논문
Optimization_of_therapeutic_an

논문을 바탕으로한 colab 환경 생성
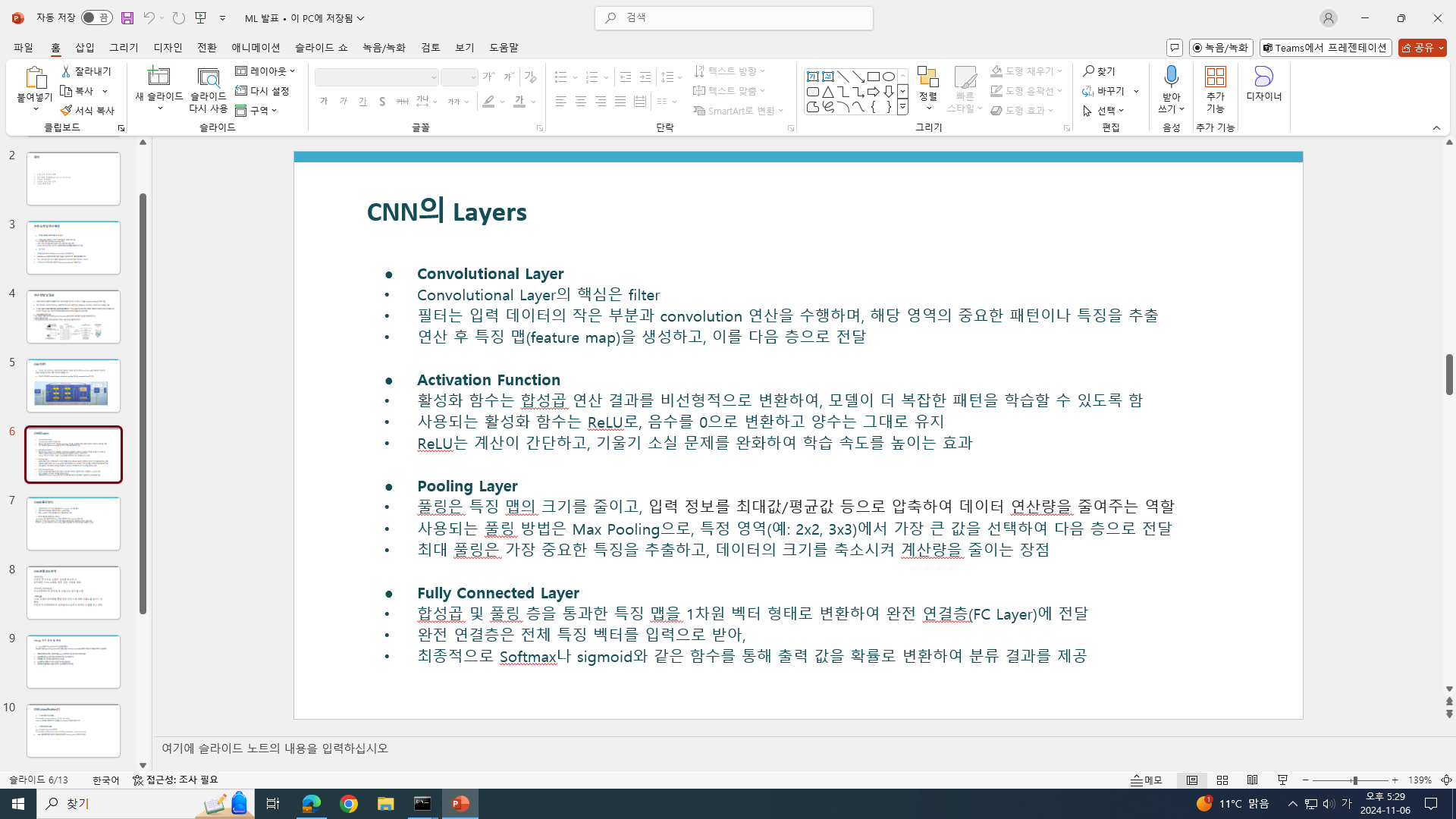
CNN 추가 준비
-
0부터 10000까지 나눌 때, 린스페이스 함수가 뭐냐
->
np.linspace(0, 10000, 11)는 0에서 10000 사이의 숫자들을 11개의 구간으로 나누어서 생성하는 역할
linspace 함수는 시작과 끝 값 사이에서 일정한 간격으로 값들을 생성하는 함수로, np.linspace(start, stop, num) 형식으로 사용
start는 시작 값, stop은 끝 값, num은 생성할 숫자의 개수
0에서 10000까지의 구간을 11개의 값으로 나누어 [0, 1000, 2000, 3000, ..., 10000]과 같은 배열이 만들어짐 -
왜 0부터 10000까지 나누는지
- 데이터는 커질 수록 좋은데 지금은 같은 데이터를 0부터 10000까지 10번 나누는 것뿐. 데이터가 커지는 건 아님. 이게 맞는가? 그렇다면 왜 이렇게 하는가
->
일단 단순히 나누기만 하는 것이 아님. 데이터 크기를 늘려가는 거임
이 코드에서는 train_sizes 변수를 통해 다양한 학습 데이터 크기를 설정하고, 각 크기에 대해 CNN의 성능이 어떻게 변하는지 실험하려는 목적
예를 들어, 데이터 크기를 1000, 2000, ..., 10000으로 늘려가면서 모델의 성능을 관찰하고, 학습 데이터가 더 많아질수록 성능이 개선되는지 또는 일정 데이터 크기에서 성능이 안정화되는지를 분석
train_size가 0인 것은, train data를 넣지 않았을 때 기본 성능을 보기 위함
