
Yu Meng, Mengzhou Xia, Danqi Chen
NeurIPS 2024
1. Introduction
- 기존 RLHF 방법론은 리워드 모델과 언어 모델을 따로 학습해야 해서 비용이 많이 든다는 문제가 있었다.
- 이를 해결하고자 나온 알고리즘이 바로 DPO이다.
Direct-Preference-Optimization-Your-Language-Model-is-Secretly-a-Reward-Model - DPO는 reparametrization을 통해 리워드 모델 없이 언어 모델을 직접 학습시키는 것만으로도 '암묵적' 리워드를 최대화할 수 있는 알고리즘이다.
- DPO의 암묵적 리워드는, 언어 모델과 SFT를 거친 레퍼런스 모델의 답변의 log-likelihood 비율을 사용한다.
- 그러나 이 리워드는 실제로 생성을 잘 할 수 있도록 가이드해주는 리워드와는 거리가 멀다는 문제가 있다.
- 실제 생성 능력에 대한 리워드는 언어 모델의 답변에 대한 평균 log-likelihood에 더 가깝다.
- SimPO의 메인 아이디어는, PO objective 속 리워드 함수를 생성 성능과 align되도록 하는 것이다.
- SimPO는 두가지 파트로 나뉜다:
- length-normalization reward: 언어 모델의 답변에 대한 평균 log-likelihood로 계산된다.
- target reward margin: win/lose간 격차가 특정 마진을 넘어서도록 보장해주는 역할을 한다.
- 따라서, SimPO는 다음과 같은 특징을 갖는다:
단순함: 레퍼런스 모델이 필요없다.
성능 향상: 모델이 단순하기 때문에, 뛰어난 성능을 보인다.
길이 남용 방지: length-normalization 덕분에 단순히 답변을 길게 하는 식으로 성능을 속이지 않는다.
2. SimPO: Simple Preference Optimization
2.1. Background: Direct Preference Optimization (DPO)
- DPO의 리워드 함수는 다음과 같이 closed-form으로 표현된다.
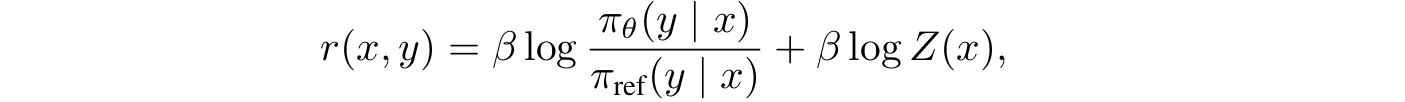
- 여기서 는 우리가 학습시킬 언어 모델, 는 레퍼런스 모델이다.
- 이를 Bradley-Terry (BT) 모델을 통해 objective를 설정하면 다음과 같다:
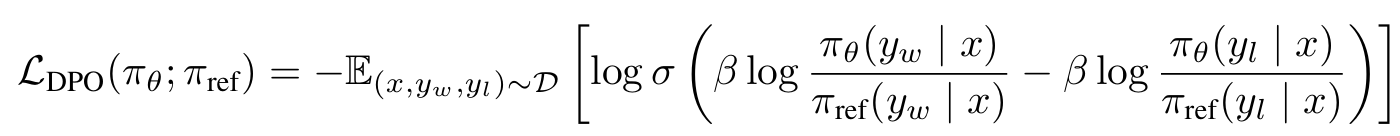
2.2. A Simple Reference-Free Reward Aligned with Generation
Discrepancy between reward and generation for DPO
- DPO의 objective는 다음과 같은 결점이 있다:
- 트레이닝 중 레퍼런스 모델이 필요하다.
- 트레이닝때는 레퍼런스 모델을 갖고 리워드를 최적화하지만, 정작 추론 단계에서는 레퍼런스 모델 없이 언어 모델의 log-likelihood를 기준으로 답변을 생성하기 때문에, 리워드가 높더라도 답변의 log-likelihood가 높지 않을 수 있다.
Length-normalized reward formulation
- 이를 해결하기 위해, SimPO는 토큰별 log-likelihood를 모두 더한 후 답변 길이에 따른 정규화를 해주는 방식을 차용한다.
