저번 시간에는 스택 자료구조에 대해 알아보았는데요.
오늘은 큐 자료구조에 대한 내용입니다.
큐(Queue) 자료구조 이해하기
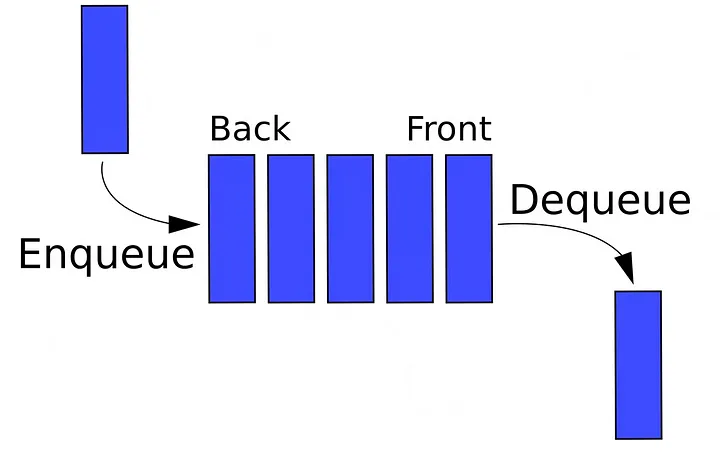
큐(Queue)는 스택과 마찬가지로 기본적인 자료구조 중 하나로, 데이터가 먼저 들어온 것이 먼저 나가는 FIFO(First In, First Out) 방식으로 동작합니다. 큐는 주로 순서대로 처리해야 하는 작업을 관리할 때 유용하게 사용됩니다. 예를 들어, 프린터 대기열이나 프로세스 스케줄링에서 큐가 사용됩니다.
이번 포스팅에서는 큐의 기본 개념을 설명하고, Python을 사용하여 큐를 구현하는 방법을 단계별로 소개하겠습니다.
1. 큐의 기본 개념
큐는 기본적으로 다음과 같은 주요 연산을 지원합니다:
enqueue: 큐의 가장 뒤에 새로운 요소를 추가합니다.dequeue: 큐의 가장 앞에 있는 요소를 제거하고 반환합니다.
추가적으로, 다음과 같은 연산이 있을 수 있습니다:
peek: 큐의 가장 앞에 있는 요소를 반환하지만 제거하지는 않습니다.is_empty: 큐가 비어 있는지 확인합니다.size: 큐에 있는 요소의 개수를 반환합니다.
큐의 대표적인 예로는 줄을 서서 차례를 기다리는 상황을 생각할 수 있습니다. 가장 먼저 줄을 선 사람이 가장 먼저 서비스를 받게 됩니다.
2. Python으로 큐 구현하기
이제 Python을 사용하여 큐를 직접 구현해보겠습니다.
Python에서는 리스트(List)를 사용하여 큐를 간단하게 구현할 수 있습니다.
class Queue:
def __init__(self):
self.items = []
def is_empty(self):
return len(self.items) == 0
def enqueue(self, item):
self.items.append(item)
def dequeue(self):
if not self.is_empty():
return self.items.pop(0)
else:
raise IndexError('You dequeued from an empty queue')
def peek(self):
if not self.is_empty():
return self.items[0]
else:
raise IndexError("You peeked from an empty queue")
def size(self):
return len(self.items)
def __repr__(self):
return f"Queue({self.items})"
def __str__(self):
return str(self.items)
위 코드는 Queue 클래스의 기본 구조를 보여줍니다. 각 메서드를 하나씩 살펴보겠습니다.
