
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea Finn
NeurIPS 2023
1. Introduction
- Preference Optimization(PO): LM을 인간이 선호하는 답변을 출력하도록 학습시키는 것.
- 기존 방식은, 대량의 텍스트 데이터를 갖고 먼저 unsupervised pre-training을 돌린 다음에 PO를 돌리는 것이다.
- PO 알고리즘 중에서 지금까지는 RL을 기반으로 하는 Reinforcement Learning from Human Feedback(RLHF) 알고리즘이 가장 성공적이었다고 한다.
- 우선, 특정 답변에 대해 인간이 얼마나 선호하는지를 나타낸 human preference 데이터셋을 갖고 reward model을 학습시킨다.
- 그런 다음, policy model(실제로 답변을 출력하는 모델)이 답변을 출력하면 reward model이 이를 평가하여 reward를 계산한다. 따라서 우리는 policy model이 reward model로부터 최대한 높은 reward를 받음과 동시에 기존 모델로부터 지나치게 멀어지지 않도록 하는(이를 위해 이 알고리즘에서는 기존 모델과의 KL-divergence constraint를 추가함) RL를 수행한다.
- 그러나 이 알고리즘은 상당히 복잡하고, 계산비용이 많이 든다는 문제가 있다.
- 이 문제를 해결하기 위해, 이 논문은 모델을 human preference 데이터셋에 직접 최적화시킴으로서 따로 reward model을 만들어서 RL를 하지 않아도 되는 Direct Preference Optimization(DPO)라는 알고리즘을 제시한다.
- DPO의 objective는 RLHF의 objective(reward 최대화 & KL-divergence constraint)를 암묵적으로 최적화하는 동시에, RLHF보다 훨씬 간단하고 직관적이다.
2. Related Work
- 여러가지가 있다...생략
3. Preliminaries
* 이 논문은 여기서 RLHF에 대해 좀 더 자세히 리뷰한다.
RLHF는 총 세 페이즈로 구성된다:
- supervised fine-tuning(SFT)
- reward modelling
- RL fine-tuning
SFT
- 보통은 pre-trained 모델을 갖고 우리가 원하는 데이터에 fine-tuning한다. 이때 나오는 모델을 로 표시한다.
Reward Modelling
- 우선 에게 프롬프트를 주고 답변 2개를 출력하도록 시킨다. 이를 로 표시한다.
- 그런 다음, 인간이 이 중 더 선호하는 것을 고른다. 이를 로 표시한다.
- 우리는 이 human preference 데이터를 Bradley-Terry(BT) 모델에서 샘플링한 것으로 가정한다. 이 모델에 따르면, human preference의 분포는 다음과 같다:
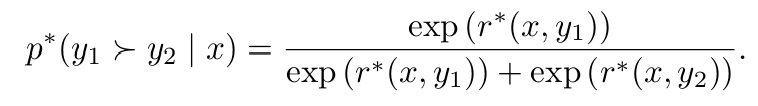
- 따라서 우리의 human preference 데이터셋 은 에서 샘플된 것이고, 이를 갖고 우리의 reward model 의 likelihood를 maximize한다.
- 따라서 우리의 negative log-likelihood loss는 다음과 같다:
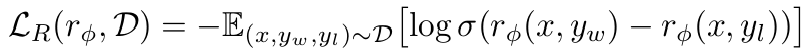
- 즉, reward model은 선호 답변과 비선호 답변의 리워드 차이를 최대한 벌리는 방식으로 학습하게 된다.
RL Fine-Tuning
- language model은 reward model이 주는 리워드를 기반으로 RL을 수행한다. 목표는 다음과 같다:
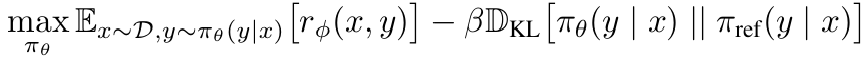
- 여기서 reference model 는 1번 페이즈에서의 이며, 는 reference model과의 편차를 컨트롤하는 파라미터이다.
- 이를 통해 우리가 학습시키는 모델 가 reference model로부터 지나치게 멀리가지 않도록 한다.
4. Direct Preference Optimization
- 이 논문은 여기서, 기존의 리워드 함수를 reparametrize함으로써 따로 리워드 모델을 학습시키지 않고 closed form만으로 최적의 policy를 적합시킬 수 있는 loss function을 제시한다.
수식으로 DPO objective 유도하기

- 즉, 리워드 함수를 굳이 설정하지 않아도, policy만 잘 학습시키면 암묵적으로 리워드가 최대화되는 방향으로 나아간다는 것이다.
DPO update는 무엇을 하는가?