- 이를 average log-likelihood라고 부른다. 식은 다음과 같다:
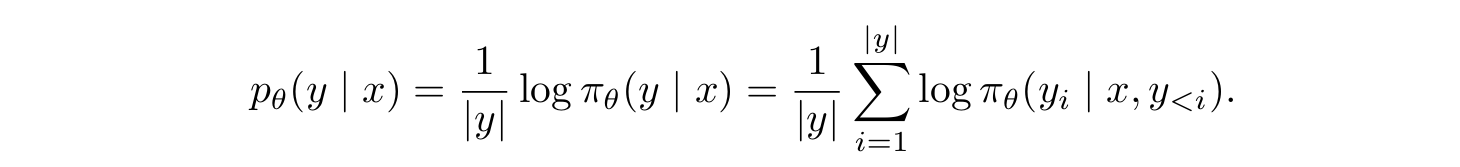
- 자연스럽게 이 average log-likelihood를 리워드 함수로 사용한다는 생각을 할 수 있다. 따라서 SimPO의 리워드 함수는 다음과 같다:
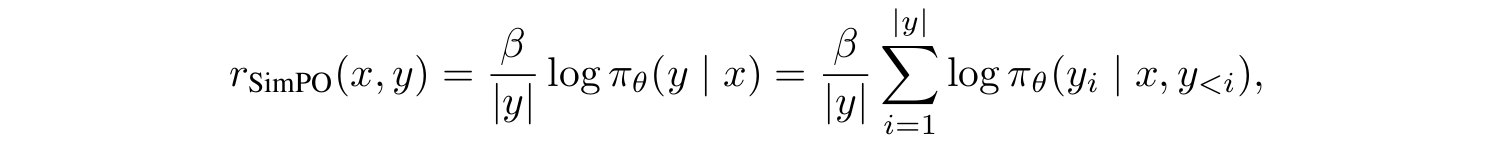
- 실제로 실험 결과, 저 length normalization term이 없으면, 모델의 답변이 쓸데없이 길고 바보같아진다는 것이 밝혀졌다.
2.3. The SimPO Objective
Target reward margin
- 추가적으로, 이 논문은 win/lose간의 리워드 차이가 target reward margin 를 넘어서도록 BT objective를 수정한다:
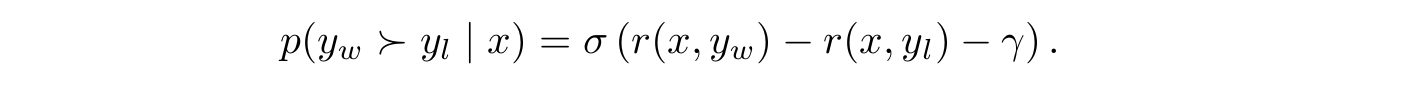
- 두 클래스간의 마진이 클수록 generalization이 향상된다는 것은 이미 증명되어 있다(그렇다고 한다).
- 실험 결과, 적당히 큰 마진은 답변의 질을 향상시키지만, 지나치게 큰 마진은 오히려 성능을 떨어트렸다.
Objective
- target reward margin을 이식함으로써, 이제 최종적으로 SimPO의 objective를 구할 수 있다:
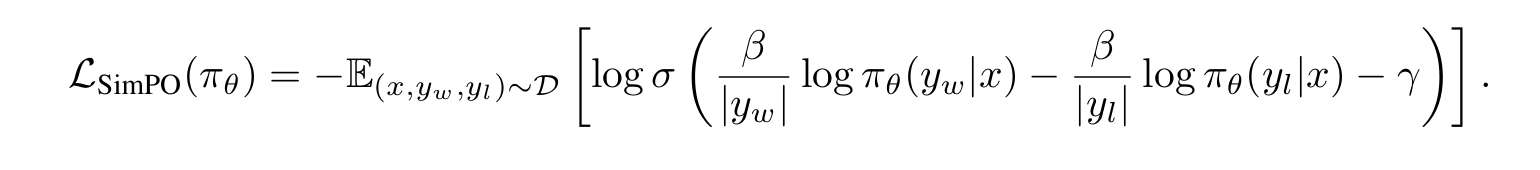
- 우리는 이제 레퍼런스 모델 없이, 생성 성능과 직접적으로 맞닿아있는 암묵적 리워드를 최적화할 수 있게 되었다!
