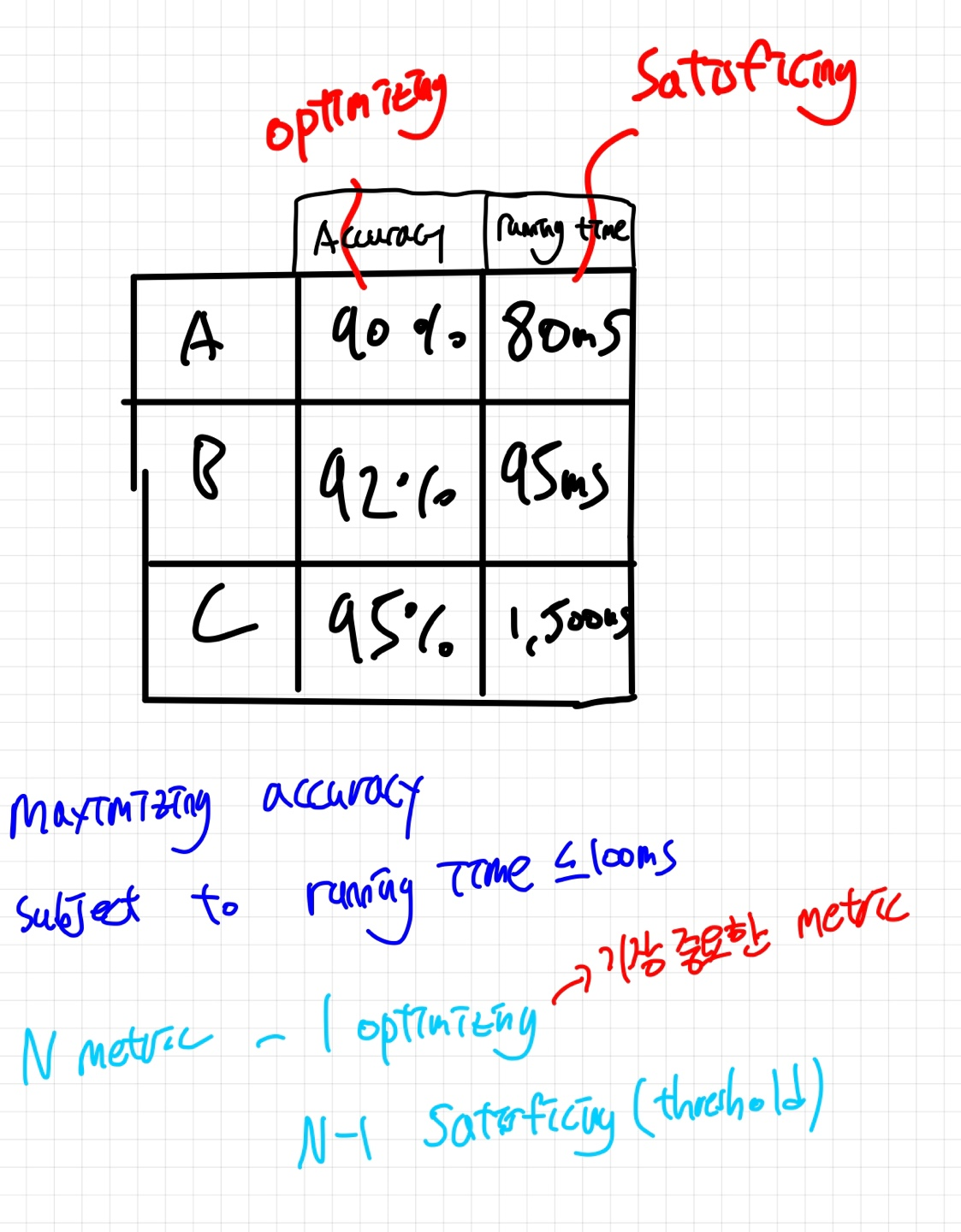
모델을 평가할 때 여러 지표(metric) 중에서 가장 중요한 하나를 선정해 최적화하는 것을 목표로 하고, 나머지 지표들은 특정 기준값을 넘기면 충분하다고 간주하는 방식을 적용할 수 있습니다
위의 표를 예로 들면, 정확도(Accuracy)를 주요 최적화 지표로 설정하고, 실행 시간(Running time)을 Satisficing metric으로 정하여, 실행 시간이 특정 기준점을 넘지 않는 한 모델이 충분히 좋다고 판단하는 것입니다.
