
결측치(Missing Value)
- 이전 글에서 다룬 결측치 관련 내용
- 데이터셋에서 특정 값이 존재하지 않거나 누락된 상태를 의미
도메인을 활용한 결측치 처리 방법
- 데이터의 도메인 지식과 맥락을 활용하여 결측치를 대체하거나 보간하는 방법을 말한다.
- 단순히 전체 평균이나 중앙값을 사용하지 않고, 데이터의 의미 있는 변수나 상황을 기반으로 그룹을 나누고, 해당 그룹 내에서 적절한 통계량(평균, 중앙값 등)을 사용해 결측치를 처리하는 방법
실습
라이브러리 불러오기
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.impute import KNNImputer
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt데이터 불러오기
titanic = sns.load_dataset('titanic')- seaborn 데이터셋의 타이타닉 데이터 불러오기
도메인 데이터를 활용한 결측치 처리
def fill_age_based_on_rules(df):
df['fare_bin'] = pd.qcut(df['fare'], q=4, labels=['low', 'mid-low', 'mid-high', 'high'])
age_means = df.groupby(['sex', 'pclass', 'fare_bin'], observed=False)['age'].mean()
def fill_age(row):
if np.isnan(row['age']):
group_mean = age_means.get((row['sex'], row['pclass'], row['fare_bin']))
return group_mean if group_mean == np.nan else df['age'].mean()
return row['age']
df['age'] = df.apply(fill_age, axis=1)
df.drop(columns=['fare_bin'], inplace=True)
return df
titanic_cleaned = fill_age_based_on_rules(titanic)- 타이타닉 데이터에 age 속성에는 177개의 결측치가 존재한다.
- 승객의 나이는 성별이나 등급, 요금과 밀접한 연관이 있을 가능성이 높다. 이런 연관성을 반영하여 더 정확한 결측치 처리를 수행한다.
- 수행 방법 :
- 그룹별 평균 계산
sex,pclass,fare_bin의 조합을 통해 그룹별로 나이의 평균값을 계산하고, 결측된 나이를 해당 그룹의 평균으로 대체한다.- 이는 단순 전체 평균보다 나이 분포를 더 잘 반영한다.
- 대체값 보완
- 그룹에 해당하는 평균값이 없는 경우, 전체 평균으로 대체하여 결측치를 최소화한다.
- 그룹별 평균 계산
독립변수와 종속변수 분리
X = titanic_cleaned[['pclass', 'age', 'sibsp', 'parch', 'fare', 'sex', 'embarked', 'class']]
y = titanic_cleaned['survived']범주형 변수에 원-핫 인코딩 적용
X = pd.get_dummies(X, drop_first=True)(참고)열을 명시해주지않아도 범주형 변수에 대해 자동으로 인코딩 적용함drop_first=True: 원-핫 인코딩 결과에서 첫 번째 범주를 제거하여 다중공선성 문제를 방지한다.- 다중공선성: 독립 변수들 간에 강한 상관관계가 존재하여 회귀 모델이 변수의 영향을 독립적으로 측정하지 못하게 되는 문제를 말합니다.
- 선형기반 모델에서는 각 독립 변수의 영향을 명확히 측정해야 하므로, 다중공선성을 줄이는 것이 중요합니다.
학습 및 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)모델 생성 및 평가
# 랜덤포레스트 모델 생성 및 훈련
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
# 성능 평가
def evaluate_model(y_true, y_pred):
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
return accuracy, precision, recall, f1
train_metrics = evaluate_model(y_train, y_train_pred)
test_metrics = evaluate_model(y_test, y_test_pred)
metrics_df = pd.DataFrame({
"Train": train_metrics,
"Test": test_metrics
})
metrics_df| Metric | Train | Test | |
|---|---|---|---|
| 0 | Accuracy | 0.980337 | 0.815642 |
| 1 | Precision | 0.988462 | 0.797101 |
| 2 | Recall | 0.958955 | 0.743243 |
| 3 | F1 Score | 0.973485 | 0.769231 |
이상치(Outlier)
- 데이터 분포에서 비정상적으로 크거나 작은 값으로, 나머지 데이터와 극단적으로 차이가 나는 값을 의미한다.
- 이상치가 발생하는 이유?