Preventing catastrophic forgetting without KL regularization
- SimPO는 KL divergence를 직접적으로 컨트롤하지 않지만, 트레이닝 세팅을 잘 한다면 낮은 KL divergence를 성취할 수 있었다.
- 이 세팅에는 다음이 포함된다:
- small learning rate
- 다양한 종류의 preference dataset
- LLM이 기존 지식을 까먹지 않으면서 새로운 데이터를 학습할 수 있는 능력
- 이에 대한 실험 결과는 4.4에서 나올 것이다.
3. Experimental Setup
Models and training settings
- 사용 모델: Llama-3-8B, Mistral-7B
- Base와 Instruct 셋업을 사용
Base
- 우선 베이스 모델을 학습시켜 SFT모델을 얻는다.
- 이 SFT모델을 시작으로 PO를 수행한다.
- 이는 전부 오픈소스이다.
Instruct
- 상용 모델을 SFT모델로 사용한다. 이 모델은 instruction-tuning을 아주 많이 받아서 Base 셋업의 SFT보다 더 강력하다.
- 그러나 RLHF 과정이 공개되지 않아 Base 셋업보다 불투명하다.
* evaluation benchmarks, Baselines는 생략.
4. Experimental Results
4.1. Main Results and Ablations
- SimPO는 기존 알고리즘들보다 상당히 뛰어난 성능을 보여줬다.
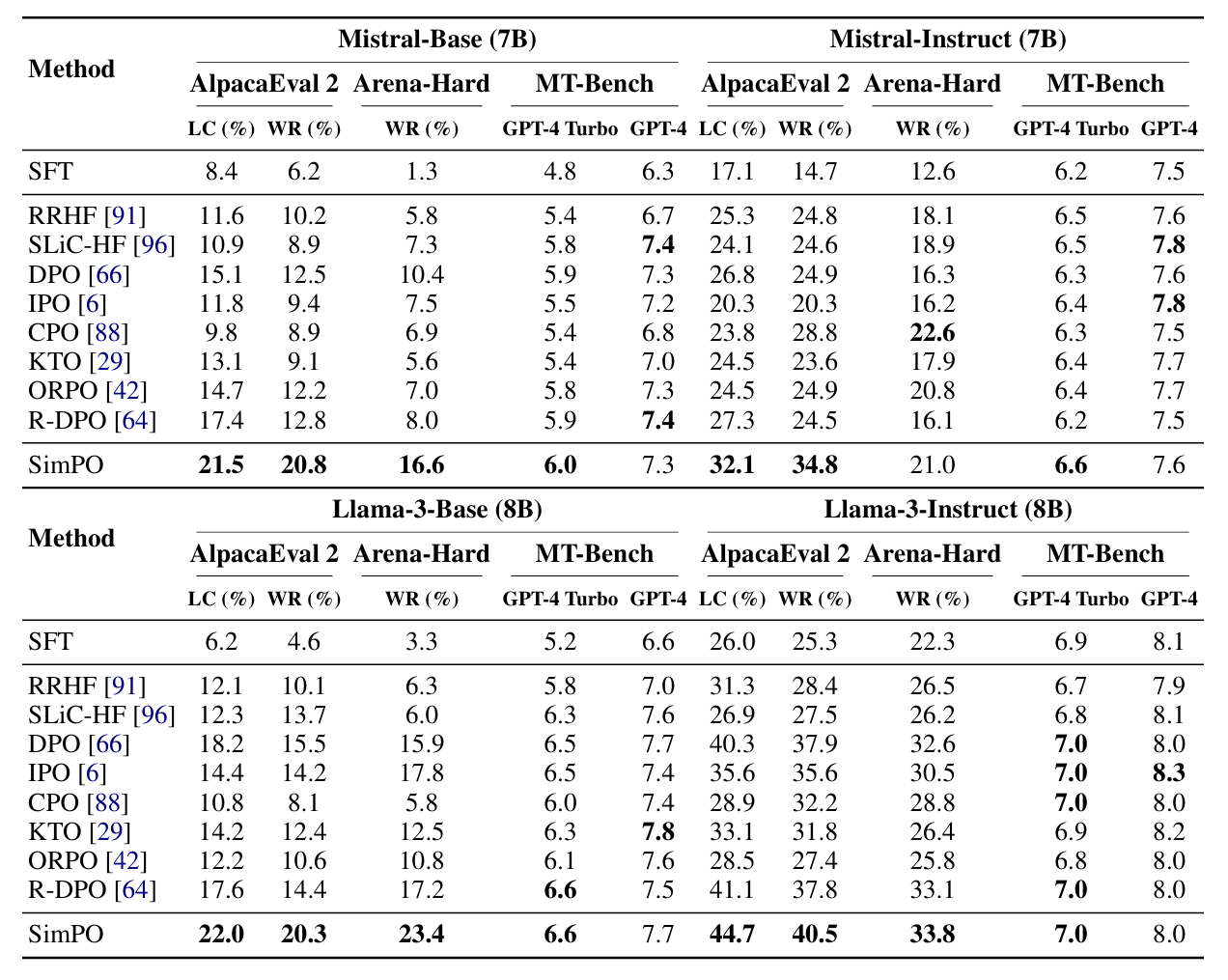
- 4가지 셋업 모두에서 SimPO의 전체적인 성능이 가장 뛰어났다.
