Machine Learning by professor Andrew Ng in Coursera
1) Cost Function
Neural Network (Classification)
우선 앞으로 사용할 새로운 변수들
- L = total no. of layers in network
- sl = no. of units (not counting bias unit) in layer l
Binary Classification에서 y는 0 또는 1 만을 갖는다.
즉, output unit은 1개 &
hθ(x)∈R
SL=1,K=1
Multiclass Classification (K classes) 라면
output units은 K개 &
y∈RK E.g⎣⎢⎢⎢⎢⎢⎡100...0⎦⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎡010...0⎦⎥⎥⎥⎥⎥⎤
hθ(x)∈RK,SL=K(K>=3)
Cost Function
neural network는 많은 ouput nodes를 가질 수 있다.
이때 hΘ(x)k를 k번째 output의 hypothesis라고 한다.
Our cost function for neural networks is going to be a generalization of the one we used for logistic regression. Recall that the cost function for regularized logistic regression was:
Logistic Regression:
J(θ)=−m1i=1∑m[y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
Neural Network:
hθ(x)∈Rk , ((hθ(x))k=kthoutput)
J(Θ)=−m1[i=1∑mk=1∑Kyk(i)log(hθ(x(i)))k+(1−yk(i))log(1−hΘ(x(i)))k]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θji(l))2
'이때 regularization term들은 전부 0이 아니라 1부터 ∑ 가 시작된다.
bias term θ0는 정규화하지 않기 때문'
- multiple output nodes를 고려하기 위해 몇 개의 nested summation이 추가된다.
- 대괄호([ ]) 안에 output node 갯수만큼 반복되는 nested summation이 추가된다.
- 정규화 부분에서 multiple theta 행렬을 고려해야 한다.
- theta 행렬의 열은 bias unit을 포함한 현재 layer의 node 개수와 같다.
- theta 행렬의 행은 bias unit을 제외한 다음 layer의 node 개수와 같다.
- logistic regression과 마찬가지로 모든 항을 제곱한다.
2) Backpropagation Algorithm
"Backpropagation"은 neural-network에서 비용 함수의 최솟값을 찾는 방법으로 logistic/linear regression에서의 gradient descent와 같은 역할을 한다.
Gradient Computation
비용 함수를 최소화하는 최적의 parameter θ 찾아야 한다.
즉,
ΘminJ(Θ)
J(θ)는 이미 위에서 알았고,
∂Θi,j(l)∂J(Θ)를 어떻게 계산할지 알아본다.
Given one training example (x, y):
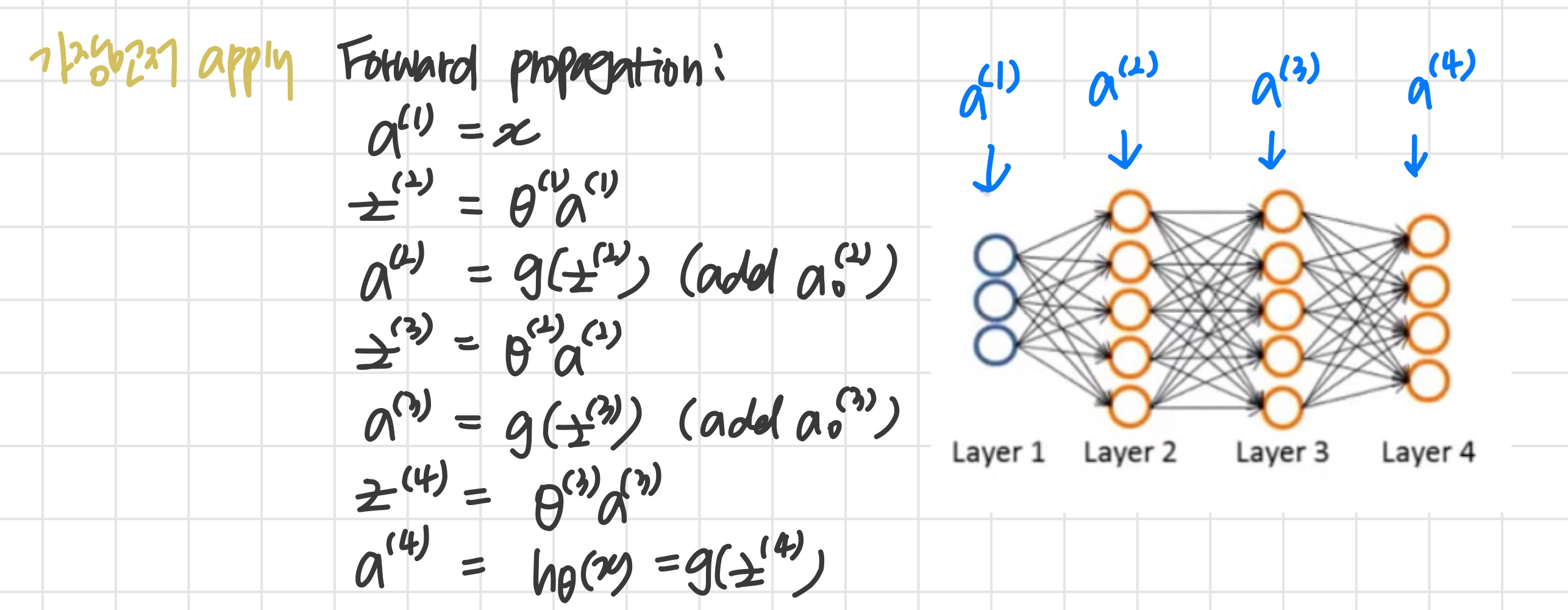