- 데이터 입력 오류 (Data Entry Errors)
- 사람이 데이터를 잘못 입력하거나 단위를 혼동해서 발생하는 오류
- 예: 나이를 입력할 때
30대신300으로 입력
- 측정 오류 (Measurement Errors)
- 장비나 시스템의 오작동으로 비정상적인 값이 기록되는 경우
- 예: 고장난 센서가 온도를 1000도로 기록
- 샘플링 오류 (Sampling Errors)
- 표본이 모집단을 제대로 대표하지 못할 때 발생
- 예: 설문 조사에서 특정 집단만 과도하게 포함된 경우
- 자연 발생 이상치 (Natural Outliers)
- 실제 데이터에서 극단적인 특성을 가진 경우
- 예: 올림픽 선수의 체중이나 세계 최고령자의 나이
- 데이터 처리 오류 (Data Processing Errors)
- 데이터 전처리, 병합, 또는 변환 과정에서 잘못된 값이 발생
- 예: 데이터 병합 과정에서 값이 중복되거나 손실된 경우
- 데이터 입력 오류 (Data Entry Errors)
정규분포를 기반으로 표준편차를 이용한 이상치 탐지
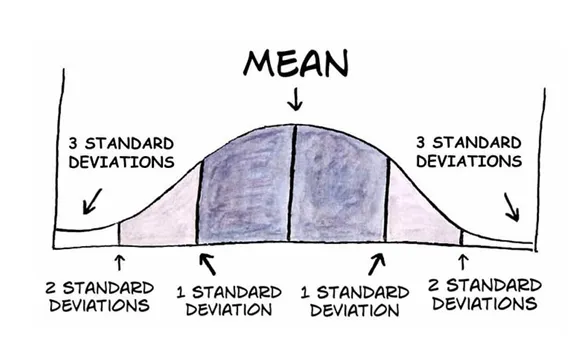
-
정규분포의 특성
- 평균(Mean)을 중심으로 대칭적인 종 모양을 가지며, 데이터가 평균으로부터 멀어질수록 발생 확률이 낮아진다.
- 표준편차(Standard Deviation)는 데이터가 평균으로부터 얼마나 떨어져 있는지를 나타낸다.
-
이상치 탐지 기준
-
일반적으로 평균으로부터 2~3표준편차 이상 떨어진 데이터를 이상치로 간주 (
68-95-99.7 Rule)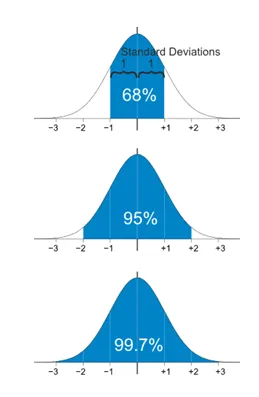
- 평균 ± 1 표준편차: 데이터의 약 68%가 포함
- 평균 ± 2 표준편차: 데이터의 약 95%가 포함
- 평균 ± 3 표준편차: 데이터의 약 99.7%가 포함
-
MAD를 기반으로 이상치 탐지

- MAD의 정의
- MAD(중앙값 절대 편차, Median Absolute Deviation)는 데이터의 중앙값(Median)을 기준으로 변동성을 측정하는 통계적 지표입니다.
- 이상치에 강건한(Robust) 척도로, 평균과 표준편차보다 이상치의 영향을 덜 받는다.
- 이상치 탐지 기준
- 일반적으로 중앙값 ± k × MAD 범위를 벗어난 데이터를 이상치로 간주
- k 값은 보통 1.5~3 사이의 값을 사용하며, 분석 목적에 따라 조정할 수 있다.
IQR을 기반으로 이상치 탐지
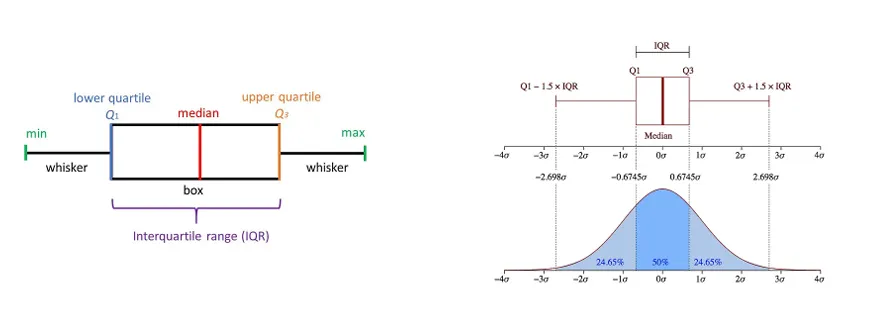
- IQR의 정의
- 사분위수 범위는 데이터의 75번째 백분위수(Q3)와 25번째 백분위수(Q1)의 차이를 나타내며, 데이터의 중심 50% 범위를 측정한다.