- 그 외에도 여러 발견점들이 있다.
- MT-Bench는 퀄리티가 별로이다.
- 모델들은 Base보다 Instruct 셋업에서 성능이 높게 나온다. 아마 SFT모델이 더 강력해서인걸로 생각된다.
- 다음으로는, SimPO의 두 파트 전부가 필수적임을 검증하는 것이다.
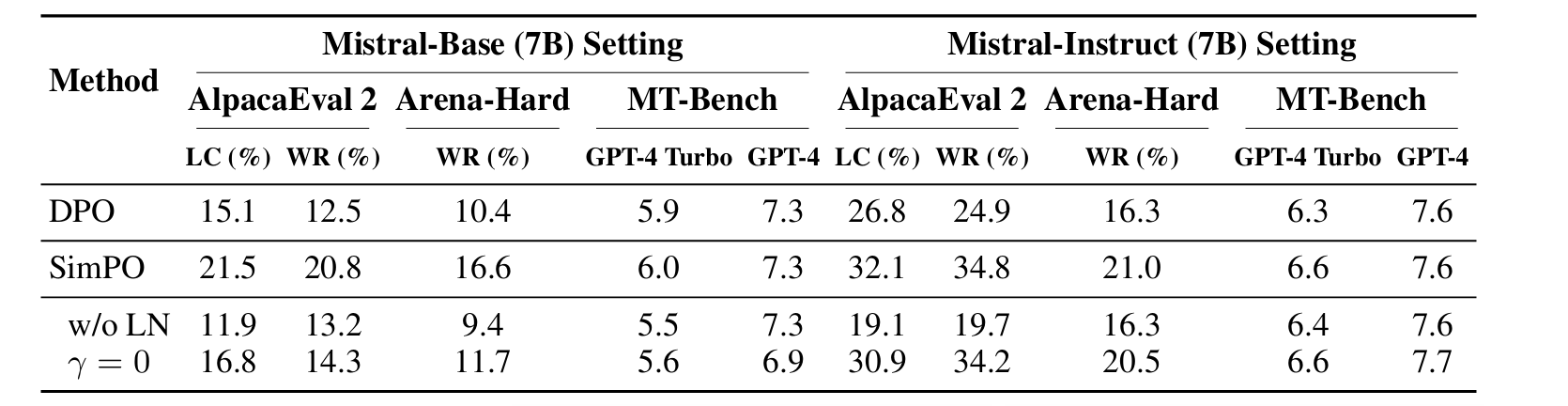
- length-normalization이나 target reward margin을 빼고 실험해보니 성능이 많이 떨어지는 걸 볼 수 있다. 이를 다음 장에서 좀 더 자세히 분석하도록 하자.
4.2. Length Normalization(LN) Prevents Length Exploitation
-
LN은 길이와 상관없이 모든 preference pair의 win/lose간 리워드 차이를 늘려준다.
-
질문은 다음과 같다: 리워드 차이 과 길이 차이 은 무슨 관계인가?
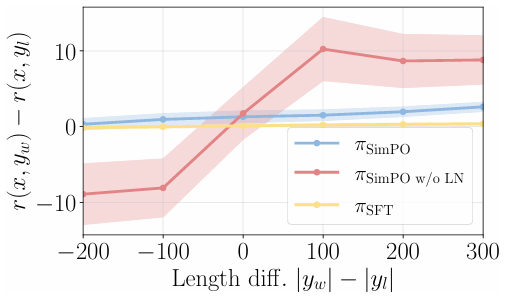
-
SimPO는 모든 길이 차이에서 안정적으로 높은 리워드를 보인다.
