💡What is word Embeddings
Word Representation
기존의 one-hot encoding 방식으로는 단어 그 자체의 의미를 머신이 파악하기엔 한계가 있었다.
예를들면 King 과 Queen과의 관계나 King과 Orange과의 관계나 서로 다름이 없었다. (실제 인간이 사용하는 언어는 이렇지 않다.)

다음과 같이 각 특징들에 대한 단어의 연관성을 수치화 시켜서 벡터로 만들고 이를 inner product를 하면 연관있는 단어끼리의 내적값은 크게 나오고 그게 아니라면 0에 가깝게 나올것이다.
(내적은 닮은 정도를 나타내니까)

그치만 이건 차원이 너무 많다 --> visualize 힘들다
T-SNE 사용-->2차원에 plot가능
기존 one-hot encoding 에 비해 훨씬 더 작은 차원을 가진다.
전반적으로 Word Embeddings는 Transfer Learning을 가능하게 해주며, 다양한 NLP 작업에 활용될 수 있는 강력한 도구임을 알 수 있다.
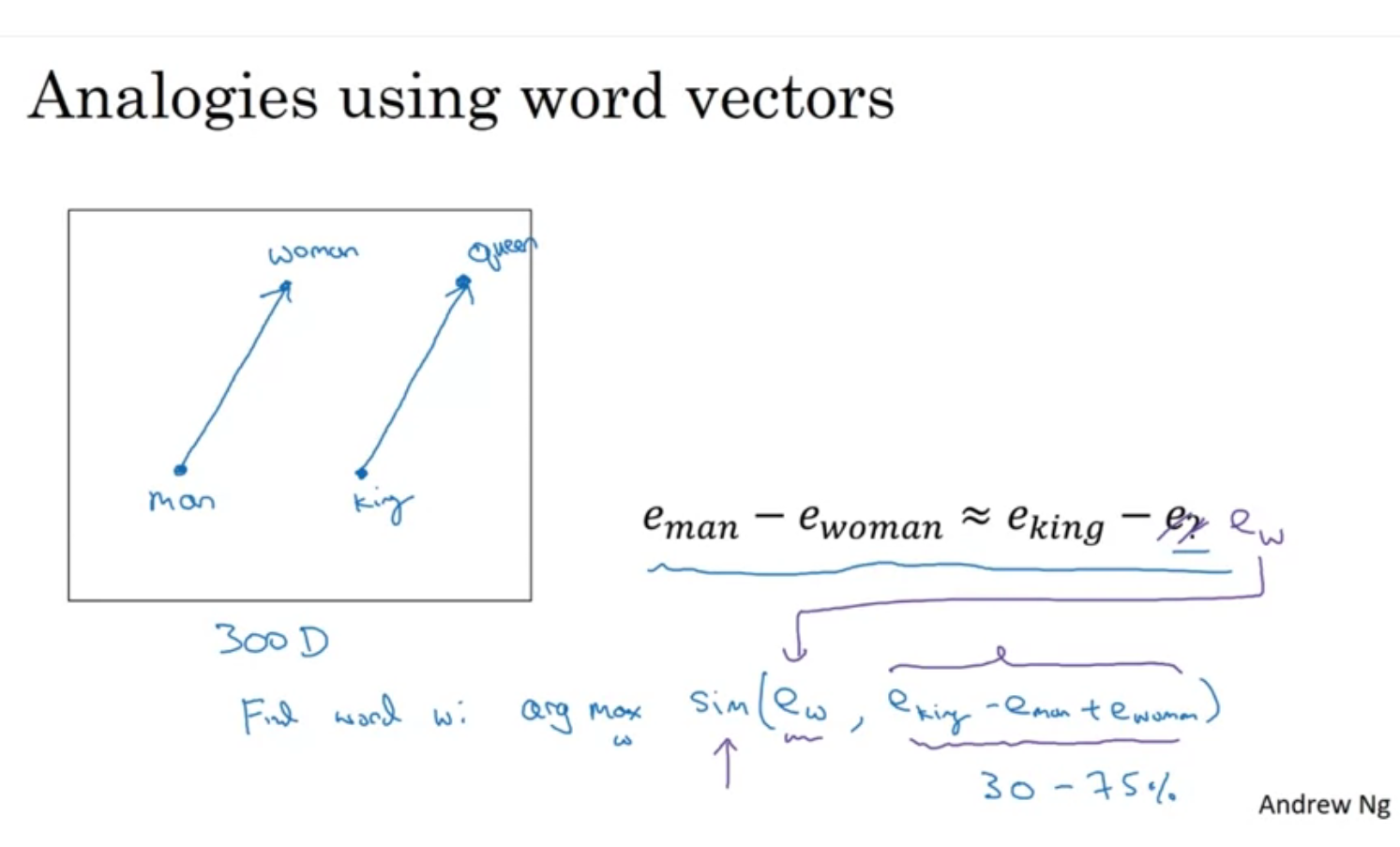
이런식의 analogy 알고리즘 설정도 가능하다.