- Q1 (1사분위수): 데이터의 하위 25% 값
- Q3 (3사분위수): 데이터의 상위 25% 값
- IQR: Q3 - Q1, 데이터의 중앙 50% 범위를 측정
- 사분위수 범위는 데이터의 75번째 백분위수(Q3)와 25번째 백분위수(Q1)의 차이를 나타내며, 데이터의 중심 50% 범위를 측정한다.
- 이상치 탐지 기준
- 경계를 벗어난 값을 이상치로 간주
- 아래 경계: Q1 - 1.5 × IQR
- 위 경계: Q3 + 1.5 × IQR
- 경계를 벗어난 값을 이상치로 간주
Isolation Forest를 이용한 이상치 탐지
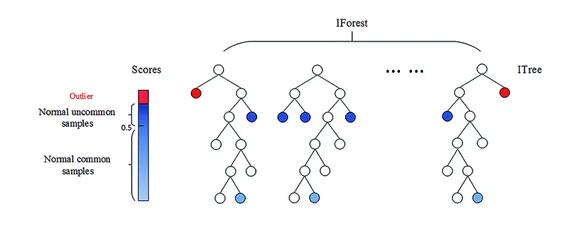
- Isolation Forest의 정의
- 랜덤 서브샘플링과 결정 트리 구조를 이용하여 이상치를 탐지하는 알고리즘이다.
- 랜덤 샘플링: 전체 데이터에서 일부(1~10%)를 랜덤하게 추출하여 분석
- 결정 트리: 데이터를 재귀적으로 분할하여 이상치 탐지
- 데이터 포인트를 재귀적으로 분할하며, 분리 깊이를 기준으로 이상치를 판별한다.
- 랜덤 서브샘플링과 결정 트리 구조를 이용하여 이상치를 탐지하는 알고리즘이다.
- 이상치 탐지 기준
- 분리 깊이가 얕을수록 이상치일 확률이 높음
- 분리 깊이: 각 데이터 포인트가 트리에서 분리되는 데 걸리는 경로 길이
- 이상치 점수: 평균 분리 깊이를 기반으로 계산하며, 데이터 분포와 샘플 크기를 반영하여 조정
- 이상치 점수가 높은 데이터를 이상치로 간주
- 분리 깊이가 얕을수록 이상치일 확률이 높음
DBSCAN을 이용한 이상치 탐지
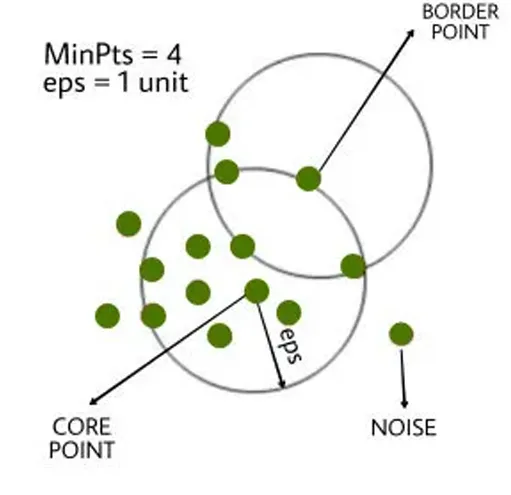
- DBSCAN의 정의
- 밀도 기반의 군집화 알고리즘으로, 데이터의 밀집된 영역(클러스터)을 식별한다.
- 밀도 기준으로 데이터 포인트를 분류하여 이상치 탐지에 활용할 수 있다.