train data가 없어도, cnn 코드에서 test data와 val data(평가 데이터)가 나눠져 존재하기 때문에, train data가 없어도 성능 측정 가능
Training Set Size: 15125
Test Set Size: 3242
Validation Set Size: 3241
- 여기서 배치사이즈랑 에포크 뭔지
->
에포크(epoch)는 모델이 전체 학습 데이터셋을 한 번 완전히 사용하는 횟수
epochs=20으로 설정되어 있어, 전체 데이터셋을 20번 반복해서 학습
배치 사이즈(batch size)는 한 번의 학습에 사용하는 데이터 샘플의 개수
batch_size=16이라면, 한 번의 학습에서 16개의 샘플씩 모델에 전달되며, 이 과정을 통해 모델의 가중치가 업데이트
-
뉴클레오타이드 서열은 약간씩만 다른데 아미노산 서열은 왜 완전 다르냐
->
TGT AGC AGG TGG CGC CTG GCC AAC TTC TTC AAC AAC AGG TAT TGG WRLANFFNNR
TGT AGC AGG TAC ACC ATC GTC CGC CCC TAC GTG CTC GGC TAT TGG YTIVRPYVLG
TGT AGC AGG TGG TCC GAC AAC GAC TAC TTC ACC CAC GCG TAT TGG WSDNDYFTHA
TGT AGC AGG TTC TTC GAG ATC GAC TTC TTC CAC ATC CTG TAT TGG FFEIDFFHIL
TGT AGC AGG TGG TAC GTG ACC AGC TTC TTC GTC TAC GAG TAT TGG WYVTSFFVYE