-
반면, LN이 없는 SimPO는 길이 차이에 따라 리워드가 흔들리는 모습을 보인다.
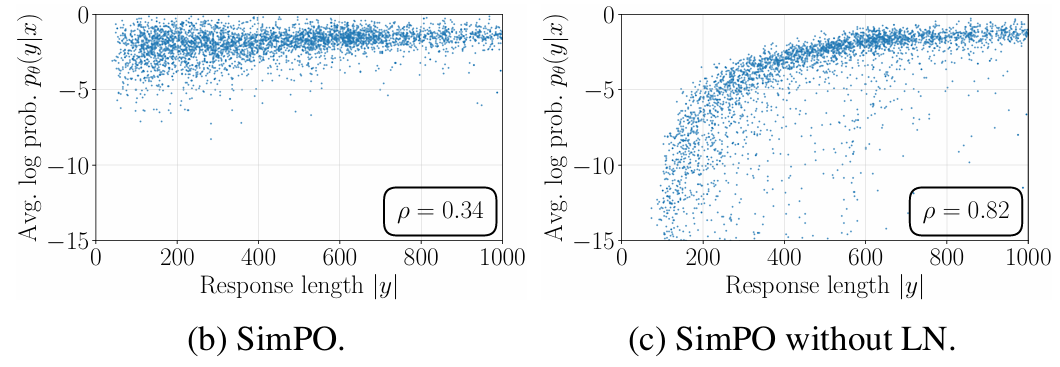
-
아래 그림을 보면, LN이 없는 경우 average log-likelihood가 답변 길이과 강한 상관관계를 가지는 것을 확인할 수 있다.
4.3. The Impact of Target Reward Margin in SimPO
- 그렇다면, 는 리워드 정확도와 win-rate에 어떤 영향을 미치는가?
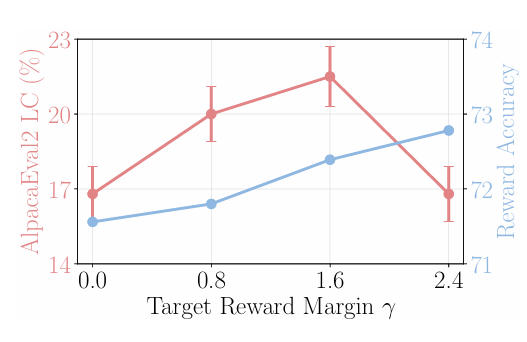
- 두 벤치마크 모두에서 가 증가할수록 accuracy가 증가한다.
- 하지만, AlpacaEval2에서는 너무 큰 가 오히려 성능을 떨어트렸다.
- 아래 그림을 보자.
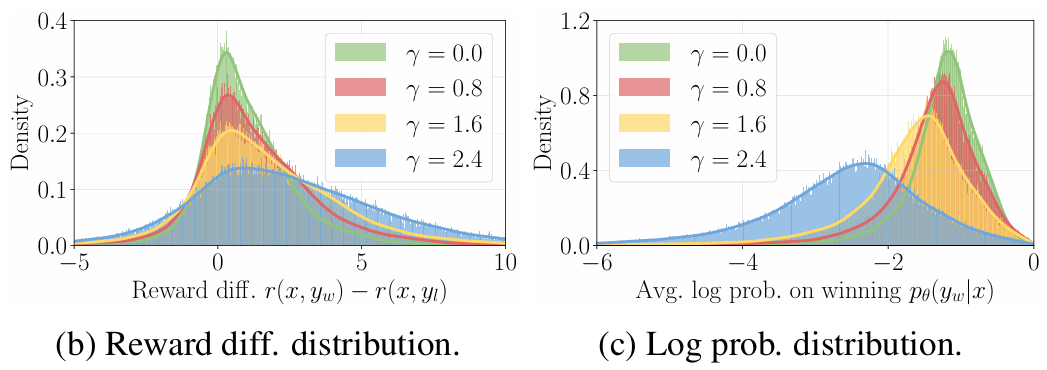
- (b)는 리워드 차이의 분포, (c)는 winning response의 리워드 분포이다.