Gradient Computation : Backpropagation algorithm
- δj(l) = error of node j in layer l
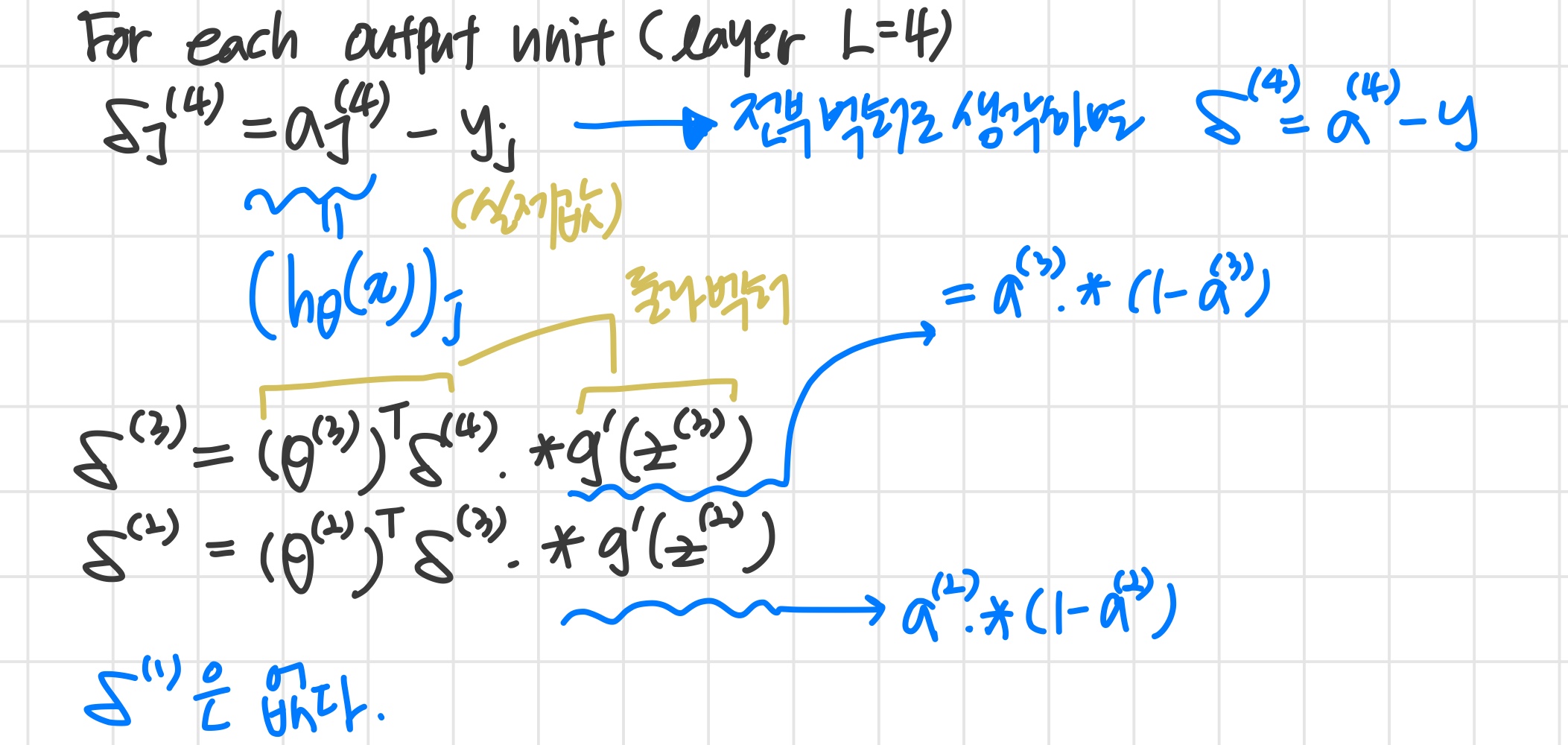
Backpropagation algorithm
{((x(1),y(1))...(xm,y(m))} 의 훈련세트가 주어진다.
- δij(l)=0 (for all l, i, j) 라 설정한다.
For i=1 to m
-
Set a(1):=x(i)
-
Perform forward propagation to compute a(l) for l = 1, 2, ... L
-
y(i)를 이용해서 δ(L)=a(L)−y(i)을 계산한다.
-
δ(l)=((Θ(l))Tδ(l+1)).∗a(l).∗(1−a(l)) 을 이용해서 δ(L−1),δ(L−2)...δ(2)를 계산한다.
이때 .*은 element-wise multiply 를 의미한다.
g′(z(l))=a(l).∗(1−a(l))
- Δi,j(l):=Δi,j(l)+aj(l)δi(l+1), 이 식을 벡터화하면 Δ(l):=Δ(l)+δ(l+1)(a(l))T
for 루프를 빠져나온 뒤
새로운 Δ 행렬을 아래와 같이 업데이트한다.
-
Di,j(l):=m1(Δi,j(l)+λΘi,j(l)), if j=0
-
Di,j(l):=m1Δi,j(l), if j≡0
이렇게 Dij(l)을 계산하면
그게 곧 ∂Θi,j(l)∂J(Θ)=Di,j(l)
The capital-delta matrix D is used as an "accumulator" to add up our values as we go along and eventually compute our partial derivative.
D 행렬은 결국에는 편미분을 구하게 해주는 "accumulator"로 동작한다.