- DPO의 gradient는 다음과 같다:
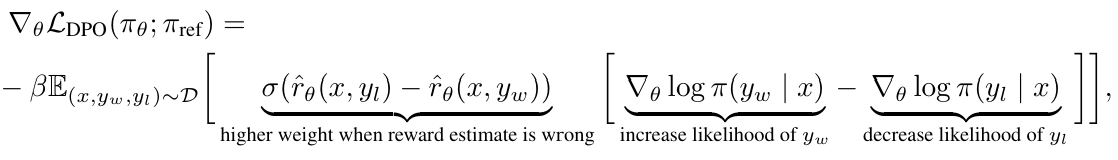
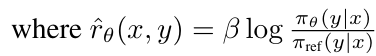
- 이를 잘 보면 알 수 있는 것들이 몇가지 있다.
- 첫번째로, 이는 선호 답변의 likelihood를 늘리고, 비선호 답변의 likelihood는 줄인다.
- 두번째로, sigmoid 부분을 보면, 비선호 답변의 암묵적 리워드()가 커질수록 총 gradient가 증가한다.
- 즉, theta가 이상해서 비선호 답변이 암묵적 리워드를 많이 받으면, 스텝을 크게 늘려서 반대편으로 빨리 가도록 한다.
DPO pipeline
DPO는 다음 과정으로 이루어진다:
- reference model로부터 를 샘플링하고, 인간이 선호를 매겨서 데이터셋 을 구성한다.
- loss를 minimize하도록 policy를 학습시킨다.
- 만약 SFT 모델이 있는 경우, 이를 reference model로 사용한다.
- 없는 경우, 선호 답변의 likelihood를 최대화하는 policy를 reference model로 사용한다.
5. Theoretical Analysis of DPO
5.1. Your Language Model Is Secretly a Reward Model
- 이 섹션에서 논문은 DPO의 reparametrization이 optimal policy를 구하는 데 제약을 걸지 않는다는 것을 이론적으로 검증한다.
Definition 1. 두 리워드 함수 에 대해 이면 두 리워드 함수는 equivalent하다(=같은 클래스이다). (역도 성립)
Lemma 1. PL 혹은 BT 모델에서 두 리워드 함수가 equivalent하면 해당하는 preference distribution도 같다.
Lemma 2. 두 리워드 함수가 equivalent하면 RL을 통해 얻어진 optimal policy도 같다.
이에 따라 다음과 같은 결과가 나온다:
Theorem 1. PL 모델의 모든 리워드 클래스는 reparametrization을 통해 의 형태로 나타낼 수 있다.
* 이들의 증명은 부록에 있다.
- 따라서, 같은 클래스의 리워드 중에서
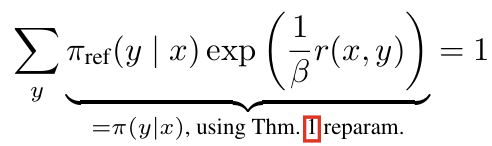
를 만족하도록 리워드를 고르면, 이 되어버린다! 또한 Theorem 1에 의해 리워드의 선택이 결과에 영향을 미치지 않는다. - 그러면, policy는 오직 리워드만의 함수가 되고, policy를 최적화하는 것이 리워드를 최적화하는 것과 정확히 같은 의미를 갖게 된다.
* 이 논문의 부제 "Your Language Model Is Secretly a Reward Model"은 아마 이런 의미일 것이라고 추측되긴 하지만...맞는지는 잘 모르겠다.
5.2. Instability of Actor-Critic Algorithms
- 이제 역으로, DPO를 통해 기존 actor-critic 알고리즘들의 불안정함을 진단할 수 있다.
- 에 해당하는 DPO의 optimal policy를 라 하면, objective는 다음과 같다:
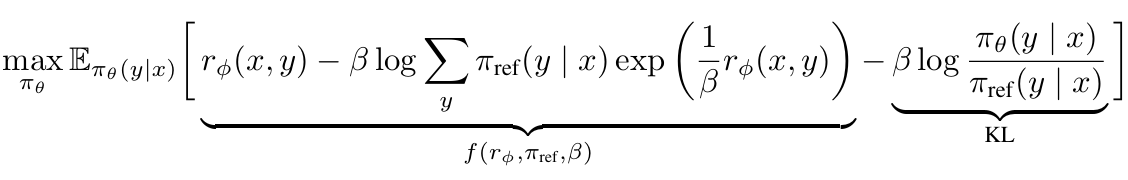
- 속 normalization term은 결과에 영향을 미치지 않지만, 이게 없으면 variance가 높아질 수 있다.
6. Experiments
크게 두가지를 검증한다.
- DPO는 리워드 최대화와 KL-divergence 최소화라는 두 목표을 얼마나 잘 균형있게 달성하는가?
- DPO는 거대한 모델과 어려운 작업에서 얼마나 잘 성능이 나오는가?
Tasks
세가지 text generation 과제가 주어진다.