이런 접근법을 통해 주요 지표에 초점을 맞추면서도 다른 중요한 측면들도 적절한 수준에서 관리할 수 있습니다.
"Satisficing"은 만족(satisfy)과 충분하다(suffice)의 합성어로, 최적의 해결책을 찾기보다는 주어진 조건에서 충분히 만족할 만한 해결책을 선택하는 의사 결정 전략을 의미합니다.
Data distribution
dev,test data가 같은 distribution을 가지는 것도 매우 중요합니다.
Size of the dev and test set
예전에 data수가 많이 없었을때 (10,000개 막 이럴 때) 저희는 train,dev,test data를 6:2:2로 분류하곤 했습니다.
하지만 데이터수가 정말 많을때 (1,000,000개) 저희는 98:1:1 의 비율로 분류를 할 수 있습니다. 모델을 평가하는데 10,000개 이상의 data set은 너무 많다고 보는 것이죠. 이는 더 많은 데이터로 학습을 할 수 있기 때문에 합리적입니다.
When to Change the metric
인터넷에서 여러 고양이 사진을 찾아서 고양이 애호가들에게 사진을 보여주는 Cat Classifier를 만들었다고 가정합시다.
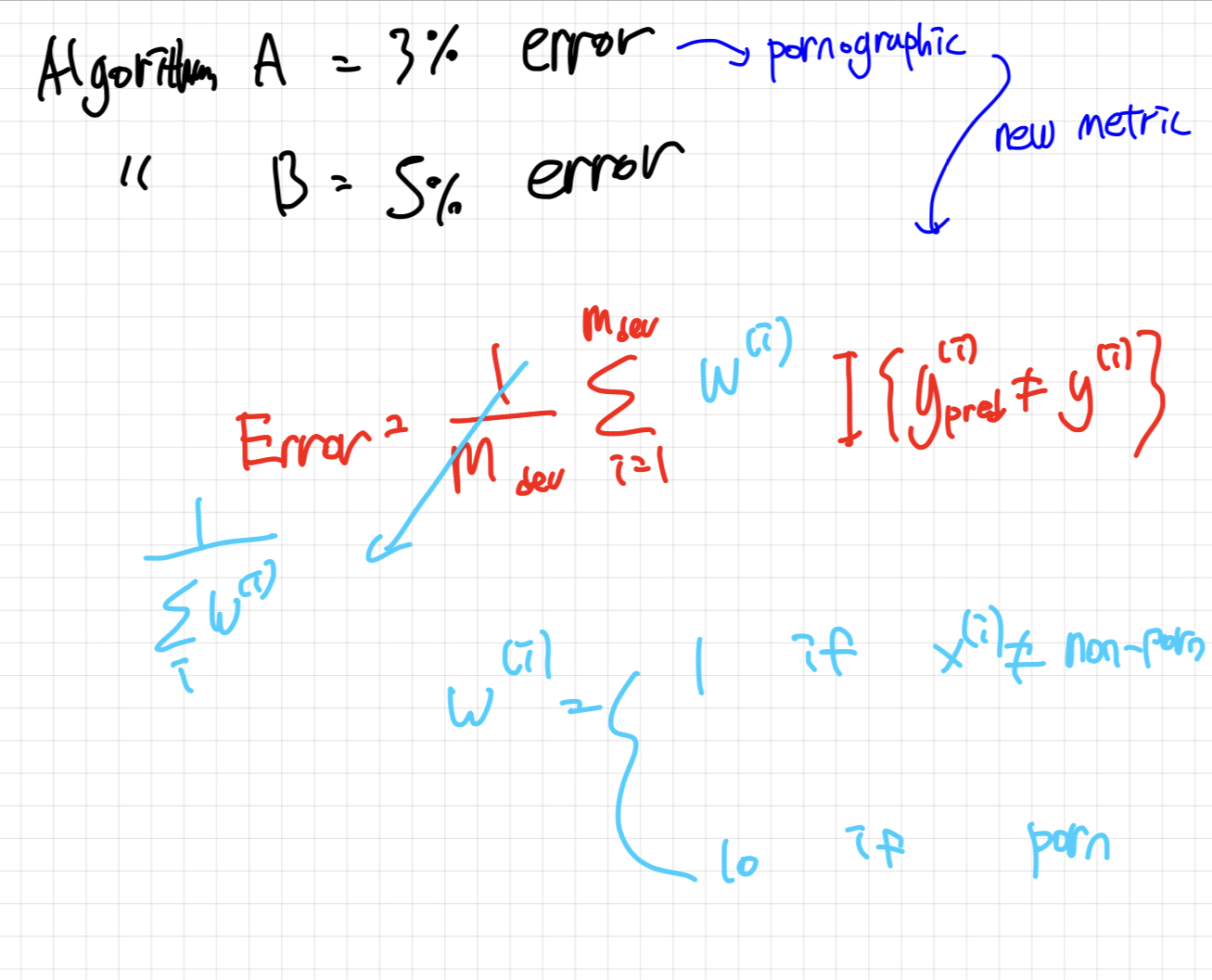