앞에 3개, 뒤에 2개만 같고 나머지는 다름
그 나머지 부분의 아미노산 서열만 표시되어 있음
서열의 앞부분(TGT AGC AGG)과 뒷부분(TAT TGG)은 framework 영역
핵심적인 변이 영역인 CDR 부분만을 강조하기 위해서 다른 부분만 표시 -
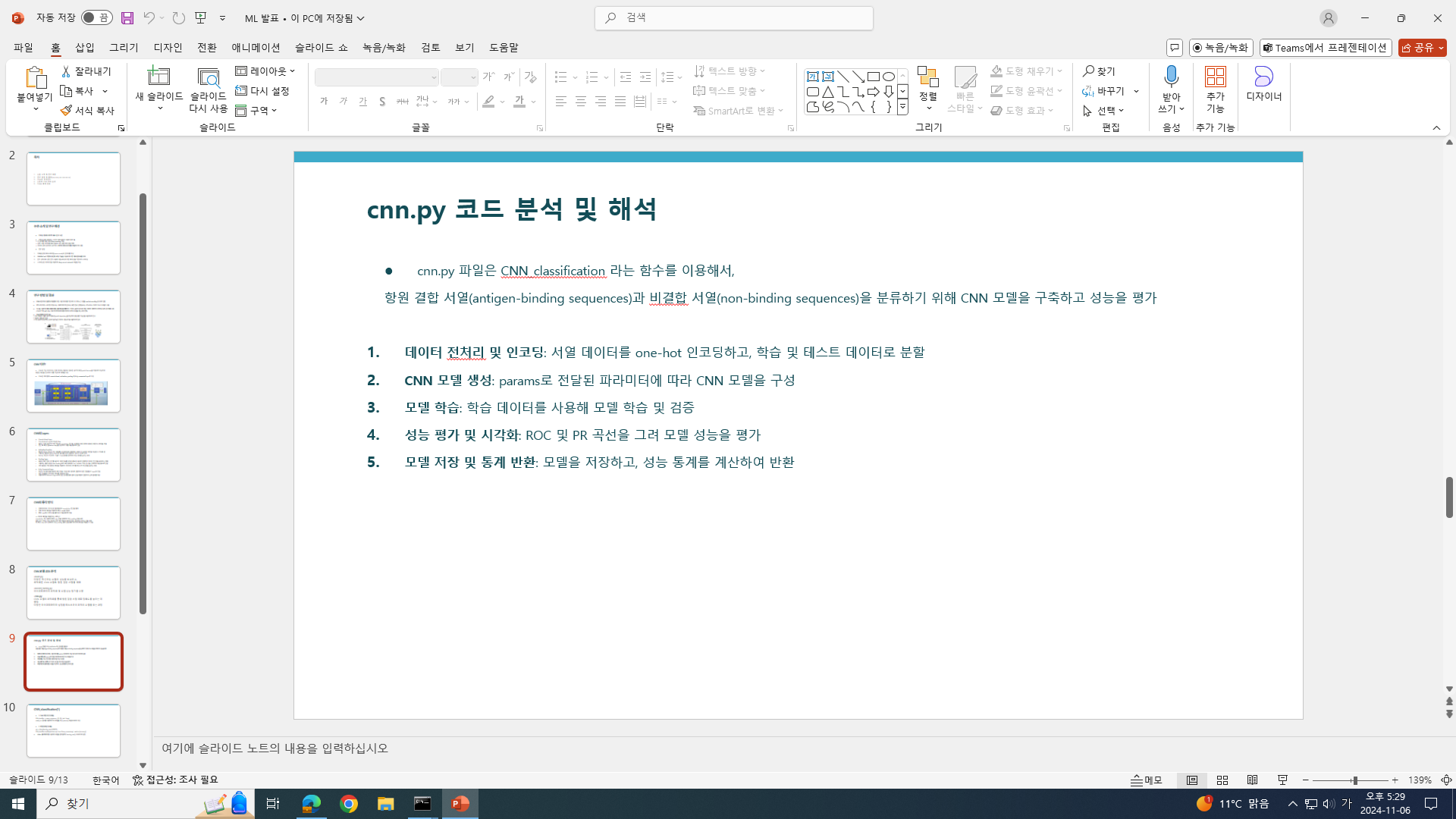
입력데이터로 저것들만 받는 것이 맞느냐, 데이터가 너무 적은 것 아니냐
- input 파일 몇 개 넣는지, 각 파일당 서열 몇 개인지(만개 넘어야 함)
->
보이는 input 파일은 8개로만 보이지만, 각 파일안에 매우 많은 서열 데이터들이 존재
- X_train, X_test, X_val, y_train, y_test, y_val 값 등 들은 어떻게, 왜 그렇게 셋팅했는가
->
X_train, X_test, X_val
데이터가 훈련, 테스트, 검증 세트로 나누어져 있어야 모델이 일반화(generalization) 성능을 평가할 수 있음
훈련 세트는 모델 학습에 사용하고, 검증 세트는 하이퍼파라미터 튜닝에 사용하며, 테스트 세트는 최종 성능 평가에 사용
one_hot_encoder 함수는 아미노산 서열을 One-hot 인코딩 방식으로 변환
np.transpose(..., (0, 2, 1))는 배열의 차원을 변경하는데, 신경망에서 아미노산 서열을 처리할 수 있도록 배열 형식을 (샘플 수, 특성 수, 서열 길이)로 맞춤
y_train, y_test, y_val
y_train: 모델 학습에 사용되는 정답 라벨
모델은 X_train(입력 데이터)을 보고 어떤 결과를 예측