similarity 는 cos similarity를 이용함 ( 내적 )
✍️Word2Vec
Skip grams
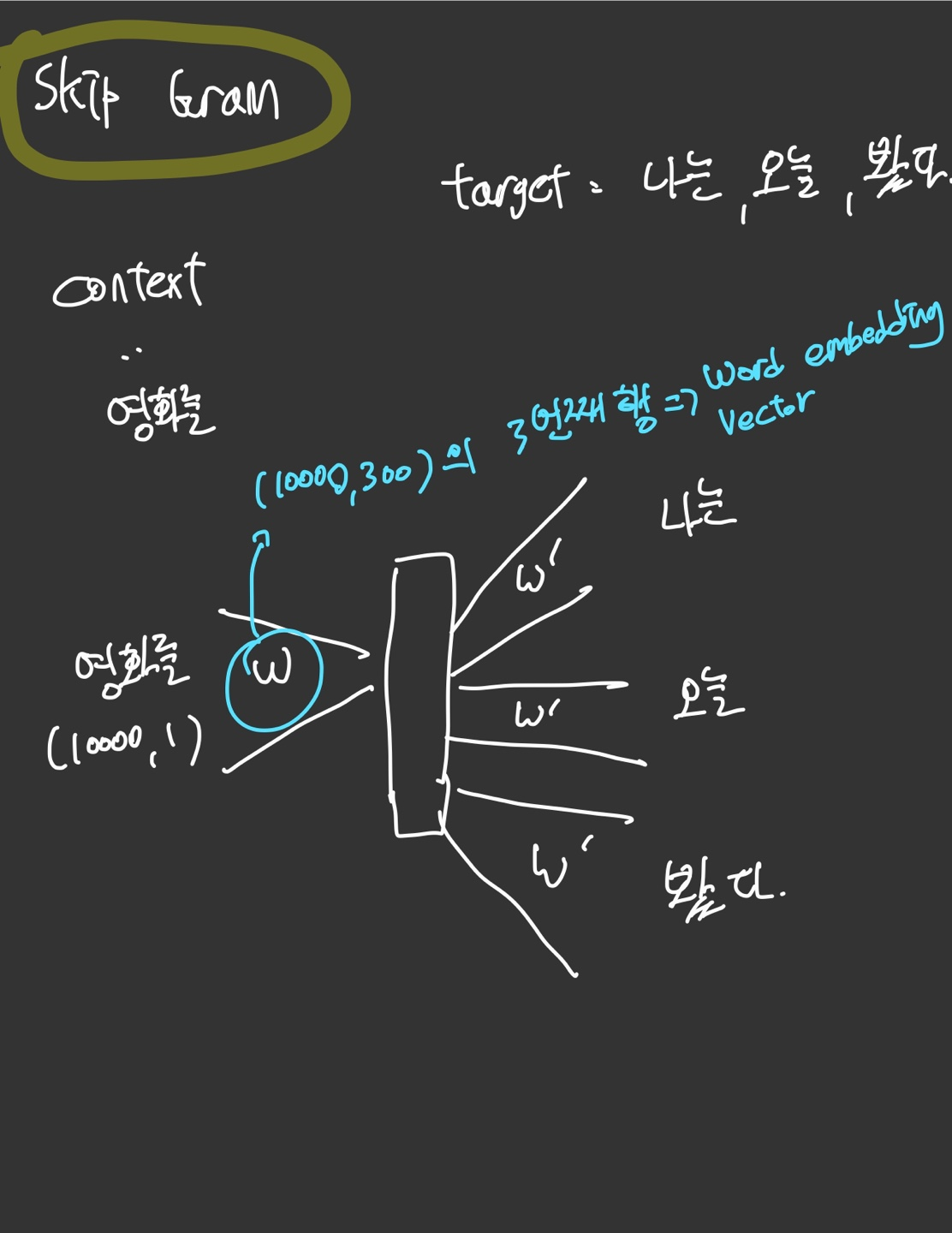
다음과 같이 하나의 Context를 정하고 그 주변 단어(target)과의 관계를 학습해서 워드임베딩을 추출하는 과정을 Skip gram이라고 한다.