- 가 커질수록 두 분포가 평평해지는 걸 볼 수 있다. 특히, (c)의 경우 아예 log-likelihood가 줄어들고 있다.
- 이 논문은 이에 대해, 정확한 리워드 분포를 찾는 것과 잘 조정된 likelihood를 유지하는 것 사이에 trade-off가 발생하기 때문이라는 가설을 제시한다.
4.4. In-Depth Analysis of DPO vs. SimPO
- 이 섹션에서는 SimPO와 DPO를 네가지 측면에서 비교한다.
- likelihood와 길이 간 상관관계
- 리워드 공식
- 리워드 정확도
- 알고리즘 효율성
DPO reward implicitly facilitates length normalization
- DPO의 리워드 함수 는 직접적인 LN term이 없다.
- 그러나 언어 모델과 레퍼런스 모델간 비율 term이 암묵적으로 length bias를 막아준다.
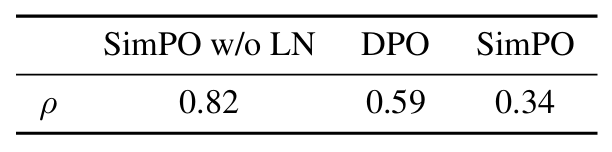
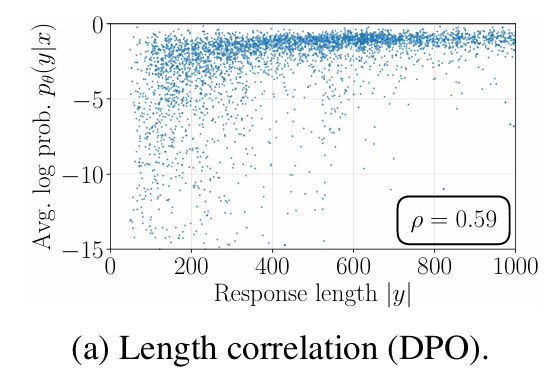
- 보면 알겠지만, DPO는 average log-likelihood와 답변 길이 간 상관관계를 줄어준다.
- 그러나 SimPO보다는 여전히 높은 상관관계를 보인다.
DPO reward mismatches generation likelihood
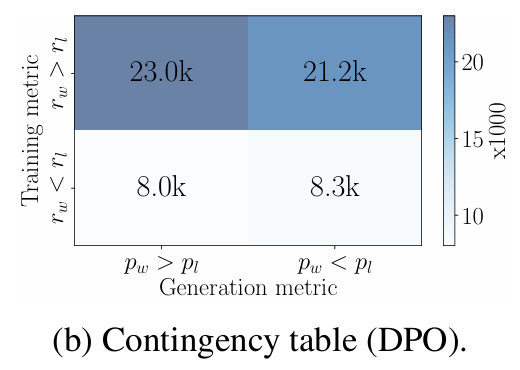
-
그림을 보면, DPO에서 인 데이터중 거의 절반이 이다.
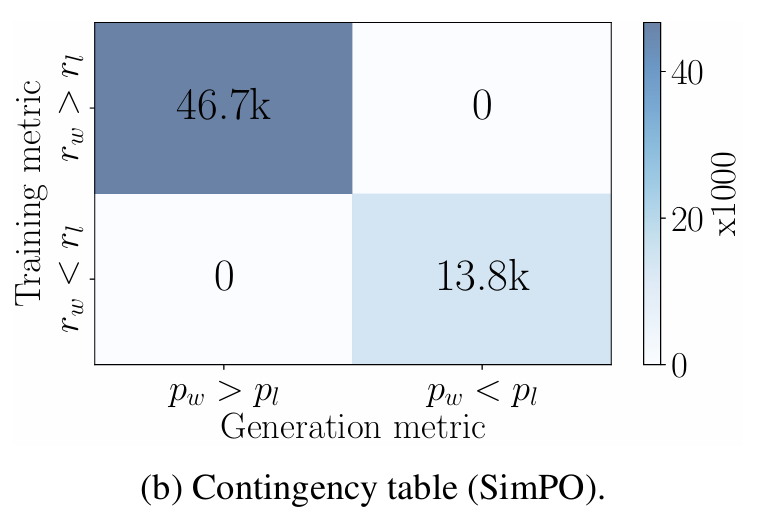
-
반면 SimPO는 아주 잘 분류되어 있다.