__init__: 큐를 초기화합니다. 내부적으로는 리스트self.items를 사용하여 큐를 구현합니다.is_empty: 큐가 비어 있는지 여부를 확인합니다.self.items의 길이가 0이면 비어 있는 것으로 간주합니다.enqueue: 큐의 맨 뒤에 새로운 요소를 추가합니다. Python 리스트의append()메서드를 사용하여 요소를 추가합니다.dequeue: 큐의 맨 앞에 있는 요소를 제거하고 반환합니다. 리스트의pop(0)메서드를 사용합니다.peek: 큐의 맨 앞에 있는 요소를 반환하지만, 제거하지는 않습니다. 리스트의 첫 번째 요소를 반환합니다.size: 큐에 있는 요소의 개수를 반환합니다.__repr__및__str__: 큐 객체의 문자열 표현을 반환합니다. 이 메서드는 주로 디버깅을 위해 사용되며, 큐 객체의 더 자세한 정보를 포함할 수 있도록 디자인되었습니다.
3. 큐 사용 예시
이제 위에서 구현한 큐를 실제로 사용해 보겠습니다.
# 큐 생성
queue = Queue()
# 큐에 요소 추가
queue.enqueue(1)
queue.enqueue(2)
queue.enqueue(3)
print(f"큐 상태: {queue}")
# 큐에서 요소 제거
print(f"dequeue: {queue.dequeue()}")
print(f"큐 상태: {queue}")
# 큐의 맨 앞 요소 확인
print(f"peek: {queue.peek()}")
print(f"큐 상태: {queue}")
# 큐의 크기 확인
print(f"큐 크기: {queue.size()}")
# 큐 비어 있는지 확인
print(f"큐가 비어 있는가? {queue.is_empty()}")
출력 결과:
큐 상태: [1, 2, 3]
dequeue: 1
큐 상태: [2, 3]
peek: 2
큐 상태: [2, 3]
큐 크기: 2
큐가 비어 있는가? False
위 예시를 통해 큐의 동작 방식을 쉽게 이해할 수 있습니다.
4. Python의 deque 라이브러리로 큐 구현하기
Python의 collections 모듈에서 제공하는 deque(double-ended queue)를 사용하여 큐를 효율적으로 구현할 수도 있습니다. deque는 양쪽에서 요소를 추가하거나 제거할 수 있는 자료구조로, 큐의 FIFO 동작을 매우 빠르게 수행할 수 있습니다. 리스트를 사용한 큐 구현과 달리, deque는 양 끝에서의 삽입과 삭제가 O(1) 시간 복잡도로 이루어집니다.
아래는 deque를 사용한 큐 구현 예제입니다.
from collections import deque
class Queue:
def __init__(self):
self.items = deque()
def is_empty(self):
return len(self.items) == 0
def enqueue(self, item):
self.items.append(item)
def dequeue(self):
if not self.is_empty():
return self.items.popleft()
else:
raise IndexError('You dequeued from an empty queue')
def peek(self):
if not self.is_empty():
return self.items[0]
else:
raise IndexError("You peeked from an empty queue")
def size(self):
return len(self.items)
def __repr__(self):
return f"Queue({list(self.items)})"
def __str__(self):
return str(list(self.items))
deque를 사용하여 구현된 큐는 리스트를 사용한 것과 동일한 기능을 가지며, 더 나은 성능을 제공합니다. 특히 큐가 커질수록 deque를 사용한 구현이 더 효율적입니다.
5. 큐 (deque) 사용 예시
이제 위에서 구현한 큐를 실제로 사용해 보겠습니다.
# 큐 생성
queue = Queue()
# 큐에 요소 추가
queue.enqueue(1)
queue.enqueue(2)
queue.enqueue(3)
print(f"큐 상태: {queue}")
# 큐에서 요소 제거
print(f"dequeue: {queue.dequeue()}")
print(f"큐 상태: {queue}")
# 큐의 맨 앞 요소 확인
print(f"peek: {queue.peek()}")
print(f"큐 상태: {queue}")
# 큐의 크기 확인
print(f"큐 크기: {queue.size()}")
# 큐 비어 있는지 확인
print(f"큐가 비어 있는가? {queue.is_empty()}")
출력 결과:
큐 상태: [1, 2, 3]
dequeue: 1
큐 상태: [2, 3]
peek: 2
큐 상태: [2, 3]
큐 크기: 2
큐가 비어 있는가? False
위 예시를 통해 큐의 동작 방식을 쉽게 이해할 수 있습니다.