이때 모델이 예측한 값과 실제 정답인 y_train 값을 비교하여, 얼마나 정확히 예측했는지를 계산
예를 들어, X_train에 'CAT'라는 단어가 있고 y_train이 1이라면, 모델이 'CAT'을 1로 예측해야 정답
y_test, y_val: 모델 성능 평가에 사용되는 정답 라벨
모델이 학습을 마치면, 이제는 새로운 데이터(즉, X_test와 X_val)에 대해 얼마나 잘 예측하는지를 확인해야 함
X_test나 X_val을 모델에 넣으면 모델은 예측 값을 내놓고, 그 예측 값과 실제 정답인 y_test 또는 y_val을 비교하여 정확도, 재현율, F1 점수 등 성능 지표를 계산
y_test와 y_val은 모델이 학습되지 않은 새로운 데이터에서 얼마나 잘 예측하는지 확인
y 값은 모델이 무엇이 정답인지 알 수 있게 해주는 역할
-
Accuracy를 어떻게 측정했냐(그니까 얼마나 약효가 좋냐를 어떻게 계산하고, 어떻게 확인하는가)
->
결합 서열과 비결합 서열을 분류하는 모델이기 때문에, Accuracy는 모델이 올바르게 결합 또는 비결합 서열을 맞춘 비율로 해석
결합 서열 분류 실험에서의 정확도는 모델이 결합 가능 여부를 얼마나 정확히 예측하는지를 나타내며, 이를 통해 약효를 추정할 수 있음
결합 서열(1)로 예측한 서열이 많고, 실제로 결합 서열이라면 약효가 좋은 것으로 볼 수 있음
여기서 결합 서열은 특정 항원과 결합하는 능력이 있는 항체 서열을 의미하고, 비결합 서열은 항원과 결합하지 않는 서열을 의미