DPO lags behind SimPO in terms of reward accuracy
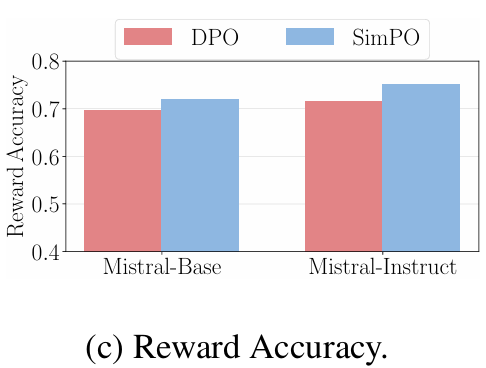
- DPO와 SimPO의 리워드를 비교한 결과 SimPO가 리워드 정확도가 훨씬 높았다.
- 즉, SimPO의 리워드 설계가 더 뛰어나다고 볼 수 있다.
KL divergence of SimPO and DPO
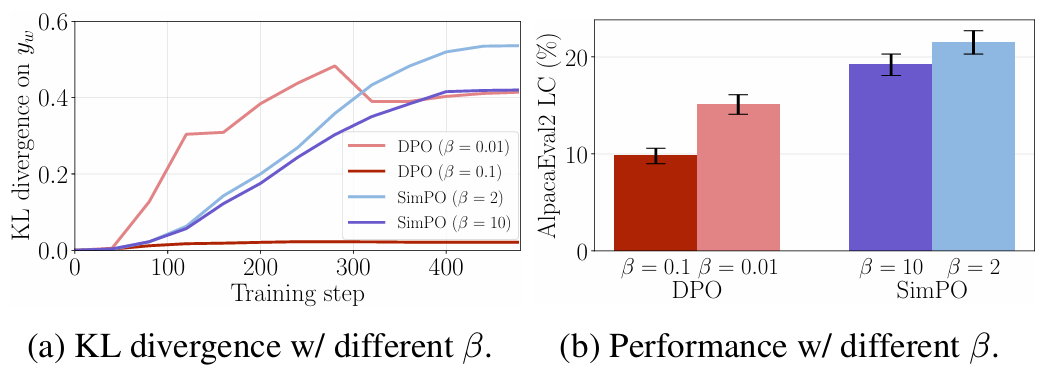
- (a) 언어 모델과 레퍼런스 모델 간 KL divergence를 보면, SimPO의 KL divergence가 꽤 낮음을 확인할 수 있다. 가 커질수록 KL divergence는 작아진다.
- 그런데 (b)를 보면, 가 오히려 작아질수록 성능이 올라간다.
- 이에 대한 가설로, 레퍼런스 모델이 약하면 KL constraint가 별로 좋지 못할 수도 있다는 것을 제시한다.
SimPO is more memory and compute-efficient than DPO
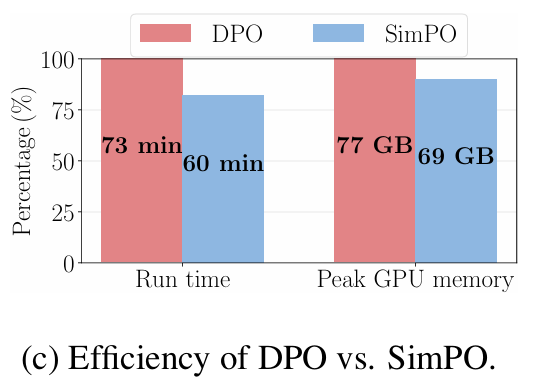
- SimPO는 DPO보다 비용 측면에서도 훨씬 효율적이었다. 이는 레퍼런스 모델이 없는 것이 크다.
6. Conclusion
- SimPO는 간단하고 효율적이며 성능은 훨씬 더 뛰어나다.
- SimPO는 리워드 함수를 생성 성능에 대한 log-likelihood와 일치시킴과 동시에, target reward margin을 추가하는 방식을 사용한다.
- 결과적으로, 레퍼런스 모델이 필요 없으면서 성능은 더 뛰어나고 length bias도 막을 수 있었다.

Basil >>>>>>>>>>>>> everything else