- DBSCAN의 핵심 개념
- Core Point (핵심점):
- 반지름 ϵ 내에 최소 데이터 포인트(minPts) 이상이 포함된 데이터 포인트
- 클러스터의 중심을 형성
- Border Point (경계점):
- Core point의 ϵ 내에 포함되지만, 최소 데이터 포인트(minPts) 기준에 도달하지 못하는 데이터 포인트
- 클러스터의 경계를 정의
- Noise (노이즈):
- 어떤 Core Point나 Border Point에도 속하지 않는 데이터 포인트
- 이상치(Outlier)로 간주
- Core Point (핵심점):
- 이상치 탐지 기준
- 밀도가 낮은 영역의 데이터 포인트를 이상치로 간주한다.
- 어떤 클러스터에도 속하지 않는 데이터 포인트를 뜻한다.
- 밀도가 낮은 영역의 데이터 포인트를 이상치로 간주한다.
LOF(Local Outlier Factor)를 이용한 이상치 탐지
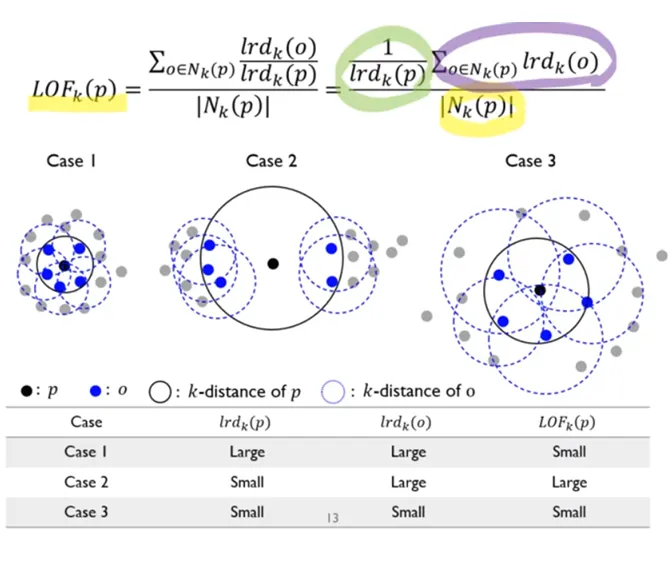
- LOF의 정의
- 밀도 기반 이상치 탐지 알고리즘으로, 특정 데이터 포인트의 지역적 밀도를 계산하고 이를 주변 데이터의 밀도와 비교하여 이상치를 탐지하는 방법이다.
- 데이터 포인트가 속한 지역의 밀도가 주변 지역보다 현저히 낮으면 이상치로 간주한다.
- LOF의 핵심 개념
- Local Reachability Density (LRD):
- 특정 데이터 포인트의 지역 밀도를 나타내며, 반경 내 데이터 포인트의 평균 거리를 기반으로 계산
- 주변 데이터 밀도가 높을수록 LRD 값이 커짐
- LOF 점수 (Local Outlier Factor):
- 특정 데이터 포인트의 지역 밀도를 이웃 데이터 포인트의 지역 밀도와 비교하여 이상치 점수를 계산
- LOF 점수가 임계값보다 ****크면 주변 밀도에 비해 낮은 밀도를 가지며 이상치로 간주
- Local Reachability Density (LRD):
- 이상치 탐지 기준
- 데이터 포인트의 LOF 점수를 기준으로 이상치 여부를 판단
- LOF 점수가 높을수록 이상치 가능성이 증가.