Accuracy는 모델이 항체 서열이 항원에 결합할지 여부를 얼마나 정확하게 예측했는지를 나타내는 지표이 지표는 약효가 있을 것으로 기대되는 항체 결합 서열을 올바르게 분류하는 능력을 보여주며, 이를 통해 약효 예측 성능을 평가 -
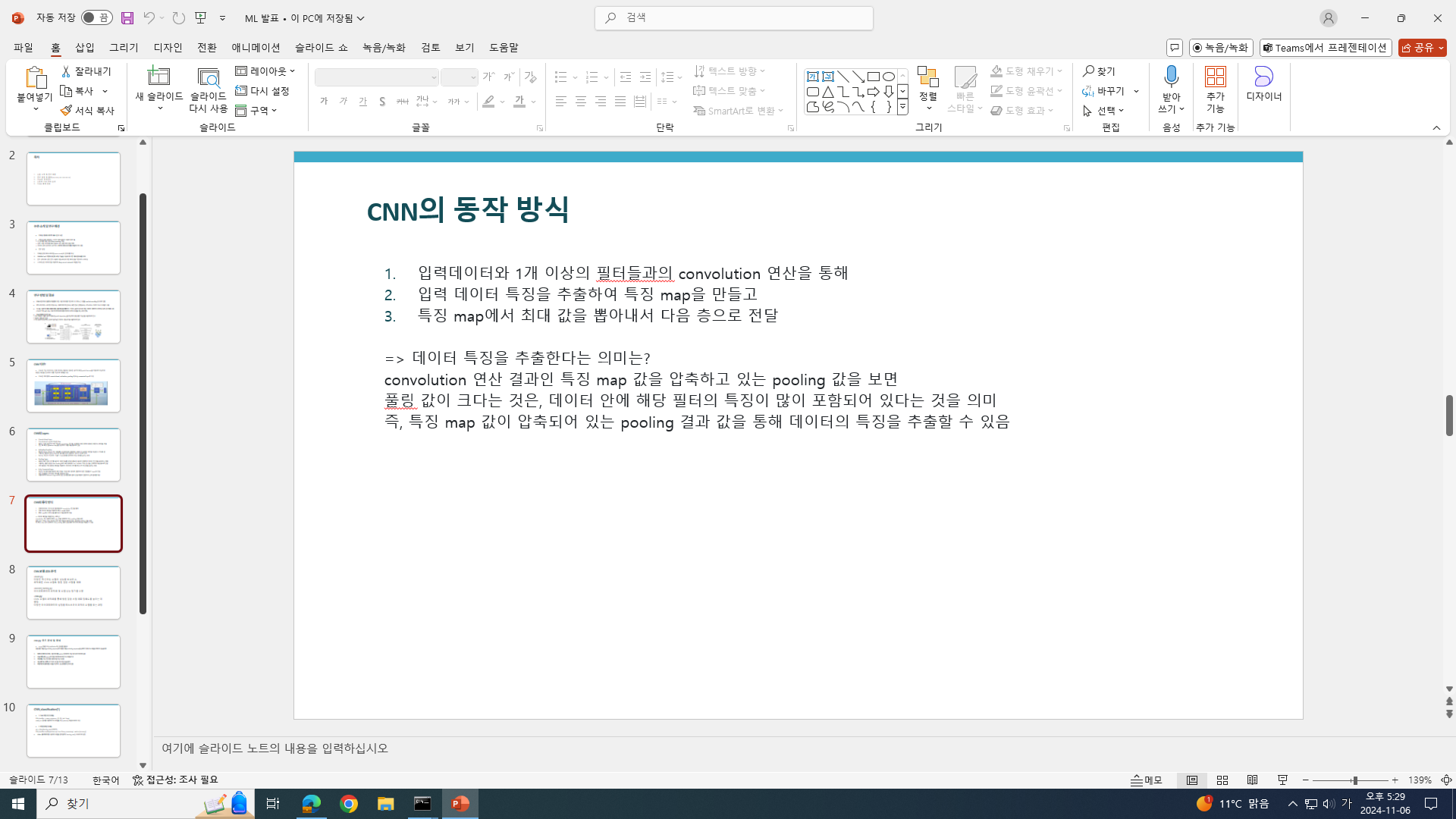
결론적으로 이 CNN으로 뭘 하고 싶은거냐(무슨 결과를 알고 싶은거냐)
->
항체 서열이 HER2 항원과 결합할 가능성이 있는지를 예측하여 항체 치료제의 효능을 최적화하는 것
모델이 성공적으로 결합 가능성을 예측할 수 있다면, 새로운 항체 설계 시 HER2에 잘 결합하는 후보군을 미리 선별하여 시간과 비용을 절약할 수 있음 -
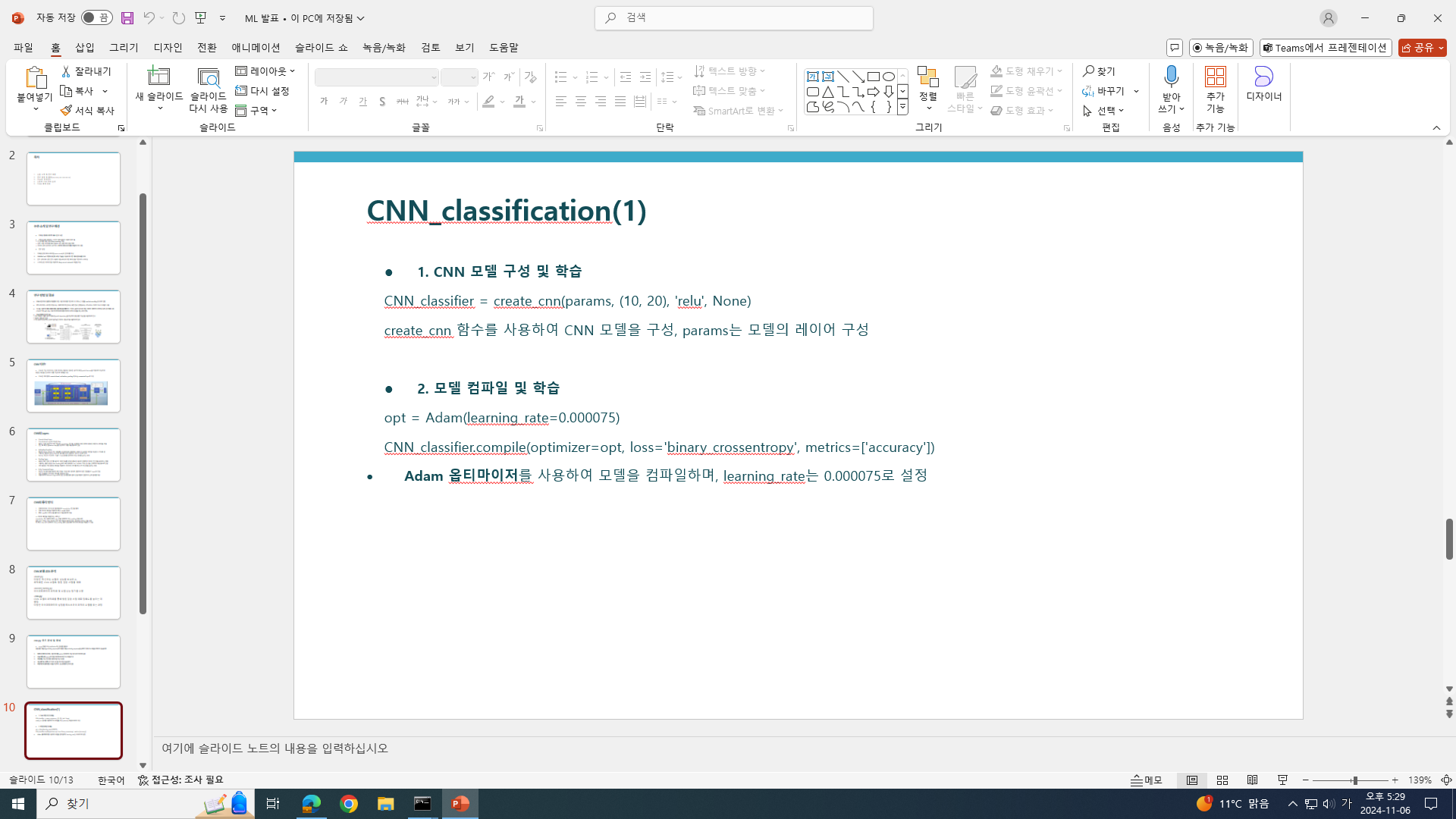
데이터 크기 달라질 때, 유독 결과 안 좋은 것 있음. 이건 왜 그런지 확인(분명 이유 있을 것)
->
코드 상에서 CNN_classification 함수가 두 번 사용됨
위쪽 CNN_classification은 데이터 크기에 따른 성능 변화를 측정하고,
밑쪽 CNN_classification은 최적의 하이퍼파라미터를 통해 전체 데이터에 대해 모델 성능을 최적화
위쪽 CNN_classification:
여러 Train_size에 대해 모델을 학습하고 성능을 평가하여 학습 데이터 크기가 모델 성능에 미치는 영향을 확인
이를 통해 적절한 데이터 크기를 찾거나, 데이터 크기에 따른 성능 변화를 분석
작은 데이터셋에서 시작해 점점 더 많은 데이터를 추가하면서 모델의 성능이 어떻게 개선되는지 관찰
큰 틀로 봤을 때, train_size 가 커질 수록 accuracy 가 증가함을 확인 할 수 있음