-
훈련 데이터셋에서 각 문장을 분석하여 단어 단위로 나눔
-
각 중심 단어에 대해 설정된 '컨텍스트 윈도우 크기'에 따라 그 주변 단어들이 타겟 단어로 선택됨. 예를 들어, 컨텍스트 윈도우 크기가 2라면, 중심 단어의 앞뒤로 두 단어씩이 타겟 단어로 선택된다.
CBOW
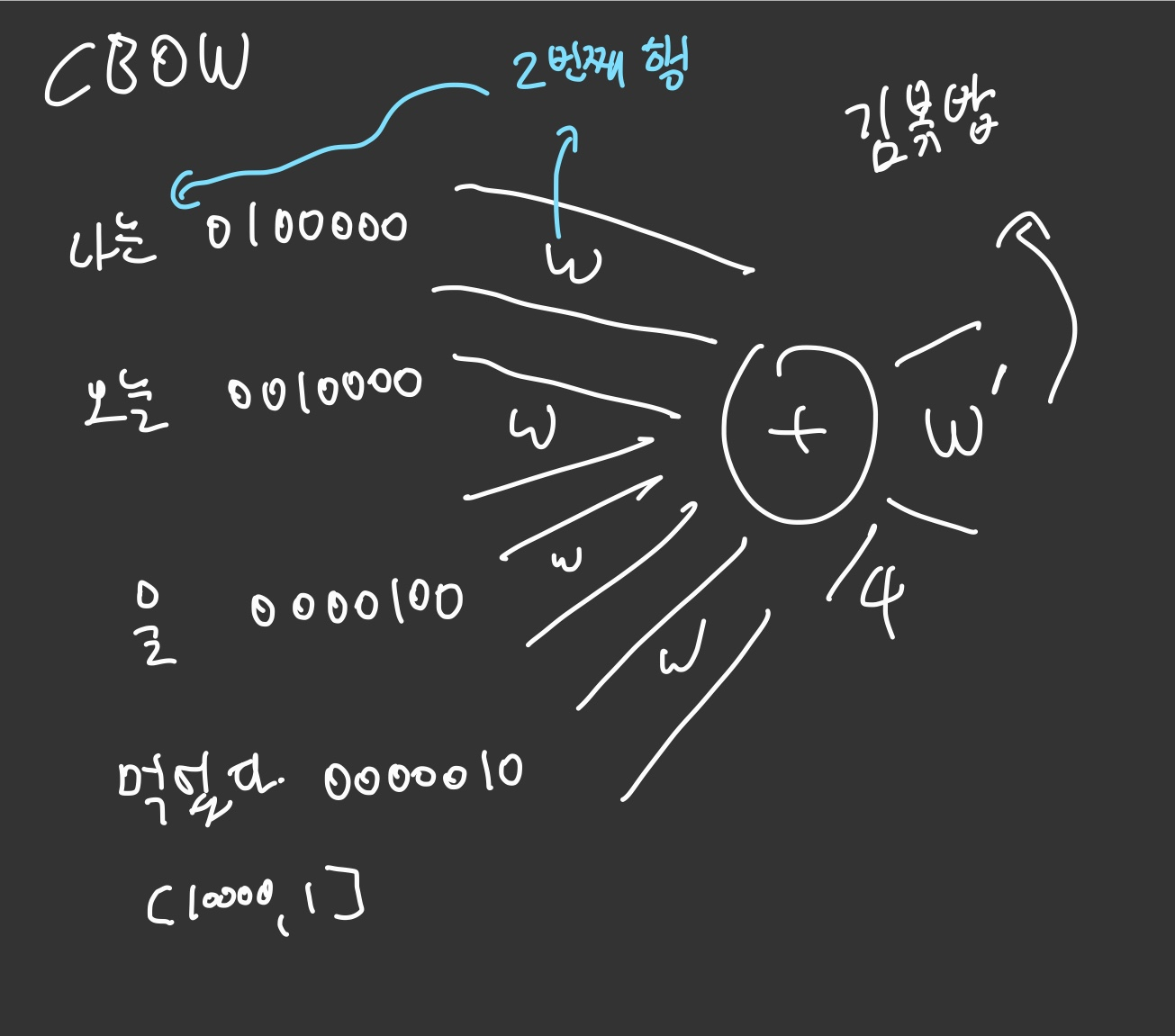
CBOW는 반대로 주변 단어들을 통해 특정 단어를 예측하는 방식이다.
NN 를 학습시키고 Weight행렬의 인덱스 값을 각 단어의 Word embedding으로 결정한다.