- controlled sentiment generation
- 영화 리뷰의 앞부분이 주어지면 positive한 리뷰로 완성해야 함
- summarization
- 레딧 게시물이 주어지면 이를 요약해야 함
- single-turn dialogue
- 인간의 질문이 주어지면 도움되는 답변을 생성해야 함
결과
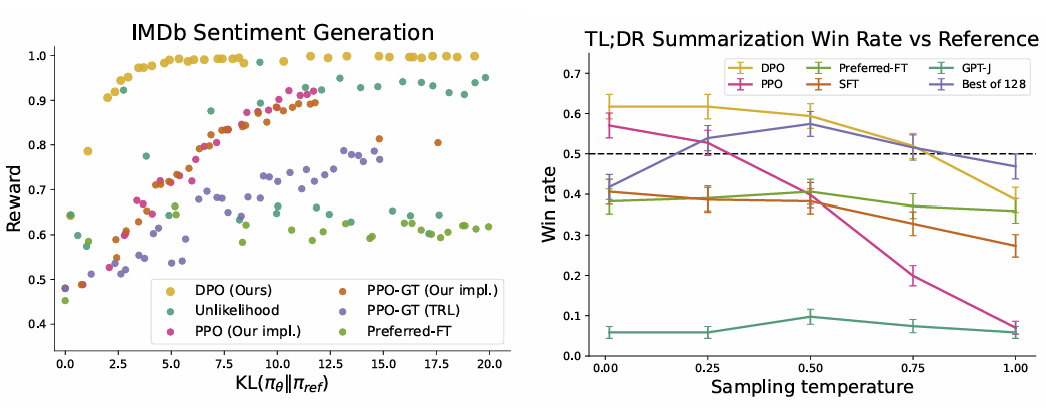
- 왼쪽을 보면, DPO가 KL이 낮으면서 가장 높은 리워드를 받았다.
- 오른쪽을 봐도 DPO가 win rate가 가장 높았다.
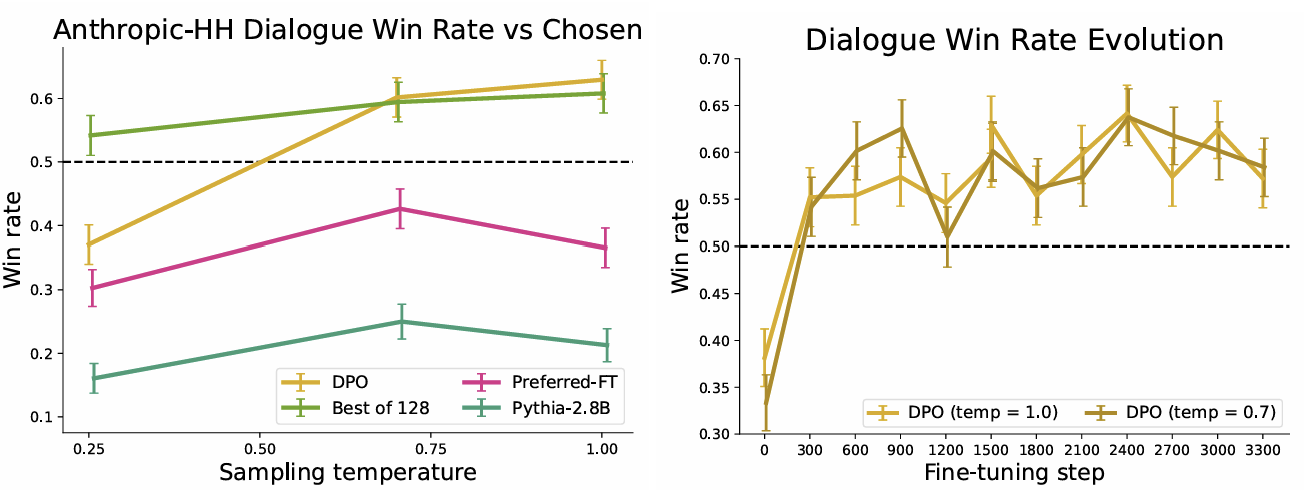
- DPO는 성능이 가장 높으면서, 상대적으로 빨리 수렴했다.
새로운 데이터에서는?
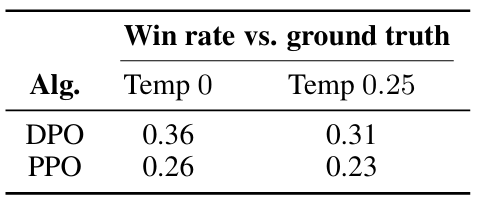
- DPO와 PPO를 완전히 새로운 데이터에 대해 테스트해본 결과, 역시 DPO가 훨씬 뛰어났다.
7. Discussion
여러 한계들과 향후 연구 방향성
- DPO는 어떻게 OOD에서 더 뛰어난 성능을 보였는가?
- 리워드가 어떻게 명백하게 보여지는가?
- 모델을 훨씬 크게 확장하기
- evaluation에서 GPT-4보다 더 나은 판별 시스템?
- DPO의 다른 분야로의 적용
등을 언급하며 이 논문은 마무리된다.

Basil >>>>>>>>>>>>> everything else