- 일반적으로 LOF 점수가 특정 임계값을 초과하면 이상치로 간주
- 데이터 포인트의 LOF 점수를 기준으로 이상치 여부를 판단
정리 표
| 방법 | 기준 값 | 특징 | 적용 데이터 |
|---|---|---|---|
| 정규분포 기반 | 평균 ± k × 표준편차 (보통 k=2~3) | 정규분포 가정, 간단한 계산 | 정규분포 데이터에 적합 |
| MAD 기반 | 중앙값 ± k × MAD (보통 k=1.5~3) | 이상치에 강건함, 중앙값 중심 | 정규/비정규분포 모두 가능 |
| IQR 기반 | Q1 - 1.5×IQR, Q3 + 1.5×IQR | 사분위수를 기준으로 이상치 탐지 | 정규/비정규분포 모두 가능 |
| Isolation Forest | 평균 분리 깊이 (결정 트리 기반) | 랜덤 샘플링과 분리 깊이 기준 이상치 탐지 | 대규모 데이터, 고차원 데이터 적합 |
| DBSCAN | 반경 ϵϵ 내 밀도와 데이터 수 | 밀도 기반, 클러스터 식별 및 이상치 탐지 | 비선형, 밀집 데이터에 적합 |
| LOF (Local Outlier Factor) | 지역 밀도와 이웃 밀도 비교 점수 (LOF) | 주변 밀도 대비 상대적 밀도로 이상치 탐지 | 밀도가 다양한 데이터에 적합 |
시계열 데이터 이상치 탐지법
슈하르트 (Shewhart Control Charts)
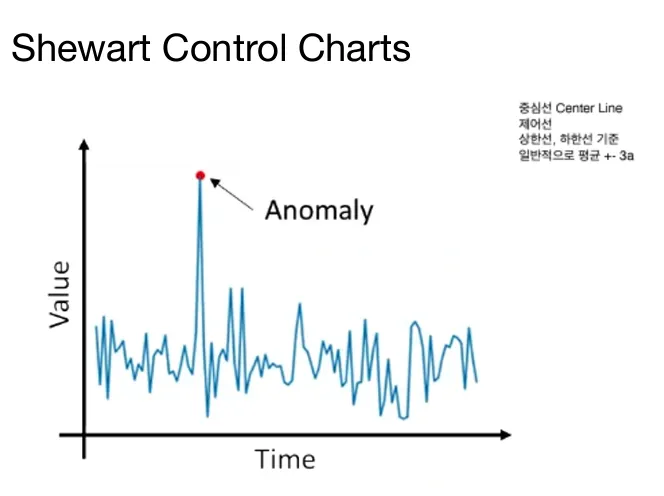
- 데이터가 관리 한계(Upper/Lower Control Limits)를 벗어나는지 판단.
- 데이터 분포의 평균과 표준편차를 기반으로 설정된 3σ 범위를 초과하면 이상치로 간주
STL Decomposition을 이용한 이상치 탐지
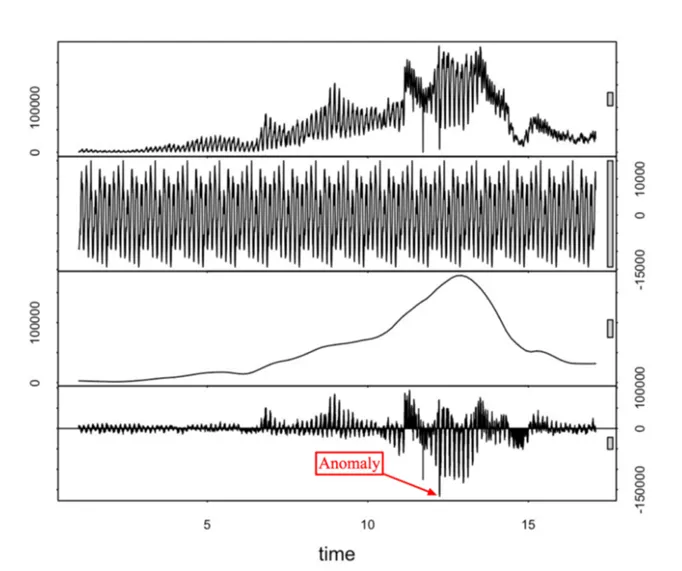
- 시계열 데이터를 Seasonal(계절성), Trend(추세), Residual(잔차)로 분해하여 이상치를 탐지
- 잔차 : 원 데이터에서 추세와 계절성을 제거한 값
- 잔차를 분석하여 패턴에서 벗어난 데이터를 이상치로 간주
- 계절성과 추세를 고려하므로, 복잡한 시계열 데이터에서도 이상치를 효과적으로 탐지.