6. 큐의 실제 활용 예
큐는 알고리즘 문제 해결 시 자주 사용됩니다. 예를 들어, BFS(너비 우선 탐색) 알고리즘에서 큐는 그래프의 각 레벨을 순서대로 탐색하기 위해 사용됩니다. 다음은 간단한 BFS 구현 예시입니다.
그래프 예시:
코드 구현:
# BFS
from collections import deque
def bfs(graph, start):
visited = []
need_visit = deque([start])
while need_visit:
node = need_visit.popleft()
if node not in visited:
visited.append(node)
need_visit.extend(graph[node])
return visited
if __name__ == '__main__':
graph = {}
graph['A'] = ['B', 'C']
graph['B'] = ['A', 'D']
graph['C'] = ['A', 'G', 'H', 'I']
graph['D'] = ['B', 'E', 'F']
graph['E'] = ['D']
graph['F'] = ['D']
graph['G'] = ['C']
graph['H'] = ['C']
graph['I'] = ['C', 'J']
graph['J'] = ['I']
print(f"BFS 방문 순서: {bfs(graph=graph,start='A')}")
출력 결과:
BFS 방문 순서: ['A', 'B', 'C', 'D', 'G', 'H', 'I', 'E', 'F', 'J']이 코드에서 큐는 그래프의 각 노드를 방문 순서대로 저장하여 BFS 알고리즘이 올바르게 동작하도록 합니다.
7. 큐 자료구조의 시간 복잡도
큐의 기본 연산인 enqueue, dequeue, peek, is_empty 등의 연산은 모두 O(1)의 시간 복잡도를 가집니다. 이는 이러한 연산이 큐의 크기에 상관없이 일정한 시간 안에 수행될 수 있음을 의미합니다.
enqueue(item): 큐의 맨 뒤에 요소를 추가하는 연산으로, 시간 복잡도는O(1)입니다.dequeue(): 큐의 맨 앞 요소를 제거하고 반환하는 연산으로, 시간 복잡도는O(1)입니다.peek(): 큐의 맨 앞 요소를 확인하는 연산으로, 시간 복잡도는O(1)입니다.is_empty(): 큐가 비어 있는지 확인하는 연산으로, 시간 복잡도는O(1)입니다.size(): 큐에 있는 요소의 개수를 반환하는 연산으로, 시간 복잡도는O(1)입니다.search(item): 큐에서 특정 요소를 찾는 연산의 시간 복잡도는O(n)입니다.
큐의 각 연산은 대부분 O(1) 시간 복잡도를 가지므로, 큐는 매우 빠르고 효율적인 자료구조입니다. 하지만 검색 연산은 큐의 모든 요소를 확인해야 하므로, 검색이 자주 필요하다면 다른 자료구조를 고려하는 것이 좋습니다.
결론
큐는 매우 기본적이면서도 강력한 자료구조입니다. Python을 활용하면 큐를 쉽게 구현하고 다양한 문제 해결에 적용할 수 있습니다. 이 블로그에서는 큐의 기본 개념과 구현 방법을 설명했고, Python을 사용한 예제 코드를 통해 큐의 동작 원리를 살펴보았습니다. 큐를 이해하고 활용할 수 있다면, 더 복잡한 자료구조나 알고리즘을 이해하는 데 큰 도움이 될 것입니다.
전체 코드는 아래 링크를 들어가셔서 확인하시면 좋을 것 같습니다:
Python/자료구조/구현/Queue at main · jw9603/Python
다음 포스팅은 스택, 큐 자료구조를 활용한 코딩테스트 문제들에 대한 포스팅으로 돌아오도록 하겠습니다.
읽어주셔서 감사합니다!
References