3) Backpropagation Intuition
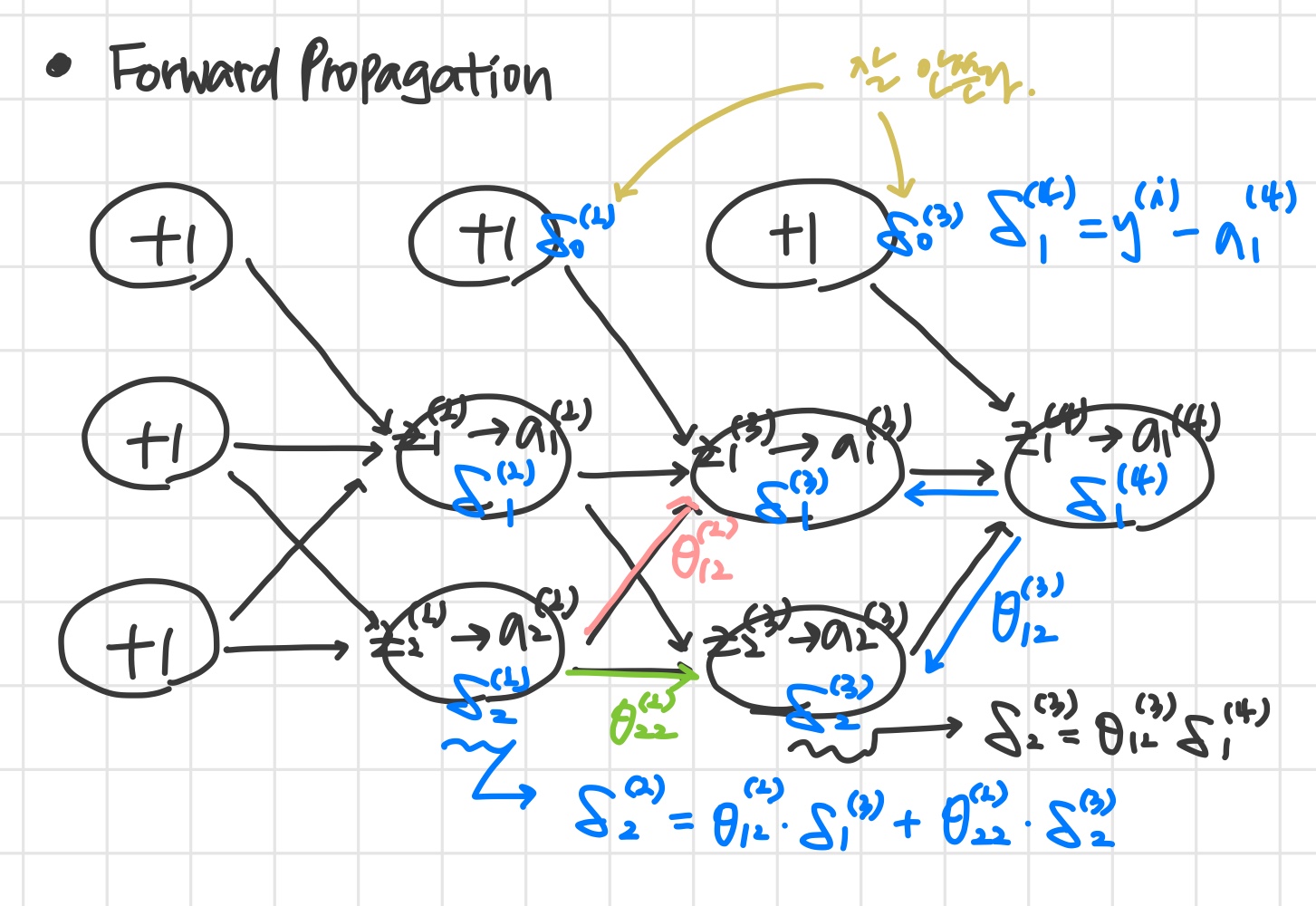
Forward Propagation
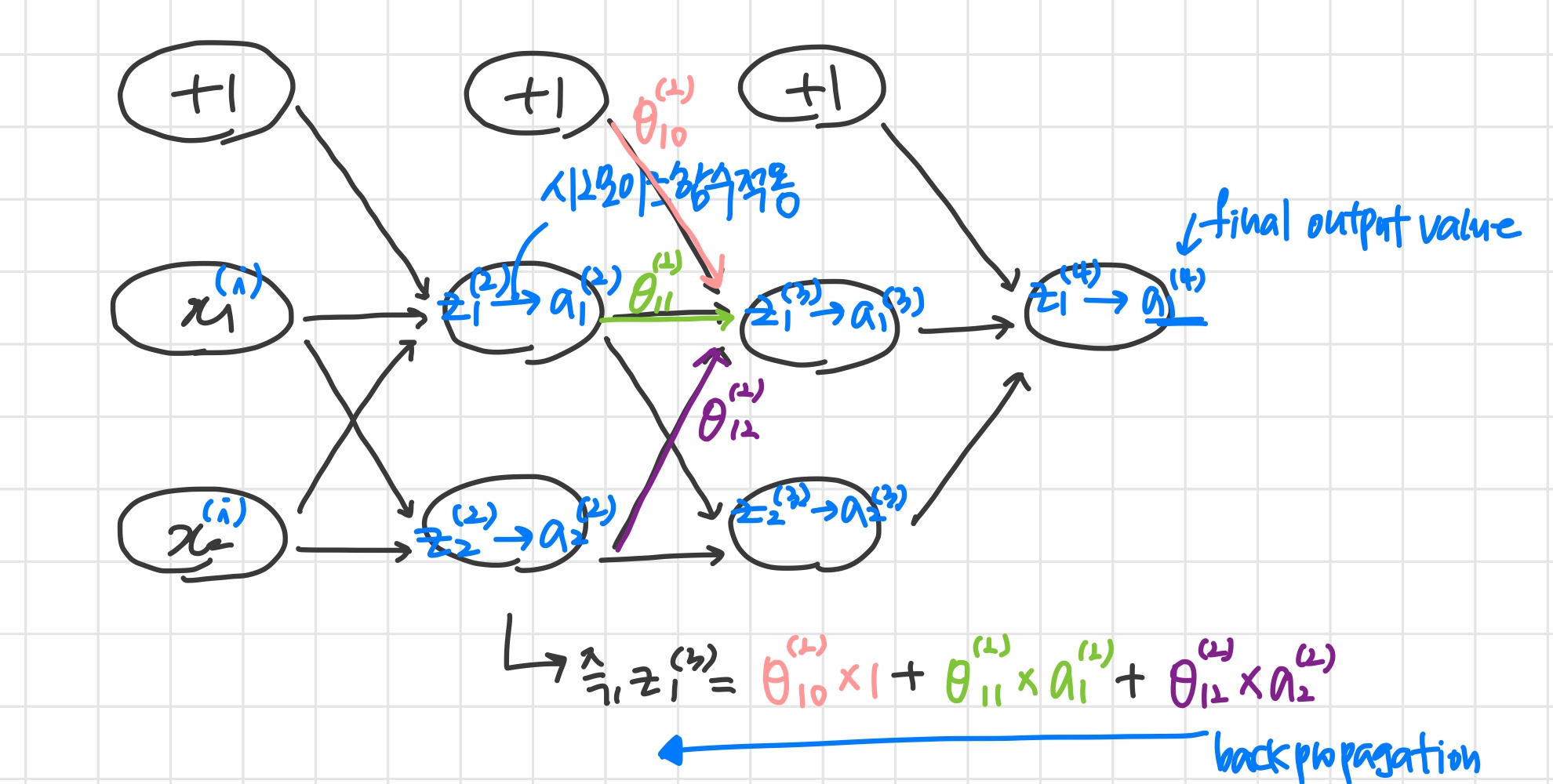
What is backpropagation doing?
neural network의 cost function은 아래와 같다.
J(Θ)=−m1[t=1∑mk=1∑Kyk(t)log(hθ(x(t)))k+(1−yk(t))log(1−hΘ(x(t)))k]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θji(l))2
If we consider simple non-multiclass classification (k = 1) and disregard regularization, the cost is computed with:
cost(t)=y(t)log(hθ(x(t)))+(1−y(t))log(1−hθ(x(t)))
Intuitively, δj(l) is the "error" for aj(l) (unit j in layer l). More formally, the delta values are actually the derivative of the cost function:
δj(l)=∂zj(l)∂cost(t)
Recall that our derivative is the slope of a line tangent to the cost function, so the steeper the slope the more incorrect we are. Let us consider the following neural network below and see how we could calculate some δj(l):

_😡