ARIMA를 이용한 이상치 탐지
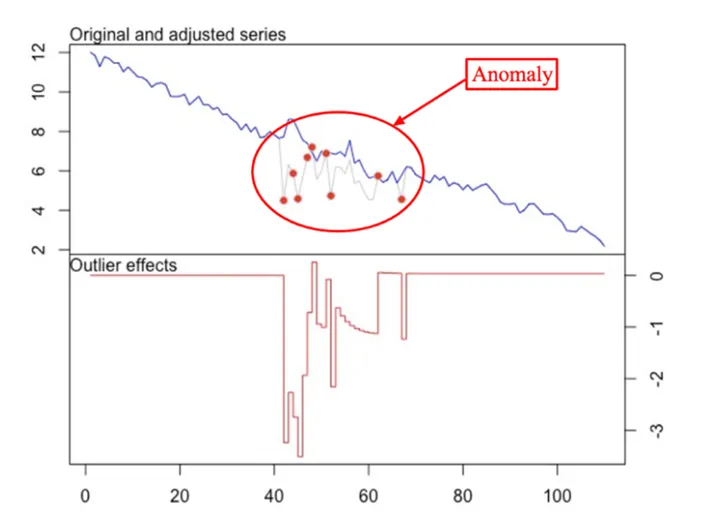
- 시계열 데이터의 예측값과 실제값의 차이(잔차)를 기반으로 이상치를 탐지
- ARIMA 모델로 예측한 값에서 잔차가 일정 임계값(예: 3σ)을 초과하면 이상치로 간주
- 데이터의 자기회귀(AR)와 이동평균(MA)을 결합하여 시계열 패턴을 반영
💡 도메인 지식을 통한 Outlier 선정의 중요성
- 특정 데이터가 이상치로 보이더라도, 실제 의미 있는 값일 수 있다.
- 반대로 정상 범위 내에 있어도 도메인 관점에서 비정상적인 데이터일 수 있다.
- 따라서 도메인 지식은 통계적 방법을 보완하여 보다 정확하고 의미 있는 이상치 선정을 가능하게 한다.
실습
💡 목표 : IQR과 IsolationForest를 이용한 이상치 탐지하기
🧪 IQR을 이용한 이상치 탐지
라이브러리 불러오기
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt데이터 불러오기
tips = sns.load_dataset('tips')
data = tips[['total_bill', 'tip', 'size']]- seaborn에서 제공하는 tips 데이터에는 일반적으로 이상치가 없이 잘 정제된 데이터셋이지만 실습을 위해 사용함
히스토그램 및 박스플롯 그리기
fix, axes = plt.subplots(3, 2, figsize=(12, 6))
for i, column in enumerate(data.columns):
sns.histplot(data[column], bins=30, ax = axes[i,0], kde=True, color='blue')
axes[i,0].set_title(f'Hist {column}')
sns.boxplot(x=data[column], ax=axes[i,1], color='orange')
axes[i,1].set_title(f'box {column}')
fix.tight_layout()
plt.show()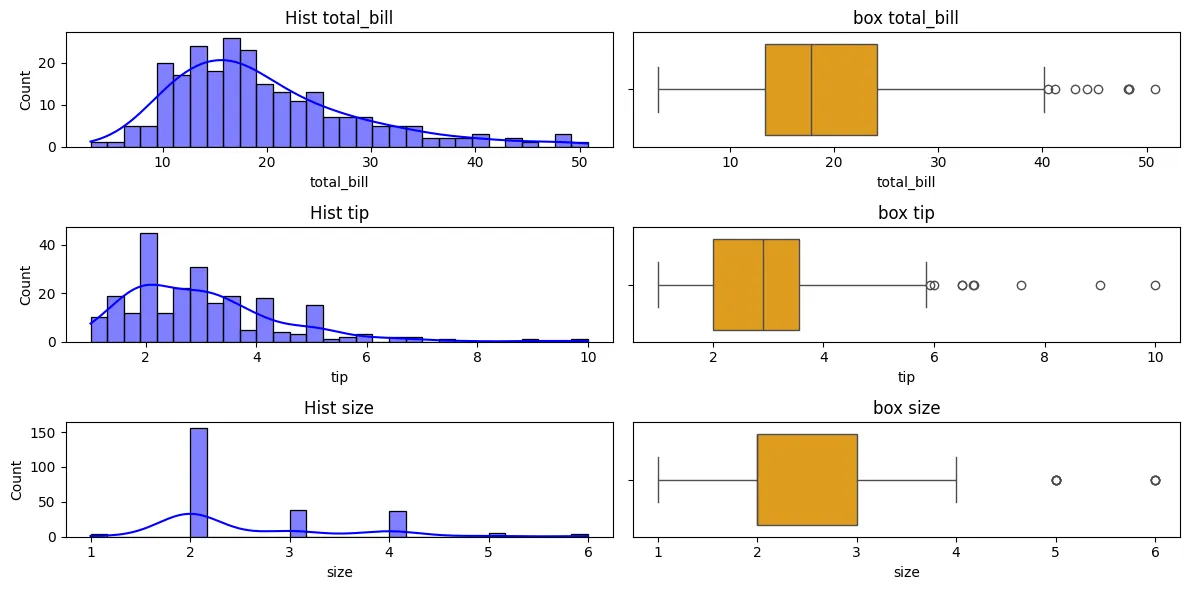
이상치 출력
def detect_outliers_iqr(df, column):
Q1 = np.percentile(df[column], 25) # 1사분위수
Q3 = np.percentile(df[column], 75) # 3사분위수
IQR = Q3 - Q1 # IQR 계산
lower_bound = Q1 - 1.5 * IQR # 이상치 하한
upper_bound = Q3 + 1.5 * IQR # 이상치 상한
return df[(df[column] < lower_bound) | (df[column] > upper_bound)]
outliers_iqr = pd.concat([detect_outliers_iqr(data, col).assign(Column=col) for col in data.columns]).reset_index()
outliers_iqr = outliers_iqr.set_index('Column')
outliers_iqr이상치가 제거된 데이터셋 출력