밑쪽 CNN_classification:
최종적으로 전체 데이터를 사용하여 모델의 성능을 최적화하는 과정
이때는 params로 설정된 하이퍼파라미터를 적용해, 네트워크 구조와 드롭아웃 등의 설정을 조정하여 최적의 성능을 이끌어냄
(위쪽에서는 CNN.py 에서 설정한 기본 하이퍼파라미터 적용)
따라서, 위쪽의 단계는 데이터 크기에 따른 성능 변화를 탐색하는 과정이고, 밑쪽 단계는 최적화된 설정으로 전체 데이터를 학습하여 최종 예측에 사용할 모델을 만드는 과정
이때, train_size를 늘려가며 accuracy가 소폭 떨어지는 구간들이 존재
이는, 하이퍼파라미터를 조정하지 않고, 기본적으로 CNN.py에서 설정한 파라미터 값을 사용해서 그런 것으로 판단
과적합 문제로 볼 수 있는데,
train_size가 작은 데이터에서는 잘 학습했지만, 데이터가 증가하면서 일부 데이터에 대해 특히, 드롭아웃 비율이 높은 기본 설정에서는 데이터가 많아질수록 과적합이 발생할 가능성이 커질 수 있음(데이터가 랜덤으로 들어올 때, 특정 비슷한 유형의 데이터들이 몰려 들어올 경우가 있을 수 있음)
하지만, 위쪽 단계의 CNN_classification 은, train_size 마다의 accuracy를 높이기 보다는, train_size를 증가시킴에 따라 전반적으로 accuracy가 향상되는가를 확인하기 위함이므로 목적은 달성했다고 볼 수 있음
밑쪽 단계의 최종 CNN_classification에서 하이퍼파라미터를 조정하며, accuracy를 90퍼센트 이상 값으로 얻어냈기 때문에, 결론적으로 하고자 하는 목적을 이뤘다 판단할 수 있음
