논문 리뷰
1.[논문 리뷰] Direct Preference Optimization: Your Language Model is Secretly a Reward Model

Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, Chelsea FinnNeurIPS 2023Preference Optimization(PO): LM을 인간이 선호하
2025년 3월 6일
2.[논문 리뷰] SimPO: Simple Preference Optimization with a Reference-Free Reward
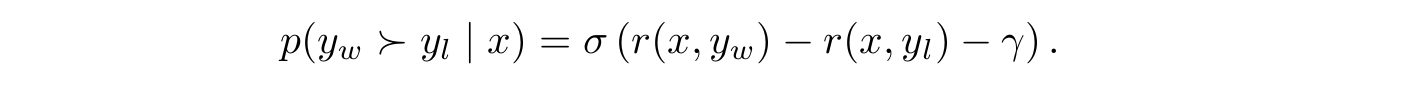
Yu Meng, Mengzhou Xia, Danqi Chen NeurIPS 2024 1. Introduction 기존 RLHF 방법론은 리워드 모델과 언어 모델을 따로 학습해야 해서 비용이 많이 든다는 문제가 있었다. 이를 해결하고자 나온 알고리즘이 바로 DPO이다.
2025년 3월 9일
3.[논문 리뷰] A Simple Framework for Contrastive Learning of Visual Representations

Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton ICML'2020
2025년 3월 13일
4.[논문 리뷰] Positive Unlabeled Contrastive Learning

Anish Acharya, Sujay Sanghavi, Li Jing, Bhargav Bhushanam, Dhruv Choudhary, Michael Rabbat, Inderjit DhillonPreprint머신러닝에서 중요한 주제 중 하나는 라벨이 있는 데이터가 한정
2025년 3월 15일