위와 같이 Classifier A는 3%의 error rate를 가지고 있고, Classifier B는 5%의 error rate를 가지고 있죠.
A가 성능이 더 좋으니 저흰 모델 A를 골라야겠죠? 하지만 문제가 있습니다. 3%의 확률로 다른 이미지를 보여주는 A가 가끔씩 pornographic한 이미지를 보여준다는 것 입니다. 이를 본 사람들은 엄청난 불쾌감을 느끼겠죠.
이럴 때 Error rate를 측정하는 Metric을 바꿔야 합니다.
pornographic 이미지일때 weight를 크게 줌으로써 error 값을 키워주는 것이죠.
이러면 pornographic 이미지를 추출해내는 모델이 큰 Error값을 갖게 됩니다.
교수님께서는 evaluation metric을 너무 신중하게 결정하기 보다는 먼저 실험을 시작하고 프로젝트를 진행하는 것을 권장하셨습니다. 추후에 더 적합한 metric을 발견한다면 그때 적용하는 것도 전혀 문제가 되지 않는다고 말씀하셨습니다. 그러므로, 중요한 것은 초기에 완벽한 메트릭을 찾으려고 시간을 지체하는 것이 아니라, 프로젝트를 실제로 실행하고, 이를 통해 학습하고, 필요에 따라 개선해 나가는 것입니다.
실제 사용자 이미지에 적용했을 때, dev/test 세트의 성능이 사용자의 애플리케이션에서 잘 작동하지 않을 수 있음.