def remove_outliers_iqr(df, columns):
total_rows = len(df)
outlier_indices = []
# 모든 열에 대해 이상치 탐지
for column in columns:
outliers = detect_outliers_iqr(df, column)
outlier_indices.extend(outliers.index.tolist())
# 중복된 인덱스 제거
outlier_indices = list(set(outlier_indices))
# 이상치 제거
df_cleaned = df.drop(index=outlier_indices)
# 제거된 이상치 개수 출력
removed_count = len(outlier_indices)
print(f"전체 데이터 중 {removed_count}개의 이상치가 제거되었습니다.")
print(f"이상치 제거 후 데이터 개수: {len(df_cleaned)}개")
return df_cleaned
data_cleaned = remove_outliers_iqr(data, data.columns).reset_index(drop=True)
data_cleaned 🧪 IsolationForest를 이용한 이상치 탐지
라이브러리 불러오기
from sklearn.ensemble import IsolationForest이상치 탐지 모델 생성 및 학습
iso = IsolationForest(contamination = 0.05, random_state=42)
outlier_flags = iso.fit_predict(data)contamination: 이상치로 간주할 데이터 포인트의 비율
이상치 출력
outliser_iso = data[outlier_flags==-1]
outliser_iso이상치 제거 후 데이터 출력
data_cleaned = data[outlier_flags == 1].reset_index(drop=True)
data_cleaned범주형 변수에 대한 이상치 처리
- 오늘 다룬 이상치 처리 기법들은 모두 수치형 변수에 대한 이상치 처리 방법이었다.
- 범주형 변수에 대한 이상치 처리는 다른 방법으로 접근해야한다.
범주형 변수 이상치 처리 기법 예시
- 빈도 기반 탐지
- 빈도수가 매우 낮은 범주를 이상치로 간주
- 예: 특정 범주의 빈도가 전체 데이터의 1% 미만인 경우 'Rare'로 대체하거나 제거
- 도메인 지식 활용
- 데이터에 허용되지 않는 범주를 도메인 지식을 통해 직접 정의
- 예: "Male", "Female" 외의 성별 값을 이상치로 간주
- 범주형 이상치 대체
- 이상치를 'Other' 또는 'Unknown' 같은 공통 범주로 대체
- 모델 기반 탐지
- K-모드(K-Modes) 또는 Categorical DBSCAN 등의 군집화 알고리즘을 사용해 밀도 기반으로 이상치 탐지
- K-Modes : K-means 알고리즘을 범주형 데티이터에 맞게 확장한 형태
- K-모드(K-Modes) 또는 Categorical DBSCAN 등의 군집화 알고리즘을 사용해 밀도 기반으로 이상치 탐지

제 글이 유익하셨다면 ♡와 팔로우로 응원 부탁드립니다.