이 경우, 실제 성능을 반영하도록 metric이나 dev/test 세트를 변경해야 함

Human-level performance
Bayes optimal error —> Best possible error
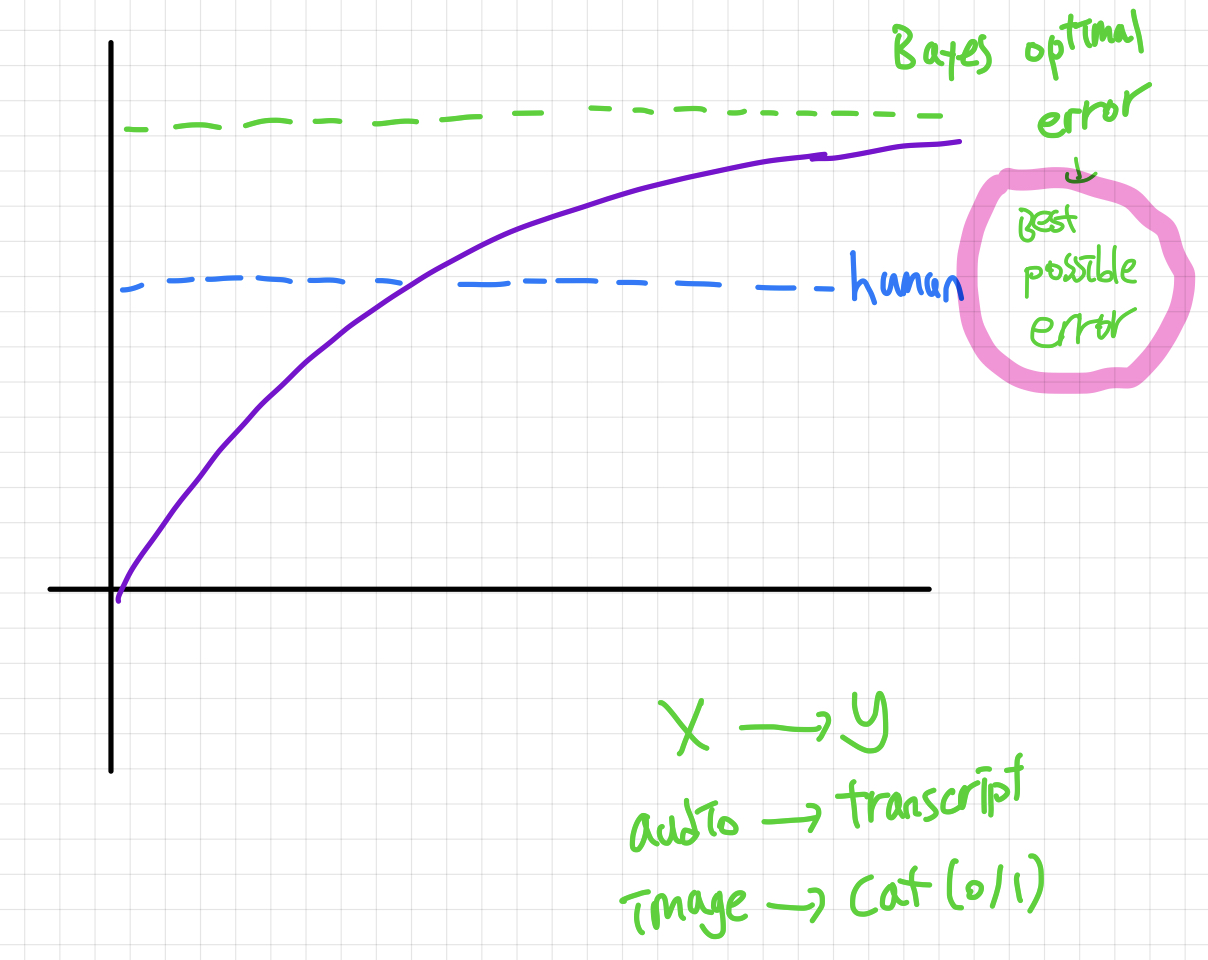
Human-level error 를 Bayes error의 proxy로 사용합니다. (인간이 잘 할 수 있는 task에 한에서)
training error가 이 값(가장 낮은 Human-level error 값) 보다 낮아졌을때는 저희가 직관적으로 적용할 수 있는 방법의수가 줄어듭니다. 그러나 계속 성능은 좋아질수있죠.
Problems where ML significantly surpasses human-level performance
- online advertising
- product recommendations
- predicting how long you take to drivce
- loan approvals
natrual perception task는 인간이 훨씬 우수함 ( Computer vision, NLP etc..)
